
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Тема: Двоичное кодирование текстовой информации.
Цели: образовательная: изучить виды кодировок текстовой информации;
развивающая: развитие логического мышления;
воспитательная: расширить информационный кругозор учащихся; воспитать бережное отношение к технике.
Задачи:
1. актуализация опорных знаний;
2. уметь определять числовой код символа;
3. уметь определять символ по числовому коду.
Программно-дидактическое обеспечение: ПК, таблицы кодов, текстовый редактор, калькулятор.
Ход урока
I. Постановка целей урока
1. Как кодируются символы в компьютере? Почему именно так, а не иначе?
2. Всегда ли разные компьютеры «понимают» друг друга?
II. Актуализация знаний
1. Как в компьютере кодируются символы?
2. Что такое «компьютерный алфавит»? Какова его мощность?
3. Чему равен информационный объём одного символа компьютерного алфавита?
III. Изложение нового материала
Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации.
Традиционно для кодирования одного символа используется 8 бит=1 байт. Если рассматривать символы как возможные события, то по формуле Шеннона можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
 При двоичном кодировании текстовой информации каждому символу ставится в соответствие своя уникальная последовательность из восьми нулей и единиц, свой уникальный код от до (десятичный код от 0 до 255). Таким образом, человек различает символы по их начертанию, а компьютер – по их кодам. (слайд 2)
При двоичном кодировании текстовой информации каждому символу ставится в соответствие своя уникальная последовательность из восьми нулей и единиц, свой уникальный код от до (десятичный код от 0 до 255). Таким образом, человек различает символы по их начертанию, а компьютер – по их кодам. (слайд 2)
При вводе в компьютер текстовой информации происходит её двоичное кодирование, изображение символа преобразуется в его двоичный код. Пользователь нажимает на клавиатуре клавишу символа, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт.
 В процессе вывода символа на экран компьютера производится обратный процесс – декодирование, т. е. преобразование кода символа в его изображение.
В процессе вывода символа на экран компьютера производится обратный процесс – декодирование, т. е. преобразование кода символа в его изображение.
Присвоение символу конкретного двоичного кода – это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.). Коды 33 до 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания. (слайд 3)
Коды с 128 по 255 являются национальными, т. е. в национальных кодировках одному и тому же коду соответствуют различные символы. К сожалению, в настоящее время существует 5 различных кодовых таблиц для русских букв, поэтому тексты созданные в одной кодировке, не будут правильно отображаться в другой. (слайд 4)

Хронологически одним из первых стандартов кодирования русских букв на компьютерах был код КОИ – 8 («Код обмена информационный – 8 битный»). Эта кодировка применяется в компьютерах с операционной системой UNIX. (слайд 5)

Наиболее распространенная кодировка – это стандартная кириллическая кодировка Microsoft Windows, обозначаемая сокращением CP1251 («CP» означает «Code Page»). Все Windows – приложения, работающие с русским языком, поддерживают эту кодировку. (слайд6)

Для работы в среде операционной системы MS-DOS используется «альтернативная» кодировка, в терминологии фирмы Microsoft – кодировка CP 866. (слайд 7)

Фирма Apple разработала для компьютеров Macintosh свою собственную кодировку русских букв (Mac). (слайд 8)

Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859 – 5. (слайд 9)

Стандарты кодировок:
1. КОИ-8 - UNIX
2. CP1251 («CP» означает «Code Page») - Microsoft Windows
3. CP 866 - MS-DOS
4. Mac - Macintosh
5. ISO 8859 – 5 (слайд 10)

Таблица кодировки символов (слайд 11)
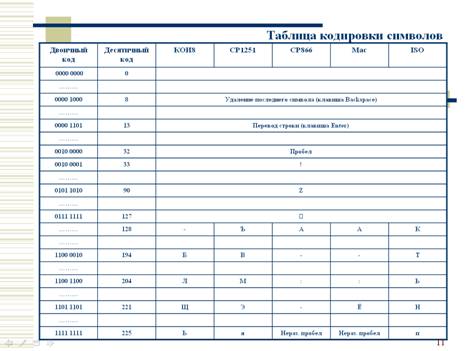
Каждая кодировка задаётся своей кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР 1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, т. к. это делают специальные программы-конверторы, встроенные в приложения.
В последнее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, и поэтому с его помощью можно закодировать не 256 символов, 216=65 536 различных символов. Эту кодировку поддерживает платформа Microsoft Windows&Office (начиная с 1997 года). (слайд 12)

IV. Закрепление изученного.
Выполните следующие задания: (на рабочих столах учащихся имеются распечатки таблицы кодов ASCII). Приложение 1.
Слайд 13:

Слайд 14:

Выполнение практической работы (карточки прилагаются)
Решите задачи:
№1
Закодируйте с помощью таблицы ASCII слова:
A) Excel; В) Windows;
Б) Access; Г) ИНФОРМАЦИЯ.
№2
Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
№3
Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help.
№4
Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link.
№5
Декодируйте следующие тексты, заданные десятичным кодом:
A) ;
Б) 45 224;
B) 11
V. Итог урока.
1. Объясните процесс кодирования и декодирования.
2. Перечислите все кодировки текстовой информации.
3.
VI. Домашнее задание

 Стандартная часть таблицы кодов ASCII Приложение 1
Стандартная часть таблицы кодов ASCII Приложение 1




 Некоторые коды национального (русского) алфавита расширенной части таблицы ASCII
Некоторые коды национального (русского) алфавита расширенной части таблицы ASCII
