
Интеграл MPI
F(x, y)=sqrt((1-x^2)*(1-y^2))
x, y Î [-1; 1]
Очевидно, всё симметрично, поэтому это то же самое, что 4*integral(x, y Î [0; 1]).
Для простоты используем метод прямоугольников.
Далее как обычно, меняем x и y от 0 до 1 равномерно за N шагов, где N достаточно большое, чтобы долго считалось. Разделяем на узлы по «полосам», на каждом считаем частичную сумму значений функции в точках на «локальной» области, потом передаем результат на один узел, где всё суммируется, делится на количество точек (границы от 0 до 1, поэтому площадь области тоже единица, в общем же случае надо еще на нее умножить) и умножается на 4.
Главное – правильно поделить область между узлами, без «просветов» и «перекрытий», а из взаимодействия между процессами здесь есть только однократная передача одного числа от всех не-первых узлов первому, выполняемая после окончания расчетов.
Текст программы.
program mpi_integral
double precision aa, bb
include 'mpif. h'
F(aa, bb)=sqrt((1-aa*aa)*(1-bb*bb))
integer(4) :: messageSize
double precision :: message
integer(4) :: ierr, nodeID, firstNode, otherNode, numberOfNodes, tag
integer(4) :: statusMPI(MPI_STATUS_SIZE)
real(8) :: beginTime, endTime
integer i, j,k! loop variables etc
integer N! number of subdivisions
double precision xstart, xend, xstep
double precision ystart, yend, ystep
double precision x, y
integer nstart, nend, nrepeat
integer cc
double precision tt
integer pp
integer maxpp
double precision int_result
firstNode = 0
otherNode = 1
tag = 100
N=100000
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, nodeID, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numberOfNodes, ierr)
if (nodeid .eq. firstnode)then
print *, 'integral started, total nodes = ',numberofnodes
print *, 'square size = ',N,' x ',N
end if
! decide range of integration for each node
ystart=0
yend=1
ystep=(yend-ystart)/N
ystart=0.5d0 * ystep
xstep=ystep
if (nodeid. eq. 0) then
! if we are in first node, start from beginning
nstart=0
else
! if in other, start from some place
nstart=floor(nodeid*1.0d0/numberofnodes*N)+1
end if
if (nodeid. eq. (numberofnodes-1)) then
! if we are in last node, end at the end
nend=N-1
else
! if in other, end just before next node starts
nend=floor((nodeid+1.0d0)/numberofnodes*N)
end if
! now calculate the linear values
xstart=nstart*1.0d0/N + 0.5d0 * xstep
nrepeat=nend-nstart+1
print *, 'node number ',nodeid
print *, 'start value = ',nstart
print *, 'end value = ',nend
print *, 'number of repeats = ',nrepeat
messagesize = 1
tt=0
beginTime = MPI_WTIME()
if(nodeID == firstNode) then
! perform as node #1
! calculate
int_result=0
x = xstart
do i=1,nrepeat
y=ystart
do j=1,N
int_result=int_result+F(x, y)
y=y+ystep
end do
x=x+xstep
end do
! receive from others and accumulate
! skip if we are the only node
if (numberOfNodes>1)then
do i=1,numberOfNodes-1
call MPI_RECV(message, messageSize, MPI_REAL8,i, tag, MPI_COMM_WORLD, statusMPI, ierr)
int_result=int_result+message
end do
end if
else
! perform as any other node
! calculate
int_result=0
x = xstart
do i=1,nrepeat
y=ystart
do j=1,N
int_result=int_result+F(x, y)
y=y+ystep
end do
x=x+xstep
end do
! send to first node
message=int_result
call MPI_SEND(message, messageSize, MPI_REAL8,firstNode, tag, MPI_COMM_WORLD, ierr)
end if
endTime = MPI_WTIME()
tt=tt+(endtime-begintime)
if (nodeid. eq. firstnode)then
int_result=int_result/(0.25d0*N*N)
print *, 'result = ',int_result
print *, 'time = ',(endtime-begintime),' seconds'
end if
call MPI_FINALIZE(ierr)
end program mpi_integral
Результаты ее запуска с использованием script-ов и очередей, выделяющих заданное количество узлов для запуска копий программы, представлены в таблице.
Количество узлов | Время расчета, с. | Результат | Ускорение |
входной узел | 180.35 | 2. | 0.92 |
1 | 166.57 | 2. | 1 |
2 | 83.45 | 2. | 2.00 |
3 | 55.64 | 2. | 2.99 |
4 | 41.74 | 2. | 3.99 |
5 | 33.39 | 2. | 4.99 |
6 | 27.82 | 2. | 5.99 |
8 | 20.90 | 2. | 7.97 |
Все измерения, кроме входного узла, выполнялись 1 раз, ждать и усреднять было лень.
После взаимодействия с одномашинным параллельным интегралом уже было ожидаемо, что при увеличении числа точек N до значений, при которых «достаточно долго считается», вновь заявит о себе накопление ошибок округления при суммировании 100000x100000 = 10 млрд чисел. Так оно и получилось (перед «достаточно долгим» запуском были проведены исследования на меньшем числе точек, подтвердившие, что используется строго одна и та же сетка вне зависимости от количества процессов, между которыми поделено выполнение расчета). И в случае «многоузлового» расчета суммы большого числа слагаемых результат менялся, когда менялось количество промежуточных переменных, использовавшихся для его накопления. Поскольку количество сложений, приходящихся на каждую такую переменную, с увеличением числа узлов уменьшается, можно предположить (хотя не очень уверенно), что результат при этом приближается к правильному.
Интересно, что при «автоматическом» размещении программы на одном из расчетных узлов уже достигается ускорение по сравнению с запуском на входном узле.
Зависимость ускорения от числа используемых процессов представлена на графике.
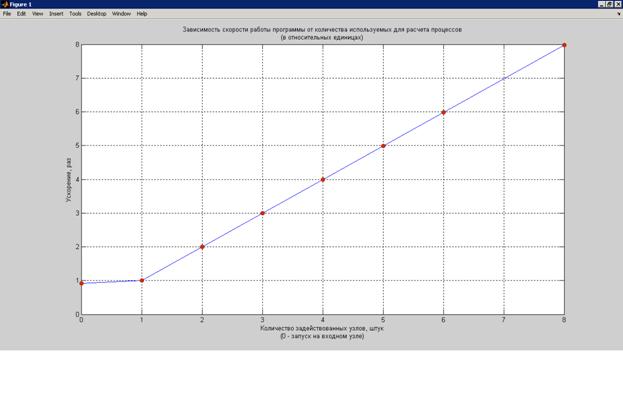
(численные значения ускорения, представленные в таблице, округлены, график же строился по исходным)
Поскольку основная часть нагрузки на узлы – параллельная, а последовательная состоит лишь из суммирования частичных результатов, даже при такой нерациональной ее реализации, как в приведенной выше программе, при использованном числе процессов (от 1 до 8) ее влияние в прямом смысле незаметно. Наблюдается устойчивый рост производительности прямо пропорционально числу задействованных процессов. Это не «подогнанная» картинка, а экспериментальные данные, причем измеренные кустарным способом один раз даже без усреднения. Но всё равно верится с трудом, поэтому ниже приведены «сырые» данные.
ydata =
0.
1
1.
2.
3.
4.
5.
7.
Сначала программа была запущена тупо по-linux-овому на локальном узле, результат приведен в графе с номером «0». Затем при количестве процессов от 1 до 6 использовался script очереди, с указанием по 1 экземпляру программы на каждый компьютер. С 7 процессами так не получилось (видимо, «входной» узел не может участвовать в очереди), поэтому число 8 получено задействованием 4 компьютеров по 2 копии программы на каждом. А дальше было не столько лень увеличивать, сколько появились опасения, что результат запуска программы по несколько копий на каждом узле будет недостаточно «чистым» по сравнению с задействованием каждого узла только однократно.
Не совсем понятно, что считать «последовательной» программой, ведь при запуске вышеприведенной “mpi”-программы в одном экземпляре (не важно, через “mpiexec” или нет) алгоритм ведет себя как чисто последовательный, не использует каких-либо пересылок, обсчитывает всю область интегрирования один целиком в последовательном цикле. Так что последовательными равноправно могут считаться запуски 0 и 1, а разница во времени их выполнения, видимо, обусловлена разницей в производительности процессоров «входного» и «расчетного» узлов (было два запуска с результатами 180.36 и 180.35 секунд, так что, скорее всего, это разница именно в производительности, а не в загрузке узлов другими пользователями). По сравнению же с запуском на одном расчетном узле в последовательном режиме, параллельный запуск на большем числе процессов дает выигрыш в производительности ровно во столько раз, каково их число.
