
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
|

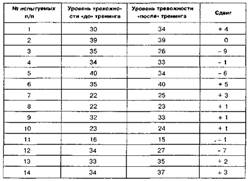

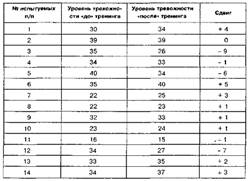
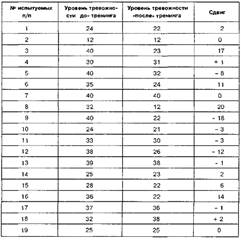 |
| |
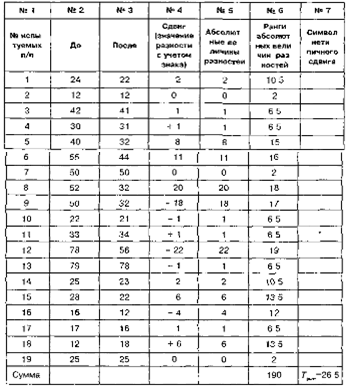 |  |
| |
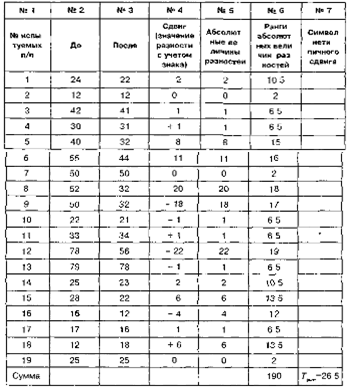 | |
|
| |
 | |
 | |
 | |
 |  |

 |
 |
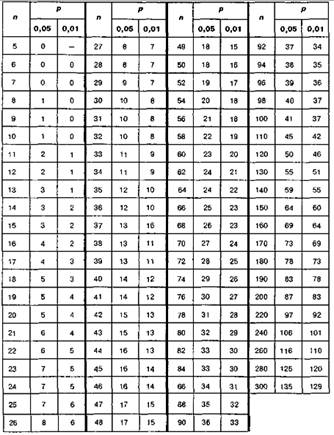
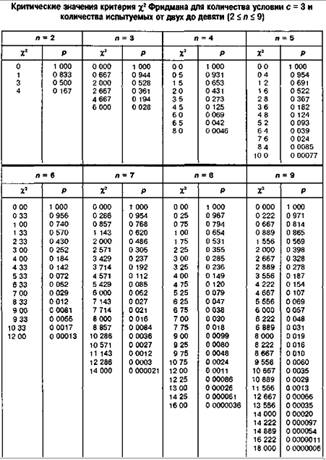
Критерий Макнамары
 Случай (а) B+C < 20
Случай (а) B+C < 20
M(m=min(B, C), n=B+C) > Ma
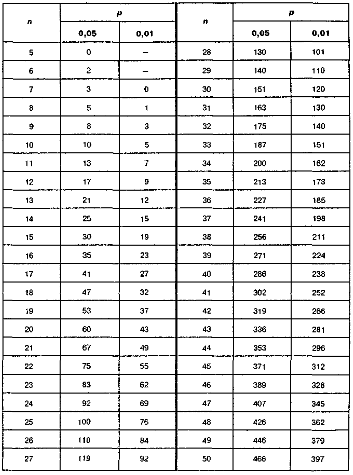
M0.05 = 0.025, M0.01 = 0.005
Случай (б) B+C > 20
Mэмп=![]() < Ma
< Ma
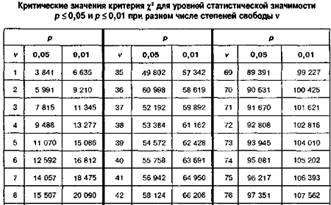
M0.05 = 3.841, M0.01 = 6.635

Критерий Макнамары
Случай (а) B+C < 20
M(m=min(B, C), n=B+C) < Ma
M0.05 = 0.025, M0.01 = 0.005
Случай (б) B+C > 20
Mэмп=![]() < Ma
< Ma
M0.05 = 3.841, M0.01 = 6.635


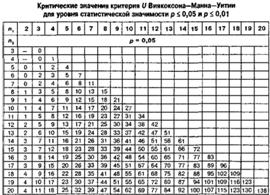 Критерий U Вилкоксона-Манна-Уитни
Критерий U Вилкоксона-Манна-Уитни
nmax = max(n1,n2), nmin = max(n1,n2)
Способ А (все числа разные)
U(x|y) – сумма числа инверсий выборки x по отношению к y
U(y|x) – сумма числа инверсий выборки y по отношению к x
Uэмп = min(U(x|y), U(y|x))
Uэмп >Ua(nmin, nmax)
Способ Б (есть одинаковые числа)
R(x|y) – сумма реальных рангов выборки x в общей выборке
R(y|x) – сумма реальных рангов выборки y в общей выборке
Rmax = max(R(x|y), R(y|x))
![]()
Uэмп >Ua(nmin, nmax)
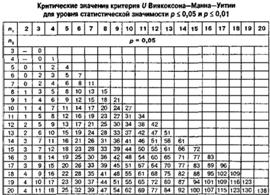 Критерий U Вилкоксона-Манна-Уитни
Критерий U Вилкоксона-Манна-Уитни
nmax = max(n1,n2), nmin = max(n1,n2)
Способ А (все числа разные)
U(x|y) – сумма числа инверсий выборки x по отношению к y
U(y|x) – сумма числа инверсий выборки y по отношению к x
Uэмп = max(U(x|y), U(y|x))
Uэмп ≥Ua(nmin, nmax) Þ H0
Способ Б (есть одинаковые числа)
R(x|y) – сумма реальных рангов выборки x в общей выборке
R(y|x) – сумма реальных рангов выборки y в общей выборке
Rmax = min(R(x|y), R(y|x))
![]()
Uэмп ≥ Ua(nmin, nmax) Þ H0
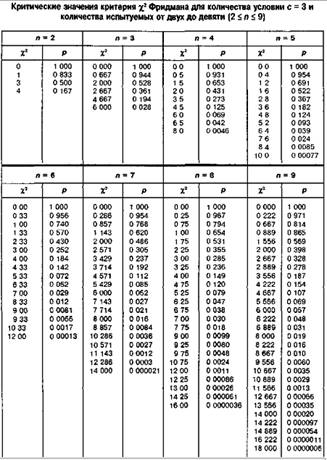
 Критерий Q Розенбаума
Критерий Q Розенбаума
 |
Критерий Q Розенбаума
|
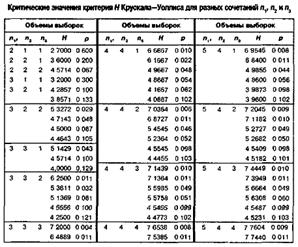
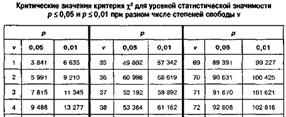
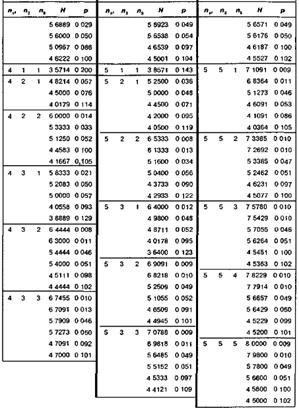
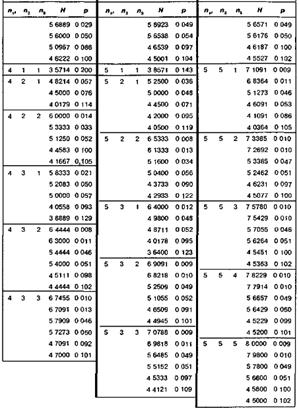 Критерий H
Критерий H
Крускала-Уоллиса
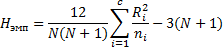
ni – объемы выборок
N – сумма объемов выборок ![]()
Ri – суммарные ранги выборок
 |
 |
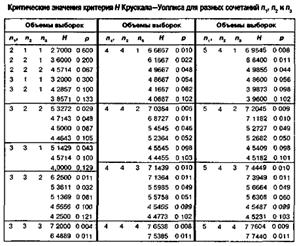 Критерий H
Критерий H
Крускала-Уоллиса
ni – объемы выборок
N – сумма объемов выборок ![]()
Ri – суммарные ранги выборок
|
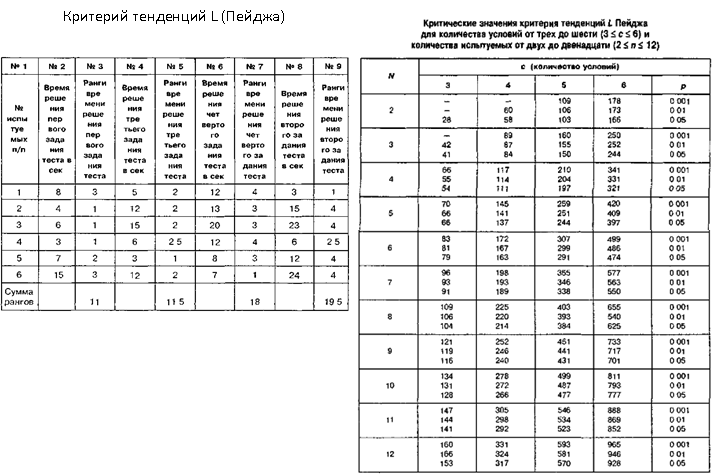
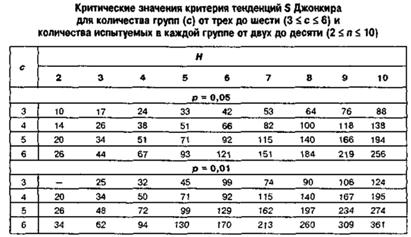
S – критерий тенденций Джонкира
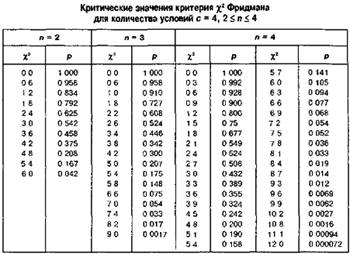
1) Выборки одинакового объема (n)
2) Число выборок (c) от 3 до 6
1. Выборки упорядочивают по возрастанию суммы их элементов
 2. Для каждого элемента подсчитывается число элементов,
2. Для каждого элемента подсчитывается число элементов,
превышающих его, в выборках, расположенных правее
3. Подсчитывается сумма инверсий А
4. Вычисляется статистика 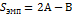 , где
, где 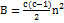
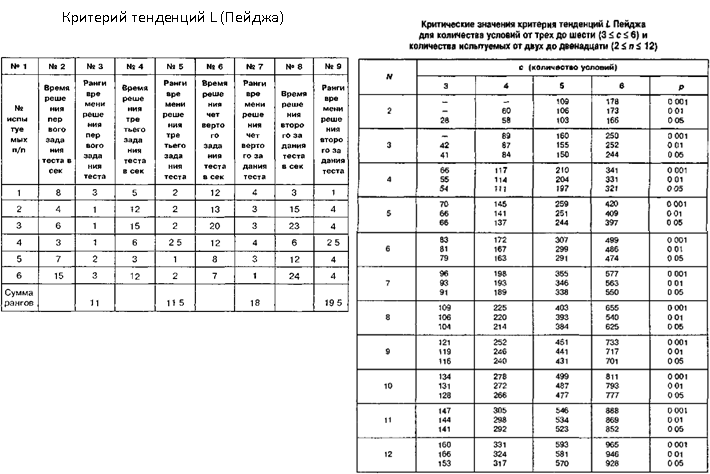
S – критерий тенденций Джонкира
1) Выборки одинакового объема (n)
2) Число выборок (c) от 3 до 6
1. Выборки упорядочивают по возрастанию суммы их элементов
2. Для каждого элемента подсчитывается число элементов,
превышающих его, в выборках, расположенных правее
3. Подсчитывается сумма инверсий А
4. Вычисляется статистика , где
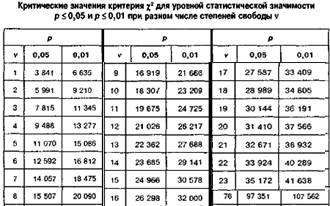
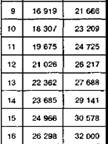
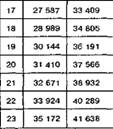
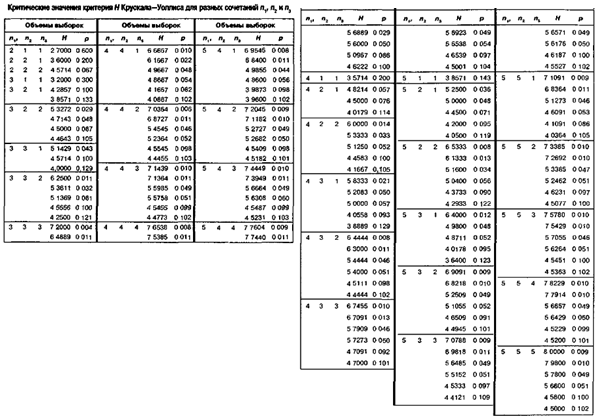
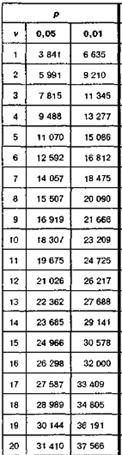 Критерий хи-квадрат c2 Пирсона
Критерий хи-квадрат c2 Пирсона
А) Сравнение теоретического и эмпирического распределения (задача согласия)
Для одномерных величин:
![]()
xi – теоретическая частота (Npi)
fi – эмпирическая частота
K – количество значений случайной величины
Критическое значение – ![]() (n), где n=K-1
(n), где n=K-1
Для двумерных величин:
![]()
Критическое значение – ![]() (n), где n= KL-1
(n), где n= KL-1
Б) Сравнение двух эмпирических распределений (задача однородности)
![]()
N=n1+n2 - суммарный объем выборки
K – количество значений случайной величины
f1i, f2i – эмпирические частоты двух выборок
В) Проверка гипотезы о независимости признаков
![]()
fij – частоты
fi fj – суммы частот по строкам и столбцам
N – объем выборки
Критическое значение – ![]() (n), где n=(K-1)(L-1)
(n), где n=(K-1)(L-1)
Критерий хи-квадрат c2 Пирсона
А) Сравнение теоретического и эмпирического распределения (задача согласия)
Для одномерных величин:
![]()
xi – теоретическая частота (Npi)
fi – эмпирическая частота
K – количество значений случайной величины
Критическое значение – ![]() (n), где n=K-1
(n), где n=K-1
Для двумерных величин:
![]()
Критическое значение – ![]() (n), где n=KL-1
(n), где n=KL-1
Б) Сравнение двух эмпирических распределений (задача однородности)
![]()
N=n1+n2 - суммарный объем выборки
K – количество значений случайной величины
f1i, f2i – эмпирические частоты двух выборок
В) Проверка гипотезы о независимости признаков
![]()
fij – частоты
fi fj – суммы частот по строкам и столбцам
N – объем выборки
Критическое значение – ![]() (n), где n=(K-1)(L-1)
(n), где n=(K-1)(L-1)
 Коэффициент корреляции Пирсона
Коэффициент корреляции Пирсона ![]()

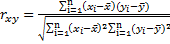
где 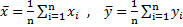
![]()
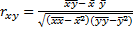
где 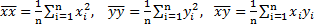

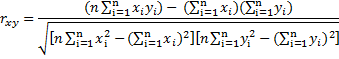
 Коэффициент корреляции Пирсона
Коэффициент корреляции Пирсона ![]()
где
![]()
где
 Коэффициент ранговой корреляции Спирмена
Коэффициент ранговой корреляции Спирмена
Случай разных рангов

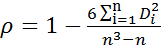
где 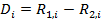
Случай одинаковых реальных рангов

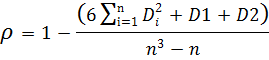
где
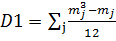
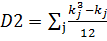
j - номер группы одинаковых рангов
mj – число одинаковых рангов в j-ой группе первой выборки
kj – число одинаковых рангов в j-ой группе второй выборки
Коэффициент ранговой корреляции Спирмена
Случай разных рангов
где
Случай одинаковых реальных рангов

где
j - номер группы одинаковых рангов
mj – число одинаковых рангов в j-ой группе первой выборки
kj – число одинаковых рангов в j-ой группе второй выборки
 Коэффициент ранговой корреляции Кендалла
Коэффициент ранговой корреляции Кендалла
Вычисление
- Парные наблюдения упорядочиваются
по возрастанию рангов первой выборки
- Считается число инверсий для элементов второй выборки
(число значений ниже этого элемента, которые меньше него)
![]()
где Q – общее число инверсий
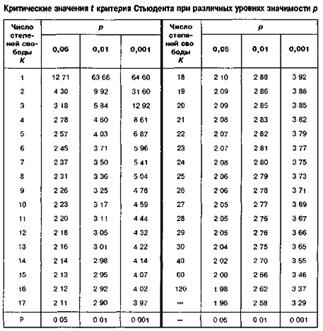
Проверка гипотезы о значимости отличия от нуля
с помощью T - критерия Стьюдента:
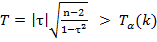
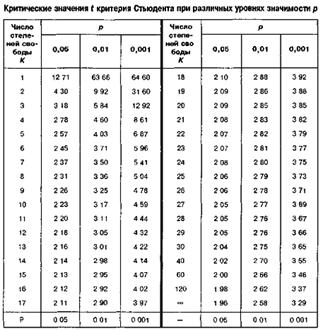
Вход в таблицу с числом степеней свободы k=n-2
 Коэффициент ранговой корреляции Кендалла
Коэффициент ранговой корреляции Кендалла
Вычисление
- Парные наблюдения упорядочиваются
по возрастанию рангов первой выборки
- Считается число инверсий для элементов второй выборки
(число значений ниже этого элемента, которые меньше него)
![]()
где Q – общее число инверсий
Проверка гипотезы о значимости отличия от нуля
с помощью T - критерия Стьюдента:
Вход в таблицу с числом степеней свободы k=n-2
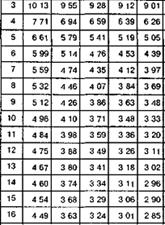
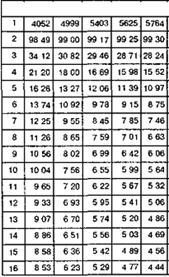
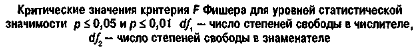 Однофакторный дисперсионный анализ
Однофакторный дисперсионный анализ
|
|
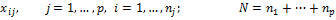
Общая сумма квадратов отклонений |
|
|
Сумма квадратов отклонений от групповых средних |
|
|
Сумма квадратов отклонений групповых средних от общего среднего |
|
|
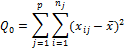
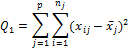
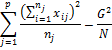
Правило сложения: 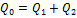
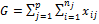
Общая дисперсия 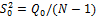
Средняя внутригрупповая дисперсия 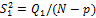
Дисперсия групповых средних 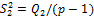
Проверка гипотезы 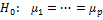
Критерий: 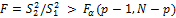
Однофакторный дисперсионный анализ
|
|
Общая сумма квадратов отклонений |
|
|
Сумма квадратов отклонений от групповых средних |
|
|
Сумма квадратов отклонений групповых средних от общего среднего |
|
|
Правило сложения:
Общая дисперсия
Средняя внутригрупповая дисперсия
Дисперсия групповых средних
Проверка гипотезы
Критерий:
Регрессия
Модель регрессии: 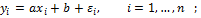
![]() - парная выборка, наблюдается
- парная выборка, наблюдается
![]() – неизвестны
– неизвестны
Отклонения (невязки): 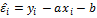
Критерий МНК: 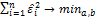
Оценки МНК: 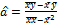 ,
, 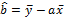
Гипотеза: H0: ![]() =0
=0
Тест: 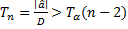
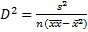
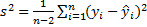
Точечный прогноз точке ![]() :
: 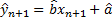
Полуширина доверительного интервала с уровнем доверия 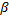 :
:
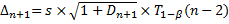 ,
, 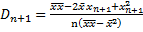
Доверительные пределы: 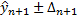
Регрессия
Модель регрессии:
![]() - парная выборка, наблюдается
- парная выборка, наблюдается
![]() – неизвестны
– неизвестны
Отклонения (невязки):
Критерий МНК:
Оценки МНК: ,
Гипотеза: H0: ![]() =0
=0
Тест:
Точечный прогноз точке ![]() :
:
Полуширина доверительного интервала с уровнем доверия :
,
Доверительные пределы:
