

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таким образом, мы получили для каждого l ранговое распределение pl(r) покрытости первыми r порциями l–строк. Построим простую расчетную формулу для верхней оценки M(B, V).
Обозначим Z общую длину «словаря–склейки», который мы будем покрывать комбинацией из первых rl порций l–строк (где 2 £ l < L), то есть r2 порциями 2–строк, r3 порциями 3–строк и т. д. Замащивание «словаря–склейки» производится последовательно — сначала всего словаря строками большей длины, затем оставшейся непокрытой части словаря — строками на единицу меньшей длины и т. д. Начнем со строк длины n, где 2 £ n £ L.
Первые rn порций ранжированных n–строк покроют (менее чем) pn(rn)Z символов словаря. Тираж этих строк составит
Обозначив ql(rl) частоту непокрытости первыми rl порциями l–строк (то есть ql(rl) = 1–pl(rl) ), запишем в более удобном виде формулы для тиража строк соответствующей длины:
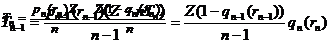
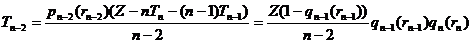
…………
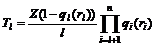
…………
Наконец, 1–строками (то есть символами алфавита) покрывается остаток словаря–склейки. Чтобы не допустить ситуации, когда какой-то из символов останется непокрытым, мы априори включаем в число 1–строк весь алфавит. То есть r1 заранее фиксировано и q1(r1) º 0. В силу последнего, число 1–строк (отдельных символов)
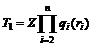
Общий тираж строк при разложении на комбинацию {rl} первых порций строк соответствующей длины, есть T = STl, а значение, обратное величине среднего покрытия, равно
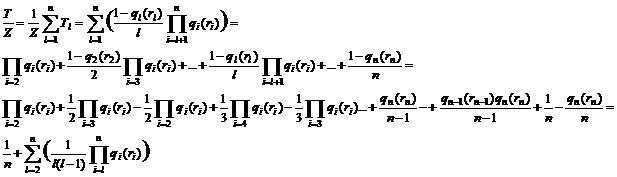
Итак, мы получили формулу для оценки величины среднего покрытия:
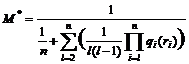
Остается найти комбинацию {rl}, удовлетворяющую ограничению на размер базиса, на которой M была бы максимальной. Ограничение на размер базиса:
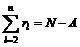
(здесь N и A — соответственно допустимый размер базиса и размер алфавита, измеренные «в порциях»). При допустимом размере базиса 256, размере алфавита 32 и шаге градации 16 имеем N = 16, r1 = A = 2, и ограничение принимает вид Srl = 14 (где l ³ 2). Верхняя оценка M* находится путем прямого перебора комбинаций {rl}, удовлетворяющих этому ограничению.
Табл. 2. Характеристики словаря основ и верхние оценки среднего покрытия
Первая буква основы | Общее число основ | Число различных основ | Средняя длина основы (в т. ч. первая буква) | Верхняя оценка среднего покрытия | |
Значения r4, r3, и r2 для лучшего разложения на 4–, 3– и 2–строки | Оценка | ||||
А | 3232 | 2826 | 8.69 | 5–3–6 | 2.40 |
Б | 3812 | 3276 | 7.89 | 5–3–6 | 2.18 |
В | 9626 | 6556 | 6.94 | 3–2–9 | 1.98 |
Г | 3347 | 2773 | 7.71 | 5–3–6 | 2.35 |
Д | 5575 | 4089 | 7.58 | 6–2–6 | 2.24 |
Е | 394 | 334 | 7.21 | ||
Ж | 822 | 646 | 6.61 | ||
З | 7795 | 4966 | 7.15 | 3–5–6 | 2.27 |
И | 4078 | 2809 | 7.67 | 7–2–5 | 2.39 |
Й | 24 | 20 | 6.17 | ||
К | 7003 | 5723 | 7.85 | 4–3–7 | 2.14 |
Л | 2216 | 1825 | 6.83 | 6–3–5 | 2.58 |
М | 4703 | 3977 | 8.08 | 4–3–7 | 2.22 |
Н | 9544 | 7244 | 8.01 | 2–4–8 | 2.11 |
О | 11304 | 7194 | 6.87 | 3–2–9 | 2.05 |
П | 28542 | 18970 | 7.90 | 2–4–8 | 2.14 |
Р | 7673 | 5242 | 7.94 | 6–2–6 | 2.42 |
С | 12212 | 9061 | 7.52 | 3–2–9 | 2.02 |
Т | 3917 | 3111 | 7.39 | 5–3–6 | 2.29 |
У | 4161 | 2634 | 6.24 | 7–2–5 | 2.65 |
Ф | 1734 | 1489 | 8.20 | 7–3–4 | 2.68 |
Х | 1378 | 1076 | 7.11 | 7–4–3 | 3.00 |
Ц | 576 | 470 | 7.36 | ||
Ч | 1077 | 885 | 7.21 | 8–3–3 | 3.00 |
Ш | 1472 | 1128 | 6.63 | 7–4–3 | 2.85 |
Щ | 212 | 144 | 5.42 | ||
Э | 1365 | 1214 | 9.45 | 8–2–4 | 2.84 |
Ю | 146 | 125 | 6.09 | ||
Я | 270 | 241 | 5.81 |
В последних столбцах табл. 2 приведены значения M*, полученные на наиболее частых 4–, 3– и 2–строках, вместе с порождающими их комбинациями {rl}. Эти результаты требуют пояснения уже потому, что в таблице отсутствуют значения для Е–, Ж–, Ц–, Щ–, Ю– и Я–словарей. Дело в том, что хотя в расчетах использовалось представление о словаре как «словаре–склейке», тем не менее проверялось, не нарушается ли для оптимальной и близких к оптимальной комбинаций {rl} мягкое ограничение на тираж, вытекающее из того, что в слове длиной k заведомо нельзя одновременно поместить более [k/l] замащивающих строк длиной l каждая. Откуда ограничение на тираж
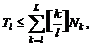
где L — максимальная длина слова, а Nk — число слов длины k. Когда это ограничение заметно нарушается (что происходило на 4–строках), это означает, что в разложении слов этого словаря должны участвовать и строки большей длины. Как видно из табл. 2, такие нарушения возникали для относительно коротких словарей. Понятно, что для больших словарей, при разложении которых роль длинных строк априори более чем скромна, ограничение длины строк величиной 4 непринципиально. С другой стороны, допущение в модели разложения на длинные строки требует полного отказа от модели «словаря–строки» в пользу более реалистичной модели словаря как множества слов, характеризуемого распределением их длин. В такой модели придется воспользоваться грубой (и по-прежнему завышающей оценку) схемой покрытия, состоящей в том, что от слова длины k «отщипывается» с одного края сколько-то l–строк, а оставшаяся часть слова попадает в число слов своей длины, что автоматически влечет изменение значений в правой части приведенного выше ограничения на тиражи.
Наконец, общим свойством верхних оценок, получаемых в рассмотренной модели, является то, что отношение порядка на верхних оценках среднего покрытия для разных словарей и отношение порядка для самих оптимальных значений среднего покрытия, вообще говоря, не совпадают. То есть если верхняя оценка для одного словаря больше, чем для другого, это не значит, что то же отношение справедливо и для оптимальных значений среднего покрытия.
Литература
1. Бузикашвили построения базиса известного размера для разложения словаря. // Настоящий сборник.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 |
