
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Оперативный анализ данных СУБД НИКА.
,
Работа выполнена при поддержке
Российского фонда фундаментальных исследований,
Проект №
В работе рассматриваются аспекты аналитической обработки объектно-ориентированных данных на примере программы, созданной над ООБД НИКА в рамках проекта РФФИ. Выбор среза БД, объектов аналитического анализа, измерений и переменных осуществляется на схеме ООБД без предварительной загрузки многомерной БД.
В настоящий момент широко распространены OLAP-системы для реляционных баз данных. Нами была предпринята попытка построения аналитической системы для сложно структурированных данных. Система строилась над объектно-ориентированной СУБД НИКА [3].
ООБД НИКА (разработка ИСА РАН, около 100000 инсталляций) позволяет работать со сколь угодно сложными (иерархическими) объектами, имеющими произвольные (сетевые) связи. Модель данных СУБД НИКА является типово-полной, т. е. любая суперпозиция допустимых типов данных является допустимым типом. Отсутствие ограничений на структуру объектов в БД существенно облегчает процесс отображения объектов реального мира в БД: нет необходимости разбивать их на части для того, чтобы поместить в различные отношения, как это, например, требуется в реляционных СУБД.
Модель данных
Формализуем модель данных СУБД НИКА. В объектно-ориентированных СУБД структура БД может представлять собой, вообще говоря, любой граф. Произвольный граф может быть представлен в виде леса (совокупности деревьев) со ссылками. В этой работе мы будем рассматривать только БД без ссылок. Заметим, однако, что использование ссылок в программных средствах, разрабатываемых на основе изложенных здесь принципах, не только возможно, но и необходимо при выполнении некоторых основных функций. Дополним БД вершиной "Корень БД" (не описанной явно в описании БД) и дугами, соединяющими ее с корнями всех деревьев леса БД (описанными явно). После такого преобразования всякая БД без ссылок является деревом. Мы будем здесь рассматривать только такие БД с корнем.
Учитывая сделанные замечания, можно считать, что структура БД является типом в соответствии с определениями в [4]. В этой работе типом БД будем называть следующее.
Определение. Типом БД будем называть граф (V, E(V)), где V - множество вершин, E(V) Ì (V х V) - множество дуг, такой что выполняются следующие условия.
V разбивается на подмножества: V* - терминальных вершин (атрибутов или *-вершин), V# - вершин-ассоциаций (массивов или #-вершин), V@ - вершин-агрегатов (структур или @-вершин); причем V@ содержит вершину V0 - корень БД. Для всех v Î V и v ¹ V0, существует единственная дуга (v',v), входящая в v. Будем говорить, что v подчинена v'. Для V0 нет входящих дуг. Если v содержится в V*, то множество E(v)={v':(v, v') Î E(V)} подчиненных ей вершин пусто. Если v содержится в V#, то из нее исходит ровно одна дуга (v, v'), причем v' содержится в V@ и называется элементом массива v. Обозначается v'=elv. Причем в множестве E(elv) выделен один элемент, являющийся терминальной вершиной, который объявлен ключом элемента массива и обозначается keyv. Если v Î V@, то из нее исходит хотя бы одна дуга. Для всех v Î V* определено d(v) - область ее значений, совпадающая с областью значений некоторого базового типа. Для всех v Î V определено &v - имя вершины (правильное имя в некотором алфавите), причем, если v', v" подчинены одной вершине v, то &v' не равно &v".Заметим, что подмножества V*, V#, V@ не пересекаются, из (2) следует, что граф $(V, E) - дерево с корнем V0. Каждая вершина из V определяет понятие тип объекта и тем самым понятие объекта в БД, соответствующее типу. Для каждой вершины из V можно единственным образом определить тип объекта в смысле [9] следующим образом: если v - терминальная, то ее тип T(v)=&v : d(v); далее рекурсивно определяются типы для всех v из V@: T(v)=&v : {T(v1),...,T(vn)}, где v1, … ,vn составляют E(v); для всех v Î V# имеем: T(v)=&v : [T(elv)]. Типом БД в этом смысле можно считать определенный таким образом тип ее корня T(V0).
Следует отметить, что модель данных НИКА близка по идеологии к XML формату [6]. Вершины БД НИКА являются аналогами XML-элементов. Терминальные вершины в такой интерпретации можно рассматривать двояко: либо как аналог XML-элементов простого содержания, либо как аналог XML-атрибутов содержащих их элементов. Далее будем придерживаться терминологии второго подхода, т. е. объектами будем называть массивы или структуры, а атрибутами – терминальные вершины.
Отличительной чертой СУБД НИКА является автоматически поддерживаемый системой индекс [2, 5].
Задание аналитических функций
Перейдем непосредственно к описанию построения аналитических функций (определение см. ниже). Все вычисления строятся относительно объектов, таким образом, первым шагом является выбор типа объектов, для которых будет выполнена обработка. Объект может находиться на любом уровне иерархии. На основе иерархии объектов можно классифицировать атрибуты всех объектов БД по отношению к выбранному:
1. прямые (атрибуты выбранного объекта)
2. подчиненные (атрибуты подчиненных объектов)
3. наследованные (атрибуты объектов, стоящих строго выше по иерархии относительно выбранного объекта)
4. косвенные (остальные атрибуты).
В соответствии с классификацией атрибутов опишем операцию разложения выбранных объектов, по значениям фиксированного атрибута. Выберем любой атрибут произвольного объекта БД и зафиксируем его значение. Объекты выбранного типа в БД, разлагаются на два множества: соответствующие данному значению и не соответствующие. По определению объект принадлежит первому множеству, если (в соответствии с классификацией):
1. значение атрибута совпадает с указанным значением
2. среди подчиненных объектов, есть объект с указанным значением атрибута
3. значение атрибута родителя (атрибут которого выбран) совпадает с указанным значением
4. среди подчиненных объектов, первого общего родителя (такой родитель, очевидно, существует, т. к. все объекты растут от корня) есть объект с указанным значением выбранного атрибута.
Обозначим через Ma – множество значений атрибута a, дополненное «пустым элементом». Описанная выше операция разложения объектов по значениям атрибута a является отображением выбранных объектов БД на множество Ma. Не трудно заметить, что в случаях 1 и 3 отображение обладает свойством инъективности, т. е. каждый объект соответствует только одному значению атрибута. В случаях 2 и 4 один объект может соответствовать нескольким значениям атрибута. Выбрав несколько атрибутов {a1, … , an}, можно определить отображение выбранных объектов БД на декартово произведение множеств Ma1 x … x Man. Объект соответствует элементу {a1, … , an}, если он соответствует каждой компоненте.
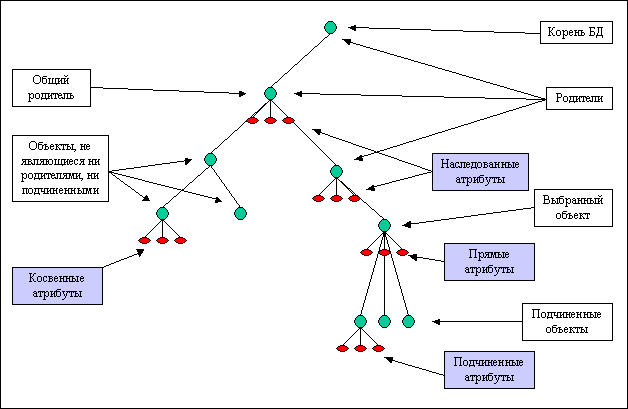
Рисунок 1. Классификация атрибутов.
Над множеством объектов фиксированного типа можно определить некоторую числовую (статистическую) функцию также как это делается в реляционных аналитических системах. При этом некоторые поля могут иметь множественное значение (случай 2 и 4 классификации). Частные примеры реализованных нами функций будут рассмотрены ниже.
Под аналитической функцией понимается отображение объектов фиксированного типа в декартово произведение множеств Ma1 x … x Man x R, где первые n измерений соответствуют разложению объектов по n атрибутам, а последнее – значению некоторой числовой функции над объектами, принадлежащими данному узлу разложения. Дополнительно на объекты выбранного типа может быть наложено ограничение – запрос [2], позволяющий анализировать не все объекты указанного типа в БД. Аналогом запроса в СУБД НИКА является понятие среза в терминологии реляционных OLAP-систем [1].
Итак, для аналитической обработки объектно-иерархических данных необходимо на первом этапе выбрать тип анализируемых объектов, при необходимости наложить ограничение (указать запрос). На втором этапе выбрать измерения, в соответствии с которыми будут разложены объекты. И на последнем этапе указать статистическую функцию (такая функция также может использовать дополнительный запрос, обрабатывая не все объекты (или атрибуты) соответствующие узлу разложения).
Реализация
Перейдем к описанию созданной нами реализации. Главное окно (диалоговое) программы предоставляет следующую функциональность. Перед началом работы пользователь должен указать (кнопка «Файлы») локальную БД НИКА (файлы данных и описания данных), с которой хочет работать. После чего автоматически запустится мастер построения аналитической функции.

Рисунок 2. Главное окно программы.
Мастер построения позволяет в порядке, соответствующем этапам построения аналитической функции, указать все параметры. В качестве примера для каждого научного сотрудника музея посчитаем количество музейных предметов, им описанных, в БД учёта музейных предметов.
Первый этап - выбор типа объекта. Программа анализирует схему БД и отображает дерево объектов. Пользователь правым щелчком мыши выбирает объект, при этом в соответствующих окнах отображается путь к объекту и его уникальный dod-номер. В нашем примере – это объект с именем «S», находящийся под массивом «ЭКСПОНАТЫ МУЗЕЯ» и идентифицируемый в массиве атрибутом «Ключ». Если просто требуется посчитать число всех объектов выбранного типа, то достаточно установить флаг «Число» и нажать кнопку «Готово», программа выполнит анализ БД и отобразит результат на экране. Иначе следует нажать кнопку «Далее» для перехода к следующему этапу.
Второй этап – выбор измерений. Реализация 2001г. поддерживает пока только одно измерение. Как и на прошлом шаге, программа анализирует схему данных и отображает дерево объектов с индексными атрибутами. В силу особенности ООБД НИКА – индекса, позволяющего быстро искать объекты с указанными значениями проиндексированных атрибутов, измерением может служить только индексный атрибут.
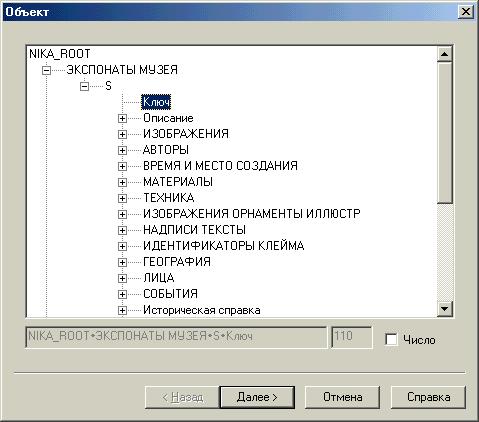
Рисунок 3. Первый этап - выбор типа объекта.
Просматривая дерево объектов с их индексными атрибутами, пользователь выбирает атрибут – измерение. В нашем примере – это атрибут «Автор описания». Кнопка «Далее» позволяет перейти к выбору следующего измерения или финальному этапу.
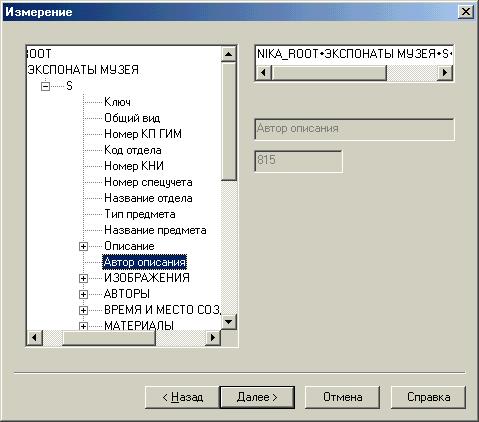
Рисунок 4. Второй этап - выбор измерения.
Третий этап – выбор статистической функции. Напомним, что мы имеем набор однотипных объектов для каждого узла измерения. В данной программе мы реализовали следующий класс статистических функций. Пользователь может дополнительно выбрать любой атрибут произвольного объекта. Тогда для каждого объекта каждого узла измерения определяется в соответствии с классификацией множество связанных атрибутов (в случаях 1 и 3 множество состоит не более чем из одного элемента). Таким образом, для каждого узла измерения мы имеем множество всех значений (возможно с повторениями) связанных атрибутов. Если атрибут не числовой можно посчитать только количество элементов. Иначе можно выбрать одну из следующих функций над множеством значений связанных атрибутов: количество, минимум, максимум, среднее арифметическое или сумма. Мы получим для каждого узла измерения число – значение статистической функции. В нашем примере выбираем атрибут «Ключ», идентифицирующий музейный экспонат и статистическую функцию – число элементов. На первом шаге мы выбрали объект – музейный предмет, на втором разложили все предметы по авторам описания, далее для каждого автора описания (узла измерения) считаем число предметов им описанных.
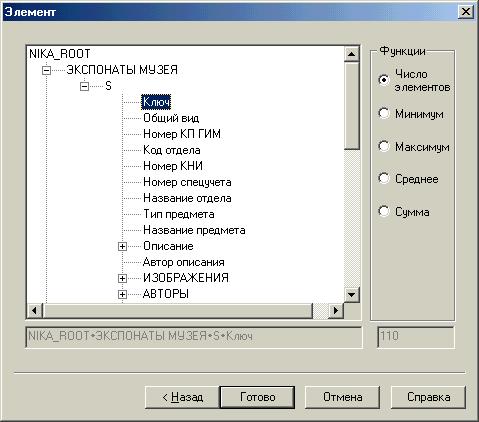
Рисунок 5. Третий этап - выбор статистической функции.
Для окончания работы мастера надо нажать кнопку «Готово». Программа будет перебирать выбранные объекты, двигаясь в индексе. Для каждого объекта будут перебраны все связанные атрибуты и вычислена статистическая функция. Результаты работы будут записаны во временную базу данных. После анализа БД вновь появится главное окно программы с графиком – результатом работы. Вид графиков можно легко менять, используя переключатели «Вид».
Для больших БД не целесообразно показывать сразу все данные на экране. В окне «Число знач.» можно указать число узлов измерения, одновременно показываемых на экране, 0 – соответствует показу всех узлов. Также имеется функция поиска узла измерения, в окно «Начиная с» вносятся начальные буквы, кнопка «Найти» осуществляет поиск.
Как было сказано выше на объекты и на элементы (атрибуты) в статистических функциях могут быть наложены некоторые ограничения, сделанные при помощи запросов. Результатом запроса в БД НИКА является ветка в БД, содержащая цепочки ключей иерархии (пути) к отобранным объектам. Для задания ограничений пользователь предварительно должен выполнить запрос средствами СУБД. Для учета ограничений при вычислении значений аналитической функции пользователь должен в главном окне программы выставить соответствующие флаги. Поле «Уровень» задает глубину, на которую требуется сравнивать пути к объектам и элементам с результатом запроса.
Кнопка «Пересчитать» позволяет выполнить вычисления аналитической функции без повторного запуска мастера построения, при этом учитываются изменения, произошедшие в БД, запросе и сделанные пользователем в главном окне. Кнопка «Новый» запускает мастер построения для вычисления новой аналитической функции.
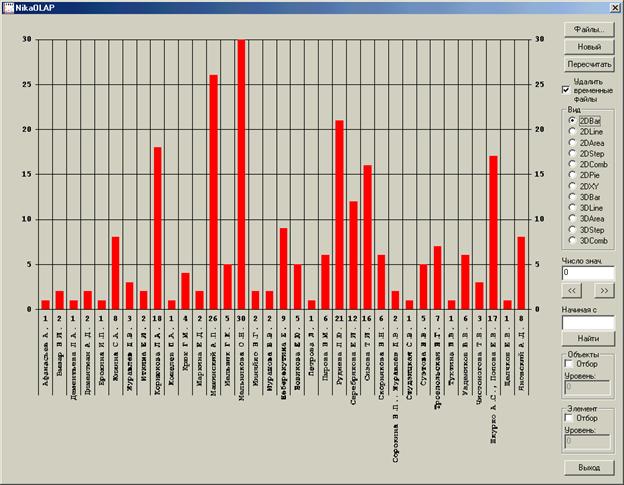
Рисунок 6. Результат обработки БД.
Следует отметить, что результаты аналитической обработки легко (технология Drag&Drop) преобразуются в формат электронных таблиц MS Excel (см. Рисунок 7). В качестве развития планируется увеличить количество измерений до 3 (четырехмерные графики тяжело рисовать) и добавить ряд новых статистических функций.
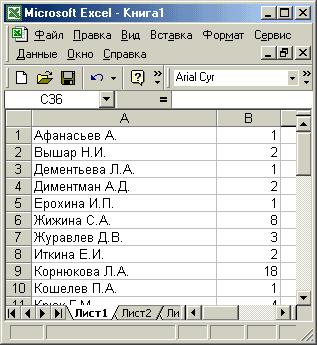
Рисунок 7. Результат экспорта в MS Excel.
Заключение
Многие авторы отмечают, что система OLAP для СУБД ORACLE (Express OLAP) наиболее продвинутая и продаваемая среди разработок многих конкурирующих фирм: Arbor Software, IBM, Informix, Microsoft, Sybase и др. Ни одна из фирм-разработчиков не представляет законченного решения для корпоративной аналитической системы, это программное обеспечение является лишь набором инструментальных средств разработки таких систем [1].
Действительно, описания практически всех реализаций над реляционным СУБД требуют понимания новой модели данных - многомерной БД и методов ее загрузки данными из существующей реляционной БД. Импорт возможен, как правило, из текстовых файлов, или из реляционных БД с использованием встроенных SQL запросов, или из других многомерных БД (для ORACLE - Express).
БД, как правило, содержит десятки взаимосвязанных таблиц и выгрузка необходимых данных в нужном формате в текстовый файл или написание соответствующего запроса требуют весьма высокой квалификации.
Достоинством предложенного в статье подхода является отсутствие какой-либо предварительной обработки данных или загрузки многомерной БД. Построение таблиц или графиков осуществляется заданием объектов исследования, измерений и переменных непосредственно над схемой БД. Схема БД отображается (см. Рисунок 3, Рисунок 4) в виде наглядного дерева объектов и их атрибутов. Опыт консультаций разработчиков многочисленных и разнообразных БД показывает, что пользователи легко осваивают средства НИКА (так же, как раньше ИНЕС), и язык описания схемы БД, который близок к концептуальному уровню, становится основным диалоговым инструментом проектирования.
Кроме того, при обычном подходе для анализа разных объектов требуется создание разных многомерных БД. При нашем подходе достаточно только выбрать на схеме БД объект, затем будут показаны все связанные с ним атрибуты, из которых нужно выбрать измерения, переменные и статистические функции. Это позволило значительно понизить уровень квалификации пользователей, нужный для работы со средства OLAP в СУБД НИКА.
