
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ЛЕКЦИЯ 6
РЕГРЕССИОННЫЙ И КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Регрессионный и корреляционный анализ - это методы исследования взаимосвязи между двумя и более НЕПРЕРЫВНЫМИ переменными, эти методы имеют много общего и часто рассматриваются вместе.
В регрессионном анализе рассматривается связь между одной переменной (называемой ЗАВИСИМОЙ переменной) и несколькими другими независимыми переменными. Зависимая переменная связана с независимыми переменными посредством ФУНКЦИИ РЕГРЕССИИ. Функция регрессии содержит независимые переменные с набором неизвестных параметров. Если функция линейна относительно параметров (но не обязательно относительно независимых переменных), то говорят о линейной модели регрессии.
В корреляционном анализе взаимосвязь между переменными анализируется посредством простого, множественного и частного коэффициентов корреляции, причем все переменные рассматриваются как равноправные.
1. Простая линейная регрессия.
Регрессия называется простой, когда зависимая переменная Y связана только с одной независимой переменной X. Это конечно, идеальный (идеализированный) случай, который позволяет, однако, проанализировать многие характерные особенности регрессионного анализа. При линейной регрессии функция регрессии
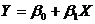 (1)
(1)
линейна по ![]() и
и ![]() .
.
Также линейной регрессии будет соответствовать функция
![]() , (2)
, (2)
но функция
![]() (3)
(3)
уже будет нелинейной.
Вообще, когда говорят о простой линейной регрессии, то обычно имеют в виду формулу типа (1), когда имеется линейная связь между Y и X. Если же получается формула типа (2), тогда делают замену
![]()
и рассматривается модель типа (1): ![]()
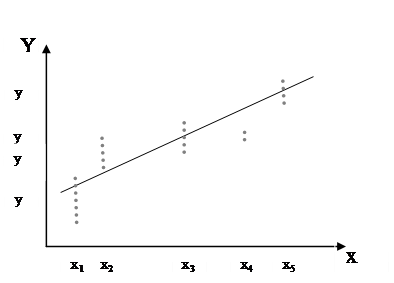
1) Первый шаг, который обычно делают при изучении взаимосвязи между X и Y‑ это построение диаграмм рассеяния. Визуальный анализ диаграммы рассеяния может подсказать, что:
а) между X и Y существует сильная линейная связь;
б) между X и Y нет никакой связи;
в) между X и Y существует нелинейная связь.

В случае в) для преобразования к виду (1) можно попробовать преобразования
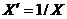 или
или ![]()
Можно сделать преобразование и по Y:
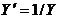 или
или ![]()
2) Второй шаг - расчет выборочного коэффициента корреляции между X и Y:
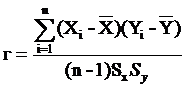
где ![]() и
и ![]() - выборочные стандартные отклонения.
- выборочные стандартные отклонения.
При г![]() ±1 имеется сильная линейная связь между X и Y. Однако коэффициент корреляции ничего не говорит о величине наклона прямой Y=Y(X).
±1 имеется сильная линейная связь между X и Y. Однако коэффициент корреляции ничего не говорит о величине наклона прямой Y=Y(X).
Раньше я говорил об использовании диаграмм рассеяния для устранения выбросов. Сейчас приведу пример влияния выбросов на количественные характеристики, диаграмма рассеяния для пар концентраций Cu-Ag и Ti-Ag при исследовании загрязнения почвы в промышленной зоне Первоуральск-Ревда имеют вид (примерно):
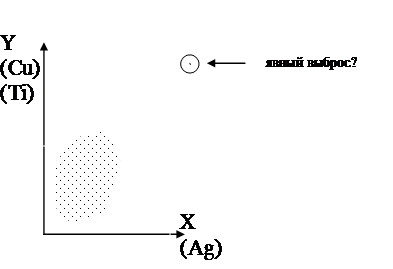
В таблице приведены значения коэффициентов корреляции между концентрациями медь-серебро и титан-серебро. Видно, что устранение выброса существенно уменьшает значение коэффициентов корреляции. Интересно отметить также, что переход к логарифмам концентраций (когда распределения приближаются к нормальному распределению) снижает влияние выброса.
Таблица
Коэффициенты корреляции между парами концентраций
Выборка | Cu-Ag | Ti-Ag | lg(Cu)- lg(Ag) | lg(Ti)- lg(Ag) |
с выбросом | 0.87 | 0.30 | 0.76 | 0.66 |
без выброса | 0.51 | 0.06 | 0.75 | 0.65 |
Теория
Теперь перейдем к рассмотрению собственно теории простой линейной регрессии. Пусть имеется выборка парных наблюдений (![]()
![]() ) из генеральной совокупности. Выражение вида
) из генеральной совокупности. Выражение вида
![]() , i = 1, 2, … n (4)
, i = 1, 2, … n (4)
называется моделью простой линейной регрессии Y по X. Величины ![]() и
и ![]() называются параметрами регрессии,
называются параметрами регрессии, ![]() - ошибки случайной переменной Y.
- ошибки случайной переменной Y.
Конкретизируем способ получения пар наблюдений (![]()
![]() ). В данном случае мы рассматриваем
). В данном случае мы рассматриваем ![]() как набор фиксированных значений, а
как набор фиксированных значений, а ![]() - как случайные величины.
- как случайные величины.
фиксированные ![]()
Другие возможные варианты получения пар (![]()
![]() ):
):
- пары (![]()
![]() ) - независимы обе переменные (только в этом случае можем оценить значимость коэф. корреляции);
) - независимы обе переменные (только в этом случае можем оценить значимость коэф. корреляции);
-![]() -фиксированы,
-фиксированы, ![]() -случайные и принимают несколько значений для одного
-случайные и принимают несколько значений для одного ![]() (набор измерений
(набор измерений ![]() для заданных
для заданных ![]() ).
).
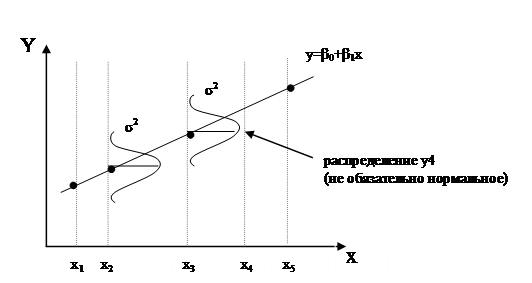
фиксированные ![]()
В нашем случае (фиксированные ![]() , случайные
, случайные ![]() , одно значение у для заданного х) ошибки
, одно значение у для заданного х) ошибки ![]() должны обладать свойствами:
должны обладать свойствами:
- математическое ожидание (![]() )=0 для любого i;
)=0 для любого i;
- дисперсия (![]() )=
)=![]() - одна и та же для любого i;
- одна и та же для любого i;
- ковариация (![]()
![]() ) = 0 при i≠j.
) = 0 при i≠j.
Когда речь идет об этих условиях для ошибок ![]() , имеется в виду совокупность выборок, сделанных по указанной методике. Для этой совокупности естественно получается для каждого i набор
, имеется в виду совокупность выборок, сделанных по указанной методике. Для этой совокупности естественно получается для каждого i набор ![]() с некоторым распределением (не обязательно нормальным).
с некоторым распределением (не обязательно нормальным).
Оценка ![]() и
и ![]() параметров регрессии
параметров регрессии ![]() и
и ![]() находится путем минимизации суммы квадратов отклонений
находится путем минимизации суммы квадратов отклонений
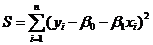 = min по
= min по ![]() и
и ![]() (5)
(5)
Для модели, линейной по ![]() и
и ![]() , оценки получаются аналитически и даются формулами:
, оценки получаются аналитически и даются формулами:
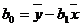 (6)
(6)
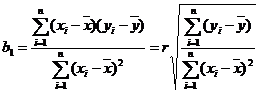 (7)
(7)
r – коэффициент корреляции.
Оценкой уравнения регрессии будет
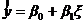 (8)
(8)
Разница между наблюдаемым значением ![]() и его оценкой
и его оценкой ![]() называется остатком (аналог ошибки в уравнения (4)):
называется остатком (аналог ошибки в уравнения (4)): ![]() . Оценкой величины S (5) будет
. Оценкой величины S (5) будет
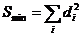 .
.
2. Доверительные интервалы. Проверка гипотез.
При условии НОРМАЛЬНОСТИ распределения ошибок (остатков):
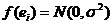 для любого i.
для любого i.
Запишем
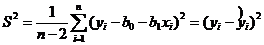
Величина
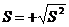 (9)
(9)
называется стандартной ошибкой оценки. Для проверки нулевой гипотезы ![]() :
: ![]() против альтернативной гипотезы
против альтернативной гипотезы
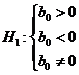
используется t – статистика
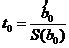 , обозначение
, обозначение ![]()
где ![]() – стандартная ошибка коэффициента
– стандартная ошибка коэффициента ![]()
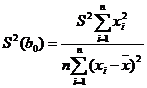
Если ![]() – верна,
– верна, ![]() имеет распределение Стьюдента с
имеет распределение Стьюдента с 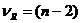 степенями свободы. Р – значение зависит от альтернативной гипотезы и определяется стандартным способом.
степенями свободы. Р – значение зависит от альтернативной гипотезы и определяется стандартным способом.
Доверительный интервал для ![]() :
:
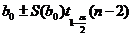 .
.
Нулевая гипотеза для ![]() :
:
![]() :
: ![]() против альтернативной гипотезы
против альтернативной гипотезы
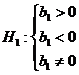
Используется t – статистика
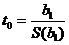 , обозначение
, обозначение ![]()
где ![]() – стандартная ошибка коэффициента
– стандартная ошибка коэффициента ![]()
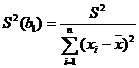
Если ![]() – верна,
– верна, ![]() имеет распределение Стьюдента с степенями свободы. Р-значение зависит от альтернативной гипотезы и определяется стандартным способом.
имеет распределение Стьюдента с степенями свободы. Р-значение зависит от альтернативной гипотезы и определяется стандартным способом.
Доверительный интервал для ![]() :
:
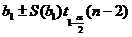
Наконец, доверительный интервал для ![]()
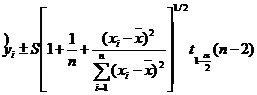 (10)
(10)
NB: доверительный интервал для ![]() зависит от х; он минимален для
зависит от х; он минимален для ![]() и увеличивается на концах интервала.
и увеличивается на концах интервала.
3. Простая линейная регрессия в статистическом пакете STATGRAPHICS
Статистический пакет STATGRAPHICS выдает следующие результаты.
Simple Regression (входные данные)
Dependent variable: имя переменной (с заглавной буквы)
Independent variable: имя переменной
Model: Linear
Confidence limits: 95.00 (для коэффициентов регрессии)
Prediction limits: 95.00 (для ![]() )
)
Table 1 (оценка коэффициентов регрессии) | ||||
Regression Analysis - Linear Model: | ||||
Dependent variable (имя) | Independent variable (имя) | |||
Parameter | Estimation | Standard Error | T-value | Prob. Level (уровень вероятности) |
Intercept |
|
|
|
|
Slope |
|
|
|
|
Здесь даются: - оценки параметров - формулы (6)-(7)
- стандартные ошибки параметров
- t - значения
- Р - значения
В пакете STATGRAPHICS величины ![]() и
и ![]() , которые не зависят от уровня значимости α, выводятся на печать. Пределы изменения линии регрессии
, которые не зависят от уровня значимости α, выводятся на печать. Пределы изменения линии регрессии 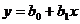 при изменении параметров
при изменении параметров ![]() и
и ![]() в пределах доверительных интервалов показываются в пакете STATGRAPHICS на графике пунктирными линиями. Доверительный интервал для самой величины у (10) показывается второй парой пунктирных линий.
в пределах доверительных интервалов показываются в пакете STATGRAPHICS на графике пунктирными линиями. Доверительный интервал для самой величины у (10) показывается второй парой пунктирных линий.
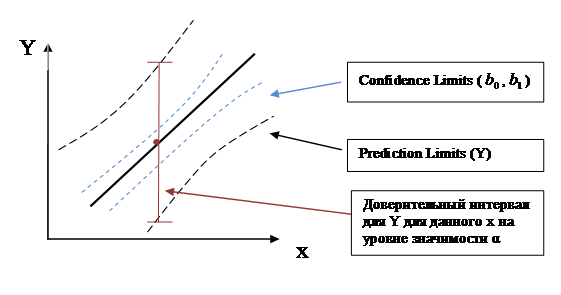
Table 2 | |||||
(оценка уравнения регрессии в целом) | |||||
Analysis of Variance (дисперсионный анализ) | |||||
Source | Sum of Squares | D. f. | Mean Square | F-Ratio | Prob. Level |
Model |
|
|
|
| P |
Error |
|
|
| ||
Total |
|
| |||
Correlation Coefficient = r | R-squared = percent | ||||
Stnd. Error of Estimat. = s | ( |
Пояснения к таблице дисперсионного анализа.
Эта таблица - еще один вариант проверки существования зависимости Y от X (значимость уравнения в целом; для простой регрессии эта проверка вырождается в проверку ![]() , а для множественной регрессии - это проверка нулевой гипотезы
, а для множественной регрессии - это проверка нулевой гипотезы ![]() :
: ![]() против альтернативной гипотезы
против альтернативной гипотезы ![]() : какие-либо из
: какие-либо из ![]() , т. е. проверка наличия зависимости Y от какого-либо
, т. е. проверка наличия зависимости Y от какого-либо ![]() ).
).
В первой колонке таблицы дисперсионного анализа (source) перечисляются источники дисперсии: дисперсия за счет регрессии (Model) и дисперсия за счет отклонения от регрессии (Error). Суммы квадратов, обусловленные регрессией и отклонением от нее, даются формулами:
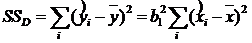
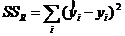 - сумма квадратов отклонений «экспериментальных» значений от модели
- сумма квадратов отклонений «экспериментальных» значений от модели
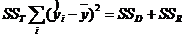
Если ошибки ![]() распределены нормально, то с помощью F-отношения можно проверить нулевую гипотезу
распределены нормально, то с помощью F-отношения можно проверить нулевую гипотезу ![]() :
: ![]() против альтернативной гипотезы
против альтернативной гипотезы ![]() :
: ![]() . Если
. Если ![]() -вернa,
-вернa, ![]() имеет F-pacnpeделение с
имеет F-pacnpeделение с ![]() и
и ![]() степенями свободы. Р-значение - это площадь под кривой
степенями свободы. Р-значение - это площадь под кривой ![]() справа от
справа от ![]() . Если
. Если ![]() , нулевая гипотеза отвергается, и, следовательно, имеется статистически значимая зависимость Y от X.
, нулевая гипотеза отвергается, и, следовательно, имеется статистически значимая зависимость Y от X.
В конце таблицы печатается значение коэффициента корреляции r, стандартная ошибка оценки s (9), а также коэффициент детерминации ![]() , т. е. доля дисперсии
, т. е. доля дисперсии ![]() , объясняемая (описываемая) регрессией Y по X. В случае простой регрессии
, объясняемая (описываемая) регрессией Y по X. В случае простой регрессии 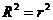 .
.
(см. Афифи, с.153).
