


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
| (27) |
Если предположить, что среднее квадратическое отклонение возмущений s(ei) (i=1, 2, …, n) пропорционально значениям xij фактора Xj (или, что одно и тоже — дисперсия возмущений ![]() пропорциональна квадрату значений фактора Xj), то исходные данные преобразуются их делением на соответствующие значения xij (i=1, 2, …, n). Такое преобразование называется масштабированием исходных данных по фактору Xj. (табл. 2).
пропорциональна квадрату значений фактора Xj), то исходные данные преобразуются их делением на соответствующие значения xij (i=1, 2, …, n). Такое преобразование называется масштабированием исходных данных по фактору Xj. (табл. 2).
Таблица | 2 |
Масштабирование исходных данных по фактору Xj |
Номер наблюдения (объекта) | Значение результата Y | Набор факторов и их значения | ||||||
X0 | X1 | X2 | … | Xj | … | Xp | ||
1 | y1/x1j | 1/x1j | x11/x1j | x12/x1j | … | 1 | … | x1p/x1j |
2 | y2/x2j | 1/x2j | x21/x2j | x22/x2j | … | 1 | … | x2p/x2j |
… | … | … | … | … | … | … | … | … |
i | yi/xij | 1/xij | xi1/xij | xi2/xij | … | 1 | … | xip/xij |
… | … | … | … | … | … | … | … | … |
n | yn/xnj | 1/xnj | xn1/xnj | xn2/xnj | … | 1 | … | xnp/xnj |
Таким же образом преобразуется и модель (27):
| (28) |
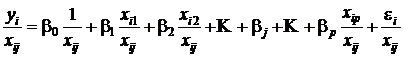 (i=1, 2, …, n),
(i=1, 2, …, n),или, что одно и тоже —
| (29) |
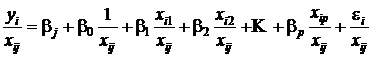 (i=1, 2, …, n),
(i=1, 2, …, n),Введем обозначения.
Пусть 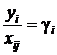 ,
, 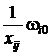 ,
, 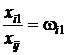 ,
, 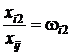 , …,
, …, 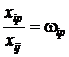 ,
, 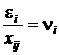 , тогда преобразованная модель окончательно будет иметь вид:
, тогда преобразованная модель окончательно будет иметь вид:
| (30) |
Параметры преобразованной модели (30) оцениваются обычным методом наименьших квадратов. Если предположение о пропорциональности среднего квадратического отклонения возмущений значениям фактора Xj имеет основание, то «новое» возмущение ni будет иметь постоянную и притом — наименьшую дисперсию, а коэффициенты уравнения регрессии окажутся несмещенными и эффективными оценками параметров модели (30). Вместе с тем следует иметь в виду, что новые преобразованные переменные получают другое экономическое содержание и их регрессия имеет иной смысл, чем регрессия по исходным данным. Поэтому численно оценки параметров моделей (27) и (30) в общем случае не совпадают.
Если строится линейная модель парной регрессии Y по X
| (31) |
то она трансформируется в модель
| (32) |
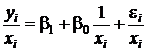 (i=1, 2, …, n),
(i=1, 2, …, n),в которой свободный член и угловой коэффициент как бы поменялись местами.
На практике иногда имеет смысл попробовать использовать одновременно несколько факторов для масштабирования исходных данных. Если каждый раз получаются сходные результаты и тесты Голдфельда–Квандта по всем факторам не выявляют гетероскедастичность возмущений, то эту проблему можно считать решенной.
В ряде случаев дисперсия возмущений зависит не от включенных в модель факторов, а от тех, которые не включены в модель, но играют существенную роль в исследуемой зависимости. Иногда для устранения гетероскедастичности необходимо изменить спецификацию модели, например, линейную на логарифмическую и т. д.
Пример 1
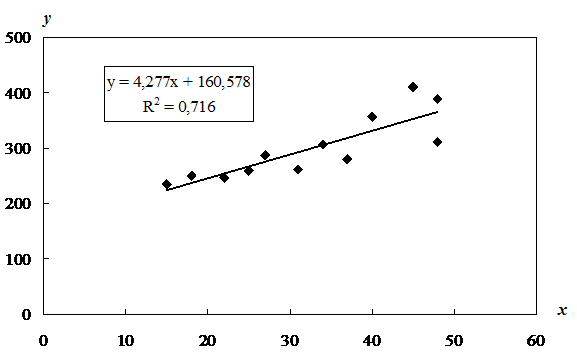
По 12 транспортным компаниям исследуется зависимость годового дохода (переменная Y, млн. руб.) от среднегодового количества грузовых автомобилей (переменная X). Имеются данные, для удобства упорядоченные по фактору X:
№ п/п | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
X | 15 | 18 | 22 | 27 | 25 | 31 | 34 | 37 | 40 | 45 | 48 | 48 |
Y | 235 | 250 | 247 | 287 | 260 | 262 | 307 | 280 | 357 | 410 | 389 | 311 |
Требуется:
1. Построить линейную модель парной регрессии Y по X.
2. Проверить наличие гетероскедастичности возмущений методом Голдфельда–Квандта.
3. При обнаружении гетероскедастичности возмущений построить взвешенную модель регрессии.
Решение
1. По исходным данным строим линейную модель парной регрессии
![]() (i=1, 2, …, n; n=12).
(i=1, 2, …, n; n=12).
Параметры модели оцениваем обычным методом наименьших квадратов. С помощь табличного процессора MS Excel были определены коэффициенты уравнения регрессии ![]() : b0=160,6; b1=4,277. Таким образом, уравнение примет вид:
: b0=160,6; b1=4,277. Таким образом, уравнение примет вид:
![]() .
.
Уравнение регрессии статистически значимо на уровне a=0,05: F‑статистика имеет значение F=25,15; табличное значение F-критерия Фишера — F0,05; 1;10=4,96; коэффициент детерминации — R2=0,716.
Значение углового коэффициента уравнения регрессии b1=4,277 показывает, что увеличение количества автомобилей на одну единицу приводит к росту годового дохода в среднем на 4,277 млн. руб.
Визуальный анализ графика зависимости годового дохода от количества автомобилей дает основание предполагать наличие гетероскедастичности возмущений. Видно, что отклонение от линии регрессии наблюдений, соответствующих крупным предприятиям, больше, чем для малых предприятий:
2. Построим график остатков и проведем его визуальный анализ. Предсказываемые уравнением регрессии значения результата ![]() и остатков (i=1, 2, …, n; n=12) приведены в таблице:
и остатков (i=1, 2, …, n; n=12) приведены в таблице:
i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
xi | 15 | 18 | 22 | 27 | 25 | 31 | 34 | 37 | 40 | 45 | 48 | 48 |
yi | 235 | 250 | 247 | 287 | 260 | 262 | 307 | 280 | 357 | 410 | 389 | 311 |
| 225 | 238 | 255 | 276 | 268 | 293 | 306 | 319 | 332 | 353 | 366 | 366 |
ei | 10 | 12 | -8 | 11 | -8 | -31 | 1 | -39 | 25 | 57 | 23 | -55 |
График остатков по фактору X показан на рисунке:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 |
