

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
С. Д. КУЛИК, К. И. ТКАЧЕНКО, И. А. ЛУКЬЯНОВ
Национальный исследовательский ядерный университет «МИФИ»
АВТОМАТИЧЕСКАЯ ГЕНЕРАЦИЯ И РАНЖИРОВАНИЕ ГИПОТЕЗ В ЗАДАЧЕ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
Предложен доработанный метод автоматической генерации и ранжирования гипотез для процесса извлечения информации из текстов на естественном языке. Генерация гипотез строится на результатах морфологического анализа предложений на естественном языке. Оценка ранга гипотезы основана на вероятности допустимости гипотезы и статистике употребления слов, образующих сущности и отношения. Приведены формулы, описывающие предложенный метод.
Доработанный метод автоматической генерации и ранжирования гипотез предлагается использовать в разрабатываемой вопросно-ответной фактографической поисковой системе с целью извлечения информации из текстов на естественном языке. Модель взаимодействия такой поисковой системы с пользователем имеет следующий вид: пользователь задает вопрос, относящийся к некоторой предметной области с использованием устройства ввода, вопрос в виде текста передается подсистеме поиска ответов, затем сформированный ответ (или ответы) сообщается пользователю через устройство вывода. Актуальность такого рода систем обусловлена возможностью более быстрого поиска требуемой информации по сравнению с традиционными поисковыми системами и простотой интерфейса (взаимодействие осуществляется в форме диалога, то есть в наиболее естественной для человека форме). В данной статье предложен доработанный метод порождения и ранжирования гипотез, положенный в основу подсистемы индексации текстовых документов, осуществляющей извлечение фактов, и подсистемы поиска ответов.
Прежде чем описанная модель сможет успешно решать задачу извлечения информации из текстов, необходимо задать предметную область системы, то есть предоставить для индексации набор текстовых документов, содержащих информацию, по которой необходимо осуществлять поиск. Индексация осуществляется с использованием метода генерации и ранжирования гипотез, описанного ниже и основанного на процедуре морфологического анализа слов.
Морфологический анализ представляет собой определение части речи слова и его морфологических признаков (падеж, число, род и т. д.). Результаты анализа слов предложения являются основанием для выявления семантических связей между словами [1]. Например, для предложения «Президент России нанес визит премьер-министру Франции» может быть построено утверждение «нанес(президент России; визит)». Полученное утверждение называется гипотезой. Вне круглых скобок указано действие (отношение). Внутри круглых скобок стоят объект и субъект речи соответственно. Выражение показывает, что данные объект и субъект связаны указанным отношением и представляет собой упрощенную форму дерева синтаксического подчинения, согласно которой корнем является действие.
Для осуществления морфологического разбора необходимо (как минимум) наличие словаря лемм [2] (канонических форм слов) и лексем (всех возможных словоформ). В таком словаре каждой лемме ставятся в соответствие все возможные словоформы, образованные на ее основе (каноническая форма так же является словоформой), каждой из которых, в свою очередь, ставится в соответствие вектор морфологических признаков. Для достижения более высокой точности разбора требуется наличие словарей имен собственных, аббревиатур и сокращений русского языка. Повышение точности достигается за счет повышения вероятности детерминированного морфологического разбора, описанного ниже, для слов, относящихся к данным группам.
Целью морфологического разбора слова ![]() является определение вектора признаков:
является определение вектора признаков:
| (1) |
где ![]() – часть речи,
– часть речи, 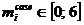 – падеж,
– падеж, 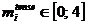 – время глагола,
– время глагола, 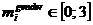 – род,
– род, 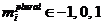 – форма множественного числа (1) или нет (–1),
– форма множественного числа (1) или нет (–1), ![]() – лицо. Если часть речи не обладает тем или иным морфологическим признаком, то его значение принимается равным нулю.
– лицо. Если часть речи не обладает тем или иным морфологическим признаком, то его значение принимается равным нулю.
Для определения вектора признаков в словаре лексем ищется словоформа, совпадающая по написанию с 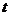 , и полагается, что слово
, и полагается, что слово ![]() может обладать такими же признаками, как и найденная словоформа. В силу омонимии (в том числе в случаях, когда формы двух и более склонений совпадают) для слова
может обладать такими же признаками, как и найденная словоформа. В силу омонимии (в том числе в случаях, когда формы двух и более склонений совпадают) для слова ![]() может быть выбрано несколько вариантов разбора. Введем множество детерминированного морфологического разбора, соответствующее слову :
может быть выбрано несколько вариантов разбора. Введем множество детерминированного морфологического разбора, соответствующее слову :
| (2) |
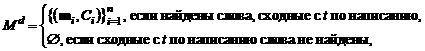
где ![]() – количество слов в словаре лексем, сходных с по написанию и имеющих одинаковые признаки
– количество слов в словаре лексем, сходных с по написанию и имеющих одинаковые признаки ![]() ,
, ![]() – количество различных вариантов разбора. Под детерминированным морфологическим разбором понимается определение признаков слова на основе имеющихся в словаре лексем словоформ.
– количество различных вариантов разбора. Под детерминированным морфологическим разбором понимается определение признаков слова на основе имеющихся в словаре лексем словоформ.
Априорная вероятность того, что слово имеет признаки ![]() , вычисляется по формуле:
, вычисляется по формуле:
| (3) |
В случаях, когда ![]() , применяется процедура эвристического морфологического разбора, основанная на следующей эвристике: чем большую долю среди первых лексем из словаря в порядке возрастания метрики (где
, применяется процедура эвристического морфологического разбора, основанная на следующей эвристике: чем большую долю среди первых лексем из словаря в порядке возрастания метрики (где ![]() – натуральное число, являющееся входным параметром алгоритма,
– натуральное число, являющееся входным параметром алгоритма, ![]() ,
, ![]() – число лексем в словаре, – лексема из словаря,
– число лексем в словаре, – лексема из словаря, ![]() – максимальное количество символов, идущих подряд от конца и одинаковых для слов и , а и – соответствующие длины слов) составляют лексемы, имеющие одинаковые признаки, тем выше вероятность того, что будет ими обладать.
– максимальное количество символов, идущих подряд от конца и одинаковых для слов и , а и – соответствующие длины слов) составляют лексемы, имеющие одинаковые признаки, тем выше вероятность того, что будет ими обладать.
По аналогии с (2) множество эвристического морфологического разбора имеет вид:
| (4) |
где ![]() – количество различных
– количество различных ![]() среди выбранных
среди выбранных ![]() лексем.
лексем.
При этом априорная вероятность того, что слово имеет признаки ![]() , имеет вид:
, имеет вид:
| (5) |
| (6) |
где 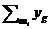 обозначает сумму всех
обозначает сумму всех ![]() , относящихся к словоформам (из выбранных
, относящихся к словоформам (из выбранных ![]() лексем), обладающим признаками
лексем), обладающим признаками ![]() . Формула (5) является общим случаем формулы (3), так как в случае наличия одинаковых по написанию слов, имеющих разные признаки,
. Формула (5) является общим случаем формулы (3), так как в случае наличия одинаковых по написанию слов, имеющих разные признаки, 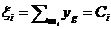 .
.
Для морфологического разбора предложения требуется выполнить описанную процедуру для каждого его слова ![]() , , где
, , где ![]() – число слов в предложении. Таким образом, слову
– число слов в предложении. Таким образом, слову ![]() соответствует множество морфологического разбора:
соответствует множество морфологического разбора:
| (7) |
каждый элемент ![]() которого имеет вероятность:
которого имеет вероятность:
| (8) |
Разобранное морфологическим анализатором предложение и полученные в результате анализа множества ![]() , а так же оценки вероятности корректного разбора
, а так же оценки вероятности корректного разбора ![]() передаются на вход модуля генерации гипотез. На первом шаге работы модуля строится множество отношений. Каждый элемент данного множества будет являться корнем дерева синтаксического подчинения, построенного для всего предложения, с некоторой вероятностью
передаются на вход модуля генерации гипотез. На первом шаге работы модуля строится множество отношений. Каждый элемент данного множества будет являться корнем дерева синтаксического подчинения, построенного для всего предложения, с некоторой вероятностью ![]() .
.
| (9) |
| (10) |
где ![]() соответствует глаголам.
соответствует глаголам.
Далее строятся множества объектов для каждого элемента ![]() соответственно:
соответственно:
| (11) |
| (12) |
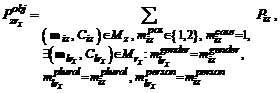
где ![]() соответствует существительному,
соответствует существительному, ![]() – местоимению,
– местоимению, ![]() – множество морфологического разбора слова
– множество морфологического разбора слова ![]() , а
, а ![]() – именительному падежу, а символы с индексом
– именительному падежу, а символы с индексом ![]() относятся к соответствующему глаголу. Другими словами, в
относятся к соответствующему глаголу. Другими словами, в ![]() попадают существительные или местоимения в именительном падеже, согласующиеся с соответствующим глаголом по роду, числу и лицу.
попадают существительные или местоимения в именительном падеже, согласующиеся с соответствующим глаголом по роду, числу и лицу.
После построения множества ![]() строится множество субъектов:
строится множество субъектов:
| (13) |
| (14) |
Важную роль играет вероятность появления слова в документе:
| (15) |
где ![]() – сколько раз слово
– сколько раз слово ![]() , его различные формы и синонимы встречаются в тексте документа,
, его различные формы и синонимы встречаются в тексте документа, ![]() – количество слов в соответствующем документе. Для более точных вычислений по формуле (15) требуется наличие тезауруса.
– количество слов в соответствующем документе. Для более точных вычислений по формуле (15) требуется наличие тезауруса.
На основе (9)–(14) для данного предложения построим множество гипотез:
| (16) |
| (17) |

Ранг каждой гипотезы вычисляется по формулам:
| (18) |
| (19) |
| (20) |
где ![]() – вероятность допустимости гипотезы,
– вероятность допустимости гипотезы, ![]() – вероятность информативности гипотезы. Чем выше ранг, тем выше вероятность того, что гипотеза будет являться ответом на коррелирующий с ней вопрос.
– вероятность информативности гипотезы. Чем выше ранг, тем выше вероятность того, что гипотеза будет являться ответом на коррелирующий с ней вопрос.
При поиске ответа к вопросительному предложению так же применяется описанные выше процедуры морфологического анализа и генерации гипотез, результатом которых является множество ![]() . Для нахождения ответов необходимо на базе множеств
. Для нахождения ответов необходимо на базе множеств ![]() (объединение берется по всем предложениям во всех проиндексированных документах) и
(объединение берется по всем предложениям во всех проиндексированных документах) и ![]() построить множество вида:
построить множество вида:
| (21) |
| (22) |
где ![]() , если
, если ![]() является характерным вопросом для падежа слова
является характерным вопросом для падежа слова ![]() ,
, 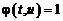 , если
, если ![]() и
и ![]() одинаковы по написанию или являются синонимами в одинаковой форме,
одинаковы по написанию или являются синонимами в одинаковой форме, ![]() в остальных случаях. Таким образом, результирующее множество ответов будет состоять из слов
в остальных случаях. Таким образом, результирующее множество ответов будет состоять из слов ![]() , для которых
, для которых ![]() , причем, чем выше соответствующая вероятность
, причем, чем выше соответствующая вероятность ![]() , тем выше вероятность того, что данный ответ найден правильно:
, тем выше вероятность того, что данный ответ найден правильно:
| (23) |
| (24) |
Стоит отметить, что для полноценного определения значения ![]() так же, как и для вычислений по формуле (15), требуется наличие тезауруса русского языка.
так же, как и для вычислений по формуле (15), требуется наличие тезауруса русского языка.
Предложенный в статье доработанный метод был реализован с некоторыми ограничениями и опробован на специально созданной базе данных новостных статей (свыше 5000 документов). В результате проведенных исследований были получены положительные результаты, что доказывает пригодность предложенных методов для решения поставленной задачи. В доработанном методе, корнем гипотезы является отношение, а не объект, что согласуется с грамматикой зависимостей [5]. В настоящее время разрабатываются алгоритмы логического вывода гипотез, основанные на дедуктивном, индуктивном и абдуктивном рассуждениях [3], которые позволят находить ответы, не содержащиеся в документах явно. Разрабатываются решения для повышения точности морфологического анализа, в частности, основанные на скрытых Марковских моделях [4]. Разрабатываются методы построения полных словарных парадигм на основе результатов морфологического анализа (в случае эвристического морфологического анализа).
Предложенный метод реализует упрощенную процедуру синтаксического анализа. На его основе ведется разработка метода построения и ранжирования деревьев синтаксического подчинения, ориентированного на полноценный разбор предложения и призванного уменьшить негативное влияние множественности вариантов разбора на точность извлечения информации.
СПИСОК ЛИТЕРАТУРЫ
1. Искусственный интеллект: современный подход. 2-е изд. М.: Вильямс, 2007.
2. Грамматический словарь русского языка: словоизменение. М.: АСТ-ПРЕСС КНИГА, 2008.
3. , , и др., Достоверный и правдоподобный вывод в интеллектуальных системах. М.: Физматлит, 2008.
4. Vinayak Borkar, Sunita Sarawahi. Automatic segmentation of text into structured records. ACM, 2001.
5. Формальные грамматики и языки. М.: Наука, 1973.
