
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рандомизация неопределенности исходных данных при анализе угрозообразующего поведения[1]
, н. с. лаборатории ТиМПИ СПИИРАН, *****@***spb. su
, м. н.с. лаборатории ТиМПИ СПИИРАН, аспирант кафедры информатики СПбГУ, *****@***ru
, зав. лаборатории ТиМПИ СПИИРАН, профессор кафедры информатики СПбГУ, *****@***spb. su
, с. н.с. лаборатории ТиМПИ СПИИРАН, доцент кафедры информатики СПбГУ, *****@***ru
Аннотация
В докладе представлена процедура рандомизации неопределенности ответа, позволяющая обработать особенности естественно-языковых формулировок ответов о последних эпизодах угрозообразующего поведения.
Разработан программный комплекс, реализующий данную процедуру и позволяющий проводить вычислительные эксперименты с разными значениями параметров.
Введение
В связи с задачами своевременного обнаружения изменений в поведении отдельных индивидов и групп, науки социогуманитарного цикла испытывают потребность в математических моделях и алгоритмах, которые бы позволили получать оценки интенсивности угрозообразующего (то есть приводящего к возникновению угрозы) поведения. В качестве примера можно привести угрозообразующее поведение пользователя информационной системы, которое может привести к раскрытию критичной информации [1]. При этом существующие методы прямого измерения интенсивности (круглосуточный мониторинг, дневниковый метод, длительное сопровождение когорты индивидов и пр.) часто не применимы из-за их дороговизны, а также из-за ряда проблем этического характера.
Отметим, что наиболее доступными исходными данными для анализа поведения выступают самоотчеты респондентов об их поведении, то есть ответы в анкете на блок вопросов или результаты проведения интервью. На данный момент разработаны и применяются в опросах два подхода к оцениванию интенсивности поведения: прямые вопросы и Лайкерт-шкалы — каждый из которых имеет недостатки [2]. Одной из возможных альтернатив представляется опрос респондента о нескольких последних эпизодах его поведения (рисунок 1). Однако ограниченное число и неточность, фактически, нечеткость естественно-языковых формулировок ответов (например, «на прошлой неделе») требуют новых методов для обработки таких данных и получения количественной оценки интенсивности угрозообразующего поведения.
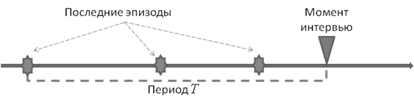
Рисунок 1: Последние эпизоды поведения.
В результате все более актуальной становится междисциплинарная фундаментальная научная проблема — развитие методологии поиска, представления, агрегирования и обработки данных и знаний (полученных из самоотчетов респондентов) в условиях информационного дефицита для последующего формирования и расчета косвенных оценок интенсивности социально-значимого поведения. Эта проблема требует развития моделей и алгоритмов в рамках специфических математических и компьютерных дисциплин: теории принятия решений, искусственного интеллекта, мягких вычислений, теории вероятностей и математической статистики.
Цель данного доклада — описать подход в обработке особенностей естественно-языковых формулировок ответов о последних эпизодах угрозообразующего поведения.
Рандомизация ответов
Ответы на вопросы об эпизодах поведения поступают на естественном языке, т. е. являются в значительной степени нечеткими и неполными. Отметим, что респонденты используют в своих высказываниях разные единицы измерения: часы, дни, недели, месяцы, полугода, года. Причем использованная единица измерения несет в себе информацию о точности измерения. Поясним это на примере двух, на первый взгляд равнозначных, высказываний: «семь дней назад» и «неделю назад». Когда респондент использует формулировку «семь дней назад», это свидетельствует о его уверенности в том, что событие произошло именно семь дней назад. В то время как «неделю назад» — это может быть и пять, и восемь дней назад.
Для учета указанной неточности каждый ответ рассматривается не как точка на временной оси, а как интервал, длина которого зависит от единицы измерения (рисунок 2). Значение каждого ответа рассматривается, таким образом, не как константа, а как случайная величина с заранее заданным распределением [2]. Введенная случайная величина за счет рандомизации [3] неопределенности ответа, обусловленной нечеткостью его формулировки, позволяет рассмотреть интенсивность как случайную величину и вычислить характеристики последней.
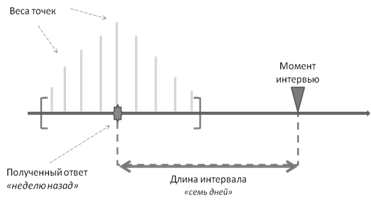
Рисунок 1: Рандомизация ответа о последнем эпизоде
Поясним более подробно. Применяя идею метода анализа и синтеза показателей при информационном дефиците Н. В. Хованова [3], получим следующую процедуру обработки естественно-языковых ответов. Пусть известны данные о ![]() последних эпизодах поведения
последних эпизодах поведения ![]() ,
, ![]() ,
, ![]() ,…,
,…, ![]() а
а ![]() ¾ общий временной промежуток, за который произошли эпизоды. Тогда интенсивность поведения
¾ общий временной промежуток, за который произошли эпизоды. Тогда интенсивность поведения ![]() оценивается по формуле:
оценивается по формуле: ![]() [4‑6].
[4‑6].
Для каждого эпизода со значением ![]() ,
, 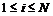 (
(![]() ¾ число рассматриваемых эпизодов поведения) через характеристику разброса
¾ число рассматриваемых эпизодов поведения) через характеристику разброса ![]() определяется интервал (возможных значений) в днях:
определяется интервал (возможных значений) в днях: ![]() , где
, где ![]() — коэффициент перевода рассматриваемой единицы измерения в дни [35]. Заметим, что любая точка из интервала
— коэффициент перевода рассматриваемой единицы измерения в дни [35]. Заметим, что любая точка из интервала 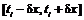 возможна в качестве значения оценки
возможна в качестве значения оценки ![]() ; что, однако, не означает, что точки из этого интервала равновероятны в качестве такого. Сведения о такого рода отношениях между допустимыми значениями можно задать с помощью их распределения вероятностей [7]. В зависимости от предположений о характере ответов респондента для задания случайной величины
; что, однако, не означает, что точки из этого интервала равновероятны в качестве такого. Сведения о такого рода отношениях между допустимыми значениями можно задать с помощью их распределения вероятностей [7]. В зависимости от предположений о характере ответов респондента для задания случайной величины ![]() оценки
оценки ![]() используется равномерное, биномиальное или какое-либо другое вероятностное распределение.
используется равномерное, биномиальное или какое-либо другое вероятностное распределение.
Введенная случайная величина ![]() за счет рандомизации [3] неопределенности ответа позволяет рассмотреть интенсивность как случайную величину и вычислить характеристики последней.
за счет рандомизации [3] неопределенности ответа позволяет рассмотреть интенсивность как случайную величину и вычислить характеристики последней.
Расчет среднего значения для случая трех последних эпизодов производится по следующей формуле:
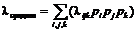 ,
,
где ![]() — вес
— вес  -ой точки из первого интервала,
-ой точки из первого интервала, ![]() — вес
— вес ![]() -ой точки из первого интервала,
-ой точки из первого интервала, ![]() — вес
— вес ![]() -ой точки из первого интервала,
-ой точки из первого интервала, ![]() — оценка интенсивности для соответствующего сочетания точек, т. е.
— оценка интенсивности для соответствующего сочетания точек, т. е. ![]() , где
, где ![]() — соответствующая точкам ,
— соответствующая точкам , ![]() ,
, ![]() оценка величины рассматриваемого интервала.
оценка величины рассматриваемого интервала.
Среднее квадратичное отклонение ![]() для рассчитываемого среднего значения:
для рассчитываемого среднего значения:
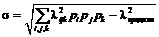 .
.
Программный комплекс
Процедуры расчета средних оценок были реализованы в программном комплексе [7], позволяющем задавать значении необходимых параметров рандомизации полученного ответа о последнем эпизоде угрозообразующего поведения. К таким параметрам относятся:
• характеристика разброса, определяющая оценку неопределенности ответа;
• число точек разбиения интервала, используемое при расчетах средней оценки интенсивности;
• вероятностное распределение, характеризующее рандомизацию — равномерное, треугольное, трапециевидное, биномиальное, бета-распределение, синусоидальное, полиномиальное, семиэллиптическое. Также имеется возможность указать параметр смещения для этих распределений;
Кроме того, можно указать алгоритм обработки неопределенности, применяющийся при расчете средней оценки интенсивности — либо на основе весов, либо на основе квантилей.
Заключение
Предложенная процедура рандомизации неопределенности ответа позволяет обработать особенности естественно-языковых формулировок ответов о последних эпизодах угрозообразующего поведения, связанные с тем, что ответ выражается в терминах «бытовой» речи, предполагающей определенную неточность ответа.
Литература
1. , , Пащенко защита как фактор уязвимости пользователя в контексте социоинженерных атак // Труды СПИИРАН. 2011. Вып. 18. С. 74–92.
2. , , Крас-носельских гранулярных данных и знаний в задачах исследования социально значимых видов поведения // Компьютерные инструменты в образовании. №4. 2010. С. 30–38.
3. Хованов и синтез показателей при информационном дефиците. СПб.: Изд-во СПбГУ, 19с.
4. , , Казакова ВИЧ-рискованного поведения в контексте психологической защиты и других адаптивных стилей. СПб.: Наука, 20с.
5. , , Николенко заражения ВИЧ-инфекцией на основе данных о последних эпизодах рискованного поведения. // Известия высших учебных заведений: Приборостроение. 2006. №8. 33–34 с.
6. , , Пащенко интенсивности поведения респондента в условиях информационного дефицита // Труды СПИИРАН. Вып. 7. СПб.: Наука, 2008. С. 239–254.
7. , Суворова комплекс для экспертного оценивания интенсивности поведения респондента в условиях дефицита информации // Интегрированные модели, мягкие вычисления, вероятностные системы и комплексы программ в искусственном интеллекте. Научно-практическая конференция студентов, аспирантов, молодых ученых и специалистов. Научные доклады. В 2-х т. Т. 2. М.: Физматлит, 2009. С. 220–241.
[1] Доклад содержит материалы исследований, частично поддержанных грантами РФФИ -а, -а, -а,
