
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Введение
Данная научная работа относится к области информационных технологий и распознавания данных. В ней содержится обзор современных методов решения избранных задач распознавания, описание разработанного алгоритма кластеризации интересов пользователей социальных сетей, особенности программной реализации данного алгоритма, а также анализ работы алгоритма на реальных данных, взятых из блоговой сети LiveJournal.
Исследования и результаты, представленные в работе, носят научно-технический характер.
В настоящее время социальные сети становятся все более популярными. При этом увеличивается не только число пользователей в одной социальной сети, но и увеличивается число самих социальных сетей. Каждый пользователь оставляет в социальной сети значительное количество информации. Эта информация может быть очень важной для решения различных задач, но в том виде, в котором её можно извлечь, её очень неудобно использовать. В связи с этим возникает огромное множество актуальных и интересных для исследования задач, связанных с структуированием, обработкой и анализом информации, содержащейся в социальных сетях. Многие из них не имеют в настоящий момент общепринятого решения и являются открытыми. Решение одной из таких задач, а именно задачи кластеризации интересов пользователей социальных сетей, – предмет данной работы. Кроме того в данной работе показывается применимость результатов решения данной задачи для реализации различных практических приложений. Основным требованием к решению являлась хорошая смысловая интерпретируемость полученных кластеров.
Несмотря на перспективность предметной области, в России пока что не очень много работ, посвященных исследованиям социальных сетей и решением связанных с ними задач, основные исследования проводятся за рубежом. В данной работе приводится обзор текущего состояния предметной области и наиболее связаных с решаемой задачей работ.
Решение задач связано с обработкой огромного количества данных, имеющих специфическую структуру. Отдельный раздел данной работы посвящен особенностям эффективной работы с подобными данными.
Постановка задачи
Формализация задачи
В качестве исходных данных имеется множество пользователей U, множество интересов R и отношение ![]() , определенное на некотором подмножестве декартового произведения множества пользователей и множества интересов
, определенное на некотором подмножестве декартового произведения множества пользователей и множества интересов ![]() . Удобно доопределить A нулём на всё множество
. Удобно доопределить A нулём на всё множество ![]() и перейти к матричному представлению исходных данных.
и перейти к матричному представлению исходных данных.
В матричном представлении задана матрица M, 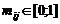 , строкам которой соответствуют пользователи (users), а столбцам – интересы (interests, items). Элемент
, строкам которой соответствуют пользователи (users), а столбцам – интересы (interests, items). Элемент ![]() означает вероятность того, что i-й пользователь отметил j-й интерес.
означает вероятность того, что i-й пользователь отметил j-й интерес. ![]() , то есть основная часть элементов матрицы равна 0, что соответствует ситуации, когда пользователь никак не связан с данным интересом. Как правило, имеется только точная информация о том, какие интересы отметили пользователи, и соответственно все ненулевые элементы матрицы равны 1. Требуется на основе этих данных получить пересекающуюся кластеризацию множества интересов, то есть сопоставить каждому интересу вектор
, то есть основная часть элементов матрицы равна 0, что соответствует ситуации, когда пользователь никак не связан с данным интересом. Как правило, имеется только точная информация о том, какие интересы отметили пользователи, и соответственно все ненулевые элементы матрицы равны 1. Требуется на основе этих данных получить пересекающуюся кластеризацию множества интересов, то есть сопоставить каждому интересу вектор ![]() единичной длины размерности k (i – номер интереса, k – число получившихся кластеров), в котором j-я компонента – степень принадлежности данного интереса к j-му кластеру. Заранее число кластеров неизвестно и определяется в процессе кластеризации. Будем называть вектором интереса ri вектор размерности, равной числу пользователей, с координатами
единичной длины размерности k (i – номер интереса, k – число получившихся кластеров), в котором j-я компонента – степень принадлежности данного интереса к j-му кластеру. Заранее число кластеров неизвестно и определяется в процессе кластеризации. Будем называть вектором интереса ri вектор размерности, равной числу пользователей, с координатами 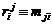 , а вектором пользователя ui вектор размерности, равной числу интересов, с координатами
, а вектором пользователя ui вектор размерности, равной числу интересов, с координатами ![]() . Введём также понятие популярности интереса
. Введём также понятие популярности интереса ![]() , то есть это число пользователей, которые отметили данный интерес.
, то есть это число пользователей, которые отметили данный интерес.
Специфика задачи не позволяет ввести функционал качества кластеризации без привлечения дополнительной экспертной базы знаний о смысловой связи интересов.
Поэтому основным требованием к алгоритму кластеризации является хорошая смысловая интерпретируемость результатов экспертом. Пересекающаяся кластеризация позволяет превратить множество интересов в метрическое пространство, но стандартные функционалы качества, которые можно ввести для кластеров в метрических пространствах могут не соответствовать правильному разбиению интересов по смыслу.
Предлагаемый алгоритм
Разработанный алгоритм состоит из двух этапов: предварительной непересекающейся кластеризации некоторого подмножества интересов и определения степени близости каждого оставшегося интереса к каждому найденному кластеру.
В начале первого этапа на декартовом произведении множества интересов с самим собой вводится мера значимости пары интересов ![]() . Рассмотрим основные требования, предъявляемые к выбору меры значимости:
. Рассмотрим основные требования, предъявляемые к выбору меры значимости:
· ![]()
· Чем чаще два интереса встречаются вместе у одних пользователей, тем больше должна быть мера значимости, то есть 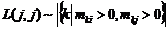
Дополнительным требованием может являться обратная пропорциональность меры значимости отклонению популярности каждого интереса из пары от средней популярности интересов. Это требование возникает из соображений о том, что интересы из пары с высокой степенью значимости будут определять смысловую характеристику кластера, к которому они будут относиться с очень высокой степенью близости. Но при этом очень редкие (уникальные) интересы и наоборот слишком популярные интересы плохо годятся на эту роль. С точки зрения программной реализуемости неизбежно возникает требование о малых затратах на вычисление.
 Этим требованиям удовлетворяют различные функции, например:
Этим требованиям удовлетворяют различные функции, например:
·
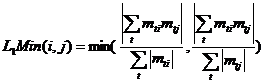 |
·
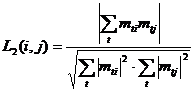 |
·
· ----
Также могут использоваться различные статистические меры (например, MI1, MI2, IDF), но они уступают перечисленным выше по простоте вычисления.
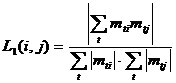
После того как мера значимости введена, её необходимо посчитать для каждой пары интересов для того, чтобы затем отсортировать все пары интересов по убыванию меры значимости. Важным параметром алгоритма является нижний порог значимости. В дальнейшем будут рассматриваться только те пары интересов, которые имеют меру значимости больше чем данный порог. Данный параметр выбирается эмпирически, исходя из свойств данной выборки пользователей и интересов (плотности матрицы M), предполагаемого количества кластеров, распределения меры значимости (если известно заранее) и прочих соображений. Подробнее о влиянии данного параметра на результаты кластеризации см. При работе с некоторыми мерами значимости (например, L1 или L1Max) необходимо ввести ещё один параметр: нижний порог популярности. При этом будут рассматриваться только те пары интересов, у которых популярность каждого интереса не ниже заданного порога. Тем самым редкие интересы не будут участвовать в первом этапе алгоритма. При выборе данного параметра следует руководствоваться распределением популярности интересов. Иногда целесообразно по аналогии с нижними порогами ввести верхний порог значимости и верхний порог популярности и соответственно рассматривать только те пары интересов, чьи меры значимости и чьи популярности интересов меньше заданных порогов. Введение подобных параметров не только положительно влияет результат при правильном подборе их значений, но и значительно упрощает вычисление мер значимости, так в случае не прохождения данной парой интересов порогов популярности, меру значимости можно вообще не считать (достаточно положить её равной 0). Более того, для рассматриваемых мер корреляций не всегда обязательно до конца вычислять её значение для пары интересов, которая не проходит нижний порог значимости. Например, если числитель в L1 меньше заданного порога, очевидно, что вся дробь будет также меньше этого порога, и знаменатель можно уже не считать.
Рассмотрим сам алгоритм построения кластеров. Входными данными для процедуры кластеризации является отсортированный по убыванию меры значимости список пар интересов. На каждом шаге алгоритма рассматривается очередная пара интересов. Кластеры, растущие по мере выполнения алгоритма, по аналогии с «островным» алгоритмом кластеризации документов будем называть островами. Введем ещё один параметр TS – минимальный размер кластера, при котором он перестает расти. Этот параметр будет отвечать за число и размер получающихся кластеров (чем больше значение параметра, тем меньше кластеров, и тем больше размер кластеров). В алгоритме будут фигурировать множества растущих островов G и множество зафиксированных островов F. Еще в алгоритме будет использоваться так называемое множество несвязываемых интересов, которое будет обозначаться как PRO. Оно будет включать интересы, относящиеся к полностью сформированным островам, которые тем самым не могут быть связаны с новыми интересами. Перед выполнением алгоритма множества F, G и PRO предполагаются пустыми, то есть, изначально нет ни одного кластера. Кроме того, в алгоритме часто будет использоваться операция фиксации острова С из множества G, состоящая в выполнении следующих трёх шагов:
1. Остров С удаляется из множества G;
2. Остров С добавляется ко множеству F;
3. Все интересы из острова С добавляются ко множеству PRO.
На каждом шаге алгоритма рассматривается очередная пара интересов <ri, rj> в порядке убывания меры значимости, пока все пары из списка (с ненулевой мерой значимости) не будут исчерпаны. Во время каждой итерации алгоритма выполняется следующая процедура:
Если ![]() и
и 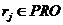 ,
,
перейти к рассмотрению следующей пары;
Если ![]() ,
,
если существует остров C, содержащий интерес ![]() ,
,
остров C фиксируется.
иначе ![]() ;
;
Если ![]() ,
,
если существует остров C, содержащий интерес ![]() ,
,
остров C фиксируется.
иначе ![]() ;
;
Если ![]() и
и ![]() не принадлежат ни одному острову,
не принадлежат ни одному острову,
добавить к множеству G остров, состоящий из интересов ![]() и
и ![]() ;
;
перейти к рассмотрению следующей пары;
Если ![]() и
и ![]() принадлежат двум разным островам C и D,
принадлежат двум разным островам C и D,
Если ![]() или
или ![]() ,
,
остров C фиксируется;
остров D фиксируется;
иначе
удалить острова C и D из G и добавить к G остров, являющийся объединением этих островов.
перейти к рассмотрению следующей пары;
Если интерес ![]() принадлежит некоторому острову, а интерес
принадлежит некоторому острову, а интерес ![]() не принадлежит ни одному острову,
не принадлежит ни одному острову,
добавить к этому острову интерес ![]() ;
;
перейти к рассмотрению следующей пары;
Если интерес ![]() принадлежит некоторому острову, а интерес
принадлежит некоторому острову, а интерес ![]() не принадлежит ни одному острову,
не принадлежит ни одному острову,
добавить к этому острову интерес ![]() ;
;
перейти к рассмотрению следующей пары;
Когда все пары интересов с ненулевой мерой значимости из списка исчерпаются, последним шагом алгоритма фиксируются все острова из множества G, если они там есть. Результатом алгоритма является множество F. Каждый остров C из этого списка соответствует найденному кластеру интересов. Каждый построенный кластер характеризуется входящими в него интересами, и таким образом имеет хорошую смысловую интерпретацию. Назовём интересы, которые на первом этапе вошли в один из кластеров – опорными. Также будем говорить, что опорные интересы, которые вошли в данный кластер – являются опорными для данного кластера. Эксперименты показывают, что входящие в один кластер опорные интересы, при удачном выборе параметров представляют собой ассоциативные и синонимичные цепочки.
Второй этап заключается в определении степени близости каждого интереса к каждому найденному кластеру. Предлагается это делать по формуле:
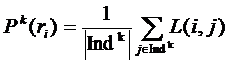 ,
,
где Pk(ri) – близость i-го интереса к k-му кластеру, Indk – множество индексов опорных для k-го кластера интересов, а ![]() – мера значимости пары интересов <ri, rj>. Стоит отметить, что для второго этапа алгоритма не обязательно вводить такую же меру значимости, как и на первом этапе, важно лишь, чтобы она удовлетворяла требованиям, которые обсуждались выше. Использование меры значимости такой же, как на первом этапе, может упростить вычисление, так как тогда можно вычислять её значения для каждой пары интересов только один раз.
– мера значимости пары интересов <ri, rj>. Стоит отметить, что для второго этапа алгоритма не обязательно вводить такую же меру значимости, как и на первом этапе, важно лишь, чтобы она удовлетворяла требованиям, которые обсуждались выше. Использование меры значимости такой же, как на первом этапе, может упростить вычисление, так как тогда можно вычислять её значения для каждой пары интересов только один раз.
Другой вариант – это сопоставить каждому найденному кластеру «обобщающих» интерес: k-й кластер ![]() интерес qk по правилу
интерес qk по правилу
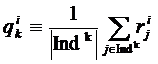
и считать близость интересов к кластерам по формуле:
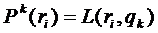
В результате для каждого интереса получается вектор размерности, равной числу кластеров, k-я координата такого вектора – выражает степень близости данного интереса к k-му кластеру. Ненулевые вектора получаются ненормированные, поэтому их следует нормировать, чтобы в дальнейшем работать с ними, как с векторами обычного евклидового пространства. Соответственно это делается по формуле:
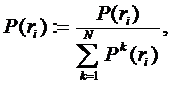
где N – число кластеров. Получившиеся в результате нормированные векторы будем называть профилями интересов.
Как правило, в результате данного алгоритма будет оставаться некоторое количество интересов, у которых будут нулевые профили. Их число зависит от выбора параметров алгоритма (чем меньше нижние пороги значимости, тем меньше будет получаться интересов с нулевыми профилями). В зависимости от решаемой задачи, для которой проводится кластеризация интересов, возможны несколько действий:
· Не использовать в данной задаче интересы с нулевым профилем, считая их «мусором», не поддающемся смысловой кластеризации;
· Считать, что интересы с нулевым профилем относятся с одинаковой степенью близости ко всем кластерам (приравнять каждую компоненту вектора 1/N);
· Итерационно повторять процесс распределения неопорных интересов;
Рассмотрим подробнее итерационный алгоритм определения профилей интересов. В алгоритме будут использоваться два списка: A – список интересов, для которых профиль уже посчитан, и B – список интересов с нулевым профилем (изначально списки пустые). На первом шаге профили для всех интересов считаются по формуле. Те интересы, для которых получился ненулевой профиль, добавляются в список A, интересы с нулевым профилем добавляются в список B. Далее на каждом шаге алгоритме для каждого интереса из списка B профили считаются по следующей формуле:
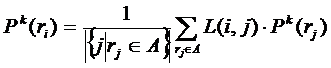
и соответственно нормируются:
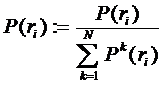
Все интересы из B, для которых на данном шаге получились ненулевые профили, переносятся в список A. Итерационный процесс заканчивается, когда число интересов в списке B перестаёт уменьшаться, либо достигает некоторого заданного максимального порога (по умолчанию 0). Оставшиеся в списке B интересы (они представляют собой очень малочисленные группы интересов, никак не коррелирующие с найденными кластерами, обычно отдельные уникальные интересы) либо в дальнейшем не рассматриваются, либо равномерно «размазываются» по кластерам.
Особенности программной реализации
В рамках данной работы была создана программа для ЭВМ, решающая задачу кластеризации интересов пользователей на основе предложенного алгоритма. Из соображений эффективности вычислительной части программы и удобства разработки был выбран язык C++, в качестве хранилища данных используется база данных MySQL. Вся необходимая информация для работы программы размещается в базе данных в трёх таблицах: Users, Interests, Users_Interests:

В таблице Users хранится список пользователей социальной сети (каждому пользователю соответствует идентификационный номер и имя), в таблице Interests хранится список интересов, которые когда-либо встречались в профилях пользователей (каждому интересу соответствует идентификационный номер и название, которое определяет смысловую нагрузку). Для каждого факта отмечания какого-либо интереса каким-либо пользователем в таблице Users_Interests заводится запись, содержащая идентификационный номер пользователя и идентификационный номер интереса. Можно считать, что для каждого интереса из списка интересов существует как минимум одна запись в таблице Users_Interests.
В рамках данной работы была реализована библиотека классов для эффективной работы с данными при решении задачи кластеризации интересов, а также при решении различных задач из области коллаборативной фильтрации (например, кластеризация пользователей). Необходимость создания собственной библиотеки была вызвана особенностями алгоритмов, а также структурой и объемом обрабатываемых данных. Библиотека классов содержит шаблонные реализации матриц, различных хранилищ данных (AVL-деревья, списки, массивы и другие) и аллокаторов памяти. Каждый шаблонный класс, реализующий хранилище данных, и соответствующий ему класс, реализующий хранимый объект, определяется типом ключа и типом значения (каждый хранимый объект реализует интерфейс получения/задания ключа и значения). При создании любого хранилища данных конструктору передается указатель на созданный аллокатор, таким образом реализация операций с данными в хранилищах не зависит от реализации работы с памятью, что даёт дополнительную гибкость при работе с библиотекой. Основные классы, которые использовались при реализации алгоритма кластеризации интересов – это различные реализации матриц. Каждый шаблонный класс, реализующий матрицу, определяется типом хранимых данных (например, целочисленный или с плавающей точкой), типом используемого аллокатора и типом используемого движка (хранилища данных). Перечислим основные интерфейсы, которые реализуют упомянутые классы:
Аллокаторы:
· Выделение объема памяти (величина выделяемого объема фиксируется заранее)
· Освобождение данного куска памяти
Хранилища данных:
· Добавление объекта с заданным ключом и значением
· Удаление объекта с заданным ключом
· Поиск объекта с заданным ключом
· Последовательная итерация по объектам в хранилище
Матрицы, вектора:
· Первоначальное заполнение значениями
· Получение/изменение значения в данной ячейке
· Последовательная итерация по всем элементам
При решении задачи кластеризации интересов и различных задач коллаборативной фильтрации используются следующие типы матриц: обычные (плотные), разреженные (то есть значительное число элементов имеет одинаковое «тривиальное» значение, принятое по умолчанию, обычно 0) и симметричные (частный случай разреженных матриц). Разреженность матрицы означает, что нет смысла выделять память под каждый элемент матрицы, достаточно хранить только нетривиальные значения. В зависимости от текущей задачи для реализации матриц целесообразно использовать различные хранилища данных, так как каждый тип хранилища имеет свои преимущества и недостатки:
массив:
+ очень быстрый случайный доступ к данным (O(1));
+ очень быстрый итерационный доступ к данным (O(1));
+ минимальный размер структуры объекта (0 дополнительных полей);
- в случае разреженности матрицы памяти используется гораздо больше, чем требуется;
список:
- очень медленный случайный доступ к данным (O(n));
+ очень быстрый итерационный доступ (O(1));
+ небольшой размер структуры объекта (1 дополнительное поле);
AVL-дерево:
+ быстрый случайный доступ к данным (O(log(n)));
- Построение итератора требует дополнительных операций с памятью и выполняется за O(n);
o Средний размер структуры объекта (минимум 2 дополнительных поля);
AVL-дерево, объединенное со списком:
+ быстрый случайный доступ к данным (O(log(n)));
- Очень быстрый итерационный доступ (O(1))
- Большой размер структуры объекта (минимум 3 дополнительных поля);
Сама реализация используемых в различных задачах классов матриц также различается. Если эффективная итерация по столбцам или строкам не требуется, то данные имеет смысл хранить в одном хранилище данных, основанном на AVL-дереве, используя в качестве ключа двойной матричный индекс. В случае, когда необходима эффективная итерация по строкам (столбцам) матрицы, предлагается хранить данные в виде массива строк (столбцов), заводя при этом отдельное хранилище данных (основанное на списке – если нет необходимости в эффективном случайном доступе, и основанное на AVL-дереве со списком – если необходим эффективный случайный доступ) на каждую строку (столбец). При этом необходимо использовать аллокатор, обеспечивающий компактное хранение данных в памяти. Необходимость компактного хранения вызвана тем, что при стандартном объеме (> 3Гб) обрабатываемые данные не смогут целиком находиться в оперативной памяти, и неизбежно будет происходить свопирование
данных на жесткий диск. Соответственно важно, чтобы при обращении к первому элементу при итерации столбец (строка) целиком загружался бы в оперативную память с жесткого диска. В случае, когда необходима эффективная и по столбцам и по строкам, и не ожидается частого изменения данных, может быть целесообразно дублировать данные, одновременно храня массив строк и столбцов. При такой реализации важно следить за синхронизацией доступа к элементам матрицы при изменении их значений.
Если компактное хранение данных не требуется, то от аллокатора не требуется ничего, кроме вызова оператора new с указанием заранее известного объема памяти. Компактное хранение данных требует от аллокатора более сложного устройства. При инициализации такой аллокатор сразу запрашивает кусок памяти, который примерно будет равен размеру предполагаемых данных, то есть произведение предполагаемого числа элементов на размер элемента (эту оценку должен сделать разработчик, основываясь на имеющуюся информацию о задаче и данных). В классе аллокатора хранится указатель на список свободных элементов (элементы, которые сначала были выделены, а потом освобождены). Список всегда заканчивается указателем на остаток незанятой памяти, которая ещё не использовалась аллокатором. Когда освобождается некоторый элемент, указатель на него помещается в начало этого списка. Когда аллокатору поступает команда на выделение памяти под новый элемент, он берет из начала списка свободных элементов указатель, возвращает его для использования под новый объект и удаляет из списка. Если у аллокатора заканчивается всё свободное место, то он выделяет ещё один большой кусок памяти и указатель на его начало помещает в список свободных элементов. В случае если об объёмах потенциально необходимой памяти нет никакой информации, можно использовать такие эвристики, как увеличение выделяемой памяти каждый раз в два раза.
Возможное применение
Определение близости между интересами
Как уже говорилось, в результате процесса кластеризации интересов для каждого интереса получается нормированный вектор размерности, равной числу найденных кластеров – профиль. При этом на множестве профилей может быть введена обычная евклидова метрика, что позволяет сравнивать близость различных интересов между собой. При наличии экспертных данных о смысловой близости тех или иных интересов, можно сопоставить степень смысловой близости интересов – расстоянию между их профилями. Если в наличие имеется группа интересов, ![]() то по формуле:
то по формуле:
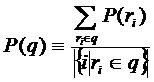
получаем профиль для группы интересов, который можно трактовать как профиль некоторого обобщающего интереса, отражающего смысл группы интересов в совокупности. Соответственно, можно рассчитывать степень смысловой близости между двумя группами интересов, как расстояния между их профилями, а также близость какого-либо интереса к некоторой совокупности интересов.
Индуцирование профилей у пользователей
Наличие профилей у интересов позволяет индуцировать профили у пользователей. Это можно сделать по формуле:
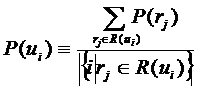
Профиль пользователя, как и профиль интересов, соответствует близости пользователя к найденным кластерам интересам. Если кластеры интересов трактовать, как некоторые темы, то по профилю пользователя можно судить о том, какие темы пользователю интересны, а какие нет. Евклидово пространство профилей пользователей изоморфно пространству профилей интересов, что позволяет считать расстояние между профилями пользователей и профилями интересов. Расстояние между профилем пользователя и профилем интереса соответствует степени заинтересованности пользователя в сущности, которую отражает интерес. По аналогии с группами интересов, определяется близость между группами пользователей, пользователем и группой пользователей, а также близость группы пользователей к группе интересов (одному интересу в частном случае) и пользователя к группе интересов. Близость между пользователями можно трактовать, как значительное пересечение интересов (в обычном смысле этого слова), то есть наличие ряда тем (чем пользователи ближе, тем таких тем больше) в которых заинтересованы оба пользователя. Профиль группы пользователей характеризует интересы сообщества, составленного из этих пользователей.
Возможность определения степени близости между пользователями создает большой потенциал для создания рекомендательных сервисов, которые рекомендуют одним пользователям других с целями знакомства или обмена информацией. Если полный перебор профилей пользователей для подбора наиболее близкого пользователя к данному является слишком вычислительно сложным, предлагается сначала провести предварительную непересекающуюся кластеризацию профилей пользователей стандартными методами, и выполнять перебор уже внутри кластера, к которому будет отнесен данный пользователь.
Получение профилей у произвольных интернет-ресурсов
По аналогии с индуцированием профилей пользователей возможно получение профилей у произвольных интернет-ресурсов, которые могут быть описаны с помощью ключевых слов (тегов) из множества интересов. Такими ресурсами могут, например, являться тексты (посты в блогах, новости, статьи, книги), аудиозаписи (музыка, аудиокниги), видеозаписи (фильмы, телепередачи, видеоролики). Если данный интернет-ресурс w описывается группой тегов![]() , которые принадлежат множеству интересов, то его профиль описывается формулой:
, которые принадлежат множеству интересов, то его профиль описывается формулой:
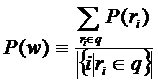 ,
,
то есть считается равным профилю группы интересов-тегов, определяющих данный интернет-ресурс. Сложности возникают в том случае, если не все теги, которыми описывается данный интернет-ресурс, принадлежат множеству интересов. Что касается тегов к постам (записям в блогах), то эта проблема снимается кластеризацией тегов вместе с интересами. А если рассматривать такие интернет-ресурсы как книги, фильмы, музыку, статьи, то теги к подобным ресурсам обычно представляют собой названия произведений, имена исполнителей, авторов, режиссеров, названия жанров, тематических разделов и другие ключевые слова, которые с очень большой вероятностью принадлежат множеству интересов. В случае, если большая часть тегов интернет-ресурса принадлежит множеству интересов, а меньшая не принадлежит, можно определить профиль данного интернет-ресурса равным профилю подгруппы, состоящей из тегов, которые принадлежат множеству интересов. При этом целесообразно определить профили тегов, не входящих во множество интересов, равными профилю интернет-ресурса и добавить эти теги к множеству кластеризованных ключевых слов (интересов). Возможен случай, когда откуда-то известны профили нескольких интернет-ресурсов, которые в описании содержат общий тег, который не принадлежит множеству интересов. Тогда имеет смысл определять профиль такого тега равным профилю группы интернет-ресурсов (профиль группы интернет-ресурсов определяется аналогично профилю группы пользователей). По аналогии с профилями пользователей можно считать расстояния между профилями различных интернет-ресурсов, пользователей, интересов. Расстояние между пользователем и интернет-ресурсом трактуется как степень заинтересованности пользователя в данном интернет-ресурсе. Возможность расчета таких расстояний дает множество практических применений.
Во-первых, это создание всевозможных рекомендательных сервисов, которые в настоящий момент набирают популярность. По аналогии с пользователями целесообразно предварительно кластеризовать множество интернет-ресурсов, которые предлагается рекомендовать для упрощения подбора рекомендации. Основным преимуществом рекомендательных сервисов, построенных на предлагаемой технологии, является то, что они используют минимум информации, которую можно получить о пользователе, а именно список интересов, извлекаемый из профильной страницы пользователя. Для получения рекомендаций пользователю не нужно создавать дополнительный контент, вроде выставления оценок интернет-ресурсам.
Во-вторых, это очень востребованная в настоящее время возможность показа пользователям таргетированной рекламы, то есть рекламы, которая не раздражала бы пользователя, а наоборот была бы ему интересна. Эта возможность определяется тем, что реклама, как и интернет-ресурсы, хорошо определяется ключевыми словами, и поэтому для каждой рекламной единицы можно определить профиль.
Хочется отметить, что как в случае рекомендательных сервисов, так и в случае показа рекламы, профили предлагаемых интернет-ресурсов, могут не вычисляться, а определяться экспертами (на основании близости к той или иной теме). Кроме постановки задачи «подобрать интересные интернет-ресурсы для данного пользователя» актуальной является задача «подобрать для данного интернет-ресурса пользователей, которые были бы в нем заинтересованы», то есть поиск целевой аудитории. С алгоритмической точки зрения эти две постановки задачи эквивалентны.
В-третьих, это автоматическая классификация интернет-ресурсов. Допустим, есть m тематических разделов (список разделов может не совпадать со списком тематических кластеров интересов) по которым необходимо распределять интернет-ресурсы (распределение может быть как строгим, так и пересекающимся). Для каждого из этих разделов известен профиль pi (вектор в пространстве профилей интересов). Данные о профиле могут быть получены от эксперта (на основе смысловой близости данного раздела к кластерам интересов), либо посчитан как профиль группы интернет-ресурсов, которые были заранее отнесены к данному тематическому разделу экспертом. Для простоты можно считать, что профили разделов линейно независимы, то есть образуют базис в линейном пространстве L размерности равной m. Тогда задача классификации сводится к нахождению матрицы отображения A из пространства профилей интересов в пространство L и легко решается методами линейной алгебры, так как известны координаты профилей разделов в базисе пространства профилей интересов. Тогда для получения вектора распределения интернет-ресурса по разделам достаточно умножить матрицу A на его профиль, и провести нормировку. Если необходимо строгое отнесение к определенному кластеру – то выбирается раздел, которому соответствует максимальное значение координаты в получившемся векторе.
Анализ тестов
Разработанную технологию можно также применять для анализа различных текстов. По аналогии с получением профилей различных инетрнет-ресурсов с целью их тематической характеристики, можно рассчитывать профили для произвольных текстов w. Для этого необходимо сначала выделить в тексте ключевые слова ![]() , принадлежащие множеству интересов, затем посчитать взвешенную сумму их профилей P(ri) (весом может служить частота употребления данного ключевого слова в тесте – ci) и нормировать получившийся вектор, то есть
, принадлежащие множеству интересов, затем посчитать взвешенную сумму их профилей P(ri) (весом может служить частота употребления данного ключевого слова в тесте – ci) и нормировать получившийся вектор, то есть
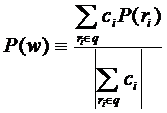 .
.
По аналогии с автоматической классификацией текстов реализуется автоматическая рубрикация текстов, это может быть особенно востребовано различными новостными ресурсами. После расчета профилей тестов, тесты могут быть также легко кластеризованы стандартными способами.
Заключение.
В результате работы был создан программный комплекс для решения задачи кластеризации интересов пользователей социальных сетей с помощью разработанного алгоритма. Были исследованы особенности работы данного алгоритма в зависимости от его параметров, и при соответствующем подборе параметров алгоритм показал себя достаточно эффективным для решения поставленной задачи. Созданную в ходе работы библиотеку для работы с матрицами и различными хранилищами данных можно использовать для множества других задач, где требуется обработка данных похожей структуры.
Написать, где результаты работы были апробированы
TODO:
Анализ сложности
Картинка с устройством матриц
Картинка с устройством дерева-списка, как пример возможно используемой структуры
Картинка с устройством простейшего аллокатора
Дополнительные условия для фиксирования островов
Введение
Обзор блогосферы
Обзор рекомендательных сервисов
Обзор методов кластеризации слов и текстов
Обзор фреймворков для работы с данными
Работы воронежского института и Миши Черномордикова
Картинка с гистограммой интересов
Список литературы
Описание возможностей для получения исходных данных
Применение в лингвистике, социологии
Результаты, в зависимости от параметров
Пояснить как именно дается рекомендация (берется top из сортированного списка)
Написать про кластеризацию тегов
Планы по улучшению
Рассказать про гаджеты/API
Заключение, перечисление конференций и наград
Возможно, привести в качестве примера что-нибудь из Никитиных результатов
