

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторная работа 6
Определение уравнения линейной регрессии
Задача описания данных, полученных в результате некоего эксперимента, может быть решена как задача оптимизации.
Предположим, что некоторая переменная Y зависит от некоторой независимой переменной X, а связь между ними задается уравнением Y = F(X, a, b), где a, b ‑ параметры, которые нужно определить.
Для этого необходимо провести серию экспериментов, в каждом из которых задается значение независимой переменной Х и регистрируется значение зависимой переменной Y. Результатом серии из N экспериментов является множество пар чисел (Yi, Xi), i=1,...,N. Затем на основе полученной информации подбираются значения a, b таким образом, чтобы обеспечить хорошую точность описания экспериментальных данных с помощью функции F.
Наиболее часто используемая на практике мера качества описания экспериментальных данных определяется так называемым критерием наименьших квадратов, в соответствии с которым требуется минимизировать функцию
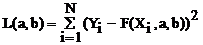 . (6.1)
. (6.1)
Разность Yi –F(Xi, a, b) между зарегистрированным и теоретическим значением показывает, насколько точно выбранная модель описывает имеющиеся данные. Если значение L(a, b) равно нулю, то сделанный выбор a и b обеспечивает точное описание, поскольку экспериментальные данные совпадают с теоретической кривой.
Таким образом, задачу описания данных можно рассматривать как задачу оптимизации, в которой требуется найти значение параметров a и b, минимизирующих функцию L(a, b).
В данной работе необходимо определить параметры линейной эмпирической модели при помощи инструмента Линия тренда, а также при помощи регрессионного анализа.
Последовательность выполнения работы:
1. Ввести исходные данные.
2. Построить график экспериментальной зависимости.
3. Провести линейную линию тренда и вывести на экран уравнение регрессии и коэффициент корреляции R2.
4. Провести регрессионный анализ и определить параметры линейной модели и коэффициент корреляции R2.
5. Определить достоверность величины R2 при помощи статистической функции FРАСП.
6. Сравнить уравнения регрессии и коэффициенты корреляции, полученные двумя способами и сделать выводы.
Исходные данные
Таблица 6.1
Вар | Независимая переменная Х | |||||||||
1 | 2,10 | 2,56 | 3,13 | 3,81 | 4,65 | 5,68 | 6,92 | 8,45 | 10,31 | 12,57 |
2 | 1,30 | 1,96 | 2,96 | 4,48 | 6,76 | 10,21 | 15,41 | 23,27 | 35,14 | 53,06 |
3 | 0,50 | 0,60 | 0,72 | 0,86 | 1,04 | 1,24 | 1,49 | 1,79 | 2,15 | 2,58 |
4 | 22,80 | 21,54 | 20,82 | 19,79 | 18,50 | 18,16 | 17,53 | 16,57 | 15,84 | 14,82 |
5 | 0,00 | -3,16 | -3,23 | -7,25 | -9,56 | -9,92 | -10,62 | -13,48 | -17,20 | -18,26 |
Таблица 6.2
Вар | Зависимая переменная Х | ||||||||||
1 | 2,97 | 2,29 | 4,51 | 5,19 | 9,47 | 9,60 | 13,89 | 16,42 | 23,96 | 26,75 |
|
2 | 13,50 | 18,07 | 14,68 | 20,17 | 18,50 | 26,38 | 27,52 | 39,45 | 47,06 | 68,95 |
|
3 | 13,50 | 13,76 | 14,07 | 14,45 | 14,90 | 15,43 | 16,08 | 16,86 | 17,79 | 18,91 |
|
4 | 73,19 | 70,12 | 65,27 | 63,43 | 58,89 | 57,91 | 54,12 | 53,90 | 48,38 | 46,89 |
|
5 | 7,74 | -24,63 | -23,29 | -63,28 | -83,35 | -88,34 | -93,33 | -122,01 | -155,56 | -168,26 |
|
Выполнение работы в среде Excel
Выполнение работы начинаем, как обычно, с формирования блока исходных данных. Исходные данные представляют собой значения независимой переменной X и зависимой переменной Y. Значения X и Y удобнее располагать в виде столбцов.
Под столбцом значений Х необходимо определить предельные значения независимой переменной, характеризующие область определения аппроксимирующей функции. Для их определения служат статистические функции МИН и МАКС Мастера функций.
Построим диаграмму функции Y=F(X). Выделим ряд данных, для которого построим линию тренда. Щелкнем по выделенному ряду данных правой клавишей мыши и выберем в появившемся контекстно-зависимом меню команду Линия тренда. На экране появляется диалоговое окно Линия тренда, содержащее две вкладки: Тип и Параметры. На вкладке Тип выбираем тип линии тренда, в данном случае ‑ Линейная. На вкладке Параметры отмечаем флажками две нижние альтернативы: Показывать уравнение на диаграмме; Поместить на диаграмму величину достоверности аппроксимации R2. После нажатия клавиши ОК на диаграмме появляется аппроксимирующая прямая, уравнение регрессии и R2.
Далее определим параметры модели другим способом. Для этого служит функция Excel ЛИНЕЙН( ). Эта функция имеет следующий формат: ЛИНЕЙН(блок значений Y; блок значений X; константа; статистика). Ввод аргументов константа и статистика осуществляется в виде одной из логических функций ИСТИНА или ЛОЖЬ. В зависимости от вида константы и статистики результаты вычислений будут выведены в различных вариантах, представленных в табл.7.3.
Таблица 6.3
Аргумент | ИСТИНА | ЛОЖЬ |
Константа | b¹0 | b=0 |
Статистика | Оценка достоверности | Оценки нет |
Функция ЛИНЕЙН вводится в виде формулы массива. Выделяем блок ячеек, в котором строк ‑ всегда 5, столбцов ‑ n+1, где n ‑ число независимых переменных Х, в данном случае n=1, столбцов в блоке ‑ 2. Вводим в выделенный блок функцию ЛИНЕЙН(блок значений Y; блок значений X; ИСТИНА;ИСТИНА). Для реализации этой функции как формулы массива следует одновременно нажать клавиши Shift + Ctrl + Enter.
В блоке ячеек, выделенном для ввода формулы массива, представлены результаты вычислений. Смысл числовых значений, полученных в этом блоке, разъясняется в табл.6.4.
Таблица 6.4
a | b |
s [a] | s [b] |
R2 | |
Fрасч | df |
В табл.6.4 приняты следующие обозначения:
a, b ‑ параметры уравнения линейной регрессии;
s [a], s [b] ‑ средние квадратические отклонения величин a, b;
R2 ‑ величина, характеризующая достоверность уравнения регрессии;
Fрасч ‑ величина, необходимая для оценки достоверности R2;
df ‑ число степеней свободы.
В табл.6.4 рассмотрены значения только тех величин, которые необходимы нам в дальнейшей работе. Другие величины, содержащиеся в данном блоке, не представляют практического интереса, поэтому нами не рассматриваются.
Таким образом, используя данные, полученные нами в расчетном блоке, можно записать уравнение регрессии в виде Y = a × X + b и сравнить его, а также величину R2 с теми, что получены при использовании линии тренда.
Оценка достоверности уравнения регрессии производится по величине R2, которая может изменяться в пределах 0 £ R2 £ 1. При R2=1 имеется функциональная зависимость, при R2=0 зависимость отсутствует, несмотря на найденные a и b.
Можно оценить достоверность самой величины R2. Это производится с помощью F распределения, которое определяет a ‑ вероятность того, что зависимость Y от X отсутствует. Следовательно, вероятность того, что такая зависимость существует, будет определяться величиной (1-a).
Для определения величины a выделим произвольную ячейку, вызовем Мастер функций и выберем в разделе Статистические функцию FРАСП. На экране появляется диалоговое окно FРАСП, в которое необходимо ввести следующие значения:
Þ X = Fрасч;
Þ степени свободы 1 = n (число независимых переменных Х);
Þ степени свободы 2 = df.
Нажимаем клавишу Готово, и в ячейке подсчитано значение a. В соседней ячейке подсчитаем величину (1-a), которая и характеризует достоверность значения R2.
Контрольные вопросы
1. Чем характеризуется точность описания экспериментальных данных полученным уравнением регрессии?
2. Каким образом можно представить задачу описания экспериментальных данных в виде задачи оптимизации?
Библиографический список
1. Курицкий оптимальных решений средствами Excel 7.0. – BHV‑Санкт-Петербург, 1997, – С.336–342.
Пример оформления работы 6 представлен в приложении.
