
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Требования к БД
БД – совокупность спец. образом организованных данных, хранимых в памяти ВС, и отражающих состояние объектов и их взаимосвязей.
Основные требования к организации БД:
1. Установление многосторонних связей 2. Производительность
3. Мин. Затраты 4. Мин. Избыточность (мин. Использование памяти)
5. Возможность поиска 6. Целостность (восстановление данных)
7. Безопасность и секретность (без – защита от доступа третьих лиц, секр – возможность руководит без.)
[Как обеспечить безопасность:
а. Данные должны быть восстановимы б. Возможность контроля данных
в. Система недоступна для вмешательства в нее
г. Процедура идентификации
д. Данные защищены от хищения, уничтожения, изменения
е. Контроль действий пользователя с точки зрения допустимости]
8. Связь с прошлым. Совместимость версий
9. Связь с будущим. Данные отделены от их представления
10. Настройка БД 11. Перемещение данных 12. Простота
2. Основные компоненты СУБД
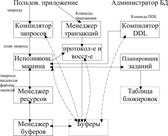
Транзакции – процессы, которые должны выполняться атомарно.
Свойства транзакций – атомарность, изолированность, устойчивость.
Условия каждой завершенной транзакции должны быть зафиксированы в БД, когда система выходит из строя
планировщик заданий отвечает за атомарность и изолированность
менеджер протоколирования и восстановления гарантирует устойчивость
Процессор транзакции выполняет функции
1. протоколирование 2. управление параллельными заданиями
3. разрешение взаимоблокировок
Процессор запросов:
1. Компилятор запросов 2. Исполняющая машина
Компилятор запросов:
1. Синтаксический анализатор на основе текста создает древовидную структуру данных
2. Препроцессор запросов выполняет семантический анализ запроса и функцию преобразования дерева в дерево алгебраических операторов
3. Оптимизатор запросов преобразует в наиболее эффективную последовательность операций над данными
Менеджер ресурсов должен:
1. Позволять создавать новые БД, и определять их схемы с помощью DDL
2. Позволять создавать запросы и модиф. данные с помощью DML
3. Хранить информацию долгое время. Предотвращать несанкц. Доступ.
4. Управлять одновременным доступом к данным для нескольких пользователей
3. Представление данных в автоматизированных информационных системах.
Информационные системы – совокупность аппаратных и программных средств, предназначенных для решения прикладных задач.
Банк данных – разновидность инф. Сист, в которой реализованы функции централизованного накопления и хранения информации, организованной в одну БД.
состоит: 1. БД или несколько БД. 2. Система управления БД
3. Словари БД 4. администратор БД 5. ВС 6. обслуж. персонал
Наиболее эффективна архитектура клиент-сервер.
РИСУНОК клиент-сервер
Представление данных в ИС
1. Физический уровень
2. Логический уровень
3. Хранение
Единица информации на логическом уровне – логич. запись.
На уровне хранения идет оперирование со структурами хранения, представляющими структуры данных в памяти ЭВМ. Ед. инф – логическая запись. Структура хранения должна поддерживаться программными средствами.
Элементы, информацию о которых сохраняем – объекты.
Набор объектов – совокупность однородных объектов
Атрибуты – свойства, характеризующие объект
Описание логической структуры БД – схема, представляющая собой таблицу типов используемых данных. Она содержит имена объектов, их атрибуты, и указывает на существующую между ними связь. Если схема содержит значения, ее называют экземпляром.
Запись – такая структура, в которую можно помещать конкретные значения данных. (экземпляр записи)
Подсхема – описание данных, которое используется для разработки в прикладных программах.
4. Классификация моделей данных:
Данные – набор каких – либо конкретных значений.
Модель данных – некоторая абстракция, которая, будучи приложена к конкретным данным, позволяет пользователям и разработчикам трактовать это как информацию, то есть сведения, содержащие не только данные, но и связь между ними.
Ограничение целостности – не противореч. данных задан. логич. огранич.
Огранич. зад-тся не только для атриб-тов, но и для типов объ-тов и связей.
Виды связи: 1:1 1:M M:1 M:M
Модель данных, поддерживаемая БД на логическом уровне определяется 3 компонентами:
1. Допустимая структура данных, разнообразие и количество типов объектов, которые можно описать с помощью модели
2. Множество допустимых операций над данными
3. Ограничения для контроля целостности.
Модели данных:
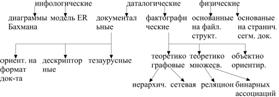
Инфологические модели отражают информационно-логический уровень абстракт, используются на ранних стадиях проекир.
Документ. Модели соответствуют представлению о слабоструктур. информации, ориентированны в основном на свободные форматы документов на естественном языке.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике.
Дескрипторные модели самые простые. Ранее широко использовались. В этих моделях каждому документу соответствует дескриптор (описатель).
5. Инфологическое моделирование
Модель сущность-связь (Entity-RelationShip ER).
Сущность имеет уникальное имя. т. к. сущность соответствует некоторому классу однотипных объектов, то предполагается, что в системе существует множество (сущности представлены таблицами). Объект, которому соответствует понятие сущности, имеет свой набор атрибутов, т. е. характеристик, определяющих свойства данного представителя класса.
Набор атрибутов (полей) должен быть таким, чтобы можно было различать конкретные экземпляры сущности.
Набор атрибутов, однозначно идентифицирующий экземпляр сущности называется ключевым.
Сотрудник | -сущность |
Табельный номер | -ключевой атрибут |
Фио | -атрибуты |
Дата рождения |
Между сущностями могут быть установлены связи – бинарные ассоциации, показывающие, каким образом сущности соотносятся или взаимодействуют. Связи могут быть как между двумя сущностями, так и рекурсивно.

![]() Связь может быть
Связь может быть
|
|
Между двумя сущ. может быть много связй с разными смысл. нагрузками.
Можно использовать принцип категоризации сущности, то есть наследовать сущности друг от друга (как в ООП). Сущность-родитель, от которой строятся подтипы, называется супертипом.
Для построения модели ER проводится системный анализ.
Для библиотеки это будет книги-экземпляры-читатели.
6. Реляционная модель данных.
В основе лежит математическая теория отношений.
Массив данных, представленный реляционным набором структур, образует реляционную БД, и схема РБД будет представлена набором схем-отношений. R1(A11,A12,A13,..A1k) R2(A21,A22,A23,..A2k) R3(A31,A32,A33,..A3k), где R-отношения, A-атрибуты. Пусть A, B атрибуты отношения R.
Говорят, что B функционально зависит от A, если в каждый момент времени каждому A соотв. не более одного значения B.
Если имеется мн-во атрибутов A1-An отношения R, а также множество функц. Завис. XàY, где X и Y подмножества A1-An, Тогда из функц. Завис., входящих в мно-во F могут быть выведены другие функц. Завис., присущие R. F+ - замыкание множества ф-х зависимостей, т. е. полное множество зависимостей, которые могут быть получены из F. Св-ва:
1. Рефлексивность: XÍU, YÍU, YÍX, то XàY
2. пополнение: XÍU, YÍU, ZÍU, XàY, то XÈZàYÈZ
3. транзитивность: XÍU, YÍU, ZÍU, XàY, YàZ, то XàZ
4. расширения: XÍU, YÍU, XàY, то "ZÍU XÈZàY
5. продолжения XÍU, YÍU, WÍU, ZÍU, XàY, то "WÍZ, XÈZàYÈW
6. псевдотранзит. XÍU, YÍU, ZÍU, WÍU, XàY, YÈWàZ, то XÈWàZ
7. аддитивность. X, Y,ZÍU XàY, XàZ, то XàYÈZ
8. декомпозиции X, Y,ZÍU, ZÍY, XàY, то XàZ
Зависимость, не заключающая в себе такой информации, которая не может быть получена на основе других зависимостей, из числа используемых при проектировании БД, называется избыточной. Как правило ее удаляют на начальном этапе проектирования с помощью правил вывода.(пример)
7. Минимальное покрытие
Правила вывода:
1. Аксиомы 1.2.3
1. Рефлексивность: XÍU, YÍU, YÍX, то XàY
2. пополнение: XÍU, YÍU, ZÍU, XàY, то XÈZàYÈZ
3. транзитивность: XÍU, YÍU, ZÍU, XàY, YàZ, то XàZ
2. Из них следуют правила:
1. Объединения AàB, AàC то AàB, C
2. Декомпозиции AàB, C, то AàB, AàC
3. Псевдотранзит: XàY; Y, WàZ; то X, WàZ
По этим правилам определяем избыточные зависимости (пример)
Отношение является избыточным, если
1. Все его атрибуты могут быть найдены в другом отношении набора.
2. Все его атрибуты могут быть найдены в отношении, которое может быть получено из других отношений проективного набора с помощью серии операций объединения.
8. Понятия в реляционной модели. Их связь с жизнью
Детерминант: Если AàB, функциональная зависимость, и B не зависит функционально от любого подмножества A, говорят, что A детерминант B.
Домен – совокупность однотипных значений данных
Степень отношения – число атрибутов, входящих в отношение.
Мощность – число кортежей отношения.
Интенсионал A(R1..Rn) – интенсионал
Экстенсионал – некоторое заполнение кортежей отношений.
Ключ Kотношения R - комбинация атрибутов, обладающих следующими свойствами:
1. в каждом кортеже отношения R величина k единственным образом определяет этот кортеж
2. не существует атрибута в ключе k, который может быть удален без нарушения св-ва 1.
Если в отношении R существует несколько возможных ключей, один из них выбирается в качестве первичного.
Отношение нормализовано, если каждая компонента кортежа является простым атомарным значением, не состоящим из группы значений.
Элементы реляционной модели | Форма представления |
Отношение | Таблица |
Схема отношения | Заголовок таблицы |
Кортеж | Строка таблицы |
Сущность | Свойства объекта |
Атрибут | Заголовок столбца |
Домен | Множество допустимых значений атрибута |
Значение атрибута | Значение поля записи |
Первичный ключ | Один или несколько атрибутов |
ТД | Тип значений элементов таблицы |
9. 6 видов простых запросов:
пусть E1-En - набор объектов. A1-An – множество атрибутов. K11-Knm – домены атрибутов
Форма | Тип запроса |
A(E)=? | Значение атрибута |
A(?)=V >< | Какой объект имеет заданное значение |
?(E)=V >< | Какой атрибут имеет значение |
?(E)=? | Все атрибуты объекта |
A(?)=? | Данный Атрибут для всех объектов |
?(?)=V >< | Все, что равно V |
10. Алгоритм преобразования ER в РМД:
1. Каждой сущности ER соответствует отношение РМД.
2. Каждый атрибут сущности становится атрибутом соответствующего отношения.
3. Первичный ключ сущности становится первичным ключом соответствующего отношения.
4. В каждое отношение соответствующее подчиненной сущности добавляется набор атрибутов основной сущности, являющийся первичным ключом основной сущности
5. Для моделирования необязательного вида связи на физическом уровне у атрибутов, соответствующих внешнему ключу, устанавливается свойство допустимости неопределенных значений. При обязательном типе связи – наоборот.
6. Для отражения категоризации сущности при переходе в РМД возможны несколько вариантов представления. Возможно создать только одно отношение для всех подтипов супертипа. Достоинство – создается всего одно отношение. Недостаток – избыточность. Второй подход – свое отношение для каждого подтипа.
11. НФ1, НФ2, Аномалия
1НФ: каждый атрибут отношений является простым атомарным атрибутом, т. е. отсутствуют составные.
2НФ: отношение нормировано, то есть каждый атрибут полностью зависит то первичного ключа.
Аномалия – такая ситуация в таблице БД, которая приводит к противоречиям в БД, либо существенно усложняет обработку данных.
Разновидности аномалий:
1. избыточность – одинаковые элементы информации повторяются многократно в нескольких кортежах.
2. аномалии изменения – один и тот же фрагмент данных изменяется в одном кортеже, но остается нетронутым в другом.
3. аномалия удаления – если множество значений становится пустым это может косвенным образом привести к потере другой информации
Один из способов устранения аномалии – декомпозиция отношения. Декомпозиция отношения R предполагает разбиение множества атрибутов R c целью построения схем двух новых отношений с последующим занесением в эти отношения определенных в отношении R кортежей. Например таблицу “поставщик, товар, цена” надо разбить на две. В противном случае:
Аномалия включения: пока поставщик не начнет поставлять товар, мы не сможем узнать информацию о товаре.
Аномалия удаления: если поставка товара прекращается, теряется вся информация о товаре.
Аномалия обновления: при изменении цены товара придется обновлять его у всех поставщиков.
12. НФ3
3НФ: каждый непервичный атрибут в отношении R не содержит транзитивных зависимостей от первичного ключа.
Например: хранение (фирма, склад, объем)
Каждая фирма – только с одного склада. Фирмаàсклад, складàобъем
Аномалия включения: Если никто не получает со склада товар, мы не знаем его объем
Аномалия удаления: если последняя фирма перестает получать товар со склада, инфа о складе теряется
Аномалия обновления: если объем склада меняется, нужно менять все объемы для всех фирм
Усиленная 3НФ: в отношении отсутствует зависимость первичных атрибутов от непервичных.
Или Необходимо, чтобы все домены функц. зависимостей были возможными ключами
Например проект(Деталь, проект, поставщик)
В проекте несколько деталей. Каждая деталь – только одним поставщиком. Каждый поставщик обслуж. только один проект.
Деталь, ПроектàПоставщик
ПоставщикàПроект
Аномалия включения: Факт поставки деталей не может быть занесен, пока детали не начнут использовать
Аномалия удаления: Если поставщик ничего не поставляет, его придется убить
Аномалия обновления: Если меняется поставщик какого либо типа деталей, придется менять асе кортежи
13. Пример НФ1,НФ2,НФ3
Отошение преподаватель-предмет
№ препода | Название предмета | Кол-во часов | Фамилия препод. | Должность | оклад | кафедра | телефон |
Отношение с составным ключом номер препода, название предмета.
Функциональные зависимости:
Должностьàоклад, номерàфамилия, кафедраàтелефон, должностьàоклад
Имеется транзитивная зависимость номерàкафедраàтелефон. Значит отошение находится в 1НФ. Имеет место неполная функциональная зависимость фамилия, должность, оклад от части ключа №препода. Эта неполная зависимость приводит к следующим аномалиям:
1. имеет место дублирование данных о преподавателях.
2. проблема избыточности данных. Изменение оклада приводит к изменению кортежа
3. Возникает проблема с преподавателем, который не ведет предметы.
4. Если препод. уходит, приходится удалять предмет.
Чтобы перейти в 2НФ разобьем составной ключ на части, и разделим по зависимости:
Номер препода | предмет | Кол-во часов |
номер | Фамилия | Должность | оклад | кафедра | телефон |
Имеются транзитивные зависимости номерàкафедраàтелефон, номерàдолжн.àоклад
Это приводит к аномалиям:
1. дублирование информации о телефоне
2. Изменение телефона вынуждает искать его для всех преподов
3. нельзя включать данные о новой кафедре, если там нет преподов.
Переходим в 3НФ
должность | Оклад |
кафедра | Телефон |
Номер | фамилия | должность | Кафедра |
14. Переход к 4НФ
Многозначная зависимость существует если при заданных значениях атрибута X существует множество, состоящее из 0 или более взаимосвязанных значений атрибута Y, причем множество значений атрибута Y связано со значением атрибута отношением U-X-Y, где U – все множество атрибутов отношений.
Обозначение многозначной зависимости X->>Y.
Аксиомы многозначной зависимости
1. дополнение X<U, Y<U, X->>Y, то X->>U-X-Y
2. пополнение Если X<U, Y<U, V<U, W<U, V<W, X->>Y, то WuX->>VuY
3. транзитивность Если X<U, Y<U, X->>Y, X->>Z, то X->>Z-Y
Дополнительные правила вывода для многозначных зависимостей
1. объединение Если X<U, Y<U, Z<U, X->>Z, X->>Y, то X->>YuZ
2. псевдотранзитивность Если X<U, Y<U, Z<U, W<U, X->>Y, WuY->>Z, то WuX->>Z-WuY
3. смешанное правило транзитивности Если X<U, Y<U, Z<U, X->>Y, XuYàZ, то XàZ-Y
4. правило декомпозиции X<U, Y<U, Z<U, X->>X, X->>Z, то X->>X^Z, X->>Y-Z, X->>Z-Y
Рассмотрим зависимость (№, курс, дети, должность)
Между преподавателем и курсом связь M:M
Между преподавателем и детьми 1:M
Многозначные зависимости №->>курс, №->>дети
Схема отношения находится в 4НФ, если всякий раз, когда существует многозначная зависимость X->>Y, где Y непусто, и не является подмножеством X, и XvY состоит не из всех атрибутов R, X содержит к-н ключ отношения R, атрибуты, между которыми существует многозначная зависимость, выделяют в отдельные отношения
R1(№,курс) R2(№,дети) R3(№,должность)
Нормализация отношений выполняется декомпозицией их схем. Декомпозиция должна гарантировать обратимость, т. е. обеспечивать получение исходных отношений путем выполнения операции соединения над их проекциями.
Обратимость предполагает:
1. Отсутствие потери кортежей 2. Не появляются ранее отсутствующие кортежи 3. Сохраняются функциональные зависимости
15. Переход в 5НФ
Отношение в 5НФ <=> любая зависимость по соединению V определяется возмож. ключами R иначе каждая проекция R содержит не менее одного возможного ключа и по крайней мере один непервичный атрибут
Процесс нормализации отношений последовательно устраняет следующие типы зависимостей:
1. частичные зависимости неключевых атрибутов от ключа
2. транзитивные зависимости неключевых атрибутов от ключа
3. зависимости ключей от неключевых атрибутов
4. многозначные зависимости
16. Соединение без потерь, сохраняющих зависимость
Из всех возможных разложений схемы должны использоваться только те, которые обладают свойством соединений без потерь. Пусть в схеме R имеется множество функциональных зависимостей. Говорят, что схема R разложима без потерь на отношения R1,R2,Rk, с сохранением функциональной зависимости, если для каждого кортежа r из R может быть r восстановлен соединением его проекций.
Условия отсутствия потерь при соединении:
Если R1 и R2 являются разложением R, с сокращением функциональных зависимостей – это разложение обеспечивает соединение без потерь с сохранением функциональной зависимости <=> если R1^R2àR1-R2 либо R1^R2àR2-R1 при многозначной зависимости R1^R2->>R1-R2, либо R1^R2->>R2-R1
Операции пересечения и разности определены над списками атрибутов отношений.
Пример:
Служащие(№,отдел, город)
1 разложение E1(№, отдел) E2(№, город)
2 разложение E3(№, отдел) E4(отдел, город)
1. E1^E2=№ E1-E2=отдел E2-E1=город. №àотдел, №àгород условие удовлетворяет, разложение без потерь.
2. E3^E4=отдел E3-E4=№ E4-E3=город. отделà№, отделàгород эти зависимости в исходном разложении не существуют, а исходные функциональные зависимости утеряны, значит это разложение с потерями.
Для разложений более чем из двух отношений можно использовать метод Табло
17. Метод Табло
Дано множество функциональных зависимостей, схема отношения полученная в результате разложения. Процедура состоит в построении таблицы, строками которой являются разложенные отношения, а столбцами – список атрибутов этих отношений без повторений. Таблица заполняется символом aj если элементы строки i в столбце j соответствуют атрибуту Aj отношения Ri в противном случае ставится bij. После построения таблицы следует просмотр всех функциональных зависимостей XàY если для атрибутов из X найдутся строки, где в соответствующих местах стоят aj, то элементы bij этих строк соответствующие столбцам атрибутов из Y заменяется на aj. Если в результате появляется строка таблицы, полностью заполненная aj, то это соединение без потерь.
Пример: R(A, B,C, D) Ф. З. AàC, BàC, CàD.
Разложили: R1(A, B) R2(B, D) R3(A, B,C) R4(B, C,D)
…
| AàC
| BàC
| CàD
|
Есть строки со всеми a, разложение без потерь.
18. Реляционная алгебра.
Две группы операций: Традиционные: объединение, пересечение, разность, декартово произведение Специализированные: проекция, ограничение, соединение, деление.
Объединение В результате применения этой операции получается отношение, объединяющее кортежи. Исходные отношения должны иметь одинаковые атрибуты, то есть должны быть объединимыми
R1:
| R2:
| R1uR2
|
Пересечение Получают однотипные кортежи для, общие для R1 и R2
Разность Получаем кортежи, входящие в R1, но не входящие в R2
Декартово произведение Объединяем столбцы как в обычном ДП
Проекция Операция заключается в том, что из отношения R выбираются столбцы, и компонуются в указанном порядке
R
| П3,1(R)
|
Ограничение Включают в выходное отношение множество строк, удовлетворяющее заданному ограничению. Пример: R[A<10]
Соединение Обратная операции проекции. Берутся два отношения, и соединяются, используя указанный атрибут (JOIN): Пример: R1∞R2
Деление R1÷R2=П1,2..n-m(R1)- П1,2..n-m(П1,2..n-m(R1)xR2-R1)
Где R1-n местное отн-ие, R2-mместное отношение n>m. Не дошли руки
19. Реляционное исчисление с переменными кортежами
Формула реляционного исчисления помимо арифметических операций включает дополнительные логические операции (A и E). Используются также операции И, ИЛИ, НЕ.
Формулы реляционного исчисления строятся из атомов и совокупности арифметических и логических операторов, выражение реляционного исчисления с переменными кортежами может иметь вид:
{r|Ψ(r)},где r-кортеж, Ψ(r) – некоторая формула исчисления.
Пример; {r|R1(r)^R2(r)} – необходимо получить множество всех кортежей, таких, что они принадлежат отношениям R1 и R2.
Атомы формул бывают трех типов:
1. R(t), где R – имя отношения, t – кортеж в отношении
2. s[i]θu[j], где s и u – переменные кортежи, θ – арифметический оператор. i, j – номера или имена интересующих столбцов. S[i]- i-й компонент кортежа переменной S u[j]-… 3. s[i]θa, или aθs[i], где a=const.
Вхождение переменной x в формулу РИ Ψ(x) связано, если она находится в части формулы, начинающейся квантором A или E, за которым непосредственно следует переменная x. В таких случаях говорят, что квантор ее связывает. Понятие связанной переменной аналогично понятию локальной переменной, несвязанной аналогично глобальной.
Выражение в РИ является безопасным, если:
1. Из истинности Ψ(t) следует, что каждый компонент кортежа t принадлежит D(Ψ).
2. Для любой подформулы вида (Eu)(Ψ1(u)) входящей в состав Ψ, из истинности Ψ1(u) следует, что u принадлежит D(Ψ1).
3. Для любой подформулы вида (Au)(Ψ1(u)), входящей в состав Ψ, из истинности Ψ1(u) следует, что u не принадлежит D(Ψ1).
Множество D(Ψ) определяется как функция фактических отношений, которая указывается в Ψ(t) констант, присутствующих в формуле Ψ(t) и элементов кортежей тех отношений, которые указывают в θ(t)
D(Ψ)={a1Ψ}U{a2Ψ}U…U{anΨ}UП1(R1)U…UПk(Rn), где aiΨ – const, встреч. В формуле Ψ(t),
Пi(Rj) – проекции кортежей фактических отношений R1-Rn встретившихся в формуле Ψ(t), то есть, в данном случае, компоненты кортежей.
Для каждого выражения реляционной алгебры существует эквивалентное ему безопасное выражение в реляционном исчислении с переменными на кортежах.
20. Реляционное исчисление с переменными на доменах.
Строится так же, как и исчисление на кортежах (с использованием тех же самых операторов).
1. Чего то там Этот атом указывает, что значение тех xi, которые являются переменными д. б. выбраны так, чтобы (x1..xk) было кортежем отношения R.
2. xθy, где x, y-const, или переменные на некотором домене. θ – арифметический оператор сравнения, смысл атома заключается в том, что x и y представляют собой значения, при которых истинно xθy. Формулы в РИ с переменными на доменах также используют A, E, И, ИЛИ, НЕ. Аналогично используются понятия свободной и связанной переменной.
Формула РИ с переменными на домене имеет вид: {x1..xk|Ψ(x1..xk)}, где Ψ – формула, обладающая тем свойством, что только ее свободные переменные на доменах являются различн. Перемен. X1..Xk.
Выражение РИ c переменными на доменах является безопасным, если
1. Из истинности Ψ(x1..xk) следует, что xi принадлежит D(Ψ).
2. Если существует и (Eu)(Ψ1(u)) является подформулой Ψ, то из истинности Ψ1(u) следует, что u принадлежит D(Ψ1)
3. Если для любого u (Au)(Ψ1(u)) является подформулой Ψ1(u) следует, что u не принадлежит D(Ψ1).
Каждому выражению с переменными на доменах существует эквив-е ему выражение реляционного исчисления с переменными на кортежах.
Выражение строится следующим образом:
1. Если t является кортежем арности k, то вводится k новых переменных на доменах t1..tk 2. Атомы R(t) заменяются атомами R(t1..tk) 3. Каждое свободное вхождение t[i] заменяется на ti 4. Для каждого кванта (Eu) и (Au) вводится m новых переменных на доменах u1..um, где u-арность кортежа. В области действия выполняются следующие замены:
RmàR(U1..Um) U[i]àUi EUàEU1..EUm AUàAU1..AUm
Выполняется построение выражения {t1..tk|Ψ`(t1..tk)}, где Ψ’, это Ψ, в которой выполнены соответствующие замены.
21. Сравнение алгебраических языков и языков исчисления.
Языки исчисления – это не процедурные языки, поскольку их средствами можно выразить все, что необходимо, и необязательно указывать, как это получить.
Выражение реал. Алгебры наоборот, специфицирует конкретный порядок выполнения операций. Пример: ISBL (Information System Base Language).
Пример языка на доменах: QBE Пример языка на кортежах: SQL
 SQL: Не процедурный язык. Как правило встроен в среду некоторого языка программирования. Ориентирован на доступ к данным, и не обладает свойствами языка разработки.
SQL: Не процедурный язык. Как правило встроен в среду некоторого языка программирования. Ориентирован на доступ к данным, и не обладает свойствами языка разработки.
Методы использования встроенного SQL:
1. статический: функции языка SQL включены в. exe после компиляции
2. динамический: динамическое построение SQL вызовов и интерпретация. Используется, когда заранее неизвестна форма запроса.
Категории команд:
DDL(Description)Create table, drop table, alter table, create view, drop view, alter view, create index, drop index.
DML(Manipulation)delete(удалить строки), insert (вставить), update(обнов.).
DQL(Query) Select
DCL(Data control language) Используется для управления доступом.
Alter password, grant, rewoke.
АДМИНИСТРИРОВАНИЕ Start audit, stop audit
УПРАВЛЕНИЕ ТРАНЗАКЦИЯМИ Commit, rollback
22. Транзакции
Виды транзакций:
1. Плоские (классические, ACID). Свойства:
атомарности – транзакция должна быть выполнена целиком, или не выполнена вообще
согласованности – транзакция не нарушает взаимной согласов-ти данных
изолированности – конкурирующие на доступ к БД транзакции фактически обрабатываются последовательно.
Долговечности – если транзакция завершена, ее изменения остаются навсегда, даже если потом произойдут ошибки.
Фиксация транзакции – запись измененных данных на диск. После этого они будут видны другим транзакциям.
Откат транзакции - отмена.
В СУБД организован принцип сохр. промеж. сост. подтверждения или отката транзакиции обеспечивается специальным механизмом для поддержания которого создается журнал транзакций. Он предназначен для надежного хранения данных в БД. Это требование предполагает возможность восстановления состояния БД после сбоя.
Принципы восстановления:
1. результаты зафиксированных транзакций должны быть в БД.
2. результаты незафиксированных транзакций должны отсутствовать.
Возможны следующие ситуации, при которых требуется восстановление состояния БД:
1. Индивидуальный откат транзакции (стандартный, аварийное завершение работы, в результате блокировки).
2. Восстановление после потери данных в ОП (мягкий сбой) (отключение электричества, сбой процессора)
3. Восстановление после поломки основного носителя БД (жесткий сбой). Основа восстановления – архивная копия и журнал БД.
Основа восстановления – избыточное хранение данных. Избыточные данные хранятся в журнале, и содержат информацию об изменениях в БД. Возможны 2 варианта:
1. Отдельный (локальный) журнал для каждой транзакции – для откатов.
2. Глобальный журнал для восстановления после сбоев.
23. Параллельное выполнение транзакций
Параллельное выполнение транзакций должно удовлетв. след. условиям:
1. В ходе выполнения транзакции пользователь видит только согласованные данные.
2. Когда 2 транзакции выполняются параллельно, СУБД гарантирует независимое выполнение. Это называется сериализация транзакций. Обычно выполняется с помощью механизма блокировок. Самый простой способ – блокировка (синхронизационный захват) объекта на все время выполнения транзакции. Также может быть блокировка на уровне страниц. Типы блокировок (захватов):
1. Совместный (shared). Нежесткая блокировка. Выполняется при чтении объекта.
2. Жесткая (exclusive). Монопольный захват объекта для операции записи.
Возможны тупики. Основой их обнаружения является построение графа ожидания транзакции. Потом одной из транзакций (самой дешевой) жертвуют – для нее выполняется откат.
24. Иерархическая модель данных.
Самая простая. Появилась первой. Основные информационные единицы база данных, поле, сегмент.
Поле – мин. и независимая единица данных, доступная пользователю с помощью СУБД.
Сегмент (DBTS) - называется записью.
Тип сегмента – поименованная совокупность типов данных.
Экземпляр сегмента образуется из конкретных значений полей.
Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Каждый тип сегмента может иметь ключ.
Сегменты объединяются в древовидный орграф.
Тип сегмента, нах-ся на более высоком уровне иерархии называется лог. исходным по отношению к типам сегмента под ним.(лог. подчиненным).
Схема иерархической БД представляет собой совокупность отдельных деревьев. Каждое дерево в рамках модели называется физ. БД и удовлетворяет следующим ограничениям:
1. Существует 1 корневой сегмент
2. Каждый лог. Исх. Элемент м. б. связан с любым числом подчненных.
3. Каждый логически подчиненный сегмент м. б. связан только с одним родительским.
Сегмент является экземпляром типа сегмента. Между экземплярами сегмента также существует иерархическая связь.
Близнецы – потомки одного типа с одним предком.
Набор всех экземпляров сегмента в одном дереве наз-ся физ. Записью Совокупность физических БД образует концептуальную БД.
Для организации физического размещения используются следующие группы методов:
1. Представление линейным списком с последовательным распред. Памяти
2. Нелинейным списком
Основное правило контроля целостности: потомок не может существовать без родителя, а у некоторых родителей не может быть потомка.
Механизмы поддержания целостности между отдельными деревьями отсутствуют.
(+) 1. Эффективное использование памяти ЭВМ
2. Высокая скорость операций над данными
3. Удобно для работы с иерархически упорядоченными данными
Громоздко для обработки информации с достаточно сложными иерархическими связями.
Пример такой БД – сеть магазинов.
25. Сетевая модель данных
Базовые объекты модели: элемент данных, агрегат данных, запись, набор данных.
Элемент данных – это минимальная информационная единица, доступная пользователю. Аналог поля.
Агрегат данных – совокупность элементов данных, имеющих общее имя, которые могут рассматриваться как единое целое. В модели определены агрегаты двух типов: вектор и повторяющаяся группа.
Вектор – минимальный набор элементов данных. Пример(Адрес: дом улица кварт. город)
Группа – совокупность векторов Пр: Стипендия – повторяющаяся группа с числом повторения 12.
Запись – совокупность агрегатов или элементов данных, аналог сегмента или кортежа.
Существует понятие типа записи и экземпляра записи.
Набор – 2х уровневый граф, связывающий 2 типа записей видом 1:M. Набор отражает иерархическую связь между двумя типами записи. Родительский тип записи – владелец набора. Дочерний – член. Существенным ограничением является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
Пример: учителя и группы
Среди всех наборов определяется сингулярный набор, владелец которого – вся система. Обозначается входящей стрелкой.
(+)Высокие возможности по созданию сложных иерархических структур
Возможность эффективной реализации по затратам памяти и оперативности
(-) Высокая сложность и жесткость схемы БД
Сложность для понимания и обработки информации в БД
Ослаблен контроль целостности
26. Файловые структуры, используемые для хранения инф. в БД.
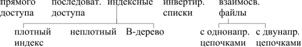
Прямого доступа на устройствах прямого доступа. Имеют фиксированную длину записи, и обеспечивают более быстрый доступ. Адрес м. б. вычислен по номеру записи. Однако поиск по номеру неэффективен. Лучше искать по ключам, поэтому есть ф-я преобразования ключа в номер.(например – хеширование(рассказать))
С переменной длиной записи – последовательного доступа. Тогда конец записи отмечается специальным маркером, либо в начале каждой записи дана ее длина.
Плотный индекс: данные в области данных одинаковой длины. В индексной области все записи упорядочены по значению ключа.
Неплотный индекс – ключ указывает не на запись, а на страницу записей. Внутри страниц записи упорядочены.
Б деревья – построение индекса по индексу
Инвертированные списки: ведется поиск по вторичным ключам. Они м. б. одинаковыми. Инвертированный список – двухуровневая индексная структура. На первом уровне расположены значения вторичных ключей. На втором – блок указателей на записи с таким значением ключа. На третьем – собственно данные.
Деревья – ежику понятно.(LPTR, DATA, RPTR)
27. Распределенная обработка данных. Архитектура клиент-сервер.
Система распределенной обработки данных: БД на одной машине, и с других машин к ней параллельно обращаются несколько пользователей.
Распределенная БД, если БД находится на нескольких машинах.
Бывает и последовательный многопользовательский режим.
Основной принцип технологии клиент-сервер – разделение функций приложения на 5 групп.
1. Функции ввода и отображения данных Presentation Logic
Это собственно интерфейс
2. прикладные функции, определяющие основные алгоритмы решения задач Business logic
3. Функции обработки данных внутри приложения Database Logic
То есть языки запросов и манипуляций с данными
4. Функции управления информационными ресурсами Database Manager System
Собственно СУБД, которая обеспечивает управление БД. В централизов. системе находится в одной машине. В децентрализованной – раскидана между сервером и клиентом.
5. Служебные функции, связывающие первые 4 группы
Модель файлового сервера (FS модель)
В этой модели презентация и логика расположены на клиенте. На сервере располагаются файлы с данными. Клиент обращается к серверу непосредственно с файловыми командами. Вся логика – на клиенте.
(+) низкая нагрузка на сервер. СУБД находится на клиенте
(-) высокий сетевой трафик. Узкий спектр операций манипулирования с данными. Низкие средства безопасности доступа к данным.
Модель удаленного доступа к данным (RDA)
СУБД – на сервере. На клиенте презентация и бизнес логика. Клиент обращается к серверу с SQL запросами.
(+)Разгрузка сервера БД. Мин. число процессов. Сервер свободен от несвойственных ему функций, и целиком занимается обработкой данных. Резко падает трафик. Унификация интерфейса клиент-сервер.
(-) достаточно сложное клиентское приложение
Модель активного сервера БД
Избавимся от недостатков RDA:
1. Необходимо, чтобы данные в БД в каждый момент были непротиворечивы. 2. Постоянный контроль за состоянием БД.
3. Контроль за типами данных.
Эту модель поддерживает большинство современных СУБД (Oracle)
Основа модели: Механизм хранимых процедур(?) как средство программирования SQL сервера. Механизм триггеров для отслеживания текущего состояния. Механизм ограничений на типы данных.
Business Logic расположена на сервере в виде хранимых процедур. Клиент обращается к серверу с командами запуска этих процедур. По сути, на клиенте только презентация.
Сервер может сам вызвать процедуры обработки данных.
(+)Трафик резко падает
Уменьшается дублирование обработки данных
(-)Высокая нагрузка на сервер.
Модель сервера приложения AS модель
Эта модель – расширение двухуровневой модели. Вводится промежуточный уровень между клиентом и сервером. Сервер приложения содержит Business Logic
(+) большая гибкость
(-) высокие аппаратные затраты
28. Многомерные модели
Можно выделить 2 направления:
1. системы оперативной транзакционной обработки.
2. аналитической обработки или системы поддержки принятия решений
Реляционные предназначались для информационных систем оперативной обработки информации. В области аналитической обработки информации более эффективны многомерные СУБД.
Основные понятия:
Агрегируемость: означает просмотр информации на различных уровнях. Ее обобщение. Степень детальности информации зависит от ее уровня.
Историчность: обеспечение высокого уровня статичности данных и их взаимосвязи, а также обязательность привязки данных ко времени. Статичность позволяет использовать при обработке данных специальные методы загрузки, хранения, индексации, выборки
Прогнозируемость: задание функции прогнозирования, и применение ее к различным временным интервалам.
Многомерность модели означает многомерное логическое представление структуры информации при описании и при операциях манипулирования данными. Обладает более высокой наглядностью и информативностью по сравнению с реляционной.
Данные представляют собой срезы из многомерного хранилища
Измерение: это множество однотипных данных, представляющих одну из граней гиперкуба. Например – временное измерение.
Ячейка: значение, которое однозначно определяется фиксированным набором измерений. Тип поля обычно цифровой. Поликубическую модель поддерживает Oracle. Операции:
1. Формирование среза. Срез – подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений.
2. Вращение. Применяется при двумерном представлении данных. Суть заключается в изменении порядка измерения при визуальном представлении данных.
3. Агрегация и детализация. Переход к более общему или более детальному представлению данных.
Основное достоинство модели – эффективность аналитической обработки данных больших объемов, связанных со временем. В реляционной модели происходит нелинейный рост трудоемкости в зависимости от размера.
Недостаток: громоздкость модели для простых задач.
29. Объектно ориентированная модель.
В этой модели при представлении данных имеется возможность иденитифицировать отдельные записи базы данных. Структура о-о БД может быть представлена как дерево, узлами которого являются объекты.
Свойства объектов описываются некоторыми стандартными типами или пользовательскими классами.
Логически структура похожа на структуру иерархической БД.
Основное отличие между ними состоит в методах уринзирования (?) данными.
Логическая структура ООБД: Рисунок какой-нибудь на тему:
База | ||
Свойство | Тип | Значение |
Суть в том, что поле внутри записи может быть классом, и содержать внутри сложную структуру.
…
30. Cache
В основе Cache лежит транзакт многомерное модели данных, которая позволяет хранить и представлять данные так, как они чаще всего используются. Сервер Cache предназначен для обработки транзакции в системе с большими и сверхбольшими БД, и с большим числом (10000)пользователей. Сервер Cache позволяет получать большую производительность, так как Cache не хранит избыточные данные и таблицы. В Cache реализована концепция единой архитектуры данных. К одним и тем же данным, хранящимся под управлением сервера есть три способа доступа:
1. Прямой
2. Объектный. Использует Java, Visual C++, Организован объектный модуль в соответствии с рекомендациями.
3. Реляционный, обеспечивает максимальную производительность реляционных приложений с использованием встроенного SQL. Разработчик может использовать разные типы триггеров и хранимых процедур. Все три типа доступа могут использоваться одновременно одним и тем же приложением. При этом все операции по редактированию выполняются только над одним экземпляром данных. Объектный модуль может описывать бизнес логику и создавать интерфейс с помощью ООП. Реляционный – для совместимости с другими системами.
31. Сервер Cache Object
Объектная модель поддерживает все основные концепции ООП. Наследование, Полиморфизм, Инкапсуляция. Также используются несколько стратегий хранения объекта в БД.
1. Автоматическое хранение в многомерной БД, Cache
2. Хранение в структурах, определенных пользователем.
3. Хранение в таблицах внешней реляционной БД.
Дополнительные возможности (характеристики)
1. классы определяются путем
2. В основе системы лежат объекты и константы, обладающие типом данных. Объекты имеют однозначные идентификаторы, независимые от их внутреннего состояния. Константы не имеют идентификаторов, но имеют значения.
3. Классы могут содержать свойства. Значение свойства объекта определяет его состояние.
4. Свойства могут представлять собой константы ссылки на объекты или встроенные объекты и коллекции их них
5. Классы могут содержать методы.
6. Классы могут содержать генераторы методов.
7. Многие общие характеристики поведения объектов могут автоматически управляться Cache. Также поведение объектов может определяться пользователем.
Виды классов:
Классы | |
классы типов данных | Классы объектов |
Незарегистр. Классы | Зарегистр. Классы |
Встраиваемые классы | Хранимые классы |
Классы типов данных: это специальные классы, определяющие дополнительные значения констант, и позволяющие их контролировать. Содержат опред. набор методов проверки. Не могут содержать св-в.
Классы объектов: определяют структуру и поведение объектов данного типа. Объекты называют экземплярами соответствующего класса. Каждый класс обладает именем, свойствами и методами.
Незарегистрированные классы: все их методы разработчик определяет сам, отвечая за назначение и поддержку уникальных идентификаторов, объектов и объектных ссылок.
Ограничения:
1. Система не выделяет память для значений свойств объектов.
2. Отсутствует автоматическая подкачка объекта, на который делается ссылка. 3. Полиморфизм не поддерживается.
4. Переменные, ссылающиеся на незарегистрированные объекты должны декларироваться с указанием соответствующего класса.
Зарегистрированные классы имеют полный набор методов. Автоматически наследуют методы управления объектов от системного класса. Экземпляры существуют временно в памяти процесса. Их называют временными объектами. Созданием новых объектов, зарегистрированных классов и управлением их размещения в памяти занимается Cache. Наследуются от Library Registered Object. Допускают полиморфизм.
Встраиваемые классы могут храниться не только временно в памяти, но и продолжительное время в БД. Эти классы наследуют свое поведение от класса Library Serial Object. Главное в их поведении – то, что экземпляры в памяти существуют как независимые объекты и могут быть сохранены в БД лишь будучи встроенными в другие объекты.
Хранимые классы обеспечивают длительное хранение экземпляра в БД. Наследуются от Library Persistent. Экземпляры обладают однозначными объектными идентификаторами и могут независимо храниться в Cache. Когда хранимый объект используется как свойство класса говорят о ссылке на хранимые объекты.
Элементы класса:
1. Название
2. Ключевые слова
3. Свойства, то есть элементы данных, хранящихся в классе. Могут быть константами, встроенными объектами и ссылками на хранимые объекты. Классы типов данных не содержат свойств. При доступе к свойствам возможно изменение формата и другое преобразование. Объекты, на которые делаются ссылки автоматически загружаются в память. Свойства могут быть public и private.
4. Методы, то есть код, реализующий те или иные функциональные возможности.
5. Параметры класса, значения, осуществляющие формирование класса во время компиляции.
6. Запросы, то есть операции с множеством операций класса.
7. Индексы – структуры, оптимизирующие доступ к объектам.
Типы данных реализуются классами.
Классы могут
1. Выполнять преобразование данных между форматами, хранимыми в БД, памяти, памяти и отображаемыми.
2. Отвечают за проверку значений
3. Обеспечивают взаимодействие с SQL, Java, ActiveX.
Отличия от классов объектов.
1. Невозможно образование экземпляров
2. не могут содержать свойств
3. методы предоставляются программисту через интерфейс типов данных
4. Имеет методы проверки значений.
Коллекция
Свойства, обладающие множеством значений могут быть представлены в Cache в виде коллекций. Могут содержать константы, объекты, и ссылки на объекты.
Коллекция массив: каждый элемент упорядочивается по ключу.
Коллекция список: в качестве ключа выступает позиция элемента.
позиция | Значение |
Методы – операции, которые может выполнять объект. Каждый аргумент имеет имя, параметры и т. д.
Бывают методы экземпляра и методы класса (static)
Виды методов:
Code – содержит код на языке ObjectScript.
Expression – содержит одно выражение. При компиляции все вызовы метода заменяются этим выражением.
Запросы – могут быть представлены в виде хранимых процедур SQL или представлений. Результаты доступны через специальный интерфейс.
Индексы – Используются для оптимизации скорости выполнения запросов. Каждый индекс создается на основе одного или нескольких свойств класса. Может быть определен метод сортировки
Объектное понятие | Реляционное |
Классы | таблицы |
Экземпляр | Строка |
идентификатор объекта | Ключ |
свойство константа | Столбец |
ссылка на хранимый объект | внешний ключ |
встраиваемый объект | индивидуальные столбцы |
коллекция список | столбец с полем-списком |
коллекция массив | Подтаблица |
поток данных | Блок |
Индекс | Индекс |
Запрос | хранимая процедура |
метод класса | хранимая процедура |
В реляционной модели нет аналогов для параметров классов, многомерных свойств и методов экземпляров. Компилятор Cache автоматически создает таблицы для всех хранимых классов.
32.Universe
Universe представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных в таблицах. Допускает многозначные поля (поля, значения которых состоят из подзначений). Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. Эта постреляционная поддерживает также многоуровневые ассоциированные поля. Совокупность ассоциированных полей называют ассоциацией. При этом, первое значение одного столбца ассоциации соответствует первым значениям всех остальных столюцов ассоциации. Аналогичным образом связанны вторые значения. На длину полей и количество полей в записях не накладывается ограничение постоянства.
Достоинства: возможность представления совокупности связанных таблиц одной постреляционной таблицой.
Недостатки: сложность решения проблемы целостности и непротиворечимости данных.
33. Хранилище данных
В хранилище могут помещаться результаты транзакционных данных, также могут подвергаться конвертированию, чтобы обеспечить совместимость данных, полученных из других источников. Для обеспечения процесса отсечения и извлечения данных используются термины: Расслоение, Расщепление.
Хранимые данные можно модифицировать методами многомерного моделирования с использованием звездообразной схемы, состоящей из таблицы фактов, окруженной таблицами измерений.
Рисунок
Отношения между таблицей фактов и измерений должны быть простыми, чтобы все было понятно. М. б. таблица развертывания измерений
