


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Некоторые разделы теории информации и их приложения к задачам прогнозирования и распознавания
В статье рассматриваются некоторые разделы теории информации в плане их использования в задачах прогнозирования и распознавания
Введение
Данная статья написана по тезисам доклада сделанного на семинаре в Институте системного анализа РАН.
Логарифмическая мера информации была предложена Р. Хартли в 1928 г. Для конечного множества Х информация любого его элемента хÎХ определяется как
![]()
С точностью до округления эта величина равна числу двоичных символов, необходимых для кодировки элемента в множестве. Это же самое можно интерпретировать, как число вопросов типа да/нет, необходимых для распознавания или идентификации элемента множества. Приведем еще одну близкую, но более формализованную интерпретацию этой величины. Для алфавита X, состоящего из m=|X| символов множество всевозможных слов длиной n обозначим через M. Выберем k так, что
2k-1 < |M|=mn £ 2k
Следовательно, слова из M можно кодировать k-битами равномерного кода и нельзя закодировать k-1 битами. Логарифмируя, получим
k-1 < n log2 m £ k или 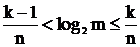 .
.
Таким образом, на кодирование буквы слова достаточно затратить не больше, чем k/n бит и не удастся обойтись (k-1)/n битами. Из последних неравенств следует, что величина 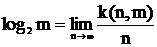 , т. е. информация символа алфавита |M| равна пределу отношения минимально возможного числа бит на одну букву равномерного кода, необходимого для кодировки слов длиной n при n®¥.
, т. е. информация символа алфавита |M| равна пределу отношения минимально возможного числа бит на одну букву равномерного кода, необходимого для кодировки слов длиной n при n®¥.
Пример. Трехзначное число содержит log 1000 = 9.965 бит информации, одна цифра несет log 10 = 3.321 бит. Здесь и везде в дальнейшем двойка в основании логарифма опускается.
Энтропия и информация
Широкий интерес к понятию информации возник после появления статьи К. Шеннона 1948 года, в которой была сформулирована проблематика этой теории, связанная с кодированием сообщений.
Рассмотрим некоторую физическую систему x, которая случайным образом может оказаться в одном из q состояний, каждое из состояний xj может наблюдаться с вероятностью pj, (p1+…+pq=1). Степень неопределенности такой системы описывается энтропией системы
![]()
(Мера априорной неопределенности системы )
Сведения, полученные о системе тем более информативны, чем больше была неопределенность системы до получения этих сведений. Отметим, что нас интересует только количество состояний системы и вероятности отдельных состояний. Энтропия системы тесно связана с вопросами оптимального кодирования.
Теорема (Шеннон). Существует способ сжатия всех файлов с частотными характеристиками (p1,…,pq), который обеспечивает сжатие сколь угодно близкое к H(p1,…,pq) бит на символ и не существует способа сжатия всех файлов с такими характеристиками, которое обеспечивает сжатие лучше.
Отметим, что равномерное кодирование ( на каждый элемент множества отводится одинаковое число бит ) не является вообще говоря оптимальным.
Среди не равномерных кодов интерес представляют префиксные коды. Код называется префиксным, если никакая битовая кодировка отдельного элемента не совпадает с началом битовой кодировки другого элемента множества. Битовые коды в этом случае можно записывать без пробелов и однозначно восстанавливать кодируемое сообщение в последующем. Существуют простые способы кодирование, близкие к оптимальному. Например, можно наболее вероятному слову приписывается слово из префиксного кода, имеющее меньшую длину.
Пример кодирования: Рассмотрим источник информации, слова которого имеют 8 позиций из алфавита в 4 буквы a, b,c, d с распределением вероятностей p(a) = 0.5, p(b) = 0.25, p(c) = p(d) = 0.125, ( aaaabbcd ).
Префиксный код, построенный по этому принципу, выглядит так: a – 0, b – 10, c – 110, d – 111.
Энтропия источника будет равна –(1/2 log ½ - ¼ log ¼ - 1/8 log 1/8 – 1/8 log 1/8) =1/2+1/2+3/8+3/8=7/4. На одно слово приходится 14 бит. При таком префиксном кодировании на слово aaaaaaa пойдет 8 бит, на слово cdcdcdcd - 24 бита, на слово aaaabbcd - 14 бит. При равномерном кодировании слова из восьми букв необходимо 2*8=16 бит.
Пусть информационный источник организован на модели слов x из n позиций, словарь X состоит из q букв, причем j-я буква встречается в слове mj раз, так что
m1+m2+…+mq=n
набор
(m1,m2,…,mq)
называется композицией слова. Отдельное слово можно интерпретировать, как систему с q состояниями и с вероятностями состояний 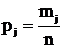 . С точки зрения сформулированных понятий, нас не интересуют позиции букв в слове, а только количество различных букв и их частоты. Информация отдельной буквы будет равна энтропии H, а информация слова, соответственно nH. Наличие в слове двух или более одинаковых букв называют иногда симметрией. Чем меньше в слове симметрий, тем больше априорная неопределенность и тем больше информация при получении слова. Среди информационных источников с заданным числом состояний энтропия достигаем максимального значения на источниках с равновероятным распределением состояний и эта величина равна логарифму от числа состояний. Минимум энтропии достигается на полностью детерминированных источниках, имеющих единственное состояние, наступающее с вероятностью единица.
. С точки зрения сформулированных понятий, нас не интересуют позиции букв в слове, а только количество различных букв и их частоты. Информация отдельной буквы будет равна энтропии H, а информация слова, соответственно nH. Наличие в слове двух или более одинаковых букв называют иногда симметрией. Чем меньше в слове симметрий, тем больше априорная неопределенность и тем больше информация при получении слова. Среди информационных источников с заданным числом состояний энтропия достигаем максимального значения на источниках с равновероятным распределением состояний и эта величина равна логарифму от числа состояний. Минимум энтропии достигается на полностью детерминированных источниках, имеющих единственное состояние, наступающее с вероятностью единица.
Алгебраический подход
Кроме вероятностного подхода определения информации существует алгебраический подход. Рассмотрим все перестановки данного слова x. Перестановки не меняют композицию слова. В этом множестве можно определить операцию умножения ( последовательное выполнение двух перестановок ), относительно которой оно становится группой. Эту группу, называемую симметрической, обозначим через G. Полученное в результате всех перестановок множество называется орбитой слова x и обозначается Gx. Информацией слова x называется информация по Хартли этого слова, как элемента своей орбиты.
I0(x) = log |Gx|
Число |Gx| равно числу размещений m1 букв X[1], …, mq букв X[q] на n позициях, т. е. биномиальному коэффициенту 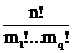 . Это же число равно числу размещений n различных элементов по q ячейкам, вместимостью m1,…,mq. Таким образом,
. Это же число равно числу размещений n различных элементов по q ячейкам, вместимостью m1,…,mq. Таким образом,
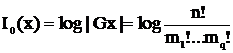
С помощью формулы Стирлинга (![]() ) можно показать, что
) можно показать, что
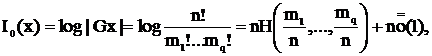
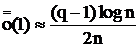
Пример: Слово x=(ааб) имеет композицию (2,1). Если делать всевозможные перестановки, то получим множество слов
«ааб», «аба», «ааб», «аба», «баа», «баа». Орбита состоит из 3-х слов «ааб», «аба», «баа», и поэтому информация, содержащаяся в этом слове равна
![]()
О-информация слова «ааа» равна нулю. О-информация слова «abcd» максимально возможная среди слов длиной в 4 букв и равна log 4 = 2 битам.
Информационный канал
Пусть имеется пара источников информации ( два слова ), которые согласовано выдают последовательности символов ( букв ). Первый из алфавита X=( X[1],X[2],…,X[p]), xÎXn, второй из алфавита Y=(Y[1],Y[2],…,Y[q]), yÎBn (j-я букву алфавита C обозначена через C[j]). Всякое согласование позволяет рассматривать пару источников, как один составной источник, алфавитом которого служит произведение ![]() . Частотная характеристика составного источника называется совместным распределение пары источников. Пусть x=(x1,x2,…,xn), y=(y1,y2,…,yn). Декартовым произведением слов называется слово xÄy=((x1,y1), (x2,y2),…, (xn, yn)). Будем называть y входным источником или входным сигналом, - x выходным.
. Частотная характеристика составного источника называется совместным распределение пары источников. Пусть x=(x1,x2,…,xn), y=(y1,y2,…,yn). Декартовым произведением слов называется слово xÄy=((x1,y1), (x2,y2),…, (xn, yn)). Будем называть y входным источником или входным сигналом, - x выходным.
Примеры:
1) Сигнал на входе – посылка сообщения, сигнал на выходе - прием искаженного сообщения.
2) Сигнал на входе - число голосов, отданных за кандидата на президентских выборах, сигнал на выходе - статья расходов на агитацию в предвыборной компании кандидата.
3) Сигнал на входе - ASCI код образца, сигнал на выходе – признак образца.
Совместное распределение для xÄy удобно записывать в виде матрицы ||mij||, где mij число повторов составной буквы (X[i],Y[j]) в xÄy. Матрица ||mij|| называется матрицей переходов слова x в слово y. Эта матрица имеет вид
Таблица 1.
Y[1] | Y[2] | … | Y[q] | åx | |
X[1] | m11 | m12 | m1q | m1 | |
X[2] | m21 | m22 | m2q | m2 | |
… | |||||
X[p] | mp1 | mp2 | mpq | mp | |
åy | n1 | n2 | nq | n |
Частоты будут равны pij=mij/n. Представим энтропию выходного источника x в виде двух слагаемых
H(x)=( H(xÄy) - H(y) ) + ( H(x) + H(y) – H(xÄy) )
Первое слагаемое называется условной энтропией выходного источника по отношению к входному
H(x/y)= H(xÄy) - H(y).
Это та добавочная ( лишняя ) информация, которая есть на выходе по отношению ко входному сигналу. Эта величина характеризует шум канала связи. Второе слагаемое
H(x:y) = H(x) + H(y) – H(xÄy)
называется взаимной энтропией пары источников. Это та часть информации выходного сигнала, которая уже содержится во входном источнике и называется пропускной способностью информационного канала. В терминах алгебраической теории вводятся аналогичные понятия для 0-информации слова xÎXn, при условии yÎYn
Io(x/y) =Io(xÄy) – Io(y)
( Аналогично определяется Io(y/x) =Io(xÄy) – Io(y) )
Взаимной информацией называется величина
Io(x:y) = Io(x) + Io(y) - Io(xÄy)
Отметим некоторые свойства о-информации
Io(xÄy) £ Io(x) + Io(y)
Io(x/y) £ Io(x), Io(y/x) £ Io(y)
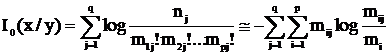
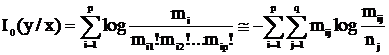
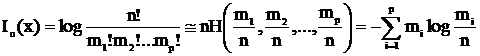
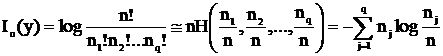
Io(x:y) = Io(x) - Io(x/y) = Io(y) - Io(y/x)
![]() ,
, ![]()
Io(x/y) также называют шумом канала, а взаимную информацию Io(x:y) называют пропускной способностью канала. Если слова связаны функциональной зависимостью y=f(x), то Io(y/x) = 0 и наоборот. В этом случае взаимная информация имеет максимальное значение, равное Io(y). В другом крайнем случае, когда Io(x:y)=0 слова x, y независимы.
Среди слов одной и той же длины можно ввести метрику
r(x, y) = ( Io(x/y) + Io(y/x) ) /2.
Эта величина называется информационным расстоянием и характеризует информационную зависимость двух источников. В частности, равенство нулю этого расстояния означает полную информационную тождественность двух источников информации.
Пример. Даны два слова x=«abaacbca», y= «». Согласование организуем в виде таблицы
Табл. 2
a | b | a | a | c | b | c | a |
1 | 2 | 2 | 1 | 3 | 2 | 1 | 3 |
составное слово xÄy= «(a,1),(b,2),(a,2),(a,1),(c,3),(b,2),(c,1),(a,3)», имеет композицию (2(a,1),2(b,2),1(a,2),1(c,3),1(c,1),1(a,3)). Совместное распределение можно найти из матрицы частот mij, где mij число повторов составной буквы (A[i],B[j]). Матрица || mij || называется матрицей переходов слова x в слово y. Эта матрица имеет вид
Табл. 3
1 | 2 | 3 | åx | |
a | 2 | 1 | 1 | 4 |
b | 0 | 2 | 0 | 2 |
c | 1 | 0 | 1 | 2 |
åy | 3 | 3 | 2 | 8 |
Выпишем характерные величины для этого случая
![]()
![]()
![]()
![]()
![]()
Задача распознавания
Исходной является информационная матрица (например, см. табл. 4.). По горизонтали расположены испытания в количестве n штук. Самый левый столбец содержит номера испытаний. Столбцы 1-N называются столбцами рабочих признаков. Последний столбец - основной признак, подлежащий распознаванию.
Табл. 4.
X1 | X2 | … | XN | Y | |
1 |
|
| … |
| y1 |
2 |
|
| … |
| y2 |
… | … | … | … | … | … |
n |
|
| … |
| yn |
Основную идею методики распознавания рассмотрим на примере. Пусть имеется два рабочих признака, информационная матрица которых имеет вид
X1 | X2 | Y |
1 | 1 | a |
1 | 0 | b |
0 | 1 | a |
0 | 1 | b |
0 | 0 | a |
Переходная матрица для признака X1
a | b | |
0 | 2 | 1 |
1 | 1 | 1 |
Согласно этой матрицы значению выходного сигнала X1=0 мы будем выставлять две альтернативы входного сигнала Y, именно, первая альтернатива «a» с оценкой доверия 66% и вторая альтернатива «b» с оценкой 33% (2 и 1 в первой строке делят альтернативы в соотношении 2:1 ). Если значение первого признака X1 = 1, то мы выставим две альтернативы: «a» с оценкой 50% и значение «b» с оценкой 50% ( 1 и 1 во второй строке матрицы ).
Переходная матрица для X2
a | b | |
0 | 1 | 1 |
1 | 2 | 1 |
Аналогично, для этого признака получаем в первом случае набор альтернатив a, b с оценками 50% и 50%. Во втором случае тот же набор альтернатив с оценками 66% и 33%.
Переходная матрица для X1ÄX2
a | b | |
00 | 1 | 0 |
01 | 1 | 1 |
10 | 0 | 1 |
11 | 1 | 0 |
Наборы альтернатив с оценками:
a, b 100% - 0%
a, b 50% - 50%
a, b 0% - 100%
a, b 100% - 0%
Подводя итог, можно сказать следующее. И первый и второй признак в половине случаев дают оценки альтернатив 50-50, в остальных 50% случаев – оценки 66-33. Композитный признак, составленный из этих двух простых признаков дает оценки 50-50 дает лишь в 25% случаев, а в остальных 75% случаев распознает объект стопроцентно.
На этом простом примере можно отметить несколько важных моментов.
1) Композитные признаки могут иметь значительно лучшие характеристики, чем признаки, из которых они составлены.
2) Необходимо иметь методику подбора композитных признаков, максимально улучшающих распознаваемость объектов.
3) Необходимо добиваться безотказной работы алгоритма.
Второе обеспечивается процедурами кластеризации пространства признаков (см. ниже). Третье обеспечивается квантованием значений признаков (см. ниже).
Общую схему распознавания можно проиллюстрировать на следующем примере из книги Гоппа [4] ( рассматривается безальтернативное распознавание).
Рассмотрим информационную матрицу
Табл. 5.
X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | Y | |
1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | a |
2 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | a |
3 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | a |
4 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | a |
5 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | a |
6 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | b |
7 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | b |
8 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | b |
9 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | b |
10 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | b |
11 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | ? |
12 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ? |
В левом столбце расположены номера объектов 1-12. Х1-Х8 – столбцы рабочих признаков. Y – столбец основного признака. Объекты 1-10 будут использованы для обучения. Объекты 11-12 предназначены для распознавания.
Обучение заключается в следующем:
а) расчет информативности рабочих признаков по отношению к основному признаку
б) отбраковка малоинформативных признаков (ниже первого параметра настройки a )
в) кластеризация в множестве признаков, создание финального для распознавания набора сложных признаков с достаточной информативностью ( не ниже второго параметра настройки b ).
Созданный набор финальных признаков используется для распознавания. Предположим, что найден следующий набор финальных признаков
11Ä1, 11Ä2, 1Ä2Ä7, 11Ä7
Процедура распознавания состоит в следующем:
1) Берем контрольный объект, точнее, значение рабочих признаков на этом объекте ( например, объект 12 )
X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | Y | |
12 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ? |
2) Берем очередной финальный признак ( например 11Ä1 )
3) Находим значение финального признака на контрольном объекте из информационной матрицы
X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | Y | |
12 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | ? |
( Это значение (1,0) )
4) В матрице переходов выбранного признака находим строку, соответствующую значению нашего признака на выбранном объекте.
Y[1]=a | Y[2]=b | |
(1,0) | 3 | 0 |
(0,0) | 1 | 1 |
(0,1) | 0 | 4 |
(1,1) | 1 | 0 |
Это стока 1.
5) Находим максимальное значение в этой строке. Это значение m11=3, соответствующая буква основного признака Y[1]=a.
6) Если в строке есть лидер, т. е. разность значения этого лидера со всеми другими значениями строки ³ выбранного порога g=1 (третий параметр настройки)
![]() ,
,
то в матрице финальных откликов (см. ниже ) в столбце 11Ä1 выставляем значение буквы, соответствующей этому лидеру (Y[1]=a). Если лидера нет, то в соответствующей ячейке проставляется пробел.
11Ä1 | 11Ä2 | 1Ä2Ä7 | 11Ä7 | Y | |
12 | a | a | - | - |
7) Полученная таким образом строка финальных откликов, сравнивается со стандартными словами
(a, a,a, a), (b, b,b, b).
Длина стандартного слова равна числу базовых признаков. Количество стандартных слов равно числу букв в алфавите основного признака.
По метрике Хэмминга ( расстояние между двумя словами равно количеству позиций, в которых стоят разные буквы) находится ближайшее стандартное слово к слову финальных откликов. Буква, определяющая ближайшее стандартное слово дает прогнозируемое значение основного признака контрольного объекта.
Квантование
В реальных задачах значения отдельных признаков в информационной матрице редко повторяются. Если по такой таблице построить переходную матрицу для отдельного признака и попытаться распознавать контрольные объекты, то вероятность отказа будет весьма велика. Рассмотрим простой пример. Имеется один рабочий и один основной признак. Информационная матрица имеет вид
X | Y |
1 | a |
2 | b |
Без всяких расчетов видно, что имеется функциональная зависимость между рабочим и основным признаком. Канал YÞX имеет максимальную пропускную способность и минимум шумов. Однако, если в какой-то момент мы получим в качестве сообщения значение признака X=3, то не сможем восстановить значение входного сигнала Y. Очевидны причины, по которым мы не можем этого сделать. Чтобы избежать этого поступают следующим образом. Возможный диапазон изменения значений отдельного признака разбивается на некоторое число участков. Каждому такому участку присваивается индекс ( 0, 1, 2, … ), который в дальнейшем будет отождествляться со значением признака. С точки зрения терминологии слов, такая операция означает, что мы перестаем различать некоторые пары или группы букв слова-признака. Очевидно, что это приведет к определенной потере информации, содержащейся в данном сообщении (в данном признаке ). Известно, что при заданном числе участков разбиения, минимальных потерь информации можно достигнуть, если выбирать эти участки по возможности с одинаковым числом попадающих в каждый участок значений признака. Отметим, что уменьшая значение числа диапазонов квантования мы увеличиваем информативность признака и тем самым увеличиваем его распознавательную способность в множестве квантованных значений. С другой стороны, квантование приводит к «размазыванию картинки» исследуемого сигнала. Таким образом, уменьшая детализацию значений интересующего нас входного сигнала и детализацию принимаемого выходного сигнала, мы повышаем пропускную способность информационного канала и уменьшаем шум. Задача оптимального квантования признаков может быть выделена в отдельную задачу и в рамках этой статьи не рассматривается.
Кластеризация
Другим важным аспект в задаче распознавания является формирование сложных финальных для распознавания признаков, имеющих большую информативность и независимых между собой. Производить такую селекцию признаков можно на основе информационного расстояния (см. раздел Информационный канал ) и цепной развертки, произведенной на основе этого расстояния. Предположим, что мы отобрали некоторое множество рабочих признаков. Возьмем самый информативный из них по отношению к основному признаку. Пусть это будет признак C0. Этот признак будет первым в строящейся цепочке признаков. Среди оставшихся признаков находим ближайший к C0 признак, пусть это будет C1, второй в цепи. Одновременно с этим начинаем строить цепочку соответствующих расстояний. Первым из них будет r1=r( C1, C0). Среди оставшихся признаков находим ближайший к множеству {C1, C0} признак, пусть это будет C2, третий в цепи. Расстояние r2=r( C2, {C1, C0}) , будет вторым в цепочке расстояний. Продолжим этот процесс до исчерпания всех признаков. Общий шаг построения описывается следующим образом. Предположим, что уже построена цепочка признаков C0, C1,…, Ck и соответствующая цепочка расстояний r1, r2,…, rк. Среди признаков, не попавших в множество Mk = { C0, C1,…, Ck } находим ближайший к этому множеству признак и обозначаем его Ck+1. Полагаем rk+1=r( Ck+1, Mk). После того, как эти две цепочки построены, производим последовательные бинарные деления множества всех признаков до желаемого числа кластеров. Именно, в цепи расстояний находим максимальное расстояние rp. По этому расстоянию разбиваем множество всех признаков на два кластера { C0, C1,…, Cp } и { Cp+1, Cp+2,…, Cn }. Тоже самое можно проделать с полученными двумя множествами. Получаемые при такой процедуре кластеры обладают следующими свойствами. Признаки лежащие в разных кластерах более информационно независимы, чем признаки лежащие в одном кластере. На основании полученной кластеризации набираются парные, сложные признаки. Пары выбираются из разных кластеров, при этом перебираются всевозможные пары, удовлетворяющие двум условиям. Информативность сложного признака относительно основного должна быть больше заданного порога, расстояния между любыми двумя парами должно быть больше другого заданного порога. После образования парных признаков это множество добавляется к множеству простых признаков и процедура построения цепной развертки повторяется в этом множестве разнородных признаков. Таким образом, можно получить заготовку для построения сложных признаков размерности 3 и более.
Литература
1. Работы по теории информации и кибернетики.-М.: ИЛ, 1963.
2. Коды и информация // УМН.-1984.-Т 39. . 77-120.
3. , , Алгебраическо-информационный подход к распознаванию образов // Труды Международной конференции по автоматизации в геологии.-М., 1990.
4. Введение в алгебраическую теорию информации, М.: Наука, 1995.
5. О некоторой схеме распознавания на основе признакового подобия объектов. Алгоритм построения дерева распознавания // Сборник трудов Института системного анализа РАН «Развитие безбумажной технологии в организационных системах». - М.: 1999. С. 144-154.
