

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Базы данных – совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязи в рассматриваемой области. Логическую структуру, хранимую в БД называют моделью представления данных, а именно иерархическая, сетевая, реляционная. Система управления БД-ых – это комплекс языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Приложения могут создаваться как в среде СУБД – это приложения СУБД, так и вне среды – внешние приложения СУБД. КБД – корпоративная БД (на сервере). ПБД – персональная БД. Сервер БД обеспечивает основной подбор обработки БД. Формируемый пользователем или сервером запрос поступает к серверу БД в виде инструкций языка SQL. Сервер БД выполняет поиск и извлечение нужных данных, которые передаются пользователю на компьютер. КБД создается, функционирует под управлением сервера БД, например, Microsoft SQL. В зависимости от задач могут быть разные конфигурации с БД. Серверы БД предназначены для организации центров обработки данных в сетях ЭВМ. Они реализуют функции управления БД-ых, запрашиваемые другими клиентскими программами, обычно с помощью операторов SQL. Назначение БД заключается в том, чтобы одну и ту же совокупность данных можно было использовать для максимального числа приложений. Основное свойство БД – независимость данных (т. е. изменение одних прикладных программ не приводит к изменению других). Основные требования к организации БД: 1. установление многосторонних связей: метод организации. 2. производительность. 3. минимальные затраты (минимальные требования к внешней памяти). 4. минимальная избыточность. 5. возможность поиска. 6. целостность. 7. безопасность и секретность (защита данных от допуска лиц, не имеющих право): 7.1.защита от хищения и других форм уничтожения. 7.2.данные должны быть восстанавливаемыми. 7.3.должна быть обеспечена возможность контроля данных. 7.4.система недоступна от вмешательств из вне. 7.5.должна быть установлена процедура идентификации пользователя БД. 7.6.в системе должен быть предусмотрен контроль действий пользователя по обработке данных с точки зрения функционирования и санкционирования. 8. обнаружение ошибок. 9. связь с прошлым. Уровни данных. 1. логический 2. физический 3. уровень хранения 1. Работают с логическими структурами данных, отражающими реальные отношения, которые существуют между объектами и их характеристиками. Единица информации – логическая запись. Каждый объект, описываемый соответствующей логической записью, характеризуется определенными признаками, являющимися атрибутами записи. На этом уровне устанавливается перечень признаков полностью характеризующий описываемый класс объектов. Здесь не учитывается техническое, математическое обеспечение данных. 2. Работают с физическими структурами данных. Единица информации – физическая запись. Физическая независимость данных – это то, что изменение в физическом расположении данных и в техническом обеспечении системы не должно отражаться на логических структурах и прикладных программах. Логическая независимость данных означает то, что изменение в структурах хранения не должно вызывать изменение в логических структурах данных. Оперирует со структурами хранения. Представление логической структуры данных памяти ЭВМ. Единица информации – логическая запись. Поддержание структуры хранения осуществляется программными средствами. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-1- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Нормальные формы схем отношений. Рассмотрим отношение R={r1,…,rn}. Возможный ключ к отношению R – это комбинация атрибутов возможно состоящих из одного атрибута, обладающих следующими свойствами: 1) В каждом картеже отношения R величина K единственным образом определяет этот картеж. 2) Не существует атрибута в возможном ключе K, который можно удалить без нарушения условия 1). Всегда существует по крайней мере один возможный ключ, т. е. комбинация всех атрибутов отношения R удовлетворяет условию 1). Если в R имеется несколько возможных ключей, то один из них выбирается в качестве первичного. Атрибут ai отношения R называют также первичным, если входит в состав любого ключа (возможного или первичного) отношения. Если есть A->B и B не зависит функционально от любого подмножества A, то говорят, что A представляет собой детерминант В. Доменом называется совокупность однотипных значений данных. Число атрибутов, входящих в отношение называется степенью отношения. Число картежей отношения называется кардинальным числом или мощностью отношения. Описание каждого отношения состоит из имени отношения, за которым в круглых скобках следует список атрибутов. Это описание называется интенсионалом отношения (схемой). Под описанием приведено некоторое заполнение картежа отношений – экспонсионал отношения. Реляционная БД является совокупностью, изменяющихся во времени нормализованных отношений различных степеней, которые могут быть связаны друг с другом через общий домен. Отношение называется нормализованным, если каждая компонента картежа является простым атомарным значением, не состоящим из группы значений. Схема нормальных форм (нф):
……. 2 нф 1 нф Отношение находится в 1 нф если каждый атрибут является простым атомарным атрибутом, т. е. отсутствуют составные: Автомобиль(модель, марка, номер, изготовитель(завод, город)) Автомобиль(модель, марка, номер, завод-изготовитель, город - изготовитель) Чтобы перейти ко 2 нф вводится понятие полной функциональной зависимости. Зависимость A->B называется полной функциональной зависимостью, если B зависит от всей группы атрибутов A. A1,A2,…,An. A1,A2->B – неполная функциональная зависимость. Говорят, что отношение R находится во 2 нф, если оно нормализовано, т. е. находится в 1 нф и каждый не первичный атрибут полностью зависит от первичного ключа. Пример. Пусть имеется отношение поставки, содержащее данные о поставщиках (идентификационный) номер ПN, о поставляемых товарах (ТОВАР) и ценах на товары (ЦЕНА). Предположим, что поставщик может поставлять различные товары, а один и тот же товар могут поставлять различные поставщики. Ключ будет составлять ПN. ТОВАР. Кроме того известно, что цена товара зафиксирована, то есть все поставщики поставляют товар по одной цене. Отсюда имеем: П№, ТОВАР->ЦЕНА ТОВАР->ЦЕНА Имеем неполную функциональную зависимость ЦЕНА от ключа. Аномалия – такая ситуация в БД, приводящая к противоречию в БД, либо существенно усложняющая обработку данных. Аномалия включения – если у поставщика появляется новый ТОВАР информация о товаре и его ЦЕНЕ не сможет хранится в БД, пока поставщик не начнет поставлять ТОВАР. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-3- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Пример. Имеем отношение хранение (фирма, склад, объем) Фирма->склад, получает товары только с одного склада. Склад->объем. Аномалия включения. Если на данный момент отсутствует фирма, получающая товар со склада, то в БД нельзя вводить информацию об объеме. Аномалия удаления. Если последняя фирма перестает получать товар со склада, данный склад и объем нельзя сохранить. Аномалия обновления. Если объем склада изменится, необходим просмотр всего отношения и изменение картежей для фирм, связанных со складом. Отношение находится в 3 нормальной форме, если оно находится во 2 нф и в нем отсутствуют транзитивные зависимости не первичного ключа. Раскладываем отношение: Хранение(фирма, склад) Объем склада(склад, объем) Пример. Служащий (номер_служащего – А, Имя_служащего – B. Зарплата – C, Номер_проекта – D, дата_окончания – E) Атрибут А не является функционально зависимым от С, ведь у нескольких А может быть один С. Аналогично А не является функционально зависимым от D. Такой зависимостью обладает атрибут Е. Е зависит от атрибута D, который зависит от А. Таким образом Е транзитивно зависит от А. Аномалия включения. До момента подключения конкретного служащего к работе над данным проектом Е его негде сохранить.
Аномалия обновления. Изменение Е приводит к необходимости внесения изменений в нескольких картежах. Информация о Е может потребоваться независимо от информации о служащих. Атрибут Е относится больше к проекту, чем к служащему. Приводим отношение к 3 нф, разбивая его надвое: Служащий(А, В, С, D) Проект (D, Е) 1) переход от производной структуры данных, не являющейся двумерной к двумерным отношениям или сегментам. 2)Устранение всех неполных зависимостей атрибутов не являющихся основными от возможных ключей. 3) Устранение всех транзитивных зависимостей атрибутов, не являющихся основными от возможных ключей. Нормальная форма Бойса-Кодда (НФБК) – 3 усиленная нормальная форма. Пусть имеется отношение: Проект(ДN, ПРN, ПN) – отражающее использование проектов деталей поставляемых поставщиком. В проекте используется несколько деталей. Но каждая DN проекта поставляется одним поставщиком. Каждый поставщик обслуживает только один проект. Но проекты могут обеспечиваться несколькими поставщиками разных деталей. В отношении детали, проекты, поставщики идентификаторы соответствуют номерам: ДN, ПРN, ПN. Имеем следующие функциональные зависимости: DN, ПРN->ПN ПN->ПРN Рассматриваемое отношение находится в 3нф, так как в нем отсутствуют неполные функциональные зависимости и транзитивные зависимости не первичных атрибутов от ключей. Наблюдаются следующие аномалии: Аномалия включения. Факт поставки поставщиком деталей для проекта не заносится в БД, пока детали не начнут использоваться. Аномалия удаления. Если последний запас деталей используется, данные о поставщиках также будут удалены из БД. Аномалия обновления. Если меняется поставщик, необходим просмотр отношения для изменения всех картежей детали. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-5- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рассмотрим отношение, связывающее студентов с группами, факультетами и специальностями, на которых они учатся. Мы имеем отношение Студент(ФИО, № зачётки, группа, факультет, специальность, выпускающая кафедра). Первичным ключом отношения является № зачетки. Группа, в которой учится студент, однозначно определяет факультет, а также специальность и выпускающую кафедру. Кроме того, выпускающая кафедра однозначно определяет факультет, на котором обучаются студенты, выпускаемые на данной кафедре. Но если предположить, что одну специальность могут выпускать несколько кафедр, то специальность не определяет выпускающую кафедру. <№ зачётки ® ФИО>, <№ зачетки ® группа>, <№ зачётки ® факультет>, <№ зачётки® специальность>, <№ зачётки® выпускающая кафедра>, <группа ® факультет>, <группа ® специальность> , <группа ® выпускающая кафедра>, <кафедра ® факультет> . Эти зависимости образуют транзитивные группы: Студ1(ФИО,№ зачетки, специальность, группа) , Группа1(Группа, Выпускающая кафедра), Фак1(Выпускающая кафедра, факультет). Подчеркнуты ключи отношений. Рассмотрим отношение, моделирующее сдачу студентом текущих экзаменов. Предполагается, что студент может сдавать экзамен по одной дисциплине несколько раз, если он получил неудовлетворительную оценку. Каждому студенту присваивается в период его обучения уникальный номер - идентификатор. Сессия(№ зачётки, идентификатор студента, дисциплина, дата, оценка). Возможными ключами отношения являются: № зачётки, дисциплина, дата и идентификатор студента. Функциональные зависимости: < № зачётки, дисциплина, дата ® оценка>, <идентификатор студента, дисциплина, дата ® оценка> , <№ зачётки ® идентификатор студента>, <идентификатор студента ® № зачётки>. Эти отношения находятся в III нормальной форме, но это отношение не находится в НФБК, т. к. есть два детерминанта, которые и являются ключами отношения: № зачётки и идент. студента. Для того, чтобы удобно привести это отношение в НФБК, его надо разложить на два отношения : R1(№ задачи, дисциплина, дата, оценка), R2 (№ зачётки, идентификатор студента) или R3 (идентификатор студента, дисциплина, дата, оценка), R4(идентификатор студента, № зачётки). R1,R2 ; R3,R4 находятся в НФБК. Последовательное приведение из одной нормальной формы к другой. Рассмотрим отношение «Преподаватель - предмет». Оно состоит из следующих атрибутов: № Назв. к-во час ФИО Должн. Оклад Кафедра Тел. 101 ЭВМ 34 Иванов доцент 300 ЭВМ 4-80 102 ПЭВМ 68 Иванов доцент 300 ЭВМ 4-80 103 Прогр. 76 Петров ассист. 700 ЭВМ 4-80 104 Прогр. 76 Сидоров профес. 500 АСУ 4-80 201 Физика 40 Фёдоров ст. преп 400 Физика 4-70 202 Оптика 60 Фёдоров ст. преп 400 Физика 4-70 Это отношение с составным ключом состоит из 2 – х атрибутов: № и название предмета. <Должность ® оклад> <Номер ® ФИО> <ФИО ® Номер> Атрибут «количество часов» зависит от части ключа, т. е. , только от атрибута «название предмета». Здесь нет атрибутов, находящихся в полной функциональной зависимости от составного ключа. Имеем транзитивную зависимость для атрибутов <ФИО ® кафедра ® телефон>. Некоторые функциональные зависимости могут изменяться со временем, например, в данном отношении преподаватель закреплён за одной кафедрой, но со временем может начать работать параллельно и на другой кафедре, тогда ему уже нельзя будет однозначно определить кафедру. Данное отношение находится в I нормальной форме, т. к. не содержит составных атрибутов. Здесь есть частичная функциональная зависимость атрибутов ФИО, должность, оклад, кафедра, телефон, отчасти номер составного ключа. Эта неполная функциональная зависимость приводит к следующим аномалиям: 1) Имеет место дублирование данных о преподавателе, поскольку он может читать несколько предметов; 2) Существует проблема контроля избыточности данных, т. к. изменение, например, атрибута «Оклад» влечёт за собой необходимость поиска и изменения значений окладов во всех кортежах с данным преподавателем. 3) Возникает проблема с преподавателями, которые в данное время не ведут предметы и т. о. его невозможно внести в отношение и наоборот, если преподаватель увольняется и удаляется из отношения, то будет удалён и предмет, хотя предмет должен продолжать читаться. Чтобы устранить частичную зависимость и привести это отношение ко II нормальной форме, необходимо разложить его на два отношения следующим образом:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-7- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-9- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Метод таблоДля разложений состоящих более чем из двух отношений можно использовать метод табло. Этот метод можно представить следующим образом: Дано множество функциональных зависимостей. Схема и отношения получены в результате разложения. Процедура состоит в построении таблицы строками которой является разложение отношения, а столбцами список атрибутов А1,…,Аn этих отношений без повторений. Таблица заполняется символами aj, если элемент строки в столбце j соответствует атрибуту Аj отношения Ri, в противном случае в таблице ставится bij. После заполнения таблицы следует осмотр всех функциональных зависимостей x->y. Если для атрибутов из х найдутся строки, где в соответствующих местах стоят аj, то элементы bij этих строк соответствующие столбцам атрибутов из у заменяются на аj. Если в результате появилась строка таблицы, полностью заполненная аj, то данное соединение без потерь. В противном случае это соединение с потерями. Пример: R(A, B,C, D) B->C R1(A, B) A->C R2(B, D) C->B R3(A, B,C) C->D R4(B, C,D) A->C
B->C C->D
После просмотра из С->В в таблице ничего не меняется. Вывод: т. е. две строки полностью заполнены элементами аij => соединение без потерь. Реляционная алгебра- в ней определены основные операции над данными реляционного типа. Все операции можно разделить на традиционные над множествами и специализированные, вводимые для удобства поиска в БД. К операциям первой группы относятся: Ç, È, разность, декартовое произведение К операциям второй группы относятся: проекция, ограничение, соединение, деление. Объединение: в результате применения этой операции получается отношение объединяющее кортежи, содержащиеся в искомых отношениях. Объединяемые отношения должны иметь одинаковые атрибуты, т. е. должны быть
Пересечение: в результате применения этой операции получают отношение вкл-щее общие картежи для R1 и R2
Разность: в результате применения этой операции получают отношение содержащее кортежи являющиеся картежами отношения R1 и не являющиеся картежами отношения R2.
Декартовое произведение: в результате применения этой операции из m местного отношения R1 и n местного отношения R2, получают отношение n+m местное, причем первые m элементов представляют собой картежи R1, а последние n элементы картежи из отношения R2.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-11- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Реляционное исчисление с переменными на доменах. {(x1,x2,...xn) Y(x1,x2,...xn)}, где ф формула обладающая тем свойством, что только ее свободными переменными на доменах явл. различными переменными {x1,x2,...xn}. Выражение - исчисление с перем. на доменах эквив-ное заданному выражению исчисления с переменными картежа {t|Y(t)} строиться следующим образом: если t является кортежем кратности к, то вводиться t1,t2,..tk атомы R(t) заменяется атомами R(t1,t2,...tk) каждое свободное вхождение t[i] заменяется на t для каждого кванта Еu Vu вводиться m новых переменных на доменах u1,u2,...um. В области действия кванта Eu и Vu выполняется R(u) и заменяется на R(u1,u2,...um), U[i] на Ui. (Eu) заменяется на (Eu1)(Eu2)...(Eum). (Vu) заменяется на (Vu1)(Vu2)...(Vum) выполняется построение выражения {(t1,t2,...tk)Y’(t1,t2,...tk)} где Y’ ф-ла Y, где выполнены соответствующие замены.Пр. Пусть надо перевести формулу {t|R1(t)VR2(t)} {t1,t2,...tk|R1(t1,t2,...tk) V R2(t1,t2,...tk)} QBE(запрос по образцу - Query by Example) ISBL(Information System Base Language) Каждый из этих трех языков эквивалентен двум другим, однако языки исчисления это не процедурные языки поскольку их средствами можно выразить все, что необходимо и не обязательно указывать как это получить. Т. е. выражение в исчислении описывает лишь св-во желаемого результата, фактически не указывая, как его получить. Выражение реляционной алгебры наоборот специализирует обыкновенный порядок выражений операций. Каждому выражению реляционной алгебры соответствует выражение эквивалентное реляционного исчисления с переменными на доменах и выр-е реляцион. исчисления с переменными на кортежах. Классификация моделей данных Опр. Данные в концепции БД - это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или V другие факторы. Опр. Модель данных - это некоторая абстракция, к-ая будучи приложима конкретными данными позволяет трактовать их как информацию, т. е. сведенья, содержащие не только данные, но и взаимосвязь между ними. Инфологические (семантические) модели. -отражает в естеств. форме информац. -????. уровень абстрагирования. Используется на ранних стадиях проектирования для описания структур данных в процессе разработки приложения. Датологические модели поддерживаются конкретной СУБД. Документальные модели данных соответствует представлению о слабоструктурированной информации, ориентированной в основном на свободн. форматы документов или текстов на естествен. языке. Тезаурусные модели основаны на применении организации словарей; содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели используют в системах переводчиках.
Дескрипторные модели - использовались на ранних стадиях использования документальн. БД. Каждому документу соответствовал дескриптор т. е. описатель. Этот дескриптор имел жесткую стр-ру и описывал документ в соотв. с теми хар-ми, которые требуются для работы с док-ми, разрабатываемыми в БД. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-13- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Древовидные структуры: Опр. Дерево каждый узел которого может быть представлен одним и тем же типом записи называют однородным. (например генеалогическое дерево) Опр. Дерево в котором задан порядок следования узлов называется упорядоченным. (алгебраическое выражение) Опр. В неоднородных деревьях каждый узел представлен различными типами. Опр. Дерево называется сбалансированным если разница деревьев любых двух листьев, т. е. конечных вершин не превышает 1. Основные методы работы с древовидными структурами Сбалансированное дерево в котором каждый порождающий элемент имеет не более 2-х потомков наз-ся двоичным или бинарным деревом. направления от порождающего элемента дерева к порожденному элементу могут быть левыми и правыми. все узлы связанные с данным узлом посредством левой привязки образуют левое под дерево, а узлы связанные посредством правой привязки-правое поддерево. двоичные деревья очень удобны в работе. Построение двоичного дерева из произвольного Для каждого порождающего узла уничтожаются все исходящие из него ребра кроме самого левого все оторвавшиеся порожденные того же уровня связываются с левым поражденным указателями на подобные элементы Левое направление идет к узлу в котором размещена запись меньшая чем запись в порождающем узле, а правое направление ведет к узлу с записью имеющий больщий луч Для построения симметричного дерева необходима предварительная обработка исходной последовательности данных, которая выполняется в два этапа: 1 этап : исходная последовательность данных записи упорядоивается по возростанию или убыванию значений величины полей 2 этап : определяются ключи размещаемые в узлах различных уровней дерева в корневом узле разместится ключ расположенный в центре упорядоченной последовательности, т .е. ключделящий ее пополам. ключи делящие пополам левую и правую последовательности размещаются в узлах 2-го уровня левого и правого поддеревьев. Процедура деления вновь получаемых отрезков последовательности и отыскание ключей соответствующих уровней продолжается до тех пор пока дерево не будет построенно полностью. 10,7,21,33,37,34,36,40,80,90,50,52 7,10,21,33,34,36,37,40,50,52,80,90 36-корневой элемент Свойства: пути в дереве от корня до любой вершины имеют одинаковую минимальную длину Для характеристики степени приближения сбалансированого дерева к симметричному виду используют понятие ОБЬЕМ ДЕРЕВА: Сумма от n*L(n) где n меняется от 0 до N, Где N - количество уровней дерева, L(n)-число узлов на этом уровне Высота дерева определяется как максимальный уровень всех его вершин Уровень вершины (листа i) определяется длиной пути от корневой вершины до вершины i При обработке двоичных структур наиболее типичной яв-ся операция обхода Эта процедура при выполнении которой каждый узел обрабатываетс ровно 1 раз .произвольное бинарное дерево можно обходить восходящим нисходящим и смещанными обходами. способы обхода различаются точкой входа в дерево ,направлением движения по дереву, временем обработки корневого узла относительно первого обработанного. В роли корневого может выступать любой уровень дерева имеющий порожденный. В каждом случае это будет корень соответсвующего под дерева. Нисходящий обход: первым читается корень, узлы читаются в процессе движения вниз и влево ,если пути влево нет то движение продолжается по ближайшему правому пути, при этом сразу после просмотра очередного узла просматриваются слева на право исходящие из него ветви: 32,21,7,10,33,34,,52,37,50,80,60,90 Восходящий обход: чтение начинается с левого листа, каждый узел читается после того как прочитаны его левый и правый порожденные узлы. 10,7,33,34,21,50,37,60,90,80,52,36 Смешанный обход первым читается левый лист, затем следует последовательно подьемы и спуски, каждый узел читается лишь тогда когда полностью обойденно его левое поддерево, после чего обходится его правое под дерево. 7,10,21,33,34,36,37,50,52,60,80,90 В результате смешанного подхода получается последовательность упорядоченная по возростанию значений ключей. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-15- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Здесь имеются транзитивные зависимости: <Номер® кафедра ® телефон> <Номер® должность® оклад> Это ведёт к следующим аномалиям ( на примере атрибута «Телефон»): 1) Имеет место дублирование информации о телефонах для преподавателей одной кафедры. 2) Изменение номера кафедры влечёт за собой поиск и изменение телефонов всех преподавателей этой кафедры. 3) Нельзя включить данные о новой кафедре, т. е. название и номер телефона, если на данный момент ещё отсутствуют преподаватели и наоборот, при увольнении всех преподавателей с кафедры данные о ней нельзя сохранить. Для того, чтобы привести данное отношение к III нормальной форме, нужно устранить эти аномалии.
Преподаватель 1 Номер ФИО Должность Кафедра 102 Иванов доцент ЭВМ 103 Петров ассистент ЭВМ 104 Сидоров профессор АСУ 201 Фёдоров ст. преп. Физика Рассмотрим отношение «Курсовой проект»: Состоит из следующих атрибутов: Преподаватель Проект Студент Пр1 П1 Ст1 Пр2 П2 Ст2 Пр3 П3 Ст3 Пр4 П4 Ст4 Пр5 П5 Ст5 Пр6 П6 Ст6 Пр7 П7 Ст7 Курсовые проекты ведут несколько преподавателей и каждый студент закреплён за одним из них. Причём студент выполняет только один проект, а один и тот же проект могут выполнять несколько студентов, но у разных преподавателей. Между атрибутами отношения существуют функциональные зависимости: <Преподаватель ® Предмет® Студент> <Студент® Предмет> Это отношение находится в III нормальной форме, так как в нём отсутствуют частичные и транзитивные функциональные зависимости. Но здесь есть два факта, когда наблюдается зависимость части «Предмет» составного ключа от неключевого атрибута «Студент». Такая зависимость приводит к следующим аномалиям: 1) Замена студента требует просмотра всего отношения с целью поиска и изменения всех кортежей, содержащих данные о преподавателе этого студента. 2) Данные о студенте и его проекте не могут быть записаны в БД до тех пор, пока не назначен руководитель проекта. 3) Если необходимо удалить преподавателя, то будут удалены и данные о руководимом им студенте. Устранение этих аномалий достигается устранением функциональной зависимости части составного ключа от неключевого атрибута, т. е. зависимости <Студент® Предмет>. Имеем два отношения:
Определение. Зависимость, не заключающая в себе такой информации, которая не могла бы быть получена на основе других зависимостей из числа используемых при проектировании БД, называется избыточной функциональной зависимостью. Определение. Набор неизбыточных функциональных зависимостей, полученный путём удаления всех избыточных функциональных зависимостей из исходного набора с помощью шести правил вывода, называется минимальным покрытием. Полное множество правил вывода состоит из трех аксиом Армстронга, а также трёх следующих из этих аксиом правил объединения, декомпозиции и псевдотранзитивности. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-8- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Определение. Отношение находится в НФБК если оно находится в 3 нф и в нем отсутствуют зависимости первичных атрибутов от не первичных. Эквивалентное определение – все детерминанты находятся в НФБК, если все они являются возможными ключами. Проект_деталь (ДN, ПРN) Проект1(ПN, ПРN) Пример. Сном – номер студента Сфам – фамилия студента Кном – номер комнаты (у каждого одна) Тном – номер телефона (в каждой комнате по телефону) Курс – номер курса, посещаемого студентом
Оценка – оценка, полученная студентом за определенный курс Сном->Сфам Сном->Тном Сном->Кном Кном->Тном Сном, курс, семестр -> оценка Тном->Кном <Сном, курс, семестр> - один возможный ключ, определяющий все остальные атрибуты картежей. Детерминант – левая часть всех функциональных зависимостей в отношении, а именно: <Сном>,<Кном>,<Тном>,<Сном, Курс, Семестр> Для того, чтобы привести отношении к НФБК проводим декомпозицию. Выделяем транзитивные зависимости: (1) Сном->Кном->Тном (2) Сном->Тном->Кном Выделяем крайнюю правую зависимость (1) R(Сном, Курс, Семестр, Сфам, Кном, Тном, Оценка) R1(Кном, Тном) R2(Сном, Курс, Семестр, оценка, Сфам, Кном) R2 разбивается на R3, R4: R3(Сном, Курс, семестр, оценка) R4(Сном, Сфам, Кном) Отношения R1,R3,R4 находятся в НФБК. Каждый детерминант является возможным ключом. (2)Если выбрать функциональную зависимость Тном->Кном, то: R5(Тном,Кном) R6(Сном, Курс, Семестр, Оценка, Сфам, Тном) Отношение R6 разбивается на R7,R8: R7(Сном,Курс,Семестр,Оценка) R8(Сном,Сфам, Тном) Отношения R5,R7,R8 находятся в НФБК Определение. Многозначная зависимость существует, если при заданном значении атрибута x существует множество из 1 или более взаимосвязанных значений атрибута y, причем множество значений у не связано со значением атрибута u-x-y, где u – все множество атрибутов отношения. x->->y. Аксиомы. 1) Дополнение. Если xÍu, yÍu и x->->y, то x->->u-x-y 2) Пополнение. xÍu, y, v,wÍu и vÍw и имеется x->->y то wux->->vuy 3) Транзитивность. Если x, u,zÍu и x->->y, y->->z, то x->->z-y | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-6- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Аномалия удаления – если поставка ТОВАРА закончилась из БД придется удалить все сведения о ТОВАРЕ и его ЦЕНЕ, даже если он имеется в наличие у ПN. Аномалия обновления – при изменении цены товара необходим полный просмотр отношения с целью найти все поставки товара, т. е. изменение одного значения атрибута влечет необходимость изменения нескольких картежей. Причина аномалий – неполная функциональная зависимость. Разложение отношения ПОСТАВКИ на два устраняет неполную функциональную зависимость. ПОСТАВКА(ПN, ТОВАР) ЦЕНА_ТОВАРА(ТОВАР, ЦЕНА) Цена поставки определяется путем соединения двух отношений по атрибуту товар. Изменение цены товара вызовет модификацию лишь одного картежа второго отношения. Пример.
Деятельность_программиста(№программы – A, №проекта – B, название_программы – C, имя_программиста – D, количество_ рабочих_часов – E) Атрибут E функционально зависит от составного ключа (A, B) или от одного из следующих возможных ключей (B, C), (C, A), (C, D). Предполагается, что среди программистов нет однофамильцев и что две программы не могут иметь одинакового названия. * - первичные атрибуты элементов возможных ключей. ___ - первичные ключи (необходимы для идентификации картежа) Данное отношение находится во 2 нф, так как атрибут Е, единственный атрибут не являющийся основным полностью зависит от каждого возможного ключа. Для этого примера не рационально иметь возможными ключами атрибуты D, C так как могут появится однофамильцы или программы с одинаковым названием, более того, если в некоторый момент времени над программой никто не работает ее имя будет утеряно. Имя программиста также исчезает из БД если он не работает. Если убрать * против названий атрибутов D, C отношение перестает быть заданным во 2 нф.
Пример. Источник_снабжения(№поставщика - A, №партии_товара – B, имя_поставщика – C, сведения_о_поставщике – D, цена - E) Возможные ключи – A, B Атрибут А не определяется значением атрибута С. Атрибуты C, D не будчи основными функционально зависят от атрибута А, являющегося подмножеством составного ключа.
Аномалия удаления – если поставщик задерживает поставку, то удаление картежа соответствующего данному значению атрибута А вызовет удаление D.
Только Е полностью зависит от составного ключа. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-4- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Целостность данных. Данные, хранимые в БД, не должны противоречить заданным логическим ограничениям – это ограничения целостности. Явные ограничения – ограничения на атрибуты объекта. Связи ограничений: 1:1 («один к одному») 1:М («один ко многим») М:1 М:М Модели данных СУБД: Сетевые (в виде графов) Иерархические Реляционные (данные в виде таблиц отношений). Элементы реляционной модели (Э. Р.М.)
Схема – описание логической структуры БД. Если схема содержит значения элементов данных – это экземпляр схемы. Запись – такая структура, в которую можно помещать конкретные значения данных. Экземпляр записи – запись с конкретным значением данных. Подсхема – описание данных, которые используются в прикладной программе. Объекты – элементы, информация о которых сохраняется. Набор объектов – совокупность однородных объектов. Атрибут – свойство, характеризующее объект. В основе реляционной модели данных лежит математическая теория отношений. Массив данных представлен набором реляционных структур и образует реляционную БД. Схема РБД будет представлена набором схем отношений. R1(A11 , . . ., A1k) Aji – имя атрибута R2 (A21, . . ., A2l) Rj – имя отношения R3 (An1, . . ., Anm) Пусть А и В атрибуты отношения R, говорят, что атрибут В отношения R функционально зависит от атрибута А если в любой момент времени каждому значению атрибута А соответствует не более одного значения атрибута В: F : A®B ( В функционально зависит от А ) или A®B 1. Аксиома рефлексивности. ХÍU, YÍU, XÍY : Y®X 2. Аксиома пополнения. ХÍU, YÍU, ZÍU, X®Y, то XÈZ®YÈZ 3.Аксиома транзитивности. ХÍU, YÍU, ZÍU, X®Y, Y®Z, то X®Z 4.Свойство расширения. ХÍU, YÍU, X®Y, тогда для любого ZÍU : XÈZ®Y 5.Свойство продолжения. ХÍU, YÍU, ZÍU, WÍU, X®Y, то для люб. WÍZ :XÈZ®YÈW 6.Свойство псевдотранзитивности. ХÍU, YÍU, ZÍU, WÍU, X®Y, YÈW®Z, то XÈW®Z 7.Свойство аддетивности. ХÍU, YÍU, ZÍU, X®Y, X®Z, то X®YÈZ 8.Свойство декомпозиции. ХÍU, YÍU, ZÍU, ZÍY, X®Y, то X®Z | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-2- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
СЕТЕВАЯ МОДЕЛЬ ДАННЫХ (смд) В основе смд лежит возможность представления связей между данными в графической форме .наиболее развитой смд является КОДАСИЛ. В ОСНОВЕ ЭТОЙ МОДЕЛИ ЛЕЖАТ ПОНЯТИЯ Сущность и связь, а к основным типам структур данных относят элемент данных, агрегат ,запись, набор. Сущность это некоторая абстракция реально существующего обьекта, предметной области, процесса или явления. Набор однородных обьектов и явлений определяет тип сущности. каждый конкретный обьект в наборе представляет экземпляр сущности. связи между сущностями фиксируются заданным множеством отношений. при анализе связей часто используют бинарные связи, связи между двумя сущностями. Элемент данных-наименьшая еденица данных которой можно оперировать в базе данных и выполнять построение всех остальных структур. элемент данных представляет собой аналог поля. он имеет имя которое хранится в БД как часть описания БД. в сетевых моделяхэлементы данных используются для представления атрибута сущности. Агрегат данных-совокупность элементов данных имеющих общее имя, которое можно рассматриватькак единое целое. Пример агрегат данных ДАТА состоит из элементов данных ЧИСЛО МЕСЯЦ ГОД Запись - это совокупность элементов данных которые описывают конкретный обьект или сущность Пример сущность ТЕЛЕВИЗОР можно описать с помощью элементов данных МАРКА ИНДЕКС ЦЕНА пример ИЗУМРУД ТЦ-8 То есть понятие запись эквивалентно понятию картежа в реляционных моделях данных Тип представляет собой собрание экземпляров записи, каждый тип записи состоит из некоторого числа элементов данных значения которых размещаются а экземплярах записи данного типа. в качестве связей между типами записей используются наборы. каждый набор представляет собой отношение или связь между двумя или более типами записей. Он отображает множество связей между экземплярами записей типа владелец или член . Для каждого типа набора один тип записи может быть обьявлен ВЛАДЕЛЬЦЕМ, а остальные его членами, при этом любой экземпляр записи типа ЧЛЕН может быть связан не более чем с 1-м экземпляром типа ВЛАДЕЛЕЦ. При графической интерпритации сетевой модели данных вершина графа соответствует типу записи, а дугам - наборы отражающие связи. между соответствующими типами записей направленые стрелки на дуге ориентируются от записи типа владелец к записи типа клиент //рисунок последний Рассмотрим граф БД КОМПЛЕКТ ТЕЛЕВИЗОРА. стрелки соответствуют наборам данныхотражающих связи между записями, надписи над стрелками именам набора Как тип записи так и набор данных в общем случае могут быть представлены таблицами ,но в отличии от таблиц реляционных моделей в сетевой модели они могут допускать дубликаты строк или записей По характеру бинарной связи между типами сущностей различают ; 1:1(один к одному ),1:M(один ко многим),M:M(многие ко многим) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-16- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Иерархическая модель данных является наиболее простой среди всех дателогических моделей. Исторически они появились самыми первыми (среди дателогических моделей). Основными информационными единицами иерархической модели данных явл. БД, сегмент и поле. Поле данных определяется как тип, неделимая единица данных доступная пользователю с помощью СУБД. Сегмент - запись, при этом в рамках иерархической модели данных определяется 2 понятия данных: тип сегмента(тип записи), экземпляр сегмента(экземпляр записи). Тип сегмента - это поименованная совокупность типов эл-тов данных. Экземпляр сегмента образуется из конкретных значений полей или элементов данных. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородной записи. Для возможности различия отдельной записи в данном наборе каждый тип сегмента должен иметь ключ, или набор ключевых атрибутов. Ключом называют набор элементов данных однозначно идентифицирующих экземпляр сегмента. В иерархической модели сегменты объединяются в ориентированный двухуровневый граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами. Каждому экземпляру сегмента, стоящему выше по иерархии и соединенным с данным типом сегмента соответствует несколько экземпляров данного подчиненного типа сегмента. Тип сегмента находящегося на более высоком уровне иерархии называют логически-исходящим по отношениям к типам сегмента соединенными с данными направленными иерархическими ребрами, которые в свою очередь называются логически-подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-продуктами, а подчиненные сегменты называют сегментами-потомками. Схема БД: Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называют физической БД. Каждая физическая БД удовлетворяет следующим иерархическим ограничениям: 1. в каждой физической БД существует один корневой сегмент, т. е. сегмент у которого нет логически-исходного типа сегмента. 2. каждый логически-исходный сегмент может быть связан с производным числом логически-подчиненным сегментом. 3. каждый логически-подчиненный сегмент может быть связан только с одним логически-исходным сегментом. Сегмент является экземпляром типа сегмент. Пр. Группа (номер, староста) сегменты этого типа: 383, иванов 500, петров и т. д. Между экземплярами сегмента также существуют иерархические связи. Экземпляры потомки одного типа, связанные с одним экземпляром сегмента-предка называют близнецами. Пр. (по рис1.) экземпляры b1,b2,b3 являются близнецами, но b4 подчинен другому экземпляру родительского сегмента и он не является близнецом по отношению к экземпляру b1,b2,b3. Набор всех экземпляров-сегментов подчиненных одному экземпляру корневого сегмента называют физической записью. Количество экземпляров потомков-потомков может быть разным для разных экземпляров родительских сегментов. Поэтому в общих случаях физические записи имеют разную длину. Физические записи в иерархической модели различаются по длине и структуре. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-14- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Проекция: операция предназначена для изменения числа столбцов в отношении, т. е. в том случае, когда из строк кортежей требуется исключить какие-либо атрибуты, обозначены через j1,…,jn номера столбцов n-местного отношения R. Операция определения проекции отношения R обозначается через Пj1,…,jn(R), а сама операция заключается в том, что из отношения R выбираются столбцы и компонуются в указанном порядке j1,…,jn.
Ограничение: называют такую операцию, в которой отношения исследуют по строкам и выделяют множество строк удовлетворяющих данному условию, обозначим через r строку отношения R, а через q определим одно из отношений =,¹,<,£,>,³, тогда q ограничение между выбранным атрибутом А в ……………. и некоторой величиной C определяют следующим образом: R[AqC]={rÎR|r[A]qC}, где r[A] соответствуют значению атрибута А в строке r, т. е. q ограничение обеспечивает получение среди строк отношения R только тех строк в которых значение атрибута А и значение величины С удовлетворяют условию сравнения q.
Соединение: операция обратная операции проекции. Рассмотрим два отношения R1 и R2, где R1(A, B), R2(B, C). Соединение в отношении R1 и R2 называют операцию при которой соединяют два отношения используя в качестве признака соединения общий атрибут В.
Деление: R1¸R2=П1,2,…,n-m(R1)-П1,2,…,n-m((П1,2,…,n-m(R1)xR2)-R1) где n-это адрес отношения R1, m-R2, и n>m.
(П1,2(R1)xR2)-R1: O P P K П1,2(П1,2(R1)xR2) : O P R1¸R2
Реляционное исчисление- также как в реляционной алгебре, имеется набор понятий и операций, которые позволяют записывать любые отношения в виде формулы или формального выражения. Формулы в реляционном исчислении помимо арифметических операций =,¹,<,£,>,³ включают дополнительные логические операции. К ним относятся операции квантификации – квантор общности и квантор существования $, а также È,Ç,Ø. Формулы в реляционном исчислении строятся из атомов и совокупности арифметических и логических операций. Выражение реляционных исчислений с применением с переменными картежами может иметь следующий вид: {r|y(r)}, где r это кортеж, а y некоторая формула исчисления. Пример: {r|R1(r)ÇR2(r)}-означает, что необходимо получить множество всех картежей r, таких что они принадлежат одновременно к R1 и к R2. Формулы в реляционном исчислении строятся из атомов и совокупности операторов. Атомы бывают трех типов: 1) R(t) где R имя отношения. Этот атом означает, что t есть кортеж в отношении R. 2) S[i]qU[j], где S, U – переменные картежи, q - арифметический оператор j, i – номера или имена интересующих столбцов соответствующих картежей. S[i] – обозначение i-го компонента в картеже переменной S, U[j]- обозначение j-го компонента в в картеже переменной U. 3) S[i]qa, где а=const; при записи выражения в реляционном исчислении используется понятие свободных или связных элементов. Определение:Вхождение переменных х в формулу реляционного исчисления y(х) связно, если y находится в части формулы начинающейся квантором " или $, за которым непосредственно следует переменная х. В таких случаях говорят, что квантор связывает переменную х. В остальных случаях вхождение переменной х в формулу свободно. Пример: "x(R(x, y)È($y)R2(x, y,z)) – здесь переменная х связана, переменная у в отношении R свободна, а в отношении R2 связна, переменная z свободна. Понятие свободной переменной аналогично понятию глобальной переменной описанной вне текущей процедуры, А понятие связной переменной аналогично понятию локальной переменной. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-12- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
R(A,B,C) Метод синтеза основан на убеждении, что необходимо все функциональные зависимости с одинаковыми детерминантами выделять в группы и каждой группе отводить своё собственное отношение, полученные отношения проверяются на их соответствие н. ф.б. к. Данное отношение разделяем: R1(A,B), R2(C,B). Метод синтеза может быть исследован как самостоятельно, так и в сочетании с методом декомпозиции. Дополнительные правила выводаГоворят, что A®®B в R, если каждому значению A соответствует множество значений B никак ни связанных с другими атрибутами R. 1. Правило объединения: XÍU, YÍU, ZÍU, X®®Y, X®®Z, то X®®YÈZ. 2. Правило псевдотранзитивности: XÍU, YÍU, ZÎU, WÍU, X®®Y, YÈW®®Z, то WÈX®®Z - WÈY. 3. Правило декомпозиции: XÍU, YÍU, ZÍU, X®®Y, X®®Z, то X®®YÇZ, X®®Y-Z, X®®Z-Y. Схема отношения R будет находиться в 4-ой нормальной форме, если всякий раз, когда существует многозначная зависимость X®®Y, где Y не пустое множество и не является подмножеством X и XÈY состоит не из всех атрибутов R, тогда существует зависимость X® A для каждого атрибута A в R. П. Рассмотрим отношение Проф.(идент.№, курсы, дети, должность) Это отношение содержит данные о детях проф., читаемых им курсах и его должности. Имеет место многозначная зависимость: дети или курсы от атрибута идент.№®®курсы идент.№®®дети Каждому значению атрибута идент.№ должно соответствовать множество атрибутов дети или курсы соответственно. Для получения 4-ой нормальной формы нужно разложить: R1(идент.№, курсы) R2(идент.№, дети) R3(идент.№, должность) R1, R2, R3 находятся в 4-ой н. ф. 4-ая н. ф. показывает, что отношение может находится в н. ф.б. к. и тем не менее могут существовать некоторые аномалии. П. Если у проф. Появится ещё один ребёнок, в отношение необходимо добавить не один кортёж, а столько, сколько проф. читает курсов. Аналогичная ситуация возникает при появлении нового курса, читаемого профессором. Эти модификации необходимы для сохранения независимости между всеми возможными значениями атрибутов. Декомпозиция должна гарантировать обратимость, т. е. обеспечивать получение исходных отношений путём выполнения операций соединения над их проекцией. Обратимость предполагает, что: 1) Отсутствует потеря кортежей. 2) Не появляются ранее отсутствовавшие кортежи. 3) Сохраняются функциональные зависимости. Отношение может быть восстановлено без потерь соединением его проекций, если оно удовлетворяет зависимости по соединению. Говорят, что отношение находиться в 5-ой н. ф., тогда и только тогда, когда любая зависимость по соединению в R определяется возможными ключами R. Каждая проекция R содержит не менее одного возможного ключа, и по крайней мере один непервичный атрибут. П. Рассмотрим отношение R1(П№, Д№, отд) R2(П№, Д№) R3(Д№, отд) R4(П№, отд) П1 Д1 A П1 Д1 Д1 А П1 А П1 Д1 B П2 Д1 Д1 В П2 А П2 Д1 A П3 Д1 Д2 А П2 В П2 Д1 B П3 Д2 Д2 В П3 А П3 Д1 A П3 В П3 Д2 B П1 В П3 Д2 A П3 Д1 B В отношении R1 отсутствуют независимые многозначные зависимости и оно состоит только из первичных атрибутов, т. е. является полностью ключевым Þ оно находиться в 4-ой н. ф. Отношения R2, R3, R4 находятся в 5-ой н. ф., т. к. R1 удовлетворяет зависимости по соединению R2, R3, R4. Говорят, что схема R разложима без потерь на отношения R1, R2,…, Rk с сохранением функциональных зависимостей, если для каждого r из R, r может быть восстановлен соединением его проекций. r=r1[R1]* r2[R2]*…* rk[Rk], где * обозначает естественное соединение. Условие отсутствия потерь при соединении: если R1 и R2 являются результатом разложения R с сохранением множества функциональных зависимостей, то это разложение обеспечивает без потерь с сохранением функциональной зависимости, тогда и только тогда, если R1 Ç R2®(или ®®)R1-R2, либо R1 Ç R2®®R2-R1. Операции пересечения и разности определены над именами атрибутов отношения. П. Пусть заданы схемы отношений “Служ.” и функциональные зависимости устанавливающие, что каждый служащий может работать лишь в одной организации и жить лишь в одном городе: Служ.(№, отд., гор.) №®отд. №®гор. Рассмотрим два разложения: 1) Е1(№, отд. ) Е2(№, гор.) Если мы возьмём Е1ÇЕ2=№ Е1-Е2=отд. Е2-Е1=гор. №®отд. №®гор., т. е. данное разложение без потерь. 2) Е1(№, отд.) Е2(отд., гор.) Е1ÇЕ2=отд. Е1-Е2=№ Е2-Е1=гор. отд.®№ отд.®гор., т. к. отделение определяет № и гор., то это разложение с потерями. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-10- | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Инфологическое моделирование. Связано с попыткой представления семантики предметной области модели БД. Хаммер 1981, Шипман 1981 - не применяются. Чен 1976 - модель сущность-связь "ER"-модель(Entity Relationship). Сущность - с её помощью моделируется класс однотипных объектов - это некоторая абстракция реально существующего объекта, процесса или явления, о котором необходимо хранить информацию в системе. Сущность имеет имя уникальное в пределах модельной системы. В системе существует множество экземпляров данной сущности. z Объект, которому соответствует понятие сущности имеет свой набор атрибутов, то есть характеристик, определяющих свойство данного представителя класса. При этом набор атрибутов должен быть таким, чтобы можно было различать конкретные экземпляры сущности. Пример. Пусть есть сущность "сотрудник" (таб. Номер, фамилия, имя и тд.). Набор атрибутов однозначно идентифицирующий конкретный экземпляр сущности называется ключевым. В данном случае ключевым будет атрибут таб. Номер. Экземпляры сущности сотрудник будут содержать описание конкретного сотрудника предприятия. Графическое обозначение для сущности: Сотрудник: -Таб. номер -Фамилия -Имя Между сущностями могут быть установлены связи - бинарные ассоциации, показывающие каким образом сущности соотносятся или взаимодействуют между собой. Связи могут существовать между двумя разными сущностями или между сущностью и ей же самой, т. е. рекурсивная связь. Студент: -№ зачетки -ФИО -группа препод: -Таб. номер -ФИО -кафедра Связь студент(слушатели лекции)-преподаватель(читает лекции)(много ко многим). Связь преподаватель(руководит)-студенты(пишут диплом)(один ко многим). Связи делятся на 3 типа: 1. один к одному; 2. один ко многим; 3. многие ко многим. Один к одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности. Связь один ко многим означает, что один экземпляр одной сущности связан с несколькими экземплярами другой сущности. Связь многие ко многим означает, что один экземпляр первой сущности может быть связан с несколькими экземплярами другой сущности и наоборот. Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками. Связи любых из этих типов могут быть обязательны, если в данной связи должен участвовать каждый экземпляр сущности и необязательными, если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-17- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Команды языка запросов SQL (Structed Qwerty Language) Создание БД. CREATE DBF <DBF-файл> (<имя поля> <тип> [(<размер> [<дробных разрядов>])) [, <имя поля>…] / FROM ARRAY <массив>] Данная команда создает новую БД с указанным именем. Для каждого поля задаются его имя, тип (C, N, D, M, F, L), длина и число десятичных разрядов. Длина и точность не задаются для типов DATA; Log; примечания(M). Точность не задается для символьного типа. Созданная БД сразу открывается. INSERT INTO <файл БД> [(<поле1> <поле2>[,…] )] VALUES (<выр1>[,< выр2>[,…]] ) Данной командой добавляются записи в конец существующего файла БД. Если опущены имена полей, указанные выражения будут записываться последовательно в поля БД в соответствии с ее структурой. INSERT INTO <файл БД> FROM ARRAY FROM MEMVAR, Т. е. команда INSERT соответствует паре команд APPEND BLANK REPLASE Пр. INSERT INTO stud (fam, kurs) VALUES (‘Иванов’, ‘1’) Данная команда позволяет дополнить БД stud новой записью для полей fam, kurs. Дополненная БД может быть и не открыта в момент выполнения команды, но после этого она остается открытой и активной. Формирование запросов из БД (1) SELECT [DISTINCT] [<псевдоним>] <выражения> [AS <колонка>] [, [<псевдоним>] <выражения> [AS <колонка>]…] FROM <БД> [<псевдоним>] [, <БД>][<псевдоним>] [, …]] (2) [[INTO <получатель> ] / [TO FILE <файл> [ADDITIVE]]] (3) [NOCONSOLE] [PLAIN] [NOWAIT] [WHERE] <условия связи> [AND <условия связи>…] [AND/OR <условия отбора>…]]] (4) [GROUP BY <колонка> [, <колонка> [,…]][HAVING BY <условие отбора>][ORDER BY <колонка> [ASC/DESC][, <колонка> [ASC/DESC][,…]]]] (1)Указание результатов выборки и источников данных. Здесь указывается, что и откуда берется выборочно. Перед словом FROM перечисляются отбираемые выражения, а после перечисляются имена баз, из которых берутся данные. Выражение может быть полем записи из БД, константой, функцией от переменной и т. д. Если выражение является именем поля, то оно может быть создано. Псевдонимом может быть любое другое имя, которое может быть присвоено команде SELECT. Это задаваемое временное имя указывается в опциях «псевдоним» после слова FROM. За пределами команды SELECT такое назначение никаких последствий не имеет. Если необходимо построить выборку и всех полей БД, вместо их перечня можно использовать *. В результате выполненной выборки получается совокупность колонок, заголовками которых могут быть имена полей. Если имена колонок совпадают, то такие колонки получают имена, к которым присоединяется одна из букв по алфавиту (TAB_A, TAB_B, TAB_C …). Аналогичным образом даются имена колонкам, полученным в результате вычисления выражения. Их имена состоят из слова EXP и послед. чисел (EXP_1, EXP_2). Исключение представляют выражения, использующие собственные функции SQL (MIN, MAX). Имена колонок в этом случае будут включать имена функций. Если не устраивают имена, формируемые по умолчанию, то можно создать свое имя с помощью оператора <выражение> AS <новое имя колонки> включение опции исключает возможность вывода одинаковых строк выборки. (2)Получатель может быть БД, массив, текстовый файл, экран и принтер. Информация может быть переслана в так называемый курсор. Курсор – это временный набор данных, который может быть областью памяти и временным файлом. Имеет режим только для чтения. Данные курсора могут быть представлены в команде BROWSE, напечатаны, из них могут быть образованы меню. Курсор может быть обработан другой командой SELECT, к колонкам курсора обращаются по имени этих колонок. INTO <получатель> ARRAY <массив> CURSOR <имя курсора> DBF / TABLE <имя> Выборка не выдается на экран – NO CONSOLE. PLANE - заголовки колонок не выделяются. NOWAIT – не делаются паузы при заполнении экрана. ADDITIVE – выборка будет добавлена в конец существующего файла без его перезаписи. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-19- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Многотабличный запрос Одна из особенностей запроса SQL явл их способность определять связи м-ду несколькими таблицами и выводить инф из них в терминах этих связей. Такие о-ции называют обьединением. Исп-я объединения, происходит непосредственное связывание инф-ции с любым № таблицы и т о создать связи м-ду сравниваемыми частями данных. При многотабличном запросе табл, представленные в виде списков предл. FROM отдельно друг от друга запятой. Предикат запроса может ссылаться к любому столбцу любой связанной таблицы. Обычно предикат сравнивает зн-я столбца различных таблиц. Чтобы опр-ть, удовлетворяют ли WHERE установл. условию SELECT TEACHER . TFAM, PREDM, TNAME FROM TEACHER, PREDMET WHERE TEACHER TNUM=PREDM. TNUM Эти таблицы уже были соединены через поле TNUM. Эта связь наз состоянием справочной целосности. Используя такое обьединение, можно извл данные терминов этой связи, обьед. многотабл. запросов которые исп. предикаты, основ. на равенствах, называют обьединения Та же самая методика м\б использована для обьединения вместе 2х одиночной таблицы. Например допускается изобразить объединение таблицы с собой как объединение 2х копий одной и той же таблицы, причем она на самом деле не копируется, но SQL выполняет команды так, как если бы это было сделано. Когда объед. таблицы с собой все повторяемые имена столбцов заполняются префиксными именами таблицы. Это можно сделать с пом-ю опр-я временных имен, наз псевдонимами. Выведем список студентов с одинаковым р-ром стипендии. SELECT first. sfam, second. sfam, third. sstip FROM students first, student second, students third WHERE first. sstip=second. sstip В данном запросе SQL работает так как если бы он соединял 3 разных таблицы. Псевдонимы могут исп в предложении SELECT до их объявления в предложении FROM, но SQL может отклонить команду если они не будут определены далее в запросе. Псевдоним Е-ет только тогда когда команда выполняется. Псевдонимы должны исп в любое время для создания альтернативных имен для таблиц запросов, например, в случае, если таблицы имеют длинные и сложные имена. Допускается исп любое число псевдонимов для одной таблицы запросов, хотя, как правило, более 2-3 не исп. В SQL предусмотрено создание объединения, к-ое вкл различные таблицы и псевдонимы одиночной таблицы. Пусть необходимо сделать запрос на объединение табл с данными об успеваемости для того чтобы найти учебные предметы которые сданы более чем одним студентом и таблицу учебных предметов. SELECT predmet. pname , first. snum, second. snum FROM students first, students second, predmet WHERE predmet. pnum=first. pnum, first. snum=second. pnum PNAME SNUM SNUM В выводе имеем: пару № студентов, сдавших тот или иной предмет, опр по названию таблицы учебных предметов. Т о операция объединения в SQL соединяет инф-цию из 2х таблиц, формируя пары связанных строк из них. Объед. таблицу обр. парой тех строк из различных таблиц, у кот в связанных столбцах содержатся одинак зн-я. Если строка одной из таблиц не имеет пары, то объединение может привести к некорректным результатам. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-21- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
МОДЕЛИ ТРАНЗАКЦИИТранзакцией называется последовательность операций, производимых над б/д и переводящих б/д из 1 непротиворечивого, т. е. согласованного, состояния в другое непротиворечивое состояние. Т. е. транзакцию можно рассматривать как логическую единицу работы системы. Существуют различные модели транзакции, которые могут быть классифицированы на основе различных свойств, включающих структуру транзакции, параллельность внутри транзакции, продолжительность и т. д. В настоящее время существуют следующие типы транзакции: плоские или классические (традиционные) транзакции; --цепочечные; --вложенные; Классические или традиционные транзакции характеризуются следующими свойствами: -атомарности (atomicity) -согласованности (consistency) -изолированности (isolation) -долговечности (durability) Иногда традиционные транзакции называются асидтранзакции (asid) Свойство атомарности выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе. Свойство согласованности гарантирует, что по мере выполнения транзакции данные переходят из 1 согласованного состояния в другое, т. е. транзакция не разрушает взаимной согласованности данных. Свойство изолированности означает, что конкурирующие за доступ к б/д транзакции физически обрабатываются последовательно, изолированно друг от друга. Но для пользователей это выглядит так, как будто они выполняются параллельно. Свойство долговечности - если транзакция завершена успешно, то те изменения данных, которые были ей произведены, не могут быть потеряны даже в случае последовательных ошибок, т. е. не при каких обстоятельствах. Фиксация транзакции - действие, обеспечивающее запись на диск изменений в б/д, которые были сделаны в процессе выполнения транзакции. До тех пор, пока транзакция не зафиксирована, допустимо аннулирование изменений, восстановление б/д в то состояние, в котором она была на момент начала транзакции. Фиксация транзакции означает, что все результаты выполнения транзакции станут видимы другим транзакциям. Откат транзакции - действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны в теле текущей незавершенной транзакции. Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создана некоторая системная структура, называемая журналом транзакции. Он предназначен для обеспечения надежного хранения данных в б/д. Общей целью журнализации изменений б/д является обеспечение возможности восстановления согласованного состояния б/д после любого сбоя. Параллельное выполнение транзакций Параллельное выполнение транзакций должно удовлетв. след. условиям: 1. В ходе выполнения транзакции пользователь видит только согласованные данные. 2. Когда 2 транзакции выполняются параллельно, СУБД гарантирует независимое выполнение. Это называется сериализация транзакций. Обычно выполняется с помощью механизма блокировок. Самый простой способ – блокировка (синхронизационный захват) объекта на все время выполнения транзакции. Также может быть блокировка на уровне страниц. Типы блокировок (захватов): 1. Совместный (shared). Нежесткая блокировка. Выполняется при чтении объекта. 2. Жесткая (exclusive). Монопольный захват объекта для операции записи. Возможны тупики. Основой их обнаружения является построение графа ожидания транзакции. Потом одной из транзакций (самой дешевой) жертвуют – для нее выполняется откат. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-23- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Файловые структуры, используемые для хранения данных. Файлы: 1. прямого доступа 2. последовательного доступа 3. индексные 3.1 плотный индекс – индексные прямые. 3.2 неплотный индекс – индексно-последовательные. 3.3 в деревья 4. инвертированные списки 5. взаимосвязанные фалы 5.1 с однонаправленными цепочками 5.2 с двунаправленными цепочками Файлы прямого доступа – это фалы с постоянной длинной записи. Файлы последовательного доступа - это фалы с переменной длинной записи. Индексно-прямые файлы – в этих файлах основная область содержит последовательность записей одинаковой длинны, расположенных в произвольном порядке. Структура индексной записи имеет вид:
Значение ключа - это значение первичного ключа Номер записи – порядковый номер записи в основной области. В этих файлах для каждой записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа. Неполный индекс строится для упорядочения записи. Структура записи:
В индексной области ищется!3 блок по заданному значению первичного ключа. Т. к. все записи упорядочены, то значение первой записи блока, позволяет быстро определять, в каком блоке находится искомая запись. Способы размещения с применением Хэш-функции.Ф-ия, осуществляющая действие над ключом и генерирующая адрес записи наз. Ф-ями преобразования. ХФ преобразует последовательность цифр, определяющих последовательность ключа записи, в результате чего получается хэш-адрес, по которому записи размещаются и записываются. ХФ должна обеспечивать однозначное преобразование ключа записи в ее адрес, причем адреса должны как можно более равномерно распределяться по области памяти, выделенной для хранения данных. ХФ не должна быть очень сложной, т. к. время необходимое для выполнения преобразования дополняется временем работы основной программы. Хорошей считается такая ХФ, которая быстро генерирует уникальные и достаточно равномерно распределенные адреса. Даже хорошая ХФ не устраняет возможности получения одинаковых адресов. В этом случае возникают коллизии, т. е. ситуации, когда различные записи получают одинаковый адрес. Методы разрешения коллизии: 1.использование полученного адреса в качестве начальной точки для последовательного просмотра следующих адресов. С этого адреса начинается поиск свободного адреса в памяти. 2. Адрес считается не адресом хранения одной конкретной записи, а областью памяти, в пределах которой, размещаются все записи, получившие этот адрес. В пределах этой области записи могут размещаться последовательно, в порядке поступления. Если со временем область окажется заполненной, в памяти выделяется новая область, связанная с предыдущей указателем. ХФ может генерировать как абсолютный адрес области и относительный. Пример ХФ: Ф-я основана на методе деления и определяется в виде: h(x)= kmodm+1, где m-делитель. Для вычисления h(x) ключ записи k делится на m и остаток от деления увеличивается на 1. (m=101 при k=2000, 2001, 20017 получаем h(x)=82, 83, 99). Эти же самые адреса окажутся сгенерированными h(x) для k=3313, 3314, 3330., т. е. для этих адресов возникает коллизия. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-25- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Многомерные модели Можно выделить 2 направления: 1. системы оперативной транзакционной обработки. 2. аналитической обработки или системы поддержки принятия решений Реляционные предназначались для информационных систем оперативной обработки информации. В области аналитической обработки информации более эффективны многомерные СУБД. Основные понятия: Агрегируемость: означает просмотр информации на различных уровнях. Ее обобщение. Степень детальности информации зависит от ее уровня. Историчность: обеспечение высокого уровня статичности данных и их взаимосвязи, а также обязательность привязки данных ко времени. Статичность позволяет использовать при обработке данных специальные методы загрузки, хранения, индексации, выборки Прогнозируемость: задание функции прогнозирования, и применение ее к различным временным интервалам. Многомерность модели означает многомерное логическое представление структуры информации при описании и при операциях манипулирования данными. Обладает более высокой наглядностью и информативностью по сравнению с реляционной. Данные представляют собой срезы из многомерного хранилища Измерение: это множество однотипных данных, представляющих одну из граней гиперкуба. Например – временное измерение. Ячейка: значение, которое однозначно определяется фиксированным набором измерений. Тип поля обычно цифровой. Поликубическую модель поддерживает Oracle. Операции: 1. Формирование среза. Срез – подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. 2. Вращение. Применяется при двумерном представлении данных. Суть заключается в изменении порядка измерения при визуальном представлении данных. 3. Агрегация и детализация. Переход к более общему или более детальному представлению данных. Основное достоинство модели – эффективность аналитической обработки данных больших объемов, связанных со временем. В реляционной модели происходит нелинейный рост трудоемкости в зависимости от размера. Недостаток: громоздкость модели для простых задач. Объектно ориентированная модель. В этой модели при представлении данных имеется возможность иденитифицировать отдельные записи базы данных. Структура о-о БД может быть представлена как дерево, узлами которого являются объекты. Свойства объектов описываются некоторыми стандартными типами или пользовательскими классами. Логически структура похожа на структуру иерархической БД. Основное отличие между ними состоит в методах уринзирования (?) данными. Логическая структура ООБД: Рисунок какой-нибудь на тему:
Суть в том, что поле внутри записи может быть классом, и содержать внутри сложную структуру. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-27- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Зарегистрированные классы имеют полный набор методов. Автоматически наследуют методы управления объектов от системного класса. Экземпляры существуют временно в памяти процесса. Их называют временными объектами. Созданием новых объектов, зарегистрированных классов и управлением их размещения в памяти занимается Cache. Наследуются от Library Registered Object. Допускают полиморфизм. Встраиваемые классы могут храниться не только временно в памяти, но и продолжительное время в БД. Эти классы наследуют свое поведение от класса Library Serial Object. Главное в их поведении – то, что экземпляры в памяти существуют как независимые объекты и могут быть сохранены в БД лишь будучи встроенными в другие объекты. Хранимые классы обеспечивают длительное хранение экземпляра в БД. Наследуются от Library Persistent. Экземпляры обладают однозначными объектными идентификаторами и могут независимо храниться в Cache. Когда хранимый объект используется как свойство класса говорят о ссылке на хранимые объекты. Элементы класса: 1. Название 2. Ключевые слова 3. Свойства, то есть элементы данных, хранящихся в классе. Могут быть константами, встроенными объектами и ссылками на хранимые объекты. Классы типов данных не содержат свойств. При доступе к свойствам возможно изменение формата и другое преобразование. Объекты, на которые делаются ссылки автоматически загружаются в память. Свойства могут быть public и private. 4. Методы, то есть код, реализующий те или иные функциональные возможности. 5. Параметры класса, значения, осуществляющие формирование класса во время компиляции. 6. Запросы, то есть операции с множеством операций класса. 7. Индексы – структуры, оптимизирующие доступ к объектам. Типы данных реализуются классами. Классы могут 1. Выполнять преобразование данных между форматами, хранимыми в БД, памяти, памяти и отображаемыми. 2. Отвечают за проверку значений 3. Обеспечивают взаимодействие с SQL, Java, ActiveX. Отличия от классов объектов. 1. Невозможно образование экземпляров 2. не могут содержать свойств 3. методы предоставляются программисту через интерфейс типов данных 4. Имеет методы проверки значений. Коллекция Свойства, обладающие множеством значений могут быть представлены в Cache в виде коллекций. Могут содержать константы, объекты, и ссылки на объекты. Коллекция массив: каждый элемент упорядочивается по ключу. Коллекция список: в качестве ключа выступает позиция элемента.
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-29- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-31- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Общие принципы восстановления: 1/ результаты, зафиксир-нные в транзакции д/б сохранены в восстановленном состоянии б/д; 2/ результаты незафиксированной транзакции должны отсутствовать в восстановленном состоянии б/д. Возможны следующие ситуации, при которых требуется производить восстановления состояния б/д: 1/ индивидуальный откат транзакции - этот откат должен быть применен в следующих случаях: а) стандартная ситуация отката транзакции; в) аварийное завершение работы прикладной программы; с) принудительный откат транзакции в случае взаимной блокировки при параллельном выполнении транзакции. 2/ восстановление после внезапной потери содержимого ОП (мягкий сбой) Ситуация возникает в следующих случаях: а) при аварийном выключении электрического питания; в) при возникновении неустранимого сбоя в процессе. 1/ восстановление после поломки основного внешнего носителя б/д (жесткий сбой). Основой восстановления является архивная копия и журнал изменения б/д. Во всех случаях восстановление основано на избыточном хранении данных. Возможны 2 варианта ведения журн. информации: 1/ для каждой транзакции поддерживается отдельный локальный журнал изменений б/д этой транзакции. Такие журналы называются локальными. Они используются для индивидуальной откатки транзакции. Кроме того поддерживается общий журнал изменений б/д, используемый для восстановления состояния б/д после мягких и жестких сбоев. Этот подход позволяет быстро выполнить индивидуальный откат транзакции, но приводит к дублированию информации локальных и общих журналов. Поэтому чаще всего используют вариант поддержки только общего журнала изменений б/д. Общая структура журнала условно может быть представлена в виде некоторого последовательного файла, в котором фиксируется каждое изменение б/д, которое происходит в ходе выполнения транзакции. Каждая запись в журнале транзакции помечается номером транзакции, к которой относится и значениями атрибутов, которые она меняет. Для каждой транзакции в журнале фиксируется команда начала и завершения транзакции. Для большей надежности журнала транзакции часто дублируются с системными средствами и, как правило, объем внешней памяти во много раз превышает реальный объем данных, которые хранятся в хранилищах. Существует 2 варианта ведения журнала транзакции: 1/ протокол с отложенными обновлениями; 2/ протокол с немедленными обновлениями. Существует вариант поддержки отдельного короткого журнала постраничных изменениями. Процедура согласованного выполнения параллельной транзакции должно удовлетворять правилам: 1/ в ходе выполнения транзакции пользователь видит только согласованные данные, пользователь не должен видеть промежуточных несогласованных данных; 2/ когда в б/д 2 транзакции выполняются параллельно, то СУБД поддерживает принцип независимого выполнения транзакции, который означает, что результаты выполнения транзакции будут такими же, как если бы сначала выполнялась транзакция 1, а потом транзакция 2 и наоборот.. Такая процедура называется сериализация транзакции. Способ выполнения набора транзакции называется сериальным, если результат совместного выполнения транзакции эквивалентен результату некоторого последовательного выполнения этих же транзакций. Наиболее распространенным механизмом для реализации сериализации транзакции является механизм блокировок. Самый простой вариант - блокировка объекта на все время действия транзакции. После окончания транзакции все заблокированные объекты становятся доступными другими транзакциями, т. е. разблокируются. Также реализована блокировка на уровне страниц. В этом случае блокируется только отдельные страницы на диске, когда транзакция обращена к ним. Для повышения параллельного выполнения транзакции используется комбинирование разных типов захвата. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-24- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Иерархическая модель данных. Самая простая. Появилась первой. Основные информ. единицы база данных, поле, сегмент. Поле – мин. и независимая единица данных, доступная пользователю с помощью СУБД. Сегмент (DBTS) - называется записью. Тип сегмента – поименованная совокупность типов данных. Экземпляр сегмента образуется из конкретных значений полей. Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Каждый тип сегмента может иметь ключ. Сегменты объединяются в древовидный орграф. Тип сегмента, нах-ся на более высоком уровне иерархии называется лог. исходным по отношению к типам сегмента под ним.(лог. подчиненным). Схема иерархической БД представляет собой совокупность отдельных деревьев. Каждое дерево в рамках модели называется физ. БД и удовлетворяет следующим ограничениям: 1. Существует 1 корневой сегмент 2. Каждый лог. Исх. Элемент м. б. связан с любым числом подчненных. 3. Каждый логически подчиненный сегмент м. б. связан только с одним родительским. Сегмент является экземпляром типа сегмента. Между экземплярами сегмента также существует иерархическая связь. Близнецы – потомки одного типа с одним предком. Набор всех экземпляров сегмента в одном дереве наз-ся физ. Записью Совокупность физических БД образует концептуальную БД. Для организации физического размещения используются следующие группы методов: 1. Представление линейным списком с последовательным распред. Памяти 2. Нелинейным списком Основное правило контроля целостности: потомок не может существовать без родителя, а у некоторых родителей не может быть потомка. Механизмы поддержания целостности между отдельными деревьями отсутствуют. (+) 1. Эффективное использование памяти ЭВМ 2. Высокая скорость операций над данными 3. Удобно для работы с иерархически упорядоченными данными Громоздко для обработки инф-ции с достаточно сложными иерархическими связями. Пример такой БД – сеть магазинов. Сетевая модель данных Базовые объекты модели: элемент данных, агрегат данных, запись, набор данных. Элемент данных – это минимальная информационная единица, доступная пользователю. Аналог поля. Агрегат данных – совокупность элементов данных, имеющих общее имя, которые могут рассматриваться как единое целое. В модели определены агрегаты двух типов: вектор и повторяющаяся группа. Вектор – минимальный набор элементов данных. Пример(Адрес: дом улица кварт. город) Группа – совок-ть векторов Пр: Стипендия – повторяющаяся группа с числом повторения 12. Запись – совокупность агрегатов или элементов данных, аналог сегмента или кортежа. Существует понятие типа записи и экземпляра записи. Набор – 2х уровневый граф, связывающий 2 типа записей видом 1:M. Набор отражает иерархическую связь между двумя типами записи. Родительский тип записи – владелец набора. Дочерний – член. Существенным ограничением является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора. Пример: учителя и группы Среди всех наборов определяется сингулярный набор, владелец которого – вся система. Обозначается входящей стрелкой. (+)Высокие возможности по созданию сложных иерархических структур Возможность эффективной реализации по затратам памяти и оперативности (-) Высокая сложность и жесткость схемы БД Сложность для понимания и обработки информации в БД Ослаблен контроль целостности |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-22- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(3)Критерии отбора данных. Условия связи применяются в случае, если выборка делается более чем из одной БД и указывается критерий, которому должны отвечать поля из разных БД. В условии связи указываются поля из разных БД. Допускается несколько критериев, соединенных AND и операторов =, <, >, <=, >=. Условие отбора строится аналогично, но из выражения только для одной БД. Допускается использовать OR, NOT. Условия могут содержать несколько операторов SQL. LIKE – позволяет построить условие сравнения по шаблону. <выражение> LIKE <шаблон> При использовании LIKE используются “_”, “%”. “_” указывает единственный неопределенный символ в строке; “%” указ. любое их количество. <выражение> BETWEEN <нижнее значение> AND <верхнее значение> - проверяет, находится ли выражение в указанном диапазоне. <выражение> IN (<выражение>, <выражение> …) – проверяет, находится ли выражение, стоящее слева от IN, среди перечисленных справа от него. (4)Группирование данных. Group by<kolonka>[,<kolonka>,…] в этой опции зад. Колонки, по кот. Производим группирование вх. Данных. все записи базы для которых зн-я колонок совпадают, отобр в выборке одной строкой HAVING<условие отбора>-критерии отбора данных ORDER BY<колонка>[ASC/DESC][,<колонка>[ASC/DESC]…]- Задаёт сортировку по заданной колонке ASC по возрастанию, DESC-по убыванию. Df сортировка вып по возрастании. SELECT s. fam, s.kurs, t.fam, t.kurs FROM stud. s,TEACHER T WHERE s. kurs=t. kurs. В рез выполнения данного запроса происх выборка всех фамилий и № курса из БД Stud. dbf в соответствии с выборкой из БД teacher для записи, у которой совпадают № курсов Здесъ для БД Stud u Teacher заданы новые временные переменные s u t. Сами колонки при этом получат имена FAM_A KURS_A FAM_B KURS_B. Если хотим задатъ собств имена колонок, а не исп задаваемые DF, необходимо полъзоватся опцией AS: SELECT FAM AS FAMYLIA, KURS AS N_KURS FROM STUD ORDER BY FAM. Если нужно вывести сформированное выражение и отсортированное в др БД, кот затем будет открыта в текущей раб области ,здесь нужно нужно добавить, куда именно отправлять наше зн-е :INTO TABL STUD1.Запросы, кот исп в качестве источника данных только одной таблицы, носят название однотабличн. запросов. В случае выбора информ из нескольких таблиц, одним из вариантов явл обьъдинение результатов неск запросов, вып независимо друг от друга. Для размещения неск запросов вместе и обьединения их вывода исп приложение UNION, обьединяющее вывод 2х и более SQLзапросов в единый набор строк и столбцов БД Students Teacher Predm Usp Sfam tfam pnum ocenka Simya timya pname udate Sotch totch tnom unom Sstip tnum kurs snum Snum tdata hours pnum Для получения списка всех студентов и преподов фамилии которых закл между буквами К и С, можно воспользов сл запросом:SELECT SFAM SIMYA FROM STUD WHERE SFAM BETWEEN ‘K’ AND ‘C’ UNION SELECT FROM TEACHER WHERE TFAM BETWEEN ‘K’AND ‘C’.Когда 2 или более запроса подвергаются обьединен их столбцы вывода д\б совместимы для обьединения. Это значит что для каждого запроса необходимо включение одинакового числа столбцов в том же порядке что и 1,2,3 и т д. При этом должна присутствовать совместимость типов, например символьное поле должно иметь одинаковое число символов, нельзя исп агрегатные ф-ции предл SELECT в случ запроса в обьединении. Предложение UNION будет автоматически искл дубликаты строк из вывода. Исп-я Опцию order by можно упорядочить вывод из обьединения. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-20- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Power designer- принято за графическое обозначение. О - необязательные связи. Обязательные связи обозначаются перпендикулярной линией, перечеркивающей - интерпретируется, что по крайней мере один экземпляр сущности участвует в этой связи. В ER-м допускается принцип категоризации сущности. Это означает, что вводится понятие подтипа сущности, т. е. сущность может быть представлена в виде двух или более своих подтипов сущности, каждый из которых может иметь общие атрибуты и отношения которые однажды определятся на верхнем уровне и наследуются на нижнем. Все подтипы одной сущности рассматриваются как взаимно исключающие и при разделении сущности на подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Сущность на основе которой строятся подтипы называется супертипом. Для графического обозначения принципа категоризации сущности вводится специальный графический элемент - узел дискрименант. Правила преобразования модели сущности-связь в реляционную модель. 1/ Каждой сущности ставится в соответствие отношение реляционной модели данных, при этом имена сущностей и отношений могут быть различны, потому что на имена сущности могут не накладываться дополнительные ограничения кроме уникальности имени в рамках модели. 2/ Каждый атрибут сущности становится атрибутом соответствующего отношения. 3/ Первичный ключ сущности становится первичным ключом соответствующего отношения. В каждое отношение, соответствующее подчинённой сущности, добавляется набор атрибутов основной сущности, являющимися первичным ключом основной сущности. 4/ Для отражения котегоризации сущности, при переходе к реляционной модели возможны несколько вариантов представления : А) возможно создать только одно отношение для всех подтипов одного супертипа. В него включают все атрибуты всех подтипов. Достоинством такого представления является то, что создаётся всего одно отношение. Б) Для каждого подтипа и супертипа создаются свои отдельные отношения. Недостатки такого способа представления: создаётся много отношений, но достоинство такого способа в том, что можно работать только с означенными атрибутами подтипа. Теория нормализации применима к модели сущность - связь. Алгоритм приведения модели ER к пятой нормальной форме. Основное назначение модели сущность-связь состоит в семантическом описании предметной области и представления информации для обоснования выбора видов модели и структур данных, которые в дальнейшем будут использоваться в системе. Бинарные модели основаны на использовании бинарных отношений для описания предметной области. Вершины графов бинарной модели называются категориями, а дуги - бинарные отношения категорий. Студент - учится у преподавателя. Преподаватель - обучает. Обоим направлениям бинарной модели присваиваются уникальные имена, которые присваиваются функции доступа. 1функция. Студент учится у преподавателя. Обратная функция преподаватель обучает студента. Здесь рассматривается понятие объекта и поименованных бинарных отношений. Взаимосвязи, в которых участвует более двух объектов интерпретируются, как объект. Объект - это реализация категории. Объекты подразделяются на абстрактные и конкретные. Абстрактные существуют всегда. Пример. Абстрактный объект используется для описания чисел и дат. Объекты соединены связями. В каждой связи в обоих направлениях присваиваются имена, соответствующие функциям доступа. Т. о. для создания бинарного отношения следует задать его имя, функции доступа и категории соответствующих данному отношению объекта. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-18- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-32- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Методы – операции, которые может выполнять объект. Каждый аргумент имеет имя, параметры и т. д. Бывают методы экземпляра и методы класса (static) Виды методов: Code – содержит код на языке ObjectScript. Expression – содержит одно выражение. При компиляции все вызовы метода заменяются этим выражением. Запросы – могут быть представлены в виде хранимых процедур SQL или представлений. Результаты доступны через специальный интерфейс. Индексы – Используются для оптимизации скорости выполнения запросов. Каждый индекс создается на основе одного или нескольких свойств класса. Может быть определен метод сортировки
В реляционной модели нет аналогов для параметров классов, многомерных свойств и методов экземпляров. Компилятор Cache автоматически создает таблицы для всех хранимых классов. Universe Universe представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных в таблицах. Допускает многозначные поля (поля, значения которых состоят из подзначений). Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. Эта постреляционная поддерживает также многоуровневые ассоциированные поля. Совокупность ассоциированных полей называют ассоциацией. При этом, первое значение одного столбца ассоциации соответствует первым значениям всех остальных столюцов ассоциации. Аналогичным образом связанны вторые значения. На длину полей и количество полей в записях не накладывается ограничение постоянства. Достоинства: возможность представления совокупности связанных таблиц одной постреляционной таблицой. Недостатки: сложность решения проблемы целостности и непротиворечимости данных. Хранилище данных В хранилище могут помещаться результаты транзакционных данных, также могут подвергаться конвертированию, чтобы обеспечить совместимость данных, полученных из других источников. Для обеспечения процесса отсечения и извлечения данных используются термины: Расслоение, Расщепление. Хранимые данные можно модифицировать методами многомерного моделирования с использованием звездообразной схемы, состоящей из таблицы фактов, окруженной таблицами измерений. Рисунок Отношения между таблицей фактов и измерений должны быть простыми, чтобы все было понятно. М. б. таблица развертывания измерений |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-30- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Cache В основе Cache лежит транзакт многомерное модели данных, которая позволяет хранить и представлять данные так, как они чаще всего используются. Сервер Cache предназначен для обработки транзакции в системе с большими и сверхбольшими БД, и с большим числом (10000)пользователей. Сервер Cache позволяет получать большую производительность, так как Cache не хранит избыточные данные и таблицы. В Cache реализована концепция единой архитектуры данных. К одним и тем же данным, хранящимся под управлением сервера есть три способа доступа: 1. Прямой 2. Объектный. Использует Java, Visual C++, Организован объектный модуль в соответствии с рекомендациями. 3. Реляционный, обеспечивает максимальную производительность реляционных приложений с использованием встроенного SQL. Разработчик может использовать разные типы триггеров и хранимых процедур. Все три типа доступа могут использоваться одновременно одним и тем же приложением. При этом все операции по редактированию выполняются только над одним экземпляром данных. Объектный модуль может описывать бизнес логику и создавать интерфейс с помощью ООП. Реляционный – для совместимости с другими системами. Сервер Cache Object Объектная модель поддерживает все основные концепции ООП. Наследование, Полиморфизм, Инкапсуляция. Также используются несколько стратегий хранения объекта в БД. 1. Автоматическое хранение в многомерной БД, Cache 2. Хранение в структурах, определенных пользователем. 3. Хранение в таблицах внешней реляционной БД. Дополнительные возможности (характеристики) 1. классы определяются путем 2. В основе системы лежат объекты и константы, обладающие типом данных. Объекты имеют однозначные идентификаторы, независимые от их внутреннего состояния. Константы не имеют идентификаторов, но имеют значения. 3. Классы могут содержать свойства. Значение свойства объекта определяет его состояние. 4. Свойства могут представлять собой константы ссылки на объекты или встроенные объекты и коллекции их них 5. Классы могут содержать методы. 6. Классы могут содержать генераторы методов. 7. Многие общие характеристики поведения объектов могут автоматически управляться Cache. Также поведение объектов может определяться пользователем. Виды классов:
Классы типов данных: это специальные классы, определяющие дополнительные значения констант, и позволяющие их контролировать. Содержат опред. набор методов проверки. Не могут содержать св-в. Классы объектов: определяют структуру и поведение объектов данного типа. Объекты называют экземплярами соответствующего класса. Каждый класс обладает именем, свойствами и методами. Незарегистрированные классы: все их методы разработчик определяет сам, отвечая за назначение и поддержку уникальных идентификаторов, объектов и объектных ссылок. Ограничения: 1. Система не выделяет память для значений свойств объектов. 2. Отсутствует автоматическая подкачка объекта, на который делается ссылка. 3. Полиморфизм не поддерживается. 4. Переменные, ссылающиеся на незарегистрированные объекты должны декларироваться с указанием соответствующего класса. |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-28- |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Распределенная обработка данных. Архитектура клиент-сервер. Система распределенной обработки данных: БД на одной машине, и с других машин к ней параллельно обращаются несколько пользователей. Распределенная БД, если БД находится на нескольких машинах. Бывает и последовательный многопользовательский режим. Основной принцип технологии клиент-сервер – разделение функций приложения на 5 групп. 1. Функции ввода и отображения данных Presentation Logic Это собственно интерфейс 2. прикладные функции, определяющие основные алгоритмы решения задач Business logic 3. Функции обработки данных внутри приложения Database Logic То есть языки запросов и манипуляций с данными 4. Функции управления информационными ресурсами Database Manager System Собственно СУБД, которая обеспечивает управление БД. В централизов. системе находится в одной машине. В децентрализованной – раскидана между сервером и клиентом. 5. Служебные функции, связывающие первые 4 группы Модель файлового сервера (FS модель) В этой модели презентация и логика расположены на клиенте. На сервере располагаются файлы с данными. Клиент обращается к серверу непосредственно с файловыми командами. Вся логика – на клиенте. (+) низкая нагрузка на сервер. СУБД находится на клиенте (-) высокий сетевой трафик. Узкий спектр операций манипулирования с данными. Низкие средства безопасности доступа к данным. Модель удаленного доступа к данным (RDA) СУБД – на сервере. На клиенте презентация и бизнес логика. Клиент обращается к серверу с SQL запросами. (+)Разгрузка сервера БД. Мин. число процессов. Сервер свободен от несвойственных ему функций, и целиком занимается обработкой данных. Резко падает трафик. Унификация интерфейса клиент-сервер. (-) достаточно сложное клиентское приложение Модель активного сервера БД Избавимся от недостатков RDA: 1. Необходимо, чтобы данные в БД в каждый момент были непротиворечивы. 2. Постоянный контроль за состоянием БД. 3. Контроль за типами данных. Эту модель поддерживает большинство современных СУБД (Oracle) Основа модели: Механизм хранимых процедур(?) как средство программирования SQL сервера. Механизм триггеров для отслеживания текущего состояния. Механизм ограничений на типы данных. Business Logic расположена на сервере в виде хранимых процедур. Клиент обращается к серверу с командами запуска этих процедур. По сути, на клиенте только презентация. Сервер может сам вызвать процедуры обработки данных. (+)Трафик резко падает Уменьшается дублирование обработки данных (-)Высокая нагрузка на сервер. Модель сервера приложения AS модель Эта модель – расширение двухуровневой модели. Вводится промежуточный уровень между клиентом и сервером. Сервер приложения содержит Business Logic (+) большая гибкость (-) высокие аппаратные затраты |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
-26- |
|

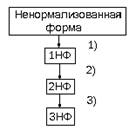 Аномалия удаления. Если все
Аномалия удаления. Если все 


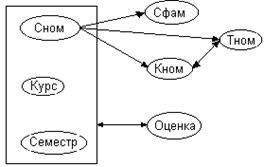 Семестр – семестр, в котором курс был завершен студентом
Семестр – семестр, в котором курс был завершен студентом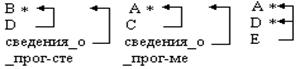
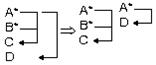 Имеем аномалию включения. D не могут заполнить до фактической поставки.
Имеем аномалию включения. D не могут заполнить до фактической поставки.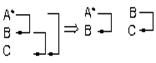 Аномалия обновления – если требуется изменить значение атрибута D, то придется внести одинаковые изменения в несколько картежей.
Аномалия обновления – если требуется изменить значение атрибута D, то придется внести одинаковые изменения в несколько картежей.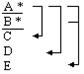
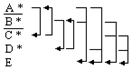 Аномалии устраняются разбиением исходного отношения на два, заданных во 2 нф.
Аномалии устраняются разбиением исходного отношения на два, заданных во 2 нф. П. Пусть имеется
П. Пусть имеетсяБазы данных, уровни данных, связи, аксиомы | 1-2 |
Нормальные формы схем отношений, аномалии, НФ 1 2 3 | 3-5 |
НФ Бойса-Кодда | 5-6 |
Многозначная зависимость | 6-10 |
НФ 4 5 | 10 |
Метод Табло, реляционная алгебра | 11-12 |
Реляционное исчисление | 12-13 |
Классификация моделей данных | 13 |
Иерархическая модель данных | 14, 22 |
Сетевая модель данных | 16, 22 |
Инфологическое моделирование | 17-18 |
Команды SQL, запросы | 19-20 |
Многотабличные запросы | 21 |
Модели транзакций | 23 |
Общие принципы восстановления | 24 |
Файловые структуры | 25 |
Распределенная обработка данных. Архитектура клиент-сервер | 26 |
Многомерные модели. ОО-модель | 27 |
Cache. Сервер Cache Object. | 28-30 |
Universe. Хранилище данных | 30 |
