
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
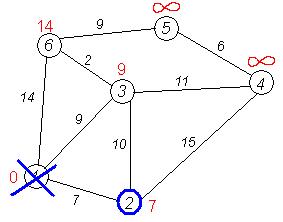
Снова пытаемся уменьшить метки соседей выбранной вершины, пытаясь пройти в них через 2-ю. Соседями вершины 2 являются 1, 3, 4.
Первый (по порядку) сосед вершины 2 — вершина 1. Но она уже посещена, поэтому с 1-й вершиной ничего не делаем.
Следующий сосед вершины 2 — вершина 4/*3*/. Если идти в неё через 2-ю, то длина такого пути будет = кратчайшее расстояние до 2 + расстояние между вершинами 2 и 4 = 7 + 15 = 22. Поскольку 22<![]() , устанавливаем метку вершины 4 равной 22.
, устанавливаем метку вершины 4 равной 22.
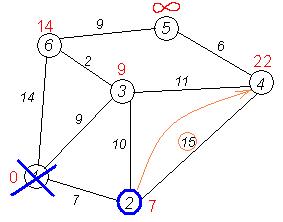
Ещё один сосед вершины 2 — вершина 3. Если идти в неё через 2, то длина такого пути будет = 7 + 10 = 17. Но текущая метка третьей вершины равна 9<17, поэтому метка не меняется.

Все соседи вершины 2 просмотрены, замораживаем расстояние до неё и помечаем ее как посещенную.
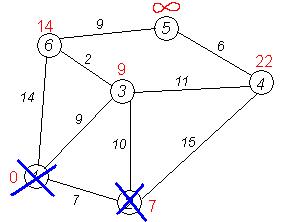
Третий шаг. Повторяем шаг алгоритма, выбрав вершину 3. После ее «обработки» получим такие результаты:
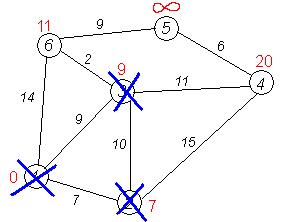
Дальнейшие шаги. Повторяем шаг алгоритма для оставшихся вершин (Это будут по порядку 6, 4 и 5).
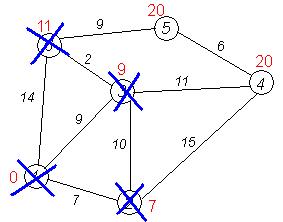
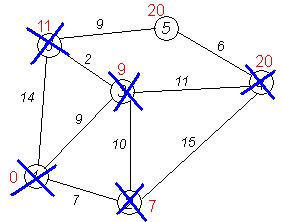
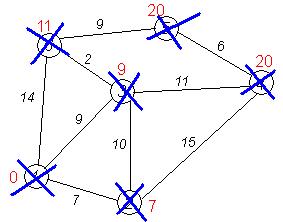
Завершение выполнения алгоритма. Алгоритм заканчивает работу, когда вычеркнуты все вершины. Результат его работы виден на последнем рисунке: кратчайший путь от вершины 1 до 2-й составляет 7, до 3-й — 9, до 4-й — 20, до 5-й — 20, до 6-й — 11.
Алгоритмы поиска пути на графе различаются также направлением поиска. Существуют прямые, обратные и двунаправленные методы поиска. Двунаправленный поиск требует удовлетворительного решения двух проблем: смены направления поиска и оптимизации "точки встречи". Одним из критериев для решения первой проблемы является сравнение "ширины" поиска в обоих направлениях - выбирается то направление, которое сужает поиск. Вторая проблема вызвана тем, что прямой и обратный пути могут разойтись и, чем уже поиск, тем это более вероятно.
6.5. Решение задач на основе нечеткого планирования
Недостатком большинства известных в настоящее время систем планирования является их жесткая привязка к схеме планирования. Любая из них всегда ищет решение либо SS - проблемы, либо PR - проблемы. Связано это с фиксацией формы представления информации для планирования. Для классических моделей SS - и PR - проблем эти формы различны. Человек в своей деятельности успешно комбинирует шаги планирования из решения SS и PR - проблем. Вторым недостатком является детерминированность систем планирования. В реальных СИИ детерминированность планирования, как правило, не имеет места. Обобщение нечетких SS - и PR - проблем заключается в допущении нечетких состояний и нечетких операторов перехода из состояния в состояние. Разбиение задачи на подзадачи имеет весовые коэффициенты на дугах со значениями из множества [0, 1], которые интерпретируются как достоверности решения соответствующих подпроблем. Достоверность решения PR-проблемы определяется как минимум достоверностей решения ее подпроблем.
Схемой SS - проблемы называется пара M = (S, G), где S - множество состояний, G - множество отображений g: S->S, называемых операторами. SS - проблема - это четверка Р = (S, G, i, f ), где (S, G) - схема SS - проблемы, i, f - соответственно начальное и заключительное состояние. Путь х, ведущий из i в f, есть решение Р, а множество всех подобных путей составляет множество решений.
Приведем формальное определение семантики сведения задачи к подзадачам.
Импликата проблемы Р есть пара (p, y ), где p =P1 P2... Pk - цепочка проблем, y - отображение из {Хр1, Хр2, ... , Хрk} в Хр. Хрi обозначает множество решений Рi. Импликативная схема есть тройка L =(Р, p, y ), такая, что Р - проблема, (p, y ) - импликата Р. Проблема Р решена тогда и только тогда, когда Хp - непустое множество.
Рассмотрим головоломку "Ханойская башня" . Имеются три стержня 1, 2 и 3 и три диска различных размеров А, В, С с отверстием в центре, которые могут одеваться на стержни. В исходной позиции диски находятся на стержне 1; самый большой диск С - внизу, самый маленький диск А - наверху. Требуется перенести все диски на стержень 3, перемещая за один раз только один диск. Брать можно только самый верхний диск на стержне, причем его нельзя класть на диск, меньший по размерам. Используем для записи состояний и операторов классическую формализацию.
Выражение ijk обозначает конфигурацию, при которой диск С находится на стержне i, диск В - на стержне j и диск А-на стержне k.
Выражение xij обозначает действие, при котором диск х перемещается со стержня i на стержень j.
С помощью этого формализма можно просто записать все состояния и переходы головоломки в виде треугольного графа, где вершины соответствуют расположению дисков на стержнях, а дуги соответствуют возможным перекладываниям дисков (рис.1). На этой головоломке легко проиллюстрировать все основные понятия обобщенной стратегии проблем.
Рассмотрим решение проблемы с использованием формализма xij :
А13, В12, А32,С13,А21, В23, А13.
Очевидно, что это решение не единственно и имеется конечное множество решений обозначенной проблемы.
Представим головоломку в виде модели проблемы R = (B, G, P0, T), где B={Р0, P1,..., P9}; G={g}; T={L1,L2,L3}. SS - проблемы Р0,P1...,P9 определяются следующим образом:
P0=(S, G, 111, 333), P1=(S, G, 111, 122), P2=(S, G, 122, 322),
Р3=(S, G, 322, 333), P4=(S, G, 111, 113), P5 =(S, G, 113, 123),
P6==(S, G, 123, 122), P7=(S, G, 322, 321), P8=(S, G, 321, 331),
P9=(S G, 331,333).
Проблемы Р2 и P4 - P9 решаются перекладыванием одного диска и являются элементарными. Проблемы P1 и Р3 решаются с помощью манипуляций только с дисками В и А и являются более простыми, чем Р0. Проблемы P1 и Р3 решаются, а проблема Р0 сводится к P1, P2 и Р3 аналогичной манипуляцией с дисками, синтаксис которой выражен оператором g, а семантика - отображением Y.
Приведенные определения обобщаются на нечеткий случай, когда состояние системы, для которой строится модель решения проблемы, не является точно заданным, а результаты действий системы неоднозначны.
Например, у робототехнической системы это может быть связано с несовершенством рецепторов, с ограниченными размерами внутренней модели, не отражающей сложности окружающего мира.
Построить решение нечеткой PR - проблемы по a - решениям ее нечетких подпроблем можно лишь в частных случаях и при наложении дополнительных условий.
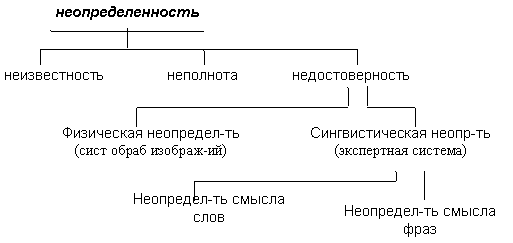
7. Определение неопределенности в экспертных системах
 | ||
 | ||
| ||
|
В экспертных системах используются следующие способы определения неопределенности, заданной на схеме 4:
· с помощью вероятностных характеристик;
· с помощью понятий логической необходимости и логической достаточности, которые связываются с вероятностными характеристиками;
· определение неопределенности на основе мощности правил, которая определяется с помощью коэффициентов уверенности;
· использование переменных неопределенности;
· использование лингвистических переменных.
Рассмотрим подробнее.
1. Для каждого утверждения, которая участвует в правиле логического вывода, задается вероятность подтверждения факта, которая лежит в пределе от 0 до 1. Например (для факта):
металлург (Х, 0.5) & мужчина (Х, 0.75)
учитель (Х, 0.5) & женщина (Х, 0.5)
2. Логическая достаточность LS и логическая необходимость LS определяют мощность правила на основе вероятностных характеристик суждения и гипотезы. Например (правило):
если идет снег, то холодно
суждение гипотеза
Е Н
Р(снег)=СХ (вероятность того, что идет снег - это будет Снег и Холодно)
Р(холод)=СНХ (Снег, но не Холодно)
Р(холод/снег)=НХС (не Холодно, Снег)
Р(снег/холод)=НСНХ (не Снег, не Холодно)
СХ+СНХ+НХС+НСНХ=1
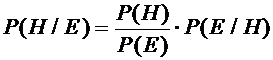 - формула Байеса
- формула Байеса
Таким образом, логическая достаточность
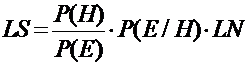
|
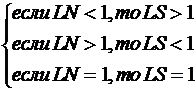
3. Коэфициент уверенности присваивается каждому факту в правиле для определения мощности правила в целом. Если факты в правиле связаны союзом И, то мощность правила будет определяться мощностью самого слабого звена правила, умноженного на мощность фактов данного уровня. Если факты в правиле связаны союзом ИЛИ, то мощность правила определяется на основе произведения мощности самого важного факта цепочки на коэфициент уверенности уровня. Например:
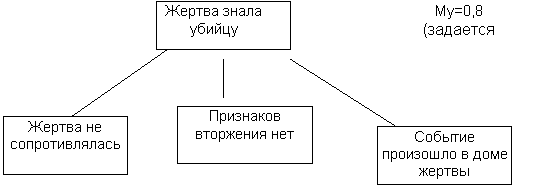 |
Мп=0,7 * Мур=0,7*0,8+0,56 - мощность всего правила.
4. Переменные неопределенности задаются следующим котрежом: Хн<b, Х,С>
b - имя переменной неопределенности;
Х - область определения переменной неопределенности;
С - ограничение на область определения переменной неопределенности.
Пример:
b - расстояние;
Х - далеко (близко, рядом);
С - те значения, которые не могут принимать переменные (где они не используются).
5. Лингвинстические переменные задаются следующем кортежом: Хл<b, a,Х, S,T>
b - имя переменной;
a - значение, которое может принимать лингвистическая переменная из области Х;
S - лингвистическая процедура использования переменной;
Т - семантическая процедура, определяющая использование лингвистической переменной.
8. Инструментальные средства проектирования экспертных систем
8.1. Инструментальные средства для разработки экспертных систем
Инструментальные средства для разработки экспертных систем делятся на три группы:
1) традиционные языки программирования, в том числе языки высокого уровня, объектно-ориентированные и функциональные;
2) пустые оболочки или среды для разработки экспертных систем. Каждая пустая оболочка включает встроенные языки или язык, определяющие взаимодействие с традиционными языками программирования. Каждая оболочка включает собственный язык организации и манипулирования знаний, таких средств внутри тоже может быть несколько.
3) специализированные системы искусственного интеллекта, содержащие программное ядро, которое позволяет менять ориентацию системы на область экспертных систем.
Экспертные системы по виду классифицируются:
· динамические экспертные системы - системы, предназначенные для решения задач анализа и синтеза в реальном времени; система принятия решений относится к экспертной системе данного вида.
· статические экспертные системы - системы, предназначенные для решения задач анализа в реальном времени и решения задач синтеза с разделением времени.
Типы экспертных систем:
· Экспериментальный прототип. Система ориентированна на правила общего вида релевантных решаемой задачи; количество правил должно быть меньше 50-ти (частный случай от 5 до 15). Система работает неустойчиво, время на разработку менее двух месяцев.
· Прмышленный образец. Среднее количество используемых правил в таких системах не более 50-ти (частный случай от 20 до 50). Правила общего вида и частные правила. Для доводки системы до экспертного образца требуется от 3 до 5 месяцев. Система работает стабильно на частных правилах.
· Прмышленная система. Стабильно работающая система, содержащая не менее 100 правил общего и частного вида; для разработки системы требуется от 10 до12 месяцев.
· Коммерческая система. Стабиль работающая система, использующая более 100 правил общего характера, используемая в конкретной области человеческой деятельности и предназначенная для продажи. На разработку, отладку и тестирование системы требуется не менее 1,5-2 лет.
Классификация по используемой технологии принятия решений:
1. Поверхностный подход.
Используемые правила общего характера, релевантные в предметной области. Правила получены только от эксперта в виде эвристик. Поиск решения индуктивным методом.
2. Структурный подход.
Технология использования правила общего и частного вида принятия решений на основе поиска по дереву решения или по специальному механизму (стратегия принятия решений).
3. Глубинный подход.
В данных технологиях проблемная область систематизированна с учетом модели представления знаний. Правила общего и частного вида формируются, исходя из используемой модели, состояния предметной области и рекомендации экспертов.
4. Совмещенные технологии.
Сочетание всех трех перечисленных выше.
8.2. Классификация оболочек экспертной системы
Тип 1. Статическая оболочка, то есть предназначена для решения статических задач.
n Используемая технология - поверхностная;
n типы использования правил - только общие;
n поиск решения от цели к данным;
n для приняти решений используется индуктивный подход на основе текущих данных;
n решаемые задачи - только задачи анализа.
Пример: Clas
Элис
Решения получаются на основе правил, заданных по имеющемся в системе шаблону.
Тип 2. Статические оболочки, предназначенные для решения задач анализа и синтеза с разделением времени.
n Используемые технологии - поверхностный, глубинный, структурный подходы;
n поиск решений - на основе правил, представленных в среде оболочки. Для работы с правилами используются функции;
n поиск решений - от цели к данным, а так же от данных к цели; поиск решений вглубь и вширь.
Пример: KAPPA;
Nexpert;
ADC;
Тип 3. Оболочки для пректирования динамических систем.
n Используемая технология - поверхностный подход. Отсутствие системы моделирования;
n принятие решения - на основе правил общего вида. Возможность использования для стстических задач.
Пример: Frame work;
Тип 4. Оболочки для разработки динамических систем.
n Решение задач анализа и синтеза в реальном времени;
n тип технологии - смешанный;
n используемые правила общего и частного вида; наличие системы моделирования, приближенной к имитационному моделированию.
Наличие планировщика решений, который повышает эффективность работы системы за счет совокупности имеющихся на текущий момент известных решений.
Много включающих инструментальных средств.
Пример: G2;
Rethink (на основе G2);
RkWorks.
Системы нечеткой логики
Одной из задач определения неопределенности в системах искусственного интеллекта является использование нечетких переменных (элементов нечеткой логики) – fuzzy logic.
Алгоритмы нечеткой логики реализуют использование нечетких переменных в нечетких подмножествах нечетких множеств.
Если представить, что S- нечеткое множество, то P – нечеткое подмножество. P определяет степень вхождения значений нечетких переменых в нечеткое множество S.
Необходимо предусмотреть реализацию правила логического вывода. Любое правило состоит из двух частей:
если …, то …
1) если … - левая часть правила
2) то … - правая часть правила
В структуре логического вывода эти правила образуют цепочки. Степень вхождения нечеткой переменной в нечеткое множество определяется на основе суперпозиций степеней вхождения левой и правой частей правила. В дальнейшм происходит сколяризации данных до четкого реального значения. Т. о. алгоритм нечеткой логики реализует четыре основных задачи:
1) Определение степени вхождения заданного параметра в нечеткое подмножество по левой части правил логического вывода с использованием функции вхождения. Наиболее часто определение функций вхождения осуществляется с использованием трех интервалов – минимальное, среднее, высокое.
2) Определение функции вхождения при той же минимальной, средней, высокой градации функции вхождения для правых частей правил логического вывода.
3) Суперпозиция левых и правых частей правил. Задается определенная цена и модифицируется функция вхождения левой части правила.
Скаляризация – получение реальных значений.
ПРИМЕР: скорость вращения вентилятора.
Если температура в помещении больше 20° С, то скорость вращения вентилятора – выше. Если температура в помещении меньше 20° С, то скорость вращения – ниже.
Нечеткое множество:
t - 12, 20, 30, 60.
U – 200, 400, 600, 1000.
1) Определение степени вхождения заданного параметра в нечеткое подмножество по левой части правил логического вывода с использованием функции вхождения.
Определим функцию вхождения ![]()
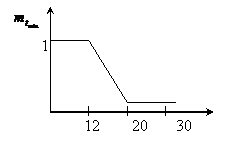 |
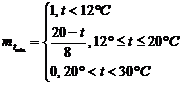
Определим функцию вхождения ![]()
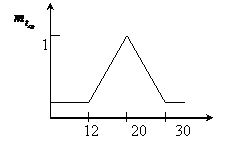
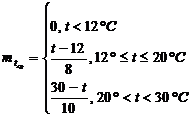
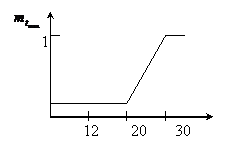 Определим функцию вхождения
Определим функцию вхождения ![]()
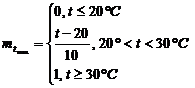
2) Определение степени вхождения заданного параметра в нечеткое подмножество по правой части правил логического вывода с использованием функции вхождения.
Определим функцию вхождения ![]()
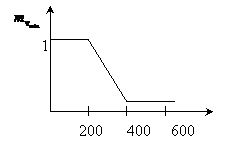 |
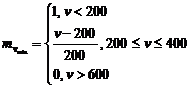
Определим функцию вхождения ![]()
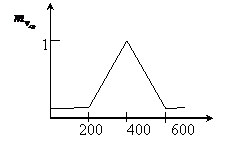
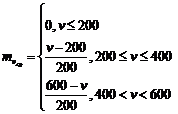
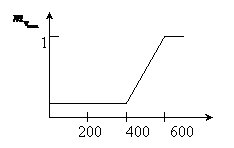 Определим функцию вхождения
Определим функцию вхождения ![]()
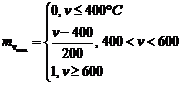
2) Суперпозиция левых и правых частей правил.
В данном случае определяем значения функции вхождения на графиках в левой части правил для конкретного значения:
![]()
![]()
![]()
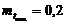
Суперпозиция заключается в изменении границы функции вхождения на графиках правых и левых частей правила.
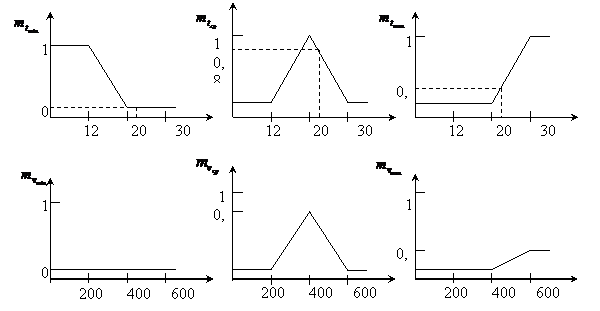 |
3) Сколяризация – определение суммарной величины функции вхождения путем объединения полученных на 3-м этапе графиков и нахождение центра тяжести графика.
 |
Центр тяжести графика будет определять скорость вращения вентилятора при температуре 22°С.
Получаем суммарный график.
9. Нейросетевые технологии
9.1. Искусственный нейрон
Основной моделью нейросетевой технологии является искусственный нейрон. Простой искусственный нейрон характеризуется совокупностью входов и выходов. Моделирование различных ситуаций на основе ярусов или ступеней искусственных нейронов приводит к идентификации на выходе данного явления.
Искусственный нейрон представлен на логическом уровне в бинарном виде в совокупности используемых пространств с помощью серых и белых шаров. Подобное моделирование используется в задачах обработки естественного языка, распознавания образов, аппроксимации функций, решение задач прогнозирования, планирования, в аналитической обработки запросов к хранилищам баз данных.
Искусственный нейрон j определяется теорией нейросетей, количеством входов ![]() {i=1,2}, весом входов
{i=1,2}, весом входов ![]() функцией состояния нейронов сети
функцией состояния нейронов сети ![]() и функцией активации нейронов при решении задачи f(
и функцией активации нейронов при решении задачи f(![]() ) = y.
) = y.
Различают 5 основных функций активации:
1. Пороговая линейная функция:
у = 0, при a<1, где a-порог функции
y = 1, при a³1 с учетом функции состояния нейронов сети ![]() .
.
2. Ступенчатая линейная функция:
у = 0, при S<a,
y = aS + b, при ![]() £ S £
£ S £![]() ,
,
у = 1, при S ³![]() .
.
3. Линейная функция:
y = kS + b, где k-множитель.
4. Функция Гауссиана:
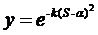
5. Сигмоидальная функция:
![]()
Парадигма нейронной сети определяется структурой нейронной сети (НС) и алгоритмом обучения сети. НС могут быть обучаемые и конструируемые. Для конструируемой сети в парадигму входит набор (или библиотека) образцов функционирования сети. А если сеть обучаемая, то строятся алгоритмы.
Различают одно-, двух - и n-уровневые нейронные сети.
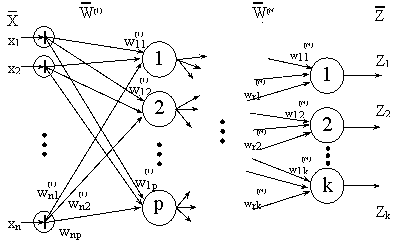 |
Для решения поставленной задачи вводятся ассоциации НС с разделением в различных пространствах белых и серых шаров. Простой персептрон, т. е.
одноуровневая двухвходная сеть не может решить поставленной задачи. Поэтому для решения задач используются 2-х и многоуровневые нейронные сети.
9.2. Пакеты для использования НС технологий
На практике реально нет смысла использовать НС технологии, они применяются только в научных целях. Реализовывать нейросетевые алгоритмы на языках высокого уровня тоже не целесообразно. Гораздо эффективнее использовать существующие пакеты, которые включают решения всех реализуемых сетью задач.
Например: BrainMaker и AITM, включающий 3 технологии-
- Neuro Shell II
- Neuro Windows
- Hyper Logic.
Для решения задачи на основе использования нейросетевых технологий необходимо:
· хорошо знать предметную область,
· иметь представление о функциях НС,
· хорошо изучить пакет, использующий нейросетевую технологию.
Последовательность обработки информации с помощью нейронных сетей:
· Сбор исходных данных.
· Создание упорядоченных последовательностей на основе выделенных исходных данных.
· Определение закономерностей в изменении совокупности параметров:
- для текущих значений;
- для текущих значений со сдвигом на один шаг;
- определение периодичности повторяющихся событий.
Совокупность выделенных закономерностей является примерами, на которых обучается сеть. Тестирование сети предусматривает задание исходных параметров, проведения их по сети (по совокупности скрытых слоев) и получения на выходе правильных и неправильных результатов. Если неправильных ответов > 50 % от общего числа полученных ответов, то сеть обучена плохо. В этом случае следует переобучить или переконструировать сеть.
Если сеть обучена хорошо (т. е. правильных ответов>50 %) подавать на входы исходные данные по решаемой проблеме с учетом корректировки результата на указанный процент.
Пример: Совокупность подсистем Brain Maker включает подсистему Net Maker, работающую с нейросетевыми технологиями. Поставлена задача: требуется получить прогноз о среднегодовой температуре в Москве на 2002 год.
Необходимо:
1. в любом текстовом редакторе подготовить исходные данные, включающие год, среднегодовую температуру в данном году и совокупность сопутствующих факторов (влажность, атмосферное давление и т. д.). Данные в текстовом файле формируются по столбцам.
2. Организовать считывание текстового файла с расширением *.dat в Net Maker. Файл считывается по столбцам и формируются графики закономерностей появления событий в указанных годах по совокупности данных и сопутствующих им факторам. По оси Y откладывается мощность события, по оси X – конкретное значение.
3. Организовать сдвиг параметров среднегодовой температуры в столбцах на 1 шаг вверх или вниз, чтобы получить новое значение температуры. Построить графики закономерности для данных со сдвигом. Выполнить поиск закономерностей на основе указанных входных значений. Это и является обучением сети на совокупности примеров.
4. Выполнить тестирование сети: задав заведомо правильные значения по годам, на выходе сети получаем процент правильных и неправильных значений.
5. Получить результаты: ввод реальных значений по годам.
10. Генетические алгоритмы
Технология, используемая для получения вероятностной или локально-оптимальной характеристики целевой функции. При реализации генетических алгоритмов моделируются эволюция происхождения событий, подобно живой природе. Алгоритмы данной группы не дают оптимального результата, однако имеют удовлетворительную сходимость.
10.1. Основные понятия теории генетических алгоритмов
Фенотип – формат кодирования информации по решаемой проблеме.
Генотип – единица информации кода (особь).
Операции генетического алгоритма:
· селекция – создание родительской популяции;
· операция скрещивания (операция Кроссенговера) – модификация кода особей
родителей;
· операция мутации – внесение случайным образом или на основе заданного закона изменение в один из разрядов на заданную долю величины от единицы и в сторону уменьшения;
· получение потомков – значение функции оптимизации, для которых является
приближенной к оптимальному значению.
Вероятность мутации. Определяется как частное от деления вероятности значения целевой функции для i-ой особи на сумму вероятностей всей популяции.
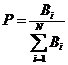
Целевая функция для особи резервируется в зависимости от решаемой задачи.
Популяция – совокупность родительских особей, участвующих в селекции.
Элитизм – передача родительских особей в фонд скрещивания с потомками.
ПРИМЕР:
1 | 2 | 3 | 4 | 5 | |
1 | 0 | 4 | 6 | 2 | 9 |
2 | 4 | 0 | 3 | 2 | 9 |
3 | 6 | 3 | 0 | 5 | 9 |
4 | 2 | 2 | 5 | 0 | 8 |
5 | 9 | 9 | 9 | 8 | 0 |
Кодирование информации осуществляется только на начальном этапе (операция эволюции выполняется только с кодом). Предположим, что этап селекции был выполнен, соответственно выполнение этапа определяется генотипом особей:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
