
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
БД – совокупность спец. образом организованных данных, хранимых в памяти ВС, и отражающих состояние объектов и их взаимосвязей.
1. Установление многосторонних связей.
2. Производительность.
3. Минимальные затраты.
4. Минимальная избыточность.
5. Возможности поиска.
6. Целостность.
Необходимо учитывать возможность возникновения ошибок и различного рода случайных сбоев. Хранение данных, их обновление, процедуры включения данных должны быть такими, чтобы система в случае возникновения сбоев могла восстанавливать данные без потерь.
7. Безопасность и секретность.
Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это право, от неавторизованной модификации данных или их уничтожения.
Секретность определяют как право отдельных лиц или организаций определять, когда, как и какое количество соответствующей информации может быть передано другим лицам или организациям.
Основные положения, особенно важные с точки зрения обеспечения безопасности данных в базе данных:
n данные защищаются от искажения, хищения и других форм уничтожения,
n данные должны быть восстанавливаемыми,
n обеспечивается возможность контроля данных,
n система недоступна для вмешательства в неё,
n должна быть установлена процедура идентификации пользователя базы данных,
n в системе предусматривается контроль действий пользователя по обработке данных с точки зрения санкционирования их выполнения,
n контроль за работой пользователя осуществляется так, чтобы его ошибочные действия были с большой вероятностью обнаружены.
Вопросы обеспечения секретности данных и их безопасности принципиально тесно связаны между собой.
8. Связь с прошлым.
9. Связь с будущим.
Должны существовать три отдельных представления организации базы данных:
1). Физическое представление,
2). Общее логическое представление базы данных,
3). Представление данных в отдельных прикладных программах.
10. Настройка.
Реконструкция базы данных с целью улучшения её производительности называется настройкой базы данных. Эффективность настройки определяется двумя требованиями:
1). Физической независимости данных,
2). Автоматического управления базами данных, обеспечивающего возможность выполнения требуемой настройки.
11. Перемещение данных.
Процесс регулирования хранения данных в соответствии с уровнем спроса на них называется перемещением данных. Иногда эта операция является частью процесса настройки базы данных. В некоторых системах перемещение выполняется автоматически.
12. Простота.
Средства, которые используются для представления общего логического описания данных, должны быть простыми.
Основные компоненты СУБД (27).
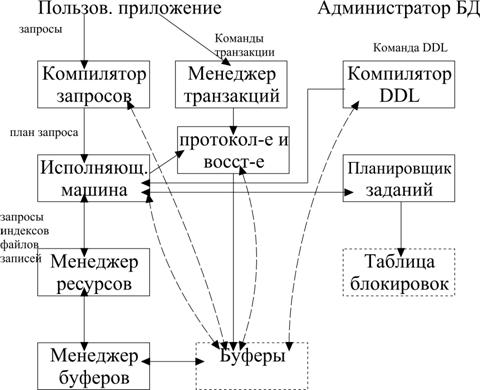
Транзакции – процессы, которые должны выполняться атомарно.
Свойства транзакций – атомарность, изолированность, устойчивость.
Условия каждой завершенной транзакции должны быть зафиксированы в БД, когда система выходит из строя
планировщик заданий отвечает за атомарность и изолированность
менеджер протоколирования и восстановления гарантирует устойчивость
Процессор транзакции представлен в виде 2-х основных компонентов:
1. Планировщик заданий, ответственный за обеспечение атомарности и изолированности транзакции.
2. Менеджер протоколирования и восстановления
Процессор транзакции выполняет функции
1. протоколирование 2. управление параллельными заданиями
3. разрешение взаимоблокировок
Задача управления размещением информации на диске и обмена ею между диском и ОП решается менеджером хранения данных.
Менеджер буфера является ответственным за разбиение доступной ОП на буферные участки страницы, куда может быть помещено содержание дисковых блоков.
Три уровня представления данных в информационные системы" href="/text/category/avtomatizirovannie_informatcionnie_sistemi/" rel="bookmark">автоматизированных информационных системах.
Внешний уровень, на котором пользователи воспринимают данные, где отдельные группы пользователей имеют свое представление (ПП) на базу данных.
Внутренний уровень, на котором СУБД и ОС воспринимают данные.
Концептуальный уровень представления данных, предназначенный для отображения внешнего уровня на внутренний, а также для обеспечения необходимой их зависимости друг от друга.
Описание структуры данных на любом уровне называется схемой. Существует три различных типа схем базы данных, которые определяются с уровнем абстракции трехуровневой архитектуры. На самом высоком уровне имеется несколько внешних схем или подсхем, которые соответствуют разным представлениям данных. На концептуальном уровне описание базы данных называют концептуальной схемой, а на самом низком уровне абстракции – внутренней схемой.
Логическая и физическая независимость данных.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных. Суть этой независимости заключается в том, что изменения на нижних уровнях никак не влияют на верхние уровни. Различают два типа независимости от данных: логическую и физическую.
Логическая независимость от данных означает полную защищенность внешних схем от изменений, вносимых в концептуальную схему. Такие изменения концептуальной схемы, как добавление или удаление новых сущностей, атрибутов или связей, должны осуществляться без необходимости внесения изменений в уже существующие внешние схемы для других групп пользователей. Таким образом, тем группам пользователей, которых эти изменения не касаются, не потребуется вносить изменения в свои программы.
Физическая независимость от данных означает защищенность концептуальной схемы от изменений, вносимых во внутреннюю схему. Такие изменения внутренней схемы, как использование различных файловых систем или структур хранения, разных устройств хранения, модификация индексов или хеширование, должны осуществляться без необходимости внесения изменений в концептуальную или внешнюю схемы. Пользователем могут быть замечены изменения только в общей производительности системы.
Классификация моделей данных.
Данные – набор каких – либо конкретных значений.
Модель данных – некоторая абстракция, которая, будучи приложена к конкретным данным, позволяет пользователям и разработчикам трактовать это как информацию, то есть сведения, содержащие не только данные, но и связь между ними.
При создании БД (база данных) всегда следует учитывать логические ограничения на значения данных и их соотношения. Они обычно представляют собой условия при которых имеют смысл те или иные данные.
Ограничение целостности – не противореч. данных задан. логич. огранич.
Огранич. зад-тся не только для атриб-тов, но и для типов объ-тов и связей.
Отсюда возникает понятие целостности данных , т. е. данные, хранимые в БД не должны противоречить заданным логическим ограничениям, которые называются ограничениями целостности. Они обычно задаются для множества объектов.
К явным ограничениям целостности можно отнести ограничения на значения атрибутов объекта. Естественно, что ограничения в явном виде задаются не только для атрибутов, но и для типов объектов (сущностей) и связей. Рассмотрим основные типы связей.
Виды связи: 1:1 1:M M:1 M:M
Связь один к одному (1:1) . Она определяет такой вид связи между двумя типами объектов А и В, при котором каждому экземпляру А соответствует только один В и наоборот. Например, связь студент курса - номер зачетной книжки.
Связь один ко многим (1:М) . Соответствует случаю, когда для двух типов А и В, одному экземпляру А соответствует несколько (0,1,2,...,М) экземпляров В. Однако каждому В соответствует только один экземпляр А, например связь группа - фамилия, имя, отчество студента.
Связь многие к одному (М:1) . Является вариантом связи, обратных к связи 1:М, т. е. в этом случае многим экземплярам А соответствует только один В. Например, Ф. И.О. студента - группа.
Связь многие ко многим. Соответствует случаю, когда каждому экземпляру А может соответствовать несколько экземпляров В, и наоборот. Например, телевизор - резистор.
Модель данных, поддерживаемая БД на логическом уровне определяется 3 компонентами:
1. Допустимая структура данных, разнообразие и количество типов объектов, которые можно описать с помощью модели
2. Множество допустимых операций над данными
3. Ограничения для контроля целостности.
Модели данных:
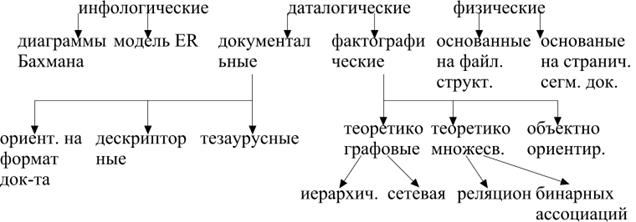
Инфологические модели отражают информационно-логический уровень абстракт, используются на ранних стадиях проекир.
Документ. Модели соответствуют представлению о слабоструктур. информации, ориентированны в основном на свободные форматы документов на естественном языке.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике.
Дескрипторные модели самые простые. Ранее широко использовались. В этих моделях каждому документу соответствует дескриптор (описатель).
Инфологическое моделирование.
Модель сущность-связь (Entity-RelationShip ER).
Сущность имеет уникальное имя. т. к. сущность соответствует некоторому классу однотипных объектов. Предполагается, что в системе существует множество экземпляров данной сущности (сущности представлены таблицами). Объект, которому соответствует понятие сущности, имеет свой набор атрибутов, т. е. характеристик, определяющих свойства данного представителя класса.
Набор атрибутов (полей) должен быть таким, чтобы можно было различать конкретные экземпляры сущности.
Набор атрибутов, однозначно идентифицирующий экземпляр сущности называется ключевым.
Сотрудник | -сущность |
Табельный номер | -ключевой атрибут |
Фио | -атрибуты |
Дата рождения |
Между сущностями могут быть установлены связи – бинарные ассоциации, показывающие, каким образом сущности соотносятся или взаимодействуют. Связи могут быть как между двумя сущностями, так и между сущностью и ей же самой.
Связь может быть: Необязательной, обязательной.
Между двумя сущ. может быть много связей с разными смысл. нагрузками.
В ER модели можно использовать принцип категоризации сущности, то есть наследовать сущности друг от друга (как в ООП). Сущность-родитель, от которой строятся подтипы, называется супертипом.
Для построения модели ER проводится системный анализ.
Для библиотеки это будет книги-экземпляры-читатели.
Иерархическая модель данных.
Самая простая. Появилась первой. Основные информационные единицы база данных, поле, сегмент.
Поле – мин. и независимая единица данных, доступная пользователю с помощью СУБД.
Сегмент (DBTS) - называется записью.
Тип сегмента – поименованная совокупность типов элементов данных.
Экземпляр сегмента образуется из конкретных значений полей или элементов данных.
Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Каждый тип сегмента может иметь ключ.
Сегменты объединяются в древовидный орграф.
Тип сегмента, находящегося на более высоком уровне иерархии называется лог. исходным(сегмент предок) по отношению к типам сегмента под ним.(лог. подчиненным или сегмент потомок).
Схема иерархической БД представляет собой совокупность отдельных деревьев. Каждое дерево в рамках модели называется физической БД и удовлетворяет следующим ограничениям:
1. Существует 1 корневой сегмент
2. Каждый лог. исх. сегмент м. б. связан с любым числом подчиненных.
3. Каждый логически подчиненный сегмент м. б. связан только с одним логически исходным.
Сегмент является экземпляром типа сегмента. Между экземплярами сегмента также существует иерархическая связь.
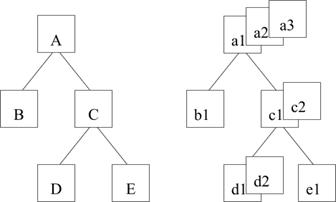
Близнецы – потомки одного типа с одним предком.
Набор всех экземпляров сегмента в одном дереве наз-ся физ. Записью. Количество экземпляров потомков м. б. разным для разных экземпляров родительских сегментов. Поэтому о общем случае физические записи имеют разную длину. Физ. записи в иерархической модели различают по длине и структуре.
В рамках иерархической модели выделают языковые средства описания данных и средства манипулирования данными. Каждая физическая база описывается набором операторов определяющих её логическую структуру и структуру хранения. В системе м. б. несколько физических БД. Каждая физическая БД. содержит только один корневой сегмент.
Для организации физического размещения используются следующие методы:
1. Представление линейным списком с последовательным распределением памяти
2. представление связанными линейными списками
Основное правило контроля целостности: потомок не может существовать без родителя, а у некоторых родителей не может быть потомка.
Механизмы поддержания целостности между отдельными деревьями отсутствуют.
(+) 1. Эффективное использование памяти ЭВМ
2. Высокие показатели времени выполнения основных операций над данными
3. Удобно для работы с иерархически упорядоченными данными
Громоздко для обработки информации с достаточно сложными иерархическими связями.
Пример такой БД – сеть магазинов.
Сетевая модель данных.
Базовые объекты модели: элемент данных, агрегат данных, запись, набор данных.
Элемент данных – это минимальная информационная единица, доступная пользователю. Аналог поля.
Агрегат данных – совокупность элементов данных, имеющих общее имя, которые могут рассматриваться как единое целое. В модели определены агрегаты двух типов: вектор и повторяющаяся группа.
Вектор – линейный набор элементов данных. Пример (Адрес: дом улица кварт. город)
Группа – совокупность векторов Пр: Стипендия – повторяющаяся группа с числом повторения 12.
Запись – совокупность агрегатов или элементов данных моделирующая некоторый класс объектов реального мира. Аналог сегмента или кортежа.
Существует понятие типа записи и экземпляра записи.
Набор – 2х уровневый граф, связывающий 2 типа записей видом 1:M. Набор отражает иерархическую связь между двумя типами записи. Родительский тип записи – владелец набора. Дочерний – член. Для любых 2-х типов записи м. б. задано любое количество наборов, которое их связывает. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора. Ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
Пример: учителя и группы
Среди всех наборов определяется сингулярный набор, владелец которого – вся система. Обозначается входящей стрелкой. Он имеет имя набора и имя члена набора, но не определён тип записи: владелец набора. Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных типов данных.
В общем случае сетевая БД представляет совокупность взаимосвязанных наборов. Язык описания данных в сетевой модели содержит описание БД, описание записи, описание набора. Операции манипулирования данными делятся на навигационные и операции модификации.
(+)Высокие возможности по созданию сложных иерархических структур
Возможность эффективной реализации по затратам памяти и оперативности
(-) Высокая сложность и жесткость схемы БД
Сложность для понимания и обработки информации в БД
Ослаблен контроль целостности
Реляционная модель данных. Элементы реляционной модели.
Определение. Элементы, информацию о которых сохраняем, называются объектами.
Определение. Совокупность однородных объектов называется набором объектов.
Определение. Свойства, характеризующие объект, называются атрибутами.
Определение. Описание логической структуры базы данных называется схемой.
Схема представляет собой таблицу типов используемых данных. Она содержит имена объектов и их атрибуты и указывает на существующую между ними связь.
Если схема содержит значения элементов данных, её называют экземпляром схемы. Запись - такая структура, в которую можно помещать конкретные значения данных. Экземпляр записи - запись с конкретным значением данных.
Термин схема используется для определения полной таблицы всех типов элементов данных и типов записей, хранимых в базе данных. Термином подсхема определяют описание данных, которое использует прикладной программист. На основе одной схемы можно составить много различных подсхем.
В основе РМД (реляционная модель данных) лежит математическая теория отношений.
Для представления данных математическое отношение используется двояко:
1). Для представления набора объектов,
2). Для представления связей между наборами объектов.
Для представления набора объектов атрибуты интерпретируются столбцами отношения. Множество допустимых значений атрибута интерпретируется соответствующим доменом. Каждый кортеж отношения выполняет роль описания отдельного объекта из набора. Само отношение выполняет роль описания всего набора объектов.
Массив данных, представленный набором реляционных структур, образует реляционную БД. Схема РБД(реляционная база данных) будет представлена набором схем отношений:
R1(А11, А21,..., Ак1);
R2(А12, А22,..., Аl2);
Rm(А1m, А2m,..., Аnm);
где Аij - имя атрибута, R j - имя отношения.
Одним из основных типов зависимостей, рассматриваемых в РБД, являются функциональные зависимости.
Элементы реляционной модели | Форма представления |
Отношение | Таблица |
Схема отношения | Заголовок таблицы |
Кортеж | Строка таблицы |
Сущность | Свойства объекта |
Атрибут | Заголовок столбца |
Домен | Множество допустимых значений атрибута |
Значение атрибута | Значение поля записи |
Первичный ключ | Один или несколько атрибутов |
Тип данных | Тип значений элементов таблицы |
Правила вывода функциональных зависимостей.
Одним из основных типов зависимостей, рассматриваемых в РБД, являются функциональные зависимости.
Пусть А и В атрибуты отношения R. Говорят, что атрибут В отношения R функционально зависит от атрибута А, если в каждый момент времени каждому значению а соответствует не более одного значения b. Функциональную зависимость f атрибута В от атрибута А обозначают : f : А ® В. Эту зависимость f можно также представить множеством упорядоченных пар {< а, b>/ а Î А, b Î В }, в которых каждому значению а соответствует только одно значение b. При этом говорят, что В функционально зависит ( или просто зависти ) от А, а А функционально определяет ( или просто определяет) В.
Если существует единственная функциональная зависимость В от А, то её обозначают просто А ® В. В случае отсутствия между ними функциональной зависимости вводят обозначение А ¹ В. Если А ® В и одновременно В ® А, то между А и В существует взаимно однозначное соответствие, что записывается как А « В.
Пусть имеется множество атрибутов А1, А2,...,Аn отношения R, а также множество F Ф. З. Х ® Y, где Х и Y - подмножества атрибутов множества А1, А2,...,Аn. Тогда из Ф. З. (функциональные зависимости), входящих в F, могут быть выведены другие Ф. З., присущие отношению R.
Обозначим через F+ замыкание множества ФЗ F, т. е. полное множество зависимостей, которое можно получить из F.
Правило вывода ФЗ :
1. Правило ФЗ 1 (свойство рефлексивности). Если Х £ U, Y £ U и Y £ Х, то имеет место Ф. З. Х ® Y.
2. Правило ФЗ 2 (свойство пополнения). Если Х £ U, Y £ U и Z £ U и имеет место Ф. З. Х ® U, X È Z ® Y È Z.
В отличии от правила ФЗ 1 данное говорит о том, что для его применения несу щественно выполнение условий Y £ Х. Т. е. любые атрибуты из множества U можно одновременно подставлять в левую и правую части выражения Ф. З. F.
Например, имеется универсальное отношение U(A1, A2, A3, A4, A5) и заданы наборы атрибутов X={A1, A3}, Y={A2, A4}, Z={A5}, тогда из условия, что существует Ф. З. Х ® Y : {A1, A3}® {A2, A4}, следует, что имеет место зависимость:
{A1, A3, А5}® {A2, A4, А5},
3. Правило ФЗ 3 (свойство транзитивности) . Если Х £ U, Y £ U и Z £ U и имеют место зависимости Х ® Y и Y ® Z, то Х ® Z. Например, имеются подмножества атрибутов X={A1, A3}, Y={A2, A4}, Z={A5}. Тогда из условия существования зависимостей {A1, A3}® {A2, A4}, {A2, A4}® {A5} следует, что имеет место зависимость {A1, A3}® {A5}.
Кроме этих правил часто используют дополнительные правила следствия ФЗ 1, ФЗ 2, и ФЗ 3.
4. Правило ФЗ 4 (свойство расширения). Если Х £ U, Y £ U и задана ФЗ,
Х ® Y, тогда для любого Z £ U имеет место Ф. З. X ÈZ ® Y.
5. Правило ФЗ 5 (свойство продолжения). Если Х £ U, Y £ U, W £ U, Z £ U и задана Ф. З. Х ® Y, то для любых W £ Z имеет место зависимость X ÈZ ® Y È W.
6. Правило ФЗ 6 ( свойство псевдотранзитивности). Если Х £ U, Y £ U,
W £ U, Z £ U и заданы Ф. З. Х ® Y, Y ÈW ® Z, то имеет место Ф. З. X ÈW ® Z.
7. Правило ФЗ 7 (свойство аддитивности). Если Х £ U, Y £ U, Z £ U, и заданы Ф. З. Х ® Y, Х ® Z, то имеет место Ф. З. X ®Y È Z.
8. Правило ФЗ 8 (свойство декомпозиции). Если Х £ U, Y £ U, Z £ U, и при этом Z £ Y и заданы Ф. З. Х ® Y, то имеет место Ф. З. Х ® Z.
Реляционная алгебра. Основные операции.
В ней определяются основные операции над данными реляционного типа. Все операции можно разделить на традиционные над множествами и специализированные, вводимые для удобства поиска в БД.
К операциям 1-й группы относятся: объединения, пересечения, разность, декартово произведение. К операциям 2 - й группы относятся: проекция, ограничение, соединение, деление.
Объединение. В результате применения этой операции получается отношение. объединяющее кортежи, содержащиеся в исходных отношениях. Пусть имеем два исходных отношения R1 и R2 . Операция объединения этих отношений обозначается R1 È R2:
R1 È R2 = { r / r Î R1 или r Î R2 }.
Объединяемые отношения должны иметь одинаковые атрибуты ( должны быть объединимы ):
Пересечение. В данной операции ( обозначенной Ç ) получают отношение, включающее кортежи, общие для R1 и R2:
R1 Ç R2 = { r / r Î R1 и r Î R2 }.
Разность: В результате применения этой операции (R1 \ R2 ) получается отношение, содержащее кортежи, являющиеся кортежами отношения R1 и не являющиеся кортежами отношения R2:
R1 \ R2 = { r / r Î R1 и r Ï R2 }.
Декартово ( прямое ) произведение. В этой операции ( R1 х R2 ) из m - местного отношения R1 и n - местного отношения R2 получают ( m + n ) - местное отношение. Причём первые m элементов представляют кортежи из отношения R1 , последние n элементов - кортежи из отношения R2:
R1 х R2 = {< r1, r2 > / r Ï R1 и r Ï R2 }.
Проекция: Операция проекции предназначена для изменения числа столбцов в отношении, то есть в том случае, когда из строк - кортежей требуется исключить какие-либо атрибуты. Обозначим через j1, j2,..., jn - номера столбцов n - местного отношения R. Операцию определения проекции отношения R обозначим через p j1, j2,..., jn ( R ), а сама операция заключается в том, что из отношения R выбираются столбцы и компонуются в указанном порядке j1, j2,..., jn.
Ограничение. Ограничением называют такую операцию, в которой отношение исследуют по строкам и выделяют множество строк, удовлетворяющим заданным условиям.
Соединение. Операция соединения обратна операции проекции. Рассмотрим два отношения R1 (А, В) и R2 (В, С). Соединением отношений R1 и R2 (R1 ¥ R2 ) называют операцию, при которой соединяют два отношения, используя в качестве признака общий атрибут В:
R1 ¥ R2 = { <A, B,C> / <A, B> Î R1 и <B, C> Î R2 }.
Отношение R1 ¥ R2 является отношением с атрибутами <A, B,C>.
Деление. Рассмотрим деление m - местного отношения R1 на n - местное отношение R2.
Пусть из общего количества m атрибутов отношения R1 выделим несколько атрибутов: A, B,...,F и из них составляем список, обозначив его через M. Набор значений атрибутов из М столбцов можно рассмотреть как проекцию отношения R на список атрибутов М, то есть pМ (R1). Тогда через М будут обозначаться атрибуты дополнительные к М, то есть атрибуты отношения R1, не вошедшие в список М, и соответственно значения атрибутов из списка М определяются pМ (R1).
Операцию деления можно определить так:
R1 [M ¸N] R2 = pМ (R1) \ pМ ((pМ (R1) ´ pN (R2)) \ R1 },
где pМ - это проекция отношения на атрибуты списка М.
Нормальные формы схем отношений (1-я, 2-я, 3-я, Боиса-Кодда).
Нормальные формы схем отношений
Рассмотрим отношение R{A1, A2,..., An}. Возможный ключ k отношения R - это комбинация атрибутов (возможно, состоящих из одного атрибута), обладающих следующими свойствами:
1. В каждом кортеже отношения R величина ключа k, единственным образом определяет этот кортеж.
2. Не существует атрибута в возможном ключе k, который мог быть удалён без нарушения свойства 1.
Если в отношении R имеется несколько возможных ключей, то один из них выбирается в качестве первичного. Всегда существует, по крайней мере, один возможный ключ, то есть комбинация всех атрибутов R удовлетворяет свойству 1.
Аномалия – такая ситуация в таблице БД, которая приводит к противоречиям в БД, либо существенно усложняет обработку данных.
Разновидности аномалий:
1. избыточность – одинаковые элементы информации повторяются многократно в нескольких кортежах.
2. аномалии изменения – один и тот же фрагмент данных изменяется в одном кортеже, но остается нетронутым в другом.
3. аномалия удаления – если множество значений становится пустым это может косвенным образом привести к потере некоторой другой информации.
Один из способов устранения аномалии – декомпозиция отношения. Декомпозиция отношения R предполагает разбиение множества атрибутов R c целью построения схем двух новых отношений с последующим занесением в эти отношения определенных в отношении R кортежей.
1НФ
Отношения находятся в 1НФ, если каждый атрибут отношения является простым (атомарным) атрибутом, то есть отсутствуют составные.
Пример: Автомобиль (модель, марка, изготовитель (завод, город)).
В данном случае атрибут изготовитель составной. Для приведения к 1НФ отношения необходимо избавится от составного отношения - изготовитель. Этого можно добиться, рассмотрев вместо составного атрибута его составляющие:
Автомобиль (модель, марка, название завода изготовителя, город ).
Приведение отношения к 1НФ достаточно для реализации языков запросов.
2НФ
Чтобы рассмотреть 2НФ, введём понятие полной зависимости. Пусть X и Y – элементы подмножества атрибутов отношения R и X ® Y. Если Y функционально не зависит от любого подмножества A множества X (причём A не совпадает с X ), то Y называют полностью зависимым от X в R.
Говорят, что отношение R находится во 2НФ, если оно нормализовано, то есть находится в 1НФ, и каждый первичный атрибут полностью зависит от первичного ключа.
Пусть имеется отношение ПОСТАВКИ, содержащее данные о поставках (идентифицируемых П№ ), поставляемых ими товарах и их ценах: ПОСТАВКИ (П№, ТОВАР, ЦЕНА)
Предположим, что поставщик может поставлять разные товары, а один и тот же товар могут поставлять разные поставщики. То есть, ключ отношения (выделенный шрифтом) будет состоять из атрибутов П№ и ТОВАР. Известно, что цена любого товара зафиксирована (то есть все поставщики поставляют товар по одной и той же цене). Семантика отношения включает следующие зависимости:
П№, ТОВАР ® цена (по определению КЛЮЧА) ТОВАР ® цена
Можно отметить неполную функциональную зависимость атрибута цена от ключа. Это приводит к следующим аномалиями: Аномалия включения. Если у поставщика появляется новый товар, информация о товаре и его цене не сможет храниться в базе данных до тех пор, пока поставщик не начнёт поставлять его.
Аномалия удаления. Если поставки некоторого товара прекращаются, из базы данных придётся удалить сведения о товаре и его цене, даже если он имеется в наличии у поставщиков.
Аномалия обновления. При изменении цены товара необходим полный просмотр отношения с целью найти все поставки товара, чтобы изменение цены было отражено для всех поставщиков. То есть, изменение значения атрибута одного объекта влечёт необходимость изменений в нескольких кортежах отношения; в противном случае база данных окажется несогласованной.
Разложение отношения ПОСТАВКИ на два отношения устраняет неполную функциональную зависимость.
ПОСТАВКИ (П№, ТОВАР)
ЦЕНА-ТОВАРА (ТОВАР, ЦЕНА)
Цену товара конкретной поставки можно определить путём соединения двух отношений по атрибуту ТОВАР. Изменение цены товара вызовет модификацию лишь одного кортежа второго отношения.
НФ3
Рассмотрим транзитивную зависимость следующего типа:
Если А ® В, В ® А (В не является ключом) и В ® С, то А ® С.
Отношение R находится в 3НФ, если оно находится во 2НФ и каждый непервичный атрибут в отношении R не содержит транзитивной зависимости от первичного ключа.
Пусть имеется отношение ХРАНЕНИЕ (ФИРМА, СКЛАД, ОБЪЁМ), которое содержит информацию о фирмах, получающих товары со складов, и объёмах этих складов. В отношении имеются функциональные зависимости:
ФИРМА ® СКЛАД (фирма получает товары только с одного склада)
СКЛАД ® ОБЪЁМ
Аномалия включения. Если на данный момент отсутствует фирма, получающая товар со склада, то в базу данных нельзя ввести информацию об объёме склада.
Аномалия удаления. Если последняя фирма перестаёт получать товар со склада, данные о складе и его объёме нельзя сохранить в базе данных.
Аномалия обновления. Если объём склада изменяется, необходим просмотр всего отношения и изменение кортежей для фирм, связанных со складом.
Преобразование отношения в 3НФ устраняет рассмотренные аномалии. Следующее разложение приводит к отношениям во 3НФ:
ХРАНЕНИЕ (ФИРМА, СКЛАД)
С_ОБЪЁМ (СКЛАД, ОБЪЁМ)
Нормальная форма Бойса - Кодда(НФБК)
Отношение R находится в НФ БК, если для всех зависимостей из X® А, когда А не принадлежит Х, Х является возможным ключом отношения R. Обычно атрибут, от которого функционально полно зависит другой, называется детерминантом. Поэтому говорят, что отношение R находится в НФБК, если все детерминанты являются ключами.
Пример: Пусть имеется отношение ПРОЕКТ (Д№, ПР№, П№), отражающее использование в проектах деталей, поставляемых поставщиками. В проекте используется несколько деталей, но каждая деталь проекта поставляется только одним поставщиком. Каждый поставщик обслуживает только один проект, но проекты могут обеспечиваться несколькими поставщиками (разных деталей). Детали, проекты, поставщики идентифицируются соответственно номерами Д№, ПР№, П№. В отношении присутствуют следующие функциональные зависимости:
Д№, ПР№ ® П№ (по определению ключа)
П№ ® ПР№
Рассматриваемое отношение находится в 3НФ, так как в нём отсутствуют неполные функциональные зависимости и транзитивные зависимости не первичных атрибутов от ключей; при этом, однако, наблюдаются следующие аномалии:
Аномалия включения. Факт поставки поставщиком деталей для проекта не может быть занесён в базу данных до тех пор, пока в проекте действительно не начнут использоваться эти детали.
Аномалия удаления. Если последний из типов деталей, поставляемых поставщиком для проекта, использован, данные о поставщике будут также удалены из базы данных.
Аномалия включения. Если меняется поставщик некоторого типа деталей для проекта, необходим просмотр отношения для изменения всех кортежей, содержащих эти детали.
Разложение исходного отношения на отношения в НФБК устраняет перечисленные аномалии. Отношение находится в НФБК, если оно находится в 3НФ и в нём отсутствуют зависимости первичных атрибутов от не первичных. Для этого необходимо устранить в данном отношении зависимость П№ ® ПР№. Следующее разложение приводит к отношениям в НФБК:
ПРОЕКТ - ДЕТАЛЬ (Д№, ПР№)
ПОСТАВКИ (П№, ПР№)
Избыточные функциональные зависимости.
Зависимость не заключающая в себе такой информации, которая могла бы быть получена на основе других зависимостей из числа используемых при проектировании БД называется избыточной функциональной зависимостью.
Поскольку избыточная функциональная зависимость не содержит уникальной информации она может быть удалена без урона для БД.
Избыточные функциональные зависимости удаляются на начальной этапе проектирования, до применения элемента декомпозиции. Набор неизбыточных функциональных зависимостей может быть получен с помощью6-ти правил, называемых минимальным покрытием.
Отношение является избыточным, если
1. Все его атрибуты могут быть найдены в другом отношении проектного набора.
2. Все его атрибуты могут быть найдены в отношении, которое может быть получено из других отношений проективного набора с помощью серии операций объединения над этими выражениями.
Если установлена избыточность отношения, то его следует исключить из проектного набора.
Минимальное покрытие. Обобщенный алгоритм декомпозиции.Полное множество правил вывода состоит из 3 аксиом Амстронга, а также трёх следующих из этих аксиом правил.
Правила вывода:
1. Аксиомы 1.2.3
1. Рефлексивность: XÍU, YÍU, YÍX, то XàY
2. пополнение: XÍU, YÍU, ZÍU, XàY, то XÈZàYÈZ
3. транзитивность: XÍU, YÍU, ZÍU, XàY, YàZ, то XàZ
2. Из них следуют правила:
1. Объединения AàB, AàC то AàB, C
2. Декомпозиции AàB, C, то AàB, AàC
3. Псевдотранзит: XàY; Y, WàZ; то X, WàZ
По этим правилам определяем избыточные зависимости
Обобщённый алгоритм декомпозиции:
1. Построение универсального отношения для БД.
2. Определение всех ФЗ, существующих между атрибутами универсального отношения.
3. Удаление всех избыточных ФЗ из исходного набора ФЗ с целью получения минимального покрытия. Эта процедура проводится путём поочерёдного удаления избыточных ФЗ с последующей проверкой получаемого на каждом шаге набора ФЗ на наличие хотя бы одной избыточной ФЗ.
4. Использование ФЗ из минимального покрытия для декомпозиции универсального отношения в набор НФБК- отношений.
5. Если может быть получено более чем одно минимальное покрытие, осуществляется сравнение результатов, полученных на основе различных минимальных покрытий, с целью определения варианта, лучше других отвечающего требованиям заказчика.
При исполнении алгебраической декомпозиции необходимо помнить о нежелательности проекции, порождаемой ФЗ, у которой зависимостная часть является детерминантом другой ФЗ или когда зависимостная часть ФЗ зависит более чем от одного детерминанта. В любом из этих случаев может быть утеряна ФЗ из БД. Если достигнуть состояние, в котором проецирование, не влекущее за собой потерь ФЗ, становится невозможным, то необходимо сделать выбор:
а). выбор оставшихся ФЗ и создание одного отношения для каждых детерминанта и набора зависящих от него атрибутов;
б). изменение порядка ранее проведенных декомпозиций, т. к. алгоритм проектирования не ведёт к единственному решению.
Соединение без потери сохраняющее зависимость, Условие отсутствия потерь при соединении.
Условия отсутствия потерь при соединении:
Если R1 и R2 являются разложением R, с сокращением функциональных зависимостей – это разложение обеспечивает соединение без потерь с сохранением функциональной зависимости <=> если R1^R2àR1-R2 либо R1^R2àR2-R1 при многозначной зависимости R1^R2->>R1-R2, либо R1^R2->>R2-R1
Операции пересечения и разности определены над списками атрибутов отношений.
Пример:
Служащие(№,отдел, город)
1 разложение E1(№, отдел) E2(№, город)
2 разложение E3(№, отдел) E4(отдел, город)
1. E1^E2=№ E1-E2=отдел E2-E1=город. №àотдел, №àгород условие удовлетворяет, разложение без потерь.
2. E3^E4=отдел E3-E4=№ E4-E3=город. отделà№, отделàгород эти зависимости в исходном разложении не существуют, а исходные функциональные зависимости утеряны, значит это разложение с потерями.
Для разложений более чем из двух отношений можно использовать метод Табло
Метод Табло.Дано множество функциональных зависимостей, схема отношения полученная в результате разложения. Процедура состоит в построении таблицы, строками которой являются разложенные отношения, а столбцами – список атрибутов этих отношений без повторений. Таблица заполняется символом aj если элементы строки i в столбце j соответствуют атрибуту Aj отношения Ri в противном случае ставится bij. После построения таблицы следует просмотр всех функциональных зависимостей XàY если для атрибутов из X найдутся строки, где в соответствующих местах стоят aj, то элементы bij этих строк соответствующие столбцам атрибутов из Y заменяется на aj. Если в результате появляется строка таблицы, полностью заполненная aj, то это соединение без потерь.
Пример: R(A, B,C, D) Ф. З. AàC, BàC, CàD.
Разложили: R1(A, B) R2(B, D) R3(A, B,C) R4(B, C,D)
…
| AàC
| ||||||||||||||||||||||||||||||||||||||||||||||||||
BàC
| CàD
|
Есть строки со всеми a, разложение без потерь.
Язык запросов SQL. Основные категории. Типы связывания.
Язык запросов SQL. Основан на реляционном исчислении с переменными-кортежами.
SQL нужен для выполнения операций над таблицами и над данными таблицы.
Как правило, SQL погружен в среду встроенного языка программирования СУБД.
SQL не обладает функциями языка разработки. Он ориентирован на доступ к данным. В этом случае его называют встроенным SQL, то есть он включен в состав средств разработки программ.
Различают 2 основных метода использования встроенного SQL: статический и динамический
При статическом использовании языка в тексте программы имеются вызовы функций языка SQL, которые жестко включаются в выполняемый модуль после компиляции.
При динамическом использовании языка предполагается динамическое построение вызовов SQL функций. Динамический метод используется в случае, когда в приложении заранее неизвестен вид SQL вызова.
Основные категории:
DDL Data Definition Language (Язык определения данных)
Основные команды:
Создать таблицу, Удалить таблицу, Изменить таблицу, Создать представление, Изменить представление, Удалить представление, Создать индекс, Удалить индекс.
DML Data Manipulation Language (Язык манипулирования данными)
Основные команды: Создать строку, Вставить строку, Обновить строку.
DQL Data Query Language (Язык запросов к данным)
Основные команды: Select
DCL Data Control Language (Язык управления данными)
Основная команда: Контроль над возможностью доступа к данным внутри базы данных.
Команды DCL обычно используются для создания объектов, относящихся к управлению доступом пользователей к базе данных, а также для назначения пользователям соответствующих уровней привилегий доступа.
Некоторые команды: Изменить пароль, Дать привилегию, Отменить привилегию
DAC – Data Administration Commands
Данные команды дают пользователю возможность выполнять анализ операций внутри базы данных.
TTC – Transaction Control Commands (Команды управления транзакциями)
Используются только с командами DML: Сохранить транзакцию, Отменить транзакцию, Создать точки внутри групп транзакций
Типы связывания:
Связывание по равенству EQUIT JOINS Естественное связывание NATURAL JOINS Связывание по неравенству NON – EQUI JOINS Внешнее связывание OUTER JOINS Рекурсивное связывание SELF JOINSСвязывание по равенству EQUIT JOINS
Самый простой тип. Называется внутренним связыванием (INNER JOIN). При связывании по равенству таблицы связываются по общему столбцу, который в каждой таблице является ключевым.
Естественное связывание NATURAL JOINS
Почти эквивалентно связыванию по равенству, но при естественном связывании повторение эквивалентных строк исключается. Условие связывания оказывается таким же.
Связывание по неравенству NON – EQUI JOINS
При связывании по неравенству 2 или несколько таблиц объединяются по условию неравенства значения столбца одной таблицы значению столбца другой таблицы.
Внешнее связывание OUTER JOINS используется, когда вывод должен содержать все записи одной таблицы, даже если некоторые из ее записей не имеют соответствующих записей в другой таблице. Во многих реализациях языка внешнее связывание разбито на левое (LEFT JOIN), правое (RIGHT JOIN) и полное внешнее связывание (FULL JOIN).
Рекурсивное связывание SELF JOINS
Рекурсивное связывание предполагает связывание таблицы с ней же самой, как будто бы это 2 таблицы, применяя временные переименования таблицы в операторе SQL.
Если нужно связать таблицы, не имеющие общих столбцов, необходимо использовать третью таблицу, имеющую общие столбцы как с 1-ой, так и со 2-ой таблицей. Такая таблица – связующая таблица.
Многотабличные запросы. Состояние справочной целостности. Использование псевдонимов.Пример: пусть необходимо поставить в соответствие преподавателей и учебные предметы, которые он ведет
Предполагается, что созданы следующие таблицы:
STUDENT (SNUM, SFAM, SIMA, STIP)
USPEV (UNUM, OCENKA, UDATA, SNUM, PNUM)
PREDMET (PNUM, PNAME, TNUM)
TEACHER (TNUM, TFAM, TIMA, TDATE)
UDATA – дата оценки
TDATE – день рождения учителя
1. Вывод фамилии преподавателя и предмет, который он ведет
SELECT TEACHER. TFAM, PREDMET. PNAME;
FROM TEACHER, PREDMET;
WHERE TEACHER. TNUM=PREDMET. TNUM
Эти таблицы уже были соединены через поле TNUM. Эта связь называется состоянием справочной целостности. Объединение многотабличных запросов, которые используют предикаты, основанные на равенствах – объединение по равенству. Этот же подход может использоваться для объединения вместе двух копий одиночной таблицы. Когда объединяется таблица сама с собой, все повторяемые имена столбца заполняются префиксами имени таблицы. Чтобы ссылаться к этим столбцам внутри запроса, необходимо иметь 2 различных имени для этой таблицы. Это можно сделать с помощью определения временных имен, называемых псевдонимами, которые определяются в предложении FROM запроса.
Вывод фамилий студентов, имеющих одинаковый размер стипендииSELECT FIRST. SFAM, SECOND. SFAM, FIRST. STIP;
FROM STUDENT FIRST, STUDENT SECOND; WHERE FIRST. STIP=SECOND.STIP
FIRST, SECOND - псевдонимы
В данном запросе SQL ведет себя так, как если бы он соединял 2 различные таблицы, называемые FIRST и SECOND. Псевдоним существует только тогда, команда выполняется, а после завершения запроса псевдоним больше не имеет никакого значения. Допускается использовать любое число псевдонимов для одной таблицы запросов.
Использование UNION для объединения результатов инструкций SELECT.
UNION объединяет информацию из 2-х и более отдельных запросов SELECT в один курсор или таблицу. При этом в команде SELECT можно использовать до 10 членов UNION, связывая каждую инструкцию SELECT с предыдущей. Результирующий набор, созданный первой командой SELECT, определяет требуемую структуру для остальных команд SELECT. Порядок, количество, размер и тип полей в первой команде SELECT определяет структуру для всех последующих команд SELECT.
Например, для получения списка всех студентов и преподавателей фамилии которых заключены между буквами «К» и «С»:
SELECT SFAM, SIMIA FROM STUD;
WHERE SFAM BETWEEN ‘K’ AND ‘C’;
UNION;
SELECT TFAM, TIMIA FROM TEACHER;
WHERE TFAM BETWEEN ‘K’ AND ‘C’
Когда 2 или более запросов подвергаются объединению, их столбцы вывода должны быть совместимы для объединения. Это означает для каждого запроса необходимость включения одинакового числа столбцов в том же порядке, что и 1, 2, 3 и т. д. и при этом должна присутствовать совместимость типов.
Например: символьные поля должны иметь одинаковое число символов. Кроме того нельзя использовать агрегатные функции в запросе SELECT при объединении. Агрегатные функции – MIN, MAX, AVG, SUM. Также UNION будет автоматически исключать дубликаты строк из вывода.
Воздействие ключевого слова UNION аналогично действию DISTINCT. Это значит, что каждая добавленная в результирующий набор запись проверяется на уникальность. Члены UNION используются только для объединения запросов, но никак не влияют на подзапросы.
Правила объединения с помощью UNION:
Любое поле, включенное в первый список полей, должно быть представлено полем или заглушкой в последующих списках полей. Любое поле из последующих списков полей, которое не входит в первый список полей, должно быть представлено заглушкой в первом списке В первом списке не должно быть вычисляемых полей Члены ORDER BY и INTO могут входить в любую инструкцию SELECT, но только 1 раз и применяются ко всему результату. Член ORDER BY должен ссылаться на поля, по их позициям в списке, а не по имени. При отсутствии члена ORDER BY для сортировки используется порядок следования полей в списке. Члены GROUP BY и HAVING могут присутствовать в каждой инструкции SELECT, причем их влияние ограничено только результатами работы данной инструкции SELECT. С помощью членов UNION нельзя объединять результаты подзапросов, то есть члены UNION нельзя применить к инструкциям SELECT, используемым внутри члена WHERE других инструкций SELECT.При построении объединения можно использовать не более 10 членов UNION.
Использование DISTINCT.
УДАЛЕНИЕ ИЗБЫТОЧНЫХ ДАННЫХ
DISTINCT (ОТЛИЧИЕ) - аргумент, который обеспечивает способ устранять дублирующие значения из предложения SELECT.
Пример:
SELECT DISTINCT snum
FROM Orders;
DISTINCT следит за тем, какие значения были ранее, чтобы они не дублировались в списке. Это полезный способ избежать избыточности данных.
ПАРАМЕТРЫ DISTINCT
DISTINCT может указываться только один раз в данном предложении SELECT. Если предложение выбирает несколько полей, DISTINCT опускает строки, где все выбранные поля идентичны. Строки, в которых некоторые значения одинаковы, а некоторые - различны, будут сохранены. DISTINCT фактически приводит к показу всей строки вывода, не указывая полей (за исключением случаев, когда он используется внутри агрегатных функций), так что нет никакого смысла его повторять.
Изменение существующих данных, представление.
Эта команда содержит ключевое слово UPDATE, где указывается имя используемой таблицы и предложение SET, которое определяет вносимое изменение для требуемого поля таблицы. При помощи команды UPDATE можно модифицировать данные из нескольких полей, а также использовать подзапросы. При этом нельзя в предложении FROM любого подзапроса модифицировать таблицу, к которой ссылается основная команда.
Представление
VIEW – некоторое подобие таблицы, содержание которой выбирается с помощью выполнения запроса. Причем при изменении значения в этих таблицах автоматически меняется их представление.
Представление создается командой CREATE VIEW, после которого указывается его имя, а далее следует запрос, формирующий тело представления. Поля представления могут иметь свои имена, полученные из имен полей основной таблицы. Представления могут также использовать подзапросы, в том числе и соотнесенные.
Вывести все оценки по дисциплине, которые больше средней оценки по этой дисциплине.
CREATE VIEW AVG OC AS;
SELECT * FROM USP FIRST;
WHERE OCENKA > (SELECT AVG (OCENKA)
FROM USP SECOND;
WHERE SECOND. PNUM=FIRST. PNUM)
_________________
Вывести фамилии, шифр, предмет, который студент сдал.
SELECT STUD. FAM, STUD. SNUM, USP. PNUM, USP. SNUM;
FROM STUD INNER JOIN USP;
ON STUD. SNUM=USP. SNUM
CREATE VIEW <имя>
(<имя поля>, <тип>[(<размер>,…)[,<имя поля>]])
/FROM ARRAY <массив>
INSERT INTO <имя файла>[(<поле1>[,<поле2>])]
VALUES <выражение1>[,<выражение2>]
Добавление записей в конец существующего файла, используя выражения, перечисленные после слова VALUES.
Если опущены имена полей, выражения будут записываться в последовательные поля базы данных в соответствии с ее структурой.
INSERT INTO <имя> FROM ARRAY <имя>
Распределенная обработка данных (модель файлового сервера, удаленного доступа к данным, активного сервера, сервера приложений).
Параллельный доступ к одной базе данных нескольких пользователей в том случае, если база данных расположена на одной машине, соответствует режиму распределенного доступа к централизованной базе данных – системы распределенной обработки данных.
Если база данных распределена по нескольким компьютерам, располагающимся в сети, и к ней возможен параллельный доступ нескольких пользователей, то это соответствует режиму параллельного доступа к распределенной базе данных.
Такие системы – системы распределенных баз данных.
Основной принцип технологии «клиент-сервер», применяемой к технологии баз данных – разделение функций стандартного интерактивного приложения на 5 групп:
1. функция ввода и отображения данных (presentation logic - PL)
2. прикладные программы, определяющие основные алгоритмы решения задач приложения (business logic - BL)
3. функция обработки данных внутри приложения (database logic - DL)
4. функция управления информационными ресурсами (Database Manager System)
5. служебные функции, играющие роль связок между функциями групп 1..4
Модель файлового сервера
или модель DDM FS
Здесь presentation logic и business-logic располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами находятся на клиенте. В этой модели файлы базы данных хранятся на сервере. Клиент обращается к серверу с файловыми командами, а механизм управляет всеми информационными ресурсами, база мета данных на клиенте.
Модель удаленного доступа к данным
(Remote Data Access)
База данных хранится на сервере. Там же находится ядро СУБД. На клиенте располагается Presentation Logic и Business Logic.
Достоинства: унификация интерфейса клиент-сервер. Резко уменьшается загруженность сети. Сервер базы данных загружается целиком операциями обработки данных запросов и транзакций.
Недостатки: так как в этой модели на клиенте располагается презентационная и бизнес логика, то при повторении аналогичных функций в разных приложениях код бизнес логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование информации. Сервер в этой модели пассивен. Функции управления информационными ресурсами выполняются на клиенте, что усложняет клиентское приложение. Запросы на SQL могут существенно загрузить сеть при интенсивной работе.
Модель активного сервера
Ее поддерживает большинство современных СУБД.
Основа этой модели – механизм хранения процедур, как средств программирования SQL сервера.
Механизм триггеров, как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры.
Модель сервер-приложение
Application Server
AS – расширение двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот уровень содержит один или несколько серверов-приложений. В этой модели компоненты – приложения делятся между тремя исполнителями.
Модели транзакций.
Транзакция – последовательность операций, производимых над базой данных и переводящих базу данных из одного непротиворечивого состояния в другое.
Типы транзакций:
Плоские (классические) Цепочечные ВложенныеПлоские характеризуются четырьмя классическими свойствами.
Атомарность (Atomicity) Согласованность (Consistency) Изолированность (Isolation) Долговечность (Durability)Атомарность (Atomacity) выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
Согласованность (Consistency) гарантирует, что по мере выполнения транзакций, данные переходят из одного согласованного состояния в другое. Транзакции не разрушает взаимной согласованности данных.
Изолированность (Isolation) гарантирует, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно изолированно друг от друга, но для пользователя выглядят так, как будто выполняются параллельно.
Долговечность (Durability): если транзакция завершена успешно, то те изменения в данных, которые были произведены, не могут быть потеряны ни при каких обстоятельствах, даже в случае последующих ошибок.
Возможны 2 варианта завершения транзакции:
Фиксация – действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. Это значит, что результаты выполнения транзакции станут видимы другим пользователям. Откат – действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.Модель транзакции:
Транзакция начинается с первого SQL оператора. Последующие составляют тело транзакции. Commit выполняется в случае успешного завершения обработки информации, объединенной в транзакцию. Его выполнение фиксирует изменения, внесенные в базу данных текущей транзакции. Roilback прерывает выполнение транзакции и осуществляет отмену изменений, проведенных в ходе выполнения транзакции.
Вопросы реализации в СУБД подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается журнал транзакций. Он предназначен для надежного хранения данных в базе данных. Это требование предполагает возможность восстановления согласованного состояния базы данных после любого рода программных или аппаратных сбоев.
Файловые структуры, используемые для хранения информации в БД (файлы прямого и последовательного доступа, индексные файлы, инвертированные списки, B-деревья и т. д.)
Классификация
Файлы:
1.прямого доступа
2.последовательного доступа
3.индексные
· плотный индекс (индексно-прямые)
· В – деревья
· Индексно-последовательные
4.инвертированные списки
5.взаимосвязанные файлы
· с однонаправленными цепочками
· с двунаправленными цепочками
Прямого доступа на устройствах прямого доступа. Имеют фиксированную длину записи, и обеспечивают более быстрый доступ. Адрес м. б. вычислен по номеру записи. Однако поиск по номеру неэффективен. Лучше искать по ключам, поэтому есть ф-я преобразования ключа в номер.(например – хеширование(рассказать))
С переменной длиной записи – последовательного доступа. Тогда конец записи отмечается специальным маркером, либо в начале каждой записи дана ее длина.
Плотный индекс: данные в области данных одинаковой длины. В индексной области все записи упорядочены по значению ключа.
Неплотный индекс – ключ указывает не на запись, а на страницу записей. Внутри страниц записи упорядочены.
Б деревья – построение индекса по индексу
Инвертированные списки: ведется поиск по вторичным ключам. Они м. б. одинаковыми. Инвертированный список – двухуровневая индексная структура. На первом уровне расположены значения вторичных ключей. На втором – блок указателей на записи с таким значением ключа. На третьем – собственно данные.
Деревья – ежику понятно.(LPTR, DATA, RPTR)
Хеширование. Методы разрешения коллизий.
Хеширование - технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля, которое может быть доже не ключевым.
1.Каждая запись БД размещается по адресу, вычисляемому путем применения к значению ключа некоторой функции свертки (хэш-функция), вырабатывающей значение меньшего размера. Для эффективного использования дискового пространства необходим подбор хэш-функции.
2.Свертка ключа используется и для доступа к записи. В самом простом случае свертка используется как адрес в таблице, содержащей ключи и записи.
Основным требование к хэш-функции является равномерное распределение значений свертки, где одному значению хэш-функция может соответствовать одно значение ключа. Если для нескольких значений ключа получается одно и то же значение хэш-функция – коллизия.
Значения ключей, которые имеют одно и то же значение хэш-функции – синонимы.
Методы разрешения коллизий
1.Метод последовательного перебора. Значение хэш-функции – отправная точка для дополнительного просмотра и поиска. Запись сохраняется в первом свободном месте.
2.Стратегия разрешения коллизий с областью переполнения. Область хранения разбивается на две части: основную и область переполнения. Значение хэш-функции – адрес записи, запись заносится в основную область. Если при вставке нового значения возникает коллизия, то новая запись заносится в область переполнения на первое свободное место, а записи-синониме в основной области делается ссылка на адрес вновь размешенной записи в области переполнения. Следующая новая запись-синоним будет располагаться на втором месте списка. Т. о. для размещения новой записи требуется не более двух обращений к диску. Хорошим результатом может считаться наличие не более 10 синонимов.
3.Организация стратегии свободного размещения. Одна общая область замещения. Записи-синонимы организуются в двухсвязный список.
a. Если при вставке новой записи ее адрес занят записью, которая не является заголовком списка, то она перемещается на свободное место с коррекцией указателей. А новая запись встает на ее место.
b. Если адрес занят заголовком списка, то новая запись располагается на свободном месте, и для нее устанавливаются соответствующие указатели.
c. Если адрес свободен, то новая запись размещается в заданном месте и становится заголовком в списке синонимов.
