

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 519.24
,
Государственный университет аэрокосмического приборостроения,
Высшая школа менеджмента Санкт-Петербургского государственного университета, г. Санкт-Петербург
Прогностические модели экономических временных рядов
Рассматриваются два типа прогностических моделей: модель множественной регрессии и регрессии на выборочные главные компоненты ряда. В первом случае рассматривается вопрос о построении лучшей регрессии и критерии применимости. Во втором – рассматривается использование оценок наименьшего риска и предлагается критерий применимости модели.
Задача прогнозирования случайных величин, составляющих экономические временные ряды (ЭВР), в настоящее время решается, главным образом, посредством построения соответствующих статистических прогностических моделей. Задача, решаемая этими моделями, состоит в том, чтобы уменьшить степень неопределенности, возникающую из-за естественного разброса величин, составляющих ЭВР. В конечном счете, речь идет о том, чтобы получить более узкие доверительные интервалы условного распределения, получаемого посредством прогностической модели, по сравнению с доверительными интервалами, которые можно получить непосредственно из оценок параметров распределения (предположительно нормального) случайных величин.
1. Модели множественной регрессии. Основная проблема, возникающая в прогнозировании ЭВР, связана с тем, что эти ряды во многих случаях характеризуются нестационарностью [3]. Тем не менее, основной упор в построении прогностических моделей делается на модели множественной регрессии вида [6]
yi = a0 + a1xi1+ a2xi2+…+ akxik + ei, (1)
где y - предсказываемая величина; x1, x2,… xk - предикторы (регрессоры); e - погрешность регрессионной модели; a'=(a0,a1,a2,…,ak) - вектор параметров регрессии (dima=k+1); ' - знак транспонирования. Индекс i =1,2,…,N (N - длина ЭВР или объем выборки) в равенстве (1) имеет формальный (порядковый) смысл, его значение соответствует, например, номеру строки выборочной матрицы X (см. ниже) значений предикторов, используемой в оценке вектора параметров регрессии [6, 11]. Сопоставление этого индекса временному отсчету t неоднозначно и зависит от характера модели. Так, например, если для yi значению i соответствует значение t, то для xij (j=1,2,…,k) i будет соответствовать значение t-hj. При этом для сдвигов (hj) выполняется hj³1, что, собственно, и делает модель (1) прогностической.
Многие вопросы, связанные с моделями вышеуказанного типа, достаточно хорошо освещены как в специальной математической литературе, именуемой регрессионным анализом, так и в экономической – именуемой эконометрикой.
Требование стационарности ЭВР, то есть статистической устойчивости стохастических элементов модели (1), прежде всего, предъявляется к моделям авторегрессии и к моделям смешанного типа, включающим в число предикторов и предшествующие значения самого прогнозируемого ЭВР (значения y со сдвигом). Однако то, что модель типа (1) дает прогноз на один шаг вперед, зачастую и позволяет глядеть "сквозь пальцы" на фактическую нестационарность, так как для следующего шага прогноза снова делается оценка параметров модели и дисперсии погрешности модели. Отдавая должное, отметим, что в литературе по эконометрике немало внимания уделяется гетероскедастичности - нестационарности дисперсии, несомненно, препятствующей адекватной оценке доверительных интервалов условного распределения (прогноза), однако нестационарность среднего значения нередко представляет собой не менее существенную проблему.
В задаче построения наилучшей регрессии основную роль играет остаточная сумма квадратов ![]() , которая традиционно обозначается англоязычной аббревиатурой RSS – в регрессионном анализе [11] и ESS – в эконометрике [6]. Предположим, что реализован алгоритм последовательного отбора (k =1,2,3,…) предикторов по критерию minRSSk, тогда несмещенная оценка дисперсии e –
, которая традиционно обозначается англоязычной аббревиатурой RSS – в регрессионном анализе [11] и ESS – в эконометрике [6]. Предположим, что реализован алгоритм последовательного отбора (k =1,2,3,…) предикторов по критерию minRSSk, тогда несмещенная оценка дисперсии e –
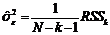 (2)
(2)
будет также минимизирована на каждом шаге отбора. Кроме того, эта оценка может служить также и критерием остановки алгоритма, так как уменьшение ![]() остановится на некотором шаге из-за увеличения числа предикторов k (см. (2)).
остановится на некотором шаге из-за увеличения числа предикторов k (см. (2)).
Не менее удобен в этом смысле и скорректированный коэффициент множественной корреляции или скорректированной детерминации ![]() с той лишь разницей, что последний максимизируется на каждом шаге отбора и перестанет расти при достижении некоторого уровня.
с той лишь разницей, что последний максимизируется на каждом шаге отбора и перестанет расти при достижении некоторого уровня.
С RSSk связан также немаловажный содержательный момент, касающийся вопроса о том, является ли полученная в результате прямого отбора предикторов регрессия наилучшей. Введем обозначение – Dk=RSSk–1–RSSk. Тогда при условии безальтернативного выбора лучшего (в смысле критерия) предиктора на каждом шаге отбора и выполнении цепочки неравенств [7]
D1³D2³…³Dk (3)
результат утвердительный. Нарушение же цепочки неравенств (3) на одном из шагов отбора означает, что распределение предиктора, выбранного на этом шаге, не подчиняется нормальному закону распределения и его включение может испортить прогноз. Здесь подразумевается, что сама прогнозируемая величина y распределена нормально.
Модель (1) имеет смысл при условии выполнения неравенства
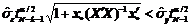 , (4)
, (4)
где 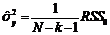 несмещенная оценка дисперсии y; X – выборочная, размерности N´(k+1), матрица значений предикторов с добавленным (первым) столбцом единиц (см. [6], [11]); (1,x1*, x2*,… xk*)=x*, где x1*, x2*,…,xk* – предикторы по которым осуществляется прогноз;
несмещенная оценка дисперсии y; X – выборочная, размерности N´(k+1), матрица значений предикторов с добавленным (первым) столбцом единиц (см. [6], [11]); (1,x1*, x2*,… xk*)=x*, где x1*, x2*,…,xk* – предикторы по которым осуществляется прогноз; ![]() и
и ![]() – квантили распределения Стьюдента при уровне значимости a и числах степеней свободы N–1 и N–k–1, соответственно. В случае, когда N превосходит k на порядок, различие между
– квантили распределения Стьюдента при уровне значимости a и числах степеней свободы N–1 и N–k–1, соответственно. В случае, когда N превосходит k на порядок, различие между ![]() и
и ![]() мало и неравенство (4), несомненно, имеет место. Следовательно, (4) следует проверять лишь в случаях, когда k приближается к N. В данном контексте отметим, что неравенство (4) означает сужение (1–a)100%-го доверительного интервала для значения y за счет перехода к условному распределению, при условии x=x*. Эта, на первый взгляд, тривиальная деталь, с одной стороны, является сущностью прогностической деятельности, а с другой, игнорируется основной массой вышеупомянутой литературы.
мало и неравенство (4), несомненно, имеет место. Следовательно, (4) следует проверять лишь в случаях, когда k приближается к N. В данном контексте отметим, что неравенство (4) означает сужение (1–a)100%-го доверительного интервала для значения y за счет перехода к условному распределению, при условии x=x*. Эта, на первый взгляд, тривиальная деталь, с одной стороны, является сущностью прогностической деятельности, а с другой, игнорируется основной массой вышеупомянутой литературы.
2. Модель на основе выборочных главных. компонент временного ряда (метод "гусеница"). Существенно более корректный подход к проблеме нестационарности представляет собой использование скользящего среднего [3]. При этом появляются различные возможности в выборе направления развития прогностических моделей. Одно из направлений базируется на выборочных главных компонентах временных рядов и, в частности, разработанном в СПбГУ методе ²гусеницы² [4], которому, однако, предшествовало несколько работ достаточно близких по своей идеологии [1,2,8].
Суть метода ²гусеницы² состоит в том, чтобы считать отрезок временного ряда фиксированной длины k случайным вектором размерности k. При этом центрирование и нормирование каждой компоненты производится по выборке, образованной сдвигами. Предложенный авторами [4] анализ выборочных главных компонент вызвал большой интерес, однако схема прогноза, построенная в [4], дает прогноз только на один шаг.
Рассмотрим схему прогноза, которая отличается от метода ²гусеницы² тем, что центрирование и нормирование осуществляется для каждого вектора по собственным компонентам, то есть каждый вектор есть вектор нормированных отклонений от скользящего среднего.
Такой подход приводит к регрессионной модели y=Fa+e, где y - вектор отклонений от скользящего среднего значения ![]() (j=1,…,m, m - число сдвигов) интервала длины k, нормированных на стандартное отклонение того же интервала sj; F - матрица размерности k´n, столбцы которой есть собственные векторы выборочной автокорреляционной матрицы C, отвечающие первым n в порядке убывания собственным значениям l1,…,ln матрицы C согласно проверяемой гипотезе [5] Но:l1>l2>…>ln+1=ln+2=…=lM M=min(m,k), m=N-k+1; компоненты вектора a в данном контексте называются выборочными главными компонентами временного ряда. Выбор k согласно [4] следует осуществлять так, чтобы m и k отличались не более чем на единицу. При нечетном N можно сделать m=k.
(j=1,…,m, m - число сдвигов) интервала длины k, нормированных на стандартное отклонение того же интервала sj; F - матрица размерности k´n, столбцы которой есть собственные векторы выборочной автокорреляционной матрицы C, отвечающие первым n в порядке убывания собственным значениям l1,…,ln матрицы C согласно проверяемой гипотезе [5] Но:l1>l2>…>ln+1=ln+2=…=lM M=min(m,k), m=N-k+1; компоненты вектора a в данном контексте называются выборочными главными компонентами временного ряда. Выбор k согласно [4] следует осуществлять так, чтобы m и k отличались не более чем на единицу. При нечетном N можно сделать m=k.
Основное предположение, непосредственно связанное с Но, состоит в том, что компоненты вектора e считаем некоррелированными, то есть ковариационная матрица e равна Se=se2I. След trC=k, следовательно [9]
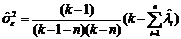 , (5)
, (5)
где ![]() (i=1,2,…,n) собственные значения несмещенной оценки С.
(i=1,2,…,n) собственные значения несмещенной оценки С.
Эта статистическая модель позволяет осуществлять прогнозирование k* (k*<k/2) последующих значений yj* (j=1,…,k*), составляющих k*-мерный вектор
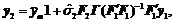 (6)
(6)
где F1 составлена из первых (k-k*) строк F, а F2 - из последних k* строк F; y1 - вектор центрированных и нормированных значений ![]() , i=N-k+1+kf,..,N (k-k* последних значений ЭВР); 1 - вектор размерности k* все компоненты которого равны единице; Г=diag(g1g2…gn) матрица, снижающая квадратичный риск [10].
, i=N-k+1+kf,..,N (k-k* последних значений ЭВР); 1 - вектор размерности k* все компоненты которого равны единице; Г=diag(g1g2…gn) матрица, снижающая квадратичный риск [10].
Поясним несколько подробнее значения элементов матрицы Г в формуле (6). Оценки по методу наименьших квадратов (МНК) компонент вектора параметров прогностической модели 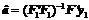 (коэффициентов разложения колебания по базису ai, i=1,…,n) являются несмещенными. Для минимизации риска целесообразно перейти к смещенным оценкам вида
(коэффициентов разложения колебания по базису ai, i=1,…,n) являются несмещенными. Для минимизации риска целесообразно перейти к смещенным оценкам вида 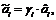 где
где ![]() - несмещенная МНК-оценка, а gi минимизирует квадратичный риск, то есть дисперсию этой оценки ri2=E
- несмещенная МНК-оценка, а gi минимизирует квадратичный риск, то есть дисперсию этой оценки ri2=E![]() (здесь E - знак математического ожидания). Взятие математического ожидания приводит это выражение к виду
(здесь E - знак математического ожидания). Взятие математического ожидания приводит это выражение к виду ![]() где
где ![]() - дисперсия оценки
- дисперсия оценки ![]() которая есть i-й элемент главной диагонали матрицы
которая есть i-й элемент главной диагонали матрицы ![]() Приравнивая производную ri2 по gi от этого выражения к нулю, получаем
Приравнивая производную ri2 по gi от этого выражения к нулю, получаем
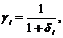 (7)
(7)
где 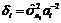 .
.
Проблема практического применения рассмотренных оценок состоит в том, что вместо значения 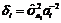 мы можем использовать лишь значение
мы можем использовать лишь значение ![]()
В [10] предлагается заменить неизвестное значение ![]() близким
близким ![]() , что приводит к квадратному уравнению относительно gi . В результате имеем
, что приводит к квадратному уравнению относительно gi . В результате имеем ![]() . В случае, когда значение
. В случае, когда значение ![]() (не di а
(не di а ![]() ) превышает
) превышает ![]() , в [10] предлагается считать gi=0. Заметим однако, что значение gi=0 приводит к величине риска ri2=
, в [10] предлагается считать gi=0. Заметим однако, что значение gi=0 приводит к величине риска ri2=![]() . Если предполагать,
. Если предполагать, ![]() »di, то простая проверка показывает, что при
»di, то простая проверка показывает, что при ![]() <di<1 значение
<di<1 значение ![]() приводит к величине риска ri2<
приводит к величине риска ri2<![]() , а при di³1 значение gi, полученное по формуле (7), приводит к величине ri2=
, а при di³1 значение gi, полученное по формуле (7), приводит к величине ri2=![]() (1-gi), что также меньше ri2=
(1-gi), что также меньше ri2=![]() .
.
Рассмотренная выше прогностическая схема дает доверительную полосу длиной k* и во многих случаях оказывается достаточно эффективной, в особенности, когда модель множественной регрессии не применима в силу каких-либо причин.
Останавливаясь на вопросе целесообразности применения этой прогностической схемы в первом приближении отметим, что неравенства (для j=1,…,k*) 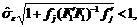 где fj – j-я вектор-строка F2 выполняются автоматически и, следовательно, надо проверить
где fj – j-я вектор-строка F2 выполняются автоматически и, следовательно, надо проверить
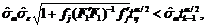 (8)
(8)
где ![]() – несмещенная оценка дисперсии элементов m-го вектора (скользящего отрезка), которая в левой части (8) выступает в роли масштабного множителя; h=k–n–1 (см. (5)). Остается некоторая неуверенность, связанная с колебаниями скользящего среднего, которая может быть преодолена тем, что "выигрыш" в снижении степени неопределенности, который дает неравенство (8), превосходит неопределенность, возникающую за счет колебаний скользящего среднего. Если предположить, что абсолютная величина пошаговых отклонений скользящего среднего распределена нормально, то возникает естественное желание, чтобы разность доверительных полос, размеры которых фигурируют в (8), не оказалась бы меньше величины
– несмещенная оценка дисперсии элементов m-го вектора (скользящего отрезка), которая в левой части (8) выступает в роли масштабного множителя; h=k–n–1 (см. (5)). Остается некоторая неуверенность, связанная с колебаниями скользящего среднего, которая может быть преодолена тем, что "выигрыш" в снижении степени неопределенности, который дает неравенство (8), превосходит неопределенность, возникающую за счет колебаний скользящего среднего. Если предположить, что абсолютная величина пошаговых отклонений скользящего среднего распределена нормально, то возникает естественное желание, чтобы разность доверительных полос, размеры которых фигурируют в (8), не оказалась бы меньше величины 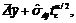 где
где ![]() – среднее значение абсолютной величины пошаговых отклонений скользящего среднего;
– среднее значение абсолютной величины пошаговых отклонений скользящего среднего; ![]() – несмещенная оценка дисперсии абсолютной величины пошаговых отклонений скользящего среднего; t – число степеней свободы оценки
– несмещенная оценка дисперсии абсолютной величины пошаговых отклонений скользящего среднего; t – число степеней свободы оценки ![]() , при условии, что пошаговый сдвиг равен k*. Другими словами, следовало бы потребовать выполнения
, при условии, что пошаговый сдвиг равен k*. Другими словами, следовало бы потребовать выполнения
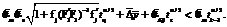 (9)
(9)
Несмотря на то, что (9) может вызвать некоторые возражения у педантичного читателя, тем не менее, это неравенство при условии его невыполнения является несомненным поводом для того, чтобы воздержаться от рассмотренной выше схемы прогноза или, по крайней мере, уменьшить значение k* до более разумных пределов.
В заключение следует отметить, что подобная прогностическая схема может быть сконструирована и на основе метода "гусеницы" в его исходном варианте. При этом в формуле (5) вместо ![]() будет стоять вектор в принципе различных средних значений скользящего отрезка и вместо величины
будет стоять вектор в принципе различных средних значений скользящего отрезка и вместо величины ![]() - матрица стандартных отклонений.
- матрица стандартных отклонений.
Замечание: Во многих случаях проверка Но может быть проигнорирована с принятием значения n=2, так как в случае наличия в исходном ЭВР некоторого основного колебания, последнее непременно будет отображено в двух (по аналогии с sin и cos) первых главных компонентах. Кроме того, проверку Но может заменить визуальный анализ графика выборочного спектра C. Учитывая (5) можно ограничиться вычислением лишь первых n собственных векторов и собственных значений, например, итерациями фон Мизеса.
Для прогностической модели множественной регрессии предложены критерии выбора наилучшей регрессии и принципиальной применимости модели. Построена прогностическая модель на основе регрессии на выборочные главные компоненты временного ряда с использованием оценок минимального риска и предложен критерий применимости этой модели.
СПИСОК ЛИТЕРАТУРЫ
1. Антоновский анализ по глобальному индексу вегетации / , , // Проблемы экологического мониторинга и моделирования экосистем.- СПб: Гидрометеоиздат, 1992. т. 14. - С. 153-172.
2. Антоновский многомерного статистического анализа для обнаружения структуры изменений во временных рядах данных экологических наблюдений / , , // Проблемы экологического мониторинга и моделирования экосистем. СПб: Гидрометеоиздат, 1993. т. 15. - С. 193-213.
3. Спектральный анализ временных рядов в экономике / К. Гренджер, М. Хатанака.- М.: Статистика, 1972.
4. Главные компоненты временных рядов: метод "Гусеница", под ред. и - СПбГУ, 1997.
5. Факторный анализ как статистический метод / Д. Лоули, А. Максвелл.- М.: Мир, 1980.
6. Магнус . Начальный курс: Учебник / , , .– М.: Дело, 2007.
7. Пичугин к отбору данных в задачах, связанных с регрессией / // Заводская лаборатория / Диагностика материалов, 2002. № 5. - С. 61-62.
8. Пичугин сезонных эффектов в задачах прогноза и контроля данных о приземной температуре воздуха / // Метеорология и гидрология, 1996. № 4. - С. 52-64.
9. К проблеме статистического контроля данных наблюдений за приземной температурой на отдаленных станциях / // Метеорология и гидрология, 2000. № 10. - С. 18-24.
10. Прикладная статистика: Исследование зависимостей: Справ. изд. / , , ; Под ред. . – М.: Финансы и статистика, 1985.
11. Себер Дж. Линейный регрессионный анализ / Дж. Себер. – М.: Мир, 1980.
