

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Линейная нейронная сеть может быть создана одним из следующих способов:
net=newlin(PR, S, id, lr),
net=newlin(PR, S, 0, P),
net=newlind(P, T),
где PR – массив размера R*2 минимальных и максимальных значений для R векторов входа;
S – число нейронов;
id – описание линии задержки на входе сети, по умолчанию [0];
lr – параметр скорости настройки, по умолчанию 0,01;
P – обучающие последовательности входов размера R*Q, причем Q – количество последовательностей;
Т – последовательность целей для Р размера S*Q;
0 – нуль. .
Первый способ применяется, когда в сеть включаются задержки, т. е. для создания динамических адаптивных линейных нейронных сетей ADALIN (ADApture Linear Neuron networks), которые позволяют корректировать веса и смещения при поступлении на вход каждого элемента обучающего множества. Такие сети широко применяются при решении задач обработки сигналов и в системах управления.
Второй способ формирует линейный слой с параметром скорости настройки, гарантирующим максимальную степень устойчивости для данного входа Р. В этом случае линии задержки не используются и сеть является статической.
Для первого и второго способа инициализация сети проводится при ее создании с помощью функции initzero. Адаптация и обучение сети затем осуществляется с помощью функции adaptwb, которая модифицирует веса и смещения, используя функцию Видроу – Хоффа hearnwh до тех пор, пока не будет достигнуто требуемое значение критерия качества обучения в виде средней квадратичной ошибки, вычисляемой функцией mse.
Третий способ формирует и настраивает линейную статическую сеть, решая систему линейных алгебраических уравнений на основе метода наименьших квадратов. Он используется для подбора коэффициентов аппроксимирующей функции и для идентификации параметров динамических систем в задачах управления. Матричная запись решаемой системы линейных алгебраических уравнений такова:
[W b]*[P;ones]=T,
при этом должно выполняться условие
S*R + S = Q.
Функция learnwh вычисляет приращение весов входов и смещений по следующим векторным формулам:
pn = p/(sqrt(1+P(1)^2)+… +P(R)^2);
dW = lr*e*pn;
db = lr*e.
При работе с моделями линейных сетей могут возникнуть ситуации, когда число настраиваемых параметров недостаточно, чтобы выполнить все условия; в этом случае сеть считается переопределенной. Если число параметров слишком велико, сеть считается недоопределенной. И в том и в другом случае метод наименьших квадратов осуществляет настройку, стремясь минимизировать ошибку сети.
Архитектура однослойной линейной сети полностью определяется задачей, которая должна быть решена, причем число входов сети и число нейронов в слое определяются числом входов и выходов задачи соответственно.
Практические задания
Задание 1. Выполнить задания с 1-го по 5-е лабораторной рабо-
ты № 6 и для линейной нейронной сети с таким же числом нейронов и входов, что и у соответствующего персептрона, заменив функцию newp функцией newlin, оставляя параметры неизменными и используя значения параметров id и lr по умолчанию, т. е. [0] и 0,01 соответственно.
Задание 2. Построить поверхность ошибок для линейной сети с одним нейроном и одним входом, используя функцию errsurf и выполнив следующие команды:
Р = [1 -1.2];
T = [0.5 1];
net = newlind(P, T);
Y = sim(net, P) % – 0.5 и 1;
net. IW{1,1} % – -0.22727;
net. b{1} % – 0.72727;
w_rangle = -1: 0.1: 0 % – диапазон весов;
b_ rangle = 0.5: 0.1: 1 % – диапазон смещений;
ES = errsulf(P, T, w_ rangle, b_ rangle, 'purelin');
contour(w_ rangle, b_ rangle, ES, 20) % – 20 уровней;
hold on
plot(-2.2727e – 001, 7.2727e – 001, 'x') % –точка
hold off % – знаком 'x' отмечены оптимальные значения
веса и % смещения.
Задание 3. Создать с помощью функции newlin линейную сеть с одним нейроном и одним входом, обучить эту сеть, используя процедуру train, и построить поверхность функции критерия качества и траекторию обучения, выполнив следующие действия:
1. Сформировать обучающее множество и рассчитать максимальное значение параметра обучения maxlr:
P = [1 -1.2];
T = [0.5 1];
maxlr = 0.40*maxlinlr(P,'bias').
2. Создать линейную сеть:
net = newlin([-2 2], 1, [0], maxlr);
gensim(net).
3. Рассчитать функцию критерия качества:
w_rangle = -1: 0.2: 1; b_rangle = -1: 0.2: 1;
ES = errsulf(P, T, w_rangle, b_rangle, 'purelin').
4. Построить поверхность функции критерия качества:
surfc(w_ rangle, b_ rangle, ES).
5. Рассчитать траекторию обучения:
Х = zeros(1, 50); Y = zeros(1, 50);
net.IW{1,1} = 1; net.b{1} = -1 % – начальные значения;
X(1) = net.IW{1}; Y(1) = net.b{1};
net. trainParam. goal = 0.001;
net. trainParam. epochs = 1;
6. Вычислить веса и смещения:
for I=2:50,
[net, tr] = train(net, P, T);
X(I) = net. IW{1, 1};
Y(I) = net. b{1};
end
7. Построить линии уровня и траекторию обучения:
clc; % очистка экрана
contour(w_ rangle, b_ rangle, ES, 20) % 20 линий
hold on
plot(X,Y,'_ *') % – построение траектории
hold off
8. Оценить значения параметров настройки для двух значений цели goal:
net.IW{1, 1} = 1; net.b{1} = -1;
net.trainParam.epochs = 50;
net.trainParam.goal = 0.001; % – первое значение;
[net, tr] = train(net, P, T);
net. IW{1, 1}, net. b{1} % - [-0.22893] [0.70519];
net. trainParam. goal = 0.00001; % – второе значение
[net, tr] = train(net, P, T);
net. IW{1, 1}, net. b{1} % – [-0.22785] [0.72495]
Задание 4. Сформировать линейную сеть с одним нейроном, одним входом, принимающим значения из диапазона [-1, 1], и линией задержки типа [0 1 2] для воспроизведения заданного отклика некоторой системы, выполнив следующие действия:
1. Создать линейную сеть заданной архитектуры с параметром скорости настройки, равным 0,01:
net = newlin([-1 1], 1, [0 1 2], 0.01);
gensim(net).
2. Сформируем две обучающие последовательности:
Р1 = {0 ––};
Т1 = {0 ––};
Р2 = {1 0 –1 ––1};
T2 = {2 1 –1 –}.
3. Выполнить обучение для последовательностей Р1 и Т1:
net = train(net, P1, T1);
net. IW{1, 1}, net. b{1}, % – [0.875] [0.8875] [-0.1336] [0.0619];
Y1 = sim(net, [P1 P2]);
4. Выполнить обучение сети на всем объеме обучающих данных:
net = init(net);
P3 = [P1 P2];
T3 = [T1 T2];
net. trainParam. epochs = 200;
net. trainParam. goal = 0.01;
net = train(net, P3, T3);
net. IW{1, 1}, net. b{1} % – [0.9242] [0.9869] [0.0339] [0.0602]
Y3 = sim(net, P3) % – дискретная модель:
% Yk = 0.9242rk+0.9869 rk-1+0.0339 rk-2+0.0602.
5. Построить графики отклика Т3 и приближений Y1 и Y3:
plot(0:0,01:20, T3, 'G'), hold on % – зеленый;
plot(0:0,01:20, Y1, 'B'), hold on % – синий;
plot(0:0,01:20, Y3, 'R'), hold off % – красный.
Задание 5. Сформировать линейную сеть из одного нейрона и одного входа, который обеспечивает для заданного входа Р, близкий к цели Т, выполнив следующие команды:
P = 0:3;
T = []; % – зависимость t = 2p;
net = newlind(P, T);
gensim(net)
net. IW{1, 1}, net. b{1} % – [1.9800] [0.3000];
Y = sim(net, P) % – [0.0300] [2.0100] [3.9900] [5.9700].
Задание 6. Сформировать линейную сеть из одного нейрона и одного входа с двумя элементами для классификации значений входа, выполнив следующие действия:
P = [; 2];
T = [];
net = newlin([-2 2; -2 2], 1);
net. trainParam. goal = 0.1;
[net, tr] = train(net, P, T);
net. IW{1, 1}, net. b{1}
A = sim(net, P);
err = T-A % – погрешности сети весьма значительны.
Задание 7. Сформировать линейную сеть из одного нейрона, одного входа и одного выхода для цифровой фильтрации сигнала, выполнив следующие действия:
1. Создать сеть и произвести ее инициализацию:
net = newlin([0 10], 1); % – диапазон входа от 0 до 10;
net.inputWeights{1, 1}.delays = [0 1 2];
net.IW{1, 1} = [7 8 9;] % – произвольная инициализация net.b{1} = [0]; весов и смещения pi = {1 2}; % – начальные условия на линиях задержки.
2. Определить входной сигнал и выходной сигнал фильтра в виде последовательности значений:
P = {}; % – входной сигнал;
T = {10}; % – требуемый выходной сигнал.
3. Промоделировать необученную сеть:
[a, pf] = sim(net, P, pi);
% a = [46] [70] [94] [118] pf = [5] [6].
4. Выполнить адаптацию сети с помощью 10 циклов:
net. adaptParam. passes = 10;
[net, y, E, pf, af] = adapt(net, P, T, pi);
y % - y = [10.004] [20.002] [29.999] [39.998].
Задание 8. Сформировать сеть ADALINE с одним нейроном и одним входом, значения которого изменяются от –1 до +1, двумя линиями задержки и одним выходом для предсказаний значений детерминированного процесса p(t), выполнив следующие действия:
1. Сформировать колебательное звено, реакция которого на ступенчатый сигнал будет использована в качестве детерминированного процесса p(t):
clear
sys = ss(tf(1, [1 1 1])); % – колебательное звено
time = 0:0.2:10; % – интервал процесса
[Y, time] = step(sys, 0:0.2:10).
2. Сформировать обучающее множество:
p = y(1: length(time)-2)' ; % – входной сигнал
t = y(3: length(time))' ; % – целевой выход
time = 0:0.2:10;
[Y, time] = step(sys, 0:0.2:10 ).
3. Сформировать сеть ADELINE и множества Р и Т:
net = newlin([-1 1], 1, [1 2]); % - lr = 0.01;
P = num2sell(p);
T = num2cell(t).
4. Настроить сеть:
pi = {0 0} % – начальные значения для задержек;
net. adaptParam. passes = 5;
[net, Y, E, Pf, Af] = adapt(net, P, T, pi);
Y1 = cat(1, Y{:}) % – массив ячеек в массив чисел.
5. Построить графики:
plot(time, Y1, 'b:', time, P, 'r-', …
xlabel('Время, c'), ylabel('Процессы'))
title('Обучение нейронной сети').
6. Промоделировать сеть ADALINE:
x = sim(net, P);
x1 = cat(1, x{:});
plot(time, x1, 'b', time, p, 'r');
title('Моделирование нейронной сети').
Лабораторная работа № 8
Исследование радиальных базисных сетей
общего вида
Цель работа: изучение архитектуры радиальных базисных нейронных сетей общего вида и специальных функций для их создания и автоматической настройки весов и смещений, ознакомление с демонстрационными примерами и их скриптами; приобретение навыков построения таких сетей для классификации векторов и аппроксимации функций.
Теоретические сведения
Радиальная, базисная сеть общего вида – это двухслойная нейронная сеть с R входами, каждый из которых может состоять из нескольких элементов. Передаточной функцией нейронов входного слоя является колоколообразная симметричная функция следующего вида:
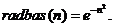
Эта функция имеет максимум, равный 1, при n = 0 и плавно убывает при увеличении n, достигая значения 0.5 при n = ±0.833. Передаточной функцией нейронов выходного слоя является линейная функция perelin.
Функция взвешивания для входного слоя вычисляет евклидово расстояние между каждой строкой матрицы весов и каждым столбцом матрицы входов:
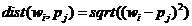 .
.
Затем эта величина умножается на смещение нейрона и поступает на вход передаточной функции, так что
a{i} = radbas(net. prod(dist(net. IW{1, 1}, p).net. b{i})).
Для нейронов выходного слоя функцией взвешивания является скалярное произведение dotprod, а функцией накопления – функция суммирования взвешенных входов и взвешенного смещения netsum.
Для того чтобы понять поведение радиальной базисной сети общего вида, необходимо проследить прохождение вектора входа p. При задании значений элементам вектора входа каждый нейрон входного слоя выдает значение в соответствии с тем, как близок вектор входа к вектору весов каждого нейрона. Таким образом, нейроны с векторами весов, значительно отличающимися с вектором входа p, будут иметь выходы, близкие к 0, и их влияние на выходы линейных нейронов выходного слоя будет незначительное. Напротив, входной нейрон, веса которого близки к вектору p, выдаст значение, близкое к единице.
Для построения радиальных базисных сетей общего вида и автоматической настройки весов и смещений используются две функции newrbe и newrb. Первая позволяет построить радиальную базисную сеть с нулевой ошибкой, вторая позволяет управлять количеством нейронов входного слоя. Эти функции имеют следующие параметры:
net = newrbe(P, T, SPREAD),
net = newrb(P, T, GOAL, SPREAD),
где P – массив размера RxQ входных векторов, причем R – число элементов вектора входа, а Q – число векторов в последовательности;
T – массив размера SxQ из Q векторов цепи и S классов;
SPREAD – параметр влияния, определяющий крутизну функции radbas, значение по умолчания которого равно единице;
GOAL – средняя квадратичная ошибка, при этом значение по умолчанию равно 0.0.
Параметр влияния SPREAD существенно влияет на качество аппроксимации функции: чем больше его значение, тем более гладкой будет аппроксимация. Слишком большое его значение приведет к тому, что для получения гладкой аппроксимации быстро изменяющейся функции потребуется большое количество нейронов: слишком малое значение параметра SPREAD потребует большего количества нейронов для аппроксимации гладкой функции. Обычно параметр влияния SPREAD выбирается большим, чем шаг разбиения интервала задания обучающей последовательности, но меньшим размера самого интервала.
Функция newrbe устанавливает веса первого слоя равным P′, а смещения – равными 0.8326/ SPREAD, в результате радиальная базисная функция пересекает значение 0.5 при значениях евклидового расстояния ±SPREAD. Веса второго слоя LW{2,1} и смещения b{2} определяются путем моделирования выходов первого слоя A{1} и последующего решения системы линейных уравнений:
[LW{2,1} b{2}]*[A{1}; ones] = T.
Функция newrb формирует сеть следующим образом. Изначально первый слой не имеет нейронов. Сеть моделируется и определяется вектор входа с самой большой погрешностью, добавляется нейрон с функцией активации radbas и весами, равными вектору входа, затем вычисляются весовые коэффициенты линейного слоя, чтобы не превысить средней допустимой квадратичной ошибки.
Практические задания
Задание 1. Создать радиальную базисную сеть с нулевой ошибкой для обучающей последовательности P = 0:3 и T = [], проанализировать структурную схему построенной сети и значения параметров ее вычислительной модели, выполнив следующие действия:
1. Создать радиальную базисную сеть с нулевой ошибкой:
P = 0:3;
T = [];
net = newrbe(P, T);
2. Проанализировать структурную схему построенной сети:
gensim(net);
3. Проанализировать параметры вычислительной модели сети:
net
net.layers{1}.size % – число нейронов в первом слое;
net.layers{2}.size % – число нейронов во втором слое;
net.layers{1}.initFcn
net.layers{1}.netInputFcn
net. layers{1}.transferFcn
net. layers{2}.initFcn
net. layers{2}. transferFcn
net. layers{2}.netInputFcn
net. inputWeights{1, 1}.initFcn
net. inputWeights{1, 1}.weightFcn
net. inputWeights{2, 1}.initFcn
net. inputWeights{2, 1}.weightFcn
net. inputWeights{1, 1}.learnFcn
net. IW{1, 1}, net. b{1}
net. LW{2, 1}, net. b{2}
net. inputWeights{1, 1}, net. biases{1}
net. inputWeights{2, 1}, net. biases{2}
4. Выполнить моделирование сети и построить графики:
plot(P, T, ‘*r’, ′MarkerSize′, 2, ′LineWidth′, 2)
hold on
V=sim(net, P);
plot(P, V, ′*b′, ′MarkerSize′, 9, ′LineWidth′, 2)
P1=0.5:2.5;
Y=sim(net, P1);
plot(P1, Y, ′*k′, ′MarkerSize′, 10, ′LineWidth′, 2)
Задание 2. Создать радиальную базисную сеть для обучающей последовательности P = 0:3 и T = [] при средней квадратичной ошибке 0.1, проанализировать структурную схему построенной сети и значения параметров ее вычислительной модели, выполнив действия задания и заменив в командах функцию newrbe(P, T) на newrb(P, T, 0.1).
Задание 3. Создать радиальную базисную сеть с нулевой ошибкой для большого числа значений входа и цели, выполнив следующие действия:
1. Задать обучающую последовательность и построить для нее график:
P = -1:0.1:1;
T = [-0.95 0.6600 …
0.413 -0.4930…
-0,1 0.36
-0.0201];
plot(P, T, ′*r′, ′MarkerSize′, 4, ′LineWidth′, 2)
hold on
2. Создать сеть и определить число нейронов в слоях:
net = newrbe(P, T);
net.layers{1}.size % – в первом слое – 21 нейрон;
net.layers{2}.size % – во втором слое – 1 нейрон;
gensim(net);
3. Выполнить моделирование сети и построить график:
V = sim(net, P);
plot(P, V, ′*b′, ′MarkerSize′, 5, ′LineWidth′, 2)
P = [-0.75]
V = sim(net, P);
hold on
plot(P, V, ′*b′, ′MarkerSize′, 10, ′LineWidth′, 2).
Задание 4. Создать радиальную базисную сеть для большого числа значений входа и цели при средней квадратичной ошибке 0.01, выполнив действия задания 3 и заменив функцию newrbe(P, T) на функцию newrb(P, T, 0.01).
Задание 5. Провести аппроксимацию функции f(x) с помощью радиальных базисных функций ![]() в виде следующего разложения в ряд:
в виде следующего разложения в ряд:
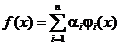 ,
,
здесь коэффициенты разложения по радиальным базисным функциям:
p = -3:0.1:3;
a1 = radbas(P);
a2 = padbas(P-1.5);
a3 = radbas(P+2);
a = a1 + a2 + 0.5*a3;
plot(P, a1, p, a2, p, 0.5*a3, p, a).
Как видно из графика, разложение по радиальным базисным функциям обеспечивает необходимую гладкость. Разложение указанного вида может быть реализовано на двухслойной нейронной сети, первый слой которой состоит из радиальных базисных нейронов, а второй – из единственного нейрона с линейной характеристикой, на котором суммируются выходы нейронов первого слоя.
Задание 6. Исследовать гладкость аппроксимации при следующих значениях параметра SPREAD: 1, 0.01 и 12, используя команды из четвертого задания.
Лабораторная работа № 9
Исследование радиальных базисных сетей
типа GRNN
Цель работы: изучение архитектурных особенностей радиальных базисных нейронных сетей типа GRNN и специальных функций для их создания, автоматической настройки весов и смещений и нормированного взвешивания; ознакомление с демонстрационным примером и его скриптом, а также приобретение навыков построения таких сетей для решения задач обобщенной регрессии, анализа временных рядов и аппроксимации функций.
Теоретические сведения
Радиальная базисная сеть типа GRNN(Generalized Regression Neural Network), или обобщенная регрессионная сеть имеет архитектуру, аналогичную архитектуре радиальной базисной сети общего вида, и отличается от нее структурой второго слоя, в котором используется блок normprod для вычисления нормированного скалярного произведения строки массива весов LW{2,1} и вектора выхода первого слоя а{1} в соответствии со следующим соотношением:
n{2} = LW{2,1} * a{1}/sum(a{1}).
В общем виде функция normprod определяется так:
normprod(W, P) = W * P/sum(P/1),
где W – матрица весов размера S × R,
P – массив входов размера R × Q,
sum(P,1) – сумма элементов массива Р по столбцам.
Создание сети осуществляется фукцией
net = newgrnn(P, T,SPREAD).
Эта функция устанавливает веса первого слоя равным Р′, а смещение – равным величине 0.8326/SPREAD, что приводит к радиальным базисным функциям, которые пересекают величину 0.5 при значениях взвешенных входов ± SPREAD. Веса второго слоя устанавливаются равными Т. Смещения отсутствуют.
Первый слой сети GRNN – это радиальный базисный слой с числом нейронов, равными числу элементов Q обучающего множества. В качестве начального приближения для матрицы весов выбирается массив Р′, смещение для этого слоя устанавливается равным вектор-столбцу с элементами 0.8326/SPREAD. Функция dist вычисляет расстояние между вектором входа и вектором веса нейрона. Вход передаточной функции равен поэлементному произведению взвешенного входа сети на вектор смещения. Входом каждого нейрона первого слоя является значение функции radbas. Если вектор веса нейрона равен транспонированному вектору входа, то взвешенный вход Ра-
вен 0, а выход равен 1. Если расстояние между вектором входа и вектором веса нейрона равно SPREAD, то выход нейрона будет равен 0.5.
Второй слой сети GRNN – это линейный слой с числом нейронов, также равным числу элементов Q обучающего множества, причем в качестве начального приближения для матрицы весов LW{2,1} выбирается массив Т. Если на вход подается вектор Рi, близкий к одному из векторов входа Р из обучающего множества, то этот вектор сгенерирует значение выхода слоя, близкое к единице. Это приведет к тому, что выход второго слоя будет близок к ti.
Если параметр влияния SPREAD мал, радиальная базисная функция характеризуется резким спадом и диапазон входных значений, на который реагируют нейроны входного слоя, оказывается весьма малым. При увеличении этого параметра диапазон увеличивается и выходная функция становится более гладкой.
Практические задания
Задание 1. Создать обобщенную регрессионную сеть для обучающей последовательности Р=0:3 и Т[], проанализировать ее структурную схему и значения параметров вычислительной модели, выполнить моделирование сети для различных входов, построить графики и оценить влияние на выходные значения параметра SPREAD, выполнив следующие команды:
P = 0:3;
T = [];
net = newgrnn(P, T) % – параметр SPREAD = 1.0;
gensim (net)
plot(P, T, ′*r′, ′MarkerSize′, 2, ′LineWidth′, 2)
hold on
V = sim(net, P)
plot(P, V, ′o8′, ′MarkerSize′, 8, ′LineWidth′, 2)
P1 = 0.5:2.5;
Y = sim(net, P1);
plot(P1,V, ′+k′, ′MarkerSize′, 10, ′LineWidth′, 2)
Y = sim(net, 0:0.5:3) % – для нового входа;
net = newgrnn(P, T, 0.1) % – параметр SPREAD = 0.1;
Y = sim(net, 0:0.5:3) % – сравнить результаты.
Задание 2. Построить обобщенную регрессионную сеть для решения задачи аппроксимации и экстраполяции нелинейной зависимости, восстанавливаемой по экспериментальным точкам, выполнив следующие команды:
P = []; % – экспериментальные;
T = []; % – данные в 8 точках;
SPREAD = 0.7; % – значение меньше шага Р, равного 1;
net = newgrnn(P, T, SPREAD)
net. layers{1}.size, net. layers{2}.size % - 8 и 8;
A = sim(net, P);
plot(P, T, ′*k′, ′MarkerSize′, 10), hold on
plot(P, A, ′ok′, ′MarkerSize′, 10) % – аппроксимация;
P2 = -1: 0.1: 10; % – диапазон Р2 больше диапазона Р;
A2 = sim(net, P2);
plot(P2, A2, ′-k′, ′LineWidth′, 2) % – экстраполяция;
hold on,
plot(P, T, ′*k′, ′MarkerSize′, 10) % – сравнить точки.
Лабораторная работа № 10
Исследование радиальных базисных сетей
типа PNN
Цель работы: изучение архитектурных особенностей радиальных базисных нейронных сетей типа PNN и специальных функций для их создания, автоматической настройки весов и смещений и конкурирующей активации; ознакомление с демонстрационным примером и его скриптом; приобретение навыков построения таких сетей для решения задач классификации на основе подсчёта вероятности принадлежности векторов к рассматриваемым классам и для решения других вероятностных задач.
Теоретические сведения
Радиальная базисная сеть типа PNN (Probabilistic Neural Networks), или вероятностная нейронная сеть, имеет архитектуру, аналогичную архитектуре радиальной базисной сети общего вида, и отличается от неё структурой второго слоя, в котором используются функция взвешивания dotprod (скалярное произведение сигналов и весов), функция накопления netsum и передаточная функция compet – конкурирующая функция, преобразующая вектор входа слоя нейронов таким образом, чтобы нейрон с самым большим входом имел выход, равной единице, а все другие нейроны имели выходы, равные нулю. Смещения используются только в первом слое.
Создание вероятностей сети осуществляется функцией
net=newpnn(P, T,spread),
где Р – массив размера R*Q из Q входных векторов с R элементами;
T – массив размера S*Q из Q векторов цели и S классов;
SPREAD – параметр влияния, значение по умолчанию 1.0.
Для вероятностей сети необходимо задать обучающее множество из Q пар векторов входа и целей. Каждый вектор цели имеет K элементов, указывающих класс принадлежности и, таким образом, каждый вектор входа ставится в соответствие одному из К классов. В результате образуется матрица связанности T размера K*Q, состоящая из нулей и единиц, строки которой соответствуют классам принадлежности, а столбцы – векторам входа. Таким образом, если элемент Т(i,j) матрицы связанности равен единице, то это означает,
что j-й входной вектор принадлежит к классу i.
Весовая матрица входного слоя IW формируется как и для радиальной базисной сети общего вида с использованием векторов входа из обучающего множества.
Весовая матрица второго слоя соответствует матрице связан-
ности Т, которая строится с помощью функции ind2vec.
Практические задания
Задание 1. Создать вероятностную нейронную сеть для обучающей последовательности, состоящей из вектора входа Р=[] и индекса классов Тс=[], проанализировать её структурную схему и параметры вычислительной модели, выполнить моделирование сети и оценить правильность классификации, выполнив следующие команды:
Р=[]; % – значения входа;
Tc=[]; % – индексы классов (3);
T=ind2uec(Tc); % – матрица связанности (целей);
net=newpnn(P,T); % – создание сети PNN;
gensim(net); % – структура сети;
net; % – параметры сети;
Y=sim(net,P); % – моделирование сети;
Yc=iecc2ind(Y); % – классы входных векторов;
%
Задание 2. Создать вероятностную нейронную сеть для определения принадлежности двухэлементных входных векторов к одному из трёх классов на основании обучающей последовательности 7 входов Р[0 0; 1 1; 0 3; 1 4; 3 1; 4 1; 4 3] и индекса классов Тс=[], значения в котором определяют класс соответствующего вектора входа, выполнив команды:
Р=[0 0; 1 1; 0 3; 1 4; 3 1; 4 1; 4 3 ]’; % – 7 векторов.
Тс=[]; % – классы.
T= ind2vec(Tc); % – формирование разряженной матрицы
% связанности;
T= full (T); % – преобразование к полной матрице;
net= newpnn; % – создание вероятностной сети;
net.layers {1}.size % – число нейронов 1-го слоя;
net.layers {2}.size % – число нейронов 2-го слоя;
Y= sim (net, P); % – моделирование сети;
Yc= vec2ind(Y); % – формирование индекса классов;
Pt= [1 3; 0 1; 5 2]’; % – векторы для тестирования;
A= sim (net, Pt); % – тестирование сети;
Ac= vec2ind (A); % – формирование индекса классов.
Задание 3. Проанализировать структурные схемы, значения параметров вычислительных моделей и результаты моделирования нейронных сетей, используемых в следующих демонстрационных примерах:
Demorb1 – рациональные базисные сети;
Demorb3 – использование не перекрывающихся функций активации (передаточных функций);
Demorb4 – использование перекрывающихся передаточных функций;
Demogrn1 – аппроксимация функций с помощью сети типа GRNN;
Demogrn1 – классификация векторов с помощью сети типа PNN.
Для анализа использовать скрипты примеров.
Лабораторная работа № 11
Исследование самоорганизующихся
слоев Кохонена
Цель работы: изучение архитектуры самоорганизующихся нейронных слоев Кохонена и специальных функций для их создания, инициализации, взвешивания, накопления, активации, настройки весов и смещений, адаптации и обучения; ознакомление с демонстрационными примерами и их скриптами, а также приобретение навыков построения самоорганизующихся слоев для исследования топологической структуры данных, их объединением в кластеры (группы) и распределением по классам.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
