
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Оглавление
Введение. 1
Глава 1. Классический метод. 3
Глава 2. Графики для классических моделей. 5
Глава 3. Метод максимального правдоподобия. 6
Глава 4. Байесовская оценка. 8
Глава 5. Проверка гипотез. 10
Глава 6. Нахождение доверительного интервала. 11
Введение
Для начала определим, что есть за раздел математическая статистика, познакомимся с основными понятиями и объясним для чего она нужна. Математическая статистика – раздел математики, в котором изучаются методы сбора, систематизация и обработка результатов наблюдений массовых случайных величин для выявления существующих закономерностей. Сбор: Методы математической статистики позволяют не только анализировать имеющиеся статистические данные, но и, например, до начала сбора статистических данных выбрать наилучшую структуру и способ сбора данных. Обработка: В отличие от теории вероятностей, которая исследует математические модели случайных явлений, математическая статистика предлагает, в частности, методы, позволяющие определить, какая математическая модель лучше соответствует имеющимся статистическим данным. Методы математической статистики позволяют выявить существенные и несущественные, с той или иной точки зрения, составляющие в данных, представить данные в удобной для интерпретации форме. Интерпретация: Методы математической статистики позволяют, основываясь на выбранной математической модели, построить оценки для неизвестных параметров модели, проверить справедливость тех или иных предположений о модели, построить прогноз или предложить решение.
Теория вероятности тесно связана с математической статистикой. Мы живем в мире, в котором эти две науки несомненно присутствуют, более того они сознают определенное правило, согласно которому мы выполняем какие-то действия. Например, мы никогда не задумываемся при походе в казино или играя в лотерею или карты о том, что все законы, по которым происходит выпадение той или иной карты/фишки/числа, разработаны этими науками. Также задачи обработки результатов научных и технических измерений, задачи контроля качества продукции, задачи оценки надежности технических систем и программного обеспечения, статистические задачи теории связи и телекоммуникаций, статистический анализ транспортных потоков, некоторые задачи криптографии и теории защиты информации, некоторые демографические, социологические и экономические задачи, исследование факторов риска в медицине и экологии, статистические задачи в теории страхования, задачи о предсказании курса доллара или евро на несколько дней вперед, задачи поведения крупных или игра на биржи – все эти задачи являются примерами того, что все в нашем мире подчинено законам теории вероятности и математической статистики, сделать свой прогноз, создать универсальную модель с помощью определенных методов. Раз существует очень много вещей, которые нас окружают, подчиняющихся законам математической статистики, то несомненно эта наука не может не вызывать у нас интерес. Интересно, понять, как создать такую модель, которая смогла бы правильно работать, производила близкие к истине вычисления.
Постановка задачи.
Требуется по выборке x1,x2,…..,xn, полученной в результате n наблюдений(опытов), оценить параметр ![]() . Для этого необходимо произвести статическую оценку
. Для этого необходимо произвести статическую оценку ![]() , причем
, причем ![]() =
= ![]() (x1,x2,…..,xn). X=S+N, где S—сигнал, N—шум. В нашем случае S=
(x1,x2,…..,xn). X=S+N, где S—сигнал, N—шум. В нашем случае S= ![]() , N=N[0,ε].
, N=N[0,ε].
В курсовой работе рассмотрены такие вопросы, как: разработка статической модели для ![]() и методы нахождения точечных оценок – метод максимального правдоподобия, байесовская оценка; проверка статических гипотез и нахождение доверительного интервала.
и методы нахождения точечных оценок – метод максимального правдоподобия, байесовская оценка; проверка статических гипотез и нахождение доверительного интервала.
Глава 1. Классический метод
Требуется по выборке x1, x2,….,xn, полученной в результате n наблюдений, оценить неизвестный параметр ![]() . x1, x2,….,xn –случайные величины: x1 – результат первого наблюдения, соответственно x2 – результат второго наблюдения и т. п.. Статической оценкой
. x1, x2,….,xn –случайные величины: x1 – результат первого наблюдения, соответственно x2 – результат второго наблюдения и т. п.. Статической оценкой ![]() параметра
параметра ![]() теоретического распределения называют его приближенное значение, зависящее от данных выбора. Оценка
теоретического распределения называют его приближенное значение, зависящее от данных выбора. Оценка ![]() есть значение некоторой функции результатов наблюдения над случайной величиной, т. е.
есть значение некоторой функции результатов наблюдения над случайной величиной, т. е. ![]() =
=![]() (x1,x2,….,xn).
(x1,x2,….,xn).
В нашем случае, x=S+N, -∞<![]() <1, где S — сигнал, который задается S=
<1, где S — сигнал, который задается S= ![]() rnd[1], и шум N задается N=N[0,ε] . Для начала разберемся с шумом. Мы знаем, что N[0,ε] — гауссовское распределение (или нормальное распределение). Значит математическое ожидание есть 0, а дисперсия равна ε. Гауссовское распределение можно задать следующим образом: N[0,ε]=
rnd[1], и шум N задается N=N[0,ε] . Для начала разберемся с шумом. Мы знаем, что N[0,ε] — гауссовское распределение (или нормальное распределение). Значит математическое ожидание есть 0, а дисперсия равна ε. Гауссовское распределение можно задать следующим образом: N[0,ε]= ![]() . Осталось разобраться что такое rnd[1]. Rnd[1] – равномерное распределение величины от 0 до 1, т. е. на интервале [0,1]. Обозначим ЕX—математическое ожидание. Т. к. X=S+N, то EX=E(S+N). Хотим придумать модель для
. Осталось разобраться что такое rnd[1]. Rnd[1] – равномерное распределение величины от 0 до 1, т. е. на интервале [0,1]. Обозначим ЕX—математическое ожидание. Т. к. X=S+N, то EX=E(S+N). Хотим придумать модель для ![]() . Сначала найдем ES. ES=E(
. Сначала найдем ES. ES=E(![]() rnd[1]).
rnd[1]).
1. Предположим, что мы хотим задать ![]() =
=![]() ( x1,x2,….,xn). E rnd[1]=
( x1,x2,….,xn). E rnd[1]= ![]() . Тогда ES=
. Тогда ES=![]() ½=
½= ![]() ; Из условия дисперсия DN=ε. Также DN=EN=ε. E(S+N)=EX=
; Из условия дисперсия DN=ε. Также DN=EN=ε. E(S+N)=EX=![]() +ε. Е(x1,x2,….,xn)=
+ε. Е(x1,x2,….,xn)= ![]() -ε. Следовательно, получаем модель для
-ε. Следовательно, получаем модель для ![]() =
=![]() .
.
Вводим ![]() =100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
=100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
Получаем ![]() = -100.04;-99.04; -98.039; -97.025; -96.018; -95.034; -94.024; -93.034;-92.015; -91.025; -90.031; -89.024; -88.021; -87.027; -86.03; -85.028; -84.029; -83.024; -82.031; -81.036; -80.032; -79.032; -78.034; -77.023; -76.021; -75.031; -74.028; -73.034; -72.024; -71.027; -70.029; -69.031; -68.030; -67.028; -66.016; -65.025; -64.029; ………………………………………-10.034; -9.039; -8.041; -7.025; -6.041; -5.045; -4.044; -3.039; -2.034; -1.043; 0.035; 1.04;
= -100.04;-99.04; -98.039; -97.025; -96.018; -95.034; -94.024; -93.034;-92.015; -91.025; -90.031; -89.024; -88.021; -87.027; -86.03; -85.028; -84.029; -83.024; -82.031; -81.036; -80.032; -79.032; -78.034; -77.023; -76.021; -75.031; -74.028; -73.034; -72.024; -71.027; -70.029; -69.031; -68.030; -67.028; -66.016; -65.025; -64.029; ………………………………………-10.034; -9.039; -8.041; -7.025; -6.041; -5.045; -4.044; -3.039; -2.034; -1.043; 0.035; 1.04;
2. Предположим, что мы хотим задать ![]() =
=![]() ( x12,x22,….,xn2). EX2=ES2+EN2. EX2 =0. EN2 =ε2. ES2=E(
( x12,x22,….,xn2). EX2=ES2+EN2. EX2 =0. EN2 =ε2. ES2=E(![]() 2 rnd2[1]).E2 rnd[1]=
2 rnd2[1]).E2 rnd[1]= 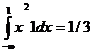 . Тогда ES2=
. Тогда ES2=![]() 2 1/3=
2 1/3= ![]() ; E(S+N)=EX=
; E(S+N)=EX=![]() +ε2. Е(x1,x2,….,xn)= =
+ε2. Е(x1,x2,….,xn)= =![]() -ε2. Следовательно, получаем модель для
-ε2. Следовательно, получаем модель для ![]() =
=![]() . В результате программной обработки было получено, что
. В результате программной обработки было получено, что ![]() =1,005 в то время как истинное значение
=1,005 в то время как истинное значение ![]() =1….и т. п.
=1….и т. п.
В результате программной обработки было получено: взяли ![]() , а
, а ![]() =0.5, получили
=0.5, получили ![]() =0,62. При
=0,62. При ![]() , то
, то ![]() =0.29. При
=0.29. При ![]() =0.4,
=0.4, ![]() =0.46. При
=0.46. При ![]() =-1,
=-1, ![]() =-1.005, При
=-1.005, При ![]() =-1.5,
=-1.5, ![]() =-1.509. т. п.
=-1.509. т. п.
Делаем вывод, что чем меньше ![]() , тем точность становится больше. Причем в обоих случаях.
, тем точность становится больше. Причем в обоих случаях.
Вводим ![]() =100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
=100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
Получаем ![]() = -100.024;-99.025; -98.021; -97.015; -96.027; -95.032; -94.014; -93.041;-92.021; -91.035; -90.032; -89.043; -88.041; -87.029; -86.038; -85.025; -84.039; -83.041; -82.032; -81.035; -80.041; -79.023; -78.036; -77.032; -76.026; -75.016; -74.046; -73.036; -72.034; -71.034; -70.041; -69.038; -68.036; -67.025; -66.027; -65.023; -64.034; ………………………………………-10.02; -9.024; -8.032; -7.012; -6.019; -5.023; -4.035; -3.025; -2.036; -1.03; 0.018; 1.032;
= -100.024;-99.025; -98.021; -97.015; -96.027; -95.032; -94.014; -93.041;-92.021; -91.035; -90.032; -89.043; -88.041; -87.029; -86.038; -85.025; -84.039; -83.041; -82.032; -81.035; -80.041; -79.023; -78.036; -77.032; -76.026; -75.016; -74.046; -73.036; -72.034; -71.034; -70.041; -69.038; -68.036; -67.025; -66.027; -65.023; -64.034; ………………………………………-10.02; -9.024; -8.032; -7.012; -6.019; -5.023; -4.035; -3.025; -2.036; -1.03; 0.018; 1.032;
Глава 2. Графики для классических моделей
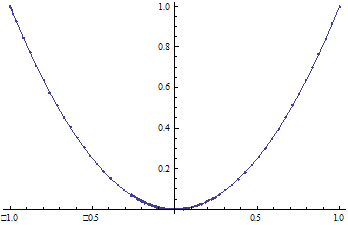
Рис1. Зависимость ![]() от
от ![]()
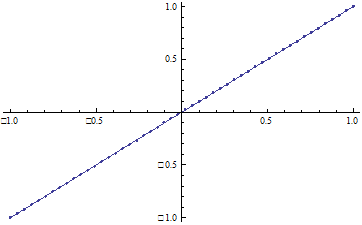
Рис 2. Зависимость ![]() от
от ![]()
Глава 3. Метод максимального правдоподобия
Наиболее распространенным методом оценки параметров является метод максимального правдоподобия. Данный метод заключается в следующем: пусть x1,x2,….,xn которая получается в результате проведения n независимых наблюдений случайной величины X. Пусть известен закон распределения величины X, у которого плотность распределения имеет вид 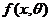 , однако не известен параметр
, однако не известен параметр ![]() , которым соответственно определяется законом распределения. Требуется по данной выборке для X оценить саму величину
, которым соответственно определяется законом распределения. Требуется по данной выборке для X оценить саму величину ![]() . Данный метод был придуман Р. Фишером. В основе данного метода лежим понятие функции правдоподобия. Функция правдоподобия – такая функция от аргумента
. Данный метод был придуман Р. Фишером. В основе данного метода лежим понятие функции правдоподобия. Функция правдоподобия – такая функция от аргумента ![]() , которая строится по выборке x1,x2,….,xn и имеет вид:
, которая строится по выборке x1,x2,….,xn и имеет вид:
L(x1,x2,….,xn; ![]() )=
)=![]()
или
L(x; ![]() )=
)=![]() , где
, где![]() -плотность распределения случайной величины X, если X-непрерывна и если X-дискретна, то фунция правдоподобия имеет вид:
-плотность распределения случайной величины X, если X-непрерывна и если X-дискретна, то фунция правдоподобия имеет вид:
L(x; ![]() )=
)=![]()
За точечную оценку параметра ![]() берут такое значение
берут такое значение ![]() , при котором функция правдоподобия достигает максимума, т. е. для этого необходимо решить уравнение:
, при котором функция правдоподобия достигает максимума, т. е. для этого необходимо решить уравнение:
![]()
Применим метод максимального правдоподобия к нашему случаю.
Из вышесказанного ясно, что начала необходимо понять, какой у нас является величина X: дискретной или непрерывной. Т. к. X=S+N, где S=![]() , N=N(0,ε),. что и S есть величина непрерывная, что и N тоже величина непрерывная. Значит необходимо найти плотность функции распределения для величины X. Она будет складываться из плотности распределения величины S и плотности распределения величины N. Напомним, что плотность распределения какой-либо величины находится как первая производная от ее функции распределения
, N=N(0,ε),. что и S есть величина непрерывная, что и N тоже величина непрерывная. Значит необходимо найти плотность функции распределения для величины X. Она будет складываться из плотности распределения величины S и плотности распределения величины N. Напомним, что плотность распределения какой-либо величины находится как первая производная от ее функции распределения![]() . Соответственно,
. Соответственно, ![]() --плотность функции распределения для сигнала. А
--плотность функции распределения для сигнала. А ![]() задается формулой
задается формулой 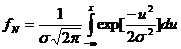 , где
, где ![]() - дисперсия, в нашем случае дисперсия DN=
- дисперсия, в нашем случае дисперсия DN=![]() , значит
, значит 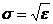 , следовательно плотность функции распределения для шума будет иметь вид:
, следовательно плотность функции распределения для шума будет иметь вид: ![]() . Тогда плотность функции распределения для X:
. Тогда плотность функции распределения для X: ![]() .
.
После чего решаем дифференциальное уравнение относительно ![]() :
: 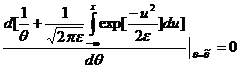
И находим максимум.
В результате программной обработки получаем:
Вводим ![]() =100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
=100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
Получаем ![]() = -100.015;-99.015; -98.015; -97.015; -96.015; -95.015; -94.015; -93.015;-92.015; -91.03; -90.03; -89.03; -88.03; -87.03; -86.03; -85.03; -84.03; -83.03; -82.03; -81.03; -80.03; -79.03; -78.03; -77.031; -76.03; -75.03; -74.03; -73.03; -72.03; -71.03; -70.03; -69.03; -68.03; -67.032; -66.037; -65.034; -64.031; ………………………………………-10.032; -9.0312; -8.03; -7.031; -6.033; -5.031; -4.031; -3.031; -2.035; -1.035; 0.031; 1.031;
= -100.015;-99.015; -98.015; -97.015; -96.015; -95.015; -94.015; -93.015;-92.015; -91.03; -90.03; -89.03; -88.03; -87.03; -86.03; -85.03; -84.03; -83.03; -82.03; -81.03; -80.03; -79.03; -78.03; -77.031; -76.03; -75.03; -74.03; -73.03; -72.03; -71.03; -70.03; -69.03; -68.03; -67.032; -66.037; -65.034; -64.031; ………………………………………-10.032; -9.0312; -8.03; -7.031; -6.033; -5.031; -4.031; -3.031; -2.035; -1.035; 0.031; 1.031;
Глава 4. Байесовская оценка
В байесовском подходе к решению задачи оценивания предполагается, что параметр ![]() является случайной величиной с некоторым распределением. Формально, на
является случайной величиной с некоторым распределением. Формально, на ![]() задается некоторая мера
задается некоторая мера ![]() и предполагается, что случайная величина
и предполагается, что случайная величина ![]() имеет плотность
имеет плотность ![]() относительно меры
относительно меры ![]() .
.
Эту плотность называют априорной плотностью ![]() .
.
Определение.
Байесовским риском решающего правила ![]() называется величина
называется величина 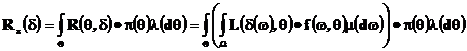
Определение.
Байесовским решающим правилом называется решающее правило
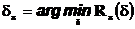
Заметим, что количество различных байесовских оценок при одном и том же распределении данных велико (в принципе, каждому априорному распределению ![]() может соответствовать своя байесовская оценка
может соответствовать своя байесовская оценка ![]() ).
).
Т. е. метод байесовский подход сводится к нахождению: 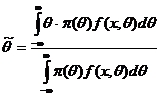
В нашем случае 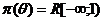 , поэтому
, поэтому 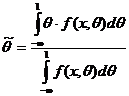 . Т. е. все сводится опять к нахождению плотности функции распределения. (См. глава3).
. Т. е. все сводится опять к нахождению плотности функции распределения. (См. глава3). ![]() .
.
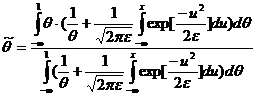
В результате программной обработки получили, что:
При ![]() = -100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
= -100;-99; -98; -97; -96; -95; -94; -93;-92; -91; -90; -89; -88; -87; -86; -85; -84; -83; -82; -81; -80; -79; -78; -77; -76; -75; -74; -73; -72; -71; -70; -69; -68; -67; -66; -65; -64; ………………………………………-10; -9; -8; -7; -6; -5; -4; -3; -2; -1; 0; 1;
Получаем ![]() = -100.005;-99.005; -98.005; -97.005; -96.005; -95.005; -94.005; -93.005;-92.005; -91.005; -90.005; -89.005; -88.005; -87.005; -86.005; -85.005; -84.005; -83.005; -82.005; -81.005; -80.005; -79.00549; -78.006; -77.006; -76.006; -75.006; -74.006; -73.006; -72.006; -71.006; -70.006; -69.00638; -68.0065; -67.0065; -66.00667; -65.007; -64.007; ………………………………………-10.01; -9.01; -8.01; -7.01; -6.01; -5.01; -4.01; -3.0175; -2.0176; -1.02; 0.02; 1.02;
= -100.005;-99.005; -98.005; -97.005; -96.005; -95.005; -94.005; -93.005;-92.005; -91.005; -90.005; -89.005; -88.005; -87.005; -86.005; -85.005; -84.005; -83.005; -82.005; -81.005; -80.005; -79.00549; -78.006; -77.006; -76.006; -75.006; -74.006; -73.006; -72.006; -71.006; -70.006; -69.00638; -68.0065; -67.0065; -66.00667; -65.007; -64.007; ………………………………………-10.01; -9.01; -8.01; -7.01; -6.01; -5.01; -4.01; -3.0175; -2.0176; -1.02; 0.02; 1.02;
Т. е. данный метод является довольно точным по сравнению с предыдущими.
Глава 5. Проверка гипотез
Под статической гипотезой понимается всякое высказывание о генеральной совокупности, проверяемой по выборке. В принципе проверки гипотез основными понятиями является допущения ошибок: ошибки первого рода –те ошибки, в которых отвергается гипотеза H0, в то время как на самом деле она верна, а ошибки второго рода – такие ошибки, в которых отвергается гипотеза H1, когда является на самом деле верна.
Глава 6. Нахождение доверительного интервала
Задачу интервального оценивания можно сформулировать так: по данным выборки построить числовой интервал (![]() ;
;![]() ), относительно которого с заранее выбранной вероятностью
), относительно которого с заранее выбранной вероятностью ![]() можно сказать, что внутри этого интервала находится точное значение оцениваемого параметра. Интервал (
можно сказать, что внутри этого интервала находится точное значение оцениваемого параметра. Интервал (![]() ;
;![]() ), накрывающий с вероятностью
), накрывающий с вероятностью ![]() истинное значение параметра
истинное значение параметра ![]() , называется доверительным интервалом, а вероятность
, называется доверительным интервалом, а вероятность ![]() --надежностью оценки или доверительной вероятностью. Величину
--надежностью оценки или доверительной вероятностью. Величину ![]() выбирают заранее, ее выбор зависит от конкретно решаемой задачи. Достоверное нахождение параметра
выбирают заранее, ее выбор зависит от конкретно решаемой задачи. Достоверное нахождение параметра ![]() в доверительном интервале
в доверительном интервале ![]() .
.
В нашем случае величина X=S+N, где S=![]() , N=N(0,ε). Сначала найдем доверительный интервал для N. Дисперсия у нормального распределения есть
, N=N(0,ε). Сначала найдем доверительный интервал для N. Дисперсия у нормального распределения есть ![]() , т. е. ее мы можем считать дисперсию величиной известной. Пусть x1,x2,….,xn –выборка, полученная в результате проведения n независимых наблюдений свободной величины X. Выборочное среднее
, т. е. ее мы можем считать дисперсию величиной известной. Пусть x1,x2,….,xn –выборка, полученная в результате проведения n независимых наблюдений свободной величины X. Выборочное среднее ![]() будет распределено по нормальному закону. Параметры распределения
будет распределено по нормальному закону. Параметры распределения ![]() таковы: M(
таковы: M(![]() )=0, D(
)=0, D(![]() )=
)=![]() =D(
=D(![]() ). Значит
). Значит ![]() ~
~ ![]() .
. ![]() , где
, где ![]() .
.
Предположим, что было произведено n измерений: x1,x2,….,xn. Возьмем ![]() =0.95 и Ф0(t)=
=0.95 и Ф0(t)= ![]() /2=0.475. t=
/2=0.475. t= ![]() =1.96.
=1.96. ![]() . Возьмем 10 разных, следовательно
. Возьмем 10 разных, следовательно 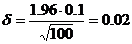 Далее ищем среднее значение для
Далее ищем среднее значение для ![]()
Свободна величина ![]()
