

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вопросы распознавания текста, оцифрованного с помощью видеокамер
,
Настоящая работа содержит результаты наших разработок, проводимых в рамках совместных с фирмой МегаПиксел исследований в области видеорегистраторов, ориентированных на ввод и обработку автомобильных и вагонных номеров. Будут указаны различия распознавания символов в процессе работы видеорегистраторов от распознавания в контексте стандартных схем OCR.
Введение
Повсеместно применяемый в настоящее время термин OCR или дословно «оптическое распознавание символов» описывает целый ряд программных средств, с одной стороны, безусловно, использующих распознавание образов символов, а с другой стороны, включающих в себя большое число алгоритмов, не сводящихся к обработке отдельных символов [1]. Расширительно толкуемый термин OCR следует понимать алгоритм распознавания текстовых образов, которые могут представлять собой как отдельно стоящий символ, так и группу символов (строку символов, абзац, весь документ в целом), при этом может использоваться дополнительная информация (алфавит, шрифт, описание структуры документа). В исследованиях, посвященных функционированию OCR в программах видеорегистраторов, мы усматриваем определенную специфику, которая будет изложена в настоящей статье.
Программы видеорегистраторов (видеоввода, ввода в компьютер видеопоследовательностей, ввода автомобильных номеров) также именуют широкий класс популярных средств. Мы кратко опишем три представления программ видеоввода различного типа. Далее мы расскажем о типичных задачах и об особенностях алгоритмов распознавания в программах видеоввода.
Примеры программ видеорегистраторов
Первая из программ [2] описывает диалоговые средства слежения за потоком автомобилей на шоссе. Программные средства выполняют технические функции приема (оцифровки) видеопоследовательностей, приема информации от оператора, сохранения информации в базе данных, извлечение информации. Распознавание состоит в выделении движущихся объектов в видеопотоке с целью измерения характеристик транспортного потока. Задача распознавания номеров именуются в этой газетной статье как «определение номерного знака», подразумевается, что эта функция системы не является основной. Программа позиционируется как автономный комплекс наблюдения за потоком автомобилей, при этом алгоритмы реализуются на базе отечественного DSP-процессора, в отличие от двух следующих программ, ориентированных на платформу WIntel.
В работах [3,4] авторы описывают развитие алгоритмического способа ввода автомобильных номеров. В схеме ввода номера, приведенной на рис.1, различаются следующие этапы:
- детектор автомобиля
- локализация области автомобильного номера
- распознавание автомобильного номера
- синтаксический контроль.
На каждом из этапов применяются свои алгоритмы, обладающие границами применимости и точностью распознавания. Отметим, что слабо описанный в [3,4] детектор автомобиля и локализатор номера, определяемый эвристическим исследованием т. н. «сигнатур», могут быть определены методом морфологических пирамид [5]. Наиболее хорошо описаны этапы распознавания символов в автомобильном номере и синтаксический контроль. Представляется интересным комбинирование двух алгоритмов
 |
Рис.1. Схема ввода автомобильного номера по Barroso [3]
распознавания символов:
- сопоставления с эталонами образов, масштабированных на стандартные размеры
- топологический анализ Щепина и Непомнящего [6]
Эти методы и их комбинирование подобны используемым в программе Cuneiform алгоритмам «3x5» и «событийный» [7], что и обуславливает низкое качество распознавания загрязненных номеров. Автор в [4] оценивает для загрязненных номеров характеристику точности, как не превосходящую 88%, что по нашему мнению объясняется применением упрощенных алгоритмов распознавания символов, ориентированных на отсканированные тексты, а не на образы автомобильных номеров.
Российская фирма МегаПиксел предлагает коммерческие варианты как плат оцифровки видеопоследовательностей, так программных приложений обработки видеопоследовательностей, в частности поиска автомобильных номеров [8]. Такая законченность решения обусловливает смещение оценки качества и проблем ввода номеров в более практическом направлении, нежели чисто алгоритмические проблемы в [3,4]. К проблемам ввода российских автомобильных номеров М. Руцков, в частности, относит
- большое число типов номеров (см. рис. 2)
- загрязненность номеров
- тени от солнца
- несовершенство оборудования (см. рис. 3).
Кроме собственно распознавания автомобильного номера Руцков упоминает следующие задачи, решаемые при оцифровке видеопоследовательностей с автомобилями:
- детектор автомобиля
- определение области автомобильного номера
- определение скорости автомобиля
- определение цвета автомобиля
Для решения первых двух задач применяются нейро-ассоциативные методы [8]. Первоочередными характеристиками качества называются быстродействие системы (связанное с необходимостью обрабатывать одновременно несколько зон автомобильных номеров и определять скорость в реальном масштабе времени) и профессионализм инсталляции системы (связанный с технологически сложными условиями российских автотрасс).
 |
Рис.2. Разнообразие российских автомобильных номеров из [8]
 |
Рис.3. Дефекты автомобильных номеров из [8]
Важнейшим отличием системы МегаПиксел является возможность отслеживания траектории объекта в видеопоследовательности, что позволяет распознать один и тот же объект несколько раз с целью уточнения результата.
Общим свойством рассмотренных программ видеоввода [3,4,8] является использование алгоритмов распознавания символов. Распознавание применяется как для надежно локализованных зон, так и для ненадежных, в последнем случае результат распознавания может быть использован для уточнения гипотезы о локализации зоны.
Распознавание автомобильных номеров
Распознавание одного кадра в программном комплексе CarFlow систем МегаПиксел производится по следующей схеме:
- локализация автомобилей
- локализация зон номеров на найденных автомобилях
- бинаризация полутонового изображения
- нормализация номера по размеру
- распознавание всех номеров с учетом синтаксического контроля
- ведение траекторий номеров
Под ведением траекторий номеров понимается следующее. Объект, интерпретируемый как автомобиль, успевает за несколько кадров переместиться в пределах области, снимаемой видеокамерой. Учитывая скоростные возможности систем МегаПиксел, состоящие в мощности видеопотока 25 кадров в секунду, становится возможным отслеживать траектории автомобилей, едущих со скоростями до 100 км/час.
Мы занимались задачей распознавания отдельного бинаризованного номера с учетом дополнительной информации, получаемой при обработке траекторий, то есть с учетом многократного распознавания одного и того же кадра.
Основным объектом исследования был выбран российский номер типа
cDDDcc|dd
где c – буквенный код из числа символов (ETYOPAHKXCBM)
D, d – цифровые коды.
Доля таких номеров в потоке автомобилей в Москве находится в диапазоне 90-95%. Из структуры номера следует ряд упрощений при распознавании. А именно, алфавит символов сильно ограничен и содержит символы принадлежащие кириллице и латинице одновременно, кроме этого последняя пара цифр регионального российского кода принадлежит диапазону 01-89. В то же самое время распознавание одного номера какой-либо библиотекой обработки текстовой строки сомнительно как из-за малости числа символов в строке номера, так и из-за сдвига цифр регионального кода вверх по отношению к образам начала номера. Простая обработка массива вариантов одного номера, суммируемых в траектории, также невозможна, ибо используемые алгоритмы ведения номера автомобиля предполагают распознавание символов с оценкой.
Реальные снимки номеров обладают рядом дефектов, связанных как с реальным загрязнением номера, так и с его оцифровкой. Основные дефекты таковы:
- случайный шум (см. рис. 4а)
- потеря части образов (см. рис. 4б)
- проблема «колонны» (см. рис. 4в).
Последний дефект связан с проявлением части рамки номера в виде вертикальной черты, к сожалению, неразличимой геометрически от цифры «1». Естественно, для образов номеров характерна вариация размера символов (до 20%) и наклона угла до 15°.
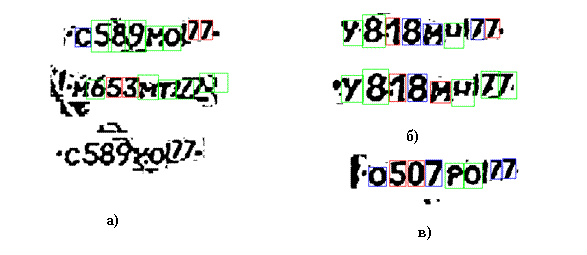
Рис.4. Дефекты бинарных образов автомобильных номеров
Описанные искажения обусловили алгоритмы сегментации и распознавания символов номера, состоящие из следующих процессов:
- обработка бинарного образа с целью разделения склеенных символов
- первичное распознавание компонент связности быстрым шрифтонезависимым алгоритмом нейронной сети [9]
- наложение описания структуры номера с опорой на надежно распознанные образы
- расширение прямоугольников для поиска ненайденных символов (см. рис.5)
- распознавание в зонах расширенных прямоугольников, для чего применялся алгоритм эталонов [10], использующий шрифт, построенный на представительной выборке символов из бинарных образов номеров.

Рис.5. Расширенные границы символов
Отметим особенности указанных алгоритмов. Обработка бинарного образа номера осуществлялась с помощью тривиальных матричных обработок типа 3х3, но в условиях сильных ограничений по размерам и топологической структуре компонент связности.
В условиях получения гипотез о наличии конкретного символа на данном знакоместе, использовались нейронные сети из некоторого массива сетей. В простейшем случае брались две сети, одна из которых была обучена на полном алфавите, а другая - на цифровом. Внешний алфавит устанавливался и для алгоритма эталонов.
Наложение описания опиралось на число надежно распознанных символов, не меньшее трех. Распространение описания структуры на оставшиеся символы является эвристическим, причем ряд отказов принимался в ущерб точности и в пользу быстродействия.
Применение алгоритма эталонов существенно замедляет распознавание, но обеспечивает порождение монотонных оценок, лучших, нежели оценки нейронной сети. Зависимость алгоритма [10] от шрифта и от размера символов делает возможным поиск загрязненных образов в расширенных границах (рис. 5), однако штрафная функция наложения эталонов, модифицированная для поиска искаженных образов, приводит к появлению ошибок распознавания. В связи с этим применялась комбинация двух штрафных функций. Штрафная функция наложения эталонов и пределы расширения границ были сбалансированы с целью оптимизации быстродействия распознавания эталонами, объединяемого с перебором вариантов в расширенных границах.
Как уже отмечалось, распознавание серий образов одного и того номера позволяет повышать качество распознавания. На рис. 6 приведен простейший пример, в котором полностью номер присутствует только в одном кадре из трех.
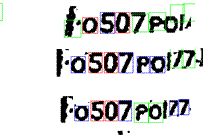 |
Рис.6. Серия снимков одного и того же автомобильного номера
Нами были получены результаты, свидетельствующие о высокой монотонности оценок распознанных номеров. Однако быстродействия алгоритма, достаточного для требований программы CarFlow систем МегаПиксел, достичь не удалось. А именно, требования распознавать 16 номеров 25 раз в секунду, что соответствует 16 автомобилям на четырехполосном шоссе, на компьютерах типа Pentium III 600 и памятью SDRAM оказалось недостижимо. Необходима дальнейшая оптимизация как общей схемы работы, так и алгоритмов распознавания, в том числе с учетом возможностей следующего поколения процессоров Pentium IV. В то же время полученные нами результаты с успехом могут быть применены в системах с меньшими требованиями к быстродействию, например, в режиме чтения номера при въезде на стоянку.
Распознавание номеров вагонов
Области применения задачи считывания номеров на вагонах достаточно широки: это и регистрация проезжающих, и учет стоящих вагонов. В отличие от задачи ввода автомобильных номеров, требования по быстродействию здесь уменьшены в несколько раз из-за того, что в зоне считывания может находиться только один вагон. Этапы ввода вагонного номера аналогичны описанным выше этапам:
- детектор движения вагона
- локализация области номера
- бинаризация номера
- нормализация номера по размеру
- распознавание номеров с учетом синтаксического контроля
- ведение траекторий номера
Подавляющее большинство российских вагонных номеров состоит из 8 однородных цифр, причем известно контекстное правило, позволяющее определить любую из восьми цифр, по оставшимся семи. Особенности структуры номера состоят в том, что расстояние между цифрами может быть различным из-за неоднородности поверхности вагона (ребра жесткости). Естественными дефектами являются случайный шум, обусловленный загрязнением вагона и неоднородностью поверхности вагона или цистерны (см. рис. 7).
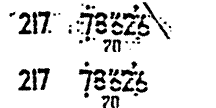 |
Рис.7. Дефекты бинарных образов вагонных номеров и устранение шума
В условиях ввода номера на станциях справедлива гипотеза о снижении скорости состава, что приводит к удлинению траектории, вычисляемой количеством снятых кадров одного номера. Это позволяет ослабить требования к распознаванию сложных случаев и в совокупности с контекстными правилами добиться качественного распознавания номеров в серии длиной 7-10 кадров с помощью упрощенной сегментации.
В процессе распознавания использовались только шрифтонезависимые нейронные сети [8], чему предшествовала жесткая фильтрация образа номера с целью уменьшения шума. Упрощенная сегментация состояла из следующих алгоритмов:
- нормализация образа по углу наклона
- наведения двух базовых линий, ограничивающих верх и низ цифр
- надежного распознавания некоторых образов символов
- локализации групп символов, расположенных поблизости
- комбинированное извлечение образов цифр, базирующееся на ориентировочных размерах цифры.
Итоговая надежность оценки серии кадров также обеспечивается длиной серии.
Организованное таким образом распознавание обеспечивает обработку серий строк цифровых символов с качеством не менее 99,5%, что делает алгоритм пригодным для реального использования.
Выводы
Рассмотренные схемы распознавания автомобильных и вагонных номеров показывают как их различие, так сходство с известными программами оптического распознавания документов как с известной и неизвестной структурой. Сходство проявляется в родстве алгоритмов бинаризации, необходимости производить комбинаторную сегментацию границ символов, необходимости комбинирования алгоритмов распознавания символов и применении контекстных корректоров. Различия состоят в общей нацеленности на достижения высокого быстродействия (при увеличении доли отказов), а также на повышения качества распознавания за счет использования нескольких снимков одного и того же объекта, что является органичным для видеорегистраторов.
Представляется перспективным доработка исследований и их внедрение в работающие системы.
Авторы выражают глубокую благодарность и А. Горелову за ценные обсуждения и практическую помощь.
Литература
, Алгоритмы распознавания и технологии ввода текстов в ЭВМ. - Информационные технологии и вычислительные системы № 1, 1996, 6, стр. 48-54 Новация «Модуля» «Красная звезда» от 01.01.01 Barroso J., Bulas-Cruz J., Rafael J., Dagless E. L. Identificação Automática de Placas de Matrícula Automóveis, 4.as Jornadas Luso-Espanholas de Engenharia Electrotécnica, Porto, Portugal, Julho (1995), ISBN -9. Barroso J., Rafael A., Dagless E. L., Bulas-Cruz J. Number plate reading using computer vision. http://www. utad. pt/~jbarroso/html/isie97.html Arndt T., Costagliola G., Chang S. K., Comments on "Mesh and pyramid algorithms for iconic indexing", pp. 819-820. Shchepin E. V., Nepomnyashchii G. M. "Character Recognition via Critical Points'', International Journal of Imaging Systems and Technology, vol.3 (1991), pp. 213-221. Славин О.А., Корольков Г.В., Болотин П.В. Методы распознавания грубых объектов. В сб. "Развитие безбумажных технологий в организациях", 1999, с. 290-311 Руцков Считывания Автомобильных Номеров http://www. /~ksi/rout/st_rouz. htm В. Использование искусственных нейронных сетейдля распознавания рукопечатных символов. В сб. "Интеллектуальные технологии ввода и обработки информации", 1998, с.122-127 , , Адаптивное распознавание символов. В сб. "Интеллектуальные технологии ввода и обработки информации", 1998, с. 39-56
