
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 Федеральное агентство по образованию РФ
Федеральное агентство по образованию РФ
ГОУ ВПО «Уральский государственный технический университет - УПИ»
Факультет дистанционного образования
Лабораторная работа № 2
по дисциплине: Теория информации
на тему: Сжатие данных. Метод Хаффмана
Семестр № 4
 Преподаватель
Преподаватель
Студент гр. № ИТЗ–26010ДТ
Номер зачётной книжки
Екатеринбург
2008
 |
Лабораторная работа № 2 по Теории информации
№ записи в книге регистрации____________ дата регистрации _______________2008 г.
Преподаватель
Студент группа № ИТЗ-26010ДТ
Деканат ФДО____________
СОДЕРЖАНИЕ:
ВВЕДЕНИЕ. 3
Мультимедиа-сжатие. 4
алгоритмы сжатия без потерь. 7
Метод повторяющихся символов (Running) 7
Зива – Лемпеля - Велча (LZW) 7
Хаффмана (Huffman) 8
Метод Хаффмана.. 10
Руководство к программе. 14
Сравнение сжатия файлов.. 17
Код программы.. 18
Вывод.. 34
Литература: 35
ВВЕДЕНИЕ
Проблема сжатия информации была актуальна всегда, т. к. объем носителей, хоть и неуклонно растёт, но всё же ограничен.
Стоит ли в таких условиях задумываться о сути архиваторов и следует ли вообще их использовать? Для этого есть целый ряд причин:
· при передаче файлов по почте или с помощью терминальных программ критичным является каждый килобайт, да и, кроме того, при пересылке большого числа файлов (особенно со сложной структурой каталогов) проще в письмо вложить всего один файл - архив;
· пропускная способность локальных сетей ограничена. При пересылке больших массивов информации по сети рекомендуется использовать архиваторы не только для уменьшения трафика, но и с целью упрощения конечной верификации: после копирования проще проверить корректность архива, нежели проверять сотни файлов на целостность, просматривая их содержимое;
· пишущий CD-ROM стал стандартом для ПК среднего класса, многие из нас сталкиваются с проблемой, когда на компакт диск необходимо перенести очень сложную структуру каталогов, тогда как файловая система компакт-диска не допускает более чем восьмикратный уровень вложенности папок. Это было бы очень серьезной проблемой, если бы не архиваторы, позволяющие упаковывать всю структуру в один файл;
· многие архиваторы являются очень эффективными кодировщиками, позволяющими скрыть конфиденциальную информацию от чужих глаз, запаковав свои файлы и установив на архив пароль.
Из выше сказанного можно сделать важный вывод: архивация сейчас используется для увеличения скорости передачи при ограниченной пропускной способности.
На сегодняшний день существует достаточно много способов архивации данных. Все они делятся на два больших, принципиально разных подхода: сжатие с потерями и без потерь. Под сжатием с потерями (или необратимым сжатием) предполагают такое преобразование входного массива данных, при котором выходной поток представляет, достаточно похожий и, возможно, даже не отличный от исходного по внешним характеристикам поток, однако, отличается от него объемом и составляющим содержимым. Примерами такого сжатия являются mp3 файлы и jpeg изображения.
Но данные алгоритмы не всегда удобны и эффективны. В некоторых случаях, например с текстом, сжатие с потерями абсолютно нецелесообразно, ибо текст – единое целое и исчезновение символов, пусть даже при уменьшении веса файла, недопустимо.
Для этого случая были разработаны так называемые алгоритмы сжатия информации без потерь данных.
Все приведенные выше выкладки имеют целью показать актуальность рассмотрения алгоритмов сжатия.
Мультимедиа-сжатие
Давайте поговорим о том, какие алгоритмы используются при сжатии мультимедийной информации, допускающей потерю качества. Следует сразу оговориться, что применение подобных алгоритмов возможно в силу ограничений органов зрения и слуха человека. Преимущество этих методов состоит в том, что как раз потеря качества обычно незначительна, зато экономия дискового пространства впечатляет: выходной файл может быть меньше исходного в сто раз и выше.
Сжатие графической информации основано на том, что человеческий глаз, обычно, способен воспринимать лишь ограниченное число градаций основных цветов. Вспоминается, в связи с этим, пример из литературы, как опытные ткачихи, подчас, способны были различать несколько сотен градаций одного и того же цвета (например, черного).
Так вот, соседние пиксели, отличающиеся друг от друга по цвету незначительно, отождествляются (коэффициент "похожести" соседних пикселей определяет баланс качества изображения и степени сжатия, см. рис.). Одинаковые группы пикселей объединяются в блоки и, далее, применяется один из методов сжатия без потери качества. Например, в формате JPEG сначала производится разбиение изображения на блоки 8x8. Затем данные блоки изображения подвергаются так называемому дискретному косинус-преобразованию (ДКП, на данном этапе происходит потеря качества) и, на заключительном этапе, применяется метод Хаффмана. Данный формат очень эффективен при хранении фотографий и прочей полноцветной графики.
Кроме того, ключевым моментом является количество бит, выделяемых для хранения цвета одного пикселя. Чем больше бит выделено под хранение одного пикселя, тем реалистичнее картинка и тем больше объем графического файла. Так, в большинстве случаев мы имеем дело с графикой, цветовая палитра которой - 16 или 24 бит (Hi и True color соответственно). Всем известный формат графических файлов GIF ограничивает цветовую палитру одним байтом (всего 256 цветов для каждого пикселя), тем самым, достигая значительной экономии в объеме файла. Следует учесть, что фотографии в данном формате хранить не следует. Приличное качество недостижимо, а объем уменьшается незначительно. Преимуществом данного формата является возможность хранения простейшей анимации.
В рамках наиболее популярного сегодня формата MPEG3, аудио-сжатие основывается на удалении наименее значимых деталей звучания (согласно психоакустической модели). Например, человек способен воспринимать звук узкого частотного диапазона, не воспринимаются сигналы, мощность которых ниже определенного пограничного значения и т. д. Очищая звуковой поток от "лишних", невоспринимаемых человеком сигналов, достигается более чем десятикратная экономия.
Основные параметры, определяющие качество сжатого файла - это битрейт и частота дискретизации. Битрейт (bit rate, битовая частота) определяет количество передаваемой за единицу времени информации; чем больше битрейт, тем выше реалистичность и соответствие исходному звуковому потоку (оптимальное значение, обеспечивающее качество компакт-диска - 128 kBit/s).
Убедиться в обоснованности этого числа можно так: для прослушивания обычного, несжатого потока аудио (записанного на Audio CD) требуется привод CD-ROM с формулой 1x. Скорость линейного чтения у такого привода равна 150 kByte/s (т. е. 1200 kBit/s). Разделим это число на отношение объемов несжатого и сжатого аудио-потоков. Как мы уже говорили, коэффициент сжатия в формате mp3 примерно равен десяти. Получаем 120 kBit/s (что и требовалось доказать).
Частота дискретизации - еще один очень важный параметр, определяющий максимальную частоту выходного сигнала (и, соответственно, чем он больше, тем ближе звучание mp3 файла к оригиналу). Общепринята точка зрения, согласно которой восприятие человеком звука ограничено частотным диапазоном от 20Hz до 20kHz. Чаще всего значение частоты дискретизации устанавливается в два раза большее, чем верхний порог восприятия (44.1 или 48 kHz).
Все известные на сегодня форматы видео поддерживают сжатие с потерей качества. Видео состоит из потока сменяющих друг друга кадров и синхронизованного с ним аудио-потока. В каждом из форматов видео используется комбинация из наиболее эффективных способов сжатия графики и звука. Но, помимо сжатия каждого кадра и аудио-потока, используются и специфические приемы.
Как известно, пороговая частота дискретного восприятия человеком сменяющих друг друга графических образов - 25 кадров/сек. В силу этого обстоятельства, наличие в выходном потоке большего числа кадров не оправдано.
Более того, смежные кадры содержат одни и те же объекты сцены. Следовательно, хранение каждого из кадров можно заменить хранением изменений, произошедших со времени показа предыдущего кадра. Таким образом, весь фильм можно представить в виде последовательности ключевых кадров, сохраненных с небольшим коэффициентом сжатия и промежуточных (зависимых) кадров, ссылающихся на предыдущие ключевые или зависимые кадры. Зависимые кадры минимальны по размеру и содержат изменения, которые претерпела сцена. В силу этого достигается впечатляющая экономия дискового пространства.
Существует несколько видео-форматов. MPEG1 - первый и довольно эффективный формат. Этот формат сделал возможным просмотр видео фильмов даже на самых скромных ПК на базе процессоров Pentium (без поддержки мультимедиа-инструкций MMX). Основным недостатком этого формата являлся недостаточный коэффициент сжатия. Например, полуторачасовой фильм в таком формате занимал два компакт диска. Пользователи, смотревшие мелодраму, очень сильно переживали необходимость смены компакт-дисков в моменты развязки сюжета :).
Формат видео MPEG2 (и его VBR-реализация) используется в рамках технологии DVD и обеспечивает высокое качество выходного видео. Особой степенью сжатия не характеризуется, в силу того, что носители, используемые в технологии DVD, обладают достаточной емкостью (DVD-Disk имеет емкость от 4,7 GByte). Соответственно процесс декодирования не особенно требователен к аппаратным ресурсам ПК.
Формат MPEG4 обладает очень высокой степенью сжатия при довольно приличном качестве. Основным недостатком этого формата являются довольно высокие требования к вычислительной мощности ПК. Так, при просмотре фильмов в этом формате на системе с процессором ниже Pentium III с частотой 600 MHz, иногда, можно наблюдать слайд-шоу. Удивляет тот факт, что аудио поток в таком случае будет воспроизводиться без искажений. Таким образом, при выборе ПК, одной из задач которого будет воспроизведение видео в данном формате, следует ориентироваться на систему на базе процессоров класса Pentium III или Athlon с частотой от 1GHz (или их дешевые аналоги Celeron и Duron). Особое внимание следует уделить производительности дисковой подсистемы (в силу того, что "картинка" и "звук" хранятся в видео-файле отдельно и требуется высокая скорость произвольного доступа к диску).
алгоритмы сжатия без потерь
Метод повторяющихся символов (Running)
Это самый простой метод сжатия информации. Суть метода заключается в том, что последовательность повторяющихся подряд байт можно заменить структурой:
· сам байт
· «флаг», показывающий, что данный участок сжат
· кол-во повторений первого байта
Пример:
Допустим, что есть строка, содержащая 10 подряд идущих пробелов. Данная последовательность из 10 одинаковых байт кодируется в 3.
· Первый байт - собственно сам пробел (кодируемый байт).
· Второй байт - "флаг", который указывает, что мы должны развернуть предыдущий в строке байт в последовательность при восстановлении строки.
· Третий байт - байт счетчик. Будет равен 10, т. к. мы кодируем 10 пробелов.
Можно увидеть, что достаточно иметь последовательность из более 3-х одинаковых символов, чтобы на выходе получить блок информации меньший по размеру, но допускающий восстановление информации в исходном виде.
Плюс: простота реализации
Минус: малая степень сжатия (не так часто встречаются непрерывные серии одинаковых символов).
Зива – Лемпеля - Велча (LZW)
История этого алгоритма начинается с опубликования в мае 1977 г. Дж. Зивом и А. Лемпелем статьи в журнале "Информационные теории". В последствии этот алгоритм был доработан А. Велчем, и в окончательном варианте отражен в статье "IEEE Computer" в июне 1984 . В этой статье описывались подробности алгоритма и некоторые общие проблемы, с которыми можно столкнуться при его реализации. Позже этот алгоритм получил название - LZW (Lempel - Ziv - Welch) .
Алгоритм LZW представляет собой алгоритм кодирования последовательностей неодинаковых символов. Возьмем для примера строку: "Объект TSortedCollection порожден от TCollection.".В данной строке слово "Collection" повторяется дважды. В этом слове 10 символов = 80 бит. Если мы заменим это слово, в выходном файле, во втором его включении, на ссылку на первое включение, то получим сжатие информации. Если рассматривать входной блок информации размером не более 64К и ограничить длину кодируемой строки в 256 символов, то, учитывая байт "флаг" получим, что строка из 80 бит, заменяется 8+16+8 = 32 бита. (1 байт – флаг, 2 байта – ссылка, 1 байт – длинна кодируемой последовательности). Если существуют повторяющиеся строки в файле, то они будут закодированы в таблицу. Очевидным преимуществом алгоритма является то, что нет необходимости включать таблицу кодировки в сжатый файл. Другой важной особенностью является то, что сжатие по алгоритму LZW является однопроходной операцией в противоположность алгоритму Хаффмана, которому требуется два прохода.
Плюс: высокая степень сжатия
Минус: сложность в реализации.
Хаффмана (Huffman)
Сжатие файла по алгоритму Хаффмана основывается на частоте повторения символов. Для сжатия необходимо подсчитать сколько раз встречается каждый символ из расширенного набора ASCII. После подсчета частоты вхождения каждого символа, необходимо отсортировать получившуюся таблицу (символ – частота вхождения) по частоте. Каждую ссылку из таблицы назовем "узлом". В дальнейшем (в дереве) мы будем позже размещать указатели, которые будут указывать на этот "узел".
Пример:
Пусть есть файл длинной в 100 байт и состоящий из 6 различных символов. Мы подсчитали вхождение каждого из символов в файл и получили следующее:
A | B | C | D | E | F |
0.25 | 0.2 | 0.05 | 0.1 | 0.1 | 0.3 |
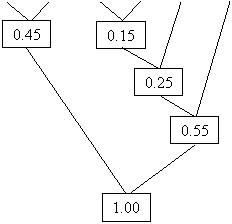
В дальнейшем элементы таблицы будем считать узлами, а их вероятность – весом узлов. Дерево получим следующим путём:
Сначала выбираются 2 узла с наименьшим весом, вместо них создаётся новый узел, с весом, равным их сумме. Повторяем данную операцию до тех пор, пока не останется 1 узел с весом в единицу.
Теперь можно приступить к кодированию, для этого начинаем обход дерева с корня (узла с весом в 1) и спускаемся до самих символов (узлов, листьев дерева). При этом мы прослеживаем вверх по дереву все повороты ветвей и, если мы делаем левый поворот, то запоминаем 0-й бит, если правый - 1-й бит.
Таким образом, для символа А получим код 00, аналогично для других:
A 00
B 01
C 1000
D 1001
E 101
F 11
Теперь подсчитаем сжатие:
было 100 байт = 800 бит
стало 25*2 + 20*2 + 5*4 + 10*4 + 10*3 + 30*2 = 240 бит = 30 байт
Получили сжатие на 70%.
Но, теперь все это дело надо разархивировать. Т. е. надо сохранить наше дерево. В данной работе сохраняется непосредственно таблица частот. Т. е. процесс построения дерева происходит дважды: при архивации и при разархивации.
6 символов = 6 байт
6 частот = 6*4 = 24 байт
30+6+24 = 60 байт
Также возьмём служебную информацию (время создания, время редактирования, атрибуты, имя файла): 4+4+1+11 (длину файла будем считать 11 символов, включая расширение) = 20 байт
Получили архив в 20+60 = 80 байт
Окончательно сжатие на 20%. В среднем алгоритм Хаффмана даёт 20-25% сжатие (для текстовых документов).
Плюс: нет необходимости в байтах-флагах, т. е. не надо разделять битовые серии.
Минус: требуется два прохода во время архивирования: первый – подсчёт кол-ва вхождения каждого байта, второй – непосредственно архивирование.
Метод Хаффмана
Это алгоритм архивации без потери качества. Исходный файл состоит в основном из однородных цепочек байтов, либо количество используемых символов довольно мало (т. е. файл состоит из небольшого подмножества элементов таблицы ASCII). Представим себе самый общий случай, когда в файле представлена большая часть таблицы ASCII и почти нет однородных последовательностей. В таком случае выгоду можно получить только если разные байты (символы) встречаются в данном файле с различной частотой. Тогда наиболее часто встречающиеся символы могут быть закодированы меньшим числом бит, а те, что встречаются довольно редко наоборот большим числом бит. В итоге результирующий файл с большой вероятностью будет меньшего объема, чем исходный.
Прежде чем описать алгоритм перекодировки, позволяющий наиболее часто встречающиеся символы (байты) кодировать не восемью, а гораздо меньшим числом бит, следует указать на ограничения, свойственные любому, даже самому эффективному алгоритму без потери качества.
Можно представить, что все файлы - это тексты, написанные в алфавите, состоящем из 256 букв (так оно на самом деле и есть). Рассмотрим все множество файлов, размер которых не превышает n byte (где n произвольное число). И допустим, что существует некий алгоритм кодирования, который любой из этих файлов сжимает с "положительной" эффективностью. Тогда множество всех их архивов содержится во множестве всех файлов, размер которых меньше n byte. Согласно нашему предположению существует взаимно-однозначное (биективное, как сказали бы математики) соответствие между двумя конечными множествами, число элементов в которых не совпадает. Чего быть не может (так называемый принцип Дирихле; да, сказывается математическое образование). Отсюда можно сделать довольно значимые выводы:
1) не существует архиватора, который бы одинаково хорошо паковал любые файлы,
2) для любого архиватора найдутся файлы, в результате сжатия которых будут получаться архивы в лучшем случае не меньшего размера, чем исходные файлы.
Теперь приступим к описанию алгоритма Хаффмана. Рассмотрим его на примере следующего файла:
cccacbcdaaabdcdcddcddccccccccccc{End of file}
Распишем частоты каждого из символов:
a - 4,
b - 2,
c - 19,
d - 7.
Весь файл занимает 32 byte. Каждый из символов в исходном файле кодируется согласно таблице ASCII восемью битами:
a - ,
b - ,
c - ,
d - .
Шаг №1. Расположим эти четыре символа в порядке убывания их частот:
{(c,19), (d,7), (a,4), (b,2)}
Шаг №2. На следующей строке запишем набор, полученный из предыдущего следующим образом:
· вместо двух последних символов с их частотами запишем новый элемент, у которого вместо названия символа будет запись "Вершина #n", а вместо частоты - сумма частот последних двух элементов предыдущего набора;
· отсортируем полученный набор по убыванию.
{(c, 19), (d, 7), ("вершина #1", 6)}
Шаг №3. Переходим на шаг №2 до тех пор, пока набор не будет состоять только из одного элемента:
("вершина #last_number", summa_vseh_chastot):
{(c, 19), ("вершина #2", 13)}
{("вершина #3", 32)}
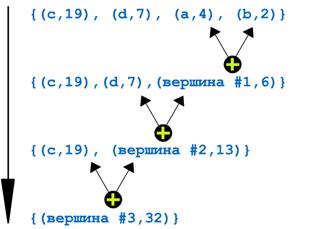
Что же в итоге? Посмотрите на рисунок. Вы видите дерево, растущее с листьев! Если соединять чертой каждый из элементов "вершина #x" с теми элементами предшествующих наборов, сумма частот которых хранится во второй части элемента "вершина #x", то мы получим своего рода дерево (в программировании подобные структуры называются бинарными деревьями).
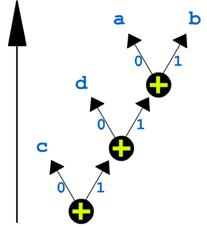 Смысл этой древесной структуры состоит в том, чтобы каждому из символов сопоставить различное число бит в зависимости от его частоты (как мы уже говорили, в несжатом файле символы хранятся в виде групп по восемь бит). Если внимательно всмотреться в следующий рисунок, вы увидите, что каждая из ветвей помечена либо нулем, либо единицей. Таким образом, если мысленно пройтись по дереву от корня до какой-либо вершины, содержащей символ, то последовательность нулей и единиц, встречающихся у вас на пути, и будет новой комбинацией бит для этого символа. Например, символ "c" как наиболее часто встречающийся будет кодироваться одним битом "0", символ "d" двумя битами "10" и т. д.
Смысл этой древесной структуры состоит в том, чтобы каждому из символов сопоставить различное число бит в зависимости от его частоты (как мы уже говорили, в несжатом файле символы хранятся в виде групп по восемь бит). Если внимательно всмотреться в следующий рисунок, вы увидите, что каждая из ветвей помечена либо нулем, либо единицей. Таким образом, если мысленно пройтись по дереву от корня до какой-либо вершины, содержащей символ, то последовательность нулей и единиц, встречающихся у вас на пути, и будет новой комбинацией бит для этого символа. Например, символ "c" как наиболее часто встречающийся будет кодироваться одним битом "0", символ "d" двумя битами "10" и т. д.
Давайте, напоследок, попробуем рассмотреть еще один пример файла, частотное дерево которого выглядит несколько более сложно, нежели в предыдущем случае. Бывает так, что частоты отдельных символов одинаковы или почти одинаковы, это приводит к тому, что такие символы кодируются одним и тем же числом бит. Однако алгоритм построения дерева от этого не меняется:
ddddddaaaaaabbbbbbccccdffffffffffdddd{37 byte, end of file}
В двоичном виде файл будет выглядеть так:
{296 bit, end of file}
Распишем частоты каждого из символов:
a - 6
b - 6
c - 4
d - 11
f - 10
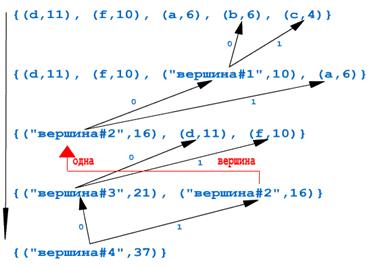
Весь файл занимает 37 byte. Каждый из символов в исходном файле кодируется согласно таблице ASCII восемью битами. Посмотрим, как будут кодироваться эти символы в сжатом файле. Для этого построим соответствующее дерево (не забываем сортировать полученный набор):
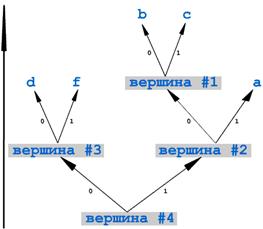
1. {(d,11), (f,10), (a,6), (b,6), (c,4)};
2. {(d,11), (f,10), (вершина #1, 10), (a,6)} (заметьте, сортировка по убыванию частот обязательна!);
3. {(вершина #2, 16), (d,11), (f,10)};
4. {(вершина #3, 21), (вершина #2, 16)};
5. {(вершина #4, 37)}
Анализируя полученное дерево, расписываем, как будет кодироваться каждый из символов после сжатия:
a - "11"
b - "100"
c - "101"
d - "00"
f - "01".
|
|
В двоичном виде файл будет выглядеть так:
хххх{88 bit, end of file}
Сжатый файл занял 11 байт (последние четыре бита xxxx записываются произвольно, ведь весь файл на самом деле умещается в 84 бита, что не кратно восьми). Коэффициент сжатия при таком кодировании равен 3,5.
Руководство к программе
Запустите программу
Рисунок 1 Главное окно программы
На панели «Установки» можно выбрать какое действие произвести с данными (упаковать/распаковать). Также можно выбрать выводить или нет отчет о ходе процесса архивирования. Пути для открытия и сохранения устанавливаются нажатием соответствующей кнопки.

Рисунок 2 Выбор файла для архивирования и задание будущего архива
Если при упаковке файла в установках стояла галочка выводить отчет то отобразится следующее окно

Рисунок 3 Отчёт о процессе архивирования
При повторном нажатии кнопки Далее файл архивируется
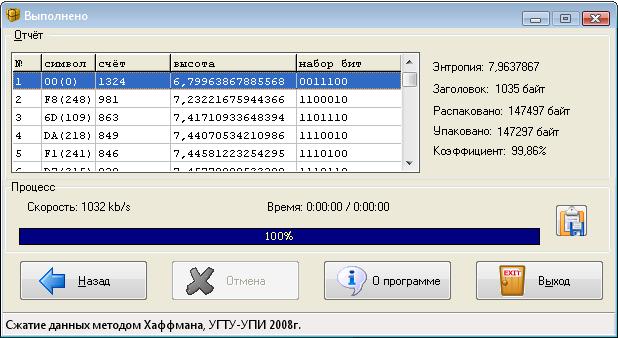
Рисунок 4 Завершение процесса архивирования
Если галочка о выводе отчета не была установлена окно выполнения архивирования будет выглядеть следующим образом
Рисунок 5 Завершение процесса архивирования
Процесс разархивации происходит аналогично.

Рисунок 6 Завершение процесса разархивирования
Сравнение сжатия файлов
В результате работы с программой, при упаковке различных файлов с информацией были получены следующие данные размеров файлов.

Код программы
unit unit1;
interface
uses
Mpacklib, Listlib, Errlib, ExtCtrls, Dialogs, Gauges, ComCtrls, Buttons,
Grids, StdCtrls, Controls, Classes, Forms, SysUtils, Graphics, XPMan;
type
TForm1 = class(TForm)
OpenName: TEdit;
SaveName: TEdit;
OpenDialog: TOpenDialog;
SaveDialog: TSaveDialog;
OpenTxt: TLabel;
SaveTxt: TLabel;
PackButton: TRadioButton;
UnPackButton: TRadioButton;
ShowReport: TCheckBox;
SettingBox: TGroupBox;
StatusBar1: TStatusBar;
Gauge: TGauge;
Timer1: TTimer;
ReportBox: TGroupBox;
StringGrid1: TStringGrid;
Speed: TLabel;
Time: TLabel;
ProcessBox: TGroupBox;
ExitBtn: TBitBtn;
PrevBtn: TBitBtn;
NextBtn: TBitBtn;
CancelBtn: TBitBtn;
RepUnpackTxt: TLabel;
RepPackTxt: TLabel;
RepRatioTxt: TLabel;
RepUnpackVal: TLabel;
RepPackVal: TLabel;
RepRatioVal: TLabel;
RepHeaderTxt: TLabel;
RepEntropyTxt: TLabel;
RepEntropyVal: TLabel;
RepHeaderVal: TLabel;
OpenBtn: TSpeedButton;
SaveBtn: TSpeedButton;
Image1: TImage;
Image2: TImage;
Image3: TImage;
Bevel1: TBevel;
BitBtn1: TBitBtn;
SaveReport: TSpeedButton;
XPManifest1: TXPManifest;
Image4: TImage;
procedure OpenBtnClick(Sender: TObject);
procedure SaveBtnClick(Sender: TObject);
procedure FormCreate(Sender: TObject);
procedure Timer1Timer(Sender: TObject);
procedure FormClose(Sender: TObject; var Action: TCloseAction);
procedure PackButtonClick(Sender: TObject);
procedure UnPackButtonClick(Sender: TObject);
procedure SaveReportClick(Sender: TObject);
procedure NextBtnClick(Sender: TObject);
procedure ExitBtnClick(Sender: TObject);
procedure PrevBtnClick(Sender: TObject);
procedure CancelBtnClick(Sender: TObject);
procedure BitBtn1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
type
Thread = class(TThread)
private
{ Private declarations }
protected
procedure Execute; override;
end;
type TPackFunc = function(si, so:string; genlist:boolean):boolean;
var
Form1:TForm1;
step:byte;
l:ptr;
PackFunc:TPackFunc;
PackFuncResult, NeedStepParser, RunProcess:boolean;
NThread:Thread;
MsgDlg:record
strng:string;
typ:TMsgDlgType;
enable:boolean;
end;
TecTime, Timer, Time1,Time2:TDateTime;
Do1,Do2:integer;
Title:string;
implementation
procedure Error(strng:string; typ:TMsgDlgType);
begin
MsgDlg. strng:=strng;
MsgDlg. typ:=typ;
MsgDlg. enable:=true;
end;
function CheckMask(name, ext:string):string;
begin
if pos('.',name)=0 then
CheckMask:=name+'.'+ext
else
CheckMask:=name;
end;
function GetSec(time:TDateTime):real;
var Hour, Min, Sec, MSec Word;
begin
DecodeTime(Time, Hour, Min, Sec, MSec);
GetSec:=Sec+MSec/1000;
end;
procedure TimerInit;
begin
Form1.Speed. Caption:='Скорость:'; Form1.Speed. visible:=true;
Form1.Time. Caption:='Время: 0:00:00 / 0:00:00'; Form1.Time. visible:=true;
Timer:=Now; TecTime:=Now;
Time1:=Timer; Time2:=Timer;
Do1:=0; Do2:=0;
end;
=*=
function Pack1(si, so:string; genlist:boolean):boolean;
var i, err, fsi, fsh:longint;
fso:currency;
root:PointRec;
h:extended;
p:ptr;
el:elementtype;
begin
Pack1:=false;
Title:='Построение дерева...';
if si='' then begin
Error('Путь для открытия файла неустановлен',mtWarning);
exit;
end;
{ инициализация словаря }
for i:=1 to 256 do begin
dict[i].n:=i-1;
dict[i].c:=0;
dict[i].b:='';
dict[i].f:=true;
end;
{ открытие входного файла }
assign(fi, si);
reset(fi,1);
err:=ioresult;
if err<>0 then begin
Error(si+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
{ анализ }
fsi:=filesize(fi);
if fsi=0 then begin
Error('файл '+si+' пустой',mtInformation);
exit;
end;
TimerInit;
RunProcess:=true;
while not eof(fi) do begin
if NThread. Terminated then exit;
i:=round(filepos(fi)/fsi*100);
Form1.Gauge. progress:=i;
Title:='('+inttostr(i)+'%) Построение дерева...';
TecTime:=now;
BlockRead(fi, Buffer, BuffSize, BuffSizeOk);
err:=ioresult;
if err<>0 then begin
Error(si+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
for i:=1 to BuffSizeOk do
inc(dict[buffer[i]+1].c);
end;
{ сортировка }
Sort(256,'c');
{ расчет кол-ва ненулевых эл-тов }
nd:=256;
while dict[nd].c=0 do dec(nd);
{ построение дерева }
nt:=0;
TreeBuild(root);
BitMapCompile(root,'');
Pack1:=true;
if not genlist then exit;
{ рапорт }
h:=0;
ListMakeNull(l);
for i:=1 to nd do begin
el. n:=i;
el. char:=dict[i].n;
el. count:=dict[i].c;
el. hi:=ln(fsi/dict[i].c)/ln(2);
h:=h+dict[i].c/fsi*el. hi;
el. bmp:=dict[i].b;
ListInsert(el, p,l);
end;
fso:=0;
for i:=1 to nd do
fso:=fso+dict[i].c*length(dict[i].b);
fso:=trunc((fso-1)/8+1);
if nd*(sizeof(dict[i].n)+sizeof(dict[i].c)) < 256*sizeof(dict[i].c) then
fsh:=nd*(sizeof(dict[i].n)+sizeof(dict[i].c))
else
fsh:=256*sizeof(dict[i].c);
fsh:=5+sizeof(fsi)+sizeof(nd)+fsh;
Form1.RepEntropyVal. Caption:=floattostrf(h, ffGeneral,8,8);
Form1.RepHeaderVal. Caption:=inttostr(fsh)+' байт';
Form1.RepUnpackVal. Caption:=inttostr(fsi)+' байт';
Form1.RepPackVal. Caption:=floattostr(fso)+' байт';
Form1.RepRatioVal. Caption:=floattostr(round(fso/fsi*10000)/100)+'%';
end;
=*=
function Pack2(si, so:string; genlist:boolean):boolean;
var i, j,err, fs, ab:longint;
abn:byte;
id:string[5] absolute Buffer;
begin
Pack2:=false;
Title:='Упаковка...';
if so='' then begin
Error('Путь для сохранения файла неустановлен',mtWarning);
exit;
end;
{ открытие выходного файла }
assign(fo, so);
rewrite(fo,1);
err:=ioresult;
if err<>0 then begin
Error(so+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
reset(fi,1);
fs:=filesize(fi);
{ заголовок }
id:='HAF'#26;
if nd*(sizeof(dict[i].n)+sizeof(dict[i].c)) < 256*sizeof(dict[i].c) then
id[5]:=#1
else
id[5]:=#2;
BlockWrite(fo, id[1],5);
BlockWrite(fo, fs, sizeof(fs));
BlockWrite(fo, nd, sizeof(nd));
if id[5]=#1 then begin
for i:=1 to nd do begin
BlockWrite(fo, dict[i].n, sizeof(dict[i].n));
BlockWrite(fo, dict[i].c, sizeof(dict[i].c));
end;
Sort(256,'n');
end
else begin
Sort(256,'n');
for i:=1 to 256 do
BlockWrite(fo, dict[i].c, sizeof(dict[i].c));
end;
{ сжатие }
abn:=0;
TimerInit;
RunProcess:=true;
if nd<>1 then while not eof(fi) do begin
if NThread. Terminated then exit;
i:=round(filepos(fi)/fs*100);
Form1.Gauge. progress:=i;
Title:='('+inttostr(i)+'%) Упаковка...';
TecTime:=now;
BlockRead(fi, Buffer, BuffSize, BuffSizeOk);
err:=ioresult;
if err<>0 then begin
Error(si+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
for i:=1 to BuffSizeOk do
for j:=1 to length(dict[Buffer[i]+1].b) do begin
if dict[Buffer[i]+1].b[j]='1' then
ab:=ab or (longint(1) shl abn)
else
ab:=ab and not (longint(1) shl abn);
inc(abn);
if abn=32 then begin
BlockWrite(fo, ab, sizeof(ab));
err:=ioresult;
if err<>0 then begin
Error(so+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
abn:=0;
end;
end;
end;
if abn>0 then begin
BlockWrite(fo, ab, trunc((abn-1)/8+1));
err:=ioresult;
if err<>0 then begin
Error(so+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
end;
{ close(fi);
close(fo);}
Pack2:=true;
end;
function UnPack(si, so:string; genlist:boolean):boolean;
var root, next:PointRec;
i, j,err, fs:integer;
id:string[5] absolute Buffer;
begin
UnPack:=false;
Title:='Распаковка...';
if (si='') or (so='') then begin
Error('Имя файла неустановлено',mtWarning);
exit;
end;
assign(fi, si);
reset(fi,1);
err:=ioresult;
if err<>0 then begin
Error(si+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
BlockRead(fi, id[1],5,BuffSizeOk); id[0]:=#5;
if (BuffSizeOk<>5) or ((id<>'HAF'#26#1) and (id<>'HAF'#26#2)) then begin
Error(si+' - Файл упакован неправильно',mtWarning);
exit;
end;
BlockRead(fi, fs, sizeof(fs));
BlockRead(fi, nd, sizeof(nd));
if id[5]=#1 then
for i:=1 to nd do begin
BlockRead(fi, dict[i].n, sizeof(dict[i].n));
BlockRead(fi, dict[i].c, sizeof(dict[i].c));
dict[i].f:=true;
end
else begin
for i:=1 to 256 do begin
dict[i].n:=i-1;
BlockRead(fi, dict[i].c, sizeof(dict[i].c));
dict[i].f:=true;
end;
Sort(256,'c');
end;
nt:=0;
TreeBuild(root);
assign(fo, so);
rewrite(fo,1);
err:=ioresult;
if err<>0 then begin
Error(so+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
if dict[1].c=fs then begin
FillChar(Buffer, BuffSize, dict[1].n);
while filepos(fo)<fs do begin
if NThread. Terminated then exit;
i:=round(filepos(fo)/fs*100);
Form1.Gauge. progress:=i;
Title:='('+inttostr(i)+'%) Распаковка...';
if filepos(fo)+BuffSize<fs then
BlockWrite(fo, Buffer, BuffSize)
else
BlockWrite(fo, Buffer, fs-filepos(fo));
err:=ioresult;
if err<>0 then begin
Error(so+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
end;
end
else begin
next:=root;
TimerInit;
RunProcess:=true;
while not eof(fi) do begin
if NThread. Terminated then exit;
BlockRead(fi, Buffer, BuffSize, BuffSizeOk);
err:=ioresult;
if err<>0 then begin
Error(si+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end;
i:=round(filepos(fo)/fs*100);
Form1.Gauge. progress:=i;
Title:='('+inttostr(i)+'%) Распаковка...';
for i:=1 to BuffSizeOk do
for j:=0 to 7 do begin
if ((Buffer[i] shr j) and 1) <> 0 then next:=tree[next. i].l else next:=tree[next. i].r;
if next. d='d' then begin
if filepos(fo)<fs then begin
TecTime:=now;
BlockWrite(fo, dict[next. i].n, sizeof(dict[next. i].n));
err:=ioresult;
if err<>0 then begin
Error(so+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError);
exit;
end
end
else
break;
next:=root;
end;
end;
end;
end;
UnPack:=true;
end;
procedure StepParser;
var p:ptr;
y:integer;
begin
case step of
1: begin {initiate}
Form1.OpenName. Enabled:=true;
Form1.SaveName. Enabled:=true;
Form1.OpenBtn. Enabled:=true;
Form1.SaveBtn. Enabled:=true;
Form1.PackButton. Enabled:=true;
Form1.UnPackButton. Enabled:=true;
if Form1.PackButton. Checked then
Form1.ShowReport. Enabled:=true
else
Form1.ShowReport. Enabled:=false;
Title:='Сжатие данных методом Хаффмана';
Form1.Speed. Visible:=false;
Form1.Time. Visible:=false;
Form1.SaveReport. Visible:=false;
Form1.Gauge. Visible:=false;
Form1.PrevBtn. Enabled:=false;
Form1.NextBtn. Enabled:=true;
Form1.NextBtn. Visible:=true;
Form1.CancelBtn. Visible:=false;
Form1.ExitBtn. Enabled:=true;
Form1.SettingBox. Visible:=true;
Form1.ReportBox. Visible:=false;
end;
2: begin {pack1/unpack}
Form1.OpenName. Enabled:=false;
Form1.SaveName. Enabled:=false;
Form1.OpenBtn. Enabled:=false;
Form1.SaveBtn. Enabled:=false;
Form1.PackButton. Enabled:=false;
Form1.UnPackButton. Enabled:=false;
Form1.ShowReport. Enabled:=false;
Form1.Gauge. Progress:=0;
Form1.Gauge. Visible:=true;
Form1.PrevBtn. Enabled:=false;
Form1.CancelBtn. Enabled:=true;
Form1.CancelBtn. Visible:=true;
Form1.NextBtn. Visible:=false;
Form1.ExitBtn. Enabled:=false;
if Form1.PackButton. Checked then begin
PackFunc:=Pack1;
NThread:=Thread. Create(false);
end
else begin
PackFunc:=UnPack;
NThread:=Thread. Create(false);
end;
end;
3: begin {end}
if PackFuncResult then begin
Title:='Выполнено';
Form1.Gauge. Progress:=100;
end
else begin
Title:='Не законцено!';
end;
Form1.PrevBtn. Enabled:=true;
Form1.NextBtn. Enabled:=false;
Form1.CancelBtn. Enabled:=false;
Form1.ExitBtn. Enabled:=true;
end;
4: begin {report}
Form1.Gauge. Progress:=100;
Form1.PrevBtn. Enabled:=true;
Form1.NextBtn. Enabled:=true;
Form1.NextBtn. Visible:=true;
Form1.CancelBtn. Visible:=false;
Form1.ExitBtn. Enabled:=true;
Title:='Просмотр отчёта';
p:=l; y:=1;
Form1.StringGrid1.cells[0,y-1]:='№';
Form1.StringGrid1.cells[1,y-1]:='символ';
Form1.StringGrid1.cells[2,y-1]:='счёт';
Form1.StringGrid1.cells[3,y-1]:='высота';
Form1.StringGrid1.cells[4,y-1]:='набор бит';
while p<>nil do begin
inc(y);
Form1.StringGrid1.cells[0,y-1]:=inttostr(p^.element. n);
Form1.StringGrid1.cells[1,y-1]:=inttohex(p^.element. char,2)+'('+inttostr(p^.element. char)+')';
Form1.StringGrid1.cells[2,y-1]:=inttostr(p^.element. count);
Form1.StringGrid1.cells[3,y-1]:=floattostr(p^.element. hi);
Form1.StringGrid1.cells[4,y-1]:=p^.element. bmp;
p:=p^.next;
end;
Form1.StringGrid1.RowCount:=y;
Form1.ReportBox. Visible:=true;
Form1.SettingBox. Visible:=false;
Form1.SaveReport. Visible:=true;
end;
5: begin {pack2}
Form1.Gauge. Progress:=0;
Form1.PrevBtn. Enabled:=false;
Form1.CancelBtn. Enabled:=true;
Form1.CancelBtn. Visible:=true;
Form1.NextBtn. Visible:=false;
Form1.ExitBtn. Enabled:=false;
PackFunc:=Pack2;
NThread:=Thread. Create(false);
end;
end;
end;
procedure Thread. Execute;
begin
FreeOnTerminate:=true;
PackFuncResult:=PackFunc(Form1.openname. text, Form1.savename. text, Form1.ShowReport. Checked);
RunProcess:=false;
close(fi);
close(fo);
if not PackFuncResult then erase(fo);
if Form1.PackButton. Checked and (step=2) and PackFuncResult then
if Form1.ShowReport. Checked then
step:=4
else
step:=5
else
step:=3;
NeedStepParser:=true;
end;
procedure TForm1.OpenBtnClick(Sender: TObject);
begin
if OpenDialog. Execute then
if OpenDialog. FilterIndex=1 then
openname. text:=CheckMask(OpenDialog. FileName,'haf')
else
openname. text:=OpenDialog. FileName;
end;
procedure TForm1.SaveBtnClick(Sender: TObject);
begin
if SaveDialog. Execute then
if SaveDialog. FilterIndex=1 then
savename. text:=CheckMask(SaveDialog. FileName,'haf')
else
savename. text:=SaveDialog. FileName;
end;
procedure TForm1.FormCreate(Sender: TObject);
begin
step:=1;
l:=nil;
NeedStepParser:=true;
MsgDlg. enable:=false;
FileMode:=fmOpenRead+fmShareDenyWrite;
end;
procedure TForm1.NextBtnClick(Sender: TObject);
begin
Image4.Visible:=False;
inc(step);
NeedStepParser:=false;
StepParser;
end;
procedure TForm1.Timer1Timer(Sender: TObject);
begin
if NeedStepParser then begin
NeedStepParser:=false;
StepParser;
end;
if MsgDlg. enable then begin
MsgDlg. enable:=false;
MessageDlg(MsgDlg. strng, MsgDlg. typ, [mbOk], 0);
end;
if RunProcess then begin
if GetSec(TecTime-timer)>0 then
Form1.Time. Caption:='Время: '+timetostr(TecTime-Timer)+' / '
+timetostr(TecTime-Timer+(filesize(fi)-filepos(fi))/(filepos(fi)/(TecTime-Timer)));
if Time2=Timer then begin
if GetSec(TecTime-Timer)>10 then begin
Time2:=TecTime; Do2:=filepos(fi);
end;
if Time1=Timer then
if GetSec(TecTime-Timer)>5 then begin
Time1:=TecTime; Do1:=filepos(fi);
end;
end
else
if GetSec(TecTime-Time2)>15 then begin
Time2:=Time1; Do2:=Do1;
Time1:=TecTime; Do1:=filepos(fi);
end;
if GetSec(TecTime-Time2)<>0 then
Form1.Speed. Caption:='Скорость: '+inttostr(round((filepos(fi)-Do2)/GetSec(TecTime-Time2)/1024))+' kb/s';
end;
Form1.Caption:=Title;
Application. Title:=Title;
end;
procedure TForm1.ExitBtnClick(Sender: TObject);
begin
close;
end;
procedure TForm1.PrevBtnClick(Sender: TObject);
begin
Image4.Visible:=True;
step:=1;
NeedStepParser:=false;
StepParser;
end;
procedure TForm1.FormClose(Sender: TObject; var Action: TCloseAction);
begin
ListMakeNull(l);
end;
procedure TForm1.PackButtonClick(Sender: TObject);
begin
OpenDialog. FilterIndex:=2;
SaveDialog. FilterIndex:=1;
ShowReport. Enabled:=true;
end;
procedure TForm1.UnPackButtonClick(Sender: TObject);
begin
OpenDialog. FilterIndex:=1;
SaveDialog. FilterIndex:=2;
ShowReport. Enabled:=false;
end;
procedure TForm1.SaveReportClick(Sender: TObject);
var i, j,err:integer;
fname:string;
f:textfile;
begin
SaveDialog. Filter:='HTML документ|*.htm*';
if SaveDialog. Execute then begin
fname:=CheckMask(SaveDialog. FileName,'htm');
assignfile(f, fname);
rewrite(f);
err:=ioresult;
if err<>0 then
error(fname+' - '+ErrStr(err)+' ('+inttostr(err)+')',mtError)
else begin
writeln(f,'<HTML>');
writeln(f,'<HEAD>');
writeln(f,'<TITLE>Хаффман отчёт</TITLE>');
writeln(f,'</HEAD>');
writeln(f,'<BODY>');
writeln(f,'<TABLE BORDER>');
for i:=0 to StringGrid1.RowCount-1 do begin
write(f,'<TR>');
for j:=0 to StringGrid1.ColCount-1 do
write(f,'<TD>'+StringGrid1.cells[j, i]+'</TD>');
writeln(f,'</TR>');
end;
writeln(f,'</TABLE>');
writeln(f, Form1.RepEntropyTxt. Caption+#32+Form1.RepEntropyVal. Caption+'<br>');
writeln(f, Form1.RepUnpackTxt. Caption+#32+Form1.RepUnpackVal. Caption+'<br>');
writeln(f, Form1.RepPackTxt. Caption+#32+Form1.RepPackVal. Caption+'<br>');
writeln(f, Form1.RepRatioTxt. Caption+#32+Form1.RepRatioVal. Caption+'<br>');
writeln(f, Form1.RepHeaderTxt. Caption+#32+Form1.RepHeaderVal. Caption+'<br>');
writeln(f,'</BODY>');
writeln(f,'</HTML>');
closefile(f);
end;
end;
SaveDialog. Filter:='{Хаффман файлы|*.haf|Все файлы|*.*';
end;
procedure TForm1.CancelBtnClick(Sender: TObject);
begin
NThread. Terminate;
inc(step);
NeedStepParser:=false;
StepParser;
end;
procedure TForm1.BitBtn1Click(Sender: TObject);
begin
MessageDlg('АРХИВАТОР'+#13+'Сжимает данные по методу Хаффмана.'+#13+'Автор: '+#13+' гр. ИТЗ26010дт '+#13+'УГТУ-УПИ 2008г', mtInformation, [mbOk], 0);
end;
end.
Вывод
В результате проделанной работы было изучено большое количество литературы, рассмотрены несколько алгоритмов сжатия. Написана программа для сжатия/распаковки данных по алгоритму Хаффмана. Программа была протестирована на компьютерах с не установленной на них средой Delphi, и успешно работала. Был получен достаточно высокий метод сжатия.
Алгоритм основан на том факте, что некоторые символы из стандартного 256-символьного набора в произвольном тексте могут встречаться чаще среднего периода повтора, а другие, соответственно, – реже. Следовательно, если для записи распространенных символов использовать короткие последовательности бит, длиной меньше 8, а для записи редких символов – длинные, то суммарный объем файла уменьшится.
Хаффман предложил очень простой алгоритм определения того, какой символ необходимо кодировать каким кодом для получения файла с длиной, очень близкой к его энтропии (то есть информационной насыщенности).
В теории кодирования информации показывается, что код Хаффмана является префиксным, то есть код никакого символа не является началом кода какого-либо другого символа. А из этого следует, что код Хаффмана однозначно восстановим получателем, даже если не сообщается длина кода каждого переданного символа. Получателю пересылают только дерево Хаффмана в компактном виде, а затем входная последовательность кодов символов декодируется им самостоятельно без какой-либо дополнительной информации.
«С 1952 года алгоритм Хаффмана стал базой для огромного количества дальнейших исследований в этой области. По сей день в компьютерных журналах можно найти большое количество публикаций, посвященных различным реализациям данного алгоритма и поискам его лучшего применения. Кодирование Хаффмана используется в коммерческих программах сжатия (например, в PKZIP и LHA), встроено в некоторые телефаксы, используется в алгоритме JPEG сжатия графических изображений с потерями.»
Литература:
1. А. Хомоненко «Delphi 7» СПб.: 2003г
2. Д. Мастрюков «Алгоритмы сжатия информации»
3. Д. Арапов «Пишем упаковщик»
4. Журнал «Монитор» статья «Кодирование Хаффмана», номер 7-8, 1993г
5. http://*****/compress/ Всё о сжатии
6. http://algolist. *****/ Общие алгоритмы сжатия и кодирования
7. http://piterustinoff. *****/ Архиватор собственными руками
