

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Опыт разработки Интернет-приложения «Система дистанционного обучения».
, ,
, ,
Аннотация
В данной работе предлагается технология обработки входных и создания выходных документов в формате HTML. Эта технология позволяет обрабатывать достаточно произвольные входные документы и изменять выходные формы независимо от программ. Последнее облегчает работу дизайнеру, который с одной стороны не скован разработчиками, а с другой имеет дело с форматом XML, который близок к HTML – основному рабочему материалу. Еще одна предлагаемая технология позволяет построить библиотеку классов на основе схемы реляционной базы данных. Она позволяет уменьшить количество кода, осуществляющего операции с базой данных и сконцентрировать внимание разработчиков на содержательных аспектах системы. Данные технологии были применены при создании Интернет-приложения «Система Дистанционного Обучения».
Введение
В последние годы одним из быстроразвивающихся и популярных видов приложений являются Интернет-приложения (или Web-приложения). Они представляют собой «активные» Web-сервера, которые предоставляют не только статическую информацию, но и позволяют пользователям вести диалог с системой, предоставляя информацию для браузера. Такие системы имеют преимущества перед традиционными системами типа «клиент-сервер»:
1. Тонкий клиент.
2. Отсутствие инсталляции на клиенте.
3. Легкость модернизации (смены версии), вплоть до полной замены пользовательского интерфейса.
4. Независимость от платформы клиента (аппаратного обеспечения, операционной системы и т. д.).
5. Возможность работы как в Intranet, так и в «большом» Internet.
В данной статье описана техническая сторона Системы Дистанционного Обучения [2], далее СДО. Общая схема системы:
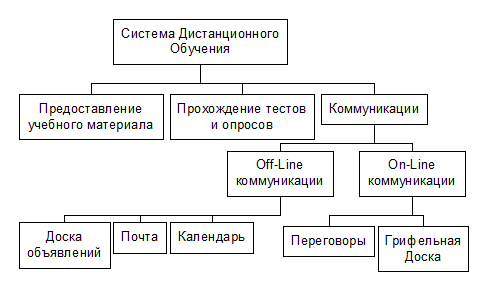
Минимальной единицей учебного материала является «страница» (не путать с печатной страницей). Отдельные страницы объединяются в модули, а модули объединяются в курс. Такая структура позволяет строить как очень большие, так и маленькие курсы.
Подготовка учебного материала осуществляется преподавателем-автором курса. Этот процесс осуществляется, например, в редакторе Microsoft Word. Автор разбивает весь материал на отдельные страницы, затем сохраняет их в формате HTML. При этом сам редактор экспортирует все внедренные графические изображения в виде отдельных GIF-файлов. Получившийся таким образом набор HTML и GIF файлов закачивается на сервер средствами системы.
1. Технологии вызова программ Web-сервером
На начальном этапе разработки Интернет-приложения стоит задача выбора основных системных компонент, которые будет использовать система. Нужно выбрать:
1. Web-сервер.
2. Технологию вызова программ Web-сервером.
3. Технологию связи с СУБД
4. Платформу (операционную систему).
5. Язык программирования.
6. Технологию межмашинного взаимодействия.
В следующей таблице приведены ограничения, который накладывает Web-сервер на способ вызова прикладных программ и на язык программирования, на котором эти программы написаны:
Web-сервер | Технология вызова программ | Язык программирования | |
1 | Любой | cgi | любой |
2 | Apache | servlets | java |
php-module | php | ||
perl-module | perl | ||
custom module | c++ | ||
isapi (частично) | c++ | ||
visual basic | |||
3 | IIS | isapi | c++ |
visual basic | |||
asp | vb script | ||
java script | |||
perl | perl |
Язык программирования совместно с операционной системой, под управлением которой работает и Web-сервер и прикладная программа, накладывают ограничение на СУБД, которую можно использовать:
Язык | Платформа | Технология связи с СУБД | СУБД | |
1 | c++ | win32 | odbc | любая |
любая | зависит от БД | * | ||
2 | perl | win32 | odbc | любая |
любая | зависит от БД | * | ||
3 | java | win32 | jdbc/odbc | любая |
любая | jdbc/private | * | ||
4 | php | win32 | odbc | любая |
любая | зависит от БД | * | ||
5 | visual basic | win32 | odbc | любая |
6 | vb script | win32 | odbc | любая |
7 | java script | win32 | odbc | любая |
В таблице символом (*) обозначен список из следующих СУБД:
1. Свободно распространяемые:
1.1. MySQL
1.2. PostgreSQL
2. Коммерческие:
2.1. Oracle
2.2. Informix
2.3. InterBase
2.4. Некоторые другие
Реальными альтернативами при выборе платформы являются следующие:
1. Win32 (Microsoft Windows 9x/NT).
2. Linux.
3. FreeBSD.
4. Sun Solaris.
Другие варианты Unix являются менее реальной альтернативой, хотя перенос системы на них выглядит чисто технической работой, впрочем, требующей времени.
При построении больших систем на первый план выходит требование масштабируемости – система должна обслуживать как несколько десятков, так и сотни, тысячи, а быть может даже и миллионы пользователей. В этом случае необходимо сделать выбор технологии межмашинного взаимодействия:
Технология | Платформы | |
1 | «чистый» TCP/IP | любая |
2 | CORBA | любая |
3 | DCOM | win32 |
При разработке данной системы выбор был сделан в пользу Web-сервера Apache, технологий вызова cgi/Apache module, языка программирования C++, платформ Win32/Linux, СУБД MySQL, TCP/IP в качестве технологии межмашинного взаимодействия. При этом упор делается на собственную библиотеку ServletContext, которая может быть адаптирована потенциально к любой технологии вызова программ Web-сервером (в первую очередь cgi и Apache module). Все программные модули используют эту библиотеку и, таким образом, с ее помощью могут работать со многими Web-серверами. Отдельные возможности этой библиотеки рассмотрены далее.
2. Объектно-ориентированный интерфейс к реляционной СУБД
В настоящее время все большую и большую популярность приобретают объектно-ориентированные СУБД [3]. Однако это направление достаточно молодое, терминология и основные принципы еще не устоялись, и зрелые реализации отсутствуют [1]. Однако желание заполучить объектно-ориентированный интерфейс велико. Одним из способов решения данной проблемы является создание такого интерфейса над ставшей уже традиционной реляционной СУБД.
В данной системе разработана технология, позволяющая преобразовать схему реляционной СУБД в набор классов и библиотека для работы с такими классами. Технология выглядит следующим образом:
1. На основании схемы базы данных, представляющей собой набор SQL-операторов, создающих структуру БД (DROP TABLE, CREATE TABLE) создаются два файла – schema. h и schema. cpp. В этих файлах каждой таблице соответствует один класс. Такой класс содержит переменные-члены (по одной переменной для каждого поля таблицы), но не содержит никаких функций.
2. Если для класса никакой дополнительной функциональности не требуется, то он остается в том виде, в каком его создала преобразующая программа. Если же необходима некоторая функциональность, то описывается (уже вручную) класс-наследник от автоматически созданного. В новом классе описываются необходимые функции и (если это необходимо) transient-переменные, которые не являются хранимыми. Значение таких переменных вычисляется после загрузки переменной на основании хранимых полей.
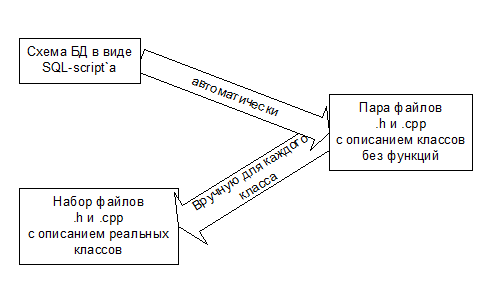
Поддерживается простейший вариант наследования, когда одна из таблиц является «родительской», а остальные – «дочерними». При этом классы автоматически формируются соответствующим образом.
3. Стандарт XML
Стандарт XML [8] - eXtensible Markup Language - разработан World Wide Web Consortium и предназначен для хранения структурированных документов в формате, независящем от прикладных программ, операционной системы, каналов передачи данных. Документ в формате XML представляет собой текст со вставленными в него тегами, которые несут дополнительную информацию о структуре документа. Стандарт XML – это упрощенный вариант SGML – чрезвычайно мощного инструмента, но достаточно сложного в реализации и потому до сих пор мало распространенного.
Наряду с собственно XML существует стандарт DOM [6] – Document Object Model – описывающий программный интерфейс (API – application programming interface) для работы со структурированными документами. В DOM документ представляет собой древовидную структуру, в которой каждый узел – это элемент XML-файла: текст, тег, комментарий, инструкция и т. д. Появление такого стандарта имеет большое значение, однако он имеет и некоторые недостатки – так как DOM является языково-независимым (существуют версии для C++, JAVA и т. д.), то его реализация для конкретного языка требует от программиста написания больше строк кода, чем заточенная под конкретный язык библиотека.
Так как XML в некотором смысле близок к HTML, то W3C выработал вариант HTML, синтаксис которого полностью соответствует XML. Получившийся формат файла назван XHTML [7]. Необходимость нового формата вызвана тем, что автоматически обрабатывать XML (а, значит, и XHTML) значительно проще, чем оригинальный HTML в связи со значительно более жестким синтаксисом. В будущем планируется полностью перейти на XHTML, оставив в программах возможность работы со старыми HTML файлами.
Преобразование XML документов в другие документы (XML, HTML, plain text) описывает стандарт XSLT [9]. Преобразование осуществляется по «программе», хранящейся в XSL файлах. Этот файл представляет собой XML, в котором описан способ создания выходного документа на основе входного.
Данная система использует формат XML в нескольких модулях:
1. Обработка входных документов, подготовленных в формате HTML.
2. Представление результатов работы программ в виде HTML.
3. Архивное хранение информации о курсах.
Для работы с XML используется библиотека Xerces, свободно распространяемая организацией Apache Software Group. Эта библиотека представляет собой реализацию, удовлетворяющую стандартам XML 1.0 и DOM 1.0.
3.1. Обработка входных документов
Входными документами являются файлы в формате HTML, подготовленные преподавателем-автором курса. Эти документы проходят обработку перед тем, как будут показаны пользователю. В процессе этой обработки выполняются следующие преобразования:
1. Преобразование HTML в XHTML. Это довольно сложный процесс, так как стандарт HTML довольно лоялен к отклонениям и поэтому многие авторы и программы работают с нестандартным HTML (непарные теги, закрытие тегов не в том порядке и т. д.).
2. Выделение тела документа (тег BODY).
3. Замена относительных ссылок на абсолютные (для внедренных файлов с изображениями, описываемыми тегом IMG).
4. Обработка псевдо-ссылок на отдельные компоненты курса (разделы, глоссарий, список литературы, список иллюстраций и т. д.) и замена их на реальные ссылки.
В дальнейшем обработанный таким способом документ вставляется в оболочку, представляющую собой каркас страницы (фоновый рисунок, стилевое оформление, панель инструментов, шапка, подвал и т. д.).
3.2. Создание выходных документов
Выходные документы – это файлы в формате HTML, которые предъявляются пользователю. Особенностью выходных документов является то, что должна существовать возможность изменять вид этих документов (по требованию заказчика, например) без изменения программ. Логичное решение в этом случае – разделить некоторым образом программу и HTML страницу. В данной системе разработан механизм шаблонов, который позволяет это сделать. Этот механизм основан на применении XML в качестве промежуточного формата данных.
В процессе работы программа заполняет некоторую древовидную структуру данных, аналогичную той, которая используется в DOM (создание собственной структуры данных вызвано тем, что использование DOM требует больше строк кода для манипулирования). Внешний вид HTML страницы определяется шаблоном, который представляет собой XHTML файл с вкраплениями дополнительных тегов и служебных символов. Вывод результатов программы заключается в обработке шаблона и замене служебной информации на реальные данные, которые извлекаются из дерева, подготовленного программой.
В шаблоне встречаются два вида служебной информации – простые подстановки и сложные инструкции.
Простые подстановки – это последовательность символов $NAME, такая, что ключ NAME определена в дереве-результате. Обработка подстановки заключается в ее замене на значение, сопоставленное ключу NAME. При этом происходит замена символов, недопустимых в HTML на соответствующие «сущности» (entities) - например, символ «<» заменяется строкой «<».
Сложные инструкции – это теги, которые программа вывода обрабатывает некоторым образом. В настоящее время определены следующие теги:
Тег | Параметры | Описание | |
1 | if | bool | Если параметр равен «истина», то содержимое тега выводится, иначе – нет |
2 | ifnot | bool | Действие противоположно тегу <if> |
3 | repeat | list | Содержимое тега выводится столько раз, сколько элементов в списке |
4 | include | string | Подставляется содержимое файла с указанным именем |
5 | define | Служит для описания новых тегов. С обработкой результатов программы непосредственно не связан | |
6 | inserthtml | string | Выполняет подстановку «сырого» HTML текста. В отличие от простой подстановки замены символов не происходит |
Отдельного внимания заслуживает механизм введения новых тегов. Он не связан непосредственно с обработкой результатов выполнения программы, но он позволяет существенно повысить производительность дизайнера, который выполняет художественное оформление HTML страниц. Вместо того чтобы копировать один и тот же фрагмент HTML кода несколько раз с небольшими изменениями (или даже без изменений) можно описать новый тег с несколькими параметрами, который включит в себя повторяющийся код и в каждом месте, где новый тег используется, программа вывода подставит исходный фрагмент с вычисленными параметрами.
С помощью механизма описания новых тегов можно как создавать новые теги, которые могли бы быть включены в стандарт HTML (например, <IMGBUTTON>), так и описывать общую структуру страницы.
Пример 1: тег IMGBUTTON представляет собой всплывающую графическую «кнопку». Он имеет атрибуты SRC и ALT как у тега IMG и атрибуты HREF и ONCLICK как у тега A. Две картинки (для нормального состояния и «вдавленного») лежат в директории /images и называются src. gif и src_.gif соответственно.
<define name="imgbutton" attr1="alt" attr2="href" attr3="src" attr4="onClick">
<a onmouseover="document['$src'].imgRolln = document['$src'].src; document['$src'].src = document['$src'].lowsrc;"
onmouseout = "document['$src'].src = document['$src'].imgRolln"
onClick="$onClick"
href="$href">
<img border="0" alt="$alt" src="/images/$src. gif"
id="$src"
name="$src"
dynamicanimation="$src"
lowsrc="/images/$src_.gif"
/>
</a>
</define>
Пример 2: тег PAGE. Определяет общую структуру страницы.
<define name="page" attr1="title" attr2="onLoad">
<head>
<title>$title</title>
<link rel="StyleSheet" type="text/css" href="/style. css" />
<meta http-equiv="content-type" content="text/html; charset=windows-1251" />
</head>
<body onLoad="$onLoad">
<h1>$title</h1>
<childs />
</body>
</define>
Пример 3: шаблон.
<html>
<include href="defines/global. xml" />
<page title="Параметры пользователя">
<commands>
<if param="isNew">
<command text="Создать" alt="Создать" onClick="return checkQuery()" href="javascript:document. user. submit()" />
</if>
<ifnot param="isNew">
<command text="Изменить" alt="Изменить" onClick="return checkQuery()" href="javascript:document. user. submit()" />
</ifnot>
<command text="Отменить" alt="Отменить" href="javascript:history. back()" />
</commands>
<pagebody>
<form name="user" ACTION="$formActionString" METHOD="POST">
<input type="hidden" name="COURSE" value="$course. code"/>
<!-- Опущено -->
</form>
</pagebody>
</page>
<script language="JavaScript" src="/user. js" />
</html>
В завершение рассказа о шаблонах нужно сказать несколько слов о взаимоотношениях со стандартом XSLT. Дело в том, что шаблоны решают проблему, похожую на ту, ради которой был придуман механизм XSL-преобразований. Однако стандарт XSL обладает чрезмерной общностью, он тяжеловесный. В XSL отсутствует механизм простых подстановок, в связи с чем необходимо пользоваться общим способом формирования элементов, который очень громоздок. Названия тегов обязаны использоваться вместе с указанием пространства имен, что делает XSL-файл в несколько раз больше и сложнее для понимания, чем аналогичный шаблон.
Здесь же стоит упомянуть о взаимоотношениях между механизмом шаблонов и стилевыми таблицами (cascading style sheet). Есть класс задач, которые можно решить двумя способами: предположим, что дизайнер хочет сделать несколько таблиц так, чтобы они выглядели одинаково. Существует два пути решения:
1. Создать стилевую таблицу, в ней описать класс для тега TABLE с желаемыми параметрами.
2. Описать один или несколько тегов, которые будут содержать в себе тег TABLE с соответствующими параметрами.
Первый способ является более современным – он использует технологию стилевых таблиц и уменьшает объем информации, передаваемой между сервером и клиентом. Но проблема в том, что существует всего несколько браузеров последних версий, которые полностью поддерживают указанный стандарт. Владельцы остальных увидят такие страницы так, как будто никаких стилей не было, или в ограниченном объеме.
Второй способ увеличивает объем данных передаваемых клиенту, но он позволяет воспользоваться многими возможностями, предоставляемыми стилевыми таблицами без необходимости осуществлять обновление версии браузера.
Из этого следует, что в большинстве случаев второй способ лучше. Единственным его недостатком является то, что часть параметров тегов можно настроить только через стилевые таблицы.
3.3. Архивное хранение информации о курсах
Система обладает одной особенностью, связанной с архивацией базы данных. Эта особенность делает ее непохожей на большинство информационных систем. Отличие заключается в том, что отдельные курсы могут сохраняться и восстанавливаться независимо друг от друга. В большинстве программных комплексов операции резервного копирования выполняются только над всей базой данных.
Извлечение информации начинается от курса. Далее по внешним ключам (FOREIGN KEY) происходит поиск всех записей, связанных с курсом, затем для этих записей операция повторяется. И так далее до тех пор, пока все записи не будут исчерпаны. При этом внешние ключи рассматриваются как двунаправленные связи, а выборка выполняется только по одному из направлений, так как двунаправленными связями окутана вся база.
Получившееся множество объектов записывается в формате XML.
При восстановлении курса XML-файл загружается на память, далее происходит многопроходная обработка, связанная с перенумерацией идентификаторов объектов. При этом возможна загрузка курса поверх такого же курса, который уже есть в базе. В этом случае происходит синхронизация данных (то есть часть информации берется из загружаемого курса, а часть – из того, который находится в базе данных). Для того чтобы наверняка знать соответствие между объектами (чтобы можно было установить идентичность) применяются глобальные идентификаторы (uuid – universally unique identifier или guid – globally unique identifier).
Пример (фрагмент):
<TeachingObjects build="4" root="211003">
<SDO_CCours id="211003"
course_flags="1"
course_forum_main="213035"
course_forum_notes="212435"
description="Курс по обучению персонала центрального офиса и филиалов работе с автоматизированной системой "Делопроизводство""
name="Делопроизводство"
obj_author="200009"
obj_date_create="03.08.2000 12:06:21"
obj_date_modify="28.08.2000 17:11:51"
obj_guid="cd24ed4-975d-0050da3d244b"
<part name="Группы" part_flags="2">
<part child="211109"/>
<part child="211209"/>
<part child="211309"/>
<part child="211409"/>
</part>
<part name="Форумы" part_flags="2">
<part child="212435"/>
<part child="213035"/>
</part>
<right grants="15" subject="211109"/>
<right grants="1" subject="211209"/>
<right grants="1" subject="211309"/>
<right grants="1" subject="211409"/>
</SDO_CCours>
</TeachingObjects>
4. Экспорт информации для работы в автономном режиме
Общая проблема всех динамических Web-серверов – то, что они требуют значительных ресурсов компьютера для своей работы. Одним из способов повышения производительности является сохранение сформированных динамически страниц в виде полноценных HTML-файлов на сервера в директории, открытой для просмотра. Ссылки при этом должны быть исправлены соответствующим образом – так чтобы они указывали не на исполняемые script-файлы, а на другие сгенерированные страницы. Скорость при этом значительно повышается за счет того, что Web-сервер не выполняет никаких программ, а просто выдает содержимое файлов клиентам, т. е. выполняет свою основную функцию, под которую он оптимизирован.
Если защитить директории, в которых находятся сформированные таким образом страницы, то сохраняется возможность предоставлять доступ лишь ограниченным лицам. При этом анализом протоколов Web-сервера может собираться статистическая информация об активности пользователя. Причем такая деятельность может производиться в асинхронном режиме, когда сервер не загружен своей основной деятельностью, например, ночью.
Небольшое изменение этой технологии позволяет формировать копию Web-сервера, предназначенную для автономного просмотра. При этом получается иерархия HTML-файлов с соответствующими файлами-изображениями (и, быть может, какими-то другими). Эти файлы можно просматривать браузером напрямую, без помощи какого-либо Web-сервера. Такую иерархию можно распространять на компакт-диске или в виде архива (например, в формате zip). Возможен также комбинированный вариант, когда распространяемые статические страницы имеют ссылки на основной сервер, на котором они были сформированы. При этом пользователь может изучить материал в автономном режиме, а затем перейти в диалоговый режим одним щелчком мыши.
5. Масштабируемость
Если система должна обслуживать большое количество пользователей, то особое значение приобретает свойство масштабируемости. Одно из решений заключается в использовании возможностей, предоставляемых сетевыми протоколами. Стек протоколов TCP/IP позволяет сопоставить одному имени несколько IP адресов. В этом случае запросы, адресованные Web-серверу с данным именем, будут реально посылаться компьютеру, имеющему IP-адрес, случайно выбранный из этого списка [5]. Это позволяет построить следующую схему балансировки нагрузки:
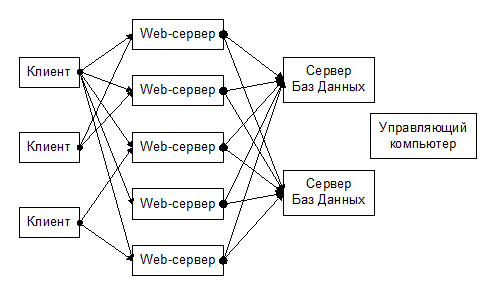
Клиент посылает запрос случайному Web-серверу. Возможны два сценария:
1. Если это запрос файла, то в ответ выдается локальная копия файла, находящаяся на данном Web-сервере.
2. Если это диалоговый запрос, требующий обращения к БД, то на данном Web-сервере запускается программа, которая на основании входных параметров определяет сервер БД, к которому нужно обратиться. Механизм выбора должен быть построен таким образом, чтобы текущая изменяемая информация в базах не пересекалась (т. е. база фрагментированная [4]). В данной системе разделение предполагается сделать на основе курсов – за данный конкретный курс отвечает один и только один сервер БД. При этом редко изменяемая информация может быть разделяемой (например, копия списка курсов может храниться в каждой базе).
Управляющий компьютер занимается синхронизацией информации между серверами БД и файлов между Web-серверами. Он может выполнять эти действия по расписанию (например, один раз в день) или по команде администратора системы. Для того чтобы сохранить удобство разработчикам курсов возможет вариант, когда каждый из них создает и проверяет курс автономно, а затем «вливает» информацию на сервер БД, который ответственен за данный курс.
В распределенной системе важным вопросом является протоколирование. В описанную выше архитектуру данный сервис вкладывается следующим образом. На управляющем компьютере работает сервис, единственная задача которого заключается в отписывании посылаемых ему сообщений в хранилище. Таким хранилищем может быть как обычный файл, так и база данных. Существование единого протокола облегчает последующий анализ и формирование выводов. Для повышения надежности соответствующие сервисы можно запускать на каждом компьютере, входящем в комплекс.
Заключение
В данной работе описаны некоторые решения, примененные при разработке Web-приложения «Система Дистанционного Обучения». Самая важная из них – подсистема обработки входных и выходных документов, основывающаяся на технологии XML. Эта подсистема позволяет обрабатывать достаточно произвольные входные документы в формате HTML и изменять выходные формы независимо от программ. Это облегчает работу дизайнеру, который с одной стороны не скован программистами, а с другой работает с форматом XML, который близок к HTML – основному рабочему материалу дизайнера. Еще одна важная подсистема – объектно-ориентированная библиотека для связи с реляционной СУБД. Она позволила уменьшить количество кода, осуществляющего операции с базой данных и сконцентрировать внимание разработчиков на содержательных аспектах системы. Особого внимания заслуживает свойство масштабируемости, но эта часть системы реализована пока лишь частично.
Литература
1. Дж. Введение в системы баз данных / Пер. с англ. 6-е изд. К.: Диалектика, 1998.
2. Дистанционное обучение через Интернет // Статья в данном сборнике.
3. , Создание среды хранения объектов над иерархической СУБД // Сборник трудов ИСА РАН «Развитие безбумажной технологии в организационных системах» / Под редакцией и - М.: Эдиториал УРСС, 1999. С. 252-279.
4. Р. Стратегические технологии баз данных / Пер с англ. / Под ред. и с пред. – М.: Финансы и статистика, 1999.
5. А. Сети Интернет. Архитектура и протоколы. - М.: «Блик Плюс», 1998.
6. DOM (официальная документация) - http://www. w3.org/TR/REC-DOM-Level-1
7. XHTML (официальная документация) - http://www. w3.org/TR/xhtml1
8. XML (официальная документация) - http://www. w3.org/TR/1998/REC-xml.
9. XSLT (официальная документация) - http://www. w3.org/TR/xslt
