


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Муниципальное образовательное учреждение средняя общеобразовательная
школа с. Таремское Нижегородская область
Статистические
характеристики экономического развития.
(по одному из агропромышленных предприятий
Павловского района)
Работу выполнила:
ученица 10 класса:
Сахарова Светлана
Научный руководитель:
учитель математики
.
2008 год.
Содержание.
Цели………………………………………………………………………………..3
Аннотация…………………………………………………………………………4
Введение…………………………………………………………………………..5
Обзор литературы…………………………………………………………………6
1. Способы систематизации и предоставления данных
1.1 Случайные величины и их виды…………………………………… 7-8
1.2 Числовые характеристики случайных величин………………….9-11
1.3 Графическое представление данных……………………………
2. Вероятность – как количественная мера возможности появления события
2.1 Классическое определение вероятности…………………………12-14
2.2 Вероятность, как ожидаемое значение частоты и её
применения……………………………………………………………15-17
3. Дискретные случайные величины.
3.1 Распределение дискретной случайной величины ……………….18
3.2 Математическое ожидание и его свойства……………………….19
3.3 Дисперсия и её свойства…………………………………………..20
3.4 Применение статистики к решению практических задач….…21
Выводы ……………….. ……………………………………………………....22
Приложения………………………………………………………………….23-25
Цели.
Основная цель работы познакомиться со случайными величинами их характеристиками, способами графических представлений случайных величин.
Научиться использовать информацию, анализировать и обрабатывать её, строить диаграммы, делать прогнозы на основе анализа и обработки полученной информации.
Аннотация
Основная цель работы познакомиться со случайными величинами их характеристиками, способами графических представлений случайных величин.
Научиться использовать информацию, анализировать и обрабатывать её, строить диаграммы, делать прогнозы на основе анализа и обработки полученной информации.
Работа над предложенной темой способствовала развитию вероятностно-статистического мышления, показала универсальность вероятностных законов, которые стали основой описания научной картины мира. Современная физика, химия, биология, демография, социология, весь комплекс социально-экономических наук построены и развиваются на вероятностно - статистической базе. Знакомство с этим разделом математики поможет Светлане не только успешно изучать в дальнейшем отдельные разделы школьной программы по многим дисциплинам, но и продолжить его изучение в вузе. В процессе работы она строила диаграммы и таблицы частот, обрабатывала числовые ряды данных и давала им характеристики, используя при этом компьютерные технологии.
Использование местного материала способствует воспитанию патриотизма,
объективной оценки развития села и возможности работы после получения образования.
Введение
Ориентация на демократические принципы мышления, на многовариантность возможного развития реальных ситуаций и событий на формирование личности, способной жить и работать в сложном постоянно меняющемся мире, с неизбежностью требует развития вероятностно-статистического мышления. В настоящее время вводится «знакомство с вероятностью» в школьный курс «Алгебра и начала анализа» Но изучение этого раздела на формально-логическом уровне, во втором полугодии 11 класса малоэффективно.
С целью подбора материала, возможности его апробации на малых группах учащихся, группе учеников 10 класса было предложено познакомиться с научной литературой по данной теме, и применить добытые знания к конкретным ситуациям в окружающей нас действительности. Работа длилась 5 месяцев, на базе Таремской средней школы. Сахарова Светлана изучила большое количество популярной и научной литературы по данному вопросу, исследовала материалы, предоставленные ей бухгалтерией администрации с. Таремское и экономическим отделом АПКФ , приготовила презентацию по данному вопросу.
Обзор литературы.
1. «Мир, построенный на вероятности».
В книге в интересной и популярной форме рассказано о вероятностных причинно-следственных связях и их принципиальной роли в природе, научном познании мира, человеческой практике. Рассмотрены физические основы кибернетики и теории информации, молекулярно-кинетической теории и квантовой механики, генетики и эволюционной теории. Предназначена для чтения школьниками, интересующимися случайными величинами.
2. Учебное пособие: «Теория вероятностей и математическая статистика» под редакцией профессора .
В книге излагаются основные сведения по теории вероятностей и математической статистике, необходимые в учебном процессе экономических вузов и научной работе, а также экономистам различных направлений в их практической деятельности. Теоретические сведения, дополняются полезными практическими заданиями. Есть полезные приложения, такие как: значение функции е - х, нормированная функция Лапласа.
3. , «Элементарное введение в теорию вероятностей» Москва 1976г.
В книге рассматриваются вопросы практического приложения теории вероятностей, показывается научная значимость вводимых понятий и правил. Книга рассчитана на читателей, владеющих математикой на уровне средней школы.
4. «Вероятность» Фредерик Мостеллер, Роберт Рурке, Джордж Томас.
Эта книга написана группой известных математиков и педагогов, представляет собой элементарное введение в теорию вероятностей и статистику – разделы математики, которые находят сейчас все большее и большее применение в науке и в практической деятельности. Написанная живым и ярким языком, она содержит множество увлекательных примеров, взятых большею частью из сферы повседневной жизни. Несмотря на то, что для чтения книги достаточно владеть математикой в объёме восьмилетней школы, она является вполне корректным введением в теорию вероятностей.
Книга будет полезна всем интересующимся теорией вероятностей, студентам технических и естественно-научных вузов, техникумов, учителям средних школ и учащимся старших классов, а также всем любителям математики.
5.Использованные сайты:
1) www. *****/articles/74/1007485/1007485a1.htm
2) *****
Вступление.
Случайные величины, ещё за несколько сотен лет до нас ученые начали замечать их. Каждый день совершается великое множество событий и явлений в окружающем нас мире. Со случайными величинами мы сталкиваемся ежедневно: при поездках на транспорте, при оценивании времени, необходимого на выполнение какой то работы, в различных играх и соревнованиях. Случайными являются результаты исследований каких либо процессов: обеспеченность населения товарами массового потребления, предварительная оценка рентабельности предприятия, влияние применения удобрений на урожайность и качество продукции и многое другое.
Случайный характер исследуемых явлений имеют системы массового обслуживания. Объектами исследований могут быть производственные процессы, транспорт, торговля. Количество заявок и временной интервал между моментами их поступления являются величинами случайными.
Эти события взаимосвязаны – одни из них являются следствием (исходом) других и, в свою очередь, служат причиной третьих. Вглядываясь в гигантский водоворот взаимосвязанных явлений, можно сделать два важных вывода. Во-первых, вместе с совершенно определёнными, однозначными исходами встречаются и неоднозначные исходы. Если первые можно предсказать точно, то вторые допускают лишь вероятностные предсказания. Другой не менее важный вывод состоит в том, что неоднозначные исходы встречаются значительно чаще, чем однозначные. Мы нажимаем на кнопку, и стоящая на нашем столе лампа загорается. Здесь второе событие (загорелась лампа) является однозначным исходом первого события (нажата кнопка). Такое событие называют строго детерминированным (от латинского determinare – «определять»). Другой пример: Человек подбрасывает кубик, на разных гранях которого изображены числа очков, и кубик падает так, что сверху оказывается грань с четырьмя очками. В данном случае второе событие (выпала четвёрка) уже не является однозначным исходом первого события (подброшен кубик). Ведь могли выпасть единица, двойка, тройка, пятерка, шестерка. Выпадение того или иного числа очков есть пример случайного события. Из приведенных примеров хорошо видно различие между строго детерминированными и случайными событиями. Со случайными событиями мы встречаемся очень часто, значительно чаще, чем это обычно принято считать.
Приведем примеры случайных величин часто встречающихся в нашей жизни: Теория очередей.
Люди, подходящие случайным образом к прилавку магазина, за которым их обслуживают, обычно выстраиваются в очередь. Если известны данные, касающиеся частоты появления покупателей и времени обслуживания одного покупателя, то как определить время, которое затрачивает один покупатель на стояние в очередях, какой эффект даст добавление ещё одного продавца? Если человек не может стоять в очереди, то какой процент покупателей останется не обслуженным?
Различные видоизменения этой задачи представляют интерес при исследовании эксплутационных характеристик комплекса станков, при решении вопроса о количестве контрольных автоматов, которые следует установить на станциях метро, при проектировании оборудования, которое надо установить для телефонных линий.
Характеристики случайных величин.
Величина называется случайной, если в результате опыта она может любые принимать заранее неизвестные значения Случайные величины подразделяются на дискретные и непрерывные.
Случайная величина называется дискретной, если она может принимать определённые, фиксированные значения.
Например, число ежедневно продаваемых в магазине холодильников является дискретной случайной величиной.
Случайная величина обычно обозначается прописной буквой латинского алфавита, а её конкретное значение - строчными буквами с индексами.
Рассмотрим основные характеристики случайных величин:
1.Модой называют число, наиболее часто встречающееся в ряду данных.
2.Медианой называется число, стоящее в середине ряда данных, если в ряде нечётное число членов. Если ряд содержит чётное число членов, то за медиану принимают среднее арифметическое двух чисел, стоящих в середине ряда.
3.Размахом числового ряда данных принято считать разность между наибольшим и наименьшим значениями этого ряда.
4.Дисперсией называют среднее арифметическое значение квадратов отклонений случайной величины от среднего арифметического ряда данных.
Дадим такие характеристики величинам являющимся заработными платами работников дошкольных учреждений за 1 месяц прошлого года.
18 183 2 92 150 7 276 119 298 10 1252
Ранжируем этот ряд:
273,561,597,642,654,688,765,857,892,935,1009,1019,1078,1103,1227,1251,1328,1350,1367,1383,1425,1433,1451,1468,1523,1692,1720,1733,1878,1882,1898,1898,1903,1968,2011,2024,2326,2376,2749,2858,2887,4193,4760.
Найдем среднее арифметическое:
1227+2025+2011+688+857+654+1382+935+1328+1425+4192+1383+642+1903+1451+272+764+1878+1078+1692+1103+1350+1733+2750+892+597+1009+2887+2326+1433+1468+2376+1898+1882+2858+1019+2380+1968+1720+1898+1523+1367+4760+560+1252=72796/45 =1618
Найдем размах нашего ряда случайных цифр:
=4487
Рассмотрев наш ранжированный ряд мы можем увидеть, что число, стоящее в середине – это 1451.
Округлим до сотен:
10 0 100 0 00 100 0 200 100 200 10 1300
Получили интервальный ряд.
В большом количестве случаев наиболее актуально рассматривать моду или медиану, чем среднее арифметическое значение. Составим таблицу частот появления случайной величины:
см. приложение №1.
Исследовать закономерности случайных величин начали довольно давно, но с применением компьютерных технологий эта задача намного облегчилась и не занимает так много времени.
Наглядное представление статистической информации имеет огромное значение. Различные виды наглядной интерпретации результатов статистических исследований постоянно встречаются в средствах массовой информации. На конкретных примерах можно вспомнить о столбчатых и круговых диаграммах, познакомиться с понятиями полигона и гистограммы.
Законы, управляющие случайными явлениями, проступают недостаточно отчетливо, затушёваны многими осложняющими факторами. Необходимо сначала изучить закономерности случайных величин на более простом, прозрачном материале. Таким материалом исторически оказались «азартные игры». Схемы азартных игр дают исключительные по простоте модели случайных явлений, позволяющие изучать управляющие ими законы.
Процессы познания законов функционирования весьма сложных систем управление ими совершается за счёт вычленения в них более простых параметров, которые можно выразить как содержательно, так и количественно. Один из основоположников кибернетики У. Росс Эшби
выразил эту тенденцию так: «Когда системы становятся сложными, то их теория практически заключается в том, чтобы найти пути их упрощения», «исследователи сложных систем должны заниматься упрощёнными формами, ибо всеобъемлющие исследования зачастую совершенно невозможно».
Пример механики, химии, физики показывает, что отбор наиболее существенных параметров возможен благодаря введению новых математизируемых понятий, которые способны наиболее эффективно кодировать, аккумулировать в себе огромное количество информации.
Огромное значение в этом плане имеют такие фундаментальные понятия, как информация, способы её кодирования, ступенчатое управление.
Таким образом, идеи и методы математического моделирования в биологи придают новое единство всей биологической науке, позволяют выделить совершенно новые черты структурной общности самых различных уровней организации колоссально разросшегося древа наших знаний о живом.
Построение математической модели – довольно трудный этап развития математических теорий. Самые разные объекты выбираются в виде элементарных строительных кирпичей соответствующих моделей. В классической механике – это материальная точка, в электродинамике - вектор напряжённости, физика элементарных частиц переживает модельный этап математизации.
Статистические испытания предполагают многократное повторение однотипных испытаний. Результат любого отдельного испытания случаен и сам по себе какого - либо интереса не представляет. В то же время совокупность большого числа подобных результатов оказывается весьма полезной. Она обнаруживает определённую устойчивость, которая позволяет количественно описать явление, исследуемое в данных испытаниях. Рассмотрим специальный метод исследования случайных процессов, основанный на статистических испытаниях. Его часто называют методом Монте-Карло. Этот город широко известен своими игорными домами, в которых богатые туристы ставят на рулетку немалые суммы. Но ведь рулетка – генератор случайных чисел. Именно это имеют в виду, когда говорят о методе Монте-Карло.
Законы, управляющие случайными явлениями, проступают недостаточно отчетливо, затушёваны многими осложняющими факторами. Необходимо сначала изучить закономерности случайных величин на более простом, прозрачном материале. Таким материалом исторически оказались «азартные игры». Схемы азартных игр дают исключительные по простоте модели случайных явлений, позволяющие изучать управляющие ими законы.
Классическое определение вероятности.
Для исследования случайной величины необходимо провести многократно один и тот же опыт. Но это не всегда удобно, поэтому существуют генераторы случайных чисел, которые представляют собой знакомые всем: рулетка, игральные кости, урны (корзины). Для примера рассмотрим одну из разновидностей урн – ящик с шарами, что он собой представляет и какое отношение имеет к случайным числам? Положим в ящик десять одинаковых шаров, помеченных цифрами от 0 до 9.Вынем наугад один из шаров и отметим его цифру. Пусть это будет 5.Затем вернём шар в ящик, хорошо перемешаем шары и снова вынем наугад один шар. Допустим, что на этот раз выпала цифра 1.Повторяя эту операцию много раз, мы можем получить неупорядоченный набор цифр, например такой: 5,1,2,7,2,3,0,2,1,3,9,2,4,4,1,3… Неупорядоченность набора связана с тем, что каждая цифра выпадала случайно. Имея множество случайных цифр, можно составить набор случайных чисел. Будем рассматривать, например, четырёхзначные числа. В этом случае достаточно разбить полученный набор случайных цифр на группы по четыре цифры и рассматривать каждую группу как одно из таких чисел: 5127,2302,1392,4413…Наиболее проще устроены генераторы случайных чисел, относящиеся к типу«кости».Из таких наборов случайных чисел можно построить таблицу. (Приведенная ниже таблица взята из книги «Мир, построенный на вероятности»)
0655 5255 6314 3157 9052 | 8453 5161 8951 9764 9565 | 4467 4889 2335 4862 4635 | 3384 7429 0174 5848 0653 | 5320 4647 6993 6919 2254 | 0709 4331 6157 3135 5704 | 2523 0010 0063 2837 8865 | 9224 8144 6006 9910 2627 | 6271 8638 1736 7791 7959 | 2607 0307 3775 8941 3682 |
4105 1437 4064 1037 5718 | 4105 2851 4171 5765 8791 | 3187 6727 7013 1562 0754 | 4312 5580 4631 9869 2222 | 1596 0368 8288 0756 2013 | 9403 4746 4785 5761 0830 | 6859 0604 6560 6346 0927 | 7802 7956 8851 5392 0466 | 3180 2304 9928 2986 7526 | 4499 8417 2439 2018 6610 |
5127 9401 4064 5458 2461 | 2302 2423 5228 1402 3497 | 1392 6301 4153 9849 9785 | 4413 2611 2544 9886 5678 | 9651 0650 4125 5579 4471 | 8922 0400 9854 4171 2873 | 1023 5998 6380 9844 3724 | 6265 1863 6650 0159 8900 | 7877 9182 8567 2260 7852 | 4733 9032 5045 1314 5843 |
4320 3466 9313 5179 3010 | 4558 8269 7489 8081 5081 | 2545 9926 2464 3361 3300 | 4436 7429 2575 0109 9979 | 9265 7516 9284 7730 1970 | 6675 1126 1787 6256 6279 | 7989 6345 2391 1303 6307 | 5592 4576 4245 6503 7935 | 3759 5059 5618 4081 4977 | 3431 7746 0146 4754 0501 |
9599 4242 3585 5950 8462 | 9828 3961 9123 3384 3145 | 8740 6247 5014 0276 6582 | 6666 4911 6328 4503 8605 | 6692 7264 9659 3333 7300 | 5590 0247 1863 8967 6298 | 2455 0583 0532 3382 6673 | 3963 7679 6313 3016 6406 | 6463 7942 3199 0639 5951 | 1609 2482 7619 2007 7427 |
0456 0672 5163 4995 6751 | 0944 1281 9690 9115 6447 | 3058 8697 0413 5273 4991 | 2545 5409 3043 1293 6458 | 3756 0653 1014 7894 9307 | 2436 5519 0228 9050 3371 | 2408 9720 5460 1378 3243 | 4477 0111 2835 2220 2958 | 5707 4745 3294 3756 4738 | 5441 7979 3674 9795 3996 |
Сколько бы таких таблиц не составлялось, всё равно вам не удастся обнаружить и тени какого-либо порядка в следовании цифр друг за другом. Всё это неудивительно: ведь на то он и случай! Но у случая есть и оборотная сторона. Если посчитать сколько раз в таблице встречается та или иная цифра, то можно обнаружить что частота появления каждой цифры примерно одна и та же: она близка к 0,1. Сразу, можно понять, что 0,1 – это вероятность выпадения той или иной конкретной цифры.
И хотя всё это естественно, нельзя не подивится лишний раз тому, как в неупорядоченном наборе случайно появляющихся цифр обнаруживается внутренняя устойчивость. Здесь наглядно проявляется оборотная сторона случая, принимающая облик точно определяемой вероятности. Если немного поработать с таблицей, то можно убедиться: вероятность того, что число будет начинаться с той или иной конкретной цифры, равна 0,1.
История возникновения теории вероятностей уходит в глубь веков, но математики начали рассматривать её только в середине 17 века. В 1657 году была издана первая книга по теории вероятностей, написанная Гюйгенсом. Определились основные понятия теории, терминология, принципы вычисления вероятности события. Формулу действия для решения вероятностных задач четко изложил Лаплас: «Теория случайности состоит в том, чтобы свести все однородные события к известному числу равновозможных случаев, то есть таких, существование которых для нас было бы одинаково неопределенно, определить число случаев, благоприятствующих явлению, вероятность, которого отыскивается. Отношение этого числа случаев к числу всех возможных случаев и есть мера этой вероятности, которая таким образом, и есть не что иное, как дробь, числитель которой есть число всех благоприятных случаев, а знаменатель - число всех возможных случаев»!
В классическом определении вероятности случайная величина разбивается на равновозможные исходы. На практике такие случайные величины встречаются очень редко. Поэтому первоначально теория вероятностей применялась только к азартным играм. К азартным играм относили бросание шестигранных игральных костей. Слово «азар» по-арабски означает трудный. Так, арабы называли азартной игрой комбинацию очков, которая при бросании нескольких костей могла появиться лишь единственным способом. Например, при бросании двух костей трудным («азар») считалось появление в сумме двух или двенадцати очков. Впервые основы теории вероятностей были последовательно изложены французским математиком П. Лапласом (1749 – 1827) в книге «Аналитическая теория вероятностей». В предисловии автор писал: «Замечательно, что наука, которая началась с рассмотрения азартных игр, обещает стать наиболее важным объектом человеческого знания. Ведь по большей части, важнейшие жизненные, вопросы являются на самом деле лишь задачами из теории вероятностей». П. Лаплас не мог предусмотреть, что пройдет несколько десятилетий и интерес к теории вероятностей снизится. А так на деле и случилось. Во второй половине XIX века и в начале XX века некоторые математики перестали интересоваться теорией вероятностей как математической дисциплиной. Но постепенно математики начали применять теорию вероятностей к исследованиям массовых явлений.
Статистическое понятие вероятности.
Статистическая теория во многом основана на теории вероятностей, хотя здесь есть и обратная связь: при построении вероятностной модели используются данные статистики.
Математическая статистика занимается изучением закономерностей, которым подчиняются массовые явления, на основе результатов наблюдений.
Рассмотрим на конкретном примере обработку данных. (В нашем случае заработная плата работников детского дошкольного учреждения)
В математической статистике вводятся понятия генеральной и выборочной совокупностей.
Если произвести измерения указанного параметра на всех объектах и вычислить некоторые характеристики измеряемого параметра, то общее количество объектов и составляет генеральную совокупность.
В некоторых случаях неудобно или невозможно получить измерения на всех объектах и поэтому выбирают некоторую часть из генеральной совокупности (выборку), которую называют выборочной совокупностью. Обрабатывая результаты измерений выборки, получают её обобщённые характеристики, с помощью которых оценивают параметры генеральной совокупности.
Объёмом совокупности называют число объектов совокупности (выборочной или генеральной).
Если выборка правильно отражает соотношения в генеральной совокупности, то её называют репрезентативной (от фр. (представительной).
Наблюдаемые значения параметров называют вариантами, последовательность вариант, записанных в порядке возрастания, называют вариационным рядом.
Числа наблюдений вариантов называют частотами, а отношение частоты к объёму выборки – относительными частотами.
Статистическим распределением выборки называют перечень вариант и соответствующих им частот.
Среднее арифметическое вариационного ряда называют выборочной средней. Это один из основных статистических показателей. Вычисление среднего арифметического позволяет перейти от частных случаев к некоторому обобщению. В связи с этим даже в тех случаях, когда ряд данных состоит из натуральных чисел, среднее арифметическое может выражаться дробным числом.
Чтобы получить статистические данные нужно многократно провести один и тот же опыт(испытание)
Испытание – это любой эксперимент, наблюдение и проверочные действия.
Единичное испытание - испытание, при котором совершается одно действие с одним предметом.
Исходы испытаний – это результаты испытаний, например, при подбрасывании монеты выпала цифра, из урны извлекли чёрный шар, обследованная деталь оказалась бракованной.
Случайные исходы испытаний - исходы, которые нельзя заранее предсказать, поскольку они могут быть разными и определяются случайным стечением обстоятельств в ходе испытания.
Множество всех исходов испытания может быть базовым - это максимальное число возможных исходов испытания, или сокращённым. Сокращённое множество исходов получается путём объединения некоторых исходов из базового множества.
Приведем пример случайного события, в котором относительная частота наступления какого-либо исхода группируется (сосредотачивается) вокруг заданного числа.
№1
Выпадение цифры 5 на игральном кубике.
10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | 140 | 150 | 160 | 170 |
0 | 0,1 | 0,07 | 0.075 | 0,1 | 0,1 | 0,086 | 0,11 | 0,1 | 0,12 | 0,225 | 0,21 | 0,15 | 0,12 | 0,12 | 0,106 | 0,159 |
0,150 0,16 0,165 |
Если по горизонтальной оси отложить количество испытаний, а по вертикальной - средние арифметические значения относительных частот, то видно, что частота появления «5» колеблется около некоторого числа, приблизительного равного 1/6 ≈ 0,167 . Р(«5») = 0,167 = 1/6. В процессе этого испытания мы переходили к сериям с постепенно возрастающим числом испытаний, в результате видим, что частота появления события сосредотачивается вокруг некоторого числа (1/6) это число и назовём вероятностью выпадения цифры «5» на игральном кубике.
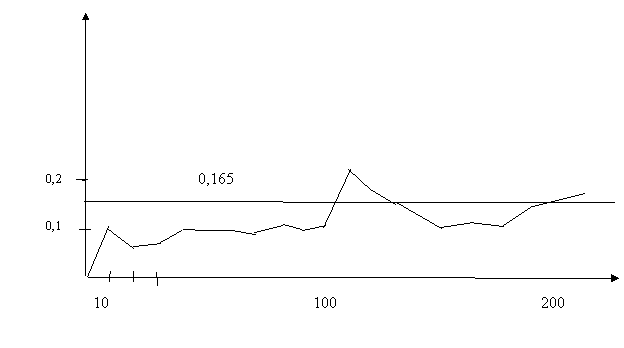

Полезно после рассмотрения этого примера обратить внимание учащихся на тот факт, что относительная частота выпадения любой цифры на гранях кубиков принимает приблизительно одинаковые значения и группируется около числа 1/6. Событие выпадения любой из шести цифр, расположенных на гранях кубика, равновозможные (равновероятны).
№2
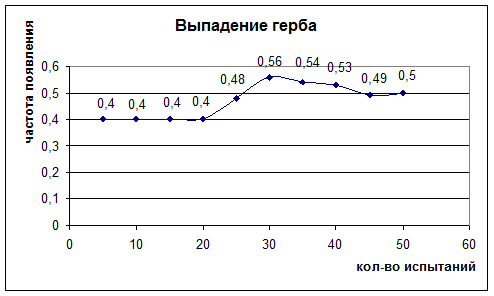
Частота выпадения герба при увеличении количества испытаний сосредотачивается около числа 0,5. Это число и называют вероятностью события, обозначают вероятность буквой Р (г) = 0,5
Вероятностью события А называется число р, около которого сосредотачиваются значения относительных частот наступления события А при возрастании числа испытаний.
Функция распределения.
Статистическое определение вероятности удобно для введения аксиом:
Ø Вероятность исхода испытаний неотрицательна.
Ø Сумма вероятностей всех исходов испытаний равна 1.
Ø Вероятность случайного события равна сумме вероятностей исходов испытания, благоприятствующих появлению события.
В то же время статистическое определение вероятности обладает рядом недостатков:
Ø она определена для конечного числа событий;
Ø не раскрывает первоначального комплекса условий;
Ø определяется только по результатам проведённого опыта.
. Использование статистического определения вероятности подчеркивает её органическую связь с практикой, с проблемами реального мира. Основанием успешного использования вероятностных методов на практике является одна удивительная особенность окружающей нас действительности – статистическая устойчивость различных величин. Понятие вероятности возникло как отражение этой устойчивости и, естественно применять его нужно в тех ситуациях, когда эта устойчивость проявляется. Трудность заключается в том, что нет в науке общих методов, позволяющих решить вопросы о существовании статистической устойчивости характеристик тех или иных явлений.
Противоречие возникло у практиков в связи с тем, что эти понятия вероятности можно применить только для конечного числа исходов, а часто таких исходов может быть бесконечно много (количество точек, в которые может попасть снаряд, впускаемый из орудия). Было предложено рассматривать вероятность как меру, и огромная роль в решении этого вопроса принадлежит Колмогорову, он дал наиболее удачное аксиоматическое обоснование теории вероятностей, в результате чего эта теория окончательно укрепилась как математическая дисциплина.
При рассмотрении случайных величин естественно давать им числовые характеристики, одной из основных является вероятность события.
Набор вероятностей р1, р2, …,рп - называют распределением вероятностей, содержит исчерпывающую информацию о случайной величине.
Однако на практике во многих случаях знание вероятностей необязательно. Достаточно знать две наиболее важные характеристики случайной величины - её математическое ожидание и дисперсию.
Распределение дискретной случайной величины.
Пусть дискретная случайная величина может принимать п –значений х1, х2, …хп. Для полной характеристики этой случайной величины должны быть заданы ещё и вероятности появления указанных значений: р1, р2,…рп.
Для дискретной так же как и для непрерывной случайной, величины вводится функция распределения, которая представляет собой вероятность события Х< х, где х - задаваемые непрерывно меняющиеся значения. F(x) = P(X<x)
В некоторых случаях целесообразно использовать не таблицу или функцию распределения случайной величины, а некоторые числовые характеристики её распределения. К их числу относится математическое ожидание.
Математическим ожиданием дискретной случайной величины Х называется сумма произведений всех её значений на соответствующие вероятности
М(Х) = Мх = х1 р1 + х2 р2 +….+ хп рп= ∑ хi pi
i=1
Математическое ожидание называют также средним значением случайной величины, учитывая то, что каждое значение величины входит в выражение с соответствующим «весом», которым и является вероятность. В частном случае, когда все значения хi равновероятны то есть рi = 1/п, математическое ожидание будет равно среднему арифметическому всех возможных значений:
п
Мх = 1/п ∑ хi
1
Математическое ожидание случайной величины - это постоянная величина. Оно означает, какое значение случайной величины можно ожидать в среднем при проведении серии испытаний.
Дисперсией случайной величины Х называется математическое ожидание квадрата уклонения её от математического ожидания самой величины
Dx= M(X-Mx)2
Dx= M(X2)-Mx2
Дисперсию случайной величины можно вычислить как разность математического ожидания квадрата величины и квадрата математического ожидания самой величины.
Чтобы измерить разброс ряда данных, или как ещё говорят величину рассеивания данных вокруг среднего арифметического, вычисляют не сами отклонения, а их квадраты. Находят среднее арифметическое этих квадратов и получившееся значение называют выборочной дисперсией ( от латинского слова dispersio, означающего рассеивание).
Однако среднее квадратичное имеет один существенный недостаток: если среднее арифметическое выражается в тех же единицах, что и сами данные, то дисперсия выражается уже в квадратных единицах. Чтобы устранить этот недостаток, в качестве меры рассеивания ряда данных принято рассматривать квадратный корень из дисперсии, который называют средним квадратичным отклонением и обозначают греческой буквой σ. Чебышев Пафнутий Львович доказал теорему, которая имеет огромное практическое применение. Она утверждает, что для любой случайной величины вероятность отклонения от среднего значения µ не более чем на 2σ не меньше 3/4.Теоретические исследования показали, что в большом числе встречающихся на практике случаев можно ожидать нормального закона распределения.
В 1657 году была издана первая книга по теории вероятностей, написанная Гюйгенсом, основное достижение этой работы состоит в том, что автор заметил нормальный закон распределения вероятностей. Позднее этот закон был выражен формулой, а его график назвали колоколом Гюйгенса. См. приложение №2.
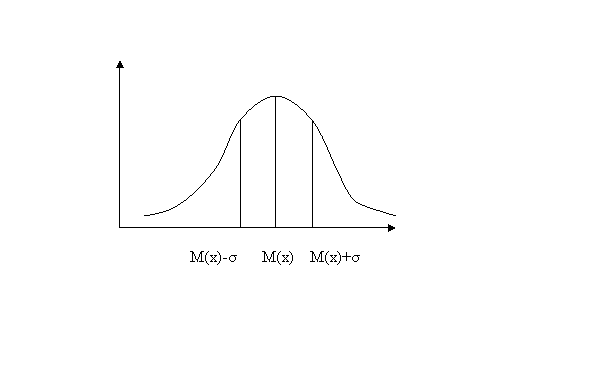

Применение статистики к решению экономических задач.
Проведение экономических исследований, оценка хозяйственной деятельности предприятий, микро - и макроэкономических показателей
, прогноз этих показателей на будущее невозможны без использования математического аппарата теории вероятностей и математической статистики. Этот аппарат позволяет получать наиболее вероятные количественные значения экономических показателей, устанавливать связь между различными, случайными параметрами и принимать обоснованные решения в экономике.
К настоящему времени разработано достаточное количество учебников и учебных пособий по теории вероятностей и математической статистике с глубоким обоснованием основных теоретических положений.
Вероятностным событием будем называть некоторое явление, которое происходит в результате действия определённых закономерностей, имеющих объективную природу, но не всегда поддающихся полномасштабному описанию и всесторонним измерениям. Возникновение таких событий характеризуется совокупностью условий, при которых они могут произойти или не произойти. В силу этого они получили наименование случайных событий.
В экономике, так же как и в других сферах человеческой деятельности, очень важно предугадывать или предвидеть исход каких либо процессов, их связь. На основе многолетних наблюдений экономисты сделали выводы, что большинство наблюдаемых явлений подчинены нормальному закону распределения вероятностей. На основе этих наблюдений делаются прогнозы развития предприятий, строится стратегия действий на ближайшее время.
Выводы.
Получив статистические данные по АПКФ за год, проанализировав эти данные, я просчитала математическое ожидание по некоторым показателям на 2008 год и по результатам этих вычислений сделала соответствующие выводы:
1.Агропромышленный комплекс стабильно получает прибыли по всем направлениям своей работы: выручка от зерновых, от продажи молока, от продажи мяса.
2.Существуют перспективы развития данного хозяйства за счет увеличения пахотных земель и поголовья скота.
3.У молодых специалистов есть перспектива вернуться в свое родное село и найти достойную, хорошо оплачиваемую работу и своей творческой деятельностью способствовать развитию инфраструктуры родного села.
Приложение
Статистическая обработка данных.
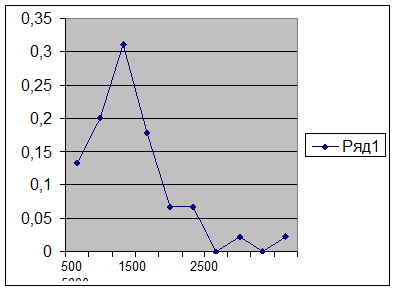
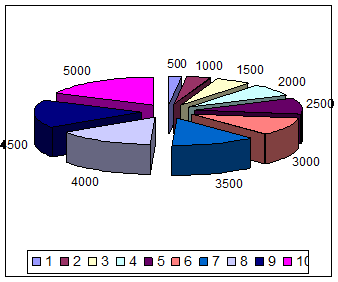
Приложение .
Нормальный закон распределения.
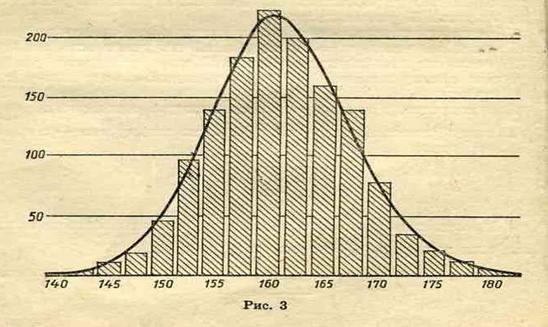

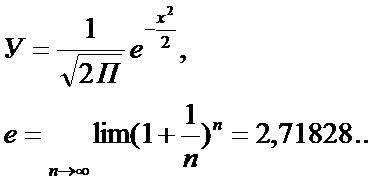 Уравнение колокообразной кривой
Уравнение колокообразной кривой
Приложение .
Математическое ожидание по надою молока за 2006 год.
6800 | 6900 | 7000 | 7100 | 7200 | 7300 | 7400 | |||||
0,05 | 0,05 | 0,1 | 0,4 | 0,25 | 0,1 | 0,05 |
| ||||
340 | 345 | 700 | 2840 | 1800 | 730 | 370 | 7125 | 2006г | 7200кг. |
На 2007 год.
7100 | 7200 | 7300 | 7400 | 7500 | 7600 | ||||||
0,05 | 0,2 | 0,4 | 0,2 | 0,1 | 0,05 |
| |||||
355 | 1440 | 2920 | 1480 | 750 | 380 | 7325 | 7687,5кг. |

Математическое ожидание выручки и прибыли от продажи молока.
 |
34200 | 34400 | 34600 | 34800 | 35000 | 35200 | ||||||
0,05 | 0,1 | 0,2 | 0,4 | 0,2 | 0,05 | ||||||
1710 | 3440 | 6920 | 13920 | 7000 | 1760 | 34750 |
| ||||
10800 | 11000 | 11200 | 11400 | 11600 | 11800 |
| |||||
0,05 | 0,15 | 0,1 | 0,2 | 0,3 | 0,2 | ||||||
540 | 1650 | 1120 | 2280 | 3480 | 2360 | 11430 |

Математическое ожидание прибыли от продажи молока в году.
 |
12800 | 13000 | 13200 | 13400 | 13600 | ||||||
0,1 | 0,2 | 0,4 | 0,2 | 0,1 | ||||||
1280 | 2600 | 5280 | 2680 | 1360 | 13200 | |||||
| ||||||||||
19900 | 20000 | 20100 | 20200 | 20300 | ||||||
0,1 | 0,2 | 0,4 | 0,2 | 0,1 | ||||||
1990 | 4000 | 8040 | 4040 | 2030 | 20100 |

По таблице видно, что разница между математическим ожиданием и фактом составляет 6930 тыс. руб. Это обусловлено резким повышением цен на молоко в августе 2007 года.
