
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
СБОРНИК НАУЧНЫХ ТРУДОВ НГТУ. – 2011. – №2() . – 1–10
УДК 519.217.2
КЛАССИФИКАЦИЯ ПОСЛЕДОВАТЕЛЬНОСТЕЙ,
поДВЕРЖЕННЫХ ДЕЙСТВИЮ ПОМЕХ С
ХАРАКТЕРИСТИКАМИ, ЗАВИСяЩАМИ от скрытых состояний
Т. А. ГУЛЬТЯЕВА§, ¨
В данной статье рассматривается задача классификации последовательностей с использованием методологии скрытых марковских моделей (СММ). Классификация проводится как с использованием стандартного подхода, так и с использованием классификатора k ближайших соседей (kNN) в пространстве признаков, инициированных скрытыми марковскими моделями. При моделировании в качестве альтернативных использовались близкие по параметрам модели, а генерируемые ими последовательности подвергались искажению.
Ключевые слова: скрытые марковские модели, производные от логарифма функции правдоподобия, классификатор k ближайших соседей
Введение
Имея хорошие описательные способности (СММ, например, используются при анализе сигналов различной природы, таких как: речи, рукописного текста, изображений лиц и т. д.), СММ не всегда демонстрируют дискриминирующие свойства, важные для задач классификации.
Традиционная техника классификации основывается на отношении функций правдоподобия. Генерируемые скрытыми марковскими моделями последовательности классифицируются при этом с приемлемым качеством, зависящим впрочем, от степени удаленности параметров конкурирующих моделей. Определенные проблемы возникают, если наблюдаемые последовательности как-либо искажены. Поэтому предлагается исследовать возможность использования в этих условиях другого классификатора, основанного, например, на метрическом алгоритме классификации в пространстве признаков, извлекаемых из обученных СММ.
1. постановка задачи
СММ – это дискретный случайный процесс с ненаблюдаемой стационарной марковской цепью. СММ описывается следующими параметрами:
1. Вектор вероятностей начальных состояний ![]() ,
, ![]() , где
, где ![]() ,
, ![]() – скрытое состояние в начальный момент времени
– скрытое состояние в начальный момент времени ![]() ,
, ![]() – количество скрытых состояний в модели.
– количество скрытых состояний в модели.
2. Матрица вероятностей переходов ![]() ,
, ![]() , где
, где ![]() ,
, ![]() , где
, где ![]() – длина наблюдаемой последовательности.
– длина наблюдаемой последовательности.
3. Матрица вероятностей наблюдаемых символов выглядит следующим образом: 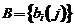 ,
, ![]() ,
, 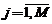 , где
, где 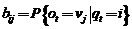 ,
, ![]() – символ, наблюдаемый в момент времени
– символ, наблюдаемый в момент времени ![]() . Здесь
. Здесь ![]() – это размерность алфавита наблюдений,
– это размерность алфавита наблюдений, ![]() – различные элементы этого алфавита. В данной работе рассматривается случай, когда функция распределения вероятностей наблюдаемых символов описывается смесью нормальных распределений. Параметры смеси задаются таким образом, что бы скрытое состояние ассоциировалось лишь с одним своим наблюдаемым состоянием:
– различные элементы этого алфавита. В данной работе рассматривается случай, когда функция распределения вероятностей наблюдаемых символов описывается смесью нормальных распределений. Параметры смеси задаются таким образом, что бы скрытое состояние ассоциировалось лишь с одним своим наблюдаемым состоянием: ![]() ,
, ![]() ,
, ![]() .
.
Таким образом, СММ полностью описывается матрицей вероятностей переходов, а также вероятностями наблюдаемых символов и вероятностями начальных состояний:  .
.
Традиционно при работе с СММ используется классификатор, основанный на отношении логарифмов функций правдоподобия: последовательность ![]() считается порожденным моделью
считается порожденным моделью ![]() , если выполняется
, если выполняется
![]() .
.
Иначе – считается, что последовательность порождена моделью ![]() . При необходимости производится оценка параметров СММ методом максимального правдоподобия.
. При необходимости производится оценка параметров СММ методом максимального правдоподобия.
Для приближения к реальной ситуации все наблюдаемые последовательности после их моделировании подвергались искажению. Задача состояла в сравнении в этих условиях возможностей традиционной методики классификации, основывающейся на, с классификатором kNN в пространстве первых производные от логарифма функции правдоподобия по элементам матрицы ![]() конкурирующих моделей
конкурирующих моделей ![]() и
и ![]() [1]. Схема работы классификатора, базирующегося на kNN, подробно изложена в [2].
[1]. Схема работы классификатора, базирующегося на kNN, подробно изложена в [2].
Зашумление производилось по двум различным вариантам:
![]()
![]()
Вариант использовался для моделирования аддитивного зашумления, а для моделирования искажения сигнала по принципу вероятностного его замещения шумом. При этом рассматривался случай, когда характеристики шума выбирались индивидуальными для каждого скрытого состояния.
2. Результаты
Исследования проводились при следующих условиях. Две модели были определены на одинаковых по структуре скрытых марковских цепях и различались только матрицами переходных вероятностей:
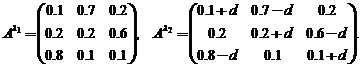
Параметры гауссовских распределений для моделей ![]() и
и ![]() выбирались одинаковыми:
выбирались одинаковыми: ![]() . Вероятности начальных состояний также совпадали:
. Вероятности начальных состояний также совпадали: 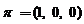 . Параметр
. Параметр ![]() , который можно варьировать в определенных пределах, определяет степень близости конкурирующих моделей.
, который можно варьировать в определенных пределах, определяет степень близости конкурирующих моделей.
Обучающие и тестовые последовательности моделировались по методу Монте-Карло. Для проведения экспериментов было сгенерировано по 5 обучающих наборов последовательностей. К каждому набору этих последовательностей моделировалось по 5 тестовых наборов. Каждый набор содержал по 100 последовательностей для каждого класса. Таким образом, всего было смоделировано ![]() обучающих и 1000 тестовых последовательностей. Здесь
обучающих и 1000 тестовых последовательностей. Здесь ![]() – это количества обучающих последовательностей в каждом классе. Результаты классификации усреднялись. Распределение шума выбиралось как нормальное, так и Коши.
– это количества обучающих последовательностей в каждом классе. Результаты классификации усреднялись. Распределение шума выбиралось как нормальное, так и Коши.
2.1. АДДИТИВНО ЗАШУМЛЕННЫЕ ПОСЛЕДОВАТЕЛЬНОСТИ
Далее на всех рисунках график, отражающий результаты классификации для kNN, имеет пунктирную линию, а график для традиционного подхода – сплошную линию. На рис. 1 (а) – рис. 4 (а) приведены зависимости процентов верно классифицированных последовательностей при распределении ошибок по нормальному закону с параметрами, разными для каждого скрытого состояния: ![]() и на рис. 1 (б) – рис. 4 (б) – по закону Коши с параметрами:
и на рис. 1 (б) – рис. 4 (б) – по закону Коши с параметрами: 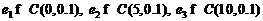 .
.
На рис. 1 приведена зависимость процента верно классифицированных последовательностей от уровня шума ![]() . При этом параметры моделирования следующие:
. При этом параметры моделирования следующие: 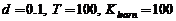 . При шуме, распределенном по закону Коши (рис. 1 (б)), наблюдается значительный выигрыш классификатора kNN в сравнении с традиционным классификатором.
. При шуме, распределенном по закону Коши (рис. 1 (б)), наблюдается значительный выигрыш классификатора kNN в сравнении с традиционным классификатором.
|
|
а) | б) |
Рис. 1. Зависимость процента верно классифицированных последовательностей от уровня шума |
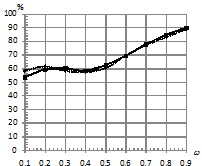
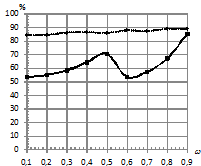
При шуме, распределенном по нормальному закону, аналогичного эффекта не наблюдается. Скорее всего, это связано с тем, что закон распределения помехи совпадает с законом распределения, используемым при эмиссии наблюдаемых последовательностей, и при этом алгоритм, используемый для оценки параметров СММ, также настроен именно для оценки параметров нормального распределения вероятностей наблюдаемых символов. При приближении уровня шума к 1 фактически происходит замена алфавита словаря наблюдаемых символов.
На рис. 2 приведены зависимости процентов верно классифицированных последовательностей от параметра близости моделей ![]() при распределении ошибок по двум законам и при различном уровне шума
при распределении ошибок по двум законам и при различном уровне шума![]() . При этом параметры моделирования следующие:
. При этом параметры моделирования следующие: ![]() . Наблюдается аналогичная картина, как и на рис.1.
. Наблюдается аналогичная картина, как и на рис.1.
|
|
а) | б) |
|
|
в) | г) |
Рис. 2. Зависимость процента верно классифицированных последовательностей от параметра близости моделей |
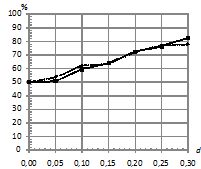
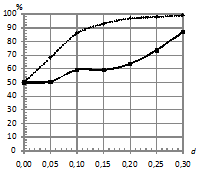
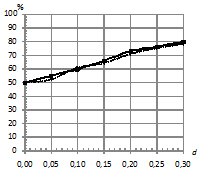
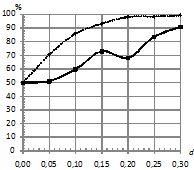
На рис. 3 приведены зависимости процента верно классифицированных последовательностей от длины ![]() при двух распределениях ошибок. При этом параметры:
при двух распределениях ошибок. При этом параметры:  . На рис 3 (б) наблюдается следующая закономерность: при увеличении длины сигнала
. На рис 3 (б) наблюдается следующая закономерность: при увеличении длины сигнала ![]() улучшение качества классификации по традиционной методике происходит неустойчиво и очень медленно.
улучшение качества классификации по традиционной методике происходит неустойчиво и очень медленно.
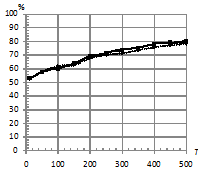
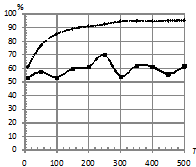
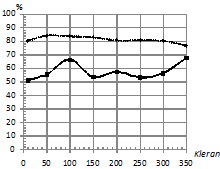
На рис. 4 приведен график зависимости процента верно классифицированных последовательностей от количества обучающих последовательностей в каждом классе ![]() при двух распределениях ошибок. При этом параметры:
при двух распределениях ошибок. При этом параметры: ![]() . На рис. 4 (а, б) наблюдается следующая закономерность: увеличение количества обучающих последовательностей
. На рис. 4 (а, б) наблюдается следующая закономерность: увеличение количества обучающих последовательностей ![]() слабо влияет на качество классификации как по традиционной методике, так и с использованием kNN. На рис. 4 (б) наблюдается даже эффект переобучения: при числе обучающих последовательностей более 100 качество kNN падает. Предположительно это можно объяснить выбранной реализацией kNN.
слабо влияет на качество классификации как по традиционной методике, так и с использованием kNN. На рис. 4 (б) наблюдается даже эффект переобучения: при числе обучающих последовательностей более 100 качество kNN падает. Предположительно это можно объяснить выбранной реализацией kNN.
|
|
а) | б) |
Рис. 3. Зависимость процента верно классифицированных последовательностей от длины последовательности |
|
|
а) | б) |
Рис. 4. Зависимость процента верно классифицированных сигналов от количества обучающих последовательностей в каждом классе нормальном (а), Коши (б). |
2.2. ИСКАЖЕНИЕ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ПО СХЕМЕ вероятностнОГО ЗАМЕЩЕНИЯ СИГНАЛА шумом
Так же как и в п. 2.1 на рис. 5 (а) – рис. 8 (а) приведены зависимости процента верно классифицированных последовательностей при распределении ошибок по нормальному закону с параметрами, разными для каждого скрытого состояния: 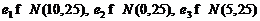 , а на рис. 5 (б) – рис. 8 (б) – по закону Коши с параметрами:
, а на рис. 5 (б) – рис. 8 (б) – по закону Коши с параметрами: 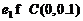 ,
, ![]() .
.
На рис. 5 приведены зависимости процента верно классифицированных последовательностей от вероятности возникновения шума ![]() при распределении ошибок, подчиняющихся двум законам распределения. При этом параметры:
при распределении ошибок, подчиняющихся двум законам распределения. При этом параметры: ![]() . На рис. 5 (а) наиболее низкий процент верной классификации, как и следовало ожидать, наблюдается при
. На рис. 5 (а) наиболее низкий процент верной классификации, как и следовало ожидать, наблюдается при ![]() , близким к 0.5. При
, близким к 0.5. При ![]() близким к 0 или 1 шумовые искажения начинают восприниматься уже как истинные элементы наблюдаемой последовательности и процент верной классификации растет. На рис. 5 (б) идет постоянный спад без подъема. Также стоит отметить, что как при шуме, распределенном по нормальному закону, так и при шуме, распределенном по закону Коши, классификатор kNN дает результаты намного лучше, чем традиционная методика.
близким к 0 или 1 шумовые искажения начинают восприниматься уже как истинные элементы наблюдаемой последовательности и процент верной классификации растет. На рис. 5 (б) идет постоянный спад без подъема. Также стоит отметить, что как при шуме, распределенном по нормальному закону, так и при шуме, распределенном по закону Коши, классификатор kNN дает результаты намного лучше, чем традиционная методика.
|
|
а) | б) |
Рис. 5. Зависимость процента верно классифицированных последовательностей от вероятности возникновения шума |
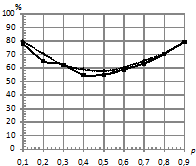
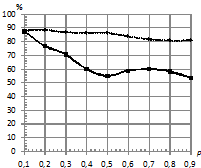
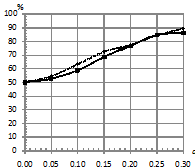
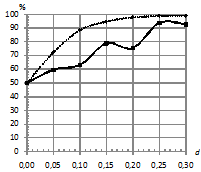
На рис. 6. приведены зависимости процентов верно классифицированных последовательностей от параметра близости моделей ![]() при двух распределениях ошибок и при различных вероятностях возникновения шума. При этом параметры:
при двух распределениях ошибок и при различных вероятностях возникновения шума. При этом параметры: 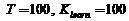 . При вероятностном замещении сигнала шумом, распределенным по Коши, заметно преобладание классификатора kNN по качеству над с традиционным классификатором.
. При вероятностном замещении сигнала шумом, распределенным по Коши, заметно преобладание классификатора kNN по качеству над с традиционным классификатором.
На рис. 7 приведены зависимости процентов верно классифицированных последовательностей от длины последовательности ![]() при двух распределениях ошибок. При этом параметры:
при двух распределениях ошибок. При этом параметры:![]() . Наблюдаемая картина аналогична рис. 3.
. Наблюдаемая картина аналогична рис. 3.
|
|
а) | б) |
|
|
в) | г) |
Рис. 6. Зависимость процента верно классифицированных последовательностей от параметра близости моделей |
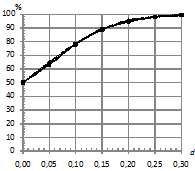
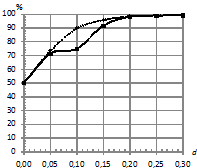
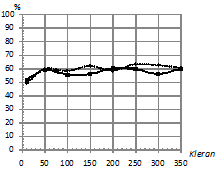
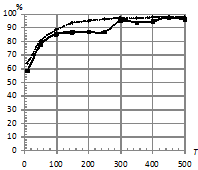
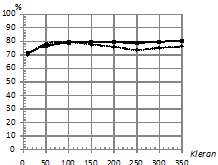
На рис. 8 приведены зависимости процентов верно классифицированных последовательностей от количества обучающих последовательностей в каждом классе ![]() . При этом параметры:
. При этом параметры: ![]() . Характер наблюдаемых зависимостей аналогичен характеру зависимостей на рис. 4, однако на рис. 8 (б) не наблюдается такого заметного преимущества классификатора kNN, как на рис. 4 (б).
. Характер наблюдаемых зависимостей аналогичен характеру зависимостей на рис. 4, однако на рис. 8 (б) не наблюдается такого заметного преимущества классификатора kNN, как на рис. 4 (б).
|
|
а) | б) |
Рис. 7. Зависимость процента верно классифицированных сигналов от длины последовательности |

|
|
а) | б) |
Рис. 8. Зависимость процента верно классифицированных последовательностей от количества обучающих последовательностей в каждом классе |
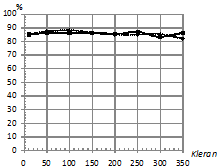
По проведенным экспериментам можно сделать вывод, что традиционный классификатор не устойчив к шуму, распределенному по закону Коши (данный вид распределения относится к распределениям с тяжелыми хвостами, и в этих условиях оценки параметров базового нормального распределения, полученные по методу максимального правдоподобия, становятся смещенными). Кроме этого следует отметить, что предложенный подход, базирующийся на простейшем метрическом классификаторе, при шуме, распределенном по нормальному закону, если и уступает то в незначительной мере традиционному классификатору, основывающемуся на отношении логарифмов функций правдоподобия.
ЗАКЛЮЧЕНИЕ
Исследования показали, что если использовать классификатор k ближайших соседей, то для близких по своим параметрам моделей и последовательностях, искаженных помехой, имеющей распределение Коши, удается повысить качество классификации. При этом прирост процентов верной классификации в рассмотренной двухклассовой задаче в сравнении с традиционным подходом в ряде случаев может достигать 40%.
[1] Гультяева, Т. А. Особенности вычисление первых производных от логарифма функции правдоподобия для скрытых марковских моделей при длинных сигналах / // Сборник Научных трудов НГТУ.. – Новосибирск : Изд-во НГТУ, 2010. – № 2(60). – С. 47-52.
[2] А. Повышение классификационных свойств скрытых марсковских моделей / Т. А. Гультяева // Информатика и проблема телекоммуникаций: Материалы российской науч.-технич. конф. - Новосибирск: Изд-во СибГУТИ, 2010. - Том I. - с.52-54.
, доктор технических наук, профессор, заведующий кафедрой программных систем и баз данных. Основные направления научных исследований – статистические методы анализа данных, оптимальное планирование эксперимента. Имеет более 100 публикаций, в том числе 1 монографию.
Тел. (383), e-mail: *****@***ami. *****
ассистент кафедры программных систем и баз данных. Основные направления научных исследований – скрытые марковские модели, статистические и структурные методы распознавания. Имеет 19 публикаций.
Тел. (383), e-mail: *****@***ru
Gultyaeva T. A., Popov A. A.
The sequences classification subject to action of noise with characteristics, depending on the hidden states
In given article, using space of the signs initiated hidden markov models (HMM), classification with use as standard approach, and with qualifier use k nearest neighbors (kNN) is spent. Relatives on parameters of model in the conditions of use of the deformed initial sequences are considered only.
Key words: hidden markov models, derivative of log likelihood function, classifier of the nearest k neighbors
§ Ассистент, аспирант кафедры программных систем и баз данных
¨ Профессор кафедры программных систем и баз данных, д-р техн. наук
