


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
На листинге
3 представлены функции для входа и выхода из критической области, выполненные в синтаксисе Ассемблера.
enter_region:
TSL REGISTER, LOCK ; значение LOCK копируется в регистр, значение
переменной устанавливается равной 1
GMP REGISTER,#0 ; старое значение LOCK сравнивается с нулем
JNE enter_region ; если оно ненулевое, значит блокировка уже
была установлена, поэтому цикл завершается
RET
leave_region:
MOVE LOCK,#0 ; сохранение 0 в переменной LOCK
RET
Листинг 3 – Вход и выход из критической области с помощью команды TSL
Прежде чем попасть в критическую область, процесс вызывает процедуру enter_region, которая выполняет активное ожидание вплоть до снятия блокировки, затем она устанавливает блокировку и возвращается. По выходе из критической области процесс вызывает процедуру leave_region, помещающую 0 в переменную LOCK. Как и во всех остальных решениях проблемы критической области, для корректной работы процесс должен вызывать эти процедуры своевременно, в противном случае взаимное исключение не удастся.
2.3.2 Примитивы межпроцессного взаимодействия
Решение Петерсона и с помощью команды TSL корректны, но у них один и тот же недостаток – использование активного ожидания. Т. е. процесс входит в цикл, ожидая возможности войти в критическую область.
Помимо бесцельной траты времени процессора на выполнение данного цикла, существует так называемая проблема инверсии приоритета. Суть её в следующем. Процессу с низким приоритетом никогда не будет предоставлено процессорное время, если в это время выполняется процесс с высоким приоритетом. Таким образом, если процесс с низким приоритетом находится в критической области, а процесс с высоким приоритетом, заканчивая операцию ввода-вывода, оказывается в режиме ожидания, то процессорное время будет отдано процессу с высоким приоритетом. В результате процесс с низким приоритетом никогда не выйдет из критической области, а процесс с высоким приоритетом будет бесконечно выполнять цикл.
Поэтому вместо циклов ожидания применяются примитивы межпроцессного взаимодействия, которые блокируют процессы в случае запрета на вход в критическую область. Одной из простейших является пара примитивов sleep и wakeup. Примитив sleep – системный запрос, в результате которого вызывающий процесс блокируется, пока его не запустит другой процесс. У запроса wakeup есть один параметр – процесс, который следует запустить. Также возможно наличие одного параметра у обоих запросов – адреса ячейки памяти, используемой для согласования запросов ожидания и запуска.
Два процесса совместно используют буфер ограниченного размера. Один из них, производитель, помещает данные в буфер, а потребитель считывает их оттуда. Трудности начинаются в тот момент, когда производитель хочет поместить в буфер очередную порцию данных и обнаруживает, что буфер полон. Для производителя решением является ожидание, пока потребитель полностью или частично не очистит буфер. Аналогично, если потребитель хочет забрать данные из буфера, а буфер пуст, потребитель уходит в состояние ожидания и выходит из него, как только производитель положит что-нибудь в буфер и разбудит его.
Это решение кажется достаточно простым, но оно приводит к состояниям состязания. Нужна переменная count для отслеживания количества элементов в буфере. Если максимальное число элементов, хранящихся в буфере, равно N, программа производителя должна проверить, не равно ли N значение count прежде, чем поместить в буфер следующую порцию данных. Если значение count равно N, то производитель уходит в состояние ожидания; в противном случае производитель помещает данные в буфер и увеличивает значение count.
Код программы потребителя прост: сначала проверить, не равно ли значение count нулю. Если равно, то уйти в состояние ожидания; иначе забрать порцию данных из буфера и уменьшить значение count. Каждый из процессов также должен проверять, не следует ли активизировать другой процесс, и в случае необходимости проделывать это. Программы обоих процессов представлены в листинге 4.
#define N 100
int count = 0;
void producer()
{
int item;
while (TRUE) {
item=produce_item(); //сформировать следующий элемент
if (count==N) sleep(); //буфер полон – состояние ожидания
insert_item(item); //поместить элемент в буфер
count++;
if (count==1) wakeup(consumer);
}
}
void consumer()
{
int item;
while (TRUE) {
if (count==0) sleep(); //буфер пуст – состояние ожидания
item=remove_item(item); //забрать элемент из буфера
count--;
if (count==N-1) wakeup(producer);
}
}
Листинг 4 – Проблема производителя и потребителя с состоянием соревнования
Для описания на языке С системных вызовов sleep и wakeup они были представлены в виде вызовов библиотечных процедур. В стандартной библиотеке С их нет, но они будут доступны в любой системе, в которой присутствуют такие системные вызовы. Процедуры insert_item и remove_item помещают элементы в буфер и извлекают их оттуда.
Возникновение состояния состязания возможно, поскольку доступ к переменной count не ограничен. Может возникнуть следующая ситуация: буфер пуст, и потребитель только что считал значение переменной count, чтобы проверить, не равно ли оно нулю. В этот момент планировщик передал управление производителю, производитель поместил элемент в буфер и увеличил значение count, проверив, что теперь оно стало равно 1. Зная, что перед этим оно было равно 0 и потребитель находился в состоянии ожидания, производитель активизирует его с помощью вызова wakeup.
Но потребитель не был в состоянии ожидания, так что сигнал активизации пропал впустую. Когда управление перейдет к потребителю, он вернется к считанному когда-то значению count, обнаружит, что оно равно 0, и уйдет в состояние ожидания. Рано или поздно производитель наполнит буфер и также уйдет в состояние ожидания. Оба процесса так и останутся в этом состоянии.
Суть проблемы в данном случае состоит в том, что сигнал активизации, пришедший к процессу, не находящемуся в состоянии ожидания, пропадает. Если бы не это, проблемы бы не было. Быстрым решением может быть добавление бита ожидания активизации. Если сигнал активизации послан процессу, не находящемуся в состоянии ожидания, этот бит устанавливается. Позже, когда процесс пытается уйти в состояние ожидания, бит ожидания активизации сбрасывается, но процесс остается активным. Этот бит исполняет роль копилки сигналов активизации.
Несмотря на то, что введение бита ожидания запуска спасло положение в этом примере, легко сконструировать ситуацию с несколькими процессами, в которой одного бита будет недостаточно. Можно добавить еще один бит, или 8, или 32, но это не решит проблему.
В 1965 году Дейкстра [16] предложил использовать семафор – переменную для подсчета сигналов запуска. Семафор – объект синхронизации, который может регулировать доступ к некоторому ресурсу. Также было предложено использовать вместо sleep и wakeup две операции down и up. Их отличие в следующем: если значение семафора больше нуля, то down просто уменьшает его на 1 и возвращает управление процессу, в противном случае процесс переводится в режим ожидания. Все операции проверки значения семафора, его изменения и перевода процесса в состояние ожидания выполняются как единое и неделимое элементарное действие, т. е. в это время ни один процесс не может получить доступ к этому семафору. Операция up увеличивает значение семафора. Если с этим семафором связаны один или несколько ожидающих процессов, которые не могут завершить более раннюю операцию down, один из них выбирается системой и разблокируется. Проблема производителя и потребителя легко решается с помощью семафоров.
Иногда используется упрощенная версия семафора, называемая мьютексом. Мьютекс – переменная, которая может находиться в одном из двух состояний: блокированном или неблокированном. Поэтому для описания мьютекса требуется всего один бит. Мьютекс может охранять неразделенный ресурс, к которому в каждый момент времени допускается только один поток, а семафор может охранять ресурс, с которым может одновременно работать не более N потоков.
Недостатком семафоров является то, что одна маленькая ошибка при их реализации программистом приводит к остановке всей операционной системы. Чтобы упростить написание программ в 1974 году было предложено использовать примитив синхронизации более высокого уровня, называемый монитором. Монитор – набор процедур, переменных и других структур данных, объединенных в особый модуль или пакет. Процессы могут вызывать процедуры монитора, но у процедур объявленных вне монитора, нет прямого доступа к внутренним структурам данных монитора. При обращении к монитору в любой момент времени активным может быть только один процесс. Монитор похож по своей структуре на класс в C++. Не все языки программирования поддерживают мониторы и не во всех операционных системах есть их встроенная реализация. Так в Windows их нет.
Все описанные примитивы не подходят для реализации обмена информации между компьютерами в распределенной системе с несколькими процессорами. Для этого используется передача сообщений. Этот метод межпроцессного взаимодействия использует два примитива: send и receive, которые скорее являются системными вызовами, чем структурными компонентами языка. Первый запрос посылает сообщение заданному адресату, а второй получает сообщение от указанного источника. Передача сообщений часто используется в системах с параллельным программированием.
Последний из рассмотренных механизмов синхронизации называется барьер, который предназначен для синхронизации группы процессов – т. е. несколько процессов выполняют вычисления с разной скоростью, а затем посредством применения барьера ожидают, пока самый медленный не закончит работу, и только потом все вместе продолжают выполнение команд.
Литература по операционным системам содержит множество интересных проблем, которые широко обсуждались и анализировались с применением различных методов синхронизации. Часть из них описана в работе [14].
3.1 Основы управления памятью
Часть операционной системы, отвечающая за управление памятью, называется менеджером памяти. Функциями операционной системы по управлению памятью в мультипрограммной системе являются:
· отслеживание свободной и занятой памяти;
· выделение памяти процессам и освобождение памяти по завершении процессов;
· вытеснение кодов и данных процессов из оперативной памяти на диск (полное или частичное), когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место;
· настройка адресов программы на конкретную область физической памяти [11].
Для идентификации переменных и команд на разных этапах жизненного цикла программы используются символьные имена (метки), виртуальные адреса и физические адреса (Рисунок 19).
· Символьные имена присваивает пользователь при написании программы на алгоритмическом языке или ассемблере.
· Виртуальные адреса, называемые иногда математическими, или логическими адресами, вырабатывает транслятор, переводящий программу на машинный язык. Поскольку во время трансляции в общем случае не известно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что начальным адресом программы будет нулевой адрес.
· Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды.
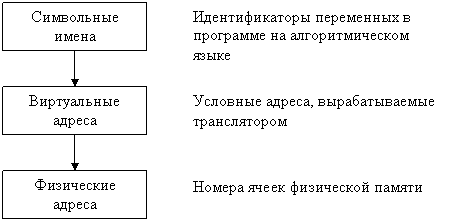 |
Рисунок 19 – Типы адресов
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Диапазон возможных адресов виртуального пространства у всех процессов является одним и тем же. Совпадение виртуальных адресов переменных и команд различных процессов не приводит к конфликтам, так как в том случае, когда эти переменные одновременно присутствуют в памяти, операционная система отображает их на разные физические адреса.
Существуют два принципиально отличающихся подхода к преобразованию виртуальных адресов в физические.
В первом случае замена виртуальных адресов на физические выполняется один раз для каждого процесса во время начальной загрузки программы в память.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, то есть операнды инструкций и адреса переходов имеют те значения, которые выработал транслятор. В наиболее простом случае, когда виртуальная и физическая память процесса представляют собой единые непрерывные области адресов, операционная система выполняет преобразование виртуальных адресов в физические по следующей схеме. При загрузке операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Схема такого преобразования показана на рисунке 20.
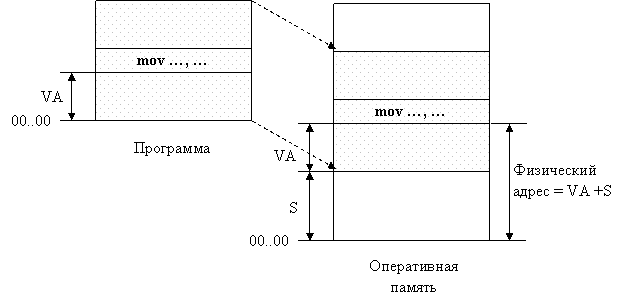 |
Рисунок 20 – Схема динамического преобразования адресов
Системы управления памятью разделяются на два класса по методам распределения памяти:
· перемещающие процессы между памятью и диском;
· не делающие этого, что представлено на рисунке 21.
Перед тем, как рассматривать методы распределения памяти для многозадачных систем, которые представлены на рисунке 21, рассмотрим однозадачную систему без подкачки на диск, т. е. систему, в которой в каждый момент времени работает только одна программа. Простейшие три способа организации памяти для такой системы, представлены на рисунке 22.
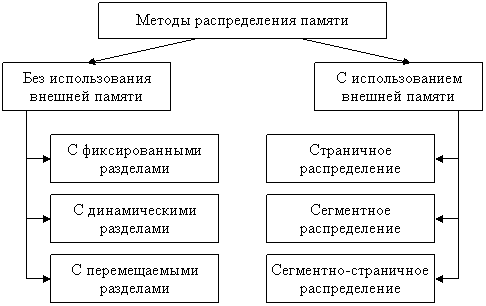 |
Рисунок 21 – Методы распределения памяти
На рисунках представлено условное разделение памяти на верхнюю ПЗУ и нижнюю ОЗУ. Первая модель использовалась на старых компьютерах, Вторая модель используется сейчас на некоторых встроенных системах. Третья модель устанавливалась на ранних персональных компьютерах, оснащенных MS-DOS, где в роли ПЗУ выступает BIOS.
При использовании многозадачности повышается эффективность загрузки центрального процессора. К примеру, если средний процесс выполняет вычисления только 20 % от того времени, которое он находится в памяти, то при присутствии в памяти одновременно пяти процессов центральный процессор должен быть занят все время.
 |
Рисунок 22 – Простейшие модели организации памяти при наличии операционной системы и одного пользовательского процесса
Если в памяти находится одновременно n процессов, вероятность того, что все n процессов ждут ввод-вывод (в этом случае центральный процессор будет бездействовать), равна pn. Тогда степень загрузки центрального процессора будет выражаться формулой [14]:
C = 1 – pn. (3)
 На рисунке 23 показана зависимость степени использования центрального процессора от числа n, называемого степенью многозадачности.
На рисунке 23 показана зависимость степени использования центрального процессора от числа n, называемого степенью многозадачности.
|
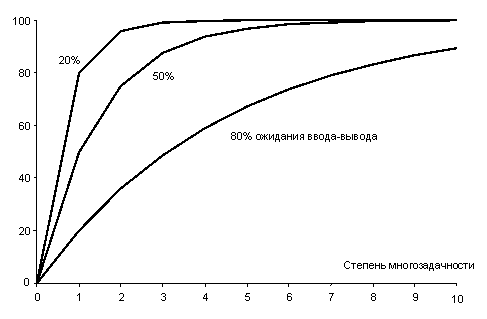

Рисунок 23 – Зависимость загрузки процессора от числа задач и процента ожидания ввода-вывода от общей времени работы процесса
Из рисунка понятно, что если процессы проводят 80 % своего времени в ожидании завершения операции ввода-вывода, то для того, чтобы получить потерю времени процессора ниже 10 %, в памяти должны одновременно находиться, по меньшей мере, 10 процессов.
3.2 Методы распределения памяти без использования подкачки
3.2.1 Метод распределения с фиксированными разделами
Первой многозадачной системой была именно система с фиксированными разделами. Память разбивается на несколько областей фиксированной величины, называемых разделами. Такое разбиение может быть выполнено вручную оператором во время старта системы или во время ее установки. После этого границы разделов не изменяются.
Очередной новый процесс, поступивший на выполнение, помещается либо в общую очередь (Рисунок 24, а), либо в очередь к некоторому разделу (Рисунок 24, б).
Подсистема управления памятью в этом случае выполняет следующие задачи.
· Сравнивает объем памяти, требуемый для вновь поступившего процесса, с размерами свободных разделов и выбирает подходящий раздел.
· Осуществляет загрузку программы в один из разделов и настройку адресов. Уже на этапе трансляции разработчик программы может задать раздел, в котором ее следует выполнять. Это позволяет сразу, без использования перемещающего загрузчика, получить машинный код, настроенный на конкретную область памяти.
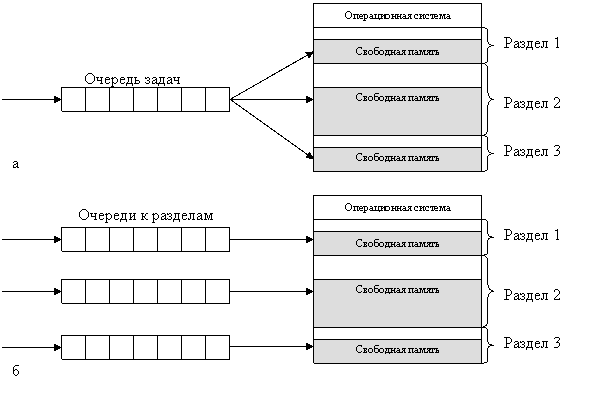 |
Рисунок 24 – Распределение памяти фиксированными разделами: с общей очередью (а), с отдельными очередями (б)
При очевидном преимуществе – простоте реализации, данный метод имеет существенный недостаток – жесткость заданных размеров памяти для каждого процесса. Подобная схема использовалась в OS/360 и на настоящий момент не используется.
3.2.2 Метод распределения с динамическими разделами
В этом случае память машины не делится заранее на разделы. Сначала вся память, отводимая для приложений, свободна. Каждому вновь поступающему на выполнение приложению на этапе создания процесса выделяется вся необходимая ему память (если достаточный объем памяти отсутствует, то приложение не принимается на выполнение и процесс для него не создается). После завершения процесса память освобождается, и на это место может быть загружен другой процесс.
На рисунке 25 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так, в момент t0 памяти находится только операционная система, а к моменту t1 память разделена между пятью процессами, причем процесс П4, завершаясь, покидает память. На освободившееся от процесса П4 место загружается процесс П6, поступивший в момент t3.
Функции операционной системы, предназначенные для реализации данного метода управления памятью, перечислены ниже.
· Ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти.
· При создании нового процесса — анализ требований к памяти, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения кодов и данных нового процесса. Выбор раздела может осуществляться по разным правилам, например: «первый попавшийся раздел достаточного размера», «раздел, имеющий наименьший достаточный размер» или «раздел, имеющий наибольший достаточный размер».
· Загрузка программы в выделенный ей раздел и корректировка таблиц свободных и занятых областей Данный способ предполагает, что программный код не перемещается во время выполнения, а значит, настройка адресов может быть проведена единовременно во время загрузки.
· После завершения процесса корректировка таблиц свободных и занятых областей.
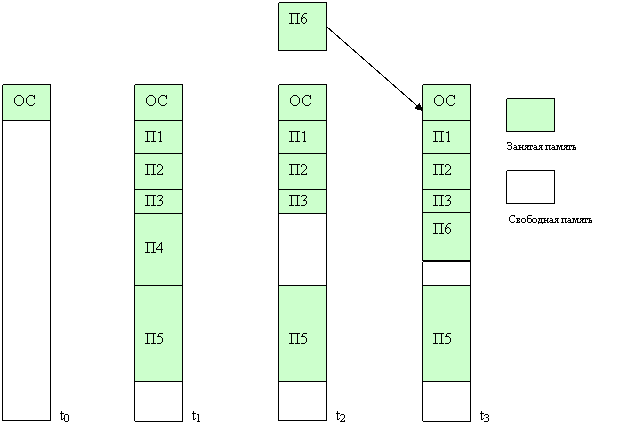 |
Рисунок 25 – Распределение памяти динамическими разделами
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток – фрагментация памяти. Фрагментация – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов).
3.2.3 Метод распределения с перемещаемыми разделами
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших или младших адресов, так, чтобы вся свободная память образовала единую свободную область (Рисунок 26). В дополнение к функциям, которые выполняет операционная система при распределении памяти динамическими разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием.
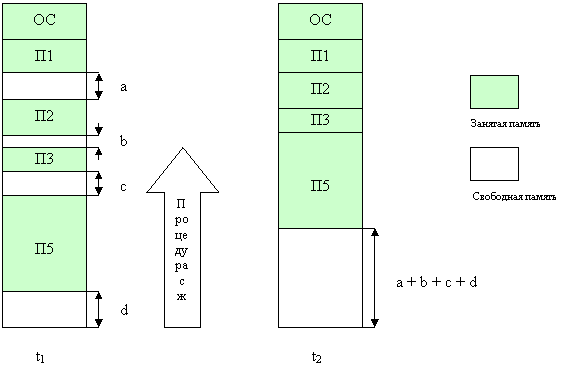
Рисунок 26 – Распределение памяти перемещаемыми разделами
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Такой подход был использован в ранних версиях OS/2, в которых память распределялась сегментами, а возникавшая при этом фрагментация устранялась путем периодического перемещения сегментов.
3.3 Методы распределения памяти с подкачкой на жесткий диск
Оперативной памяти иногда оказывается недостаточно для того, чтобы вместить все текущие процессы, и тогда избыток процессов приходится хранить на диске, а для обработки динамически переносить их в память.
Такая подмена (виртуализация) оперативной памяти дисковой памятью позволяет повысить уровень мультипрограммирования – объем оперативной памяти компьютера не столь жестко ограничивает количество одновременно выполняемых процессов, поскольку суммарный объем памяти, занимаемой образами этих процессов, может существенно превосходить имеющийся объем оперативной памяти. Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает.
Виртуализация оперативной памяти осуществляется совокупностью программных модулей операционной системы и аппаратных схем процессора и включает решение следующих задач:
· размещение данных в запоминающих устройствах разного типа, например часть кодов программы – в оперативной памяти, а часть – на диске;
· выбор образов процессов или их частей для перемещения из оперативной памяти на диск и обратно;
· перемещение по мере необходимости данных между памятью и диском;
· преобразование виртуальных адресов в физические.
Виртуализация памяти может быть осуществлена на основе двух различных подходов:
· свопинг
(swapping) или обычная подкачка – образы процессов выгружаются на диск и возвращаются в оперативную память целиком;
· виртуальная память (virtual memory) – между оперативной памятью и диском перемещаются части (сегменты, страницы и т. п.) образов процессов.
Недостатком свопинга является то, что при его осуществлении происходит перемещение избыточной информации, а также операционные системы, поддерживающие свопинг не способны загрузить для выполнения процесс, виртуальное адресное пространство которого превышает имеющуюся в наличии свободную память. Именно из-за указанных недостатков свопинг как основной механизм управления памятью почти не используется в современных операционных системах.
В настоящее время все множество реализаций виртуальной памяти может быть представлено тремя классами.
· Страничная виртуальная память организует перемещение данных между памятью и диском страницами – частями виртуального адресного пространства, фиксированного и сравнительно небольшого размера.
· Сегментная виртуальная память предусматривает перемещение данных сегментами – частями виртуального адресного пространства произвольного размера, полученными с учетом смыслового значения данных.
· Сегментно-страничная виртуальная память использует двухуровневое деление: виртуальное адресное пространство делится на сегменты, а затем сегменты делятся на страницы. Единицей перемещения данных здесь является страница. Этот способ управления памятью объединяет в себе элементы обоих предыдущих подходов.
Для временного хранения сегментов и страниц на диске отводится либо специальная область, либо специальный файл, которые во многих операционных системах по традиции продолжают называть областью, или файлом свопинга (подкачки), хотя перемещение информации между оперативной памятью и диском осуществляется уже не в форме полного замещения одного процесса другим, а частями.
3.3.1 Страничная организация памяти
На рисунке 27 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами (virtual pages). В общем случае размер виртуального адресного пространства процесса не кратен размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
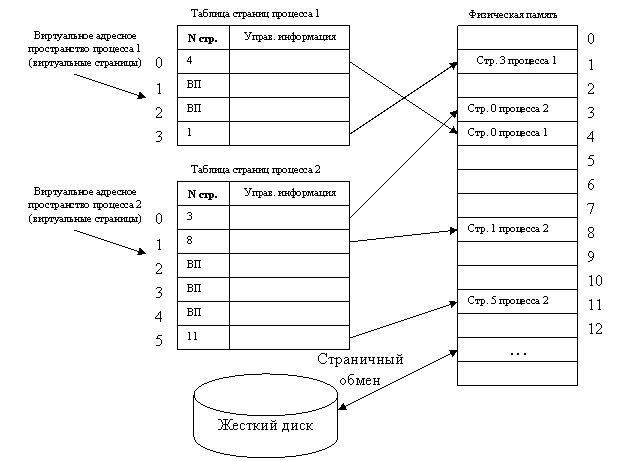 |
Рисунок 27 – Страничное распределение памяти
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками, или кадрами).
Размер страницы выбирается равным степени двойки: 512, 1024, 4096 байт и т. д. Это позволяет упростить механизм преобразования адресов.
Операционная система при создании процесса загружает в оперативную память несколько его виртуальных страниц (начальные страницы кодового сегмента и сегмента данных). Копия всего виртуального адресного пространства процесса находится на диске. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. Для каждого процесса операционная система создает таблицу страниц – информационную структуру, содержащую записи обо всех виртуальных страницах процесса.
Запись таблицы, называемая дескриптором страницы, включает следующую информацию:
· номер физической страницы, в которую загружена данная виртуальная страница;
· признак присутствия, устанавливаемый в единицу, если виртуальная страница находится в оперативной памяти;
· признак модификации страницы, который устанавливается в единицу всякий раз, когда производится запись по адресу, относящемуся к данной странице;
· признак обращения к странице, называемый также битом доступа, который устанавливается в единицу при каждом обращении по адресу, относящемуся к данной странице.
Информация из таблиц страниц используется для решения вопроса о необходимости перемещения той или иной страницы между памятью и диском, а также для преобразования виртуального адреса в физический. Виртуальные адреса не передаются напрямую на шину памяти, а передаются на диспетчер памяти (MMU – Memory Management Unit), которые отображает виртуальные адреса на физические (Рисунок 28). Диспетчер памяти в настоящее время обычно встраивается в микросхему процессора.
 |
Рисунок 28 – Расположение и функции диспетчера памяти
Например, если использовать команду mov [3] для получения доступа к адресу 0
MOV REG, 0
виртуальный адрес 0 передаётся в MMU. Предположим, что размер страницы 4096 байт, тогда, руководствуясь таблицей страниц процесса 1 (Рисунок 27), MMU преобразует команду следующим образом:
MOV REG, 16384
При каждом обращении к памяти выполняется поиск номера виртуальной страницы, содержащей требуемый адрес, затем по этому номеру определяется нужный элемент таблицы страниц, и из него извлекается описывающая страницу информация. Далее анализируется признак присутствия, и, если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический, то есть виртуальный адрес заменяется указанным в записи таблицы физическим адресом. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди процессов, находящихся в состоянии готовности. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу (для этого операционная система должна помнить положение вытесненной страницы в страничном файле диска) и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то на основании принятой в данной системе стратегии замещения страниц решается вопрос о том, какую страницу следует выгрузить из оперативной памяти.
Важным фактором, влияющим на производительность системы, является частота страничных прерываний, на которую, в свою очередь, влияют размер страницы и принятые в данной системе правила выбора страниц для выгрузки и загрузки. При неправильно выбранной стратегии замещения страниц могут возникать ситуации, когда система тратит большую часть времени впустую, на подкачку страниц из оперативной памяти на диск и обратно.
При выборе страницы на выгрузку могут быть использованы различные критерии, смысл которых сводится к одному: на диск выталкивается страница, к которой в будущем, начиная с данного момента, дольше всего не будет обращений.
При страничной организации памяти есть 2 проблемы: 1) таблица страниц может быть слишком большой; 2) отображение страниц должно быть быстрым.
Для решения первой проблемы используют многоуровневые таблицы памяти [14], при использовании которых в памяти находятся только части таблицы страниц.
Для решения второй компьютер снабжается небольшим аппаратным устройством, служащим для отображения виртуальных адресов в физические без прохода по таблице страниц. Это устройство называется буфером быстрого преобразования адреса (TLB – Translation Lookaside Buffer) или ассоциативной памятью.
Большинство программ склонно делать огромное количество обращений к небольшому количеству страниц, а не наоборот. Таким образом, в таблице страниц только малая доля записей читается интенсивно, остальная часть едва ли вообще используется. Поэтому эта малая доля записей копируется в TLB, который работает гораздо быстрее стандартного обращения к таблице страниц.
Когда происходит страничное прерывание, операционная система должна выбрать страницу для удаления из памяти, чтобы освободить место для страницы, которую нужно перенести в память. Если удаляемая страница была изменена за время своего присутствия в памяти, ее необходимо переписать на диск, чтобы обновить копию, хранящуюся там. Однако если страница не была модифицирована (например, она содержит текст программы), копия на диске уже является самой новой и ее не надо переписывать. Тогда страница, которую нужно прочитать, просто считывается поверх выгружаемой страницы.
Хотя в принципе можно при каждом страничном прерывании выбирать случайную страницу для удаления из памяти, производительность системы заметно повышается, когда предпочтение отдается редко используемой странице. Ниже описаны некоторые наиболее важные алгоритмы замещения страниц.
1Оптимальный алгоритм
В тот момент, когда происходит страничное прерывание, в памяти находится некоторый набор страниц. К одной из этих страниц будет обращаться следующая команда процессора (к странице, содержащей требуемую команду). На другие страницы, возможно, не будет ссылок в течение следующих 10, 100 или даже 1000 команд. Каждая страница может быть помечена количеством команд, которые будут выполняться перед первым обращением к этой странице. Оптимальный страничный алгоритм просто сообщает, что должна быть выгружена страница с наибольшей меткой.
С этим алгоритмом связана только одна проблема: он невыполним. В момент страничного прерывания операционная система не имеет возможности узнать, когда произойдет следующее обращение к каждой странице.
2 Алгоритм NRU – не использовавшаяся в последнее время страница
Чтобы дать возможность операционной системе собирать полезные статистические данные о том, какие страницы используются, а какие – нет, большинство компьютеров с виртуальной памятью поддерживают два статусных бита, связанных с каждой страницей. Бит R (Referenced – обращения) устанавливается всякий раз, когда происходит обращение к странице (чтение или запись). Бит М (Modified – изменение) устанавливается, когда страница записывается (то есть изменяется). Биты содержатся в каждом элементе таблицы страниц. Если аппаратное обеспечение не поддерживает эти биты, их можно смоделировать.
Биты R и M могут использоваться для построения простого алгоритма замещения страниц, описанного ниже. Когда процесс запускается, оба страничных бита для всех его страниц операционной системой установлены на 0. Периодически (например, при каждом прерывании по таймеру) бит R очищается, чтобы отличить страницы, к которым давно не происходило обращения от тех, на которые были ссылки. Когда возникает страничное прерывание, операционная система проверяет все страницы и делит их на четыре категории на основании текущих значений битов R и M:
· класс 0: не было обращений и изменений;
· класс 1: не было обращений, страница изменена;
· класс 2: было обращение, страница не изменена;
· класс 3: произошло и обращение, и изменение.
Хотя класс 1 на первый взгляд кажется невозможным, такое случается, когда у страницы из класса 3 бит R сбрасывается во время прерывания по таймеру. Прерывания по таймеру не стирают бит М, потому что эта информация необходима для того, чтобы знать, нужно ли переписывать страницу на диске или нет. Поэтому если бит R устанавливается на ноль, а M остается нетронутым, страница попадает в класс 1.
Алгоритм NRU (Not Recently Used) удаляет страницу с помощью случайного поиска в непустом классе с наименьшим номером. Привлекательность алгоритма NRU заключается в том, что он легок для понимания, умеренно сложен в реализации и дает производительность, которая может вполне оказаться достаточной.
3 Алгоритм FIFO – первым прибыл – первым обслужен
Операционная система поддерживает список всех страниц, находящихся в данный момент в памяти, в котором первая страница является старейшей, а страницы в хвосте списка попали в него совсем недавно. Когда происходит страничное прерывание, выгружается из памяти страница в голове списка, а новая страница добавляется в его конец. Данный алгоритм не используется, так как он может удалить наиболее часто вызываемую страницу.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
