
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Комбинированные методы распознавания печатных и рукопечатных символов
Работа посвящена распознаванию печатных и рукопечатных образов символов в условиях различных искажений образов символов. Рассматриваются алгоритмы комбинирования нескольких методов распознавания, оптимизированные к различным деформациям образов символов. Приводятся характеристики распознавания комбинированных алгоритмов.
Введение
Распознавание образов символов является важнейшей задачей в системах распознавания документов. Критерии качества распознавания различаются в зависимости от назначения системы ввода. Например, персональным программам распознавания текстов с бумажных носителей свойствен естественный и объективный критерий качества, оцениваемый числом исправлений, необходимых для приведения результатов распознавания к приемлемому для последующей обработки виду. Для профессиональных систем массового ввода документов с проверкой результатов операторами не менее важным является критерий надежности распознавания. Важным условием распознавания являются ограничения на время решения задачи. В настоящей работе описываются подходы к комбинированию алгоритмов распознавания символов для различных классов образов: почтовых индексов, рукопечатных, печатных.
В работе описывается комбинирование над несколькими базовыми алгоритмами распознавания образов символов:
- алгоритм 3x5 [1];
- событийный алгоритм EVN [1];
- древовидные алгоритмы [2];
- методы сравнения с эталоном MSK [3];
- распознавания скелетных образов SKE [4];
- нейронная сеть над образами 3x5 NET3x5 [1];
- общая нейронная сеть NET [5].
Используются следующие характеристики алгоритмов распознавания, описанные в автором в работе [6]:
- точность;
- полнота коллекции;
- доля отказов;
- монотонность оценок;
- быстродействие.
Для монотонности оценки применяются две характеристики M240 и M255, представляющие собой долю ошибок с оценками, превышающими значения 240 и 255, при условии масштабирования оценок на интервал 0-255, где 255 – максимальная оценка.
Обучение алгоритмов и оценка перечисленных характеристик производилась на следующих базах графических образов [7]:
- BNL, состоящий из 3000 образов рукопечатных почтовых индексов;
- BNT (~1000 образов рукопечатных почтовых индексов);
- BHL (~1000000 рукопечатных образов);
- BHT (~100000 рукопечатных образов);
- BPL (~1000000 печатных образов);
- BPT (~100000 печатных образов).
1 Распознавание полей рукопечатных цифровых индексов
Распознавание полей структурированных документов, содержащих почтовые рукопечатные цифровые индексы (см. рис. 1) , четко локализовано, то есть после ориентации документа, наложения

Рис. 1. Примеры почтовых рукопечатных индексов
Рис. 2. Примеры нерекомендованых сегментированных начертаний индексных цифр «7»и «5» и несегментированных начертаний цифр «1» и «7»
на него формы и удаления статической информации известны не только границы полей с индексами, но и ориентировочные границы каждого индекса [8].
Наиболее характерными ошибками заполнения индексных элементов являются:
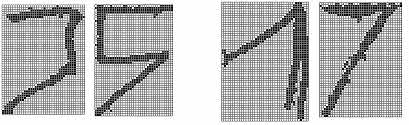
- нерекомендованные сегментированные, то есть написанные в соответствии с индексной сеткой, начертания (см. рис.2);
- склеивание изображений из двух соседних знакомест;
- несегментированные произвольные начертания (см. рис. 2);
- зачеркивания, кляксы.
Естественным дефектом рукопечатных индексов в отсканированных документах является выход части линий индекса за ориентиры индексного знакоместа.
Учитывая перечисленные дефекты, представляется естественной схема распознавания индексного поля, состоящая в выделении компонент связности в расширенной области поля со снятой статической информацией и последующим комбинированием компонент связности, попавших в индексное знакоместо, с компонентами, близкими к границам знакоместа. Относительно нечастые случаи компонент связности, близких двум знакоместам также требуют пробного разрезания. Для некоторых документов, содержащих значительное число индексов, необходимо достаточное быстродействие.
Рассмотрим голосующую схему синтеза метода распознавания индексов из описанных базовых методов. А именно ограничимся четыремя базовыми методами
- метод 3x5;
- событийный метод с сильной фильтрацией малых линий с ограниченным числом альтернатив распознавания;
- дерево с информативными признаками;
- сравнения с эталоном.
каждый из методов обучен на базе BNL, содержащей образы индексов с кодами «0»,…,«9». Характеристики методов на базе BNT сведены в таб.1.
Таблица 1. Характеристики методов распознавания индексов
Эталоны | 3x5 | События | Дерево | |
Точность (%) | 99.6 | 99.4 | 96.5 | 94.5 |
Полнота коллекции(%) | 99.9 | 100.0 | 98.5 | 100 |
Отказов(%) | 0.1 | 0 | 2 | 0 |
Быстродействие (образов/сек) | 1000 | 800 | 800 | 600 |
M240 (%) | 0.1 | 0 | 0.3 | 10.1 |
M255 (%) | 0.1 | 0 | 0 | 0 |
Частота ошибки | 0.004 | 0.006 | 0.035 | 0.055 |
Отметим что, несмотря на небольшой объем база графических образов BNT, эта база содержит некоторое число индексов с несегментированым или нерегламетированным начертанием, что ухудшает характеристики методов. В таблице 1 присутствует еще одна характеристика – частота ошибки, определяемая как отношение числа ошибок к общему числу символов в базе. Частота ошибки является приближением вероятности ошибки.
Распознав всеми методами исследуемый образ, получим четыре коллекции и общую коллекцию, состоящую из альтернатив вида
(Si,Ni),
где Si – код символа, порожденного хотя бы одним базовым методом
Ni – количество методов, породивших этот код.
Очевидно, что вероятность ошибки Perr кода, подтвержденного несколькими точными методами, уменьшается по сравнению с вероятности ошибки каждого из методов. Приняв вероятность ошибки Pi одного метода одинаковой для всех цифр и предполагая независимость событий, состоящих в генерации альтернативы одним из методов, получаем вероятность ошибки при совместной генерации n методами Perr (n) = ![]() Pi . То есть Perr (2)»10-5, Perr(3)» 10-6, что должно обеспечить требуемую точность. Учитывая определенную зависимость базовых методов (хотя бы из-за обучения на общей базе образов), для надежности используем не три, а четыре метода.
Pi . То есть Perr (2)»10-5, Perr(3)» 10-6, что должно обеспечить требуемую точность. Учитывая определенную зависимость базовых методов (хотя бы из-за обучения на общей базе образов), для надежности используем не три, а четыре метода.
Выявим особые случаи, опираясь на свойства методов. Реализация альтернативы с высокой оценкой методами 3x5 или наложения дает возможность не использовать коллекции других методов, то есть не активизировать процесс распознавания для экономии времени. В случае малых оценок методов 3x5 или наложения, а также для отказов дерева и событийного метода необходима отработка всех четырех методов с последующим уменьшением оценки. Также необходимо предусмотреть случаи разрешения конфликтов, состоящих в генерации альтернатив с равным числом проголосовавших методов Ni=Nj. Конфликт устраняется, если оба монотонных метода голосуют за одну из конкурирующих альтернатив. Финальную оценку Wi удобнее сохранять в масштабированном виде (например, положив Wi =Ni´64-1), отмеченные случаи ненадежности уменьшают оценку на размер штрафа, оптимизированного на тестовом материале.
Характеристики голосующей схемы следующие: точность - 100%, полнота коллекции - 100%, отказов – 0, быстродействие 500 символов в секунду, критерии монотонности M240=M255=0. То есть на тестовой базе BNT ошибки отсутствуют. Таким образом, с помощью голосующей схемы удается достичь значительного повышения надежности распознавания, с сохранением монотонности при приемлемом быстродействии. Это удалось из-за высокой точности базовых методов при остальных приемлемых характеристиках. Также немалую роль играет разнородность методов, состоящая в разнообразии представлений, каждое из которых в конкретных случаях может лучше распознавать искаженный образ.
В заключение отметим, что голосующая схема позволяет без потерь качества устранять некоторые ошибки заполнения. Например, обучив статистически частым вариантам неправильного сегментированного заполнения один или несколько (но не все) из используемых методов, мы добьемся распознавания таких начертаний без высоких оценок.
2 Распознавание полей рукопечатных символов
Таким образом, от метода распознавания рукопечатных символов ожидается в первую очередь высокая монотонность, призванная обеспечить надежность пропускаемых операторами строк. Необходима полнота коллекции для постобработки. Естественно, что характеристики точности и скорости метода также должны быть оптимизироваться, но не за счет монотонности и полноты коллекции.
Таблица 2. Характеристики методов распознавания рукопечатных образов
NET | SKE | MSK | 3x5 | |
Точность (%) | 99.22 | 95.6 | 93.9 | 80.5 |
Полнота коллекции(%) | 99.63 | 96.1 | 97.8 | 98.8 |
Отказов(%) | 0.04 | 2 | 0 | 0 |
Быстродействие (образов/сек) | 300 | 500 | 120 | 300 |
M240 (%) | 0.2 | 1.5 | 2 | 0.1 |
M255 (%) | 0.1 | 1 | 0.7 | 0 |
Рассмотрим схему синтеза метода распознавания рукопечатных символов из описанных базовых методов. Будем использовать четыре базовых метода
- общая нейронная сеть NET
- скелетон SKE
- наложения MSK
- метод 3x5
с характеристиками, приведенными в таблице 2. Алгоритмы обучались на базе графических образов BHL, и тестировались на базе BHT.
Описанная выше (для рукопечатных индексов) голосующая схема не может быть применена, прежде всего, из-за низкой точности методов. Рассмотрим механизм совпадений результатов нескольких методов, заключающийся в идентичности кодов ведущих альтернатив нескольких методов. От совпадения ожидается «полиномиальное» повышение точности, обеспечиваемое гипотезой о независимости базовых методов. Разумеется, независимость методов, интуитивно понимаемая как различие их представлений и схем обучения, не гарантирует реальной независимости событий, представляющих собой реализацию ведущей альтернативы
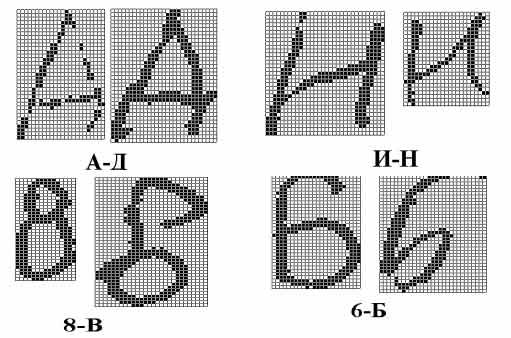
Рис. 3. Примеры родственных символов
несколькими методами. Для двух базовых методов M1 и M2 определим метод совпадения M1 Ç M2, комбинирующий две базовые коллекции по следующему правилу. Если коды ведущих альтернатив в коллекциях обоих методов совпадают, то результирующей будет коллекция первого метода, а в
случае несовпадения ведущих кодов вырабатывается отказ. Вычислим процент ошибок (без учета отказов) совпадений различных методов на тестовой базе BHT по отношению к ошибкам более точного метода из пары, образующей совпадение. Процент совпадающих ошибок NETÇSKE равняется 43% по отношению к NET, точность NETÇMSK - 39% по отношению к NET, а точность SKEÇMSK - 70% по отношению к SKE. Это говорит о значительной зависимости базовых методов распознавания рукопечатных символов, требующих более сложного комбинирования, нежели голосующая схема.
В рассматриваемых алфавитах кириллицы и латиницы присутствуют группы родственных символов, близких по начертанию, таких как «АД», «ИН», «8В», «6Б», «5S» и т. д. Родственные символы порождают классы образов, объективно близких друг к другу, распознаванию которых свойственны специфические проблемы. Одна часть Ã1 образов родственных символов различается между собой различными базовыми методами, другая Ã2 – допускает многозначную интерпретацию, как в распознавании, так и в ручной классификации оператором при разметке базы графических образов (см. рис. 3), третья промежуточная часть Ã3 не представляет проблем для человека, но является источником ошибок базовых методов. Как было определено выше, алфавит содержит коды символов, различимые данным базовым методом. Для родственных символов нельзя говорить о тождественности их для базового метода, ибо их образы могут различаться, а могут и не различаться, и оба случая реализуются с ненулевой вероятностью, определяемой частотой встречаемости подклассов Ã1 и Ã2 в рукопечатных документах. Реализация подкласса Ã3 различна у различных базовых методов и зависит, в первую очередь, от грубости представления метода. Разумеется, уменьшение мощности подкласса Ã3 используемых методов является важной задачей, но после оптимизации обучения по этому критерию появление ошибок распознавания родственных символов, связанных, как минимум, с подклассами Ã1 и Ã2, все равно остается неизбежным. Доля ошибок, связанных с родственными символами, сопоставима с долей оставшихся ошибок. В подтверждение этого факта свидетельствуют данные таблицы 3, характеризующие долю ошибок на родственных символах по отношению к общему числу ошибок на базе BHT.
Таблица 3. Ошибки распознавания родственных рукопечатных символов
Точность | % ошибок (без учета отказов) | % родственных ошибок | |
NET | 99.22 | 0.78 | 0.34 |
SKE | 95.6 | 4.4 | 2.0 |
MSK | 93.8 | 6.2 | 4.3 |
3x5 | 80.5 | 19.5 | 8.1 |
Наиболее частым случаем ошибки, связанной с родственными символами, является генерация коллекции, содержащей конкурирующие старшие альтернативы с кодами родственных символов. Продуктивный анализ родственных кодов, которые, как было сказано, являются неизбежными, состоит в нахождении конфликта и принятии нескольких решений:
- разделение родственных конфликтов от иных случаев конкуренции старших альтернатив
- разрешение части родственных конфликтов может откладываться на последующие этапы распознавания, например, контекстно-лингвистические механизмы, для которых важна полнота коллекции и близость оценок старших альтернатив
- не родственные конфликты должны быть устранены, то есть должен быть сделан выбор между кодами старших альтернатив, а расстояние между конкурирующими оценками – увеличено. В случае невозможности принятия такого решения в конфликтной коллекции необходимо снизить все оценки.
Одними из целей комбинирования базовых методов является разрешение конфликтов оценок старших альтернатив, в том числе принятие решений о невозможности разрешения, с делегированием полномочий для этого последующим этапам распознавания.
Далее будет описаны схема комбинирования трех методов нейронной сети, скелетона и наложения, учитывающая особенности этих методов, прежде всего различие в точности распознавания. А именно, нейронная сеть как наиболее точный метод поддерживается скелетоном и наложением для выработки более надежных оценок. Полученные коллекции NET, SKE и MSK объединим, используя только первые две альтернативы каждого метода, выделяя следующие случаи
- NET1 совпадает со SKE1 и MSK1
- NET2, имея близкие с NET1 оценки, совпадает со SKE1 и MSK1
- NET1 совпадает со SKE1 и не совпадает с MSK1
- NET1 совпадает со MSK1 и не совпадает с SKE1
В первом случае в результат войдет только одна альтернатива NET1, поддержанная всеми тремя методами. Во втором случае результирующая коллекция будет содержать единственную альтернативу NET2, случай является разрешением конфликта родственных кодов альтернатив нейронной сети. В третьем случае к альтернативе NET1 добавляется альтернатива MSK1 и различаются следующие ситуации:
- оценка NET1 равна 255 и SKE2 и NET2 не совпадают с MSK1.
- оценка NET1 не равна 255 и одна из альтернатив SKE2 и NET2 совпадает с MSK1.
- оставшиеся случаи.
Здесь используется монотонность оценок базового метода NET, и для наибольшей надежности результаты нейронной сети разбиваются по уровню 254. Четвертый случай аналогичен третьему.
Во всех случаях коллекция пополняется символом «~», который интерпретируется как произвольный код из оставшихся символов или несимвол. Каждому исходу соответствует набор условных вероятностей, однако, в качестве оценок добавляются не вероятности, а коды от 255 для первых двух случаев до 248 для последнего исхода четвёртого случая. То есть диапазон оценок 255¸248 может быть пересчитан в вероятности.
Если процедура выработки условных вероятностей не сработала, то есть все три альтернативы NET1, SKE1 и MSK1 различны, то распознавание продолжается, и для выработки итоговой коллекции альтернативы всех методов складываются согласно следующей процедуре. Каждая альтернатива (Si,Wi,Mi), где Mi – код метода, преобразуется в альтернативу (Si,W(Si,Mi)´Pi,Mi)), где W(Si,Mi) – вес метода, который может параметризоваться кодом символа. Из альтернатив с одинаковым кодом (S,Wj,Mj)…(S,Wk,Mk) выбирается альтернатива с наибольшей оценкой. Полученный набор альтернатив сортируется по убыванию оценки. В нашем случае веса метода подбираются так, что нейронная сеть получила приоритет.
Описанная схема комбинирования трех методов практически не использует исходные оценки для формирования итоговых оценок, а также игнорирует младшие альтернативы. Главным достоинством схемы является генерация оценок, обладающих вероятностным смыслом. В то же время потеря младших альтернатив препятствует применению полученных коллекций в лингвистических механизмах, существенно опирающихся на полноту коллекций, а не на возможность подстановки произвольного символа. Выход из этой ситуации состоит в обогащении полученной вероятностной коллекции альтернативами базовых методов с не вероятностными оценками. Утрата полноты коллекции не важна для распознавания полей, содержащих цифры и не связанных с контекстно-лингвистической постобработкой, опирающихся на полноту коллекции.
Возможно использование схемы с парным совпадением методов NET и SKE, ориентированная на случай совпадения кодов альтернатив SKE1 и NET1 и на поддержку альтернативой скелетона SKE1 с оценкой не менее WS некоторой альтернативы сети NETi при условии, что оценка NET1 не превосходит WN. При любом исходе сохраняются младшие альтернативы. Распознавание третьим методом MSK реализуется только для случая полученных малых оценок ведущей альтернативы. Эта схема обладает большим быстродействием по сравнению с предыдущей, хотя вероятностный смысл оценок, а значит и надежность распознавания, значительно ниже. Для повышения надежности используется этап переоценки, заключающийся в следующем изменении оценок коллекции
Wi ¢= W3x5 ´ Wi / W0
где Wi - исходная оценка альтернативы i, а W3x5 – оценка метода 3x5 кода символа S0 оценки исходной ведущей альтернативы. Иными словами, оценка 3x5 уменьшает пропорционально оценки всех альтернатив коллекции, и эта процедура призвана уменьшить высокие оценки образов, далеких от сверток 3x5 эталонного набора. Уменьшение оценок полноценных символов, незнакомых методу 3x5, устраняется запретом этапа переоценки коллекций, полученных надежным совпадением или обладающих большой оценкой ведущей альтернативы.
В общем виде схема комбинированного распознавания рукопечатного символа состоит из трех этапов
- совпадение ведущих альтернатив нескольких методов, включая разрешение конфликтов оценок. Этап призван выявить области надежного распознавания.
- пополнение альтернативами дополнительных базовых методов. Происходит в случае неудачи этапа совпадения, что интерпретируется как ненадежное распознавание с результатом, возможным быть улучшенным более трудоемкими методами, альтернативы которого привносятся с целями улучшения и точности и полноты коллекции.
- переоценка одним из методов с монотонными оценками. Выполняется для неудачных предыдущих этапов. Этап предназначен для увеличения монотонности всей схемы.
Результирующие характеристики комбинированных методов распознавания рукопечатных символов и рукопечатных цифр сведены в таблицу 4, из которой видны достоинства синтезированного метода перед методом общей нейронной сети, являющейся основой рукопечатного распознавания. Характеристики синтезированного метода удовлетворяют требованиям переборной схемы распознавания (в первую очередь – схемы с фиксацией границ знакомест) и постобработки, позволяя добиваться точности распознавания 198-199 правильных символов из 200 знакомест и высочайшей надежности порядка 1 ошибки подсветки на 10000 знакомест.
Таблица 4. Характеристики нейронной сети и комбинированных методов распознавания рукопечатных образов букв и цифр
буквы | цифры | |||
NET | Комб. | NET | Комб. | |
Точность (%) | 99.22 | 99.26 | 99.75 | 99.88 |
Полнота коллекции(%) | 99.63 | 99.9 | 99.9 | 99.96 |
Отказов(%) | 0.04 | 0 | »0 | 0 |
Быстродействие (образов/сек) | 300 | 130 | 320 | 160 |
M240 (%) | 0.2 | 0.1 | 0.01 | 0 |
M255 (%) | 0.1 | 0.05 | 0 | 0 |
3 Распознавание полей печатных символов
Рассмотрим комбинирование грубых базовых методов распознавания с целью получения быстрого метода с монотонными оценками. Характеристики описанных выше алгоритмов 3x5, нейронной сети над 3x5 и событий сведены в таблицу 5. Алгоритмы обучались на базе графических образов BPL, и тестировались на базе BPT.
Таблица 5 Характеристики грубых алгоритмов, подсчитанные на базе BPT
Алгоритм | 3x5 | Сеть над 3x5 | События |
Точность (%) | 95.3 | 99.17 | - |
Полнота коллекции (%) | 99.9 | 99.81 | 94.5 |
Отказы (%) | - | - | 5.4 |
Быстродействие (букв в сек) | 800 | 400 | 2000 |
Монотонность оценок | Высокая | Низкая | - |
Очевидно, что достоинства и недостатки у всех трех алгоритмов различны. А именно, событийный метод обладает наибольшим быстродействием, но, являясь генератором, не может сформировать оценок. Нейронная сеть над 3x5 дает наибольшую точность, но обладает наименьшим быстродействием и низкой монотонностью оценок. А метод 3x5, имея высокую монотонность оценок и наилучшую полноту коллекции, дает наименьшую точность, которая, как было показано выше, повышается дискриминационными методами. Построим схему комбинирования алгоритмов распознавания, призванную сохранить достоинства каждого из рассмотренных методов.
Комбинированное распознавание будем производить поэтапно:
- генерация. Состоит в выработке гипотез событийным методом
- экспертиза. Заключается в последовательной отработке методов 3x5 и нейронной сети 3x5 на суженном алфавите, определенным порожденными событийным методом гипотезами. Коллекции, порожденные двумя методами, объединяются таким образом, чтобы букве приписывалась наибольшая оценка, то есть алгоритмы 3x5 и нейронной сети 3x5 конкурировали между собой по точности. Оба этапа проходят достаточно быстро из-за скорости событийного метода и ограничения количества эталонов при экспертизе.
- полное распознавание. Реализуется в случаях отказов при генерации или малой оценки экспертизы. Последний случай может свидетельствовать об ошибках генерации. При полном распознавании методы 3x5 и нейронной сети 3x5 запускаются на полном алфавите, их результаты объединяются аналогично этапу экспертизы.
- переоценка. Этап призван придать оценкам коллекции, сформированным предыдущими этапами, большую монотонность. Для этого используются уже подсчитанные оценки алгоритма 3x5.
Произведенное таким образом комбинирование (обозначим описанный метод как Â0) для тестовой базы BPT дает следующие характеристики распознавания: точность - 99.5 %, полнота коллекции - 99.9%, быстродействие – 900 букв в секунду. Характеристики монотонности оценок на базе BPT составляют M240»0.2%, M255»0%. Неплохие результаты естественны для комбинированного метода, использующего быстрый, точный и монотонный базовые методы. Обратившись к анализу ошибок, мы обнаружим тенденцию к конкуренции между ведущей и следующей за ней альтернативами с кодами родственных символов, объективно похожих друг на друга, в первую очередь, между символами «И», «Н», «П». Число ошибок, связанных с конкуренцией символов «ИНП», на базе BPT составляет около 60% от общего числа ошибок. Значительная доля таких ошибок сохраняется и на других ГБД. Это связано с реальным сходством линейных представлений и сверток 3x5 указанных символов, собранных из различных печатных шрифтов и используемых базовыми методами, образующими комбинаторный метод. Также существует объективная аналогичная конкуренция в группах печатных символов «ЭЗ», «се» русского алфавита и в группе узких символов «il1Irtf» латинского алфавита. Тестирование описанного метода в комбинаторной схеме сегментации образов в слове выявляет большой класс ошибок, связанных с распознаванием фиктивных образов, не являющихся символами. Например, на рис. 4а при попытке разрезания латинской буквы «Н» на две части частичные образы в грубых представлениях методов близки к представлениям идеальных символов «I», что и приводит к их распознаванию с высокими оценками. Метод 3x5 для кириллицы неизбежно содержит эталоны, обладающие достаточно равномерным распределением масс в представлении 3x5. Такие эталоны порождаются символами «ИН» и широкими образами символов «ШЖЫМ». Эталоны 3x5 с равномерным распределением масс близки к сверткам 3x5 произвольных несимволов, имеющих сходное распределение, например, склейка нескольких образов (см. рис. 4б). Другим классом несимволов являются компоненты связности из иллюстраций, которые не смогла отделиться от текстовых строк при сегментации страницы. Перечисленные источники происхождения несимволов, распознаваемых как символы с высокими оценками в комбинаторной схеме распознавания слов требуют дополнительных механизмов устранения ошибочных результатов с высокими оценками, то есть повышения монотонности метода.
 а) б)
а) б)
Рис. 4. Примеры несимволов при разрезании а) и склейке символов б)
Рассмотрим способы компенсации ошибок комбинированного метода с помощью исследований исходных образов, а не сжатых представлений. Интуитивной эвристикой устранения широких и узких несимволов являются пропорции образа, определяемые отношением ширины символа к его высоте. Вычислив для некоторой базы графических образов диапазон пропорций для каждого из символов Si и составив таблицы пропорций {PropMin(Si)} и {PropMax(Si)} получим для произвольного образа с пропорциями Prop, распознанного как символ S с оценкой P, штрафующую процедуру, состоящую в уменьшении оценки
P = max(0,P – F1( Prop - PropMax(Si) ) – F2( PropMin(Si) - Prop))
на величину, задаваемую штрафными функциями F1 и F2 недостаточности нижней границы или превышения верхней границы допустимых пропорций. Простейшие F1 и F2 являются кусочно-постоянной функцией дающей значение 255 при положительном значении аргумента и 0 – в остальных случаях, что приводит в случае нарушения априорных пропорций к назначению альтернативе нулевой оценки, то есть к игнорированию альтернативы. Функции F1 и F2 более сложного вида, например, кусочно-линейные, обеспечивают убывающий штраф по мере приближения пропорции к граничным значениям. Процедуру уменьшения оценки альтернативы с помощью геометрического анализа образа назовем дискриминатором. Каждый дискриминатор опирается на сопоставление геометрических характеристик, инвариантных для некоторого класса образов, известным характеристикам в модели идеального символа. В случае дискриминатора пропорций модель состоит в точном соответствии (или близости) диапазона идеальных пропорций. Применение дискриминатора ко всем альтернативам одной коллекции с последующей сортировкой по убыванию оценок приводит к образованию новой коллекции, часть альтернатив исходной коллекции может быть утрачена.
Так при дискриминации коллекции с помощью пропорций могут быть удалены (получить нулевые оценки) все альтернативы исходной коллекции, получение после дискриминации пустой коллекции свидетельствует о том, что распознаваемый образ является несимволом.

Рис. 5. Изображения символов ИНП идеального качества a), среднего качества б) и рассыпанного в) начертаний
Рассмотрим дискриминатор предназначенный для анализа символов, распознанных с кодом родственных букв из группы «ИНП». Для изображений прямых (не курсивных) букв «ИНП» не составляет труда достаточно точно найти область между парой массивных вертикальных линий («колонн»). Именно в этих областях находятся геометрические элементы (см. рис. 5), различные для достаточно большого числа образцов отсканированных букв ИНП различных шрифтов. Наклон перекладины должен различаться для букв ‘И’ и ‘Н’, а ее отсутствие свойственно только букве ‘П’. Для рассыпающихся изображений это простое правило требует уточнений, но и в этих случаях остатки перекладины могут быть зафиксированы и соотнесены с представлениями об идеальных буквах «ИНП». Итак, моделью дискриминатора являются свойства перекладины и перемычек в зоне между двумя «колоннами». Перечислим этапы дискриминатора «ИНП»:
- нахождение «колонн». Число «колонн», неравное двум, налагает сильный штраф на все буквы «ИНП».
- Оценка заполненности области в средней трети зоны между двух «колонн». Заполненность вызывает штраф альтернативы «П», для которой наличие перекладины невозможно.
- Поиск перекладины с помощью горизонтальных и вертикальных гистограмм. Определение надежных случаев горизонтальной и наклонной монолитной перекладин, которые разделяют альтернативы «ИН».
- Анализ перекладины с разрывами. Небольшие разрывы игнорируются, при значительных потерях в перекладине (рис. 5.в) исследуются остатки перекладины в виде выступов на «колоннах», с точки зрения их близости по вертикали. Если выступы близки по вертикали, то штрафуется «И», в противном случае штрафуется «Н».
Наиболее трудным для дискриминации «ИНП» являются жирные буквы малого размера, для которых предпринимаются специальные эвристические процедуры.
Описанный дискриминатор в некоторых случаях может служить верификатором, то есть гарантом соответствия геометрии образа достаточно сложной модели буквы. В таких случаях результат может использоваться не для уменьшения, а увеличения оценки символа. Например, в случае рассыпанных образов (рис. 5в) информация, собранная в процессе дискриминации позволяет назначить надежные монотонные оценки для образов, представляющих собой две «колонны» с выступами в соответствующих местах.
В латинском алфавите существует класс узких образов (далее мы будем их называть стиковыми), моделью которых является вертикальная «колонна» со значительными (рис. 6а) или незначительными (рис. 6б) выступами. Очевидно, что распознавание стиковых образов с незначительными выступами не может быть организовано надежно при применении грубых базовых методов, представления которых выступы не различают, поскольку игнорирование незначительных изменений образа рассматривается как одна из причин использования таких базовых методов. Перечень стиковых

Рис. 6. Примеры стиковых образов со значительными (a) и незначительными (б) выступами
символов со значительными выступами может быть значительно расширен для различения пар достаточно широких букв «YT», «IL», а список узких стиковых символов немыслим без кодов скобок «[]{}()». Применение дискриминаторов стиковых букв делает возможным как достижение приемлемой точности распознавания, так и различение фиктивных стиковых образов, генерируемых комбинаторной схемой разрезания слова.
В отличие от описанного выше дискриминатора «ИНП» стиковая модель символа не предполагает отсутствия наклона, но курсивные символы подвергаются выпрямлению, то есть нормализации наклона. Началу нахождения наклона предшествует тест образа на предмет отсеивания изображений, состоящих из нескольких компонент связности или содержащих несколько «колонн». Не прошедшие тест стиковые альтернативы получают максимальный штраф. В оставшихся образах, подразумевающих наличие одной «колонны», в линейном представлении из всех интервалов рассматриваются множество интервалов (yi,xi,di) (где yi – смещение интервала относительно верхней границы символа, di - смещение интервала относительно левой границы символа, di - ширина интервала), незначительно отличающихся по ширине от наиболее частой ширины интервала. Описанное множество интервалов соответствует в основном интервалам «колонны» и
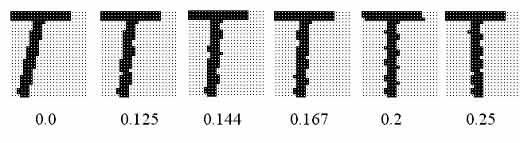
Рис. 7. Поворот с различными углами (обозначен тангенс угла) курсивного стикового образа
может быть нормализовано по наклону. Для этого рассматривается сумма середин интервалов линейного представления повернутых на угол с тангенсом Q относительно левого нижнего угла рамки образа символа (см. рис. 7)
S(Q)=S xi – (H-yi)·Q + wi/2
где H – высота образа, и решается задача максимизации сумм S(Q) в зависимости от тангенса угла наклона Q, например, методом наименьших квадратов. Угол наклона, при котором середины интервалов «колонны» дают максимальную сумму, то есть наиболее близки друг к другу, нормализует образ так, что «колонна» становится вертикальной.
В образе с единственной вертикальной «колонной» правая и левая границы ноги определяются явным образом. Относительно границ «колонны» на правом и левом абрисах образа находятся выступы и впадины как экстремумы графиков абрисов. Например, буква «I» имеет два выступа справа и два слева, а буква «i» кроме выступов обладает двумя впадинами (см. рис. 6). Массив точек границ перед нахождением абрисов, как правило, сглаживается, но точки, близкие к границе «колонны», остаются неизменными для сохранения информации. Координаты экстремумов нормализуются по высоте образа, разбиваемого на несколько вертикальных зон, например, на пять зон (число 5 выбрано из тех же соображений, что и параметр сетки 3x5, то есть из анализа структуры стиковых образов латиницы и кириллицы). Составляется набор признаков стиковой модели:
- ширина и высота образа
- наклон образа
- ширина «колонны»
- массив размеров и нормализованных координат выступов с разбиением по 5-ти зонам
- массив размеров и нормализованных координат впадин с разбиением по 5-ти зонам
- специальные признаки, связанные с предысторией формирования образа, в частности вырезания образа из склейки
- специальные признаки широких стиковых образов, например, экстремум верхнего абриса для различения пары «TY»
- специальные признаки узких стиковых образов, например, кривизна для селекции скобок.
Стиковые признаки используются для написания дискриминирующих (отличающих идеальные стиковые образы от не стиковых) и различающих (конкурирующие стиковые символы) штрафных функций. Очевидными примерами являются штраф произвольного стикового образа за выступ в центральной зоне, если отрезание произошло по этому выступу (дискриминация отрезания стиковых образов от более сложных символов – см. рис. 6.а) и штраф альтернативе «I» за отсутствие правого верхнего выступа при наличие левого верхнего, левого нижнего и правого нижнего выступов (снятие конкуренции пары «lI»).
Стиковые дискриминаторы пишутся вручную, при этом получается значительный объем кода программы, содержащего функции с параметрами, подлежащими оптимизации на символах из ГБД и реальных страниц с текстом. Также над стиковыми признаками, рассматриваемыми как векторное представление, может быть организован базовый метод с автоматическим обучением, например, бинарная нейронная сеть. Использование стиковых дискриминаторов позволяет достигнуть точности и монотонности в распознавании стиковых образов из ГБД или образов, порождаемых комбинаторными переборными схемами, сопоставимыми с точностью наилучших базовых методов, то есть точности 99.9% и монотонности M240»0.1.
Переборная схема сегментации символов, опирающаяся на оценки распознаваемых образов (как печатных, так и рукопечатных), сталкивается с рядом дополнительных проблем, связанных с тем обстоятельством, что подмножества реальных начертаний букв обладают естественным сходством с цельными образами. Эти проблемы свойственны всем рассмотренным схемам сегментации и всем комбинированным алгоритмам распознавания и символа.
Одна из проблем порождается рассыпанием образов при низких уровнях яркости сканирования или из-за объективных дефектов бумажного документа (см. рис 8) и состоит в необходимости комбинирования компонент связности внутри определенных границ символа. Даже при сравнении обоих вариантов на примерах рис. 8, то есть наибольшей компоненты и всего символа в сборке, простое сравнение оценок некорректно, ибо потери частей буквы в собранном образе могут сказаться на оценке. В частности, для алгоритма Â1 с дискриминацией снижения оценок разорванных символов более ожидаемы, что требует учета наиболее вероятных разрывов в модели идеальных образов. Помимо отмеченного пути адаптации дискриминаторов к неидеальным разорванным образам, для
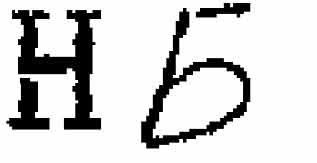
Рис. 8. Примеры частей образов, являющихся символами
устранения возможного приоритета в оценках частей символов используется дискриминатор компонент. Дискриминатор компонент назначает штраф образам, вблизи границ которых находятся компоненты связности. Для специальных случаев корреляции подмножества начертания символа с начертанием другого символа назначается дополнительный штраф за компоненту в определенном месте, призванный дать приоритет символу в сборке. На примере рис. 8 штраф символу «Ь» назначается за наличие компоненты в верхнем левом угле прямоугольной границы образа, а символу «Ч» – за левую нижнюю компоненту, эти интуитивные эвристики подтверждаются при анализе отсканированных страниц достаточного объема.
Обратим внимание на то обстоятельство, что дискриминаторные механизмы не являются базовыми методами распознавания, хотя и обладают формальным сходством с ними. Дело в том, что цель конструирования дискриминаторов (вручную или автоматически) состоит не в достижении высоких характеристик распознавания произвольного образа, а в разрешении конфликтов коллекций, порожденных базовыми методами, или работе в условиях сильных ограничений, например, набор стиковых дискриминаторов, примененных к анализу узкого образа, может рассматриваться в качестве стикового распознавателя. То есть дискриминаторы работают в определенных границах, компенсируя стабильные несовершенства основных распознавательных схем.
Дополнив комбинированный метод Â0 этапом дискриминации, мы повысим его характеристики распознавания. Точность распознавания повысится до 99.8%, монотонность - до M240»0.01, M255=0, полнота коллекции осталась равной 99.98%, скорость незначительно понизилась до 850 символов в секунду. Более того, полученный метод успешно отличает символы от несимволов, порождаемых комбинаторной схемой сегментации символов. Таким образом, на основе группы базовых методов с грубыми представлениями и набора дискриминаторов удалось построить комбинированный метод Â1 удовлетворяющий требованиям монотонности, налагаемыми схемой сегментации, и высокими характеристиками распознавания.
Метод с дискриминацией обладает двумя большими недостатками. Во-первых, образы символов, не удовлетворяющие модели идеального символа, используемой дискриминаторами, например, символов из декоративных шрифтов исключаются из числа старших альтернатив. Во-вторых, символы, в общем, удовлетворяющие модели идеального символа, но оштрафованные за различные дефекты, получают невысокие оценки, даже будучи верно распознанными. Последний недостаток затрудняет использование метода с дискриминацией в распознавании печатных форм, поля которых валидируются оценками распознавания, так как правильно распознанные поля с недостаточно высокими оценками увеличивают время работы оператора, тратящего время на проверку правильно распознанных полей.
Для преодоления недостатков комбинирования с дискриминацией рассмотрим адаптивную схему с отменой переоценки и дискриминации, в которой в дополнение к ранее используемым базовым методам будем использовать общую нейронную сеть и наложения, характеристики которых приведены в таблице 6.
Таблица 6. Характеристики алгоритмов, подсчитанные на базе BPT
Алгоритм | Нейронная сеть | Наложения |
Точность (%) | 99.96 | 99.5 |
Полнота коллекции (%) | 100 | 99.96 |
Отказы (%) | - | - |
Быстродействие (букв в сек) | 500 | 160 |
Монотонность оценок | Высокая | Высокая |
Целью комбинированного метода Â2 является достижение высоких точности, полноты коллекции и монотонности при сохранении высоких оценок надежно распознанным образам, далеким от идеальных.
Метод использует базовые методы 3x5, наложения, нейронную сеть и дискриминаторные механизмы, и состоит из нескольких этапов.
- Пропорциональный критерий, то есть отбраковка образов по допустимым пропорциям
- Стиковый распознаватель узких образов выбирает стиковые символы, не противоречащие модели узкой стиковой буквы. При этом учитываются признаки схемы сегментации, сообщающие о разрезании узкого образа от более широкого. В последнем случае стиковый распознаватель может дать отказ, и образ отправляется на следующие этапы. Успешное стиковое распознавание завершает процесс.
- Генерация событийным методом EVN, который умеют распознавать только однокомпонентные образы, в случае неудачи может запускаться второй раз со сжатым до 16х16 образом. Сжатие иногда помогает устранить разрывы, тем самым, приводя к разумному результату.
- Совпадение сети и событий с дискриминацией. Производится распознавание общей нейронной сетью NET, после чего происходит проверка совпадения результатов EVN и NET в случаях, когда образ надежно распознан событийным методом (одна альтернатива в коллекции) и поддержан сетью (альтернатива EVN присутствует в коллекции NET) или образ распознан сетью с высокой оценкой и поддержан событиями (ведущая альтернатива NET присутствуют в коллекции EVN), и при этом дискриминаторы не дают штрафа. В этих случаях, то есть при распознавании двумя методами и соответствии модели дискриминаторов, коллекция сети берется в качестве окончательной. На символах высокого и среднего качества на этапе совпадения событий и сети с дискриминацией отрабатывается большое число случаев распознавания, например, на базе BPT на этом этапе успешно распознается более 95% символов из базы.
- Зона надежности сети. Этап имеет целью выделение ситуаций, когда результаты общей нейронной сети NET подтверждаются результатами методов 3x5 и наложений MSK, и представляет собой анализ трех коллекций NET, 3x5 и MSK. Коллекция сети подтверждается двумя или одним методом, то есть совпадением ведущей альтернативы сети NET1 и ведущей (или следующей за ней) альтернативой 3x51 (3x52) и MSK1 (MSK2) аналогично схеме комбинирования трех рукопечатных методов. На этом этапе существенно используются как оценки, являющиеся монотонными для всех трех используемых методов, так и коды альтернатив. Последнее означает, что существует подмножество алфавита (например, символы кириллицы «ШЩЖЗЭ»), на котором надежность совпадения недостаточна и требует дополнительных дискриминаторов или снижения оценки. Также выделяются коллекции с конкурирующими кодами, начертания которых объективно близки и требуют более тонкого анализа. Положительный исход выделения надежной коллекции сети отменяет последующие этапы.
- Экспертиза. Проводится только в случае успеха этапа генерации, коллекция от которого используется для сужения алфавитов распознавания двух методов 3x5 и наложений MSK. Эти методы выступают в качестве экспертов, то есть расставляют оценки заранее сгенерированным кодам возможных букв. Полученные коллекции складываются в одну общую коллекцию. К полученной сумме добавляется коллекция общей нейронной сети NET. Цель суммирования альтернатив состоит в конкуренции результатов методов NET, 3x5 и MSK в случае несрабатывания совпадений сети и других методов, то есть для буквы, отличной от идеальной.
- Полное распознавание. Этап задуман для неудачной экспертизы, в результате которой получились малые оценки, или для неудачной генерации (для которой отсутствует и экспертиза). Образ распознаётся на полном алфавите методами 3x5 и MSK. Коллекции результатов этих методов и коллекция сети NET складываются в одну общую коллекцию. Целью этапа является конкуренция результатов трех методов для неидеальных образов.
- Переоценка, призванная придать оценкам коллекции, сформированным предыдущими этапами, большую монотонность. Для этого используются уже подсчитанные оценки алгоритма 3x5 или 5х3. Экспертиза грубым растром с размерами 5 на 3 производится для широких образов из списка кодов «ШЩЖЫФМ». От переоценки освобождаются коллекции получившие высокие оценки каким-либо монотонным методом и особые случаи, к которым относятся стиковые образы или топологически сложные символы (например, «№»), которые заведомо не получат монотонных оценок 3x5.
Дискриминация, необходимая для результатов, сформированными несколькими методами, в особенности для коллекций с конкурирующими старшими альтернативами, родственные коды которых обладают сходным начертанием. Дискриминационные разделители успешно устраняют конфликты родственных символов. Поскольку процент образов, подвергаемых дискриминации мал и составляет от 1 до 10 % на символах различного качества, то и процент ошибок, привнесенных дискриминаторами ничтожно мал.
Адаптивный комбинированный метод Â2 обладает очень высокими характеристиками распознавания. На ГБД BPT он совершает только одну ошибку, оценка которой ниже 240, то есть точность »100%, полнота коллекции равняется 100%, скорость составляет примерно 300 символов в секунду, монотонность M240=M255=0. Использование метода Â2 в комбинаторной схеме сегментации символов показывает надежность его результатов с точки зрения различения символов от несимволов и сохранения качества распознавания отдельных символов.
Выводы
Рассмотренные в настоящей работе схемы распознавания полей документов и печатных слов позволяют достигать высоких характеристик, сведенных в таблицу 7.
Таблица 7. Характеристики схем распознавания
Цифровые индексы | Поля рукопечатных символов | Печатные слова (Â1) | Печатные слова (Â2) | |
Точность (%) | 99.95 | 99 | 99.1 | 99.6 |
Быстродействие (образов/сек) | 300 | 200 | 400 | 200 |
M240 (%) | 0.1 | 0.2 | 0.1 | »0.05 |
M255 (%) | 0 | 0.01 | 0.01 | 0.01 |
Разработанные схемы и комбинированные методы обладают адаптивностью на различных уровнях. Прежде всего, возможен подбор типа схемы с точки зрения использования ориентировочных границ символов или их динамический перебор с распознаванием. Метод распознавания управляет комбинированием результатов в зависимости от качества коллекций базовых методов, отделяя более простые и надежные случаи от сложных, требующих привлечения дополнительных методов и дискриминаторов. Адаптивность схем и методов к сложности распознавания групп образов и отдельных образов позволяет достигнуть не только высоких точности и монотонности, но и повысить общее быстродействие.
Литература
[1] , , Методы распознавания грубых объектов. // Сб. трудов ИСА РАН "Развитие безбумажных технологий в организациях", М.: Эдиториал УРСС, 1999, с. 290-311
[2] , Древовидное распознавание нормализованных символов. // Сб. трудов ИСА РАН "Интеллектуальные технологии ввода и обработки информации", М.: Эдиториал УРСС, 1998, с. 137-157
[3] Barroso J., Bulas-Cruz J., Rafael J., Dagless E. L. Identificação Automática de Placas de Matrícula Automóveis, 4.as Jornadas Luso-Espanholas de Engenharia Electrotécnica, Porto, Portugal, Julho (1995), ISBN -9.
[4] , Распознавание скелетных образов. // Сб. трудов ИСА РАН "Методы и средства работы с документами", М.: Эдиториал УРСС, 2000
[5] В. Использование искусственных нейронных сетей
для распознавания рукопечатных символов. // Сб. трудов ИСА РАН "Интеллектуальные технологии ввода и обработки информации", М.: Эдиториал УРСС, 1998, с.122-127
[6] , , Характеристики программ оптического распознавания текста. // Программирование №3, 2002, стр. 45-63
[7] Средства управления базами графических образов символов и их место в системе распознавания. // Сб. трудов ИСА РАН " Развитие безбумажных технологий в организациях ", М.: Эдиториал УРСС, 1999, с. 277-289
[8] , Алгоритмы сегментации рукопечатных символов. // Сб. трудов ИСА РАН " Развитие безбумажных технологий в организациях ", 1999, с. 179-188
