Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вариант решения домашнего задания №3.
Задача 1.
Хэш-значения будут следующими:
n=222; h(n) = 222%32 = n=500; h(n) = 500%32 = n=319; h(n) = 319%32 = n=215; h(n) = 215%32 = n=591; h(n) = 591%32 = n= 51; h(n) = 51%32 = | n=101; h(n) = 101%32 = 5 (00101) n=130; h(n) = 130%32 = 2 (00010) n= 6; h(n) = 6%32 = 6 (00110) n= 42; h(n) = 42%32 = n=185; h(n) = 185%32 = n=177; h(n) = 177%32 = |
а) Рассматриваются старшие биты хэш - значений. При j=1 минимальная расширяемая хэш-структура должна состоять из двух блоков. Вставка трех первых записей осуществляется в блок, соответствующий ключевому значению 1. Структура тогда будет следующей:
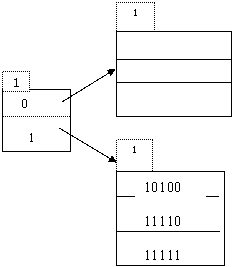
При вставке элемента 215(10111) требуется увеличить размер оглавления и затем разделить второй блок, на который указывает элемент оглавления 1. Элементы 222(11110) и 319(11111) будут перенесены во вновь созданный блок, на который будет указывать элемент оглавления с ключевым значением 11. Элемент 500(10100) и вставляемый элемент 215(10111) окажутся в старом блоке, на который указывает элемент оглавления 10. Далее вставка элемента 591(01111) осуществляется в блок, на который указывают совместно элементы оглавления 00 и 01 (поскольку число значащих бит остается для этого блока 1). Элемент 51(10011) должен быть помещен на свободное место в блоке, на который указывает элемент оглавления 10. Элементы 101(00101) и 130(00010) попадают в первый блок, совместно используемый ключевыми значениями оглавления 00 и 01.
Таким образом, при j=2 (2 старших бита хэш - значения являются значащими) получим следующую расширяемую хэш - структуру.

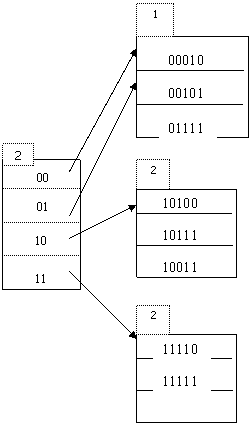
Вставка следующего элемента данных 6(00110) должна производиться в первый блок, на который ссылаются элементы оглавления 00 и 01, однако этот блок заполнен, т. е. требуется создание нового блока и перераспределение между блоками хэш – значений. Итак, во вновь созданный блок, на который будет указывать элемент оглавления 01, должно переместиться запись 591(01111). Новая же запись 6(00110) встанет на ее место в старом блоке, на который теперь будет ссылаться только элемент оглавления 00. Получим следующую структуру:
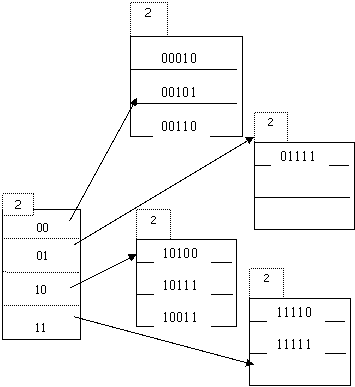
Вставка следующих двух записей 42(01010) и 185(11001) не требует изменения структуры, поскольку первая из них попадает на свободное место второго блока (на который указывает элемент оглавления 01), а вторая – на свободное место в последнем блоке (на который указывает элемент оглавления 11). Наконец, последняя запись с ключевым значением 177(10001) должна быть вставлена в блок, на который указывает элемент оглавления 10, но так как этот блок заполнен, потребуется увеличить размер оглавления и разделить соответствующий блок согласно третьему биту хэш - значений. Таким образом, окончательная хэш – структура будет выглядеть следующим образом:

б) При использовании линейной хэш - структуры используются младшие биты хэш - значения. Первоначально имеется один сегмент с номером 0. Количество используемых битов j=1. Максимальный номер сегмента m=0. Если j младших бит хэш - значения h(n)[j]>m, то записи вставляются в сегмент с номером h(n)[j]-2j-1. Таким образом, если h(n)[j]=1, то записи вставляются в сегмент h(n)[j]-2j-1=1-1=0.
Вставка записей 222(11110), 500(10100). В обоих случаях младшие биты 0, следовательно, вставка производится в сегмент с номером 0 по основному правилу. |
|
При вставке записи 319(11111) отношение количества записей к количеству сегментов составит 3, т. е. происходит превышение порогового значения 2.25. Поэтому добавляется сегмент с номером 1 (m=1), в который и производится вставка нового элемента данных. Следующую запись 215(10111) вставляем в сегмент 1 на свободное место. |
|
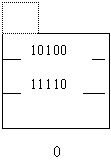


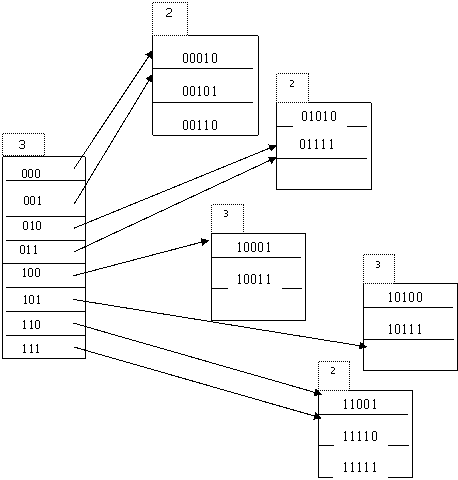
Вставка записи с хэш - значением 591(01111) приведет к тому, что пороговое значение будет опять превышено (5/2=2.5). Требуется добавить новый сегмент хэш - структуры. Количество используемых бит теперь становится j=2. Максимальный номер сегмента m=10.
Рассмотрим дополнительное правило: если хэш - значение равно 11, то запись помещается в сегмент с номером h(n)[j]-2j-1= 11 – 10 = 01.
Таким образом, записи с ключами 215(10111) и 319(11111) остаются в сегменте 01, хотя этот сегмент не соответствует их хэш - значению. Запись с хэш - значением 222(11110) перемещается в новый сегмент 10. Новый элемент с хэш - значением 519(01111) по дополнительному правилу попадает в сегмент с номером 01. Таким образом, имеем структуру:

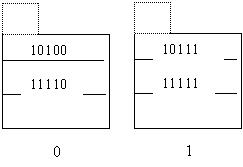
Следующая запись 51(10011) должна попасть в сегмент 01 (по дополнительному правилу). Поскольку в основном блоке этого сегмента нет свободного места, создаем блок переполнения к этому сегменту, т. е. получаем следующую структуру:
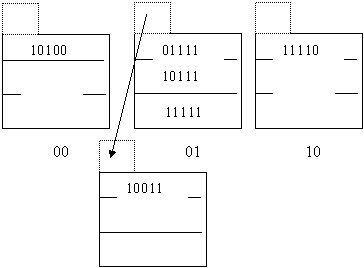

Вставка следующего элемента данных 101(00101) вызовет превышение порогового значения (7/3=2.33>2.25). Эта ситуация требует добавления еще одного сегмента с номером 11. Первым делом, требуется найти все записи, которые должны попасть в новый сегмент, но по дополнительному правилу были помещены в другие сегменты. Это все записи, находящиеся в данный момент в сегменте 01. Перемещаем их, вместе с созданием блока переполнения, в сегмент 11. Новая запись помещается в сегмент 01. Следующие два хэш - значения 130(00010) и 6(00110) можно вставить в хэш - структуру, поскольку пороговое значение при их наличии превышено не будет (9/4=2.25). Оба новых хэш - значения подлежат вставке в сегмент 10.
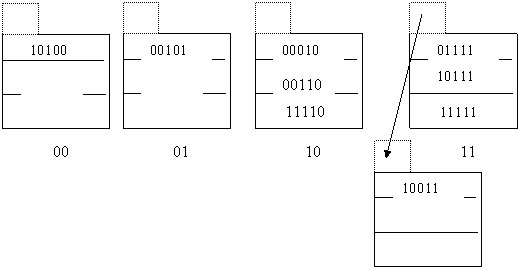

Вставка следующей записи с хэш - значением 42(01010) приведет к увеличению хэш - структуры. Теперь количество значащих бит j=3, максимальный номер сегмента m=100. Согласно дополнительному правилу, если значащие биты хэш - значения 101 (например, 101(00101)), то запись помещается в сегмент с номером h(n)[j]-2j-1= 101 – 100 = = 001, т. е. запись остается на прежнем месте. Если значащие биты хэш - значения 110 (например, 222(11110) и 6(00110)), то записи должны храниться в сегменте с номером 110-100=010 (прежнее место хранения для уже существующих записей). Наконец, если значащие биты хэш - значения 111, то сегмент хранения 111-100=011. Таким образом, при добавлении нового сегмента требуется только перенести запись 500(10100) во вновь созданный сегмент 100. Новая запись помещается в блок переполнения к сегменту 010.
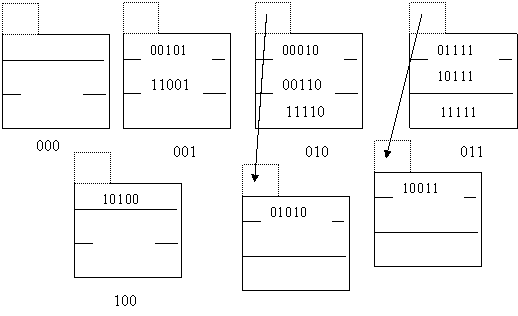

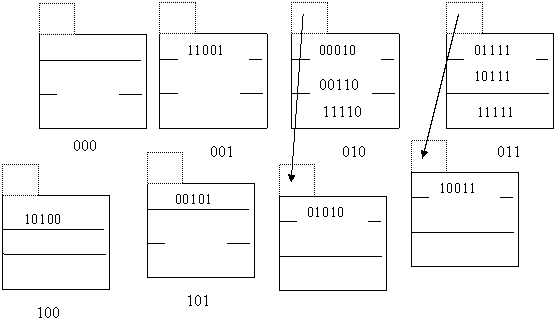
Заметим сразу, что следующую запись 185(11001) можно сразу вставить в сегмент 001. Вставка последнего элемента данных 177(10001) опять вызовет превышение порогового значения (12/5=2.4>2.25). Создаем новый сегмент с номером 101. В него потребуется переместить запись 101(00101).
Таким образом, окончательный вид линейной хэш - структуры будет следующим:

Задача 2.
Итак, даны следующие данные: пороговое значении U=3.2, число записей в блоке 5, число блоков в линейной хэш - структуре N=15, m – наибольший номер сегмента хэш - структуры.
Заметим сразу, что количество сегментов хэш - структуры = m + 1, поскольку нумерация сегментов начинается с 0.
Минимальное число операций ввода/вывода равно 1. Оно соответствует ситуации, когда требуется только прочитать блок сегмента, соответствующего хэш - значению поля записи, т. е. сегменты такой хэш - структуры не имеют цепочек блоков переполнения. В этом случае все блоки были выделены для первых блоков сегментов, т. е. количество блоков равно количеству сегментов. Таким образом, наибольший номер сегмента будет m = N – 1 = 14.
Максимальное число операций ввода/вывода потребуется выполнить, если все записи, помещенные в хэш-структуру, будут иметь одинаковое хэш-значение. Тогда все записи будут содержаться в одном сегменте, а m блоков остальных сегментов будут выделены, но пусты.
Пусть K – количество записей, занесенных в хэш - структуру. Так как пороговое значение не должно быть превышено, число записей удовлетворяет условию K/(m+1)£U=3.2, или K £ 3.2(m+1). Однако одновременно m сегментов было недостаточно для хранения кортежей отношения, т. е. при m сегментов пороговое значение было превышено, что означает выполнение неравенства K/m > U=3.2, или K > 3.2m.
Блоки переполнения содержат K - 5 £ 3.2(m+1)-5 записей (5 записей содержит первый блок соответствующего сегмента). Для хранения этого количества записей требуется не более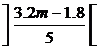 блоков переполнения. С другой стороны, K - 5 > 3.2m-5, что означает, что требуется не менее
блоков переполнения. С другой стороны, K - 5 > 3.2m-5, что означает, что требуется не менее ![]() блоков переполнения.
блоков переполнения.
Таким образом, получим систему неравенств:
N £ m+1 +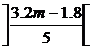 (при использовании m+1 сегмента)
(при использовании m+1 сегмента)
N > m +![]() (при использовании m сегментов)
(при использовании m сегментов)
Из первого неравенства получим, что 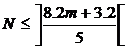 , или
, или 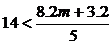 , т. е.
, т. е. 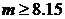 . Из второго неравенства получаем, что
. Из второго неравенства получаем, что ![]() , или
, или ![]() ,
, ![]() . Таким образом, обоим неравенствам удовлетворяет m=9 (10 сегментов плюс 5 блоков переполнения, в которых хранится максимально 30 записей).
. Таким образом, обоим неравенствам удовлетворяет m=9 (10 сегментов плюс 5 блоков переполнения, в которых хранится максимально 30 записей).
Задача 3.
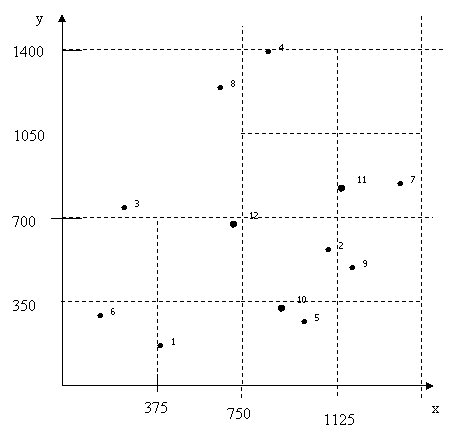
а) Требуется построить сеточный файл. Поскольку только 2 записи могут попасть в один блок данных, на некоторых этапах придется вводить новые линии сетки.
1. При вставке объекта 1003 можно ввести линию сетки по атрибуту y = 600.
2. При вставке объекта 1005 вводим линию сетки по атрибуту x = 800.
3. При вставке объекта 1009 вводим линию сетки по атрибуту y = 350.
4. При вставке объекта 1011 вводим линию сетки по атрибуту y = 1000.
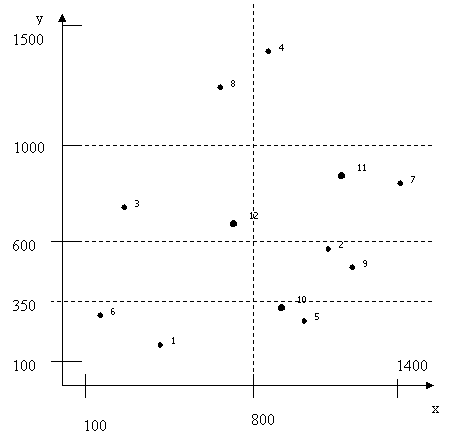

Таким образом, сеточный файл представляет собой двумерную хэш – структуру размерности 4х2.
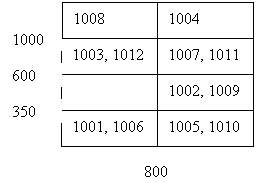

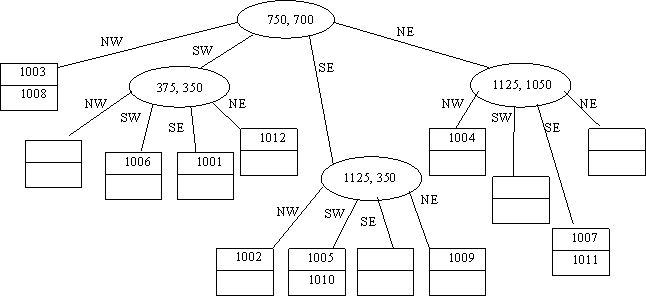
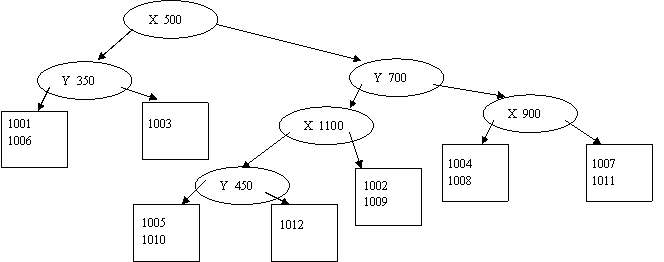
б) kd – дерево.
Первое разделение потребуется при вставке объекта 1003. В качестве значения для разделения по атрибуту x, в частности, можно выбрать значение 500. В листовой узел правой ветки далее будет вставлен объект 1004 (x=870>500). Получим следующий вид дерева:
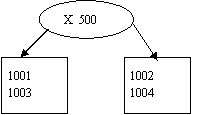

Вставка объекта 1005 должна производиться в правый листовой узел, однако он заполнен. Следовательно, требуется произвести разбиение теперь уже по второму атрибуту y. В качестве значения для разделения можно выбрать 700. Получим дерево:
|
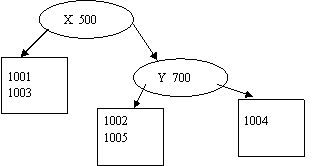

Вставка объекта 1006 должна производиться в левый потомок корня. Опять требуется выполнить разделение по атрибуту Y. В качестве значения для разделения выберем 350. Следующий объект помещаются на свободное место в последний листовой блок. Таким образом, получим:
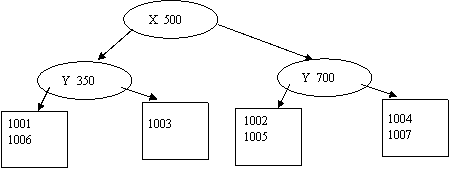

Вставка следующего объекта вызовет деление последнего узла. Деление теперь должно проходить по атрибуту x. В качестве значения для разделения примем 900.
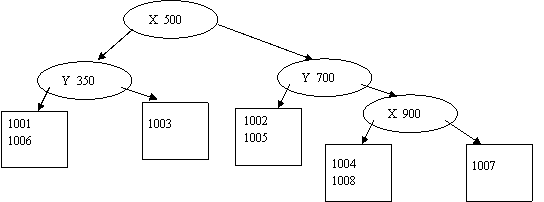

Вставка следующего элемента должна производиться в третий листовой блок (элементы 1002, 1005). Требуется произвести деление этого листового блока по атрибуту x, приняв в качестве разделяющего значения, к примеру, 1100. На свободное место в левый из вновь образовавшихся блоков помещается и следующий объект 1010. На свободное место в последнем листовом блоке встает элемент 1011.
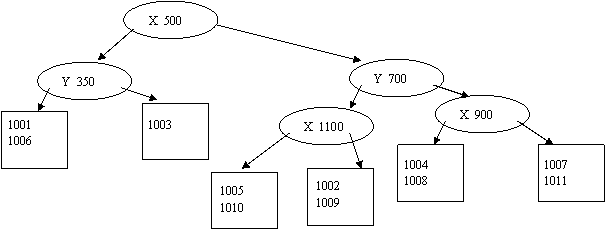

Наконец, последний объект данных 1012 опять требует произведения процедуры разбиения листовых блоков. На этот раз требуется разделить листовой блок с объектами 1005 и 1010. Разбиение производится по атрибуту y, в качестве разделяющего значения можно принять y=450. Окончательный вид kd – дерева будет следующим:

в) квадратичное дерево. Пусть начальный диапазон составляется: 0 £ x £ 1500,
0 £ y £ 1400. При таком диапазоне потребуется разделить основной регион и три его потомка – юго-западный, юго-восточный и северо-восточный.
|
Соответствующий вид квадратичного дерева будет следующим: