
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
И. А. СМИРНИТСКАЯ
Научно-исследовательский институт системных исследований РАН, Москва
Институт высшей нервной деятельности и нейрофизиологии РАН, Москва
СХЕМА УЧАСТИЯ ЦИНГУЛЯРНОЙ КОРЫ, БАЗОЛАТЕРАЛЬНОЙ МИНДАЛИНЫ И ГИППОКАМПА
В ПЕРЕОБУЧЕНИИ
Обсуждается возможность применения теории обучения с подкреплением (reinforcement learning, RL) в случае быстрого обучения: при отрицательном подкреплении или переобучении. Обсуждаются особенности представления функции значимости разными областями фронтальной коры. Предложена схема вычисления функции значимости совокупностью корковых областей, миндалины и гиппокампа.
Ключевые слова: обучение с подкреплением, значимость, отрицательное подкрепление, переобучение
Введение
Применение теории обучения с подкреплением (reinforcement learning, RL [1]) при моделировании задачи поведенческого выбора дает результаты, качественно согласующиеся с экспериментом [2]. Однако не всегда эта теория применима. Например, она не подходит в случае отрицательного (болевого) подкрепления.
Во-первых, потому, что обучение с подкреплением – это обучение методом проб и ошибок, а в случае, когда выбор состоит в отказе от действий, влекущих за собой болевое воздействие, метод проб и ошибок не подходит. В случае сильного болевого стимула обучение часто происходит после всего лишь однократного воздействия. Да и с чисто эволюционной точки зрения пробные действия неуместны в угрожающих жизни ситуациях.
Во-вторых, в нервной системе имеются специальные структуры, обрабатывающие сигналы о негативных воздействиях. В случае отрицательного подкрепления поведенческим выбором управляет миндалина [11].
Еще одно соображение, указывающее на недостаточную адекватность теории обучения с подкреплением – скорость обучения. Теория RL требует сотен (и даже тысяч) итераций. В реальности животному для обучения нужно гораздо меньше.
И, наконец, наиболее ощутимый аргумент, определяющий возможность применения RL – рассмотрение реальных сетей мозга, участвующих в обучении, и операций, которые можно приписать управляющим структурам.
Модификация теории обучения с подкреплением
Попробуем найти модификацию теории обучения с подкреплением, которую можно применить для случая быстрого обучения.
Рассмотрим поведенческую задачу, в которой животному предоставлен бинарный выбор типа: совершать, или не совершать действие при предъявлении некоего сенсорного стимула (go/no-go задачи). Если животное совершает действие и получает награду, то говорят, что предъявлен значимый сенсорный стимул.
Понятие значимости (value) занимает центральное место в теории RL. С точки зрения этой теории в итоге обучения животное научается выбирать действие, обладающее наибольшей значимостью. Значимость каждого варианта выбора является функцией добытой в результате действия награды, и равна средней награде.
Обозначают:
s – сенсорный стимул,
a(t) – действия животного в момент времени t,
a1(t) – совершение действия (например, нажать на рычаг),
a2(t) – несовершение действия (воздержаться от нажатия на рычаг),
Характеристикой правильности выбора действия является Qt(a(s)) –значимость действия a при предъявлении сенсорного стимула s. Обозначим:
Qt (a) = Qt (a(s)),
Qt (a1) – значимость нажатия на рычаг,
Qt (a2) – значимость ненажатия на рычаг.
Кроме значимости действия, вводят значимость стимула Vt (s), которая в нашем случае равна сумме значимостей обоих возможных действий.
Vt (s) = Qt (a1) + Qt (a2).
Животное находит, какова значимость каждого действия в результате обучения. Значимость, найденная на каждом последующем шаге обучения, связана со значимостью, найденной на предыдыдущем шаге, итерационным соотношением [1]:
Qt (a) = Vt-1(s) + a[R t - Vt-1(s)], (1)
здесь Rt – награда (reward), полученная после каждого действия a(t).
Стоящую в квадратных скобках величину обозначают
d = Rt - Vt -1 (s) (2)
и называют ошибкой прогноза награды.
Вводим обозначение: a – шаг усреднения. Величину a выбирают не слишком маленькой, чтобы обеспечить достаточно быструю сходимость (1), но и не слишком большой, чтобы влияние каждой последующей награды было меньше найденного за предыдущее время среднего. В наших моделях ранее принималось a =0.1 [2].
Нейрофизиологи предприняли множество попыток нахождения соответствия нейронной активности различных структур мозга фигурирующим в теории RL переменным. Было обнаружено, что значимость сенсорного сигнала Vt (s) отображается активностью нейронов орбитофронтальной коры [5], значимость действия Qt (a) – активностью нейронов дорзолатеральной префронтальной коры [6,15,20], а активность дофаминергических нейронов соответствует ошибке прогноза значимости d [18], или, возможно, величина ad соответствует всему второму слагаемому формулы (1).
Пусть животному после предъявления стимула s нужно нажать на рычаг и получить награду. При ненажатии оно не получает ничего. В этом случае значимость сенсорного стимула равна значимости нажатия:
Vt (s) = Qt (a1) + Qt (a2) = Qt (a1).
Можно предположить, что обучение состоит в том, что при каждом нажатии на рычаг эффективность синапсов нейронов орбитофронтальной коры изменяется по формуле (1).
Более сложным классом поведенческих задач являются задачи переобучения, в которых животному сначала предлагают выучить, что после предъявления стимула надо нажать на рычаг, и после того, как оно твердо это выучит, внезапно меняют условие на противоположное – теперь награду дают при ненажатии.
Обеспечивающая это переучивание сеть должна включать блок, сравнивающий старую значимость предъявляемого стимула с новой значимостью, блок, выдающий сигнал ошибки, и блок, прибавляющий эту ошибку к старой значимости. В нашем случае, когда надо прекратить нажимать на рычаг, блок сигнала ошибки может, кроме того, еще и посылать запрещающий движение сигнал к исполнительному блоку.
Активность нейронов цингулярной коры пропорциональна ошибке прогноза награды [14]. Но это еще не означает, что именно в ней эта ошибка вычисляется. В работе [7] показано, что при удалении цингулярной коры ошибка прогноза продолжает где-то вычисляться, однако удаление коры ухудшает вычисление изменившейся значимости стимула.
Кроме орбитофронтальной коры, пропорциональный значимости сигнал находят в миндалине [12,16]. Анатомические работы свидетельствуют, что самые сильные из корковых связей миндалины – с вычисляющими значимость отделами орбитофронтальной коры [4] (в том числе с ростральной частью передней инсулярной коры [10]). Важно, что при исследовании запоминания запаховых последовательностей [17] обнаружено, что хотя значимость запоминается и в орбитофронтальной коре и в миндалине, миндалина раньше изменяет свою активность при изменении условий получения награды, чем орбитофронтальная кора.
Сейчас нет единого мнения о функции гиппокампа. Давнее и до сих пор не потерявшее актуальности предположение приписывает гиппокампу функцию сравнения [19]. Ошибка прогноза награды вычисляется на основе сравнения значимости найденной на основе предыдущего опыта с полученной (или неполученной) в настоящий момент наградой. Обеспечивающие такое сравнение связи гиппокампа с орбитофронтальной корой имеются [10]. Кроме того, имеются мощные двусторонние связи между гиппокампом и гиппокамповой формацией с одной стороны, и базолатеральным отделом миндалины с другой стороны [13]. Именно в базолатеральном отделе миндалины запоминаются структурированные задачи обучения [3]. Перерезка связей гиппокампа с базолатеральной миндалиной нарушает это обучение.
Мы предлагаем следующую схему взаимодействия структур старой и новой коры в режиме переобучения (рис. 1).
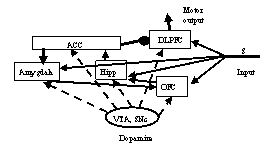

Рис. 1. Схема взаимодействия областей, вычисляющих значимость сенсорного стимула: ACC – передняя цингулярная кора, DLPFC – дорзолатеральная
прифронтальная кора, Amygdala – миндалина, hipp – гиппокамп, OFC –
орбитофронтальная кора, VTA, SNc – дофаминергические области.
Влияние ACC на DLPFC – тормозящее
На этой схеме:
1) блок гиппокамп-орбитофронтальная кора производит сравнение значимостей стимула старой и текущей;
2) блок гиппокамп-цингулярная кора выдает сигнал ошибки;
3) блок цингулярная кора-базолатеральная миндалина выдает сигнал пропорциональный новой значимости стимула;
4) блок базолатеральная миндалина-орбитофронтальная кора корректирует значимость стимула в орбитофронтальной коре;
5) блок цингулярная кора-дорзолатеральная кора меняет значимость действия, вытормаживая его [8] (все указанные изменения значимостей происходят только при наличии соответствующих изменений в двигательном поведении);
6) все изменения эффективности синапсов происходят под влиянием, и только при наличии дофамина.
На рис. 1 показаны только связи, обеспечивающие вышеописанные вычисления. Между всеми этими блоками имеются реципрокные связи. Но с учетом последовательности прохождения сигналов и силы влияния на вычисления сети в данном поведенческом контексте, здесь наиболее важны именно эти. Кроме того, даже указанные взаимодействия структур в реальности осуществляются не как одномоментные вычислительные действия, а как изменение циркулирующей активности.
Рассмотрим поведенческий опыт, в котором животному предлагается при подаче одного из двух сенсорных сигналов достать из кормушки вознаграждение, одинаковое по размеру, но поступающее с разной задержкой, большей и меньшей. Когда животное выучит, при каком сигнале можно скорее получить награду, условие опыта меняют на противоположное.
После того, как животное выучило прямую задачу, в орбитофронтальной коре будет представлена значимость обоих сигналов. На рис. 2 представлена условная схема взаимодействия корковых областей, гиппокампа и миндалины.
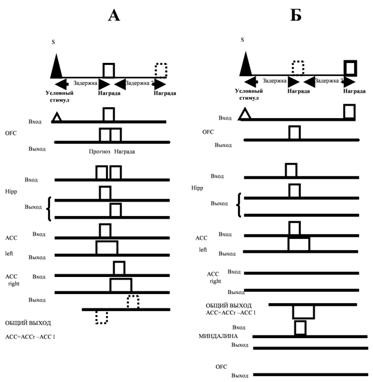
Рис. 2. Схема взаимодействия гиппокампа, корковых областей и миндалины
при переобучении: А – результат обучения: в орбитофронтальной коре представлен прогноз награды; Б – схема переобучения (обозначения те же, что и на рис. 1)
На рис. 2, А показан результат обучения: вычисление значимости условного сигнала, предсказывающего появление награды с малой задержкой. На рис. 2, Б показан ход переобучения. Ошибка прогноза находится вычитанием активности орбитофронтальной коры в последовательных временных интервалах. Это вычитание осуществляется гиппокампом, посылающим два последовательных сигнала значимости по отдельности в правую и левую цингулярную кору, и самой цингулярной корой, посылающей возбуждающие связи к тормозным интернейронам противоположного полушария. Далее сигнал от цингулярной коры идет на миндалину, которая вытормаживает оставшийся неподтвержденным прогноз награды орбитофронтальной корой.
Для нахождения ошибки прогноза награды в режиме переобучения можно применить ту же формулу (1). При резком изменении условий опыта животное обучается очень быстро. Можно учесть это изменением коэффициента a. А именно, в данном случае соображение, что при каждом новом прогоне опыта вклад текущей награды в вычисление новой значимости должен быть меньше предыдущей, не подходит. При таких кардинальных изменениях новое значение должно быть гораздо весомее предыдущих. Этого можно добиться изменением параметра усреднения a. Например, если для первоначального обучения a = a1 = 0.1, то для переобучения, a = a2 = 0.9.
Механизм, обеспечивающий требуемое усиление вклада текущей награды, имеется. Это влияние стресса, опосредованное выбросом норадреналина. Даян [21] пишет, что выброс норадреналина связан с «network reset», переобучением, происходящим, когда внешний сигнал неожиданно перестает соответствовать ранее выученной линии поведения. В базолатеральной миндалине имеется существенное количество бета адренорецепторов [22]. Их наличие обуславливает не только активацию миндалины при стрессе, но и усиливает синаптическую пластичность в связанной с миндалиной ростральной цингулярной коре [22]. Все это вместе и обуславливает больший вклад в обучение по сравнению с более рутинной внешней обстановкой. Формально это отражается увеличением параметра a и изменением знака награды R = –R.
Список литературы
1. , Барто с подкреплением. М.: Бином, 2011.
2. , , Мержанова выбора вознаграждения, на основе теории обучения по подкреплению. //Журн. высш. нервн. деят., 20Р.133-143.
3. Blundell P, Hall G, Killcross S. Lesion of the basolateral amygdale disrupt selective aspects of reinforcer representation in rats.//J. Neurosc., 20Р. 9018–9026.
4. Höistad M, Barbas, H. Sequence of information processing for emotions through pathways linking temporal and insular cortices with the amygdale.// Neuroimage. 2008, 40(3). Р. 1016–1033.
5. Hosokawa, T., Kato, K., Inoue, M., & Mikami, A. Neurons in the macaque orbitofrontal cortex code relative preference of both rewarding and aversive outcomes. //Neuroscience Research., 20–445.
6. Kennerly S. W, Wallton M. E. Decision making and reward in frontal cortex: Complementary evidence from neurophysiological and neuropsychological studies.// Behav. Neurosc., 2011. V. Р. 297–317.
7. Kennerley S. W,Walton M. E, Behrens T. E, Buckley M. J., Rushworth M. F. Optimal decision making and the anterior cingulate cortex. //Nat. Neurosc., 20Р.940-47.
8. Medalla, M, Barbas, H. Anterior cingulate synapses in prefrontal areas 10 and 46 suggest differential influence in cognitive control.// J Neurosci. 20Р. 16068–16081.
9. Miller E. J., Saint Marie R. L., Breier M. R., Swerdlow N. R. Pathways from the ventral hippocampus and caudal amygdala to forebrain regions that regulate sensorimotor gating in the rat.// Neurosci., 20Р. 601–611.
10. Ongur D, Price J. L., The organization of networks within the orbital and medial prefrontal cortex of rats, monkeys and humans. //Cerebral Cortex, 20Р. 206-219.
11. Paré D., Quirk G. J., Ledoux J. E. New vistas on amygdala networks in conditioned fear. //J. Neurophysiol, 20Р. 1–9.
12. Paton J. J, Belova M. A., Morrison S. E., Saltzman C. D. Primite amygdala represents positive and negative value of visual stimuli during learning.//Nature, 20Р. 865-870.
13. Pitkänen A., Pikkarainen M., Nurminen N., Ylinen A. Reciprocal connections between the amygdala and the hippocampal formation, perirhinal cortex, and postrhinal cortex in rat. //A review. Ann N Y Acad Sci., 2000, Jun. 911. Р. 369-391.
14. Polli F. E., Barton J. J.S., Thakkar K. N., Greve D. N., Goff D. C., Rauch S. L., Manoach D. S. Reduced error-related activation in two anterior cingulate circuits is related to impaired performance in schizophrenia.// Brain, 20Р. 971-986.
*****shworth M. F., Behrens T. E. Choice, uncertainty and value in prefrontal and cingulate cortex. //Nat. Neurosci, 2008, Apr. 11(4). Р. 389-397.
16. Saltzman C. D. , Fusi S. Emotion, cognition, and mental state representation in amygdala and prefrontal cortex. //Annu Rev Neurosci, 20Р. 173–202.
17. Schoenbaum G., Chiba A. A, Gallagher M. Neural encoding in orbitofrontal cortex and basolateral amygdala during olfactory discrimination learning. //J. Neurosc., 19Р. .
18. Shultz W. Predictive reward signal of dopamine neurons.// J. Neurophysiol., 19Р. 1-27.
19. Vinogradova O. S. Hippocampus as comparator: role of the two input and two output systems of the hippocampus in selection and registration of information.// Hippocampus. 20Р. 578-598.
20. Wallis J. D., & Kennerley S. W. Heterogeneous reward signals in prefrontal cortex. //Current Opinion in Neurobiology, 20Р. 191–198.
21. Dayan P, Yu A. Phasic norepinephrine: a neural interrupt signal for unexpected events.// Network, 20Р.335-350.
22. Holloway-Erickson C. M., McReynolds J. R., McIntyre C. K., Memory-enhancing intra-basolateral amygdale infusions of clenbuterol increase Ar and CaMKIIα protein expression in the rostral anterior cingulate cortex. Front. In Neurosc. 19 April 2012.
