

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 Вариант 15. Лабораторная работа №3. Модели стационарных рядов – ARMA и нестационарных – ARIMA.
Вариант 15. Лабораторная работа №3. Модели стационарных рядов – ARMA и нестационарных – ARIMA.
Задание 1. Для TS рядов, по результатам ADF – теста, из Лабораторной работы №1 построить модели ARMA, если необходимо – исключить линейный тренд.
Для TS рядов, по результатам ADF – теста, из Лабораторной работы №1 построим модели ARMA, по заданию также надо исключить линейный тренд, если это необходимо. Итак, в первой лабораторной работе были получены три TS-ряда (т. е. стационарных) - для цепной индексной формы исходного временного ряда (дебет доходов), индексной формы по отношению к соответствующему периоду предыдущего года и формы с нарастающим итогом к соответствующему периоду предыдущего года. А также два DS-ряда (разностно-стационарных, т. е. интегрированных определенного порядка, в нашем случае порядка 1 (первые разности)) - для индексной базисной формы и для самого исходного временного ряда.
Исследуем TS-ряды. При построении авторегрессионных моделей со скользящим средним ARMA(p, q) для определения параметров p и q используются автокорреляционная функция ACF и частичная автокорреляционная функция PACF. Пусть Р(k) – значение функции ACF, а Рpart(k) - значение функции РACF.
1) Цепная форма исходного ряда:
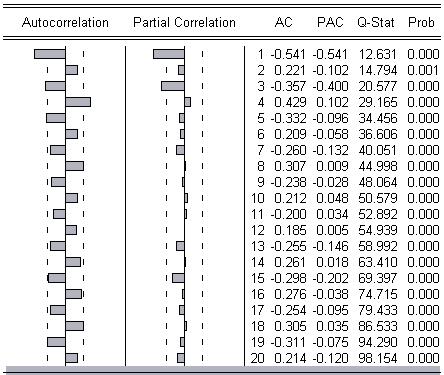
По данной кореллограмме видно, что наблюдается приближение функции Р(k) к нулю при k>4, при этом не важно как ведет себя Рpart(k). Следовательно, можно построить модель МА(4). Такая модель получилась:
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 1.135322 | 0.095950 | 11.83241 | 0.0000 |
MA(4) | 0.410803 | 0.148776 | 2.761228 | 0.0008 |
R-squared | 0.176668 | Mean dependent var | 1.133570 | |
Adjusted R-squared | 0.155002 | S. D. dependent var | 0.477400 | |
S. E. of regression | 0.438844 | Akaike info criterion | 1.239362 | |
Sum squared resid | 7.318201 | Schwarz criterion | 1.323806 | |
Log likelihood | -22.78724 | F-statistic | 8.153933 | |
Durbin-Watson stat | 2.813685 | Prob(F-statistic) | 0.006926 |
2) Индексная форма по отношению к соответствующему периоду предыдущего года:
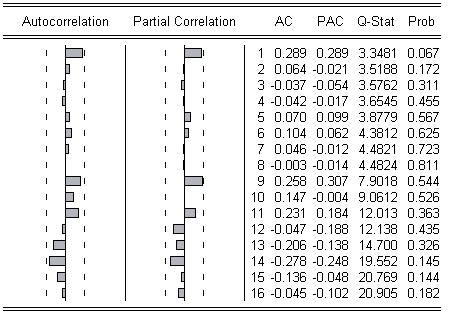
По данной кореллограмме видно, что функция Р(k)=0 и Рpart(k)=0 при любых k. Следовательно, это белый шум МА(0) - случайный процесс и моделировать его бесполезно.
3) Индексная форма с нарастающим итогом к соответствующему периоду предыдущего года:
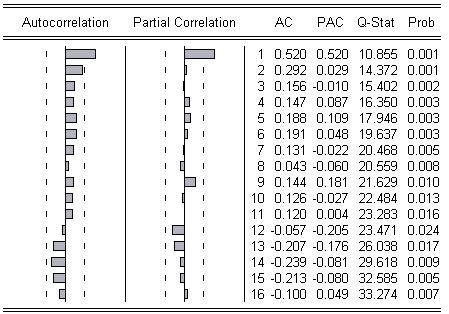
По данной кореллограмме видно, что функция Р(1)=0 и далее при всех остальных k>1 P(k) осцилирующе убывает, а Рpart(1)=Р(1) и далее при любых k>1 экспоненциально убывает. Следовательно, это соответствует модели ARMA (1,1).
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
AR(1) | 1.002963 | 0.021008 | 47.74181 | 0.0000 |
MA(1) | -0.675689 | 0.134708 | -5.015945 | 0.0000 |
R-squared | 0.179397 | Mean dependent var | 1.161094 | |
Adjusted R-squared | 0.155261 | S. D. dependent var | 0.447571 | |
S. E. of regression | 0.411361 | Akaike info criterion | 1.115261 | |
Sum squared resid | 5.753403 | Schwarz criterion | 1.203234 | |
Log likelihood | -18.07469 | Durbin-Watson stat | 1.573056 |
Задание 2. Для DS рядов, по результатам ADF – теста, из Лабораторной работы №1 построить модели ARIMA, если необходимо – исключить линейный тренд.
Теперь приступим к исследованию DS-рядов.
4) Исходный временной ряд:
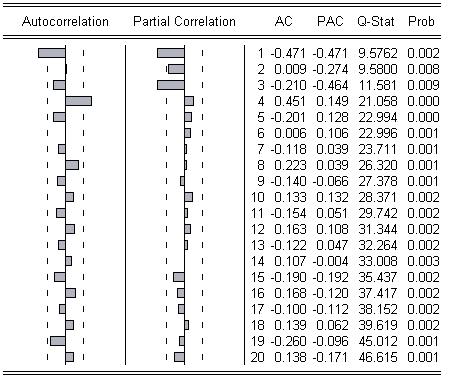
По данной кореллограмме видно, что наблюдается зануление функции Р(k) при k>4, при этом не важно как ведет себя Рpart(k). Следовательно, можно построить модель МА(4). Такая модель получилась:
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | -31.20324 | 3.453301 | -9.035770 | 0.0000 |
MA(4) | 0.836357 | 0.089805 | 9.312989 | 0.0000 |
R-squared | 0.409448 | Mean dependent var | -29.36341 | |
Adjusted R-squared | 0.394305 | S. D. dependent var | 15.71839 | |
S. E. of regression | 12.23306 | Akaike info criterion | 7.893712 | |
Sum squared resid | 5836.262 | Schwarz criterion | 7.977301 | |
Log likelihood | -159.8211 | F-statistic | 27.03985 | |
Durbin-Watson stat | 0.907136 | Prob(F-statistic) | 0.000007 |
5) Индексная базисная форма:
По данной кореллограмме видно, что наблюдается приближении функции Р(k) к нулю при k>4, при этом не важно как ведет себя Рpart(k). Следовательно, можно построить модель МА(4). Такая модель получилась:
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
C | 1.405551 | 0.155554 | 9.035770 | 0.0000 |
MA(4) | 0.836357 | 0.089805 | 9.312989 | 0.0000 |
R-squared | 0.409448 | Mean dependent var | 1.322676 | |
Adjusted R-squared | 0.394305 | S. D. dependent var | 0.708036 | |
S. E. of regression | 0.551039 | Akaike info criterion | 1.693527 | |
Sum squared resid | 11.84210 | Schwarz criterion | 1.777116 | |
Log likelihood | -32.71731 | F-statistic | 27.03985 | |
Durbin-Watson stat | 0.907136 | Prob(F-statistic) | 0.000007 |
Во всех моделях проведена проверка статистической значимости коэффициентов при независимых переменных, причем ни в одной из моделей тренд не был статистически значим, поэтому и был исключен. Также в некоторых моделях константа была не значима, поэтому она также была исключена.
Задание 3. По моделям из п.1 и 2 построить прогноз показателя на 2 года вперед и сравнить с прогнозами, построенными в Лабораторной работе № 2.
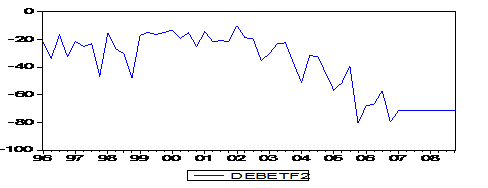
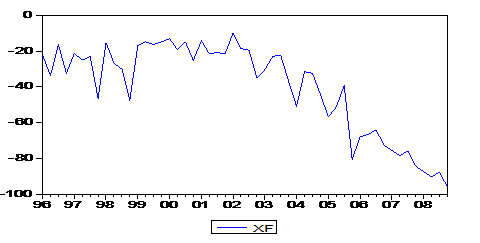
Построим прогноз исходного показателя на два года вперед (то есть прогноз модели начиная со 2 квартала 2006 года до 4 квартала 2008 года) и сравним данный прогноз с прогнозом, полученным в Лабораторной работе №2. Как видно из рисунка, они довольно-таки отличаются. Однако трудно сказать, который из них лучше. Модель МА(4), построенная в данной лабораторной работе, не учитывает тренда, но ее достоинство - в учете лагов (предыдущих значений зависимой переменной). Модель из лабораторной работы №2 учитывает сезонность и выбросы, а также тренд. Пожалуй, наиболее правильным было построить объединенную модель, учитывающую все данные факторы.
Модель из лабораторной работы №3:
Модель из лабораторной работы №2:
Сравнение прогнозов
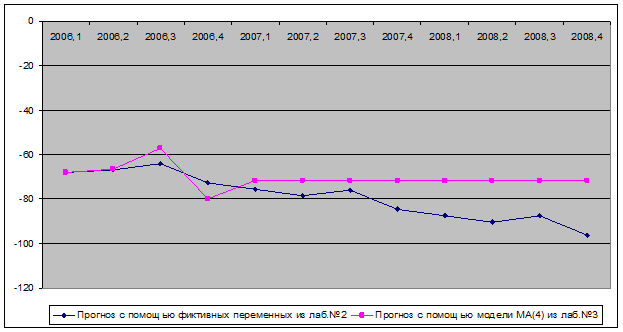
Итак, построены два прогноза на период 2006 г. 2 квартал – 2008 г. 4 квартал. Как видно из графиков и числовых представлений прогноза значения существенно отличаются. Такое различие прогнозов можно объяснить отличием построения моделей и учетом в них разных факторов. Так, в лабораторной работе 2 были учтены изменения тренда, выбросы (введены соответствующие фиктивные переменные). В данной лабораторной работе строена модель MA(1) с учетом исключения незначимых тренда и константы. Установить, какой прогноз является более точным сложно.
