

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ГОУВПО «Самарский государственный архитектурно-строительный университет»
Факультет информационных систем и технологий
Кафедра прикладной математики и вычислительной техники
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
К КУРСОВОМУ ПРОЕКТУ (РАБОТЕ)
по дисциплине
ТЕХНОЛОГИЯ/МЕТОДОЛОГИЯ
НАУЧНЫХ ИССЛЕДОВАНИЙ
на тему
« Оптимизация компактного табличного вывод информации»
1 СЕМЕСТР 1 КУРС
Научный руководитель:
Проверили: | Выполнил: студент ГИП -107 |
Общая оценка _______________
Методический руководитель
оценка дата
2007 г.
Оглавление.
Цели и задачи исследования. 3
Введение. 4
1 Описание алгоритма. 6
1.1 Формат исходных данных. 6
1.2 Бинарные деревья. 6
1.3 Построение бинарных деревьев. 7
1.4 Создание итоговых таблиц.. 11
Заключение. 14
Список использованных источников. 15
Цели и задачи исследования.
Цель: повышение эффективности информационного поиска знаний за счет подключения интуиции пользователя, базирующейся на адекватном информационном запросе, геометрическом представлении элементов базы знаний.
Такая задача носит системный характер, поскольку связана со структуризацией и визуализацией обширной, разноплановой информации. Необходима разработка методов и алгоритмов моделей оптимизации для расчета близостей отдельных терминов, понятий и таблиц, моделей расчета координат понятий в геометрическом пространстве, модели иерархической кластеризации объектов и модели создания максимально информативных таблиц как результата поисковых запросов пользователей.
Задачи:
1) Рекомбинация знания. Объединение конкретных данных в семантические сети терминов, понятий, источников;
2) Введение метрики в пространство терминов, понятий и источников. Разработка методов тексто-графических представлений информации.
3) Создание информационные системы" href="/text/category/avtomatizirovannie_informatcionnie_sistemi/" rel="bookmark">автоматизированной информационной системы с интуитивными механизмами информационного поиска в созданной базе знаний.
Введение.
Характерной чертой современности является стремительный научно-технический прогресс, что требует значительного повышения ответственности за качество принятия решений. Это основная причина, которая обусловливает необходимость научного принятия управленческих решений. Для того чтобы правильно принять какое-либо управленческое решения, необходимо обработать огромное количество информации. Так как современный мир пронизан массой информационных потоков и связей, возникающих во многих объектах общенаучных исследований, промышленности, связи, практической жизни, работникам практически всех специальностей приходится извлекать заданную в разнообразных формах информацию из всевозможных информационных потоков, перерабатывать эту информацию. Нарастание потока информации, приводящее к ее удвоению каждые несколько лет, делает в ряде случаев невозможным решение различных задач без широкого использования вычислительной техники, непосредственного внедрения современных компьютеров практически во все сферы науки, техники, экономики. Развитие программного и аппаратного обеспечения сделало создание интегрированных рабочих мест вполне реальным. Но для того, чтобы интегрированное рабочее место позволяло людям лучше выполнять свою работу, оно должно быть простым: пользователи должны иметь возможность быстро извлекать и использовать любую информацию.
Проблема получения информации в наиболее доступной форме неразрывно связано с проблемой преобразования ее из одного вида в другой, принятия на основе полученной информации необходимых решений и проведения их в жизнь, постоянно учитывая при этом вновь поступающие сведения. Без такой деятельности невозможно эффективное и целенаправленное осуществление задач, стоящих перед нашим обществом в целом и его работниками в частности.
Любую информацию можно представить в табличной, текстовой, графической или другой форме. Табличная форма представления информации обеспечивает простой и емкий способ получения пользователем всей необходимой информации. Главное преимущество табличной структуры представления информации знаний является то, что она позволяет осуществлять преобразовании информации, то есть разбивать таблицы на отдельные информационные единицы, включающие конкретную информацию с привязкой к названиям строки и столбца, на пересечении которых она находилась в исходной таблице, создания максимально информативных таблиц как результата поисковых запросов пользователей. С помощью этого представления на ограниченном пространстве размещается вся информация, необходимая для восприятия в компактном виде. Первичный ввод информации наиболее удобен в простой текстовой форме. Но он не удобен для восприятия и анализа. Поэтому встает задача оптимизации введенной информации для восприятия любым пользователем. Оптимизация - целенаправленная деятельность, заключающаяся в получении наилучших результатов при соответствующих условиях.
Для обеспечения возможности оптимизации представления информации, вводимой в простой текстовой форме, а также для получения средств для дальнейшего анализа информации, мною был разработан способ представления и оптимизации вывода информации в табличной форме.
Этот метод позволяет объединить данные с разных источников, таких как базы данных, таблицы, а так же внешних источников данных, например сеть Интернет.
1 Описание алгоритма.
Выходная, оптимизированная таблица будет представлена в следующем виде: в строках таблицы сгруппированы понятия из соответствующих строк начальных данных, при этом, если существуют общие понятия для нескольких значений, то производится разбиение таблицы на подстрочные элементы. Для оптимального формирования подстрочных элементов, в данной работе используется метод с промежуточным построением бинарных деревьев. Этот метод позволяет создать наиболее визуально-информативное представление данных
1.1 Формат исходных данных.
Исходные данные представляют собой таблицу, содержащую числовые значения и характеризующие их понятий, при этом каждое числовое значение имеет собственный неповторяющийся набор понятий.
Пример исходных данных:
Field5, Field2, Field1, Field3, 1
Field4, Field1, Field2, Field5, 5
Field2, Field5, Field3, 4
Field5, Field1, Field4, 7
Field3, Field4, 3
1.2 Бинарные деревья.
Бинарное дерево - это конечное множество элементов, которое либо пусто, либо содержит один элемент, называемый корнем дерева, а остальные элементы множества делятся на два непересекающихся подмножества, каждое из которых само является бинарным деревом.
Эти подмножества называются левым и правым поддеревьями исходного дерева. Каждый элемент бинарного дерева называется узлом дерева. Узел, не имеющий сыновей, называется листом.
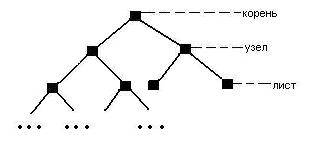
1.3 Построение бинарных деревьев.
Представим исходную таблицу в следующем виде:
Field1 | Field2 | Field3 | Field4 | Field5 | |
1 | 1 | 1 | 0 | 1 | 1 |
0 | 0 | 0 | 0 | 0 | 2 |
0 | 0 | 1 | 1 | 0 | 3 |
0 | 1 | 1 | 0 | 1 | 4 |
1 | 1 | 0 | 1 | 1 | 5 |
1 | 0 | 0 | 1 | 1 | 7 |
Для этого запишем все имеющиеся понятия и значения, и составим логическую таблицу принадлежности понятий.
Конечная таблица должна иметь вид, при котором, каждый корень бинарного дерева представляет собой набор только истинных или только ложных значений, при этом каждый левый узел должен быть истинный, а каждый правый – ложный. Также, для оптимального представления данных, каждый последующий корень должен иметь меньший размер.
Пример бинарного дерева принадлежности понятий:
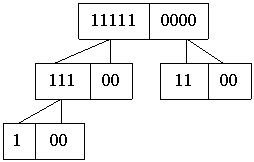 |
Формирование данного дерева возможно, если количество понятий, входящих в строку, уменьшается от первой строки к последней.
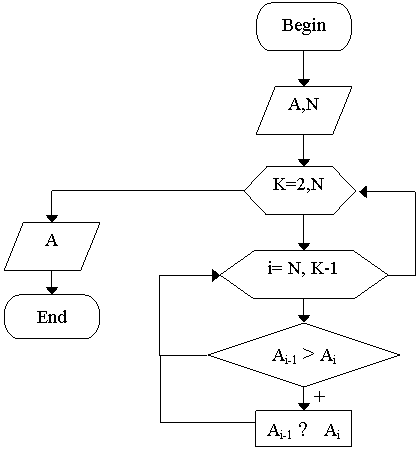
Для этого введем временный столбец значений, содержащий количество понятий в строке. Сортировка возможна следующим образом: берется пара рядом стоящих элементов из введенного столбца, если элемент с меньшим индексом оказывается меньше элемента с большим индексом, то они меняются местами. Эти действия продолжаются до тех пор, пока есть такие пары. Так как каждый раз на свое место становится, по крайней мере, один элемент, то потребуется не более N проходов, где N — количество элементов; A – временный столбец значений.

Пример отсортированной таблицы
Field1 | Field2 | Field3 | Field4 | Field5 | |
1 | 1 | 1 | 0 | 1 | 1 |
1 | 1 | 0 | 1 | 1 | 5 |
0 | 1 | 1 | 0 | 1 | 4 |
1 | 0 | 0 | 1 | 1 | 7 |
0 | 0 | 1 | 1 | 0 | 3 |
0 | 0 | 0 | 0 | 0 | 2 |
Для приведения полученной таблицы к виду бинарного дерева, каждая строка должна быть разбита на узлы. Поменяем столбцы местами таким образом, чтобы все истинный значения первой строки были у левый границы таблицы. Таким образом, получаются два первых узла дерева отходящих от одного мнимого корня.
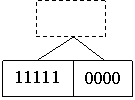

Если, не нарушая порядка истинных и ложных значений первой строки, аналогичным образом привести второю строку, то получаются ещё четыре узла бинарного дерева:
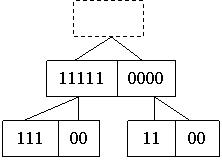

Вторая строка таблицы может быть отсортирована данным образом, если отдельно переместить двоичные значения внутри столбцов образующих два первых узла.
Общий алгоритм приведения таблицы к виду бинарного дерева:
arr – таблица бинарных значений.
a – количество строк в таблице
t – количество узлов в данной строке
t=2q (где q – номер текущей строки), но не больше количество столбцов.
point – массив порядковых номеров узлов.
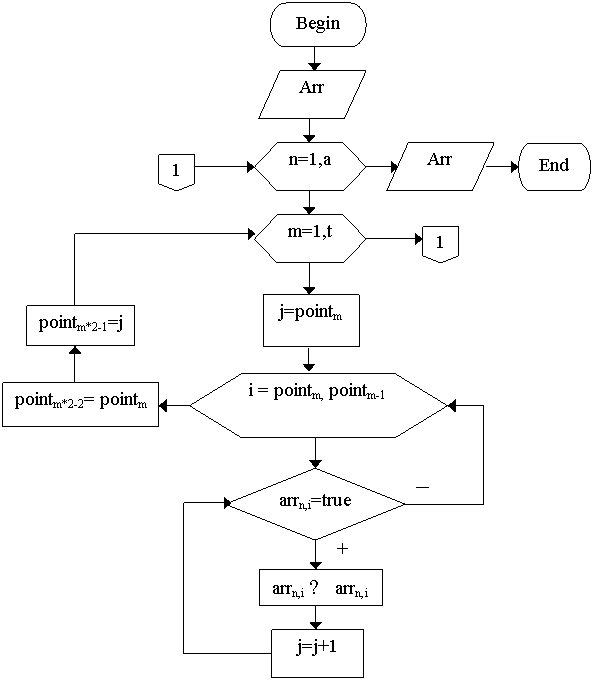

Пример конечной бинарной таблицы:
Field5 | Field2 | Field1 | Field3 | Field4 | |
-1 | -1 | -1 | -1 | 0 | 1 |
-1 | -1 | -1 | 0 | -1 | 5 |
-1 | -1 | 0 | -1 | 0 | 4 |
-1 | 0 | -1 | 0 | -1 | 7 |
0 | 0 | 0 | -1 | -1 | 3 |
1.4 Создание итоговых таблиц
Таблица, приведенная к виду бинарного дерева, представляет собой массив, заполненность которого убывает от первой строки и первого столбца. Таким образом, понятия, включенные в них, имеют наибольшую информационную нагрузку. Выходная таблица, построенная по этим понятием в данной последовательности, будет иметь наибольшую плотность.
Для формирования этой таблице запишем понятия, принадлежащие строкам в строки выходной, но последние понятия внесем в столбец, при этом исключив повторения понятий в наименования столбцов.
Тогда, конечная таблица примет вид:
Field3 | Field4 | |||
Field5 | Field2 | Field1 | 1 | |
5 | ||||
Field2 | 4 | |||
Field1 | 7 | |||
Field3 | 3 |
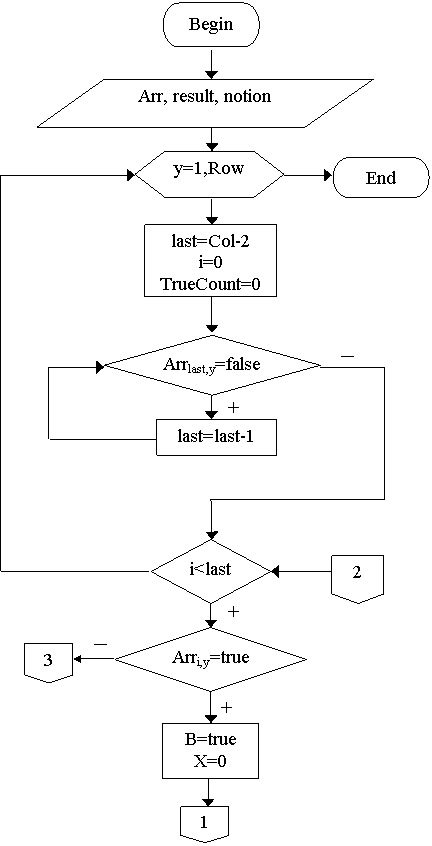
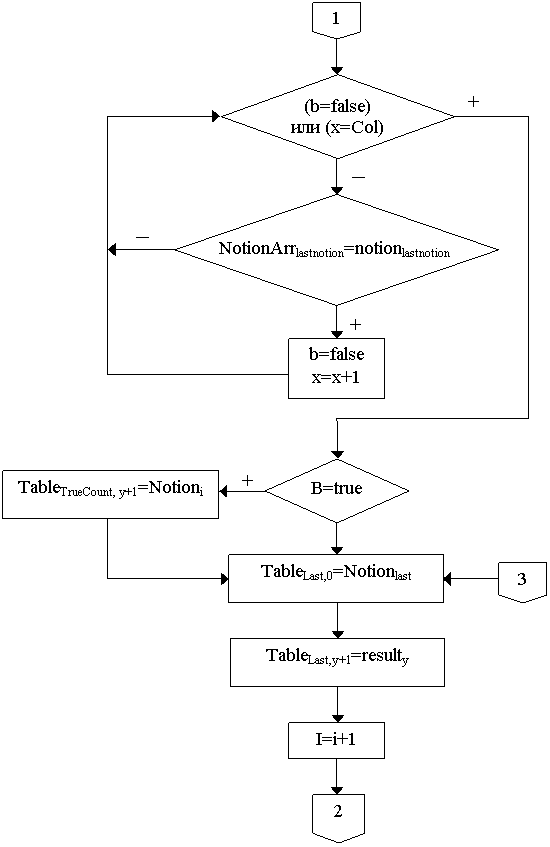
Общий алгоритм формирования выходной таблицы:
Col - количество колонок в бинарной таблице
Row - количество рядов в бинарной таблице
Table – выходная таблица
Arr – бинарная таблица


Заключение.
Ранее обычные предприятия, компании использовали компьютеры в основном для хранения информации. Но ввод информации и особенно извлечение нужной информации порождало проблемы. Приходилось заранее, иногда за несколько месяцев, ставить перед программистами задачу подготовки средств поиска информации, которая будет нужна, и программисты должны были писать программу поиска и извлечения нужной информации.
Сейчас, когда общий объем информации хранимой в электронном виде возрос, люди предпочитают обращаться к компаниям, которые могут обеспечить более быстрое распространение информации. Многие стараются реорганизовать информационные потоки так, чтобы исключить необходимость в программистах — посредниках между пользователями и компьютерами.
Поэтому оптимизация компактного вывода информации имеет огромное значение для простых пользователей. Вводя исходные данные в любой доступной для него форме, он должен автоматически получать необходимые готовые результаты обработки информации в наиболее удобном и понятном виде.
Метод, представленный в этой работе, обеспечивает один из наиболее полных видов представлений табличной информации. Конечные таблицы, являются кластеризированными, это означает, что, из них могут быть выделены знания с необходимым количеством и значимостью. Также, при наличии заданного словаря понятий, может происходить автоматический, регулярный, сбор и систематизация какой-либо информации. В практической значимости, возможным примером этому будет являться получение и объединений данных с различных метеостанций или выявление литературы заданной тематики.
Список использованных источников.
1. Деревья. Основные понятия и определения. Бинарные деревья. http://cylib. iit. nau. /Books/ComputerScience/FundamentalAlgorithm/
2. Бинарные деревья.
http://khpi-iip. mipk. kharkiv. edu/library/datastr/book_sod
3. “Структуры и таблицы” А. Леммов.
М. Просвещение; 1998г.
