

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Новосибирский государственный технический университет
Кафедра вычислительной техники
 |
Курсовая работа
по дисциплине «Программирование»
Факультет: АВТФ
Группа: АМ-511
Выполнил:
Проверил:
Новосибирск, 2006г.
Содержание:
1. Задание.
2. Теоретический материал.
3. Структурное описание разработки.
4. Функциональное описание.
5. Описание работы программы, достоинства и недостатки.
6. Литература.
7. Приложение: текст программы с комментариями.
Задание
Для заданной двухуровневой структуры данных, содержащей указатели на строки, разработать полный набор операций (добавление, включение и извлечение по логическому номеру, сортировка, включение с сохранением порядка, загрузка и сохранение строк в текстовом файле, балансировка – выравнивание размерностей структур данных нижнего уровня).
Список, каждый элемент которого содержит динамический массив указателей на строки, упорядоченные по длине. Размерность массива в каждом следующем элементе в 2 раза больше, чем в предыдущем. Строка включается в структуру данных с сохранением упорядоченности. Если строка включается в заполненный массив, то последний указатель перемещается в следующий элемент и так далее).
Структурное описание разработки
Данная программа является средством для представления данных в памяти в виде определенной структуры, а так же средством для работы с этой структурой. Структура данных представляет собой список, каждый элемент которого содержит динамический массив указателей на строки, упорядоченные по длине: в списке первого уровня находится указатель на ДМУ, и информация необходимая для эффективной работы со структурой, а именно: количество элементов в подсписке и максимально допустимая размерность ДМУ. В ДМУ находится собственно сам хранимый объект, в данном случае – строки. Что касается упомянутой мною поддержки сбалансированности, то она достигается переносом половины указателей из ДМУ в следующие ДМУ.
Структура данных создается динамически, т. е. всё, создается в ходе выполнения программы. При включении, исключении элементов в структуре выделяется и освобождается память, если памяти не хватает, то действие отменяется.
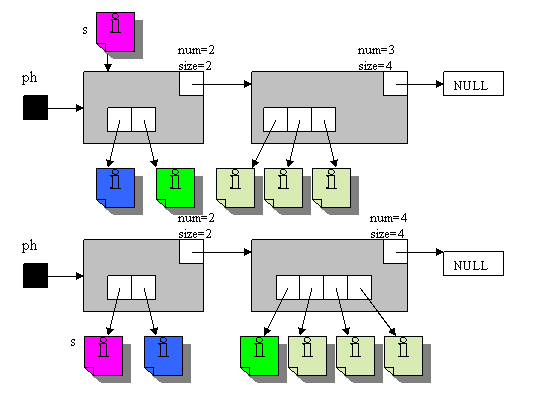
Указатель на первый элемент списка (вершину списка) объявляется глобально, так же как и размерность ДМУ в первом элементе списка. Программа может работать с любой размерностью ДМУ первого элемента списка Структура начинает заполняться при добавлении элементов или при загрузке из файла. При добавлении в структуру в начало должна быть известна максимальная размерность ДМУ, т. к. при переполнении ДМУ последний указатель перемещается в следующий элемент и так далее. Если структура пуста, то просто создается первый элемент. А если структура не пуста, то в первом ДМУ новый элемент включается в начало и сдвигает далее до конца все указатели структуры.
Если ДМУ переполнен, то последний указатель перемещается в следующий элемент и так далее.
Принцип действий при переполнении:
(максимально допустимая размерностью ДМУ первого элемента списка 2)

Сбалансированность структуры данных поддерживается периодической балансировкой (периодическим вызовом специальной функции меню). Перенесение половины элементов в другой ДМУ связано с тем, что необходимо еще обеспечивать локальность изменений, т. е. если просто при переполнении включать в другой ДМУ, например следующий, то включение в текущий ДМУ постоянно будет вызывать переполнение. А если же мы переносим половину элементов, то изменения в этих двух ДМУ локализованы в них до следующего переполнения каждого. Однако, не всегда возможно, и целесообразно следить за сбалансированностью при всех изменениях вносимых в структуру данных. Возможно, что было бы лучше, если бы этого слежения вообще не было, а сбалансированность восстанавливалась при каком-то пороговом, критическом изменении или параметре, характеризующем состояние структуры. Однако не всегда возможно отследить этот критический момент: иногда проверка после выполнения какого-то действия, операции уже запаздывает, т. е. данные не теряются, а вот свойства иерархической структуры данных теряются. Эти свойства можно восстановить, но это уже будет какой – то не естественный процесс для работы со структурой, она имеет смысл только при хотя бы некоторой сбалансированности.
Сортировка структуры данных носит название «быстрой». Принцип сортировки основан на переписывании всей структуры данных в обычный ДМУ, а с ДМУ как и с обычным массивом можно работать известными нам методами. В так называемой быстрой сортировке разделение производится с использованием оригинального алгоритма. Специфика алгоритма “быстрой сортировки” состоит в выполнении разделения на основе обмена. Сравнение элементов производится с концов массива (i=a, j=b) к середине (i++ или j--), причем "укорочение" происходит только с одной из сторон. После каждой перестановки меняется тот конец, с которого выполняется "укорочение". В результате этого массив разделяется на две части относительно значения первого элемента in[a] , который и становится медианой. После того как массив отсортирован следует переписать из ДМУ все значения обратно в структуру, т. е. берутся по порядку все элементы из ДМУ и, с помощью функции вставки в начало, вставляются в структуру. Так вот если в функции вставки не следить за сбалансированностью, то структура данных не будет отвечать основным требованиям. Поэтому после сортировки необходимо сбалансировать структуру.
Вставка с сохранением упорядоченности заключается в следующем:
· Обходим структуру данных
· Ищем место, где длина строки не превосходит очередную.
· Включаем строку.
· Если места не нашлось, то включаем последней.
Сортировка основана на использовании функции включения в начало, т. к. мы уже имеем отсортированный массив. Элементы последовательно включаются в структуру данных, и в результате мы получаем отсортированную структуру. Недостатком моей сортировки является тот факт, что во время выполнения этой процедуры в памяти находятся одна структура. То есть вернуть старую структуру данных после сортировки невозможно.
В программе предусмотрена функция просмотра текущего состояния структуры данных через такую информацию, как число хранимых объектов, количество элементов в структуре второго уровня, и количество байтов, занимаемых структурой. По этим данным можно судить о сбалансированности всей структуры, и если необходимо выполнять процедуру балансировки структур данных второго уровня. Дело в том, что контролировать сбалансированность при всех вносимых изменениях затруднительно, а под час нецелесообразно по причине затрат на время выполнения, а потому в данной программе сбалансированность обеспечивается самостоятельной функцией. Функции изменения (вставка по логическому номеру, удаление и т. д.) не контролируют сбалансированность, т. к. результат их выполнения однократного не может привести к потере структурой данных своих свойств, а поэтому их можно контролировать с помощью функции отображения всей структуры данных.
Процедура выравнивания размерностей структур второго уровня заключается в том, чтобы представить текущую структуру в наиболее оптимальном виде. Самый оптимальный вариант это если количество хранимых объектов в структурах второго уровня равно половине максимальной размерности текущего элемента. Однако такой оптимальной структурой данная перестает быть уже при первых вносимых изменениях, т. е. при первой вставке в каждый подсписок происходит переполнение, структура начинает «расти вниз».
На схеме максимально допустимая размерность первого ДМУ равна 2
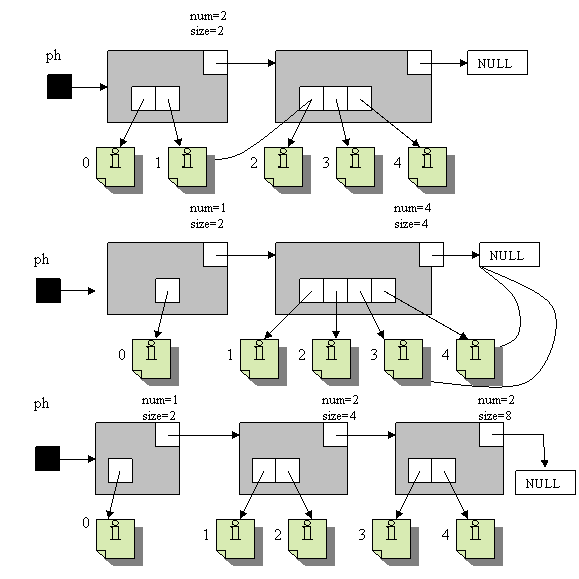

Таким образом, оптимальность должна достигаться примерно: в данной программе в результате выравнивания структур данных второго уровня, в ДМУ располагается по половине от максимально допустимой размерности структуры второго уровня. То есть получается, что сразу после балансировки структура не оптимальна, как должна быть в идеальном случае, но по мере вносимых изменений она может приближаться к оптимальной, к тому же выполняется свойство локальности вносимых изменений, т. к. ДМУ заполнены наполовину.
Алгоритм выравнивания размерностей структур данных второго уровня:
· Пока текущий элемент заполнен и не последний перекидываем половину указателей из ДМУ текущего элемента в следующий
· Если ДМУ последнего элемента заполнен меньше, чем на половину - вернуться
· Иначе создаём новый элемент
· И перекидываем в него указатели, находящиеся за серединой ДМУ
Загрузка из текстового файла основана на функции добавления в начало структуры данных. Это накладывает некоторые ограничения: после заполнения структуры данных текст будет «висеть вверх ногами». После открытия файла в режиме чтения, выделяется память под строки, и считываются последовательно все строки из файла в память. Для каждой строки выполняется функция добавления, причем в эту функцию передается пересчитанный параметр (максимально допустимая размерность ДМУ). После загрузки изменяется заголовок на структуру.
Извлечение по логическому номеру происходит с помощью функции позиционирования на нужном элементе списка. Она работает на основе движения последовательно по структуре первого уровня и вычета из логического номера количества хранимых строк в пройденных элементах второго уровня. Если логический номер слишком велик, то с помощью функции получения максимального логического номера фиксируется тот факт, что элемента по такому номеру в структуре нет. Суммарное количество указателей в структурах второго уровня должно быть больше логического номера, т. к. нумерация начинается с нулевого элемента. При достижении значения логического номера, меньшего чем количество указателей в текущем элементе, извлекаем из текущего подсписка необходимый элемент. Извлечение из подсписка происходит на основе того, что, мы имеем порядковый номер, указатель на нужный элемент списка, а номер элемента списка можно узнать вычисляя логарифм.
Так же как и в функции вставки в функцию включения по логическому номеру передается логический номер элемента. Только здесь – это номер элемента, перед которым необходимо включить новый. Так же как и в извлечении просматриваем верхний список, подсчитывая количество строк в предыдущих подсписках. Если структура пуста или нет элемента по такому номеру, то просто добавляем новый элемент в конец. Если же такой номер есть, позиционируемся в списке второго уровня и включаем элемент новый элемент в соответствующее место. Позиционирование аналогично, позиционированию в функции извлечения, т. е. путем вычисления количества переходов.
Аналогично предыдущей (описанной выше) функции, происходит удаление элемента структуры, только необходимый элемент удаляется (освобождается память), а соседние «связываются».
Удаление структуры происходит следующим образом:
1. Переходим на последний элемент верхнего списка.
2. Путем двух кратного просмотра подсписка получаем указатель на предпоследний элемент списка.
3. Удаляем последний по порядку в подсписке элемент и записываем ограничитель (NULL). Если этот последний элемент является единственным элементом в подсписке, то удаляем его, и обновляем указатель на подсписок в элементе верхнего списка (записываем NULL).
4. Повторение процесса, начиная со второго пункта, до тех пор, пока подсписок не будет пуст, и в этом случае удаляется текущий (последний) элемент верхнего списка и записывается ограничитель.
5. Процесс повторяется, начиная с первого пункта, до тех пор, пока список верхнего уровня не будет пуст, что соответствует удалению всей структуры.
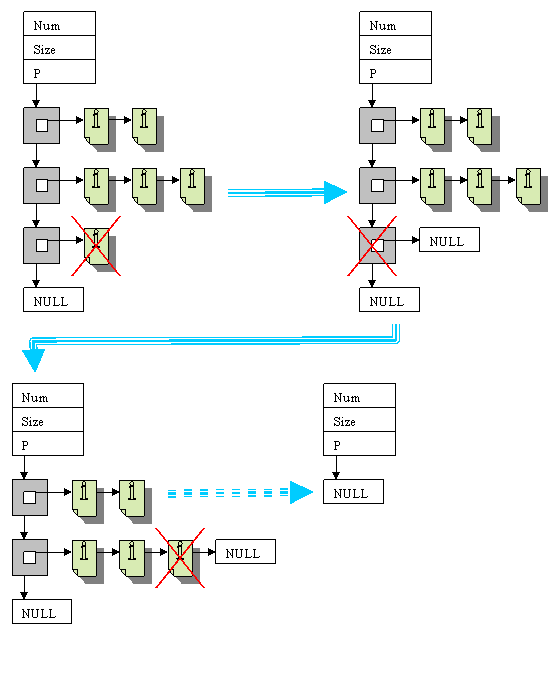

Таким «удалением с конца» в результате получаем удаленную структуру. Указатель на структуру передается по ссылке, таким образом, после удаления в дескрипторе получаем обновленный, пустой указатель на структуру. Остальные параметры в дескрипторе надо обновлять.
Сохранение в файл происходит путем последовательной записи строк из элементов подсписков при последовательном просмотре структуры.
Вывод на экран хранимой информации осуществляется с помощью функции вывода страницы текста: просматривается структура данных, и строки из необходимого диапазона выводятся на экран. Диапазон определяется номером страницы и тем, что на странице выводится 20 строк. При движении курсором с помощью функции извлечения по логическому номеру делаем подсветку текущего положения курсора. При движении контролируется номер на странице, и если он выходит за пределы страницы, то выводим соответствующую страницу, запоминая номер текущей. Смена страниц производится с учетом пределов структуры. Так же для более наглядной работы со структурой существует несколько функций ввода данных, рисующих окна и возвращающих либо данные, либо указатель на них.
Контроль соответствия параметров структуры, записанных в дескрипторе, текущему состоянию структуры осуществляется (за исключением некоторых функций) вне выполняемых функций, в зависимости от возвращаемого результата.
Функциональное описание
Функции обрабатывают структуру данного вида:
struct list
Двухуровневая структура данных(ДМУ в односвязанном списке)
{int num; //Текущее количество элементов в ДМУ
int size; //Размерность ДМУ
char **p; //Указатель на ДМУ на строки(char)
}*ph; //Вершина списка
Функция вывода на экран текста на русском языке: void rus(char* s)
В функцию передается указатель на стороку в памяти. Затем эта строка выводится на русском языке с помощью библиотечной функции CharToOem(char* s, char* q).
Функция вывода на экран часто повторяющихся сообщений: void messeng(int k)
Примитивная функция вывода сообщений пользователю. Функция получает целое значение k соответствующее порядковому номеру в статически заданном массиве указателей на строки в памяти. Через функцию вывода на экран русского текста – выводим k-ое сообщение.
Функция подсчёта количества элементов списка: int getnum(list *ph)
Функция получает указатель на на вершину списка. Возвращает целое значение равное количеству элементов списка. Двигаемся по списку, считаем вершины. По окончании цикла возвращает полученный результат.
Функция создания элемента списка: list *create(list *&ph, char *s)
В функцию передается указатель на структуру (заголовок верхнего списка) по ссылке, чтобы в необходимых случаях можно было настраивать заголовок на новый элемент. И указатель на строку в памяти. Создается новый элемент списка. Настраиваются указатели и увеличивает размерность ДМУ в 2 раза больше чем в предыдущем, присваивает текущему количеству элементов ДМУ=1. Включаем указатель на строку в динамический массив указателей нулевым элементом. После процесса заполнения функция возвращает указатель на новый элемент списка.
Функция добавления в начало списка:void add(list *&ph, char *s)
В функцию передается указатель на структуру по ссылке. Также передается указатель на строку в памяти. Если список оказался пустой, функция создаёт первый элемент в списке. Настраивает указатели, устанавливает размерность ДМУ для первого списка SZ=2, присваивает текущему количеству элементов ДМУ =1, и включает указатель на строку в динамический массив указателей нулевым элементом.
Если же список не был пустым, запоминаем последний элемент ДМУ. Сдвигам все указатели на строки в ДМУ на один в право и на освободившееся место(нулевой элемент) включаем указатель на входящую строку. Переходим на следующий элемент списка и повторяем процедуру с исключенным указателем из ДМУ предыдущего элемента списка до тех пор пока текущее количество элементов в ДМУ не будет равно размерности ДМУ данного элемента списка или когда элемент списка не будет является последним. Если же количество элементов в ДМУ будет равно размерности, то создаем новый элемент списка с помощью функции create описанной выше. После того как указатель на строку включён – выход из функции.
Функция загрузки из файла: void load(list *&ph)
Функция получает указатель на вершину списка по ссылке. Функция просит ввести имя файла. После чего открывает его в режиме чтения. Последовательно читаем строки из файла, пропуская пустые и с помощью функции add, описанной выше добавляем в начало списка.
Функция подсчета максимального логического номера: int maxnum(list *ph)
Функция получает указатель на вершину списка. Обходим список подсчитываем количество указателей на строки. Возвращаем полученный результат.
Функция сохранения в файл: void save(list *p)
Функция получает указатель на вершину списка. Если список пуст сообщаем об этом и выходим из функции. Иначе вводим имя файла и открываем его в режиме записи. Обходим список и последовательно записываем строки в файл ставя после каждой символ конца строки. По окончании записи в файл – выход и функции.
Функция удаления всего списка: void delall(list *&ph)
Функция получает указатель на вершину списка по ссылке. Если список пуст сообщаем об этом и выходим из функции. Иначе последовательно обходим весь список. Обнуляем указатели на строки в ДМУ и обнуляем текущий элемент списка. Если список отчищен – выход из функции.
Функция поиска вершины, содержащий строку с заданным ЛН:
list *set_ij(list *p, int &m)
Функция получает указатель на вершину списка, ссылку на ЛН искомой строки. Двигаемся по списку до конца, вычитая из ЛН количество указателей на строки в текущем элементе списка. Если искомая строка находится в текущем элементе то возвращаем на него. Если искомая строка не найдена возвращаем NULL.
Функция удаления по логическому номеру: void deln(list *&ph, int m)
Функция получает указатель на вершину списка по ссылке и логический номер искомой строки. Сначала позиционируемся на элемент списка содержащею искомую строку. Затем сдвигаем с заданной позиции ДМУ этого элемента списка на 1 влево. Помещаем первый указатель на строку уз ДМУ следующего элемента списка, последним в ДМУ текущего элемента списка. Далее аналогичным способом сдвигаем все указатели на строки влево на одну, пока не достигнем конца списка. Когда удаление по ЛН будет завершено – выход из функции.
Функция вывода на экран содержимого всего списка: void show(list *p)
Функция получает указатель на вершину списка. Если список пуст сообщаем об этом и выходим из функции. Совершаем обход списка выводя последовательно строки из ДМУ каждого элемента кроме того параллельно выводим : ЛН строки, номер элемента списка и индекс указателя на строку в ДМУ текущего элемента. Функция выводит по 20 строк и спрашивает о дальнейшем продолжении вывода. Если ДА то продолжаем, если нет выходим из функции.
Функция вывода на экран содержимого списка по ЛН: void shown(list *p, int m)
Функция получает указатель на вершину списка и ЛН искомой строки. С помощью выше описанной функции set_ij позиционируемся на элемент списка с заданным ЛН. Из размерности найденного ДМУ элемента списка вычисляем его номер и выводим.
Функция отображения общей информации о структуре: void showinf(list *p)
Функция получает указатель на вершину списка. Если список пуст сообщаем об этом и выходим из функции. Обходим список и считаем наибольший ЛН, размер занятой памяти(т. к размер одного символа занимает 1 байт то сумма всех строк и будет размером занятой памяти), среднею длину строки получаем разделив количество заданной памяти на длину строк. Выводим эти данные.
Функция включения по ЛН: void ins(list *&ph, int m, char *s)
Функция получает указатель на вершину списка по ссылке, логический номер искомой строки и указатель на строку. список пуст сообщаем об этом и выходим из функции. Функция включения по ЛН аналогична функции удаления по ЛН с некоторой разницей. В место сдвига в лева совершаем сдвиг в право и на освободившееся место включаем указатель на строку. По завершении вставки – выход из функции.
Функция переписывания списка в ДМУ для сортировки: char **getarray(list *p)
Функция получает указатель на вершину списка. Если список пуст сообщаем об этом и выходим из функции. Создаем ДМУ на строки. Обходим структуру данных и переписывает последовательно все указатели на строки в новый ДМУ. Возвращаем указатель на новый ДМУ.
Функция восстановления списка из отсортированного ДМУ:
void getlist(list *&ph, char **s)
Функция получает указатель на вершину списка по ссылке и указатель на ДМУ. Если список пуст сообщаем об этом и выходим из функции. Обходим структуру данных и переписываем все указатели из ДМУ на строки в структуру. По восстановления – выход из функции.
Функция включения с сохранением порядка: void inssort(list *&ph, char *s)
Функция получает указатель на вершину списка по ссылке и указатель на строку в памяти. Если список пуст сообщаем об этом и выходим из функции. Обходим двухуровневую структуру данных считаем ЛН и если длина входящей строки не больше очередной то включить её с помощью вышеописанной функции ins по ЛН. Иначе помощью этой же функции включить последней. Если указатель на строку включён – выход из функции.
Функция сортировки рекурсивной сортировки: void sort(char **&A, int a, int b)
Функция получает на указатель на ДМУ и левую и правую границы. Передвигаемся по ДМУ от левой и правой границ к середине. Сравниваем длину концевых пар, если левая меньше правой меняем местами. Продолжаем до тех пор пока левая граница меньше правой. Далее вызываем функцию рекурсивно с изменением левых и правых границ. По окончании сортировки – выход из функции.
Функция балансировки: void balans(list *&ph)
Функция получает указатель на вершину списка по ссылке. Если список пуст сообщаем об этом и выходим из функции. Перебрасываем половину указателей из ДМУ текущего элемента в ДМУ следующего продолжаем эту операцию пока текущий элемент списка заполнен или не является последним. Если ДМУ последнего элемента списка заполнен меньше чем на половину завершаем балансировку. Если ДМУ последнего элемента списка заполнен больше чем на половину то с помощью функции create создаем навый элемент списка и перебрасываем указатели находящееся за серединой ДМУ текущего элемента списка в следующий. Выводим время выполнения. Балансировка завершена – выход из функции.
Описание работы программы, достоинства и недостатки.
Возьмем текстовый файл в 5688 строк(размер 96424 байт) и проанализируем работу программы с данными из этого файла. После загрузки в каждом последующем элементе количество элементов ДМУ в 2 раза больше чем в предыдущем что соответствует условию курсовой работы. Время выполнения загрузки текстового файла: 0.043333сек. После балансировки структура становится приблизительно оптимальной: в ДМУ количество элементов меньше чем середина размерности ДМУ и время выполнения равно 0,025556.
Отсортируем только что сбалансированную структуру данных и получим время сортировки: 0,043333 сек. При повторной сортировке, т. е. уже отсортированной структуры время сортировки увеличивается: 0,268889 сек. Отсортировав структуру после загрузки, но, не сбалансировав, получим время выполнения: 0,043889 сек. Время выполнения увеличилось, т. к. структура находится не в оптимальном состоянии.
Возникали проблемы при сортировке и балансировке большого объема информации. Например при загруженном файле 400kb(30 770строк) и вызове функции сортировки программа вылетала из за нехватки памяти под данные. Дело в том, что системная часть любой структуры занимает память, а при введении иерархии в структуру эта системная часть увеличивается, иногда существенно. Таким образом, происходит увеличение занимаемой памяти при неизменном объеме хранимой информации. Это и отображается при больших объемах перерабатываемой информации в выше упомянутых функциях.
Существует и масса достоинств данной структуры, одно из которых превосходство по обработке данных по сравнению с другими одноуровневыми структурами.
Литература.
· Курс лекций по программированию. Преподаватель
· Практикум по программированию на C++.
Приложение: текст программы с комментариями
//______________________ Подключение библиотек ______________________________________________
#include <string. h>
#include <iostream. h>
#include <stdlib. h>
#include <windows. h>
#include <time. h>
#include <stdio. h>
#include <conio. h>
#include <math. h>
//////////////ПРОГРАММНЫЙ КОД//////////////////////////////////////
#define SZ 2 //Размерность ДМУ в первом элементе списка
#define EXIT '\33' //ESC
struct list //Двухуровневая структура данных(ДМУ в односвязанном списке)
{int num; //Текущее количество элементов в ДМУ
int size; //Размерность ДМУ
char **p; //Указатель на ДМУ на строки(char)
list *next;} //Указатель на следующий элемент списка
*ph=NULL; //Вершина списка
//………………………………………………И так далее……………………………………………………………………………………………
