

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
О свойстве распределения общих документов в списках, извлеченных из интернета разными поисковыми машинами
, ,
, ,
В статье рассмотрена интерпретация метапоиска как слияния списков, извлеченных по одному запросу разными поисковыми машинами. Единственной основой для определения согласованности списков и возможности их слияния служат документы, входящие в разные списки. Одним из эмпирически наблюдаемых свойств общих документов является то свойство, что среди релевантных число общих документов обычно выше, чем среди нерелевантных. В статье дана строгая, обобщающая традиционную, формулировка этого свойства, приведены необходимые и достаточные условия его выполнения, а также показано, что оно должно выполняться практически всегда.
1. Введение
Процедура метапоиска состоит в том, что получив запрос, метапоисковая система адресует его одновременно нескольким поисковым машинам или поисковым методам. Каждая поисковая машина (метод), руководствуясь своими представлениями о релевантности, упорядочивает все доступные ей документы по убыванию релевантности и возвращает начальную часть этого списка. Получив списки, процедура метапоиска пытается представить их пользователю в удобном для него виде. Существует два принципиально различных варианта представления — без слияния исходных списков и с их слиянием в один. В первом случае мы имеем дело с такими задачами проектирования пользовательского интерфейса, как одновременное отображение списков на экране, отслеживание того, что документ уже был просмотрен в одном из списков и т. п. Второй случай основан на той посылке, что результат работы метапоисковой системы должен внешне ничем не отличаться от результата работы отдельной поисковой машины, а именно иметь форму списка, документы в котором упорядочены по убыванию релевантности. Хотя на практике наиболее распространен как раз первый вариант, в работах по метапоиску он уже давно не рассматривается, поскольку, как и большинство задач проектирования интерфейса, более относится к области эргономики и психологии восприятия, нежели к вычислительным наукам. Поэтому под задачей метапоиска обычно понимают задачу слияния нескольких (нестрого) упорядоченных списков в один. Эта задача известна под именем задачи data fusion.
Поисковые машины имеют дело с пересекающимися, а поисковые методы — (обычно) с одной и той же базой документов. Поисковые машины осуществляют поиск в интернете, а поисковые методы обычно используются в тестовом режиме и на тестовых коллекциях, и, показав хорошие результаты, могут в последующем быть включены в поисковые машины. Каждая поисковая машина имеет собственную базу проиндексированных документов и пользуется своими собственными методами поиска (упорядочения документов базы в соответствии с используемыми машиной алгоритмами назначения релевантности). Второй случай (разные поисковые методы) характерен для ситуации верификации как отдельных методов, так и процедуры слияния их результатов. Эффективность процедур слияния существенно определяется свойствами распределений документов, входящих в более чем один список. Единственное, что известно о списке и выдавшей его поисковой машине — это само представленное списком (нестрогое) упорядочение. Конкретные правила упорядочения, используемые поисковой машиной, ни даже назначенные документам оценки, в соответствии с которыми документы упорядочены, неизвестны.
Различные ранговые методы слияния списков явным образом используют свойство общих документов (СОД) [1], [7]. Причина не в том, что выполнение СОД приводит к лучшим результатам слияния, а в том, что общие документы являются единственной основой для комбинирования (или, что никогда не рассматривается в задачах метапоиска, отказа от комбинирования) результатов поиска по одному и тому же запросу, полученных различными поисковыми машинами. В то же время, если СОД не выполняется, результат комбинирования может оказаться хуже, чем некоторые из исходных списков. Как эмпирическое свойство СОД детально описано в [3], [4], [6] для случая бинарной релевантности. В то же время, заключение, что обычно это свойство выполняется, трудно признать вполне удовлетворительным. В частности, хотелось бы знать условия, при которых оно выполняется.
Рассмотрим поисковую машину (ПМ) как классификатор <Xt, Rt()>, где Xt — база проиндексированных машиной документов, т. е. та база, в которой и производится поиск, а Rt() — классифицирующее правило, по которому ПМt относит документ к той или градации релевантности. Отметим, что ниже рассматривается произвольное число градаций релевантности. Это позволяет оперировать как с “истинной”, так и воображаемой релевантностью, получаемой введением фиктивных подградаций. Последний прием позволяет учесть неравномерность распределений документов внутри частей списков (ранжировок), соответствующих одной градации. С другой стороны, этот прием в действительности лишь усложняет техническую сторону, не привнося ничего нового в результаты.
Итак, будем считать, что релевантность r имеет R градаций (рангов) и что большей релевантности соответствует меньший ранг. Назовем r-документом документ, относящийся к r–й градации релевантности. Если R = 2, то r = 1 интерпретируется как “релевантный”, а r = 2 как “нерелевантный”. В этом случай списки поисковых машин содержат только те документы, которые были опознаны как релевантные. В случае R > 2 порог отсечения обычно несколько выше, чем R–1. Однако в любом случае релевантность — только один из факторов, определяющих актуальное обрезание списка. Список может быть обрезан значительно раньше, если он слишком длинный. В свою очередь, порог по длине списка может определяться загруженностью ПМ. Когда ПМ сильно загружена, длинный список — это буквально несколько документов. Единственное, что не учитывает ПМ, принимая решение прервать или продолжить поиск, — это возможности пользователя–человека, заведомо не готового просматривать сотни документов [2].
2. Совпадающие базы
Начнем с (модельного) допущения, что базы всех ПМ идентичны. Случай пересекающихся баз будет рассмотрен в главе 4. Пусть каждой ПМ сопоставлена вероятностная матрица ![]() , где
, где ![]() — вероятность того, что ПМt опознает i-документ как. j-документ. Каждая база состоит из
— вероятность того, что ПМt опознает i-документ как. j-документ. Каждая база состоит из ![]() документов, где nr — число r-документов. Тем самым ПМt опознает
документов, где nr — число r-документов. Тем самым ПМt опознает ![]() документов как
документов как ![]() .
.
Рассмотрим списки, выданные двумя поисковыми машинами: ПМv и ПМw. Как показано в Приложении 1, вероятность того, что два случайных подмножества Yv и Yw “универсального ” множества Y0 содержат m общих объектов, описывается гипергеометрическим распределением:
| (1) |
где Ni — число объектов в Yi и m = 0, 1, …, min(Nv, Nw). Из (1) очевидным образом следует (Приложение 2), что для каждой градации релевантности r распределение общих документов является биномиальным
|
(где m = 0, 1, …, nr) и математическое ожидание числа общих i–документов, опознанных двумя поисковыми как j–документы, равно
|
В частности, ожидаемое число j– документов, верно опознанных обеими ПМ, равно
|
В свою очередь, математическое ожидание общего числа верно опознанных документов
|
С другой стороны, ожидаемое число документов, опознанных ПМv как j–документы
| (2) |
включая
| (3) |
верно опознанных j-документов.
3. Характеристики распределений документов
Рассмотрим следующие характеристики распределений документов.
Ожидаемая доля общих документов, опознанных одновременно ПМv и ПМw как j-документы, среди всех документов, опознанных ПМv как j- документы
| (4) |
Ожидаемая доля верно опознанных документов среди всех общих документов, опознанных обеими ПМ как j- документы
| (5) |
Кроме того, полезной характеристикой является доля верно опознанных общих документов среди документов, опознанных ПМv как j- документы
|
Понятно, что ![]() ,
, ![]() и
и ![]() . Последние две характеристики (b и g) отражают эффективность поиска в терминах общих документов, тогда как a просто характеризует распределение как верно, так и ошибочно опознанных общих документов для двух ПМ.
. Последние две характеристики (b и g) отражают эффективность поиска в терминах общих документов, тогда как a просто характеризует распределение как верно, так и ошибочно опознанных общих документов для двух ПМ.
Наконец, введем характеристику эффективности отдельной ПМ. Ожидаемая доля верно опознанных документов среди всех документов, опознанных как j- документы
| (6) |
В частности, если R=2, формула (6) есть ни что иное как формула для широко используемой меры точности (precision) поиска. Напомним, что (как всегда, для случая бинарной релевантности) для описания эффективности поиска массово используются две характеристики: P-точность (precision), равная доле истинно релевантных документов среди всех найденных (опознанных как релевантные), и R-точность (recall), равная доле найденных релевантных документов среди всех релевантных документов, входящих в базу. (Подробнее о мерах эффективности см. безусловно уникальное руководство по теории поиска информации [5], появившееся без малого четверть века назад и при этом не только не утратившее актуальности, но и представляющее в явном виде подходы, которые сегодня еще только начинают осознаваться. На русский язык, к сожалению, эта книга не переведена.)
4. Пересекающиеся базы
Выше мы рассмотрели случай, когда базы обеих ПМ совпадают. Теперь положим, что базы случайным образом пересекаются и доли общих документов в Xv и Xw
|
Пусть ![]() — число r- документов в Xt, а
— число r- документов в Xt, а ![]() — число общих r- документов ПМv и ПМw. Тогда в среднем
— число общих r- документов ПМv и ПМw. Тогда в среднем 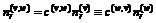 и
и
|
И среднее число верно опознанных j- документов
|
В результате, формулы (2) и (3), не содержащие ‘com’-компонент, останутся без изменений. Далее, понятно, что если исходное выражение содержит ‘com’-компоненту только в числителе (знаменателе), то множитель c(v,w) появится в этой части выражения. Если же ‘com’-компоненты одновременно присутствуют и в числителе и в знаменателе, выражение останется без изменений. Тем самым, применительно к характеристикам распределений документов (4)–(6), c(v,w) появится в (4), но не появится в (5) и (6).
5. Условие выполнения свойства общих документов
Общепринятая формулировка свойства общих документов (СОД) звучит следующим образом: пересечение списков документов, извлеченных из интернета разными ПМ, выше среди истинно релевантных документов, чем среди истинно нерелевантных. В действительности это достаточно нечеткая формулировка, поскольку из нее не ясно, идет ли речь о числе документов или о долях, а если долях, то долях от одноименных документов в базе или от документов, попавших в список. Забавно, что в как бы теоретической работе [7] СОД обрело гордое название Гипотезы (Overlap Hypotesis) и в таком качестве используется.
Как часто бывает, одни и те же наблюдения приводят к, на первый взгляд, взаимоисключающим формулировкам, а иногда и взаимоисключающие формулировки представляют в дествительности эквивалентные утверждения. В терминах введенных ранее характеристик СОД звучит очень просто: для каждой градации релевантности доля верно опознанных документов выше среди общих документов, чем в любом из списков:
|
(т. е. для обеих t = v, w) для каждой градации j, представленной в списках, извлеченных ПМv и ПМw.
Как следует из (4) и (5), мы имеем систему из 2R неравенств с 2R(R–1) независимыми переменными pij:
|
Она выполняется, если верно  и хотя бы для одного i имеет место
и хотя бы для одного i имеет место ![]() . Это достаточное условие СОД. Заметим, что в случае бинарной релевантности (R=2) число переменных равно числу неравенств и названное условие также является необходимым.
. Это достаточное условие СОД. Заметим, что в случае бинарной релевантности (R=2) число переменных равно числу неравенств и названное условие также является необходимым.
Таким образом, СОД выполняется, если диагональные элементы матриц P(t) максимальны в столбцах, т. е. вероятность быть опознанным как r–документ наиболее высока для документов, таковыми и являющихся.
Если только первые R* из R градаций релевантности попадают в список, СОД справедливо для первых R* столбцов матриц P(t). В частности, если R=2, то списки содержат только те документы, которые опознаны как релевантные (R*=1). И в этом случае наша формулировка СОД идентична общепринятой.
Итак, для бинарной релевантности условие СОД является необходимым и достаточным, а две формулировки СОД совпадают.
(Еще одна формулировка СОД приведена в Приложении 3.)
Выполнение СОД не означает высокого качества опознания документов. Более того, СОД может выполняться при сколь угодно низком качестве опознания. Например, СОД имеет место для матриц типа 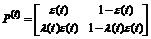 , где
, где ![]() и вероятность верного опознания релевантных документов — сколь угодно малая
и вероятность верного опознания релевантных документов — сколь угодно малая ![]() .
.
Очень маловероятно, чтобы СОД не выполнялось. Однако, как видим, СОД может выполняться исключительно как следствие высокой вероятности верного опознания малорелевантного документа. В частности, это может быть сопряжено с чрезмерной требовательностью в опознании высокорелевантных документов и опознанием их как документы меньшей релевантности.
Следствием СОД является ![]() . Действительно, согласно СОД,
. Действительно, согласно СОД, 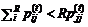 . Тогда
. Тогда ![]() . С другой стороны
. С другой стороны 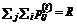 . Тем самым,
. Тем самым, ![]() , т. е.
, т. е. ![]() .
.
Как было показано в главе 4, переход от случая идентичных баз к случаю пересекающихся баз не влечет изменений в (5) и (6). Поскольку условие СОД формулируется как раз в терминах (5) и (6), условие выполнения СОД одинаково для случая общей базы и случая пересекающихся баз.
Литература
1. Dwork, C., Kumar, R., Naor, M., Sivakumar, D.: Rank Aggregation Methods for the Web. WWW10 (20–622
2. Jansen, B., Spink, A., Saracevic, T. Real life, real users, and real needs: A study and analysis of user queries on the web. Information Processing and Management, 36(20
3. Katzer, J., McGill, M., Tessier, J., Frakes, W., DasGupta, P.: A study of the overlap among document representations. Information Technology: Research and Development. Vol.2, (19–274
4. Lee, J. H.: Analyses of Multiple Evidence Combination. Proceedings of the 20th Annual International ACM–SIGIR Conference (19–276
5. van Rijsbergen, C. J. Information Retrieval. 1979.
6. Saracevic, T., Kantor, P.: A study of information seeking and retrieving. III. Searchers, searches, overlap. Journal of the American Society for Information Science. Vol. 39, No–216
7. Zhang, J. et al.: Improving the Effectiveness of Information Retrieval with Clustering and putational Linguistics and Chinese Language Processing. Vol. 6, No–125
Приложение 1. Пересечение выборок
Пусть Y0 — универсальное множество, содержащее N0 объектов, а {Yt} (t = 1,…,T) — его независимые случайные подмножества (выборки). Объем выборки Yt равен Nt. Рассмотрим рекурсивную процедуру получения распределений для пересечений выборок. Пусть G(T–1)(l) — распределение l (0 £ l £ N0) общих объектов для T–1 выборки. На очередном шаге произведем случайным образом из Y0 выборку объемом NT и, используя распределение G(T–1)(l), построим распределение G(T–1)(l) для T выборок.
Пусть k — число общих объектов T–1 выборки. Понятно, если l — число объектов, общих для этих T–1 выборки и T–й выборки, то l £ k и l £ NT. Число вариантов выбора l из k равно ![]() . Остальные NT–l объектов T–й выборки входят в число N0–k объектов, не являющихся общими для полученных на предыдущем шаге T–1 выборки. Т. е. число вариантов выбора этих объектов
. Остальные NT–l объектов T–й выборки входят в число N0–k объектов, не являющихся общими для полученных на предыдущем шаге T–1 выборки. Т. е. число вариантов выбора этих объектов ![]() .
.
Таким образом,
|
И тем самым вероятность получить l общих объектов для T выборок объемом N1, …, NT из универсального множества объемом N0 равна
|
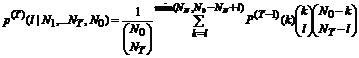
Обозначим эту вероятность через p(T)(l).
Начальные распределения
|
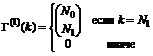 и
и откуда
|
и
| (1) |
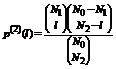
где ![]() . (Заметим, p(T)(l) — асимметрично усеченное симметричное распределение.)
. (Заметим, p(T)(l) — асимметрично усеченное симметричное распределение.)
Таким образом, математическое ожидание для общих объектов двух выборок
|
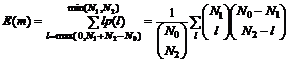
Так как для k>0 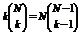 ,
,
|
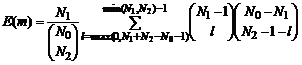
Поскольку для M £ Z ![]() , ожидаемое число общих объектов двух выборок определяется простой формулой
, ожидаемое число общих объектов двух выборок определяется простой формулой
|
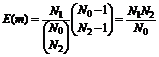
По индукции, ожидаемое число общих объектов для T выборок равно ![]() .
.
Поскольку нашей целью является качественная картина, а не технические детали, мы будем рассматривать исключительно пересечения двух выборок. Случай T>2, когда пришлось бы рассматривать объекты, входящие ровно в 2 выборки, в 3 выборки, и т. д., лишь усложняет рассмотрение, не привнося ничего качественно нового.
Приложение 2. Распределение общих документов
Положим, ПМv и ПМw опознают градации релевантности независимо (это весьма сильное допущение, справедливое разве что в случае, когда одна ПМ назначает релевантности по частотам входящих в запрос терминов, а другая выполняет поиск с использованием онтологий). Тогда
|
где ![]()
Тогда из (1)
|
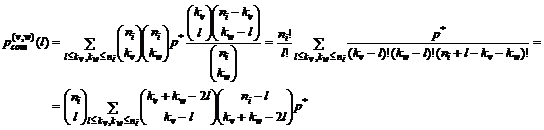
Обозначим ![]() и
и ![]() . Тогда
. Тогда
|
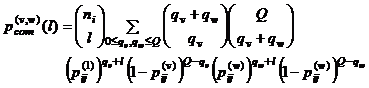
Поскольку ![]() , имеем
, имеем
|
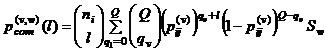
где
|
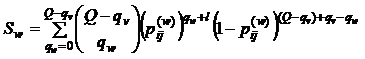
Последняя сумма равна
|
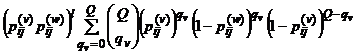
Сумма в последней формуле есть биномиальное выражение
|
И тем самым для двух ПМ распределение числа общих документов на [0, ni] есть
|
Приложение 3. Общая база. Агрегированные градации релевантности
Вместо отдельных градаций релевантности от 1-й до r-й включительно рассмотрим их агрегат, т. е. “£r- документы”. Это соответствует, например, ситуации воображаемой бинарной релевантности, когда порог релевантности берется достаточно низким (близким к R, обычно равным R–1) и все документы, релевантность которых не ниже этого порога, считаются релевантными, а документы меньшей релевантности — нерелевантными (обычно действительно такими и являющимися, т. е. имеющими релевантность R).
Итак, всем документам, релевантность которых не выше r, назначим релевантность 1, а документам релевантности i > r — релевантность i – r + 1. Теперь вместо матрицы ![]() получим матрицу
получим матрицу ![]() , в которой
, в которой
|
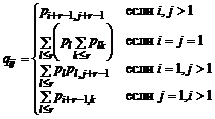
где pl — условная вероятность ![]() .
.
Как и P, Q — вероятностная матрица. Если заменить ‘p’ на ‘q’, к ней применимы формулы (4)–(6). Тогда условием СОД для Q является  . Как СОД для Q зависит от СОД для P? Ясно, если j>1, СОД для P влечет СОД для Q, поскольку
. Как СОД для Q зависит от СОД для P? Ясно, если j>1, СОД для P влечет СОД для Q, поскольку ![]() ,
, ![]() для i>1, и q1j есть взвешенное среднее
для i>1, и q1j есть взвешенное среднее ![]() (1£l£r), т. е. не превосходит
(1£l£r), т. е. не превосходит 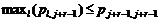 . Та как
. Та как ![]() и
и ![]() ,
,
![]() .
.
Таким образом, если j=1, достаточное условие СОД есть ![]() для всех l£r и m>r. Более обще, достаточное условие выглядит так. Пусть объединяются градации с r1–й по r2–ю. Пусть в матрице P выбрана подматрица P’ Ì P, состоящая из столбцов P с r1–й по r2–й. СОД имеет место, если сумма по любой строке l (r1 £ l £ r2), пересекающей главную диагональ P, больше суммы по любой строке, не содержащей диагональных элементов P.
для всех l£r и m>r. Более обще, достаточное условие выглядит так. Пусть объединяются градации с r1–й по r2–ю. Пусть в матрице P выбрана подматрица P’ Ì P, состоящая из столбцов P с r1–й по r2–й. СОД имеет место, если сумма по любой строке l (r1 £ l £ r2), пересекающей главную диагональ P, больше суммы по любой строке, не содержащей диагональных элементов P.
