
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Виды шкал
Измерение – это приписывание числовых форм объектам. Выделяют 4 типа измерительных шкал.
Номинативная (номинальная, категориальные) Номинативная шкала – это шкала, в которой не выражены количественные характеристики объектов. Учитывается только то свойство объектов, что они разные. Порядковая (ранговая, ординальная) позволяет ранжировать объекты (присваивать им ранги) по какому-либо признаку. Интервальная это шкала, классифицирующая по принципу «больше (меньше) на определенное количество единиц». Шкала отношений шкала, классифицирующая по принципу «больше (меньше) в определенное количество раз.Типы данных
Данные – это основные элементы, подлежащие классифицированию или разбитые на категории с целью обработки. Выделяют три типа данных:
Метрические данные: количественные данные, получаемые при измерениях. Их можно распределить на шкале интервалов или отношений. Ранговые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке. Эти данные можно представить в виде порядковой шкалы. Номинативные данные: категориальные (качественные) данные, представляющие собой особые свойства элементов выборки. Например, цвет глаз у испытуемых. Эти данные нельзя измерить, но можно оценить их частоту встречаемости.Правила ранжирования
Правило порядка ранжирования. Надо решить, кто получает первый ранг: объект с самой большей степенью выраженности какого-либо качества или наоборот.
Правило связанных рангов. Объектам с одинаковой выраженностью свойств приписывается один и тот же ранг.
Тема 2 Описательные статистики
Меры центральной тенденции
Мода – это наиболее часто встречающееся значение в ряду данных.
Среднее арифметическое – это отношение суммы всех значений данных к числу слагаемых.
Медиана разбивает выборку на 2 равные части. Для определения медианы рекомендуется сначала упорядочить данные.
Меры изменчивости
Размах – это разница между максимальным и минимальным значениями.
Р = Хmax – Xmin
Дисперсия – это мера разброса данных относительно среднего значения. Если вычисление дисперсии производится вручную, то рекомендуется пользоваться специальной таблицей.
![]()
Стандартное отклонение представляет собой квадратный корень из дисперсии. По ряду причин этот показатель является более удобным, чем дисперсия.
![]()
Нормальное распределение( распределением Гаусса)
Характеризуется тем, что крайние значения признака в нем встречаются достаточно редко, а значения, близкие к средней величине – часто. Нормальное распределение имеет колоколообразную форму, значения моды, медианы и среднего арифметического равны между собой. Было установлено, что многие биологические параметры распределены подобным образом (рост, вес, показатели интеллекта, темпераментных особенностей, способностей и другие психические явления и так далее).
Асимметрия и эксцесс. Проверка нормальности распределения.
Асимметрия – это показатель симметричности / скошенности кривой распределения, а эксцесс определяет ее островершинность. У всех симметричных распеделений (в том числе и у нормального распределения) величина асимметрии равна нулю.
Формула асимметрии: ![]()
Формула эксцесса: ![]()
Распределение считается достоверно нормальным если абсолютная величина показателей асимметрии и эксцесса меньше их ошибок репрезентативности (от фр. в 3 и более раз.
Формулы приближенных вычислений
Если выборка достаточно большая, а данные подчиняются закону нормального распределения, то можно очень быстро вычислить приблизительные значения среднего арифметического и стандартного отклонения по следующим формулам:
![]()
![]()
n | 2 - 5 | 6 - 15 | 16 - 49 | 5 | > 1000 | |
K | 2 | 3 | 4 | 5 | 6 | 7 |
Тема 3 Первичное описание исходных данных
Таблицы кросс-табуляции используются для анализа номинативных данных и указывают частоту встречаемости явления.
Вариационый ряд – сгруппированные элементы выборки на однородные группы по некоторому признаку.
Графики (называются также диаграммами, полигонами, гистограммами) – это чертежи, которые можно использовать для наглядности распределения количественно выраженной величины в выборке.
Тема 4 Основные понятия математической статистики
Статистическая значимость
Уровень достоверности (статистическая значимость) результата исследования (так называемый р - уровень) – это выраженная количественно степень уверенности, что полученные результаты можно распространить на всю популяцию.
0,1 > р | результаты статистически незначимы |
0,05 < р £ 0,1 | результаты значимы на уровне тенденции |
р £ 0,05 | результаты статистически значимы |
р £ 0,01 | результаты на уровне высокой статистической значимости |
Статистические гипотезы
1)Ненаправленные говорят о наличии-отсутствии различий
2)Направленные Они говорят не о простом наличии-отсутствии различий, но и об их направлении.
1)Нулевая гипотеза (обозначается как H0) – это гипотеза об отсутствии различий между какими-либо показателями.
2)Альтернативная гипотеза (обозначается как H1) – это гипотеза о наличии различий у этих показателей.
Зависимые и независимые выборки
Зависимые выборки содержат результаты, полученные на одной и той же группе испытуемых, но в разные моменты времени. Например, до и после стимульного воздействия. Количество объектов в этих выборках всегда одинаковое.
Независимые выборки получаются при исследовании двух различных групп испытуемых. Например, это экспериментальная и контрольная группы. Допускается, чтобы количество объектов в них было различным.
Степени свободы
В таблицах критических значений приводятся или показатели объема выборки, или показатели степеней свободы. Степень свободы (обозначается как df или ν)это величина производная от объема выборки (обозначаемой буквой n). Вопрос о степени свободы всегда возникает при сравнении выборок. Если мы не определили этого параметра, то мы не сможем пользоваться таблицами.
Классификация и назначение критериев
1)Параметрические критерии включают в формулу расчета среднее арифметическое и дисперсии и применяются при анализе метрических данных, вписывающихся в кривую нормального распределения.
2)Непараметрический критерий рекомендуется использовать также для анализа метрических данных, распределение которых значительно отличается от нормального. При этом метрические данные следует перевести в ранговые.
Параметрические критерии | Непараметрические | |
Определение согласованности изменений (корреляция) | R (коэффициент корреляции Пирсона) | rs (коэффициент корреляции Спирмена) τ (коэффициент корреляции тау-Кендалла) C (коэффициент сопряженности С-Пирсона φ (коэффициент фи-корреляции) |
Сравнение эмпирической и теоретической частот | χ2 (критерий хи-квадрат) | |
Оценка достоверности | t-критерий Стьюдента для независимых выборок | U-критерий Манна-Уитни |
Оценка достоверности различий при повторных измерениях | t-критерий Стьюдента для зависимых выборок | T-критерий Вилкоксона |
Анализ изменений признака | Дисперсионный анализ |
Тема 5 Исследование взаимосвязи признаков
Понятие корреляции
Корреляция – это согласованность изменения признаков. Если два явления изменяются синхронно и эти изменения можно выразить количественно, то между показателями этих явлений будет наблюдаться корреляция.
1)Линейная корреляция. Линейную корреляцию можно количественно измерить. Степень связи между признаками выражается величиной, называющейся коэффициентом корреляции. Значения данного коэффициента (обозначается чаще всего буквой R или r) могут находиться в диапазоне от +1 до –1.
2)Нелинейная корреляция. Нелинейной может быть, например, связь между уровнем мотивации и эффективностью выполнения задачи
Классификация коэффициентов корреляции по значимости.
Высокозначимая корреляция | r соответствует уровню статистической значимости p ≤ 0,01 |
Значимая корреляция | r соответствует уровню статистической значимости p ≤ 0,05 |
Незначимая корреляция | r не достигает уровня статистической значимости p>0,1 |
Тема 6 Линейная корреляция
Коэффициент линейной корреляции
Коэффициент корреляции Пирсона называется также коэффициентом линейной корреляции или произведением моментов Пирсона. Он позволяет определить силу связи между двумя признаками, измеренными в метрических шкалах.
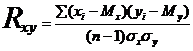
Тема 7 Ранговая корреляция
Вычисление ранговой корреляции позволяет определить силу и направление корреляционной связи между двумя признаками, измеренными в ранговой шкале или между двумя иерархиями признаков.
Вычисление ранговой корреляции по Спирмену
rs = 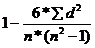
Вычисление ранговой корреляции по Кендаллу
![]()
Коэффиицент ранговой корреляции Кендалла, называемому также τ–Кендалла (тау Кенделла) основан на определении числа «совпадений» и «инверсий». Столбец с первым рядом значений упорядочивается, то есть сортируется по возрастанию. После этого анализу подвергается только второй столбец. Для каждого значения из второго ряда определяется:
1)Сколько рангов расположенных ниже анализируемого ранга выше него по значению (результат заносится в дополнительный столбец, обозначенный символом Р);
2)Сколько рангов расположенных ниже анализируемого ранга меньше него по значению (результат заносится в следующий столбец, обозначенный символом Q).
Тема 8 Сравнение распределений
Использование критерия c2 позволяет ответить на вопрос: с одинаковой ли частотой встречаются разные значения признака в эмпирическом и теоретическом распределениях или в нескольких эмпирических распределениях.
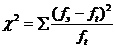
Коэффициент многоклеточной сопряженности С-Пирсона есть характеристика силы связи между номинативными переменными. Величина этого коэффициента варьируется в диапазоне от 0 (абсолютное отсутствие связи) до +1 (абсолютная положительная связь). Его формула выглядит следующим образом:
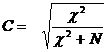
Тема 9 Оценка достоверности различий
t-критерий для несвязанных (независимых) измерений
Для оценки достоверности различий в выборках, то есть фактически для их сравнения, при работе с данными, измеренными в метрических шкалах, чаще всего используют t-критерий Стьюдента. Это мощный параметрический критерий, дающий достоверные результаты даже если выборка мала:
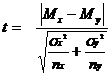
U-критерий Манна-Уитни
Непараметрический U-критерий Манна-Уитни позволяет оценить достоверность различий в независимых выборках, если данные в них представлены в ранговой шкале. Данный критерий следует применять и в том случае, если данные представлены в метрических шкалах, но не укладываются в кривую нормального распределения. При этом следует обратить на ограничения в использовании критерия: в каждой выборке должно быть не менее 3 и не более 60 наблюдений:
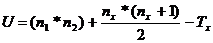
где n1 – объем первой выборки; n2 – объем второй выборки; Тх – большая из ранговых сумм; nx – объем группы с большей суммой рангов.
Тема 10 Оценка достоверности различий при повторных измерениях
t-критерий для связанных (зависимых) измерений
С целью оценки достоверности сдвига значений в зависимых выборках используют t-критерий Стьюдента для зависимых измерений. Критерий для связанных выборок имеет следующую формулу:
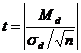 ,
,
Т-критерий Вилкоксона (ранговый критерий для повторных измерений)
Т-критерий Вилкоксона используется для решения тех же задач, что и t-критерий Стьюдента для связанных выборок. Отличие состоит в том, что Т-критерий Вилкоксона можно применять для порядковых данных, и исходные распределения не обязательно должны быть нормальными.
Тема 11 Использование математического аппарата при описании группового поведения
Математический аппарат может активно использоваться при обработке результатов социометрического, референтометрического и других видов исследований.
Тема 12 Дисперсионный анализ
Дисперсионный анализ – это анализ изменчивости признака под влиянием какого-либо фактора или совокупности факторов. Метод основан на разложении общей дисперсии (вариативности) на составляющие компоненты, сравнивая которые можно определить долю общей вариации изучаемого признака, обусловленную действием на него как регулируемых, так и неучтенных в опыте факторов.
Принято выделять однофакторный и многофакторный виды дисперсионного анализа.
1)Однофакторный дисперсионный анализ - дисперсия разлагается на две составные части: дисперсию, связанную с изменением внутригрупповых средних значений и случайную дисперсию.
2)Многофакторный дисперсионный анализ – дисперсия разлагается на ряд частей: дисперсии, обусловленные воздействием каждого фактора по отдельности; дисперсии, обусловленные воздействием парных сочетаний факторов; случайную дисперсию.
SSобщ -общая сумма квадратов
SSмг – межгрупповая сумма квадратов, обусловленная взаимодействием факторов.
SSвг - внутригрупповая сумма квадратов, рассчитывается для каждого фактора.
SSслуч – сумма квадратов соответствующая случайному рассеиванию
MS – средняя сумма квадратов
Тема 13 Методы многомерного статистического анализа
Корреляционный анализ
Процедура корреляционного анализа предполагает подготовку таблицы данных (называется также матрицей наблюдения), где в первом столбце приводятся коды или фамилии испытуемых, а последующие столбцы содержат значения зарегистрированных признаков.
Дальнейший этап – составление матрицы интеркорреляций. При этом исходные данные должны быть измерены в метрических шкалах.
Следующий этап заключается в маркировке соответствующим числом звездочек (цветов маркера) тех значений коэффициентов, которые статистически значимо отличаются от нуля (р £ 0,05, 0,01, 0,001).
Затем следует построение корреляционного графа. На чертеже представляются отдельные качества, измеренные субтестами, при этом коррелирующие качества соединяются линиями. Фрагмент графа называется корреляционной плеядой.
Факторный анализ
Матрица наблюдений может содержать несколько сотен строк, в соответствии с числом наблюдаемых объектов. В этом случае корреляционный анализ, ввиду больших размеров, становится неэффективным. Возникает потребность «ужать» информацию и описать явление малым числом обобщающих факторов, которые непосредственно не наблюдаются, но характеризуют явление. Такое свертывание информации и выделение главных факторов реализуется методами факторного анализа. Методика его проведения вручную в данном пособии не приводится, так является весьма трудоемкой процедурой. Для проведения анализа рекомендуется использовать компьютерные программы, такие как Statistica, Stadia или SPSS.
Кластерный анализ
Кластерный (таксономический) анализ используется с целью упорядочивания объектов и объединения их в однородные разряды. В результате исходная выборка объектов разделяется на группы схожих между собой объектов, называемых кластерами. Кластер – это группа объектов, характеризующихся повышенной плотностью (сгущенность внутри разряда) и дисперсией.
Тема 14: F - критерий Фишера
F - критерий Фишера используют для сравнения дисперсий двух вариационных рядов. Он вычисляется по формуле:
F= Сигма1 в квадрате/Сигма2 в квадрате
где - Сигма1 в квадрате большая дисперсия, Сигма2 в квадрате - меньшая дисперсия.
Если вычисленное значение критерия F больше критического для определенного уровня значимости и соответствующих чисел степеней свободы для числителя и знаменателя, то дисперсии считаются различными.
Число степеней свободы числителя определяется по формуле:
Степень свободы1 = n1-1, где n1 – число вариант для большей дисперсии
Степень свободы2 = n2-1, где n2 – число вариант для меньшей дисперсии
Глоссарий
t-критерий – параметрический критерий статистического вывода, используемый: 1) для определения достоверности различий между выборками; 2) для определения достоверности сдвига значений в результате стимульного воздействия.
T-критерий Вилкоксона - непараметрический критерий статистического вывода, применяемый для оценки результативности сдвига значений в результате стимульного воздействия.
U-критерий Манна-Уитни - непараметрический критерий статистического вывода, применяемый для оценки различия между двумя выборками при использовании ранговых данных.
Абсцисса – горизонтальная ось графика, на которой чаще всего фиксируют степень выраженности независимой переменной.
Альтернативная гипотеза – статистическая гипотеза о наличии различий между показателями.
Бимодальное распределение – распределение частот, имеющее две моды (точки максимума по сравнению с соседними значениями).
Вариационыый ряд – упорядоченное отражение распределение значений признака. Представляет двойной ряд чисел, состоящий из обозначения классов и соответствующих частот.
Гистограмма – столбиковая диаграмма. Абсцисса (горизонтальная ось ) служит для фиксации степени выраженности, а ордината (вертикальная ось) – для фиксации частоты.
Дисперсия – мера разброса распределения значений вокруг среднего арифметического.
Корреляция – связь между двумя переменными. Корреляция характеризуется направлением, силой связи и уровнем достоверности этой связи.
Коэффициент корреляции – число, отражающее силу и направление связи между двумя переменными. К. к. бывают достоверные и недостоверные (т. е. случайные).
Коэффициент сопряженности – показатель силы связи между двумя рядами чисел номинативной шкалы.
Криволинейная функция - функция, график которой отклоняется от прямой линии и содержит компоненты, которые могут быть описаны исключительно математическими формулами для кривых линий.
Критерий хи-квадрат - параметрический критерий статистического вывода, используемый для определения: 1) отличается ли статистически наблюдаемая частота от другой эмпирической частоты; 2) отличается ли наблюдаемая частота от равномерного распределения.
Кумулята (кумулятивная кривая) – изображение распределения в виде кривой, ординаты которой пропорциональны накопленным частотам вариационного ряда.
Линейная функция – функция, график которой образует прямую линию.
Математическое моделирование – процедура описания различных процессов (в том числе и социально-психологических) посредством математического аппарата. Указанная процедура включает в себя выделение всех факторов процесса, определение доли вклада каждого из факторов, выявление закономерностей их функционирования и вероятностное предсказание протекания всего процесса в дальнейшем.
Медиана – среднее значение в выборке. Для определения медианы необходима операция упорядочивания выборки.
Мода – значение выборки, встречающееся наиболее часто. Распределения бывают одномодальными (с одной модой), бимодальными (с двумя модами) и полимодальными (с большим количеством значений моды).
Нейронная сеть – вычислительная система, автоматически формирующая описание характеристик случайных процессов (прогноз поведения потребителя, предсказание ситуации на рынке, анализ товарных потоков и т. д.), имеющих сложные функции распределения.
Непараметрический критерий - критерий статистического вывода, не требующий допущения о нормальности распределения признака.
Нормальное распределение – распределение частот, характеризующееся колоколообразной формой графика, одномодальностью,
Нулевая гипотеза – статистическая гипотеза об отсутствии симметричностью, равенством среднего арифметического, медианы и моды. Большинство психологических свойств имеют нормальное распределение. различий между показателями.
Ордината – вертикальная ось графика, на которой чаще всего фиксируют частоту встречаемости конкретного уровня выраженности переменной.
Параметрический критерий - критерий статистического вывода, требующий допущения о нормальности распределения признака.
Размах – разница между наименьшим и наибольшим значением в выборке.
Репрезентативность – возможность распространить полученные на ограниченной выборке выводы на всю генеральную совокупность.
Стандартное отклонение – мера разброса распределения частот. Численно равна квадратному корню из дисперсии.
Статистическая значимость – количественный показатель вероятности, что полученные результаты неслучайны. Результаты считаются неслучайными и достоверными, если количественный показатель статистической значимости не превышает 0,05.
Шкала – отрезок, содержащий совокупность отметок (цифр) для фиксации последовательных значений измеряемой величины. Шкалы бывают номинативные, порядковые, метрические (интервальные и пропорциональные).
