

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
УДК 004.421.2
Моделирование распределениЯ нагрузки в кластерной системЕ СЕРВЕРОВ DNS НА ОСНОВЕ ИСПОЛЬЗОВАНИЯ распределенной хеш-таблицы
, ,
Воронежский государственный университет
Воронеж, Университетская площадь, 1
*****@***ru
Статья посвящена моделированию распределения нагрузки на узлы в DNS-кластере. Рассматривается метод построения подсистемы распределения нагрузки, основанный на распределенной хеш-таблице (Distributed Hash Table, DHT). Дается детальное описание принципов построения указанной подсистемы и приводятся численные результаты кластерных измерений.
Ключевые слова: кластер DNS, хеш-таблица, распределение нагрузки, система доменных имен
При обеспечении эффективного функционирования кластерной системы возникают проблемы распределения нагрузки на его узлы, а также выбора конкретного узла для обработки информации.
В данной работе рассматривается кластерная система DNS со следующими свойствами. Каждый узел кластера должен являться точкой входа в кластер. При поступлении запроса на какой-либо узел кластера, узел сам должен определить, обработать ли ему поступивший запрос, или же передать его на обработку какому-либо другому узлу, и, дождавшись результата обработки, отправить его в ответ на первоначальный запрос. Вследствие того, что каждый узел кластера должен получить примерно одинаковое количество запросов на обработку, возникает необходимость балансировки нагрузки в кластере. Такая балансировка должна происходить с учетом особенностей системы DNS. Отметим, что каждый DNS-сервер содержит кэш DNS-записей. При поступлении запроса на разрешение домена сервер сначала ищет соответствующую запись в своем кэше, и, если находит, то сразу дает ответ запрашиваемому клиенту, иначе он начинает запрашивать вышестоящие серверы DNS, возвращаемые ответы этот сервер кэширует и возвращает клиенту. При следующем запросе этого домена на сервере уже будет содержаться соответствующая запись и он сразу же вернет ответ клиенту. Каждый узел кластера представляет собой DNS-сервер со своим отдельным кэшем, и если узел будет обслуживать только определенные домены, то он будет максимально использовать свой кэш и редко обращаться к вышестоящим серверам, что крайне положительно скажется на производительности каждого узла – в частности, и кластера в целом. Т. е. система распределения нагрузки должна не просто равномерно распределять запросы среди узлов кластера, но и ретранслировать запросы с определенными доменами конкретным узлам кластера.
Из вышесказанного вытекают требования к масштабируемости кластера. При выходе узла из системы запросы с доменами, которые он должен обслуживать, необходимо равномерно перераспределить между оставшимися узлами, а при обратном его входе в систему он должен «вернуть» себе именно эту часть запросов и в дальнейшем их обслуживать.
Для решения поставленных проблем может использоваться инфраструктура распределенной хеш-таблицы. Основной ее задачей является выбор узла для обработки запрашиваемых данных. Выбор должен производиться таким образом, чтобы обеспечить равномерное распределение нагрузки на узлы кластера. Реализуемая система DHT должна также обеспечить масштабируемость кластера и корректным образом обрабатывать вход и выход узлов из системы.
Распределенная хеш-таблица (Distributed Hash Table, DHT) –это инфраструктура, которая может быть использована для построения многих комплексных сервисов, таких как распределенные файловые системы, пиринговое распространение файлов и системы распространения контента, кооперативный web-кэш, многоадресная доставка (multicast), anycast, сервисы доменных имен, системы мгновенных сообщений и т. д. Основная задача DHT состоит в отображении хеш-значения, полученного от определенного параметра (в нашем случае – это запрашиваемый домен), в узел системы.
Базовым механизмом DHT является механизм консистентного хеширования (consistent hashing), который при переконфигурировании кластера сохраняет положение ключей относительно узлов. Основная идея данного подхода состоит в следующем: все пространство значений используемой хеш-функции (например, в случае 64-х битной хеш-функции область ее значений будет составлять отрезок [0, 264]) представляется в виде кольца, в котором пространство «склеивается» в своем максимальном и минимальном значениях (0 и 264). Каждому узлу ставится в соответствие идентификатор – число в пределах пространства хеш-функции. Таким образом, каждый узел получает некоторое положение на кольце. Ключевым моментом здесь является то, что между идентификатором узла и ключом, получающемся в результате вычисления хеш-функции от нужного значения, нет никакой принципиальной разницы. Два соседних узла на кольце образуют область, за которую отвечает один из них (с бóльшим или меньшим идентификатором). Каждый элемент данных идентифицируется ключом (путем вычисления хеш-функции) и получает некоторую позицию на кольце. Далее по кольцу ищется первый встретившийся по (или против) часовой стрелке идентификатор узла. Таким образом элемент данных связывается с определенным узлом (см. рис. 1).
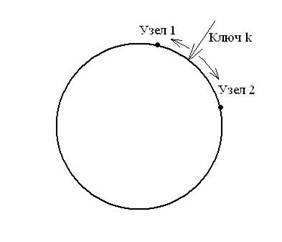
Рис. 1. Отображение элемента данных в узел кластера посредством ключа k.
В нашем конкретном случае элемент данных – запрашиваемый домен.
Основным вопросом при реализации DHT является схема разбиения пространства ключей между участниками кластера.
Самый простой способ деления пространства – равномерно разделить его на части, соответствующие числу узлов, и каждому узлу назначить свою часть. Однако данный подход имеет ряд недостатков: при выходе узла область его ответственности, практически, полностью перейдет только одному узлу, также и при входе, никаким образом не учитывается неравномерность распределения получаемых хеш-значений и т. д. Содержание кэша каждого узла полностью зависит от того, за какую часть пространства отвечает узел. Соответственно, если после изменения состава участников кластера пространство ответственности узла претерпит существенные изменения, то большая часть его кэша станет неактуальной и при подавляющем большинстве запросов узел, определив, что в кэше не содержится запрашиваемых данных, будет для разрешения домена обращаться к вышестоящим серверам, производить рекурсивные запросы, дожидаться ответов и т. д. Все это отрицательно скажется на производительности кластера.
Следовательно, если представить вышеозначенную проблему графически (см. рис.2), то для каждого узла необходимо добиться максимального пересечения его пространства до изменения состава участников кластера, и его пространства после такого изменения.

Рис. 2. Пересечение пространств узлов до и после изменения состава участников кластера в линейном представлении (верхняя и нижняя горизонтальные линии – хеш-пространство, разделенное между узлами 0, 1, 2 и т. д.).
Ситуация выхода узла под номером 4 из кластера, состоящего из узлов 0, 1, 2 и т. д., отображена на рис. 2 в линейном представлении (для удобства восприятия). Как видно и рисунка, размеры пересечения пространств для каждого узла сильно различаются. Наибольшее пересечение получается для узла 0, большая часть его кэша останется актуальной и, таким образом, изменение состава участников кластера не сильно повлияет на изменение скорости его работы. Однако этого нельзя сказать про другие узлы. Высвободившийся участок вышедшего узла 4 полностью перешел только одному узлу под номером 3, причем этому узлу придется, практически, полностью обновить свой кэш, что существенно скажется на времени. Меньше всего обновлять свой кэш придется узлу 0, узлу 1 – уже больше и т. д. по нарастающей. В итоге получается большая неравномерность в перераспределении освободившегося пространства. Следовательно, нужно использовать более гибкий способ разделения пространства.
После проведенных исследований и расчетов, нами была реализована следующая концепция распределения области значений хеш-функции. В данной системе используется хеш-функция, вычисляющая 64-битный ключ. Таким образом, мы имеем пространство ключей размером 264. Все пространство разбивается на 232 одинаковые части, которые будем называть «чанками». В свою очередь каждый чанк в равных частях делится на количество «живых» узлов кластера.
Для того чтобы при выходе узла из состава кластера его участки не переходили одним и тем же соседним узлам, порядок следования отрезков ответственности узлов должен быть неодинаковым (для равномерности перераспределения запросов при выходе узла из системы). Но при этом, например, для 10 узлов существует 10 (!) вариантов перестановок, что сложно для вычисления, хранения и поиска искомого узла, что в конечном итоге критично сказывается на скорости работы системы. Это решение также, практически, не масштабируется и имеет «плохое поведение» при изменении состава кластера, т. к. в каждом чанке порядок следования отрезков ответственности узлов не должен меняться при выходе или входе узла, что очень сложно поддерживать при таком решении. Поэтому было решено ввести 512 вариантов распределения узлов, где каждый вариант распределения соответствует одному чанку, и хранить их в таблице. Т. к. вариантов распределения значительно меньше, чем чанков (512 и 232), то варианты распределения повторяются циклически: первому чанку соответствует первый вариант, второму чанку – второй вариант, 512-му – 512-ый, 513-му чанку – первый вариант и т. д. Такое количество вариантов распределения было получено экспериментальным образом, исходя из равномерности распределения запросов: до 512 – наблюдалось улучшение показателей равномерности, более 512 – показатели практически не изменялись. Варианты распределения вычисляются с помощью собственно реализованной функции генерации псевдослучайных чисел (назовем ее dht_rand ( )), чтобы исключить различия в её библиотечных реализациях и обеспечить одинаковое поведение на платформах с различной разрядностью.
Алгоритм построения варианта распределения состоит в следующем. Для начала создается временная таблица, полями которой являются IP узла и соответствующее хеш-значение, полученное с помощью функции dht_rand ( ). Далее для каждого узла генерируются хеш-значения на основании комбинации IP-адреса и номера варианта распределения, полученное значение и соответствующий IP-адрес записываются во временную таблицу. После того, как хеш-значения получены для каждого IP, таблица сортируется по хеш-значениям в порядке возрастания (см. рис. 3).

Рис. 3. Показатели эффективности для пяти узлов кластера.
Полученный порядок следования IP-адресов и является вариантом распределения. Далее эти действия повторяются для следующего варианта. В конечном итоге мы получаем таблицу размерностью 512 x N, где N – количество узлов, в соответствии с которой строится функция отображения ключей в узлы. При изменении состава участников кластера все действия повторяются и таблица обновляется, причем обновление DHT на каждом из узлов происходит «налету», т. е. без остановки кластера.
Алгоритм отображения состоит в следующем. Для начала от запрашиваемого домена считается хеш-сумма, полученный ключ является входным параметром алгоритма. Далее, зная количество чанков и, соответственно, их размер, находится номер чанка, в который попал ключ, и соответствующий ему вариант распределения. После этого, зная размеры областей ответственности узлов, по таблице распределения определяется узел, который должен обработать пришедший запрос.
В ходе тестирования системы распределения нагрузки за основу были взяты реальные данные – 5∙106 уникальных доменов из запросов, принятых за две недели работы системой DNS. Тестовые запуски проводились для различного количества узлов кластера: два, три, пять и десять узлов. В каждом из тестов к системе были обращены 5∙106 запросов с собранными уникальными доменами.
На рис. 4 представлены результаты проведенных тестов для пяти узлов в кластере, где эффективность распределения нагрузки определяется как отношение среднего числа запросов, обслуживаемых каждым узлом, к максимальному количеству запросов, принятых самым нагруженным узлом. По горизонтали обозначено различное количество запросов к системе с шагом 106, по вертикали – эффективность как отношение средней нагрузки к максимальной нагрузке. Как видно из представленного графика, каждый узел системы получает, практически, одинаковое количество запросов. Расчеты показывают, что отклонение составляет в среднем около 0.07% (для запросов с уникальными доменами).
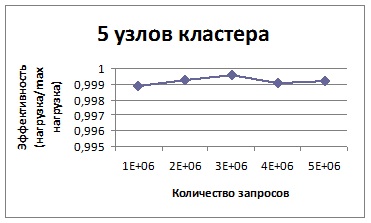
Рис. 4. Показатели эффективности для пяти узлов кластера.
В заключение можно сказать, что в ходе проведенной работы была полностью реализована инфраструктура распределенной хеш-таблицы, обслуживающая кластер DNS.
Разработка данной системы производилась в несколько этапов:
• анализ проблемы и технического задания, изучение теоретического материала, касающегося распределенных хеш-таблиц и их реализации;
• рассмотрение существующих решений и реализаций, анализ возможности их частичного применения;
• разработка общей архитектуры системы;
• подбор хеш-функции нужной разрядности и исследование ее характеристик;
• моделирование информационных процессов;
• непосредственная реализация системы: использование функций инициализации и деинициализации системы, построение внутренних структур данных и алгоритмов их корректировки при изменении состава участников кластера, применение функции вычисления узлов для обработки и репликации, организация взаимодействия с внешними системами, обслуживающими кластер;
• тестирование системы и оценка её эффективности.
В целом, представленная система DHT обладает высокими показателями распределения нагрузки, надежности, быстродействия, гибкости поведения при изменении состава участников кластера. В ней также реализован механизм репликации DNS-записей.
Литература
1. De Candia G., Hastorun D., Jampani M. et al. Dynamo: Amazon’s Highly Available Key-value Store // Proc. of the 21st ACM Symposium on Operating Systems Principles “SOSP '07”. – ACM Press, NY, 2007. – P. 205-218.
2. Fox A., Gribble S. D., Chawathe Y. et al. Cluster-based scalable network services // Proc. of the Sixteenth ACM Symposium on Operating Systems Principles “SOSP '97”. – ACM Press, NY, 1997. – P.78-91.
3. Karger D., Lehman E., Leighton T. et al. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web // Proc. of the Twenty-Ninth Annual ACM Symposium on theory of Computing “STOC '97”. – ACM Press, NY, 1997. – P.654-663.
4. Ghodsi Ali. Distributed k-ary System: Algorithms for Distributed Hash Tables // KTH-Royal Institute of Technology, 2006. – P. 23-40.
5. Zhao B. Y., Huang Ling, Stribling J. et al. Tapestry: A Resilient Global-Scale Overlay for Service Deployment // IEEE Journ. On Selected Areas In Communication. – 2004. – V. 22, № 1. – P.41-48.
LOAD DISTRIBUTION MODELING IN CLUSTER SYSTEMS OF DNS SERVERS ON THE BASIS OF USAGE OF THE DISTRIBUTED HASH TABLE
S. N. Shilov, S. D. Kurgalin, A. A. Krylovetsky
Voronezh State University
Voronezh, Universitetskaya pl.,1
*****@***ru
This article is devoted to a load distribution modeling on clusters in DNS cluster. Within article the method of creation of a subsystem of the load distribution, based on the distributed hash table (DHT) is considered. Article provides the detailed description of the principles of creation of the specified subsystem and numerical results of cluster measurements.
Key words: cluster DNS, hash table, load distribution, domain name system
