
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Анализ временных рядов
Поскольку условия ведения бизнеса изменяются с течением времени, предпринимателям и менеджерам требуется постоянно "держать руку на пульсе" этих изменений для успешного ведения своей предпринимательской деятельности. Одним из приемов, которым предприниматели и менеджеры могут воспользоваться для оценки эффективности будущих управленческих решений, является метод прогнозирования. К настоящему времени разработаны различные методы прогнозирования, но у всех у них одна общая цель — предсказать с той или иной степенью надежности будущие события, чтобы этот прогноз можно было учесть при принятии тех или иных управленческих решений.
Предприниматели и менеджеры должны уметь прогнозировать
спрос на свою продукцию,
предпочтения потребителей,
будущий объем продаж,
эффективность рекламных кампаний и т.д.
Анализ временных рядов — это анализ, основанный на исходном предложении, согласно которому случившееся в прошлом служит достаточно надежным указанием на то, что произойдет в будущем. Это также можно назвать проектированием тенденций.
1. Временные ряды и их характеристики
Временной ряд представляет собой последовательность данных, описывающих объект в последовательные моменты времени. В отличие от анализа случайных выборок, анализ временных рядов основывается на предположении, что последовательные данные наблюдаются через равные промежутки времени (тогда как в других методах привязка наблюдений ко времени была для нас не важна). Временные ряды встречаются сплошь и рядом. В медицине это может быть кардиограмма, в астрономии — графики солнечной активности, в экономике — изменения уровня безработицы или процентных ставок и т. д.
Существует две основные цели анализа временных рядов: определение природы ряда и прогнозирование, т. е. предсказание будущих значений временного ряда по настоящим и прошлым значениям. Обе цели требуют, чтобы модель ряда была определена и более или менее формально описана. Как только модель определена, с ее помощью можно интерпретировать рассматриваемые данные — например, использовать ее для анализа наличия сезонного изменения цен на товары. Затем можно экстраполировать ряд на основе найденной модели, т. е. предсказать его будущие значения.
Как и большинство других видов анализа, анализ временных рядов предполагает, что данные содержат систематическую составляющую (обычно включающую несколько компонент) и случайный шум (ошибку), который затрудняет обнаружение регулярных компонент. Большинство методов исследования временных рядов включает различные способы фильтрации шума, позволяющие увидеть регулярную составляющую более отчетливо.
Большинство регулярных составляющих временных рядов принадлежит к двум классам: они являются либо трендом, либо сезонной составляющей.
Тренд представляет собой общую систематическую линейную или нелинейную компоненту, закономерно изменяющуюся во времени.
Сезонная составляющая — это периодически повторяющаяся компонента. Оба эти вида регулярных компонент часто имеются в рядах одновременно. Например, продажи компании могут возрастать из года в год (тренд), но при этом они могут содержать и сезонную составляющую (например, 30% годовых продаж приходится на январь и только 5% — на июль). В табл. 11.1 приведено сравнение компонент, влияющих на значения временного ряда.

2. Декомпозиция временных рядов
Основным положением, на котором базируется использование временных рядов для прогнозирования, является то, что факторы, влияющие на полученные данные, воздействовали некоторым образом на наблюдаемый процесс в прошлом и настоящем, и предполагается, что они будут действовать схожим образом и в не очень далеком будущем. Поэтому основной целью анализа временных рядов будет разложение их на составные компоненты (декомпозиция) с целью прогноза дальнейшего поведения системы и выработки рациональных управленческих решений.
Двумя простейшими моделями, в которых переменная временного ряда У раскладывается на трендовую, циклическую, сезонную и нерегулярную компоненту, являются аддитивная модель и мультипликативная.
Модель, которая трактует каждое значение временного ряда как сумму указанных выше компонент, называется аддитивной. Согласно этой модели любое значение временного ряда представляется в виде:
![]() (11.1)
(11.1)
где![]() - значение временного ряда, а
- значение временного ряда, а ![]() - соответственно значения трендовой, циклической, сезонной и нерегулярной компонент в любой точке ряда.
- соответственно значения трендовой, циклической, сезонной и нерегулярной компонент в любой точке ряда.
Аддитивная модель применима в тех случаях, когда анализируемый временной ряд имеет приблизительно одинаковые изменения на протяжении всей длительности ряда.
Наиболее фундаментальной является классическая мультипликативная модель временного ряда, широко используемая при анализе ежемесячных, ежеквартальных и ежегодных данных и потому чаще всего применяемая в экономических исследованиях.
В классической мультипликативной модели временных рядов определяется, что наблюдаемое значение в любой точке временного ряда является произведением трех факторов — тренда, циклической и нерегулярной компонент (в случае короткошаговых наблюдений — четырех, здесь добавляется еще и сезонная компонента), и любое значение ряда может быть представлено в виде:
![]() (11.2)
(11.2)
где ![]() - значение временного ряда, а
- значение временного ряда, а ![]() - соответственно значения трендовой, циклической, сезонной и нерегулярной компонент в любой точке ряда.
- соответственно значения трендовой, циклической, сезонной и нерегулярной компонент в любой точке ряда.
3. Анализ тренда
Не существует "автоматического" способа обнаружения тренда во временном ряду. Однако если тренд является монотонным (устойчиво возрастает или убывает), то анализировать такой ряд обычно нетрудно. Если временные ряды содержат значительную ошибку, то первым шагом выделения тренда является сглаживание.
Сглаживание всегда включает некоторый способ локального усреднения данных, при котором несистематические компоненты взаимно погашают друг друга. Самый общий метод сглаживания — скользящее среднее, в котором каждый член ряда заменяется простым или взвешенным средним m соседних членов, где m — ширина "окна". Также для выделения тренда широко используется метод экспоненциального сглаживания.
Многие монотонные временные ряды можно хорошо описать линейной функцией. Если же имеется явная монотонная нелинейная компонента, то данные вначале следует преобразовать таким образом, чтобы устранить эту нелинейность. Чаще всего для этой цели используют логарифмическое, экспоненциальное или (не так часто) полиномиальное преобразование данных.
Относительно реже, когда ошибка измерения очень большая, используется метод сглаживания методом наименьших квадратов, взвешенных относительно расстояния или метод отрицательного экспоненциально взвешенного сглаживания.
Все эти методы отфильтровывают шум и преобразуют данные в относительно гладкую кривую.
3.1 Метод скользящего среднего
Среднее скользящее значение относится к категории аналитических инструментов, которые, как принято говорить, "следуют за тенденцией". Его назначение состоит в том, чтобы позволить определить время начала новой тенденции, а также предупредить о ее завершении или повороте. Методы скользящего среднего предназначены для отслеживания тенденций непосредственно в процессе их развития, их можно рассматривать как искривленные линии тренда. Однако методы скользящего среднего не предназначены для прогнозирования движений на рынке в том смысле, в котором это позволяет делать графический анализ, поскольку они всегда следуют за динамикой рынка, а не опережают ее. Иначе говоря, эти показатели, например, не прогнозируют динамику цен, а только реагируют на нее. Они всегда следуют за движениями цен на рынке и сигнализируют о начале новой тенденции, но только после того, как она появилась.
Построение скользящего среднего представляет собой специальный метод сглаживания показателей. Действительно, при усреднении ценовых показателей их кривая заметно сглаживается и наблюдать тенденцию развития рынка становится намного проще. Однако уже по самой своей природе скользящее среднее как бы отстает от динамики рынка. Краткосрочное скользящее среднее точнее передает движение цен, чем более продолжительное, т. е. вычисленное для более длинного интервала. Применение краткосрочного скользящего среднего позволяет сократить отставание во времени, однако полностью устранить его при использовании любого метода скользящих средних невозможно.
Простое скользящее среднее, определяемое как среднее арифметическое значение, вычисляется по следующей формуле, при условии что m — нечетное число:
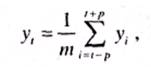 (11.3)
(11.3)
где у, — фактическое значение /-го уровня; m — число уровней, входящих в интервал сглаживания![]() - текущий уровень ряда динамики; i — порядковый номер уровня в интервале сглаживания; р — при нечетном m имеет значение р = (m - 1)/2.
- текущий уровень ряда динамики; i — порядковый номер уровня в интервале сглаживания; р — при нечетном m имеет значение р = (m - 1)/2.
Интервал сглаживания, т. е. число входящих в него уровней m, определяют по следующим правилам. Когда необходимо сгладить незначительные, беспорядочные колебания, интервал сглаживания берут большим, если же требуется сохранить более незначительные колебания и освободиться лишь от периодически повторяющихся выбросов — интервал сглаживания обычно уменьшают.
Метод простого скользящего среднего используется обычно в тех случаях, когда график временного ряда представляет собой прямую линию, поскольку при этом динамика исследуемого явления не искажается.
В том случае, когда тренд ряда имеет явно нелинейный характер и желательно сохранить незначительные колебания в динамике значений, этот метод не используется, так как его применение может привести к значительным искажениям исследуемого процесса. В таких случаях используется взвешенное скользящее среднее или методы экспоненциального сглаживания.
Практика показывает, что метод простого скользящего среднего позволяет выработать объективную стратегию и четко определенные правила, например, в сфере торговли. Именно поэтому данный метод положен в основу многих компьютерных систем для торговых организаций. Как же можно использовать метод скользящего среднего? Наиболее распространенные способы применения скользящего среднего таковы.
1. Сопоставление значения текущей цены со скользящим средним, используемым в этом случае как индикатор тенденции. Так, если цены находятся выше 65-дневного скользящего среднего, то на рынке имеется промежуточная (краткосрочная) восходящая тенденция. В случае более долгосрочной тенденции цены должны быть выше 40-недельного скользящего среднего.
2. Использование скользящего среднего как уровня поддержки или сопротивления. Закрытие цен выше данного скользящего среднего служит "бычьим" сигналом, закрытие ниже его — "медвежьим".
3. Отслеживание полосы скользящего среднего (другое часто используемое название — конверт). Эта полоса ограничивается двумя параллельными линиями, которые располагаются на определенную процентную величину выше и ниже кривой скользящего среднего. Эти границы могут служить индикаторами уровня поддержки или сопротивления соответственно.
4. Наблюдение за направлением наклона кривой скользящего среднего. Так, если после длительного подъема она выравнивается или поворачивает вниз, это может быть "медвежьим" сигналом.
5. Еще один простой метод наблюдения заключается в построении линий тренда по кривой скользящего среднего. Также иногда может быть целесообразно использование комбинации из двух скользящих средних.
Microsoft Excel располагает функцией Скользящее среднее (Moving Average), которая обычно используется для сглаживания уровней эмпирического временного ряда на основе метода простого скользящего среднего. Для вызова этой функции необходимо выбрать команду меню Tools^Data Analysis (Сервис1*Анализ данных). На экране раскроется окно Data Analysis, в котором следует выбрать значение Moving Average. В результате на экран будет выведено диалоговое окно Moving Average, представленное на рис. 11.1.
В диалоговом окне Скользящее среднее задаются следующие параметры.
1. Input Range (Входные данные) — в это поле вводится диапазон ячеек, содержащих значения исследуемого параметра.
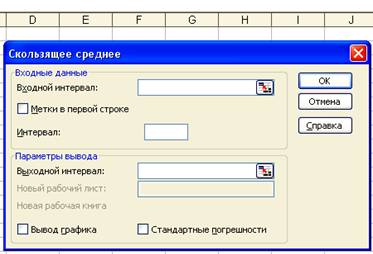
2. Labels in First Row (Метки в первой строке) — данный флажок опции устанавливается в том случае, если первая строка/столбец входного диапазона содержит заголовок. Если заголовок отсутствует, флажок следует сбросить. В этом случае для данных выходного диапазона будут автоматически созданы стандартные названия.
3. Interval (Интервал) — в это поле вводится число уровней m, входящих в интервал сглаживания. По умолчанию v = 3.
4. Output options (Параметры вывода) — в этой группе, помимо указания диапазона ячеек для выходных данных в поле Output Range (Выходной диапазон), можно также потребовать автоматически построить график, для чего нужно установить флажок опции Chart Output (Вывод графика), и рассчитать стандартные погрешности, для чего необходимо установить флажок опции Standart Errors (Стандартные погрешности).
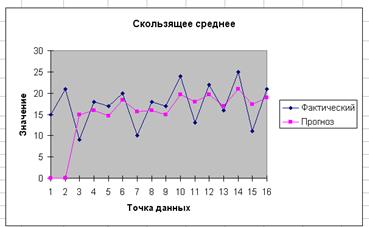
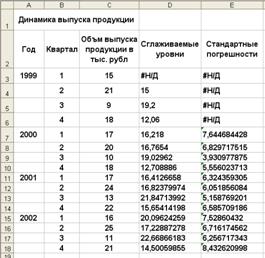
Рассмотрим конкретный пример. Допустим, за указанный период ( гг.) необходимо выявить основную тенденцию изменения фактического объема выпуска продукции и характер сезонных колебаний этого показателя. Данные для примера представлены на рис. 11.2. На рис. 11.3 отображены вычисленные с помощью функции Moving Average (Скользящее среднее) значения сглаженных уровней и значения m=3.
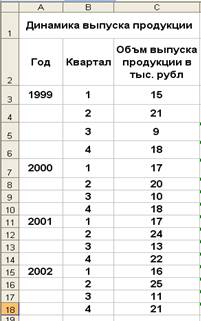
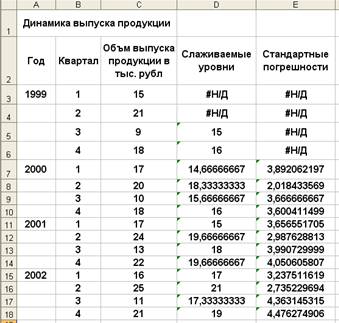
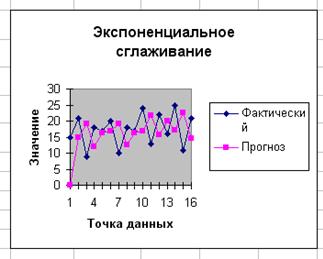
Ha puc. 11.4 rpaфически представлены фактические и прогнозируемые значения анализируемого ряда.
Рассчитанные сглаженные уровни не только дают представление об общей тенденции поведения изучаемого ряда, но и может быть также использованы для вычисления индексов сезонности IS , совокупность которых характеризует сезонную кривую исследуемого процесса. Средние индексы сезонности определяются по формуле

где![]() - исходные уровни ряда,
- исходные уровни ряда,![]() - сглаженные уровни ряда, u — число одноименных периодов.
- сглаженные уровни ряда, u — число одноименных периодов.
На рис. 11.3 представлены вычисленные значения ![]() . Для получения средних индексов сезонности IX выполняется усреднение вычисленных значений
. Для получения средних индексов сезонности IX выполняется усреднение вычисленных значений 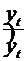 , по одноименным кварталам.
, по одноименным кварталам.
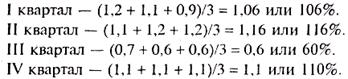
Вычисленные показатели являются средними индексами сезонных колебаний объема выпуска продукции по кварталам.
3.2 Метод экспоненциального сглаживания
Простая и логически ясная модель временного ряда имеет следующий вид:
![]() (11.5)
(11.5)
где b — константа, а ε — случайная ошибка. Константа b относительно стабильна на каждом временном интервале, но может также медленно изменяться со временем. Один из интуитивно ясных способов выделения значения b из данных состоит в том, чтобы использовать сглаживание скользящим средним, в котором последним наблюдениям приписываются большие веса, чем предпоследним, предпоследним большие веса, чем пред- предпоследним, и т. д. Простое экспоненциальное сглаживание именно так и построено. Здесь более старым наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не только те, которые попали в определенное окно. Точная формула простого экспоненциального сглаживания имеет вид:
![]() (11.6)
(11.6)
Когда эта формула применяется рекурсивно, каждое новое сглаженное значение (которое является также прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра α. Если α равен 1, то предыдущие наблюдения полностью игнорируются. Если а равен 0, то игнорируются текущие наблюдения. Значения α между 0 и 1 дают промежуточные результаты. Эмпирические исследования показали, что простое экспоненциальное сглаживание весьма часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать α меньше 0,30. Однако выбор а больше 0,30 иногда дает более точный прогноз. Это значит, что лучше все же оценивать оптимальное значение α по реальным данным, чем использовать общие рекомендации.
На практике оптимальный параметр сглаживания часто ищется с использованием процедуры поиска на сетке. Возможный диапазон значений параметра разбивается сеткой с определенным шагом. Например, рассматривается сетка значений от α =0,1 до α = 0,9 с шагом 0,1. Затем выбирается такое значение α, для которого сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.
Microsoft Excel располагает функцией Экспоненциальное сглаживание (Exponential Smoothing), которая обычно используется для сглаживания уровней эмпирического временного ряда на основе метода простого экспоненциального сглаживания. Для вызова этой функции необходимо на панели меню выбрать команду Tools - Data Analysis. На экране раскроется окно Data Analysis, в котором следует выбрать значение Экспоненциальное сглаживание. В результате появится диалоговое окно Экспоненциальное сглаживание, представленное на рис. 11.5.
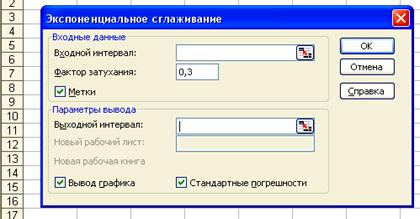
В диалоговом окне Exponential Smoothing задаются практически те же параметры, го и в рассмотренном выше диалоговом окне Moving Average.
1. Input Range (Входные данные) — в это поле вводится диапазон ячеек, содержащих значения исследуемого параметра.
2. Labels (Метки) — данный флажок опции устанавливается в том случае, если первая строка (столбец) во входном диапазоне содержит заголовок. Если заголовок отсутствует, флажок следует сбросить. В этом случае для данных выходного диапазона будут автоматически созданы стандартные названия.
3. Damping factor (Фактор затухания) — в это поле вводится значение выбранного коэффициента экспоненциального сглаживания α. По умолчанию принимается значение α = 0,3.
4. Output options (Параметры вывода) — в этой группе, помимо указания диапазона ячеек для выходных данных в поле Output Range (Выходной диапазон), можно также потребовать автоматически построить график, для чего необходимо установить флажок опции Chart Output (Вывод графика), и рассчитать стандартные погрешности, для чего нужно установить флажок опции Standart Errors (Стандартные погрешности).
Воспользуемся функцией Экспоненциальное сглаживание для повторного решения рассмотренной выше задачи, но уже с помощью метода простого экспоненциального сглаживания. Выбранные значения параметров сглаживания представлены на рис. 11.5. На рис. 11.6 показаны рассчитанные показатели, а на рис. 11.7 — построенные графики.
3.3 Метод аналитического выравнивания
Основным содержанием метода аналитического выравнивания временных рядов является расчет общей тенденции развития (тренда) как функции времени:
![]() (11.7)
(11.7)
где ![]() — теоретические значения временного ряда, вычисленные по соответствующему аналитическому уравнению на момент времени t.
— теоретические значения временного ряда, вычисленные по соответствующему аналитическому уравнению на момент времени t.
Определение теоретических (расчетных) значений![]() производится на основе так называемой адекватной математической модели, которая наилучшим образом отображает основную тенденцию развития временного ряда.
производится на основе так называемой адекватной математической модели, которая наилучшим образом отображает основную тенденцию развития временного ряда.
Простейшими моделями (формулами), выражающими тенденцию развития, являются следующие:
• линейная функция, график которой является прямой линией'- ![]() ;
;
• показательная функция: ![]()
• степенная функция второго порядка (парабола): ![]()
• логарифмическая функция: ![]()
Расчет параметров функции обычно производится методом наименьших квадратов (МНК), в котором в качестве решения принимается точка минимума суммы квадратов отклонений между теоретическим и эмпирическим уровнями:
![]() (11.8)
(11.8)
где ![]() -, — выровненные (расчетные) уровни, a yt — фактические уровни.
-, — выровненные (расчетные) уровни, a yt — фактические уровни.
Параметры уравнения αi удовлетворяющие этому условию, могут быть найдены решением системы нормальных уравнений. На основе найденного уравнения тренда вычисляются выровненные уровни.
Выравнивание по прямой используется в тех случаях, когда абсолютные приросты практически постоянны, т. е. когда уровни изменяются в арифметической профессии (или близко к ней).
Выравнивание по показательной функции применяется, когда ряд отражает развитие в геометрической профессии, т. е. цепные коэффициенты роста практически постоянны.
Выравнивание по степенной функции (параболе второго порядка) используется, когда ряды динамики изменяются с постоянными цепными темпами прироста.
Выравнивание по логарифмической функции применяется, когда ряд отражает развитие с замедлением роста в конце периода, т. е. когда прирост в конечных уровнях временного ряда стремится к нулю.
По вычисленным параметрам выполняется синтез трендовой модели функции, т. е. получение значений α0, α1, α2 и их подстановка в искомое уравнение.
Правильность расчетов аналитических уровней можно проверить по следующему условию: сумма значений эмпирического ряда должна совпадать с суммой вычисленных уровней выровненного ряда. При этом может возникнуть небольшая погрешность в расчетах из-за округления вычисляемых величин:

Для оценки точности трендовой модели используется коэффициент детерминации:

где![]() — дисперсия теоретических данных, полученных по трендовой модели, а ст; - дисперсия эмпирических данных.
— дисперсия теоретических данных, полученных по трендовой модели, а ст; - дисперсия эмпирических данных.
Трендовая модель адекватна изучаемому процессу и отражает тенденцию его развития при значениях![]() , близких к 1.
, близких к 1.
После выбора наиболее адекватной модели можно сделать прогноз на любой из периодов. При составлении прогнозов оперируют не точечной, а интервальной оценкой, определяя так называемые доверительные интервалы прогноза. Величина доверительного интервала определяется в общем виде следующим образом:

где![]() - среднее квадратическое отклонение от тренда;
- среднее квадратическое отклонение от тренда;![]() - табличное значение t-критерия Стьюдента при уровне значимости α, которое зависит от уровня значимости α (%) и числа степеней свободы
- табличное значение t-критерия Стьюдента при уровне значимости α, которое зависит от уровня значимости α (%) и числа степеней свободы![]()
Величина S; определяется по формуле:
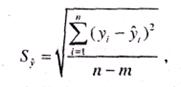 (11.12)
(11.12)
где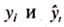 - фактические и расчетные значения уровней динамического ряда; п —число уровней ряда; m — количество параметров в уравнении тренда (для уравнения прямой m = 2, для уравнения параболы 2-го порядка m = 3).
- фактические и расчетные значения уровней динамического ряда; п —число уровней ряда; m — количество параметров в уравнении тренда (для уравнения прямой m = 2, для уравнения параболы 2-го порядка m = 3).
После необходимых расчетов определяется интервал, в котором с определенной вероятностью будет находиться прогнозируемая величина.
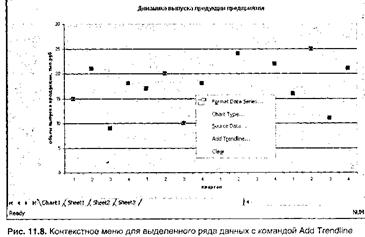
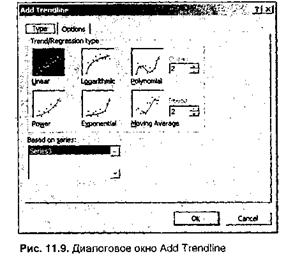
С помощью Microsoft Excel строить трендовые модели достаточно просто. Сначала эмпирический временной ряд следует представить в виде диаграммы одного из следующих типов: гистограмма, линейчатая диаграмма, график, точечная диаграмма, диаграмма с областями, а затем щелкнуть на диаграмме правой кнопкой мыши на одном из маркеров данных. В результате на диаграмме будет выделен сам временной ряд, а на экране раскроется контекстное меню, как показано на рис. 11.8. В этом меню следует выбрать команду Add Trendline (Добавить линию тренда). На экран будет выведено диалоговое окно Add Trendline, как показано на рис. 11.9.
На вкладке Туре (Тип) этого диалогового окна выбирается требуемый тип тренда:
• линейный (Linear);
• логарифмический (Logarithmic);
• полиномиальный, от 2-й до 6-й степени включительно (Polinomial);
• степенной (Power);
• экспоненциальный (Exponential);
• скользящее среднее, с указанием периода сглаживания от 2 до 15 (Moving Average).
На вкладке Options (Параметры) этого диалогового окна, показанной на рис. 11.10, задаются дополнительные параметры тренда.
1. Trendline Name (Название сглаженной кривой) — в этой группе выбирается название, которое будет выведено на диаграмму для обозначения функции, использованной для сглаживания временного ряда. Возможны следующие варианты:
Automatic (Автоматическое) — при установке переключателя в это положение Microsoft Excel автоматически формирует название функции сглаживания тренда, основываясь на выбранном типе тренда, например Linear (Линейная функция).
Custom (Другое) — при установке переключателя в данное положение в поле справа можно ввести собственное название для функции тренда, длиной до 256 символов.
2. Forecast (Прогноз) — в этой группе можно указать, на сколько периодов вперед (поле Forward) требуется спроектировать линию тренда в будущее и на сколько периодов назад (поле Backward) следует спроектировать линию тренда в прошлое (эти поля недоступны в режиме скользящего среднего).
3. Set intercept (Пересечение кривой с осью Y в точке) — этот флажок опции и расположенное справа поле ввода позволяют непосредственно указать точку, в которой линия тренда должна пересекать ось Y (эти поля доступны не для всех режимов).
4. Display equation on chart (Показывать уравнение ка диаграмме) — при установке этого флажка опции на диаграмму будет выведено уравнение, описывающее сглаживающую линию тренда.
5. Display R-squared value on chart (Поместить на диаграмму величину достоверности аппроксимации R-) — при установке данного флажка опции на диаграмме будет показано значение коэффициента детерминации.
Вместе с линией тренда на графике временного ряда могут быть также изображены планки погрешностей. Для вставки планок погрешностей необходимо выделить ряд данных, щелкнуть на нем правой кнопкой мыши и выбрать в раскрывшемся контекстном меню команду Format Data Series (рис. 11.8). На экране раскроется диалоговое но Format Data Series (Формат ряда данных), в котором следует перейти на вкладку Error Bars (Y-погрешности), показанную на рис. 11.11.
На этой вкладке с помощью переключателя Error amount (Величина погрешности) выбирается тип планок и вариант их расчета в зависимости от вида погрешности.
• Fixed value (Фиксированное значение) — при установке переключателя в это положение за допустимую величину ошибки принимается заданное в поле счетчика справа постоянное значение;
• Percentage (Относительное значение) — при установке переключателя в данное положение для каждой точки данных вычисляется допустимое отклонение, исходя из заданного в поле счетчика справа значения процента;

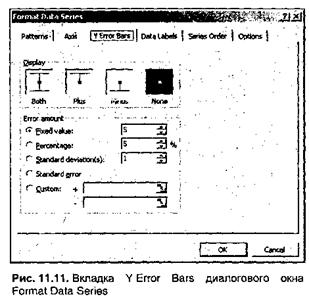
• Standard deviation(s) (Стандартное отклонение) — при установке переключателя в данное положение для каждой точки данных вычисляется стандартное отклонение, которое затем умножается на заданное в поле счетчика справа число (коэффициент кратности);
• Standard error (Стандартная погрешность) — при установке переключателя в данное положение принимается стандартная величина ошибки, постоянная для всех элементов данных;
• Custom (Пользовательская) — при установке переключателя в это положение вводится произвольный массив значений отклонений в положительную и/или отрицательную сторону (можно ввести ссылки на диапазон ячеек).
Планки погрешностей тоже можно форматировать. Для этого их следует выделить щелчком правой кнопки мыши и выбрать в раскрывшемся контекстном меню команду Format Error Bars (Формат планок погрешностей).
Рассмотрим конкретный пример — пусть требуется построить модель тренда для исходных данных, представленных на рис. 11.2. Вначале представим этот временной ряд в виде графика, построенного с помощью мастера диаграмм (см. рис. 11.8). Для нахождения наиболее подходящего случаю уравнения тренда воспользуемся командой Add Trendline. Результаты подбора уравнения приведены в табл. 11.2.

Принимая во внимание результаты выполненного в Excel аналитического выравнивания (см. табл. 11.2), в качестве математической модели тренда выбирается полином 3-го порядка (при подборе уравнения не рассматривались полиномы выше третьего порядка). Выбранная модель тренда графически представлена на рис. 11.12.
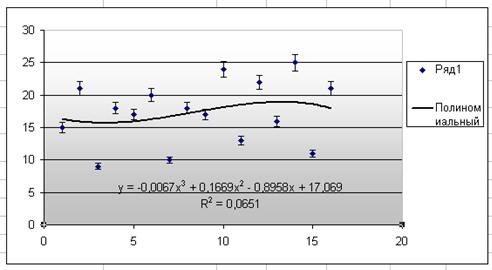
Рисунок 12
Резюме
В данной главе были рассмотрены основные характеристики временного ряда, модели декомпозиции временного ряда, а также основные методы сглаживания ряда - метод скользящего среднего, экспоненциального сглаживания и аналитического выравнивания. Для решения этих задач Microsoft Excel предлагаются такие инструменты, как Moving Average (Скользящее среднее) и Exponential Smoothing (Экспоненциальное сглаживание), которые позволяют сглаживать уровни эмпирического временного ряда, а также команда Add Trendline (Добавить линию тренда), которая позволяет строить модели тренда и делать прогноз на основе имеющихся значений временного ряда.
Вопросы
1. При анализе тренда для некоторого набора данных коэффициент детерминации для линейной модели оказался равен 0,95, для логарифмической — 0,8, а для полинома третьей степени — 0,9636. Какая трендовая модель наиболее адекватна изучаемому процессу:
а) линейная;
б) логарифмическая;
в) полином 3-й степени.
2. Поданным, представленным на рис. 11.2, спрогнозируйте объем выпуска продукции в 2003 году. Какая общая тенденция поведения исследуемой величины следует из результатов вашего прогноза:
а) наблюдается спад производства;
б) производство остается на прежнем уровне;
в) наблюдается рост производства.
