
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Лабораторный практикум
по дисциплине
Компьютерное моделирование
Лабораторная работа №1
Моделирование и статистический анализ скалярной дискретной стохастической системы при использовании операторов ДАТА и PROC Цель работы: Написать программу для вычисления значения функции sin(x) разложением в ряд. Получить навыки вычисление рекуррентных формул
Теоретические основы
Как правило, при решении задачи приходится вычислять значения элементарных функций (тригонометрических, показательных, логарифмических и др.). При ручном счете для этой цели могут быть использованы таблицы. Однако в вычислениях на ЭВМ ввод таблиц функций в машину потребовал бы больших затрат памяти. Кроме того, поиск нужного значения функции в памяти ЭВМ – не простое для машины занятие. Поэтому для вычисления значений функций на ЭВМ используются разложения этих функций в степенные ряды. Например, функция sin(x) вычисляется с помощью ряда:
![]()
При известном значении аргумента х значение функции может быть получено с точностью до погрешностей округления. Количество используемых членов ряда зависит от значения аргумента. Напомним, что в соответствии с правилами приближенных вычислений для предотвращения влияния погрешностей округления необходимо, выполнение неравенства 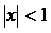 .
.
С помощью степенных рядов вычисляются значения и других элементарных функций. В частности, для вычисления значений функции cos(x) можно использовать ряд sin(x) с учетом соотношения:
![]()
Для выполнения однотипных вычислений использующих в качестве исходных значений результаты, полученные в предыдущих вычислениях используют рекуррентные формулы. Так значения числителя и знаменателя элементов сумм ряда могут быть получены при домножении числителя на ![]() , а знаменателя на
, а знаменателя на ![]() , где n – текущий элемент факториала.
, где n – текущий элемент факториала.
Например:
|
|
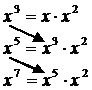
Выполнять цикл вычисления элементов ряда до тех пор пока их значение не станет меньше ε.
Задание
1. Написать программу для вычисления значений функций sin(x) или cos(x) разложенных в ряд, сравнить со значением, вычисленным с помощью стандартной тригонометрической функции;
2. Определить количество элементов ряда, при котором значения суммы ряда и функции будут совпадать с точностью до ε.
Контрольные вопросы
Лабораторная работа №2
Моделирования и статистический анализ многомерной стохастической системы без резервирования при использовании процедуры IML Цель работы: Получить навыки работы с массивами данных. Написать программу для нахождения максимального и минимального элементов массива
Теоретические основы
Массив – это последовательность данных, записанная в определенной области памяти, обращение к которым осуществляется по их индексу. Данные, хранимые в массиве, могут быть различного типа как строковые (символьные), так и числовые (целые и вещественные).
Массив бывает одномерным (вектор) и n – мерным. Размерность определяется количеством индексов, с помощью которых происходит доступ.
В Visual Basic n – мерный массив определяется как
Dim Mas(a,…, n) As Type
где Mas – название переменной, по которой будет происходить обращение к массиву;
a,…,n – размерность массива;
Type – тип хранимых в массиве данных.
Нахождение минимального и максимального элементов массива происходит последовательным сравнением всех элементов массива с «эталоном». В качестве первого значения «эталона» обычно применяют первый элемент массива. В случае если «эталон» оказывается больше текущего элемента при нахождении минимума (меньше при нахождении максимума), то «эталону» присваивают значение текущего элемента и продолжают перебор значений до последнего элемента.
Задание
1. Написать программу для нахождения максимального и минимального элементов n–мерного массива, массив должен отображаться;
2. Преобразовать программу для нахождения 3–х наибольших элементов массива.
Контрольные вопросы
Лабораторная работа №3
Моделирование и статистический анализ многомерной стохастической системы без резервирования (аномальный режим работы системы).
Цель работы: Ознакомиться с различными методами сортировки массивов. Написать программу для сортировки массива всеми рассмотренными методами
Теоретические основы
Сортировка – это процесс перегруппировки заданного множества объектов в некотором определённом порядке. Цель сортировки: облегчить поиск элементов.
Существует множество методов сортировки, каждый из которых имеет свои достоинства и недостатки. Выбор алгоритма зависит от структуры обрабатываемых данных.
Методы сортировки можно разбить на два класса – сортировку массивов и сортировку файлов. Иногда их называют внутренней и внешней сортировкой, так как массивы хранятся в быстрой, оперативной, внутренней памяти машины со случайным доступом, а файлы размещаются в более медленной, но и более ёмкой внешней памяти.
Основное условие: выбранный метод сортировки должен экономно использовать доступную память. Это предполагает, что перестановки, приводящие элементы в порядок, должны выполняться «на том же месте», т. е. методы, в которых элементы из массива «А» передаются в массив «В», представляют существенно меньший интерес, что экономит память.. Поэтому будем классифицировать методы по их экономичности, т. е. по времени их работы. Хорошей мерой эффективности может быть С – число необходимых сравнений и М – число перестановок элементов. Эти числа есть функции от n – числа сортируемых элементов.
Сортировка массива методом прямого выбора
Алгоритм сортировки массива по возрастанию методом прямого выбора может быть представлен так:
1. Просматривая массив от первого элемента, найти минимальный элемент и поместить его на место первого элемента, а первый – на место минимального.
2. Просматривая массив от второго элемента, найти минимальный элемент и поместить его на место второго элемента, а второй – на место минимального.
3. И так далее до предпоследнего элемента.
Таблица 1 – Пример сортировки с помощью прямого выбора

Сортировка массива методом прямого обмена (пузырьковым методом)
В основе алгоритма метода прямого обмена лежит обмен соседних элементов массива. Каждый элемент массива, начиная с первого, сравнивается со следующим, и если он больше следующего, то элементы меняются местами. Таким образом, элементы с меньшим значением продвигаются к началу массива (всплывают), а элементы с большим значением – к концу массива (тонут), поэтому этот метод иногда называют "пузырьковым". Этот процесс повторяется на единицу меньше раз, чем элементов в массиве.
Сортировка массива методом прямого включения
Сортировка методом прямого включения, так же, как и сортировка методом простого выбора, обычно применяется для массивов, не содержащих повторяющихся элементов.
Сортировка этим методом производится последовательно шаг за шагом. На k–м шаге считается, что часть массива, содержащая первые k–1 элемент, уже упорядочена, то есть ![]() .
.
Далее необходимо взять k–й элемент и подобрать для него место в отсортированной части массива такое, чтобы после его вставки упорядоченность не нарушилась, то есть надо найти такое ![]() что
что ![]() . Затем надо вставить элемент a(k) на найденное место.
. Затем надо вставить элемент a(k) на найденное место.
С каждым шагом отсортированная часть массива увеличивается. Для выполнения полной сортировки потребуется выполнить n–1 шаг.
Осталось ответить на вопрос, как осуществить поиск подходящего места для элемента х. Поступим следующим образом: будем просматривать элементы, расположенные левее х (то есть те, которые уже упорядочены), двигаясь к началу массива. Нужно просматривать элементы а(j), j изменяется от k–l до 1. Такой просмотр закончится при выполнении одного из следующих условий:
• найден элемент ![]() , что говорит о необходимости вставки х между
, что говорит о необходимости вставки х между 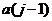 и а(j).
и а(j).
• достигнут левый конец упорядоченной части массива, следовательно, нужно вставить х на первое место.
До тех пор, пока одно из этих условий не выполнится, будем смещать просматриваемые элементы на 1 позицию вправо, в результате чего в отсортированной части будет освобождено место под х.
Методику сортировки иллюстрирует таблица 2:
Таблица 2 – Пример сортировки с помощью прямого включения
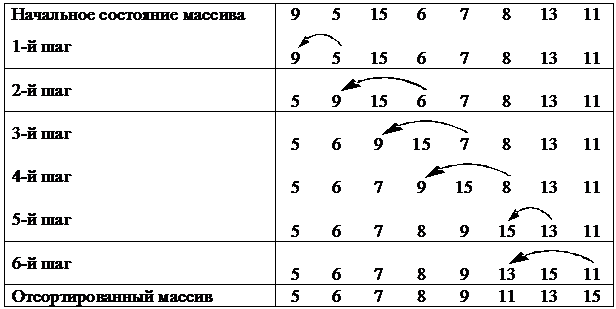
Первоначально упорядоченная последовательность состоит из 1–го элемента 9. Элемент а(2)=5 – первый из неупорядоченной последовательности и 5 < 9, поэтому ставится на его место, а 9 сдвигается вправо. Теперь упорядоченная последовательность состоит из двух элементов 5, 9. Элемент а(3)=15 неупорядоченной последовательности больше всех элементов упорядоченной последовательности, поэтому остаётся на своём месте и на следующем шаге упорядоченная последовательность состоит из 5, 9, 15, а рассматриваемый элемент 6. Процесс происходит до тех пор, пока последовательность не станет упорядоченной.
Шейкерная сортировка
Метод пузырька допускает три простых усовершенствования. Во–первых, если на некотором шаге не было произведено ни одного обмена, то выполнение алгоритма можно прекращать. Во–вторых, можно запоминать наименьшее значение индекса массива, для которого на текущем шаге выполнялись перестановки. Очевидно, что верхняя часть массива до элемента с этим индексом уже отсортирована, и на следующем шаге можно прекращать сравнения значений соседних элементов при достижении такого значения индекса. В–третьих, метод пузырька работает неравноправно для "легких" и "тяжелых" значений. Легкое значение попадает на нужное место за один шаг, а тяжелое на каждом шаге опускается по направлению к нужному месту на одну позицию.
На этих наблюдениях основан метод шейкерной сортировки (ShakerSort). При его применении на каждом следующем шаге меняется направление последовательного просмотра. В результате на одном шаге "всплывает" очередной наиболее легкий элемент, а на другом "тонет" очередной самый тяжелый. Пример шейкерной сортировки приведен в таблице 3.
Таблица 3 – Пример шейкерной сортировки

Шейкерную сортировку рекомендуется использовать в тех случаях, когда известно, что массив "почти упорядочен".
Сортировка массива с помощью включений с уменьшающимися расстояниями (метод Шелла)
Д. Шеллом было предложено усовершенствование сортировки с помощью прямого включения.
Идея метода: все элементы массива разбиваются на группы таким образом, что в каждую группу входят элементы, отстоящие друг от друга на некоторое число позиций L. Элементы каждой группы сортируются. После этого все элементы вновь объединяются и сортируются в группах, при этом расстояние между элементами уменьшается. Процесс заканчивается после того, как будет проведено упорядочивание элементов с расстоянием между ними, равным 1.
Пример сортировки методом Шелла приведен в таблице 4.
Таблица 4 – Пример сортировки методом Шелла

Сначала рассмотрим вариант, когда первоначальное значение L равно половине числа элементов в массиве, а каждое последующее значение вдвое меньше предыдущего. Заметим, что обмениваются элементы, которые отстоят на величину шага. Если при сравнении 2–х элементов обмена не произошло, то места сравниваемых элементов сдвигаются вправо на одну позицию. Если обмен произошёл, то происходит сдвиг соответствующих сравниваемых элементов на L.
Сортировка разделением (быстрая сортировка)
Метод сортировки разделением был предложен Чарльзом Хоаром. Этот метод является развитием метода простого обмена и настолько эффективен, что его стали называть методом быстрой сортировки – «Quicksort».
Основная идея алгоритма состоит в том, что случайным образом выбирается некоторый элемент массива x, после чего массив просматривается слева, пока не встретится элемент a(i) такой, что a(i) > x, а затем массив просматривается справа, пока не встретится элемент a(i) такой, что a(i)< x. Эти два элемента меняются местами, и процесс просмотра, сравнения и обмена продолжается, пока мы не дойдем до элемента x. В результате массив окажется разбитым на две части – левую, в которой значения ключей будут меньше x, и правую со значениями ключей, большими x. Далее процесс рекурсивно продолжается для левой и правой частей массива до тех пор, пока каждая часть не будет содержать в точности один элемент. Рекурсию можно заменить итерациями, если запоминать соответствующие индексы массива.
Процесс сортировки массива быстрым методом представлен в таблице 5.
Таблица 5 – Пример быстрой сортировки
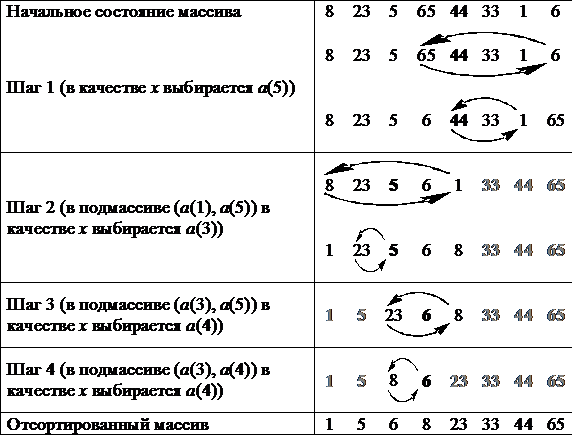
В большинстве утилит, выполняющих сортировку массивов, используется именно этот алгоритм.
Задание
1. Написать программы для сортировки массива всеми рассмотренными методами;
2. Сравнить эффективность методов сортировки.
Контрольные вопросы
Лабораторные работы. № 4
Моделирование многомерной дискретной системы с резервированием при использовании процедуры IML.
Цель работы: освоить навыки нахождения значения полинома различными методами, с оценкой точности произведенных вычислений и количества производимых математических действий
Теоретические основы
При аппроксимации функций, а также в некоторых других задачах приходится вычислять значения полиномов вида
Q(p) = a0pn+a1pn–1+a2pn–2+…+an–1p+an
Если проводить вычисления «в лоб», т. е. находить значения каждого члена и суммировать их, то при больших п потребуется выполнить большое число операций (n2+n/2 умножений и п сложений). Кроме того, это может привести к потере точности за счет погрешностей округления. В некоторых частных случаях, как это сделано при вычислении синуса, удается выразить каждый последующий член через предыдущий и таким образом значительно сократить объем вычислений.
Метод Горнера
Анализ многочлена в общем случае приводит к тому, что для исключения возведения х в степень в каждом слагаемом полином целесообразно переписать в виде:
p(a0pn–1+a1pn–2+a2pn–3+…+an–1)+an,
в следующей итерации он принимает вид:
p(p(a0pn–2+a1pn–3+a2pn–4+…+an–2)+an–1)+an.
Прием, с помощью которого полином представляется в таком виде, называется схемой Горнера. Этот метод требует п умножений и п сложений. Использование схемы Горнера для вычисления значений полиномов не только экономит машинное время, но и повышает точность вычислений за счет уменьшения погрешностей округления.
1) вычисление значения полинома последовательным перемножением:
![]()
![]()
![]()
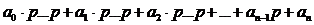
n n–1 n–2
2) вычисление методом Горнера
![]()
3) вычисление значения полинома возведением в степень оператором «^»
4) вычисления значения полинома возведением в степень с использованием формулы 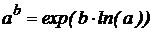
Задание
Написать программу нахождения значения полинома n–ой степени четырьмя методами, в качестве значения p задавать дробные.
Контрольные вопросы
Лабораторная работа №5
Моделирование многомерной дискретной системы при использовании процедуры IML.
Цель работы: использовании процедуры IML.
Теоретические основы
Среди задач линейной алгебры существуют такие задачи как вычисление определителей нахождение обратных матриц, собственных значений матрицы и др. Легко вычисляются лишь определители невысоких порядков и некоторые специальные типы определителей.
В частности, для определителей второго и третьего порядков соответственно имеем:
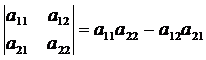
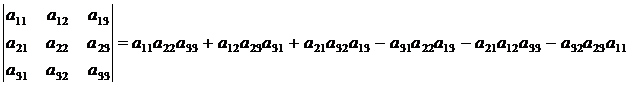
Определитель треугольной матрицы равен произведению ее элементов, расположенных на главной диагонали: ![]() . Треугольной называется матрица, у которой все элементы находящиеся ниже главной диагонали имеют нулевое значение.
. Треугольной называется матрица, у которой все элементы находящиеся ниже главной диагонали имеют нулевое значение.
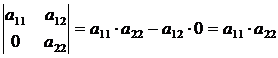

Отсюда также следует, что определитель единичной матрицы равен единице, а нулевой – нулю: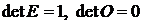 .
.
В общем случае вычисление определителя оказывается значительно более трудоемким. Определитель D порядка п имеет вид:
![]()
Из этого выражения следует, что определитель равен сумме п! слагаемых, каждое из которых является произведением п элементов. Поэтому для вычисления определителя порядка п (без использования специальных приемов) требуется ![]() умножений и
умножений и ![]() сложений, т. е. общее число арифметических операций равно
сложений, т. е. общее число арифметических операций равно
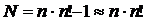
Оценим значения N в зависимости от порядка п определителя:
п | 3 | 10 | 20 |
N | 17 | 3.6 | 5 |
Итак, непосредственное нахождение определителя требует большого объема вычислений. Вместе с тем легко вычисляется определитель треугольной матрицы: он равен произведению ее диагональных элементов.
Для приведения матрицы к треугольному виду может быть использован метод исключения, т. е. прямой ход метода Гаусса. В процессе исключения элементов величина определителя не меняется. Знак определителя меняется на противоположный при перестановке его столбцов или строк. Следовательно, значение определителя после приведения матрицы А к треугольному виду вычисляется по формуле:
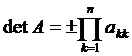
Здесь диагональные элементы ![]() берутся из преобразованной (а не исходной) матрицы. Знак зависит от того, четной или нечетной была суммарная перестановка строк (или столбцов) матрицы при ее приведении к треугольному виду (для получения ненулевого или максимального по модулю ведущего элемента на каждом этапе исключения). Благодаря методу исключения можно вычислять определители больших порядков, при значительно меньшем объеме вычислений, чем в проведенных ранее оценках.
берутся из преобразованной (а не исходной) матрицы. Знак зависит от того, четной или нечетной была суммарная перестановка строк (или столбцов) матрицы при ее приведении к треугольному виду (для получения ненулевого или максимального по модулю ведущего элемента на каждом этапе исключения). Благодаря методу исключения можно вычислять определители больших порядков, при значительно меньшем объеме вычислений, чем в проведенных ранее оценках.
Приведение к треугольному виду достигается последовательным исключением элементов в нижних строках матрицы. Сначала с помощью первой строки исключается первый элемент всех строк. Затем с помощью второй строки исключается второй элемент третьей и всех последующих строк. Этот процесс, продолжается до тех пор, пока в последней (п–ой) строке не останется лишь один элемент.
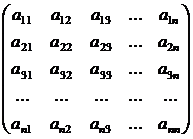
1–ый шаг:
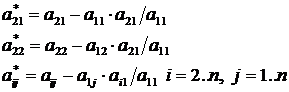

n–ый шаг 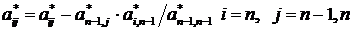

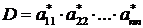
Задание
Написать программу для нахождения определителя матрицы размерностью n×n.
Контрольные вопросы
Контрольные вопросы
Приложение 1
УСЛОВНЫЕ ОБОЗНАЧЕНИЯ ЭЛЕМЕНТОВ БЛОК–СХЕМ АЛГОРИТМОВ
Блок–схема это графическое отображение алгоритма описывающего выполнения, каких либо действий (ход программы, последовательность выполнения операций и т. д.). Определено несколько типов блоков представляющих собой определенные виды действий. Последовательность этих действий определяют связи
1. Терминатор отображает выход во внешнюю среду и вход из внешней среды (начало или конец схемы программы, внешнее использование и источник или пункт назначения данных).

![]()
2. Данные – отображает данные, носитель которых не определен

![]()
3. Ручной ввод отображает данные, вводимые вручную во время обработки с устройств любого типа (клавиатура, переключатели, кнопки, световое перо, полоски со штриховым кодом).


4. Процесс отображает функцию обработки данных любого вида (выполнение определенной операции или группы операций, приводящее к изменению значения, формы или размещения информации или к определению, по которому из нескольких направлений потока следует двигаться).

![]()
5 Предопределенный процесс Символ отображает предопределенный процесс, состоящий из одной или нескольких операций или шагов программы, которые определены в другом месте (в подпрограмме, модуле).


6. Условие – блок, осуществляющий выбор одного из альтернативных вариантов действий в зависимости от результатов выполнения условия входящего в него. Блок используется для определения вариантов действий при условных операторах if, while, и др., а также оператора выбора множественных вариантов switch …case. Соответствующие варианты (да/нет), которые может принимать внутреннее условие, могут быть записаны по соседству с линиями, отображающими эти пути.

![]()
7. Цикл со счетчиком Используется для отображения циклов вида for … to…
![]()

8. Линия отображает поток данных или управления. При необходимости или для повышения удобочитаемости могут быть добавлены стрелки–указатели.



7. Соединитель отображает выход в часть схемы и вход из другой части этой схемы и используется для обрыва линии и продолжения ее в другом месте. Соответствующие символы–соединители должны содержать одно и то же уникальное обозначение.

Комментарий Символ используют для добавления описательных комментариев или пояснительных записей в целях объяснения или примечаний. Пунктирные линии в символе комментария связаны с соответствующим символом или могут обводить группу символов. Текст комментариев или примечаний должен быть помещен около ограничивающей фигуры.
Пример: 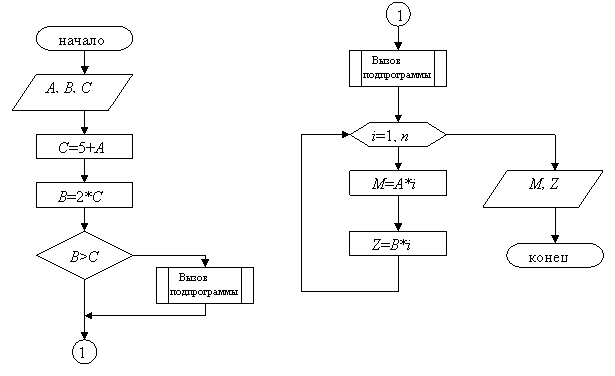

Литература
1. Алгоритмы и структуры данных: Пер. с англ. – 2–е изд., испр. – СПб.: Невский Диалект, 2001
2. Волченков на Visual Basic 6; В 3–х ч. Часть 3 – М.: ИНФРА–М, 2000
3. , А Лабораторный практикум по высшей математике: Учеб. пособие для втузов. – М.: Высш. шк., 1983
4. и др. Практикум по программированию на алгоритмических языках. – М.: Наука, 1980
5. Турчак численных методов: Учеб. пособие. – М.: Наука Гл. ред. физ.–мат. лит., 1987
6. ГОСТ 19.701–90. Схемы алгоритмов, программ, данных и систем. Условные обозначения и правила выполнения
|
