


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Семантически взаимодействие параллельных процессов лучше всего представлять как работу сети неких устройств, соединенных "проводками", по которым текут данные. Спроектировав в таких терминах, например, систему параллельных процессов для быстрого суммирования большого количества чисел, можно легко описать эту систему в приведенном синтаксисе.
Каждый вычислитель производит типичные для его вычислительной модели операции (например, императивный вычислитель будет переходить из состояния в состояние). Когда процесс встречает инструкцию "Принять значение (из канала)", он входит в состояние ожидания, пока канал пуст. Как только в канале появляется значение, процесс его считывает и продолжает работу.
Достаточно распространенной является так же и следующее понимание параллелизма: в системе параллельных процессов каждый отдельный процесс обрабатывает события. События могут быть как общими для всей системы, так и индивидуальными для одного или нескольких процессов. В таких терминах достаточно удобно описывать, например, элементы графического интерфейса пользователя, или моделирование каких-либо реальных процессов (например, управление уличным движением) - так как понятие события является для таких задач естественным. Такое программирование принято называть событийно-управляемым. В событийно-управляемом программировании отдельные процессы максимально автономны, единственное средство общения между ними - посылка сообщений (порождение новых событий). Событийно-управляемое программирование очень близко к объектно-ориентированному программированию, которое будет подробно разобрано в дальнейшем.
Параллелизм является не только надстройкой над другими вычислительными моделями; некоторые методологии программирования имеют естественную реализацию на платформах, поддерживающих параллелизм. Об этом будет упомянуто отдельно в каждом таком случае.
6. Объектно-ориентированное программирование
Объектно-ориентированное программирование появилось на свет божий из недр событийно-управляемого программирования и практически затмило его своим светом, так как оказалось значительно более мощным и универсальным средством программирования и проектирования.
В чистом объектно-ориентированном программировании все, что можно - процессы, данные, события - являются объектами. Все объекты располагают некоторыми "собственными" данными, представленными как ссылки на другие объекты. Объекты могут обмениваться между собой сообщениями. При получении объектом сообщения запускается соответствующий ему обработчик, иначе называемый методом. У объекта есть ассоциативный контейнер, который позволяет получить по сообщению его метод для его обработки. Кроме этого, у объекта есть объект-предок. Если метод для обработки сообщения не найден, сообщение будет перенаправлено объекту-предку. Эту структуру в целом (таблица обработчиков + предки) из соображений эффективности выделяют в отдельный объект, называемый классом данного объекта. У самого объекта будет ссылка на объект, представляющий его класс. Объект по отношению к сковему классу является экземляром. Так как классы тоже представлены, как объекты, существует класс, определяющий поведение, общее для всех классов. Такой класс принято называть метаклассом.
Важно выделить следующие основные свойства объектов:
1.) Так как один объект может воздействовать на другой исключительно при помощи посылки последнему сообщений, он не может как-либо непосредственно работать с собственными данными "собеседника", и, следовательно, не может нарушить их внутреннюю согласованность. Это свойство (сокрытие данных) принято называть инкапсуляцией.
2.) Так как объекты взаимодействуют исключительно засчет обмена сообщениями, объекты-собеседники могут ничего не знать о реализации обработчиков сообщений у своего визави. Взаимодействие происходит исключительно в терминах сообщений/событий, которые достаточно легко привязать к предметной области. Это свойство (описание взаимодействия исключительно в терминах предметной области) называют абстракцией.
3.) Объекты взаимодействуют исключительно через посылку сообщений друг другу. Поэтому если в каком-либо сценарии взаимодействия объектов заменить произвольный объект другим, способным обрабатывать те же сообщения, сценарий так же будет реализуем. Это свойство (возможность подмены объекта другим объектом со сходной структурой класса) называется полиморфизмом.
Отношение "потомок-предок" на классах принято называть наследованием.
Все эти свойства по-отдельности встречаются и в других методологиях программирования. Так, локальные переменные инкапсулированы в процедуре. Объектно-ориентированное программирование достаточно гармонично их сочетает.
Синтаксис чистых объектно-ориентированных языков описывает всего одну операцию: послать сообщение M объекту А с параметрами B1..Вn. Параметры сообщения - это объекты, которые сами могут быть результатами обработки других сообщений. Часто операцию "вернуть объект-результат" так же вводят в явном виде, хотя ее достаточно легко реализовать как посылку сообщения системному объекту "стек возвращаемых значений".
Если в чистом объектно-ориентированном языке нужно создать новый класс - требуется послать классу-предку сообщение: "породить наследника" ( sublcass ). Существует класс, являющийся вершиной всей иерархии наследования (как правило, наываемый Object), так что предок будет у всех классов, даже явно его не имеющих. Для описания обработки сообщения нужно послать классу, в котором задается обработчик, сообщение: "установить новый обработчик сообщения" ( answer ).
7. Функциональное программирование
До сих пор рассматриваемые нами парадигмы программирования воспринимались нами как некоторые "полезные надстройки над императивным программированием". Уже отмечалось, например, что параллельное программирование - это программирование в терминах взаимодействия некоторых одновременно работающих абстрактных вычислителей, и почти ничего не говорили о вычислительной модели, на которой основаны отдельные элементы этой системы. Мы ничего не сказали о том, на каком языке описаны обработчики сообщений у объектов (кроме того, что в этих языках основной операцией является посылка сообщения). Функциональное программирование представляет из себя одну из альтернатив императивному подходу.
В императивном программировании алгоритмы - это описания последовательно исполняемых операций. Здесь существует понятие "текущего шага исполнения" (то есть, времени), и "текущего состояния", которое меняется с течением этого времени.
В функциональном программировании понятие времени отсутствует. Программы являются выражениями, исполнение программ заключается в вычислении этих выражений. Практически все математики, сами того не замечая, занимаются функциональным программированием, описывая, например, чему равно абсолютное значение произвольного вещественного числа.
Императивное программирование основано на машине Тьюринга-Поста - абстрактном вычислительном устройстве, предложенном на заре алгоритмической эры для описания алгоритмов. Функциональное программирование основано на более естественном с математической точки зрения формализме - лямбда-исчислении Черча.
Как правило, рассматривают так называемое "расширенное лямбда-исчисление". Его грамматику можно описать следующим образом (жаль, что не в любой локализации есть символ "лямбда"):
Выражение ::= Простое выражение | Составное выражение
Простое выражение ::= Константа | Имя
Составное выражение ::= Лямбда-абстракция | Применение | Квалифицирванное выражение | Ветвление
Лямбда-абстракция ::= lambda Имя -> Выражение end
Применение ::= ( Выражение Выражение )
Квалифицированное выражение ::= let ( Имя = Выражение ; )* in Выражение end
Ветвление ::= if Выражение then Выражение (elseif Выражение then Выражение)* else Выражение end
Константами в расширенном лямбда-исчислении могут быть числа, кортежи, списки, имена предопределенных функций, и так далее.
Результатом вычисление применения предопределенной функции к аргументам будет значение предопределенной функции в этой "точке". Результатом применения лямбда-абстракции к аргументу будет подстановка аргумента в выражение - "тело" лямбда-абстракции. Сами лямбда-абстракции так же являются выражениями, и, следовательно, могут быть аргументами.
Вы уже заметили, что лямбда-абстракции имеют всего один аргумент. В то же время, функции в традиционном понимании не обязаны быть одноместными. Представления функций от нескольких аргументов можно достичь двумя способами:
1.) Считать, что аргумент является кортежем. Например, apply = lambda (f, x) -> ( f x ) end можно понимать как apply = lambda y -> ( ( first y ) ( second y ) ) end.
2.) Понять, что множество вычислимых функций X * Y -> Z очевидным образом взаимнооднозначно отображается в множество вычислимых функций X -> (Y -> Z). Так, apply = lambda f -> lambda x -> (f x) end end.
Когда нам надоест ставить скобки вокруг применения функций к аргументам, мы можем объявить операцию применения функции (которую мы при записи опускаем, так же, как в математике принято не писать явно символ умножения) левоассоциативной, то есть, понимать запись вида f x y как ((f x) y). Это - традиционное соглашение, поэтому никаких "стандартов" мы при этом не нарушаем.
Чистое лямбда-исчисление Черча позволяет обходится исключительно именами, лямбда-абстракциями от одного аргумента и применениями выражений к выражениям. Оказывается, в этих терминах можно описать и "предопределенные" константы (числа и т. п.), структуры данных (списки, кортежи...), логические значения и ветвление. Более того, в чистом лямбда-исчислении можно обойтись без квалифицированных выражений, и, следовательно, выразить рекурсию, не используя для этого употребления имени функции в теле функции. Некоторые экспериментальные модели функционального программирования позволяют обходится без каких-либо имен вообще. Подробнее об этом можно почитать в специальной литературе, например, в книге Филда и Харрисона "Функциональное программирование".
Функциональное программирование обладает следующими двумя примечательными свойствами:
1.) Аппликативность: программа есть выражение, составленное из применения функций к аргументам.
2.) Настраиваемость: так как не только программа, но и любой программный объект (в идеале) является выражением, можно легко порождать новые программные объекты по образцу, как значения соответствующих выражений (применение порождающей функции к параметрам образца).
Настраиваемость активно используется в таком направлении программирования, как generic programming. Основная задача, решаемая в рамках это направления - создание максимально универсальных библиотек, ориентированных на решение часто встречающихся подзадач (обработка агрегатных данных; потоковый ввод-вывод; взаимодействие между программами, написанными на разных языках и различающихся в деталях семантики; универсальные оконные библиотеки). Эти направления наиболее ярко представлены в STL - стандартной библиотеке шаблонов (контейнеров) языка Си++, а так же - в реализации платформы. NET фирмы MicroSoft. Нередко в разговорах о пользе функционального программирования можно услышать следующее утверждение: "самые крупные специалисты по функциональному языку Haskell в настоящее время находятся в MicroSoft Research".
Для обеспечения видовой корректности программ в функциональные языки вводят специальные системы типов, ориентированные на поддержку настраиваемости. Как правило, трансляторы функциональных языков могут самостоятельно определять типы выражений, без каких-либо описаний типов вообще. Так, функция add = lambda x -> lambda y -> x+y end end будет иметь тип number -> number -> number, а уже рассматриваемая нами функция apply - тип any(X).any(Y).(X->Y)->X->Y, где any обозначает "квантор всеобщности" для типов, а X и Y являются переменными.
Можно заметить, что так как порядок вычисления подвыражений не имеет значения (благо "состояния" у функциональной программы нет), функциональное программирвание может быть естественным образом реализовано на платформах, поддерживающих параллелизм. "Потоковая модель" функционального программирования, о которой так же можно почитать у Филда и Харрисона, является естественным представлением функиональных программ в терминах систем взаимодействующих процессов.
Функциональное программирование, как и другие модели "неимперативного" программирования, обычно применяется для решения задач, которые трудно сформулировать в терминах последовательных операций. Практически все задачи, связанные с искусственным интеллектом, попадают в эту категорию. Среди них следует отметить задачи распознавания образов, общение с пользователем на естественном языке, реализацию экспертных систем, автоматизированное доказательство теорем, символьные вычисления. Эти задачи далеки от традиционного прикладного программирования, поэтому им уделяется не так много внимания в учебных программах по информатике.
8. Логическое программирование
В функциональном программировании программы - это выражения, и их исполнение заключается в вычислении их значения. В логическом программировании программа представляет из себя некоторую теорию (описанную на достаточно ограниченном языке), и утверждение, которое нужно доказать. В доказательстве этого утверждения и будет заключаться исполнение программы.
Логическое программирование и язык Пролог появились в результате исследования группы французских ученых под руководством Колмерье в области анализа естественных языков. В последствии было обнаружено, что логическое программирование столь же эффективно в реализации других задач искусственного интеллекта, для чего оно в настоящий момент, главным образом, и используется. Но логическое программирование оказывается удобным и для реализации других сложных задач; например, диспетчерская система лондонского аэропорта Хитроу в настоящий момент переписывается на Прологе. Оказывается, логическое программирование является достаточно выразительным средством для описания сложных систем.
В логике теории задаются при помощи аксиом и правил вывода. То же самое мы имеем и в Прологе. Аксиомы здесь принято называть фактами, а правила вывода ограничить по форме до так называемых "дизъюнктов Хорна" - утверждений вида A <= B1& ...& Bn. В Прологе такие утверждения принято записывать так:
a :- b1, ..., bn.
а факты, они же аксиомы, представлять как правила с пустой "посылкой":
a.
Переменные в утверждениях Пролога принято обозначать идентификаторами, начинающимися с заглавной буквы.
Пример простейшей программы на Прологе:
member(X, [X|_]).
member(X, [_|T]) :- member(X, T).
Эту программу можно прочитать так: "Х является членом списка, если он совпадает с головой списка, или является членом хвоста списка". В этой программе объявлен один предикат - member.
Как вы заметили, это - только набор аксиом и правил. Обычно Пролог-система работает в форме диалога с пользователем. Утверждение, которое требуется доказать, вводится с клавиатуры. Компилирующие версии трансляторов Пролога могут располагать специальными синтаксическими средствами для задания утверждений, которые требуется доказать. Такие утверждения в Прологе принято называть целями.
Зададим Пролог-системе простейший вопрос: является ли 2 членом списка [1,2,3]? Для этого введем:
?- member(2, [1,2,3]).
Пролог-система сначала попытается применить первое правило для предиката member, сравнивая 2 с головой списка [1,2,3]. Это сравнение даст неуспех, в результате чего система продолжит вывод по второму правилу, рекурсивно вызывающему предикат member, с аргументами 2 и [2,3]. В этом рекурсивном вызове сработает первое правило (так как 2 совпадает с головой списка [2,3]), и Пролог-система выдаст нечто вроде:
yes ->
Так как произвольная цель может быть доказана не единственным образом, система предлагает нам решить, пытаться ли доказать это утверждение по-другому. Ответим "да" (тем способом, как это предусмотрено в используемой Пролог-системе). Осталось незадействованным второе правило для предиката member для аргументов 2, [2,3], по которому следует пытаться доказать, что 2 есть член списка [3]. Так как 2 =/= 3, первое правило для этой цели не сработает, и доказательство пойдет дальше по второму правилу, которое предписывает доказывать утверждение member(2, []). Так у для пустых списков нет головы и хвоста, ни одно из правил для предиката member не применимо, и Пролог-система выдаст ответ:
no.
Сведущие в автоматизированном доказательстве теорем люди скажут, что Пролог-система использует для доказательства утверждений "унификацию и метод резолюций". Унификация - это сопоставление двух произвольных термов, содержащих переменные, с целью определения того, можно ли присвоить этим переменным такие значения, чтобы получились два одинаковых терма. Например, унификация термов f(X, 2) и f(1, Y), где X, Y - переменные, выдаст подстановку: X=1, Y=2. Унификация термов f(X) и Х пройдет безуспешно. Метод резолюций заключается в последовательном доказательстве отдельных утверждений, входящих в посылку дизъюнкта Хорна, для доказательства его следствия. То есть, применение метода резолюций к правилу a :- b, c. и утверждению a приведет к последовательному доказательству утверждений b и c. Метод резолюций имеет прямой аналог в обычной логике высказываний - правило modus ponens, по которому (A & A=>B) => B.
Логическое программирование допускает естественную параллельную реализацию. В примере a :- b, c. порядок согласования целей b и c не имеет значения, поэтому их можно доказывать параллельно. Говорят, что процессы доказательства b и с образуют И-систему процессов: И-система успешно доказывается, если каждый процесс, входящий в систему, успешен. В примере с предикатом member два правила для него могли применяться параллельно, образуя ИЛИ-систему процессов. ИЛИ-система успешно доказывается, если хотя бы 1 процесс в системе успешен. Переменные, общие для системы процессов(например, в случае a(X) :- b(X), c(Х).) преобразуются в каналы связи между процессами в системе. Связывание переменной (присвоение ей значения) аналогично посылке значения в канал.
В настоящее время существует несколько "промышленных" реализаций языка Пролог (наряду с большим количеством "исследовательских" версий). "Промышленный" транслятор Пролога, как правило, порождает исполняемый код, сопоставимый по эффективности с кодом аналогичной программы на императивных языках; компилируемое им подмножество "чистого Пролога" наделено строгой системой типов и возможностью вызывать процедуры, написанные на других языках (Си, Паскаль, Ассемблер...).
Среди экспериментальных расширений Пролога следует упомянуть такие языки, как лямбда-Пролог (Пролог с элементами функционального программирования), Goedel (язык, в котором семантический анализ может быть описан алгоритмически средствами самого языка), Mercury (версия чистого Пролога, предназначенная для промышленного использования и снабженная системой полиморфных типов, аналогичной используемой в современных функциональных языках).
Лекция 2
Классификация технологий программирования
1. Структурное программирование
2. Модульное программирование
3. Объектно-ориентированное программирование (ООП)
1. Структурное программирование
Сутью структурного программирования является возможность разбиения программы на составляющие элементы.
Идеи структурного программирования появились в начале 70-годов в компании IBM, в их разработке участвовали известные ученые Э. Дейкстра, Х. Милс, Э. Кнут, С. Хоор. Распространены две методики (стратегии) разработки программ, относящиеся к структурному программированию: программирование "сверху вниз" и программирование "снизу вверх".
Программирование "сверху вниз", или нисходящее программирование – это методика разработки программ, при которой разработка начинается с определения целей решения проблемы, после чего идет последовательная детализация, заканчивающаяся детальной программой. Является противоположной методике программирования «снизу вверх».
При нисходящем проектировании задача анализируется с целью определения возможности разбиения ее на ряд подзадач. Затем каждая из полученных подзадач также анализируется для возможного разбиения на подзадачи. Процесс заканчивается, когда подзадачу невозможно или нецелесообразно далее разбивать на подзадачи.
В данном случае программа конструируется иерархически - сверху вниз: от главной программы к подпрограммам самого нижнего уровня, причем на каждом уровне используются только простые последовательности инструкций, циклы и условные разветвления.
Программирование "снизу вверх", или восходящее программирование – это методика разработки программ, начинающаяся с разработки подпрограмм (процедур, функций), в то время когда проработка общей схемы не закончилась. Является противоположной методике программирования «сверху вниз».
Такая методика является менее предпочтительной по сравнению с нисходящим программированием так как часто приводит к нежелательным результатам, переделкам и увеличению времени разработки.
Рассмотрим следующий пример.
Разработать программный комплекс, который рисует на экране дисплея дачный участок, состоящий из дороги, забора, елки и сияющего на небе солнца. Нарисованная картина показана на рис. 1.
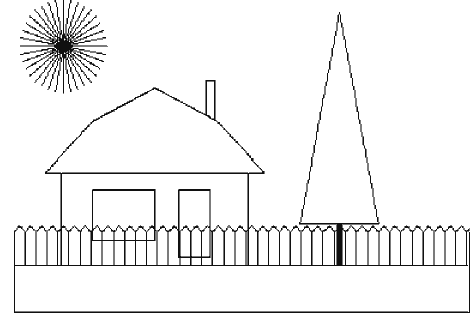
Рис. 1. Дачный участок
Укажем в виде схем, которые называются структурными диаграммами, составные элементы картины :
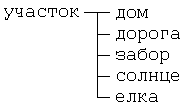
Посмотрим на изображение дома. Здесь можно выделить следующие элементы:
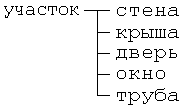
Дальнейшая детализация стены, крыши, двери, окна, трубы, дороги, забора и солнца нецелесообразна.
Елка состоит из двух элементов:
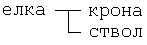
Если объединить все приведенные структурные диаграммы, то получим первый вариант изображения структурной диаграммы программного комплекса, показанный на рис. 2.
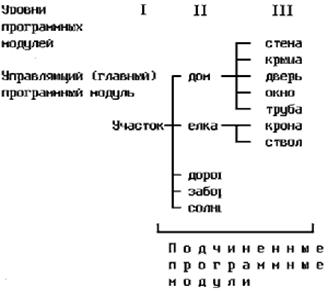
Рис. 2. Структурной диаграммы (первый вариант)
Второй вариант представления структурной диаграммы имеет вид, представленный на рис. 3.
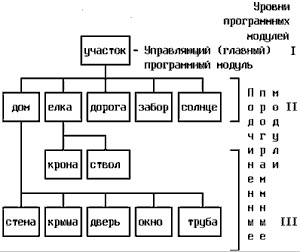
Рис. 3. Структурной диаграммы (второй вариант)
На рис. 2 и рис. 3 отмечены уровни, занимаемые программными модулями. Каждый нижележащий уровень соответствует более полной детализации программного комплекса. Те модули, которые не имеют дальнейшей детализации, например, "солнце", "ствол", "стена", являются процедурами, или функциями, реализующими решение соответствующей подзадачи. Разбиение программы на модули представляет одну из достаточно ответственных и сложных задач, так как влияет на дальнейший ход разработки программного комплекса, его надёжность, эффективность, продолжительность тестирования и отладки, сопровождение и возможность использование стандартных программных процедур.
Достоинства структурного программирования:
1) повышается надежность программ (благодаря хорошему структурированию при проектировании, программа легко поддается тестированию и не создает проблем при отладке);
2) повышается эффективность программ (структурирование программы позволяет легко находить и корректировать ошибки, а отдельные подпрограммы можно переделывать (модифицировать) независимо от других);
3) уменьшается время и стоимость программной разработки;
4) улучшается читабельность программ.
Резюме
Технология структурного программирования при разработке серьезных программных комплексов, основана на следующих принципах:
- программирование должно осуществляться сверху вниз;
- весь проект должен быть разбит на модули (подпрограммы) с одним входом и одним выходом;
- подпрограмма должна допускать только три основные структуры – последовательное выполнение, ветвление (if, case) и повторение (for, while, repeat).
- недопустим оператор передачи управления в любую точку программы (goto);
- документация должна создаваться одновременно с программированием в виде комментариев к программе.
Структурное программирование эффективно используется для решения различных математических задач, имеющих алгоритмический характер.
2. Модульное программирование
Модульное программирование - это организация программы как совокупности небольших независимых блоков (модулей), структура и поведение которых подчиняется определенным заранее правилам.
Модулем (в модульном программировании) называется множество взаимосвязанных подпрограмм (процедур) вместе с данными, которые эти подпрограммы обрабатывают.
Модульное программирование предназначено для разработки больших программ.
Разработкой больших программ занимается коллектив программистов. Каждому программисту поручается разработка некоторой самостоятельной части программы. И он в таком случае отвечает за конструирование всех необходимых процедур и данных для этих процедур. Сокрытие данных (запрет доступа к данным из-за пределов модуля) предотвращает их случайное изменение и соответственно нарушение работы программы. Для взаимодействия отдельных частей (модулей) программы коллективу программистов необходимо продумать только интерфейс (взаимодействие) сконструированных модулей в основной программе.
Напомним понятие и структуру модуля в терминах языка Pascal.
Модуль (unit) – программная единица, текст которой компилируется независимо (автономно).
Модуль содержит 4 раздела: заголовок, интерфейсная часть (раздел объявлений), раздел реализации и раздел инициализации.
UNIT <имя модуля>; {заголовок}
INTERFACE {интерфейсная часть}
Uses <используемые модули>;
Const <объявления глобальных констант>;
Type <объявления глобальных типов>;
Var <описание глобальных переменных>;
Procedure <заголовки(!) доступных процедур>;
. . .
Function <заголовки(!) доступных функций>;
. . .
IMPLEMENTATION {раздел реализации}
Uses <используемые при реализации модули>;
Const <объявления скрытых (локальных) констант>;
Type <объявления скрытых (локальных) типов>;
Var <описание скрытых (локальных) переменных>;
Procedure <тела(!) скрытых (локальных) процедур>;
. . .
Function <тела(!) скрытых (локальных) функций>;
BEGIN
<основной блок модуля = раздел инициализации>
END.
Замечание. Различие всех описаний, содержащихся в разделах интерфейса и реализации, заключается в сфере их использования. В интерфейсном разделе – внешние описания, в разделе реализации – внутренние.
3. Объектно-ориентированное программирование (ООП)
Чтобы написать еще более сложную программу, необходим новый подход к программированию - технология объектно-ориентированного программирования.
OOП включает лучшие идеи, воплощённые как в структурном программировании, так и в модульном. «Является еще более структурным программированием, еще более модульным» (Джеф Дантеманн?).
И, кроме того, ООП сочетает старые принципы с мощными новыми концепциями, которые позволяют оптимально организовывать программы.
Объектно-ориентированное программирование позволяет разложить проблему на составные части. Каждая составляющая становится самостоятельным объектом, содержащим свои собственные коды и данные, которые относятся к этому объекту. В этом случае программирование в целом упрощается, и программист получает возможность оперировать гораздо большими по объёму программами.
Таким образом, ООП – «это методология, основанная на представлении программы в виде совокупности объектов, каждый из которых является реализацией собственного класса» ().
Основным понятием ООП является понятие класса.
Класс – множество объектов, связанных общностью структуры и поведения (класс содержит описание структуры и поведение всех объектов, связанных отношением общности). Любой объект является экземпляром класса.
Методом называется процедура или функция, определенная внутри класса.
Базовые принципы ООП
ООП характеризуется тремя базовыми принципами:
1. Инкапсуляция
2. Наследование
3. Полиморфизм
Инкапсуляция
Инкапсуляция представляет собой комбинирование данных (записи, структуры) с процедурами и функциями для получения нового типа данных.
Здесь проводится аналогия с физическими объектами. Конкретные физические свойства определяются данными различных типов. Кроме того, любой физический объект характеризуется и своим поведением во внешнем мире. Поведение объекта задается процедурами и функциями.
Итак, инкапсуляция означает, что методы (коды) и данные одновременно представлены в одной и той же структуре.
Например,
Type
Coordinates = class
x, y : byte;
procedure Init (Xinit, Yinit: byte);
function GetX : byte;
function GetY : byte;
end;
Наследование
Наследование служит для использования однажды определенного класса в построении целой иерархии производных классов, каждый из которых наследует доступ к данным и методам работы с ними всех своих «родителей».
То есть, можно построить иерархию классов, которая выражает родословное дерево классов. Классы организованы в единую древовидную структуру с общим корнем. Свойства и методы определенного класса автоматически доступны любому классу, расположенному ниже в иерархическом дереве.
Таким образом, наследование – это особенность ООП, посредством которой класс может быть определен как расширение уже существующего класса.
Например,
Type
Cursor = class (coordinates)
Hidden : Boolean;
end;
Здесь класс «курсор» наследует все свойства и методы предварительно описанного класса «координаты», т. е. для него определены координаты x, y, а также методы «инициализация», «определить координату х», «определить координату y» (см. выше описание класса «координаты»). Кроме того, класс «курсор» обладает собственным методом - «быть невидимым».
Наследование позволяет различным типам данных совместно использовать один и тот же код, приводя к уменьшению его размера и повышению функциональности.
Полиморфизм
Полиморфизм – это придание действию (методу) одного имени, которое совместно используется объектами всей иерархии класса, причем каждый объект реализует это действие своим собственным, подходящим для него образом.
Другими словами, полиморфизм – это использование одинаковых имен методов на разных уровнях иерархии классов.
Достоинства ООП
С помощью уменьшения взаимозависимости между компонентами программного обеспечения ООП позволяет разрабатывать системы, пригодные для многократного использования. Такие компоненты могут быть созданы и отлажены как независимые программные единицы.
Несколько слов об использовании технологии ООП в среде Delphi на языке Object Pascal.
Для разработки приложений в Delphi используются специальным образом оформленные классы – компоненты.
Компонент обладает набором свойств и методов. Свойства компонента изменяются либо на этапе сборки приложения (под воздействием системы), либо программно, в процессе работы приложения (под воздействием пользователя).
Особым видом свойства компонента является событие. Процедура обработки события – это реакция приложения на изменение свойства компонента под воздействием системы или пользователя (нажатие клавиши, перемещение курсора и т. п.)
В Object Pascal объекты существуют только в динамической памяти (т. е. переменная, являющаяся объектом, по сути является указателем на объект, и содержит адрес объекта).
Лекция 3
Язык программирования Delphi. Пакеты прикладных программ.
1. Интегрированная среда разработки ( I DE )( Integrated Development Environment.)
2. Характеристика проекта Delphi
3. Компиляция и выполнения проекта
4. Разработка приложения
5. Средства интегрирования среды разработки
1.0. Интегрированная среда разработки ( I DE )( Integrated Development Environment.)
1.1 Основные характеристики.
Возможна работа с группой проектов.
Delphi – это греческий город, где жил дельфийский оракул. Этим именем был назван новый ПП с феноменальными характеристиками. Он удачно сочетает в себе несколько передовых технологий.
В процессе работы разработчик выбирает готовые компоненты и проектирует в среде. После выполнения компиляции получают код, который исполняется в 10-20 раз быстрее, чем то же самое, сделанное при помощи интерпретатора.
Delphi включает полный набор визуальных инструментов для скоростной разработки приложений (из готовых компонентов, число которых непрерывно растет даже за счет других фирм).
Delphi включает в себя локальный сервер для того, чтобы можно было разработать приложения на любые внешние серверы.
Сам Delphi разработан на Delphi.
Пользователи - это учителя, врачи, преподаватели ВУЗов, бизнесмены. Не привлекая для решения своих задач программистов со стороны.
Любой программист на Паскале способен сразу профессионально освоить Delphi. Журнал Visual Basic Magazine присудил свою премию Delphi for Windows.
IDE позволяет создавать, компилировать, тестировать и редактировать проект в единой среде программирования. (IDE входит в комплект Delphi.)
Система Delphi – это комбинация нескольких технологий:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
