

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
12.Вычислительные системы. Уровни параллелизма. Классификация ВС Флинна. Закон Амдала.
Параллелизм – 1-ин из главных способов повышения производительности работы вычислительных систем (ВС). ВС – это такая система которая производит параллельныеые вычисления.
Уровни параллелизмаизма.
1. Уровень заданий – независимые задания выполняются на разных процессорах с малым взаимодействием между собой. Уровень реализуется на ВС с множеством процессоров в мультизадачном режиме.
Положим ВС с 4-мя процессорами, надо отработать задания:
S - для выполнения требуется 1 процессор, M – 2 процессора, L – 4 процессора.
Есть очередь заданий : SMLSSMLLSMM
Время | Задание | %-ент использо-вания |
1 | SM | 75 |
2 | L | 100 |
3 | SSM | 100 |
4 | L | 100 |
5 | L | 100 |
6 | SM | 75 |
7 | M | 50 |
Время | Задание | %-ент использо-вания |
1 | SMS | 100 |
2 | L | 100 |
3 | SMS | 100 |
4 | L | 100 |
5 | L | 100 |
6 | MM | 100 |
Как видно в первой организации последовательности подачи команд на выполнение средний процент загрузки равен 83%, а во втором 100%, следовательно, 1-а из основных задач – организация эффективного ввода данных.
2. Уровень программ – части одной задачи выполняются на множестве процессоров, уровень реализуется на любой параллельной ВС.
В программе выделяются независимые участки которые могут выполняться параллельноо.
For i:=1 to N Do
A[i]:=B[i]+C[i]
Если имеем 4 процессора, то распараллеливание следующее:
для 1-го i=1,5,…
для 2-го i=2,6,…
для 3-го i=3,7,…
для 4-го i=4,8,…
Разделение данных необходимо для организации параллелизма уровня программ и это разделение называется декомпозицией данных.
3. Уровень команд – выполнение команды разделятся на фазы, а фазы последовательных команд перекрываются за счет конвейеризации, уровень достигается на ВС с 1-им процессором.
Имеет место когда обработка нескольких команд, или выполнение различных этапов 1-ой и той же команды перекрывается во времени за счет конвейеризации вычислений и параллелизма вычислений, которое достигается благодаря наличию сдублированных ФБ.
4. Уровень битов – если биты данных обрабатываются параллельно то говорят о бит-параллельной операции, уровень достигается в суперскалярных ЭВМ.
При параллельной обработке используют понятие гранулярности – мера отношения объема вычислений,
выполненных в параллельной задаче к объему коммуникаций.
Гранулярность:
- Крупнозернистый параллелизм (каждое параллельное вычисление мало зависит от других, требуется редкий обмен информацией между вычислениями. Единицей распараллеливания большие независимые программы 1000-и команд. Уровень параллелизма обеспечивается ОС).
- Среднезернистый параллелизм (единица распараллеливания – процедуры 100-и команд, организуется программистом и компилятором).
- Мелкозернистый параллелизм (параллельное вычисление мало – около 10-ов команд, единица распараллеливания – элементы выражения или операции цикла).
Если коммутационная издержка велика, то лучшую производительность дает мелкозернистый, если нет, то крупнозернистый.
Закон Амдала
В идеальном случае при увеличении числа процессоров (далее CPU) в n раз, производительность так же должна возрасти в n раз, что на практике не возможно т. к. нельзя распараллелить выполнение задачи целиком на все n CPU, кроме того, надо организовывать связи между CPU, а так же использовать дополнительную индексацию при декомпозиции данных.
Оценка производительности или ускорения от числа CPU и распараллеливаемой части программы определяется законом Амдала: S=Ts/Tp – ускорение. (Ts – время без распараллеливания, Tp – с распараллеливанием)
Программный код решаемой задачи состоит из 2-ух частей: последовательной и распараллеливаемой. Пусть f – для операций которые должны выполняться последовательно 1-им CPU, при этом 0 £ f £ 1, тогда (1- f ) – доля распараллеливаемой части программы. Если f = 0, то программа полностью распараллеливаемая, что невозможно. Распараллеливаемая часть программы равномерно распределяется по всем CPU:

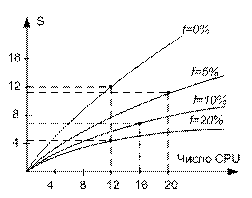
Tp=f×Ts+(1-f)Ts/n
S=Ts/Tp=n/(1+(n-1)f) (*)
Формула (*) выражает зависимость ускорения от числа CPU и доле распараллеливаемой части программы f.
См. правый рисунок. Если в программе 10% последовательных операций, т. е f = 0.1, то при любом числе CPU, ускорение более чем в 10 раз не получить, при этом 10 – это теоретическое значение.
Классификация ВС по Флинну.
В основе классификации находится понятие потока – это последовательность команд или данных, обрабатываемая CPU. В зависимости от числа потока команд или данных Флинн разделил ВС на 4 группы:
1. SISD (ОКОД – одиночный поток команд одиночный поток данных).
| К данному классу относятся все машины Фон – Неймана, в которых 1-ин поток команд, они обрабатываются последовательно и каждая команда инициирует одну операцию с 1-им потоком данных. |

2. MISD (МКОД – множественный поток команд одиночный поток данных).
| В структуре данного класса имеется множество процессоров, которые обрабатывают один и тот же поток данных, пример таких структур - структура цифровой обработки данных (АА ТЦОС) (пример: 1проц – интерполяция, 2 – фильтрация, 3 – фильтр высокого порядка). |
3. SIMD (ОКМД – одиночный поток команд множественный поток данных).
| ВС данного класса позволяет выполнять 1-у арифметическую операцию над множеством данных (элементами вектора, поэтому их называют векторными), к данному классу относятся матричные ВС, где имеется одно УУ, управляющее множеством процессорных элементов, которые выполняют одновременно одну ту же операцию над своими локальными данными. |

4. МIMD (МКМД – множественный поток команд множественный поток данных).
| ВС данного класса имеют множество устройств обработки команд, которые объединены в комплекс, при этом каждое устройство работает со своим потоком команд и данных. Данный класс включает в себя все мультипроцессорные элементы. |

Данная классификация позволяет оценить базовый принцип работы системы.
Недостаток такой классификации:
1. Невозможность однозначно отнести некоторые ВС к определенному классу (если вектор – единица данных, то вместо SIMD систему можно отнести к SISD).
2. Класс MIMD очень насыщен (большинство систем именно этого класса).
