

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Автоматический словарь
анализа и приведения слов к канонической форме
,
Таганрогский государственный радиотехнический университет
г. Таганрог
ВВЕДЕНИЕ
При разработке информационно-поисковых систем (ИПС) огромная роль отводится созданию эффективных методов представления и структуре хранения информации о документах, во множестве которых осуществляется поиск. Существует ряд подходов к проблеме представления информации, содержащейся в документе и в коллекции документов.
В рамках статистического подхода документ рассматривается как последовательность слов, которые могут группироваться в более крупные структуры (предложения, абзацы и т. п.). В этом подходе не анализируется смысл отдельных слов, предложений и всего текста документа. Учитывается информация только о структуре текста документа, прежде всего о частоте вхождения в текст отдельных слов.
В рамках семантического подхода делается попытка выявить смысл текста за счет анализа грамматики, использования различных специальных словарей и тезаурусов, отражающих семантические связи между отдельными словами и их группами.
При этом большинство существующих классических ИПС используют механизм автоматического сжатия (индексации) текста документов. Проблемой индексации является автоматическое выделение ключевых слов и выражений, специфичных для определенных предметных областей и отражающих тематическую направленность текстов документов. Для определения множества терминов, пригодных для индексации документов, необходимы вычисление степени (частоты) присутствия терминов в документе, места присутствия (находится в заголовке, подзаголовке, начале документа), получение информации о склонении термина (форме употребления термина в тексте) анализ и выявление семантических связей терминов. Все это характеризует статистические и семантические параметры терминов в тексте документа.
ПОДХОДЫ К ОРГАНИЗАЦИИ СЛОВАРЯ
Для выявления множества ключевых терминов, а так же при обработке терминов запросов пользователей необходимо все множество форм склонения сводить к заранее оговоренной канонической форме (КФ). В качестве КФ может выступать либо основа (или даже корень), либо традиционные исходные формы слова (именительный падеж единственного числа).
Для задачи приведения необходимо создание автоматического словаря основ [1], с помощью которого можно получить каноническую форму слова и информацию о склонении [2, 3]. Следует выделить основные компоненты, от реализации которых зависит эффективность использования словаря в статистическом и семантическом анализе:
– Организация структуры словаря. Словарь должен быть прост в реализации, не должен содержать сложных и многообъемных элементов. Необходимо учесть минимальное использование дополнительных ресурсов и затраченное время на доступ к элементам словаря.
– Алгоритм определения канонической формы и склонения. Элементы словаря должны содержать необходимую информацию для приведения и максимально полную для определения склонения, что исключает использование дополнительных методов пред - и постобработки.
В рамках разработки методов статистического и семантического анализа текстов документов был создан автоматический словарь начальных форм слов.

Рис. 1. Схематическое представление словаря.
Словарь разработан так, что в нем содержаться именно формы слов, а не их неизменяемые части или другие виды их представления, а также дополнительная информация о склонении и правила построения начальной формы.
Это позволяет искать слова в словаре без какой-либо предобработки, в том виде, в котором они были получены из текста документа, и только при положительном поиске входной формы строить выходную каноническую форму по соответствующим правилам.
Особое внимание следует уделить внутреннему представлению элементов словаря. Хранение полностью форм слов неэффективно с точки зрения объема словаря, хранение форм слов в сжатом виде подразумевает использование различных дополнительных методов (получение хранимой формы по правилам распаковки), что влияет на скорость обработки. Элементы разработанного словаря содержат буквы (символы) слов, что позволяет уменьшить объем словаря, значительно увеличить скорость обработки входящих форм и использовать для его организации древовидные структуры, которые в отношении хранения и поиска очень удобны и эффективны. Принцип такой организации заключается в объединении у разных словоформ одинаковых комбинаций символов и создании последовательной цепочки словообразования:
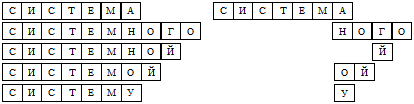
Рис. 2. Пример объединения комбинаций символов и образование цепочек.
РЕАЛИЗАЦИЯ В ВИДЕ БИНАРНОГО ДЕРЕВА
Для реализации данного представления элементов было взято бинарное дерево [4], построенное по принципу «левый сын, правый брат». При этом «братья» являются равноправными, «сыновья» — подчиненными. Каждый узел бинарного дерева содержит 0 или 1 подчиненный узел, который соединен с равноправными ему «братьями». Рассмотрим бинарное дерево для вышеуказанного примера:
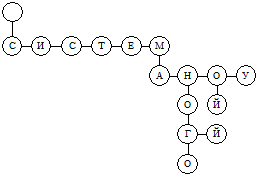
Рис. 3. Пример бинарного дерева.
Как видно, после буквы М могут следовать или А, или Н, или О, или У. После Н — О, после этой О — или Г, или Й, после Г — О и т. д.
Бинарное дерево очень удобное и простое в плане программной реализации. Дерево было реализовано в виде линейной структуры:
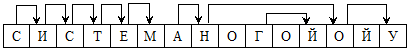
Рис. 4. Пример бинарного дерева в виде линейной структуры.
Следует отметить, что для правильного построения словаря, вводимые слова должны располагаться в алфавитном порядке, чтобы достигнуть максимального уплотнения за счет общих комбинаций символов и не нарушить порядок следования букв друг за другом.
Для реализации линейной структуры необходимы указатели, причем, ссылка происходит на следующего «брата», «сыновья» (подчиненная ветка) в линейной структуре следуют без ссылки сразу за «родителем».
Учитывая все необходимые данные для поиска и для приведения к канонической форме, элементы словаря представлены в следующем виде:
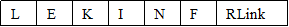
Рис. 5. Элемент автоматического словаря.
Где:
– L — символ слова,
– E — признак конца слова,
– K — признак продолжения слова (т. е. наличие «сына»),
– I — информация о склонении слова,
– N — позиция удаления флексии слова,
– F — флексия канонической формы,
– RLink — указатель на следующий узел (на «брата»).
Признак конца слова (E) служит для указания об окончании поиска слова. У последних букв слов данный признак установлен, у остальных — нет. Но как показали исследования: одного признака E не достаточно. Для корректного поиска введен признак K — признак «сына», т. е. признак продолжения последовательности букв в слове. Существуют слова, которые являются частью других слов, например:
![]()
Соответственно, осуществляя поиск слова «организация», система находила бы признак конца слова «орган» и выдавала неправильную информацию. В данном случае, найдя признак конца слова «орган», система проверяет: есть ли продолжение (установлен ли признак K), в данном случае признак будет установлен и поиск слова «организация» продолжится.
С помощью поля I можно получить следующую информацию о слове:
– Часть речи: существительное, прилагательное, глагол, деепричастие, наречие, краткое прилагательное, причастие. И что немаловажно для индексирования — общеупотребительное;
– Общая информация для каждой части речи индивидуальная: род, число, лицо, падеж, совершенная или несовершенная форма.
Поле N используется при образовании канонической формы и определяет, с какой позиции входного слова удаляется ненужная часть и дописывается флексия, для получения канонической формы.
Поле F содержит флексию, которая дописывается с позиции N.
Поле RLink содержит численное значение, определяющее порядковый номер элемента в линейной структуре, на который ссылается данный элемент.
Алгоритмы создания словаря в виде дерева и дальнейшего пополнения достаточно просты. Построение дерева начинается с создания списка всех форм слов в алфавитном порядке с необходимой служебной информацией, каждое слово разбивается на символы, которые и записываются в узлы дерева. Для каждого конечного символа слова записывается служебная информация (I, N, F). Алгоритм дополнения повторяет создание словаря, только предварительно необходимо внести изменения или дополнения в алфавитный список форм слов.
Алгоритм поиска в словаре заключается в последовательном сравнении букв слова и значения поля L в элементах словаря. Поиск считается удачным, если до конца слова цепочка сравнения не прервалась и последний сравниваемый элемент имеет установленный признак конца слова.
ХАРАКТЕРИСТИКИ РАЗРАБОТАННОГО СЛОВАРЯ
Разработанный словарь имеет следующие характеристики:
– Начальное заполнение словаря производилось за счет словарного запаса словаря А. Зализняк, которое составляет около 110 000 слов в начальной форме. Было образовано 1 272 200 форм слов, которые и были записаны в словарь. Дерево словаря насчитывает 1 832 919 узлов (элементов). При «грубой», неэкономной записи, когда в узлы записываются флексии и информация о склонении в явном виде (в виде символьных строк), размер элементов составляет 24 байта. При этом размер словаря — 43 990 056 байт. Разработанные механизмы экономичной записи позволили уменьшить размер элементов до 8 байт, а размер словаря — до 14 663 352 байт;
— Скорость обработки входного слова напрямую зависит от скорости посимвольного поиска его в словаре. В результате посимвольной организации словаря максимальное количество проверок букв входящего слова при поиске составляет ![]() , где
, где ![]() — длина слова. Число 33 определяется количеством букв алфавита, в данном случае русского алфавита.
— длина слова. Число 33 определяется количеством букв алфавита, в данном случае русского алфавита.
Вообще, возможно создание словаря данной структуры для любого другого языка. При этом требуется список слов в алфавитном порядке, правила образования словоформ и информация о склонении.
Автоматический словарь был успешно реализован для русского и английского языков. Русский и английский словари были использованы в задаче автоматического распознавания факсимильных сообщений с помощью алгоритма Витерби [5]. Русский словарь с полным набором служебной информации — в задаче автоматической обработки и индексации текстовых документов [6].
Разработка автоматического словаря производится в рамках проекта, поддержанного грантом РФФИ № и грантом № в.
ЛИТЕРАТУРА
1. А. Разработка автоматического словаря машинных основ в системе анализа текста //6 всероссийская научная конференция молодых ученых и аспирантов «Новые информационные технологии Разработка и аспекты применения». 27–28 ноября 2003 г. С. 482–485.
2. Семантический анализ текстов на русском языке //Вестник СПбГУ, (1): 45–50, 1998.
3. Текст, машина, человек — СПб.: Наука, 19с.: ил.
4. Искусство программирования для ЭВМ. Т. 1: Основные алгоритмы. — М.: Мир, 19с.
5. , Контекстное нейросетевое распознавание символов с учетом словаря и переходных вероятностей /Сборник трудов научно-практической конференции «Информационная безопасность». Таганрог, 28–31 мая 2002 г. С. 288–292.
6. , Кононова Т. С. Алгоритмические основы разработки поисковой системы //Четвертая Всероссийская конференция «Электронные библиотеки: перспективные методы и технологии, электронные коллекции». Дубна, 15–17 октября 2002 г. С.170–177.
