Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Настройка робота Avalanche 2.0 на обработку RSS-потоков
Avalanche 2.0 может работать как RSS-робот и автоматически собирать новости прямо с RSS-потоков.
Рассмотрим настройку RSS-потоков на примере сайта www. ***** .
Видим, что на его главной странице помещаются заголовки всего трех главных новостей,
Однако сайт содержит RSS-поток, и в нем сейчас около 100 новостей.
Порождаем в окне робота Avalanche новый источник с названием RSS-поток с Billing.ru и стартовым адресом http://www. *****/news/rss/
Сохраняем его и открываем снова для задания тонкой настройки (в момент порождения нового источника тонкая настройка недоступна – она активируется после появления источника в списке стартовых страниц).
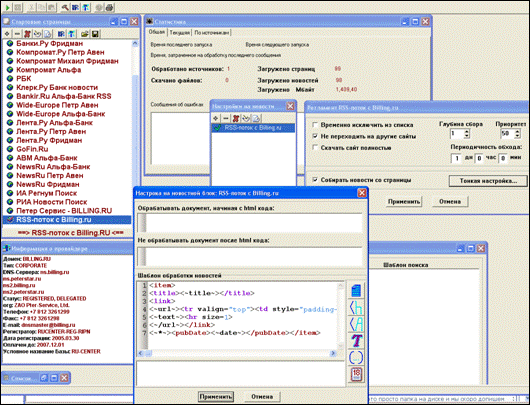
В окне Шаблона обработки новостей блока тонкой настройки задаем :
<item>
<title><~title~></title>
<link>
<~url~><tr valign="top"><td style="padding-right:20px">
<~text~><hr size=1>
<~/url~></link>
<~*~><pubDate><~date~></pubDate></item>
Что означают строки этого шаблона?
В приведенном выше шаблоне содержатся куски кода, по которым робот находит заданные места на исходной странице (ниже выделены зеленым) , команды роботу (выделены синим), и куски кода на дочерней странице, куда робот уйдет по ссылке в процессе обработки новости.
Вот тот же шаблон с раскраской:
<item>
<title> <~title~></title>
<link>
<~url~> <tr valign="top"><td style="padding-right:20px">
<~text~><hr size=1>
<~/url~> </link>
<~*~> <pubDate><~date~></pubDate></item>
А вот как его будет выполнять робот Avalanche:
Робот зайдет на исходную страницу http://www. *****/news/rss/
и будет двигаться по ней, ища первое вхождение первого куска текста, с которого ему велено начать обработку (это вот такая строчка: <item> , причем для робота это не более чем набор символов ). Как только робот встретит ее в тексте, он знает, что сразу вслед за ней на странице должна встретиться строчка <title> , сразу после которой роботу велено выполнить свою команду <~title~> - т. е. взять заголовок новости, который закончится, когда на странице встретится следующий набор символов - </title>
Далее робот проверит, что сразу вслед за этим расположены символы <link>,
и как только их найдет, выполнит свою команду <~url~> - т. е. выделит на странице ссылку на текст новости и далее уйдет по этой ссылке. Следующий кусок текста, который роботу нужно найти - <tr valign="top"><td style="padding-right:20px">, и он будет искать этот текст уже на странице новости, куда только что перешел с главной. Найдя этот кусок текста, робот должен выполнить свою команду <~text~>, т. е. выделить основной текст новости, который закончится, когда на странице встретится набор символов <hr size=1>.
Встретив эти символы, робот должен выполнить команду <~/url~> - вернуться с данной страницы назад на исходную. Далее ему надо найти набор символов </link>, и дальше двигаться по странице ( команда <~*~> означает, что надо двигаться по странице и все пропускать, пока не встретится набор символов, заданный в шаблоне следующим), пока не встретится наборт символов <pubDate><~date~></pubDate></item>.
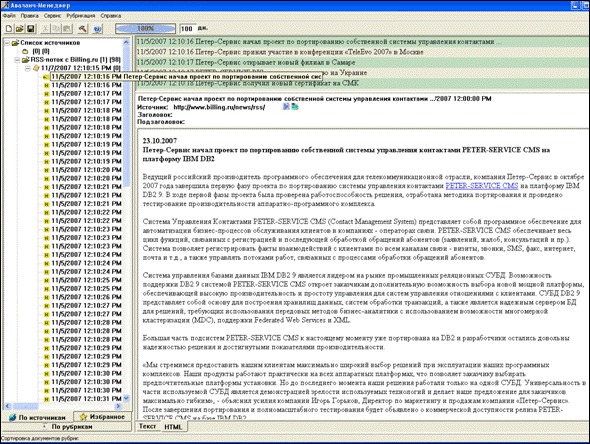
Для робота это означает, что данная новость кончилась, и надо приступать к поиску следующей, работая по тому же шаблону. Если на странице собрано несколько новостей, сверстанных однотипно, робот найдет их все (например, на указанной странице робот находит 98 новостей).
Если же на странице есть несколько групп новостей, сверстанных по-разному, то можно задать для этой страницы сразу несколько шаблонов – и робот выполнит их все, и соберет все группы новостей.
После того, как шаблон задан, делаем новый источник активным (на его иконке должна появиться галочка) и запускаем робота. Ход настройки и статистика работы робота приведены ниже:
Видно, что робот обработал и принес в базу 98 новостей. Вот как выглядит после этого окно менеджера Avalanche: