

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
А. В. ПРОТОДЬЯКОНОВ, С. Е. ШВЕЦ, А. Н. ФОМИН
Кузбасский государственный технический университет, Кемерово
*****@***ru
Оценка эффективности
Светофорного регулирования на перекрестке
при использовании адаптивной
нейро-нечеткой системы управления*
Рассмотрена задача создания адаптивной нейро-нечеткой системы светофорного регулирования, включая ее структуру и алгоритм обучения. Приведено сравнение условий движения, полученных с помощью имитационного моделирования, при использовании фиксированных и адаптивно управляемых светофорных циклах.
Введение
В городах автомобили большую часть времени находятся в условиях светофорного регулирования. Поэтому эффективное управление светофорами является необходимым условием для решения проблемы транспортных заторов. Многие городские магистрали эксплуатируются на пределе пропускной способности, и даже незначительное увеличение интенсивности потоков может привести к значительному затруднению движения.
Наиболее распространенный способ светофорного регулирования – использование фиксированных по длительности фаз, рассчитанных на основе статистических данных. Однако данный подход испытывает значительные трудности из-за нестабильности транспортных потоков, которые меняются не только в течение дня, но и в более короткие промежутки времени. К тому же транспортные потоки очень быстро адаптируются к изменениям дорожно-транспортной сети, и приходится регулярно проводить перерасчет.
Поэтому последние 30 лет активно развиваются различные системы, которые позволяют адаптивно учитывать изменения в транспортных потоках [1, 2].
Данная работа является развитием исследований [3, 4].
Постановка задачи
Цель данной работы – разработка нейро-нечеткой системы управления светофорными циклами. Задача системы управления – максимально повысить пропускную способность перекрестка, управляя переключением фаз на основании информации, собранной с различных детекторов (индукционных петель, видеокамер и т. п.).
Основная сложность создания систем светофорного регулирования заключается в том, что в настоящее время нет единой математической теории управления транспортными потоками [5]. Поэтому целесообразно систему управления представить в виде «черного ящика». Естественным и удобным базисом для создания систем управления в подобных условиях являются искусственные нейронные сети. Искусственные нейронные сети, обладая свойством обобщения и способностью к нелинейному разделению классов, позволяют выполнить гибкое отображение входных параметров на действия системы.
Тем не менее, нейронные сети обладают несколькими недостатками: невозможностью включения в сеть априорной информации и «проклятием размерности» (то есть уменьшением вероятности удачного обучения сети при увеличении сложности сети и задачи в целом). Частично решить эти проблемы позволяет объединение аппарата нейронных сетей с теорией нечетких множеств.
При данном подходе нейронная сеть состоит из специальных нейронов, которые представляют конкретные сущности систем с нечеткой логикой. Это позволяет представить систему в виде набора нечетких правил и при этом обучать ее как нейронную сеть. Такие системы получили название «нейро-нечетких».
Структура нейро-нечеткой системы
Нейро-нечеткую систему, так же как и любую другую нейронную сеть, необходимо предварительно обучить. При этом возникает проблема сложности построения обучающей выборки, необходимой для применения алгоритмов обучения с учителем. Обучающая выборка в данном случае должна содержать отдельные дорожно-транспортные ситуации, в соответствии с которыми нужно изменять текущие фазы светофорного регулирования. Для решения этой проблемы используется техника подкрепляющего обучения, позволяющая обучать систему в процессе ее взаимодействия со средой. Существует несколько техник такого обучения: Q-learning, SARSA, обучение актер-критик и т. д.
В работе используется структура системы и метод обучения, предложенные Джоуффи [4]. Концептуальная схема такой структуры представлена на рис. 1.

Рис. 1. Структурная схема нейро-нечеткой системы с «критиком»
Первый слой является входным и получает значения переменных состояния среды. Второй состоит из ассоциированных с конкретными переменными нечетких множеств, каждый нейрон в этом слое имеет определенную функцию принадлежности, которая применяется к входящему в нейрон сигналу. Слой правил образуют нейроны, которые имитируют правила (нечеткие множества, составляющие правила, определяются структурой связей с предыдущим слоем), выход нейронов в этом слое определяет активационную силу соответствующего правила. Последний слой представляет заключения, которые делает система, отдельно выделяется нейрон «Критик», использующийся для обучения сети. Выходы нейронов «Действия» определяет уровень предпочтения определенного управляющего воздействия системы (выбор конкретной фазы светофора).
Алгоритм функционирования системы
Общей целью системы является максимизация получаемой награды, которую можно получить в будущем в течение длительного периода времени. [6] Система на основе текущего состояния S(t) среды, выбирает определенное действие и применяет его, что приводит к новому состоянию S(t+1). Разница между ними оценивается функцией награды r(t+1), которая характеризует степень пользы или вреда, которое принесло примененное действие. Однако само по себе это значение ничего не означает для системы (так как в разных условиях это может означать разный результат), поэтому в системе вводится дополнительная внутренняя оценка ситуации, которая также подстраивается в процессе обучения.
Таким образом, функционирование системы условно можно разделить на расчет предпочтения действий и обучение (корректировка весов) на основе функции награды.
Расчет предпочтения действий:
1. Вычисление активационной силы (firing strange – FS) j-го правила определяется выражением:
![]() , (1)
, (1)
где a(i) – одно из нечетких множеств для i-й входной переменной; ![]() – значение функции принадлежности a(i) нечеткого множества и это значение используется в j-м правиле.
– значение функции принадлежности a(i) нечеткого множества и это значение используется в j-м правиле.
2. Вычисление предпочтений к выбору действий:
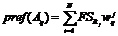 , (2)
, (2)
где 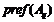 – предпочтение выбора действия
– предпочтение выбора действия ![]() ;
; ![]() – вес связи между действием
– вес связи между действием ![]() и j-м правилом.
и j-м правилом.
Выбор действия в режиме управления производится согласно жадному алгоритму, т. е. выбирается действие, имеющее наибольшее значение предпочтения. В процессе обучения выбор действия происходит согласно ε-жадному алгоритму (что позволяет выходить из локальных минимумов).
3. Значения критика вычисляется аналогичным образом:
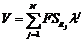 , (3)
, (3)
где V – значение критика; ![]() – вес связи между критиком и j-м правилом.
– вес связи между критиком и j-м правилом.
Процедура обучения
После того как рассчитаны предпочтения к выбору действий и оценка критика для времени t:
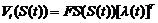 , (4)
, (4)
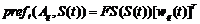 , (5)
, (5)
на основе ε-жадного алгоритма выбирается действие Aj, которое применяется к системе, что приводит к новому состоянию на следующем временном шаге S(t+1), которое критик оценивает с теми же весами связей:
![]() . (6)
. (6)
Переход из состояния S(t) в S(t+1) приводит к получению награды r(t+1). На основе оценки критиком этих двух состояний и выигрыша от перехода вычисляется ошибка временной разности:
![]() , (7)
, (7)
где γ – коэффициент забывания (дисконтный фактор), означающий уверенность в оценке награды, 0< γ <1.
Ошибка временной разности применяется для обновления весов как критика, так и действий, используя формулы (8) и (9) соответственно:
![]() , (8)
, (8)
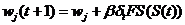 , (9)
, (9)
где β – скорость обучения, заранее определенная константа (0; 1).
При этом на каждом шаге обновляются только веса выбранного j-го действия, которое было применено к среде. Если изменения веса критика и действий изменяются меньше, чем предопределенное минимальное значение, или система имеет тенденцию к стабилизации, обучение прекращается.
Входные и выходные параметры, функция награды
В большинстве исследований в качестве входных переменных используются длины очередей на каждом из направлений, а также текущая фаза светофора. С каждой переменной длины очереди ассоциированы по два нечетких множества «short» и «long», примеры их функции принадлежности выражаются уравнениями (10) и (11) соответственно, и графики изображены на рис. 2 [3]:
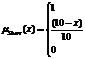
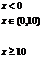 (10)
(10)
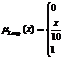
![]() (11)
(11)
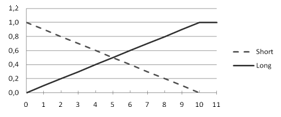
Рис. 2. Функции принадлежностей нечетких множеств «Short» и «Long»
(схематичо)
Текущая фаза представляет собой переменную, принимающую целые значения, с которой ассоциировано N нечетких множеств (N – число фаз светофора). Если значение переменной совпадает с номером нечеткого множества, то функция принадлежности ему равна 1, иначе 0.
Так как цель системы – максимизировать функцию награды, то ее выбор оказывает значительное влияние на эффективность функционирования всей системы. Например, если в качестве целевой функции принять количество автомобилей, проехавших через перекресток за один цикл, то это может привести к ситуациям, когда одни направления получают приоритет, а на других возникают очереди транспортных средств.
В качестве целевой функции используется выражение [3]:
![]() , (12)
, (12)
где x1 – количество автомобилей, которые проехали; x2 – количество автомобилей в очередях; x3 – количество автомобилей, которые добавились к очереди; x4 – количество автомобилей на дороге, имеющей зеленый сигнал; x5 – количество автомобилей, которые остановились в момент переключения с зеленого на красный свет; βi – неотрицательный коэффициент для каждой переменной.
Параметр x1 поощряет движение через перекресток в течение времени между двумя точками решения, x2 – отображает задержку остановившихся, x3 используется для оценки ухудшения ситуации, x4 показывает количество автомобилей на текущей зеленой фазе (т. е. те, кто может воспользоваться ее продлением), x5 соответствует штрафу переключения с одной фазы на другую.
Оценка эффективности системы
Для оценки эффективности предложенного подхода к светофорному регулированию проводились эксперименты с имитационной моделью транспортных потоков. В качестве объекта для моделирования был взят один из наиболее проблемных перекрестков города Кемерово: пересечение пр. Советского и пр. Кузнецкого (рис. 3).
В имитационной модели использовались интенсивности транспортных потоков, измеренные на данном перекрестке 29 июня 2009 года в вечерний час-пик с 16:00 до 19:00.
Эксперимент состоял из трех этапов. На каждом этапе проводилось имитационное моделирование перекрестка с использованием различных схем светофорного регулирования. В качестве критерия эффективности использовалось количество автомобилей в очереди.
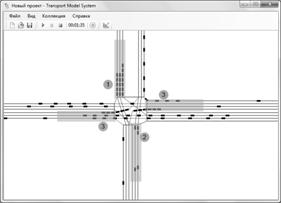
Рис. 3. Структурная схема перекрестка
(цифрами показаны соответствующие фазы перекрестка)
На первом этапе было проведено имитационное моделирование перекрестка с фиксированными светофорными циклами, используемыми в реальности.
На втором этапе с помощью генетического алгоритма были найдены оптимальные фиксированные фазы и проведено моделирование уже с этими фазами.
И на третьем этапе с помощью генетического алгоритма были найдены оптимальные коэффициенты функции награды (12) и проведено моделирование со светофорами, управляемыми адаптивной нейро-нечеткой системой.
Результаты эксперимента представлены на рис. 4. На рисунке точками обозначены длины очередей в различные моменты времени, а линиями – скользящее среднее. Обозначение «Исходный» соответствует реальному светофорному циклу, «ГА» – оптимальному светофорному циклу, найденному с помощью генетического алгоритма, и «НС» – адаптивной нейро-нечеткой системе.
Как видно из рисунка, худшие результаты показала система с реальными фиксированными светофорными циклами (средняя длина очереди – 30.5). За ней следует система с оптимальными фиксированными циклами, найденными с помощью генетического алгоритма (средняя длина очереди – 24.0). И лучший результат показала адаптивная нейро-нечеткая система (средняя длина очереди – 16.3).
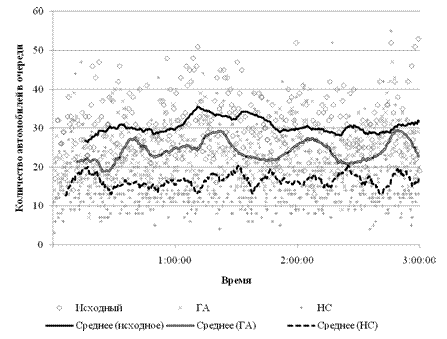
Рис. 4. Количество машин в очереди в зависимости
от используемой схемы управления светофором
Выводы
В результате выполнения исследований разработана адаптивная нейро-нечеткая система светофорного регулирования. С помощью генетического алгоритма была найдена оптимальная функция награды для ее обучения.
Проведенный эксперимент показал возможность применения подобной системы на высоконагруженном многофазном перекрестке. Предложенная система позволяет более эффективно управлять перекрестком по сравнению с оптимальным фиксированным светофорным циклом.
Список литературы
1. Dunn Engineering Associates. Traffic Control Systems Handbook. Westhampton Beach : б. н., 2005. С. 367.
2. U. S. Department of Transportation. Intelligent Transportation Systems for Traffic Signal Control: Deployment Benefits and Lessons Learned. 2007. http://www. itsdocs. fhwa. dot. gov//JPODOCS/BROCHURE//14321.htm.
3. Zhang, Yunlong, Xie, Yuanchang и Ye, Zhirui. Development and Evaluation of a Multi-Agent Based Neuro-Fuzzy. Texas Transportation Institute. 2007. Technical Report. SWUTC/07/2-1.
4. Actor-Critic Learning Based on Fuzzy Inference System. Jouffe, L. Beijing : Proceedings of IEEE International Conference on Systems, Man, and Cybernetics, 1996. Р. 339-344.
5. Traffic Signal Timing Manual. 2008. http://ops. fhwa. dot. gov/publications/fhwahop08024/fhwa_hop_08_024.pdf.
6. Редько происхождения интеллекта и модели адаптационного поведения // Научная сессия МИФИ. Материалы конференции «Нейроинформатика-2006». М.: МИФИ, 2006. С. 112-166.
Когнитивные исследования
* Работа выполнена в рамках программы «Развитие научного потенциала высшей школы », проект № 000.
