
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство Образования РФ
Новосибирский государственный технический университет
Кафедра вычислительной техники
Лабораторная работа №6
«Анализ межпроцессных взаимодействий»
Студенты: Преподаватель:
Мирошниченко Л. А.
Группа:
АП-518
Новосибирск, 2008
Цель работы
Изучение и исследование некоторых алгоритмов и способов управления процессами с учетом их требований к вычислительным ресурсам.
Введение
В данной лабораторной работе моделируются некоторые аспекты функционирования операционной системы UNIX.
Модель обладает следующими характеристиками.
1. Три фиксированных приоритета процессов – пользовательские, серверные и системные задачи (задачи ядра).
2. Максимальное количество пользовательских процессов – 8.
3. Количество серверных процессов операционной системы – 2. В их числе:
- менеджер памяти, осуществляющий динамическое преобразование адресов;
- менеджер файловой системы, обслуживающий соответствующие системные вызовы.
4. Количество системных задач – 8. В их числе:
- задача, обслуживающая принтер;
- задача, обслуживающая терминал;
- задача, обслуживающая жесткий диск;
- задача, обслуживающая гибкий диск;
- системные часы;
- задача, обслуживающая системные вызовы (SYSTASK) (для простоты взаимодействия пользовательских процессов с ядром осуществляется без ее участия);
- процесс «аппаратуры», «пустой процесс» – протекающий во время простоя процессора.
Взаимодействие процессов в системе происходит при помощи механизма сообщений. Процесс, пославший сообщение, становится блокированным, процесс, получивший сообщение, – готовым к выполнению. Системные задачи имеют наибольший приоритет, затем идут соответственно серверные и пользовательские процессы.
Планировщик использует дисциплину планирования RR, при этом процессы разных приоритетов образуют разные циклические очереди, и диспетчер каждый раз выбирает наиболее приоритетный процесс.
Все процессы имеют виртуальное адресное пространство от 0 до некоторого N (старший виртуальный адрес), произвольным образом разбитое на сегменты кода, данных и стека.
Распределение ресурсов в системе происходит при помощи семафоров, причем терминал и принтер процесс использует безраздельно, но все процессы могут совместно использовать гибкий и жесткий диски.
При разработке данной программы использовались исходные тексты и идеи операционной системы MINIX.
Общие положения
Управление процессами
Центральной частью ОС является ядро. BOC UNIX написано в основном на языке СИ и занимает примерно 10 % программного кода всей системы.
Текущее состояние псевдокомпьютера, предоставляемого пользователю, называется образом. Процесс – это выполнение образа. Образ состоит из: образа памяти, значений общих регистров, состояния открытых файлов, текущей директории и другой информации.
Образ процесса во время выполнения размещается в основной памяти. Образ может быть откачен на диск, если какому-либо более приоритетному процессу потребуется место в основной памяти. Образ памяти состоит из трех сегментов (рис. 4.1).
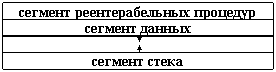 |
Рис. 4.1. Образ памяти
Сегмент реентерабельных процедур может совместно использоваться несколькими процедурами – в первичной памяти такие разделяемые сегменты представляются единственной копией. Сегментами процедур система управляет централизованно при помощи таблицы процедур (рис. 4.2).
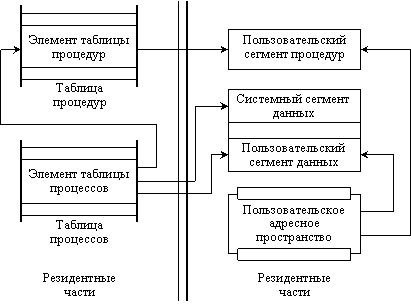
Рис. 4.2. Таблицы управления процессом
Каждый элемент таблицы содержит адреса сегмента как в первичной, так и во вторичной памяти. Когда процесс первый раз обращается к разделяемому сегменту, этот сегмент помещается во вторичную память и заводится элемент в таблице процедур с соответствующими адресами и счетчиком, указывающим число процессов, совместно использующих этот сегмент. Когда в счетчике окажется нуль, освобождается элемент таблицы и области первичной и вторичной памяти.
Сегмент данных располагается следом за сегментом процедур и может расти вниз. Он содержит данные, записываемые и считываемые только одним процессом. Системные данные, относящиеся к процессу, хранятся в отдельном сегменте фиксированного размера. Этот системный сегмент откачивается вместе с процессом. Он содержит:
- состояние регистров;
- дискрипторы (описатели) открытых файлов;
- данные для расчетов за использование машины;
- область рабочих данных;
- стек для системной фазы выполнения процесса.
Сам процесс к этому сегменту адресоваться не может. Когда процесс не активен, система хранит информацию о процессе в таблице процессов. В ней содержится имя процесса, расположение его сегментов и информация для планировщика.
Сегмент стека (рис. 4.1) начинается со старшего адреса в виртуальном адресном пространстве и растет вверх по мере занесения в него информации при вызовах подпрограмм и прерываниях.
Синхронизация процессов
Синхронизация процессов осуществляется механизмом событий. Процессы ожидают событий. События представляются адресами соответствующих таблиц. Родительский процесс, ожидающий завершения одного из дочерних процессов, ожидает события, представленного адресом его собственного элемента таблицы своего родительского процесса.
Планирование процессов
Процессы выполняются в двух состояниях: либо в системном, либо в пользовательском. В пользовательском состоянии процесс имеет доступ к пользовательскому сегменту данных, а в системном – к системному сегменту.
Главной целью планирования процессов в системе является обеспечение высокой реактивности для интерактивных пользователей. Планирование процессов происходит в соответствии с их приоритетами. Высший приоритет отдан процессу, который обрабатывает события и ожидания. События, связанные с работой дисков, получают следующий по старшинству приоритет. События, связанные с терминалами, временем суток и пользовательскими процессами, получают соответственно более низкие приоритеты. Все системные процессы имеют более высокий приоритет. Пользовательские приоритеты зависят от времени загрузки процессора. Чем больше процесс получает пользовательского времени, тем ниже его приоритет. Такой метод планирования обеспечивает хорошее время реакции во время диалога.
Вталкивание – выталкивание
Процесс может выталкиваться во вторичную память и вталкиваться обратно, при этом применяется стратегия «первый подходящий». Если процесс запрашивает дополнительную память, то ему выделятся новая секция памяти достаточного размера и туда копируется содержимое старой памяти. Старая память освобождается. Если в момент расширения процесса в первичной памяти не оказывается в наличии свободного куска, процессу отводится нужное место во вторичной памяти, он выталкивается и будет втолкнут снова в первичную память (уже учитывая его новый размер), когда в ней появится достаточный по размерам свободный кусок. Вталкиванием и выталкиванием руководит специальный процесс подкачек.
Модель операционной системы
Конфигурация вычислительной системы
Любую вычислительную систему можно охарактеризовать, описав ее составляющие, а именно CPU, ОП и устройства ввода/вывода.
Центральный процессор CPU – любой, способный обеспечить одновременное выполнение нескольких процессов в реальном времени.
Оперативная память имеет двухпортовую организацию для обеспечения параллельной работы CPU и каналов ввода/вывода.
Устройства ввода/вывода составляют минимальный необходимый набор:
- терминал (TTY);
- жесткий диск (Winchester);
- гибкий диск (Floppy);
- принтер (Printer).
Модель в своем функционировании имеет именно такую конфигурацию.
Состояние процесса
Пользовательский процесс в данной модели может находиться в одном из трех состояний:
- активный – ему в данный момент предоставлен CPU;
- готовый (ready) – не обладает CPU, но в любой момент времени может стать активным;
- блокированный (unready) – не обладает CPU, и не может стать активным, поскольку ожидает какого либо события (например, завершения операции ввода/вывода). При наступлении этого события процесс переходит в одно из первых двух состояний. На рис. 4.3 представлен переход из одного состояния в другое.
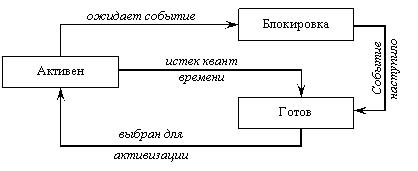
Рис. 4.3. Состояния процесса
Взаимодействие процессов в системе
В данной модели пользовательские процессы взаимодействуют с системными задачами не непосредственно, а через обращения к серверным процессам (Memory Manager & File System). Эти два процесса являются суть независимыми от ядра операционной системы (настолько, что возможны несколько вариантов реализации этих процессов). Их отличия от пользовательских процессов в следующем:
а) серверные процессы обладают более высоким приоритетом;
б) серверные процессы могут непосредственно взаимодействовать с системными;
в) работают с реальным адресным пространством.
Такая иерархическая структура позволяет реализовать различные способы защиты как пользовательских программ друг от друга, так и операционной системы от несанкционированного доступа (подобные идеи используются в UNIX'е).
Поскольку Memory Manager и File System выполняют в данной модели (как, впрочем, в UNIX) исключительно важную и сложную роль, целесообразно рассмотреть их подробнее.
Управление памятью (MEMORY MANAGER)
В данной модели Memory Manager выполняет функцию динамического преобразования адресов при адресации виртуальной памяти (в UNIX трансляция адресов осуществляется непосредственно ядром, а Memory Manager контролирует динамическое использование памяти). Во время исполнения Memory Manager на экране появляется окно с картой ОП. При возникновении страничного сбоя Memory Manager производит загрузку требуемой страницы, используя текущую стратегию замещения (выбирается пользователем).
Возможно также динамическое изменение размера ОП в процессе моделирования.
Управление файлами (File System).
Семафорные операции
File System содержит двоичные семафоры для обеспечения взаимоисключения процессов при использовании устройств ввода/вывода.
Когда процесс обращается к какому-либо устройству ввода/вывода, он выполняет операцию P над соответствующим семафором P(S) (операция P уменьшает S на 1). Если при этом состояние семафора равно 1, то он сбрасывается, а процесс получает доступ к УВВ, в противном случае процесс переводится в состояние ожидания (блокируется).
Когда процесс освобождает ресурс (например, при завершении операции ввода/вывода), то, если есть ожидающие ресурса процессы, один из них получает доступ к ресурсу, иначе (если их нет), семафор устанавливается (операция V(S). Операция V увеличивает S на 1).
Временная диаграмма выполнения P, V операций над семафорами (S) приведена на рис. 4.4, где A, B, C обозначен критический участок (CS).
Под CS подразумевается часть процесса, в течение которого некоторый общий ресурс должен монополизироваться.
Выполнение операций P и V в данной модели сопровождается появлением на экране соответствующих окон. Кроме того, когда исполняется процесс файловой системы, на экране появляется окно, изображающее список УВВ вычислительной системы и список процессов, ожидающих к ним доступа.
Поскольку некоторые ресурсы используются процессами безраздельно, то в модели возможно возникновение тупиков (дедлоков), отражающих реальную проблему, которую необходимо решать при проектировании операционных систем.
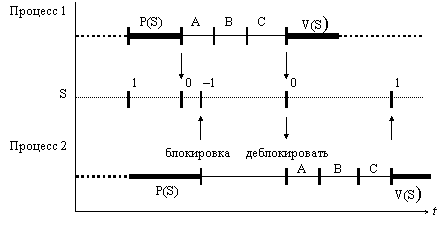
Рис. 4.4. Временная диаграмма двоичного семафора
При появлении окна, описывающего состояние семафора, работа системы останавливается. Для продолжения работы нужно нажать любую клавишу.
Пользовательские процессы
Типы системных вызовов, генерируемых пользовательскими процессами, выбираются случайным образом при помощи ГСЧ. Перечень всех видов вызовов можно посмотреть в заголовочном файле <message. h>.
В модели предусмотрены следующие стратегии вталкивания – выталкивания (стратегии вытеснения):
FIFO – замещается та страница ОП, которая дольше всех находилась в ОП, при этом планировщику памяти нужно следить за очередью всех физических страниц, упорядоченных по времени вталкивания (подкачки);
LFU – least frequently used – стратегия вытеснения наиболее редко используемых страниц – выталкивается та страница, к которой за данный интервал времени было меньше всего обращений;
NUR – оптимальная стратегия вытеснения.
Ход работы
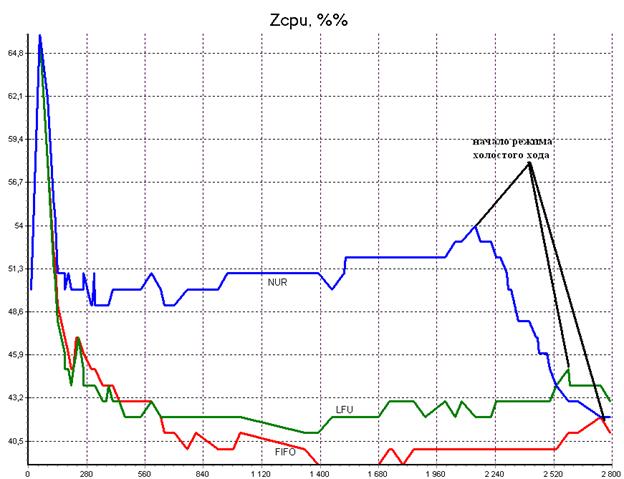
Рис.1. Временная диаграмма загрузки процессора
№ | Время | Zcpu, %% | Семафорные операции | Событие |
1 | 14 | 50 | P(FDD) | 11 занял ресурс |
2 | 56 | 66 | V(FDD) | 11 освободил ресурс |
3 | 93 | 58 | P(HDD) | 10 занял ресурс |
4 | 123 | 52 | P(HDD) | 11 блокирован по HDD |
5 | 128 | 52 | P(FDD) | 15 занял ресурс |
6 | 140 | 49 | V(HDD) | 10 освободил, 11 занял ресурс |
7 | 175 | 47 | P(HDD) | 14 блокирован по HDD |
8 | 176 | 47 | V(FDD) | 15 освободил ресурс |
9 | 193 | 46 | V(FDD) | 10 занял ресурс |
10 | 206 | 45 | V(HDD) | 11 освободил ресурс, 14 занял ресурс |
11 | 215 | 45 | P(FDD) | 12 блокирован по FDD |
12 | 230 | 47 | V(FDD) | 10 освободил ресурс, 12 занял ресурс |
13 | 231 | 47 | P(HDD) | 15 блокирован по HDD |
14 | 240 | 47 | P(FDD) | 16 блокирован по FDD |
15 | 265 | 46 | V(HDD) | 14 освободил ресурс, 15 занял ресурс |
16 | 266 | 46 | V(FDD) | 12 освободил ресурс, 16 занял ресурс |
17 | 304 | 45 | V(HDD) | 15 освободил ресурс |
18 | 305 | 45 | P(FDD) | 11 блокирован по FDD |
19 | 311 | 45 | P(FDD) | 14 блокирован по FDD |
20 | 317 | 45 | V(FDD) | 16 освободил ресурс, 11 занял ресурс |
21 | 318 | 45 | P(HDD) | 12 занял ресурс |
22 | 359 | 44 | V(FDD) | 11 освободил ресурс, 14 занял ресурс |
23 | 363 | 44 | V(HDD) | 12 освободил ресурс |
24 | 376 | 44 | P(HDD) | 16 занял ресурс |
25 | 386 | 44 | P(FDD) | 13 блокирован по FDD |
26 | 405 | 44 | V(FDD) | 14 освободил ресурс, 13 занял ресурс |
27 | 437 | 43 | V(HDD) | 16 освободил ресурс |
28 | 463 | 43 | V(FDD) | 13 освободил ресурс |
29 | 534 | 43 | P(HDD) | 13 занял ресурс |
30 | 541 | 43 | P(HDD) | 11 блокирован по HDD |
31 | 591 | 43 | V(HDD) | 13 освободил ресурс, 11 занял ресурс |
32 | 635 | 42 | P(HDD) | 17 блокирован по HDD |
33 | 654 | 41 | V(HDD) | 11 освободил ресурс, 17 занял ресурс |
34 | 701 | 41 | V(HDD) | 17 освободил ресурс |
35 | 762 | 40 | P(FDD) | 17 занял ресурс |
36 | 803 | 41 | V(FDD) | 17 освободил ресурс |
37 | 912 | 40 | P(FDD) | 13 занял ресурс |
38 | 956 | 40 | V(FDD) | 13 освободил ресурс |
39 | 983 | 40 | P(HDD) | 10 занял ресурс |
40 | 1017 | 41 | V(HDD) | 10 освободил ресурс |
Рис.2. Временная диаграмма межпроцессных взаимодействий (часть 1)
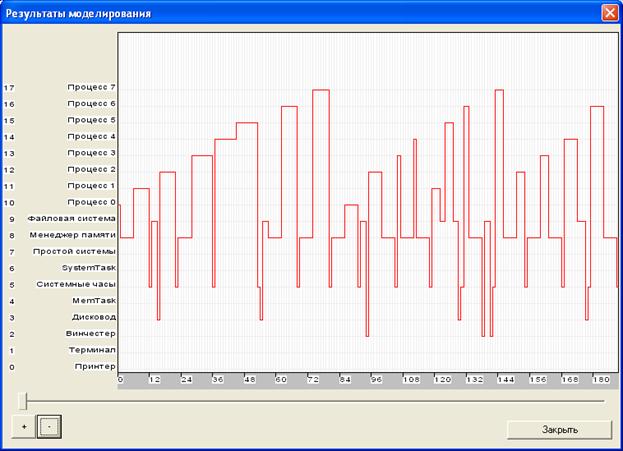
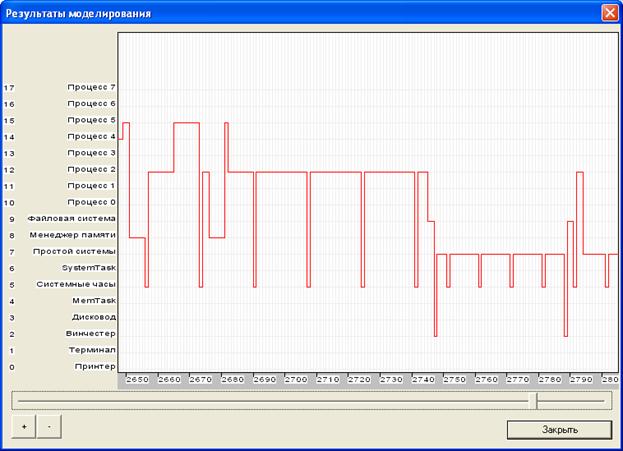
Вывод
Изучили и исследовали некоторые алгоритмы и способы управления процессами с учетом их требований к вычислительным ресурсам. Научились строить диаграмму синхронизации процессов.
Выводы по рис.1:
- Среди дисциплин замены страниц памяти наибольшую загрузку процессора обеспечила NUR, в среднем наименьшую – LIFO. Загрузка ЦП при NUR значительно выше загрузки при двух других дисциплинах. Загрузка ЦП на дисциплинах LIFO и LFU отличается незначительно. Время перехода к режиму холостого хода тем меньше, чем больше был загружен процессор на этапе исполнения.
