
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
10. Стек и очередь, общая характеристика, формы представления и операции.
Структура, отражающая отношение соседства между своими элементами, наз. линейной. К линейным структурам можно отнести массивы, очереди, стеки, деки, линейные списки.
Стек.
Это такой последовательный список переменной длины, включение и исключение элементов из которого выполняется только с одной стороны стека, называемого вершиной стека. Выборка элементов осуществляется в порядке, обратном их засылке (LIFO – Last Input – First Output). Это статическое или динамическое множество.
Форма представления: 1) массив: top – показывает на первую свободную ячейку, в которую можно поместить новый элемент, - это точки доступа к элементам; 2) односвязная структура.
Операции: 1) создание стека (конструктор: создание массива или пустого списка); 2) включение элемента в стек push(S, место) (если мест нет, push вернет overflow); 3) удаление элемента из стека (если пусто pop вернет underflow); 4) извлечение данных pop(S) (без удаления самого элемента, указывается номер элемента от вершины); 5) уничтожение стека (освобождение динамической памяти, деструктор); 6) опрос размера; 7) поиск search(S).
Очередь.
Это динамически изменяемый упорядоченный набор элементов. Добавление элементов в очередь производится с одного конца (хвост очереди), а выборка – с другого (голова) в соответствии с правилом FIFO (First In – First Out). Такая очередь является простой очередью без приоритетов. В очередях с приоритетами, более приоритетные элементы включаются ближе к голове очереди, выборка осуществляется с головы очереди.
Форма представления: 1) массив (для статической очереди; это последовательность, замкнутая в кольцо). В момент создания очереди front (первый элемент) = tail (последний элемент) = 0. Так же есть overflow (front = (tail+1) mod n) и underflow (front = tail). 2) односвязная структура.
Операции: 1) создание очереди (конструктор: создание массива или пустого списка); 2) включение нового элемента в очередь (1. очередь заполнена – возврат признака переполнения. 2. в очереди единственный элемент – выбрать элемент и установить указатели в начальное состояние. 3. очередь заполнена частично – выбрать элемент с головы очереди с учетом кольцевой организации, скорректировать указатель головы.) O(log2n); 3) выборка элемента из очереди (если пусто pop вернет underflow) O(1); 5) освобождение очереди (освобождение динамической памяти, деструктор).
Очередь с приоритетами.
Обеспечивает извлечение из очереди элемента с мин. или макс. приоритетом. Как правило, строится на базе массивов, в которых элементы хранятся по схеме через упорядоченные дерево или пирамиду (частично упорядоченное дерево). Добавление нового элемента – сначала в конец очереди, затем size+1, затем просеивание вверх/вниз. При удалении элемент извлекается из корня пирамиды, а на его место записывается самый правый элемент нижестоящего слоя. После этого элемент просеивается по пирамиде вниз, пока не займет правильного положения или не достигнет нижнего слоя.
Высота дерева h = log2n = количество узлов. Наиболее часто пирамида хранится в массиве, элементами которого является пара: приоритет и данные (p, data). Для пирамиды фиксируется индекс последнего элемента. Enqueue (Q, p, data). Dequeue (Q).
Деки.
Это разновидность очереди, в которой включение и выборка элементов возможны с обоих концов. Например, дек может использоваться при управлении памятью, когда расщепление памяти производится сверху и снизу.
Существуют дек с ограниченным входом (допускает включение элементов только на одном конце) и дек с ограниченным выходом (допускает выборку элементов только с одного конца).
Деки могут иметь как векторную, так и списковую (двусвязный) структуру хранения. Операции те же, что и над очередями.
11. Список, общая характеристика, формы представления и операции.
Списком называется упоря-доченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения и доступа к значению по номеру позиции. Список, отражающий отношения соседства между элементами, называется линей-ным. Длина списка равна числу элементов, содержащихся в списке, список нулевой длины называется пустым списком. Линейные связные списки являются простейшими динамическими структурами данных. Графически связи в списках удобно изображать с помощью стрелок. Если компонента не связана ни с какой другой, то в поле указателя записывают значение, не указывающее ни на какой элемент. Такая ссылка обозначается специальным именем - nil.
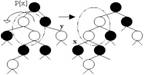 На рис. приведена структура односвязного списка. На нем поле INF - информационное поле, данные, NEXT - указатель на следующий элемент списка. Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка, который обычно по формату отличен от остальных элементов. В поле указателя последнего элемента списка находится специальный признак nil, свидетельствующий о конце списка.
На рис. приведена структура односвязного списка. На нем поле INF - информационное поле, данные, NEXT - указатель на следующий элемент списка. Каждый список должен иметь особый элемент, называемый указателем начала списка или головой списка, который обычно по формату отличен от остальных элементов. В поле указателя последнего элемента списка находится специальный признак nil, свидетельствующий о конце списка.
Двусвязный список характеризуется наличием пары указателей в каждом элементе: на предыдущий элемент и на следующий. Очевидный плюс тут в том, что от данного элемента структуры мы можем пойти в обе стороны. Таким образом упрощаются многие операции. Однако на указатели тратится дополнительная память. Разновидностью рассмотренных видов линейных списков является циклический список, который может быть организован на основе как односвязного, так и двухсвязного списков. При этом в односвязном списке указатель последнего элемента должен указывать на первый элемент; в двухсвязном списке в первом и последнем элементах соответствующие указатели переопределяются. При работе с такими списками несколько упрощаются некоторые процедуры. Однако, при просмотре такого списка следует принять некоторые меры предосторожности, чтобы не попасть в бесконечный цикл.
Форма представления: 1) массив (статический и динамический (надежный)); 2) связанная структура (список на базе массива (в качестве ссылок используются индексы)).
Список на базе массива (если задан предельный размер списка). Поиск – О(1) - достоинство; вставка/удаление – О(n) – недостаток.
Insert (L, v, n).
Односвязный список. List_Insert (L, v, n).
Двусвязный список – вставку и удаление нужно рассматривать отдельно и внимательно.
Кольцевой список с барьерным (фиктивным) элементом. Barier_List_insert (L, v, n). Недостаток – ограниченность массива. Достоинство – 1) гибкая структура без трудоемких перестроек (сдвигов); 2) нет динамического распределения памяти.
Операции: 1) создание списка; 2) уничтожение списка; 3) печать списка; 4) копирование списка; 5) упорядочение списка; 6) поиск элемента; 7) вставка элемента; 8) удаление элемента.
18. Рекурсивный и итеративный алгоритмы вставки в красно-черное дерево.
RB_Insert (root. x) + RB_Insert1 (t, x, S). It_RB_Insert (root, x) + It_L (root, t).
Алгоритм вставки в красно-черное дерево гарантирует логарифмическую эффективность для поисков и включений. В худшем случае, когда путь поиска состоит из чередующихся 3- и 4-узлов, требуется 2logn+2 шагов. Анализ и моделирование RB-деревьев с n узлами, построенных из случайных ключей, показали, что эффективность имеет оценку О(1.02*logn). В этом смысле RB-деревья оптимальны для практического применения и часто включаются в библиотеки. При реализации алгоритма часто используется альтернативный подход при рассмотрении RB-дерева, как дерева с определенными структурными свойствами. При этом игнорируется соответствие с 2-3-4- деревом.
RB-дерево, как структура обладает следующими RB-свойствами: 1) каждый узел либо R, либо B; 2) каждый лист B; 3) если узел R, то оба сына – B; 4) все пути вниз (от корня к листьям) содержат одинаковое число B узлов (одинаковая B высота); 5) корень черный.
Начальная стадия операция вставки и удаления выполняется точно так же, как и в BST-дереве. Узел с новым элементом вставляется в лист дерева и всегда окрашивается в красный цвет. Это может привести к нарушению третьего свойства структуры RB-дерева, если родитель нового узла тоже красный. При удалении узла из RB-дерева может быть нарушено четвертое свойство, если удаленный узел был черным. Алгоритмы операций вставки и удаления восстанавливают свойства RB-дерева путем восходящих поворотов и перекрасок узлов, лежащих на пути вставки и удаления. Тем самым достигается сбалансированность RB-дерева.
Поскольку управление стеком в RB-дереве становится довольно сложным, то вместо стека введем в структуру каждого узла указатель на родителя. Итак, узел RB-дерева содержит, помимо данных, 3 указателя на сыновей и родителя (p[t]), и цвет color[t].
Ссылка nil всегда считается черным псевдолистом. Часто для удобства программирования nil заменяется ссылкой на общий для всех фиктивный черный узел-лист.
При вставке, при нарушении 3-его свойства RB-дерева, возможны три случая конфигурации дерева в области включения нового элемента x.
Случай 1: Если дядя нового узла y-красный, то восстановление свойства в области включения сводится к перекраске родителя и дяди в черный цвет, а деда – в красный. Перекраска не меняет черной высоты дерева.
Но теперь может быть нарушено 3-е свойство выше по дереву.
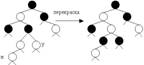
Случай 2, 3 - у красного узла x-родитель красный, но дядя - черный.
Случай 2: разные ориентации в дереве. Используем левый поворот родителя узла x, чтобы свести случай 2 к случаю3.
Случай 3: делаем правый поворот деда узла x и перекраску: опущенный дед перекрашивается в красный цвет, а поднятый родитель – в черный цвет.

Один из лучших методов открытой адресации. Перестановки индексов, возникающие при двойном хешировании, близки к равномерному хешированию. В отличие от линейного и квадратичного методов при двойном хешировании можно получить при правильном выборе h1 и h2 не m, а 0(m2) различных перестановок, поскольку каждой паре (h1 и h2) соответствует своя последовательность проб. Благодаря этому производительность двойного хеширования близка к той, что получилась бы при равномерном хешировании.
Анализ хеширония с открытой адресацией.
Так же как при анализе хеширования с цепочками стоимость операций с открытой адресацией оценивается в терминах коэффициента заполнения α=n/m. Для открытой адресации α ≤ 1. Если предположить идеальный случай, что хеширование равномерно, ключи выбираются случайным образом и все m! последовательностей проб равновероятны, то математическое ожидание проб при поиске в таблице с открытой адресацией отсутствующего элемента будет 1(1- α). Если α отделен от 1, то поиск отсутствующего элемента будет занимать время О(1). Например, при α = 0.5, среднее число проб будет не больше 1/(= 2. Если α = 0.9, то среднее число проб не больше 1/(1 – 0.9) = 10. Точно такую же оценку имеет и математическое ожидание стоимости операции добавления в таблицу. Математическое ожидание(МО) успешного поиска равно 1/α ln (1/1-α). Если таблица заполнена наполовину (α=0.5), то среднее число проб для успешного поиска не превосходит 1.387, а если на 90% - то 2.559.
МО успешного поиска получается усреднением общего числа проб при добавлении каждого элемента. МО общего числа проб равно сумме МО для каждого шага. При добавлении (i+1)-го элемента α = i/m и МО i + 1 = 1/1- αi = 1/(1-i/m) = m/m-i.
Таким образом, общее МО = m ln(m/m-n). Общее МО усредняем, т. е. делим на n: m/n ln(m/m-n) = 1/α ln(1/1-α).
Вставка - О( 1 / (1-α) ); поиск - О( (1/α) * ln( 1/(1+α) ) ); удаление - О(1). 0 < α < 1. α опт. = 0,5.
19. Итеративный алгоритм удаления из красно-черного дерева.
It_RB_Delete (root, k) + RB_FixUp (root, z). О(logn).
Удаление вершины несколько сложнее включения (может быть нарушено 4-ое свойство при удалении черного узла). Для упрощения программирования операции удаления в RB-дерево вводится фиктивный элемент NIL, который будет использоваться вместо ссылок nil в терминальных узлах дерева. Все терминальные узлы, не имеющие сыновей или одного сына, вместо nil имеют ссылку на фиктивный элемент NIL. Фиктивный элемент не содержит ни ключей, ни данных. Используются только ссылки на сыновей и родителя. Цвет фиктивного элемента всегда черный. Благодаря фиктивному узлу все реальные узлы всегда внутренние.
После удаления вызывается дополнительная операция (RB_FixUp), которая восстанавливает нарушенное 4-ое свойство - все пути вниз (от корня к листьям) содержат одинаковое число черных узлов (одинаковая черная высота). Восстановление ведется путем перекрашивания узлов и вращений на пути поиска удаляемого элемента. 1)Если удаляемый узел y-красный, то 4-е свойство RB-дерева не нарушается и операция удаления на этом завершается. 2)Если удалена черная вершина, то выполняется операция RB_FixUp для сына (z) удаленного узла (y). Сыном удаленного узла может быть либо его единственный левый или правый сын, либо фиктивный узел NIL, причем в этот момент p[z] или p[NIL] указывают на родителя удаленного узла y.
RB-дерево, как структура обладает следующими RB-свойствами: 1) каждый узел либо R, либо B; 2) каждый лист B; 3) если узел R, то оба сына – B; 4) все пути вниз (от корня к листьям) содержат одинаковое число B узлов (одинаковая B высота); 5) корень черный.
При удалении черного узла возможны 2 ситуации:
 1) нарушение можно компенсировать, пере-красив узел х в черный цвет. Это позволит ликвидировать и нарушение 3-его свойства, если родитель вырезанного узла у – красный.
1) нарушение можно компенсировать, пере-красив узел х в черный цвет. Это позволит ликвидировать и нарушение 3-его свойства, если родитель вырезанного узла у – красный.
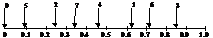 2) применяется перестройка в корне поддерева, где возникло нарушение четвертого свойства. Причем узел х считается дважды черным, способным поделиться своей чернотой с вышележащими на пути к нему узлами. Нужно перестроить вышележащие узлы таким образом, чтобы избавиться от дважды черного узла, не нарушив RB-свойств дерева. Если х – корень, тогда лишняя чернота просто удаляется из дерева. Иначе выполняется циклическая перестройка корней поддеревьев, лежащих на пути к х, путем перекрашивания и вращений влево или вправо.
2) применяется перестройка в корне поддерева, где возникло нарушение четвертого свойства. Причем узел х считается дважды черным, способным поделиться своей чернотой с вышележащими на пути к нему узлами. Нужно перестроить вышележащие узлы таким образом, чтобы избавиться от дважды черного узла, не нарушив RB-свойств дерева. Если х – корень, тогда лишняя чернота просто удаляется из дерева. Иначе выполняется циклическая перестройка корней поддеревьев, лежащих на пути к х, путем перекрашивания и вращений влево или вправо.
Перестройка учитывает 4 возможных случая, которые могут встретиться на пути:
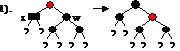 Можно перекрасить родителя х в черный цвет, х сделать обычным черным узлом, а w – красным. На этом перестройка заканчивается.
Можно перекрасить родителя х в черный цвет, х сделать обычным черным узлом, а w – красным. На этом перестройка заканчивается.
Если родитель х – черный, то он становится дважды черным и перестройка поднимается в верхнее поддерево. Если новый х – корень дерева, то лишняя чернота просто удаляется из дерева.
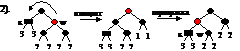 Этот случай можно свести к первому, чтобы братом х стал черный узел. Для этого сделаем левый поворот родителя узла х.
Этот случай можно свести к первому, чтобы братом х стал черный узел. Для этого сделаем левый поворот родителя узла х.
to be continued…
 Сыновья w разно-го цвета. Перекра-сив родителя х в черный цвет, а w – в красный, мы на-рушим свойство 3 для w. Поэтому сделаем сначала правый поворот узла w.
Сыновья w разно-го цвета. Перекра-сив родителя х в черный цвет, а w – в красный, мы на-рушим свойство 3 для w. Поэтому сделаем сначала правый поворот узла w.

Важно, что правый сын узла w – красный. Перекрашивать нельзя. Левый сын может быть и красным и черным. Опять же действие по схеме случая 1 не годится, т. к. это приведет к нарушению свойства 3. Поэтому произведем вращение влево родителя х. Узел х отдает свою черноту родителю, а правый сын узла w перекрашивается в черный цвет. Узел w берет цвет корня поддерева до поворота. В этом случае происходит полное поглощение излишней черноты и на этом перестройка прекращается.
Операция RB_Delete выполняется за O(logn). Обычно производится не более трех вращений.
20. Хеш – таблицы. Типы и особенности функций хеширования.
Применяются для «словарей». Это множество данных большого объема, в котором преобладает операция поиска. Реже происходит вставка и удаление. Т. е. множество со стабильным размером. Это обычный массив с необычной адресацией, задаваемой хеш-функцией. Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа. Хэш-таблицы часто применяются в базах данных, и, особенно, в языковых процессорах типа компиляторов и ассемблеров, где они изящно обслуживают таблицы идентификаторов. В таких приложениях, таблица - наилучшая структура данных. Так как всякий доступ к таблице должен быть произведен через хэш-функцию, функция должна удовлетворять двум требованиям: 1) она должна быть быстрой; 2) она должна порождать хорошие ключи для распределения элементов по таблице. Последнее требование минимизирует коллизии (случаи, когда два разных элемента имеют одинаковое значение хеш-функции) и предотвращает случай, когда элементы данных с близкими значениями попадают только в одну часть таблицы. Один из наиболее эффективных способов реализации словаря - хеш-таблица. Среднее время поиска элемента в ней есть O(1), время для наихудшего случая - O(n).
k | 99 | 199 | 1099 | 4399 | 200199 | 303 | 707 | 100 | 200 |
h1 | 99 | 99 | 99 | 99 | 99 | 3 | 7 | 0 | 0 |
h2 | 99 | 98 | 89 | 56 | 8 | 0 | 0 | 100 | 99 |
Хеш-функции.
Хорошая хеш-функция должна обеспечивать равномерное хеширование, т. е. для любого ключа все m (общее число элементов) хеш-значений должны быть равновероятны.
Модульнное.
Построение хеш-функции методом деления с остатком состоит в том, что ключу k ставится в соответствие остаток от деления k на m, где m – число возможных хеш-значений. h(k) = k mod m. Например, если m=13, k=100, то h(k)=9. Не рекомендуется m=10P, если ключи – десятичные числа. Тогда уже часть младших цифр полностью определяет хеш-значение. Хорошие результаты получаются, если в качестве m выбирать простые числа, далеко отстоящие от степени двойки. Значения, дающие коллизии при любом М – числа, кратные М, М + 1, …, М + m-1. Пример: плохого М (М1=100 - h1(k)=k mod 100) и хорошего М (М2=101 - h2(k)=k mod 101).
Мультипликативное. Пусть количество хеш-значений равно m. Зафиксируем константу А на интервале 0<A<1 и положим h(k) = ëm(k A mod1)û, где k A mod1 – дробная часть kA. Достоинство метода умножения заключается в том, что качество хеш-функции мало зависит от выбора m. Обычно в качестве m – выбирают степень двойки, т. к. в большинстве компьютеров умножение на m реализуется как сдвиг слова. Метод умножения работает при любом выборе константы А, но некоторые значения А могут быть лучше других. Оптимальный выбор А зависит от того, какого рода данные хешируются. Кнут после исследований заключает, что А » (√5 - 1)/2 = 0, является довольно удачным. (√5 - 1)/2 = 0, – золотое сечение. Если рассмотреть интервал [0…1], на котором лежат значения k A mod 1 (дробная часть k A), то можно заметить, как ведут себя последовательные значения k (+ 0)A mod 1, k (+ 1)A mod 1, k (+ 2)A mod 1 и т. д. Каждая новая точка делит наибольший из интервалов золотым сечением (длина отрезка = сумме двух составляющих отрезков). Соответственно ведет себя и хеш-функция: h(k) = ëm(k A mod1)û на интервале ключей [0…m-1].
Выбор цифр.
Основана на выборе цифр. Быстро и легко вычисляется, однако не обеспечивает равномерного распределения элементов в таблице. Напр., из идентификационного номера сотрудника можно извлечь четвертую и последнюю цифры, образовав число 35 – индекс элемента в таблице. Выбирая цифры из поискового ключа, следует быть осторожным, чтобы не произошло совпадение ключей.
Свертка.
Улучшить хеширование можно с помощью суммирования всех цифр поискового ключа. Напр., можно сложить все цифры числа (0+0+1+3+6+4+8+2+5=29). 0 h(ключ) 81. Чтобы модифицировать этот метод или увеличить размер таблицы, можно сгруппировать цифры поискового ключа и складывать группы цифр.
21. Хеш – таблицы с цепочками коллизий и с открытой адресацией. Алгоритмы операций в хеш-таблицах. Методы повторного хеширования в хеш-таблицах с открытой адресацией. Эффективность операций в хеш-таблицах.
Цепочки коллизий. Технология сцепления элементов состоит в том, что элементы множества с одним и тем же хеш-значением связываются в цепочку-список. В позиции j хранится указатель на голову списка тех элементов, у которых хеш-значение ключа равно j. Если таких элементов в таблице нет, то позиция j содержит NIL. Такой способ разрешения коллизий позволяет хранить множества с потенциально бесконечным пространством ключей, снимая ограничения на размер множества. Поэтому этот способ организации хеш-таблицы называется открытым или внешним хешированием.
Каждый элемент хранит указатель на голову списка или NIL. Основная идея при открытом хешировании заключается в том, что потенциальное множество разбивается на конечное число подмножеств. Для m подмножеств, пронумерованных от 0 до m-1 строится хеш-функция h такая, что для любого элемента из исходного множества h(k) принимает целочисленное значение на интервале [0…m]. Значение хеш-функции определяет индекс в массиве указателей Т. Если подмножества примерно одинаковы, то в этом случае списки всех подмножеств должны быть наиболее короткими и средняя длина сегментов будет │U│/ m = α.
Используется массив списков. При хэшировании включаемого ключа получаем место в массиве (фактически попадаем в нужный нам список) и включаем в данный список наши данные(ключ). Графически это может быть проиллюстрированно так: в данном примере размер таблицы = 8. Например, чтобы добавить 11, мы делим 11 на 8 и получаем остаток 3. Таким образом, 11 следует разместить в списке, на начало которого указывает hashTable[3].
Операции поиска и удаления аналогичны. Чтобы найти число, мы его хешируем и проходим по соответствующему списку. Чтобы удалить число, мы находим его и удаляем элемент списка, его содержащий. При добавлении элементов в хеш-таблицу выделяются куски динамической памяти, которые организуются в виде связанных списков, каждый из которых соответствует входу хеш-таблицы. Этот метод называется связыванием.Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай - когда все ключи хешируются в один индекс. При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция.
Вставка - О(1); поиск - О(α); удаление - О(1). α оптим. = 2-5. 1 < α < 10.
Открытая адресация. Хеш-таблицы с открытой адресацией особенно эффективны, когда максимальные размеры входящего набора данных уже известны. Было доказано, что, когда таблица заполняется более чем на 50 процентов, ее эффективность значительно ухудшается (возрастает количество коллизий). Такие таблицы обычно используются для быстродействующего макетирования (они просты для программирования и быстры) и там, где быстрый доступ (нет связанного списка) приоритетен, а память легко доступна.
Хэш-таблица строится на базе динамического массива. При вставке элемента может возникнуть ситуация, что это место в массиве занято в этом случае делается повторное хэширование и т. д. пока либо не будет найдено пустого место либо все варианты будут просмотрены. Повторение элементов не допустимо.
При открытой адресации порядок просмотра зависит от ключа. К хеш-функции добавляется второй аргумент - номер попытки (нумерация начинается с 0). Хеш-функция имеет вид: h:U*{0,1, …,m-1}→{0,1,…,m-1}. Последовательность проб для данного ключа k имеет вид: <h(k,0), h(k,1),…, h(k,m-1)>. Функция h должна быть такой, чтобы каждое из чисел 0, …, m-1 встречалось ровно один раз.
При поиске элемента с ключом k в таблице ячейки просматриваются в том же порядке, что и при вставке элемента с ключом k. Если встречается ячейка, в которой записан NIL, то это значит, что искомого элемента в таблице нет.
Удаление элемента из таблицы с открытой адресацией не так просто. Если записать на его место NIL, то в дальнейшем нельзя будет найти те элементы, в момент добавления которых это место вошло в число проб и было занято, и из-за этого была выбрана более удаленная позиция. Возможное решение – записывать на место удаленного элемента не NIL, а специальное значение DELETED (“удален”), и при добавлении рассматривать ячейку со значением DELETED, как свободную. При поиске эту ячейку нужно рассматривать, как занятую. Недостаток этого подхода в том, что время поиска может оказаться большим даже при низком коэффициенте заполнения.
Поэтому, если требуется удалять записи из хеш-таблицы, то предпочтение отдается хешированию с цепочками.
На практике используются обычно три способа вычисления последовательности проб: линейный, квадратичный и двойное хеширование.
Линейная последовательность проб. h (k, i) = (h`(k) + i) mod m.
Три состояния: занято, свободно, свободно после удаления. У метода очевидный недостаток: он может привести к образованию кластеров – длинных последовательностей занятых ячеек, идущих подряд. Это удлиняет поиск. Недостаток: уходим от О(1) к О(n).
Квадратичная последовательность проб. h (k, i) = (h` (k) + c1i + c2i2) mod m.
h’(k) – хеш-функция; c1 и c2 ≠ 0 – некоторые константы. Номер пробуемой ячейки квадратично зависит от номера попытки. Для того, чтобы использовались все ячейки таблицы, c1 и c2 выбираются не случайно. Как и при линейном методе, вся последовательность проб определяется ключом, т. е. h`(k), поэтому получается m различных перестановок. Однако тенденция к образованию кластеров частично устраняется. Хотя и остается эффект кластеризации в более мягкой форме – образование вторичных кластеров.
Двойное хеширование. h (k, i) = (h`(k) + h’’(k)*i) mod m.
h’(k) – хеш-функция; h'’(k)=k mod (m-1) + 1 – шаг перебора позиций. h'’(k) должна давать любые шаги, зависящие от ключа в пределах таблиццы.
