

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Министерство образования и науки
Российской федерации
Федеральное агентство по образованию
Новосибирский государственный университет
Факультет информационных технологий
Кафедра систем информатики
Дипломная работа
Разработка модуля идентификации объектов на основе локального и глобального контекста в задаче семантического анализа документов
Научный руководитель
н. с. ИСИ СО РАН
Новосибирск 2007
СОДЕРЖАНИЕ
СОДЕРЖАНИЕ.. 2
ВВЕДЕНИЕ.. 3
1. ПОСТАНОВКА ЗАДАЧИ.. 4
1.1. АКТУАЛЬНОСТЬ. 4
1.2. ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ.. 4
1.3. ПОНЯТИЕ ЛОКАЛЬНОГО КОНТЕКСТА.. 5
1.4. ПОНЯТИЕ ГЛОБАЛЬНОГО КОНТЕКСТА.. 6
2. ОБЗОР СИСТЕМ АНАЛИЗА ДОКУМЕНТОВ.. 7
2.1. СИСТЕМА InDOC.. 7
2.2. RCO КАОТ. 9
2.3. ВЫВОДЫ... 10
3. ОПИСАНИЕ РАЗРАБОТАННЫХ АЛГОРИТМОВ.. 11
3.1. ПОИСК ФОКУСНЫМИ МНОЖЕСТВАМИ.. 11
3.2. ИЕРАРХИЧЕСКИЙ ПОИСК.. 13
3.3. СТРАТЕГИИ РАЗРЕШЕИЯ ПРОТИВОРЕЧИЙ.. 14
4. ОПИСАНИЕ ПРОГРАММНОГО ПРОДУКТА.. 15
4.1. ВЫБОР СРЕДСТВ РАЗРАБОТКИ.. 15
5. РЕАЛИЗАЦИЯ.. 17
5.1. ОСОБЕННОСТИ РЕАЛИЗАЦИИ.. 17
5.2. ОПИСАНИЕ МОДУЛЕЙ.. 17
ЗАКЛЮЧЕНИЕ.. 19
ЛИТЕРАТУРА.. 20
ПРИЛОЖЕНИЯ.. 21
ПРИЛОЖЕНИЕ 1. 21
ПРИЛОЖЕНИЕ 2. 23
ВВЕДЕНИЕ
В связи с быстрым ростом информационных технологий растет количество накопленной информации. Возрос интерес к системам, которые анализируют текстовую информацию, а предполагают извлечение смысла из представленных текстовых документов.
Хотя современные системы поддерживают тематические рубрикации, поиск по ключевым словам, но пользователь все же имеет доступ лишь к фрагментам текста документов, а не к смысловой нагрузке представленной в текстах.
Этого не достаточно для современных систем, так как в огромных архивах информации, затруднен поиск конкретной, нужной информации. Так же зачастую информация устаревает – в лучшем случае появляются «дублеры», копии уже встречавшихся ранее данных, в худшем случае возможны появления противоречивой информации. Что приводит к ошибкам в предоставлении пользователю данных, а в дальнейшем может повлечь за собой неправильные решения.
Целью данной дипломной работы является разработка алгоритмов для автоматической идентификации объектов на основе глобального и локального контекстов, а так же написание модуля, основанного на разработанных алгоритмах, который бы вел автоматическую работу с данными, корректно идентифицировал полученную информацию, предоставлял пользователю возможность выбора настроек.
Для достижения поставленной цели, были рассмотрены различные варианты решения и выбраны наиболее оптимальные.
Дипломная работа была выполнена на кафедре систем информатики под научным руководством
1. ПОСТАНОВКА ЗАДАЧИ
1.1. АКТУАЛЬНОСТЬ
Сегодня, когда автоматизированные системы обработки текста получили большое распространение, встает вопрос о правильности, корректности накопленных ими данных. Современная информационная система должна с легкостью управлять потоками «серых данных», уточнять, пополнять информацию, которая к ней поступает. Важно, чтобы информация в системах не пропадала, не терялась, но при этом была корректной, полной и легко доступной.
Нужно, чтобы система следила за пополнением данных, автоматически отсеивала неполные данные, которые могут нарушить целостность и корректность информации. В системе должен быть реализован нечеткий поиск единиц информации, когда информация, которую ищем, не определена всеми характеристиками.
На сегодняшний день задача идентификации объектов очень актуальна, и интересна, так как пока не существует разработок решающих проблему, которая встала перед компьютерной лингвистикой уже сейчас.
1.2. ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ
Онтология — это всеобъемлющая и детальная формализация некоторой области знаний с помощью концептуальной схемы. Обычно такая схема состоит из иерархической структуры данных, содержащей все релевантные классы объектов, их связи и правила (теоремы, ограничения), принятые в этой области. Этот термин в информатике заимствован от древнего философского понятия «онтология».[2] В данной работе под онтологией понимается следующее:
Онтология – это шестерка вида <C, A, T, D, R, F>, где
C – множество классов, описывающих понятия предметной или проблемной области;
A – множество атрибутов, описывающих свойства понятий;
T – множество типов данных;
D – множество доменов;
R – множество отношений, заданных на классах (понятиях);
F – множество ограничений на значения атрибутов.
Элементы онтологии:
Атрибуты:
Объекты в онтологии имеют атрибуты. Каждый атрибут имеет, по крайней мере, имя и значение, и используется для хранения информации, которая специфична для объекта и привязана к нему[2]. Например, объект “Форд Explorer” имеет такие атрибуты как:
· Название: Форд Explorer
· Число-дверей: 4
· Двигатель: {4.0Л, 4.6Л}
· Коробка-передач: 6-скоростная
Значение атрибута может быть сложным типом данных.
Ключевые атрибуты – это атрибуты, по которым идентифицируется объект. Не может быть два объекта с одинаковыми значениями ключевых атрибутов.
Информационный объект – описание некоторого объекта предметной области[3]. Набор разнотипных ИО – составляют информационное напыление системы. Каждый ИО соответствует некоторому понятию или отношению представленному в онтологии. Он имеет фиксированное количество атрибутов. ИО, являющийся экземпляром отношения онтологии однозначно определяется своими аргументами и не рассматривается, если один их аргументов не задан.
1.3. ПОНЯТИЕ ЛОКАЛЬНОГО КОНТЕКСТА
Под локальным контекстом понимается содержание анализируемого документа, которое используется для решения следующих задач:
· определение референта для местоимений;
· определение референта для неоднозначных именных групп;
· отождествление объектов, имеющих один и тот же референт (который обозначает один и тот же объект действительности), на основании частично совпадающего и непротиворечивого набора атрибутов и связей.[1]
На основе локального контекста обозначены следующие задачи:
· сравнение информационных объектов по имеющимся данным; Т. е уточнение объектов, используя информацию, выделенную из конкретного текста, не затрагивая информацию, полученную раннее из других источников.
· объединение объектов; Если обнаружены два идентичных объекта, то произвести «склейку», данных объектов, т. е. объединить значения атрибутов, объединить связи с другими объектами.
1.4. ПОНЯТИЕ ГЛОБАЛЬНОГО КОНТЕКСТА
Глобальный контекст представлен всем информационным пространством системы, в котором осуществляется поиск объекта. Он содержит как результаты ранее проанализированных документов, так и информацию, вводимую пользователем вручную или поступающую из подсоединенных баз данных.[1]
На основе глобального контекста выделены следующие задачи:
· сравнение информационных объектов по всем имеющимся данным в системе. Т. е. уточнение объектов, используя информацию, выделенную из базы данных всей системы;
· при идентификации объекта, обновить информацию о нем в базе данных; Если обнаружены два идентичных объекта, то произвести склейку данных объектов, т. е. объединить значения атрибутов, объединить связи с другими объектами.
2. ОБЗОР СИСТЕМ АНАЛИЗА ДОКУМЕНТОВ
Задача разработки информационных систем, таких как системы семантического анализа текста, является одной из самых актуальных на сегодняшний день. На рынке представлены различные системы, рассмотрим две из них: систему InDoc разработанную в Институте Систем Информатики им. Сибирского Отделения Российской Академии Наук и систему RCO КАОТ от компании «Гарант-Парк-Интернет», которая специализируется на создании продуктов, предназначенных для поддержки широкого класса систем, использующих средства поиска и анализа текстовой информации, таких, как информационно-поисковые и аналитические системы, электронные архивы и системы управления документооборотом.
2.1. СИСТЕМА InDOC
Система документооборота InDoc ориентирована на предметную область и потребности крупной инвестиционной компании, управляющей строительством газопроводов
. При ее создании была разработана технология, основной задачей которой является интеллектуализация документооборота.
Такая технология должна поддерживать решение целого комплекса задач, связанных с управлением потоком входящих документов – их автоматическую классификацию и автоматическое индексирование, оперативное и адекватное распределение среди сотрудников предприятия, передачу в электронный архив и последующий поиск в нем документов по содержанию.[1]
Потребовались интеллектуальные решения с ориентацией процесса автоматической обработки документов на семантический анализ текста.
Ниже представлена общая схема системы документооборота, которая включает три контура работы с документами:
1. ввод и первичная обработка документов,
2. автоматическая обработка, индексирование и распределение документов,
3. оперативный поиск и выдача документов в соответствии с их содержанием.
InDOC поддерживает автоматическую обработку документов, с использованием знаний о предметной области и деятельности предприятия, Эта автоматическая обработка обеспечивает автоматическую адресацию и индексирование документов на основе выделенных из их текстов важных содержательных единиц.
Все проиндексированные документы хранятся в электронном архиве. Наличие индексов обеспечивает быстрый поиск документов по их содержанию.
Рассмотрим подробнее архитектуру системы документооборота (Рис. 1).
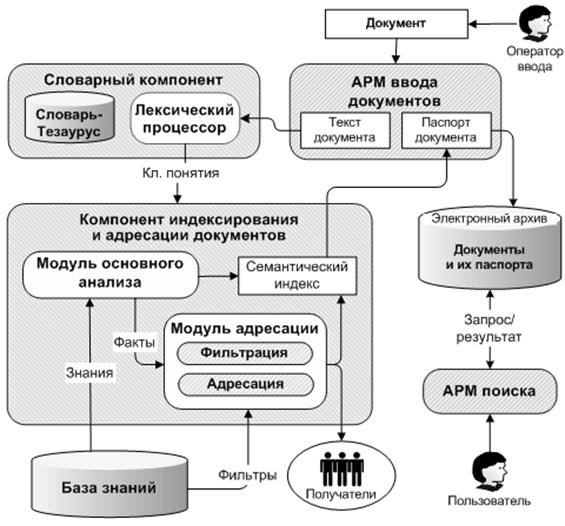
Рис. 1. Архитектура системы документооборота InDoc.
Документ поступает в систему через подсистему ввода документов. С каждым документом в системе ассоциируется электронный паспорт, который содержит индекс, т. е. список атрибутов, заполняемых либо вручную оператором при вводе документа, либо в результате его последующей автоматической обработки.
Все знания о предметной области и языке документов заносятся пользователем-экспертом в базу знаний через соответствующие АРМы. Эти же АРМы позволяют настраивать базу знаний при изменении среды и условий эксплуатации системы.
В процессе автоматической обработки текст документа поступает на вход лексического процессора, который выделяет из текста ключевые понятия ПО и передает их модулю основного анализа. Результатом работы модуля основного анализа является совокупность Фактов, отражающих содержание документа, на основе которых генерируется семантический индекс документа.
Для обеспечения рассылки документов их фактическим адресатам (получателям) служит модуль адресации. Он фильтрует полученные в результате основного анализа Факты, сравнивая их с фильтрами, отражающими информационные предпочтения сотрудников предприятия. Если тема документа соответствует фильтру, то он будет адресован ассоциированному с ним сотруднику.
По завершении этапа автоматической обработки электронный документ направляется адресатам и в электронный архив.
Для поиска необходимых документов в архиве служит подсистема поиска.[1]
2.2. RCO КАОТ
Компания «Гарант-Парк-Интернет» создала RCO КАОТ – Russian Context Optimizer Комплекс Аналитической Обработки Текста.
RCO КАОТ представляет базовое решение для организации автоматизированного рабочего места аналитика и включает в себя передовые технологии обработки текста, лингвистические и математические алгоритмы, которые могут быть использованы для решения широкого класса задач: от контекстного поиска документов с учетом всех словоформ, синонимов и опечаток до поддержки принятия экспертных решений на основе анализа информационных массивов с применением искусственного интеллекта. Все программные компоненты, вошедшие в состав RCO КАОТ, уже более года активно используются в силовых ведомствах России.
RCO КАОТ обеспечивает автоматический анализ содержания полнотекстовых документов и поддержку рабочего места аналитика с возможностью работы в локальной сети по протоколам tcp-ip и http. Серверная часть комплекса работает под управлением ОС Windows NT/2000 Server, используя в качестве сервера приложений Internet Information Server. На клиентской машине должен быть установлен Web-броузер Internet Explorer. В базовой поставке RCO КАОТ работает с документами, хранящимися в папках файловой системы, однако предполагает адаптацию к используемым хранилищам документов при необходимости. В состав RCO КАОТ входит набор программных модулей, часть из которых может поставляться или адаптироваться к нуждам заказчика независимо от других.
В полной поставке комплекс содержит следующие модули:
· RCO TopSearch Win – расширенные возможности поиска. Контекстный поиск с применением морфологического анализа и тезауруса русского языка обеспечивает эффективный поиск документов по содержащимся в них словам и фразам. Нечеткий поиск позволяет отыскать требуемую информацию при наличии орфографических ошибок в документе или в запросе. Тематический поиск позволяет находить темы, связанные в тексте по смыслу с запросом, а также искать документы по темам;
· RCO TopTree Win – построение иерархических рубрикаторов для оперативного мониторинга и маршрутизации информационных потоков, а также систематизация результатов контекстного поиска;
· RCO TopNet Win – построение и визуализация семантических сетей для навигации в информационном пространстве с опорой на ключевые объекты документов и их взаимосвязи. Позволяет исследовать смысловое окружение интересующих объектов, выявлять цепочки и области связности объектов в коллекции документов;
· RCO TopSOM Win – представление содержания коллекции документов на плоскости в форме тематической карты, визуализация распределения результатов поиска на карте;
· RCO TopLine Win - визуализация изменений тематики потока документов. Позволяет исследовать смену ракурсов, в которых фигурирует целевая проблема, во времени.[4]
2.3. ВЫВОДЫ
Система InDOC является узкоспециализированной системой, не рассчитанной на различные предметные области.
RCO КАОТ - это система, созданная для решения широкого круга задач, для различных предметных областей.
Но и в той другой есть недостаток – отсутствует модуль для идентификации объектов, полученных в ходе обработки текстовой информации. И та и другая система не следят за корректным пополнением базы данных, а, следовательно, возможны случаи, когда системы начнут наполняться ошибочной информацией.
3. ОПИСАНИЕ РАЗРАБОТАННЫХ АЛГОРИТМОВ
Была поставлена задача разработки модуля идентификации объектов, для её реализации автором были описаны и реализованы следующие алгоритмы.
3.1. ПОИСК ФОКУСНЫМИ МНОЖЕСТВАМИ
В качестве входных данных для модуля имеется упорядоченный список ИО найденных в тексте, а так же список экземпляров отношений, связывающих найденные объекты. Требуется идентифицировать найденные ИО, для того, что бы ими пополнить базу знаний информационной системы.
Данную задачу предлагается решать, используя фокусные множества, найденные в тексте. Фокусное множество включает все объекты, непосредственно связанные с одним ИО с помощью экземпляров отношений, и сопоставлении его с фокусными множествами объектов, найденных в БД системы. Важно дополнить, что в фокусные множества нужно включать лишь объекты, которые уже были идентифицированы.
Можно выделить следующие основные этапы построения фокусных множеств:
1. Разделяем общий список на два подсписка, в первый относим те объекты, у которых указаны все ключевые атрибуты, что значит, что они однозначно идентифицированы, обозначим его за А.. Во второй список заносим объекты, которые требуют уточнения, т. е. имеют не все ключевые атрибуты, обозначим его за B.
2. Список A связываем с БД.
3. Затем для каждого объекта biÎB создаем фокусное множество Fi, которое включает в себя два списка объектов. В первый список biI попадают те экземпляры отношений, которые связывают выбранный объект с объектами из списка идентифицированных A (т. к. два объекта могут связывать разные отношения, то запоминаются именно связи, в соответствии с которыми всегда можно восстановить объект[1]). Во второй же список biII попадают те экземпляры отношений, которые связывают выбранный объект с объектами, требующими уточнения, то есть из списка B.
Различия между поиском в локальном и глобальном контексте состоят на данном этапе в том, что при локальном контексте объекты, подлежащие идентификации и анализу, берутся сугубо из входных данных. В глобальном же контексте, для идентификации объектов используется всё информационное пространство системы. Также в локальном контексте, если объект не доопределен, то он часто уточняется ближайшим, встретившимся ранее "похожим" объектом. Пример: ООО "Газпром". Это компания.
Так же если объекты могут быть связаны в БД, а тексте этой связи может и не быть, но само наличие связанного объекта может предполагать (а может и нет) эту связь.
4. Создается множество похожих объектов на анализируемый объект, путем сравнения объектов по ключевым атрибутам. Выделяется множество объектов, имеющих большее количество совпадений.
5. Множество объектов «похожих» на выбранный объект из списка B фильтруются следующим образом:
· удаляются объекты, не имеющие ни одной связи;
· удаляются объекты, имеющие хоть одну связь из первого списка A (связи с идентифицированными объектами);
· если осталось несколько объектов, то продолжаем удалять объекты, только с каждым разом увеличивая требование к количеству связей, и продолжаем до тех пор, пока не останется один объект, который мы считаем «копией» выбранного объекта. Считаем, что выбранный объект нами идентифицирован;
· если же все попытки не влекут сужение множества до одного объекта, то считаем, что этот объект пока не подходит для идентификации, и переходим к рассмотрению следующего объекта.
Процесс идет до тех пор, пока мы не идентифицируем все объекты, или перестанет проходить идентификация, или никакие связи более не будут уточнены.
6. С идентифицированным объектом bi, мы поступаем следующим образом:
· производим уточнение объекта, т. е. объединяем значения атрибутов;
· переносим уточненный объект в список идентифицированных объектов A;
· пересматриваем фокусные множества для объектов связанных с только что идентифицированным объектом. Если существует связь <bi,bj>ÎbjII, то она переносится в список bjI и объект bj «выделяется», что означает, что будет осуществлена еще одна попытка идентифицировать bj, так как изменились данные.
С не идентифицированными объектами, если таковые останутся после выполнения всех шагов алгоритма, мы не производим никаких действий, так как считаем, что информации для их корректной идентификации недостаточно.
Основная идея разработанного алгоритма состоит в том, что, производя уточнение одного объекта, тем самым производим уточнение объектов, связанных с ним. Реализация приведенного алгоритма представлена в ПРИЛОЖЕНИИ 2.
3.2. ИЕРАРХИЧЕСКИЙ ПОИСК
При поиске и идентификации объектов возможны случаи, когда объект алгоритмом фокусных множеств не идентифицируется или не найден. В этих случаях автор предлагает воспользоваться алгоритмом иерархического поиска.
Алгоритм иерархического поиска:
Считаем, что класс объекта указан неверно. Расширяем запрос. Теперь ищем одинаковые или «похожие» объекты не только в экземплярах представленного данным объектом класса, но также в экземплярах класс-родителя и класс-наследника.
Использование иерархии по отношению «часть-целое» возможно в случае, когда объект подчинен другому объекту и имеет сложную структуру, представленную линейными цепочками наименований, совокупность которых образует дерево (множество деревьев) информационных объектов.[1]
Для идентификации такого объекта нужно восстановить иерархию вложенности объектов.
Для иерархии «общее-частное» необходимо определить все классы-родителей и классы-наследников, взять эту информацию из онтологии.
При выборе классов-родителей учитывается факт наличия у объекта, который нужно идентифицировать, некоторого набора ключевых атрибутов. Вложенность классов-родителей рассматривается до тех пор, пока не будет найден последний класс-родитель с набором таких же атрибутов, как и у объекта.
Затем возобновляем поиск по всем объектам, принадлежащим выбранному множеству классов. Ищем прямым способом, где поиск осуществляется по ключевым атрибутам и идет полное сравнение значений всех атрибутов или представленным раннее, т. е.построением фокусного множества.
3.3. СТРАТЕГИИ РАЗРЕШЕИЯ ПРОТИВОРЕЧИЙ
При редактировании объекта в системе могут возникать противоречия между «старыми» и «новыми» значениями его атрибутов. Это не относится к ключевым атрибутам (т. к. иначе объект невозможно было бы идентифицировать).
Существуют различные способы разрешения таких противоречий.
· замена старых значений атрибутов на новые значения. Это самый простой способ. Основан он на свойстве информации устаревать. Считается, что новая информация более правильная. Но минусом данного подхода является необратимая потеря данных, т. е. старая информация безвозвратно теряется. А если был неправильно проведен анализ текста, если новая информация оказалась ошибочной, то такой подход повлечет внесению неправильной информации в систему и в дальнейшем к некорректной её работе;
· сохранение старых и новых значений. В данном подходе считается, что проще указать дату изменений с сохранением всех значений, чем потом бороться с недостоверными данными. Но этот способ требует дальнейшей корректировки данных вручную. Т. е. конфликтную ситуацию будет решать эксперт, а не система.
· введение параметра достоверности значений. Этот способ требует сохранения старых и новых значений. Но по мере изменения этого параметра информационная система будет избавляться автоматически от недостоверных данных. Значение же этого параметра будет зависеть от частоты встречаемости данного атрибута в текстах системы.
Автором решено вынести в пользовательские настройки модуля выбор стратегии, используемой при редактировании объектов.
4. ОПИСАНИЕ ПРОГРАММНОГО ПРОДУКТА
4.1. ВЫБОР СРЕДСТВ РАЗРАБОТКИ
Для программной реализации был выбрана среда программирования Visual Studio 2005. Язык программирования – C#, база данных – СУБД MySQL. По следующим причинам:
C#— язык программирования, сочетающий объектно-ориентированные и контекстно-ориентированные концепции. Разработан в 1998—2001 годах группой инженеров под руководством Андерсa Хейлсбергa в компании Microsoft как основной язык разработки приложений для платформы . Компилятор с C# входит в стандартную установку самой. NET, поэтому программы на нём можно создавать и компилировать даже без инструментальных средств, таких как, например, Visual Studio.
C# относится к семье языков с C-подобным синтаксисом, из них его синтаксис наиболее близок к С++ и Java. Язык имеет строгую статическую типизацию, поддерживает полиморфизм, перегрузку операторов, указатели на функции-члены классов, атрибуты, события, свойства, исключения, комментарии в формате XML. С# исключает некоторые модели, зарекомендовавшие себя как проблематичные при разработке программных систем: так, C# не поддерживает множественное наследование классов (в отличие от C++) или вывода типов.[2]
4.2. Технология
.NET — программная технология, предложенная фирмой Microsoft в качестве платформы для создания, как обычных программ, так и web-приложений. Во многом является развитием идей и принципов, заложенных в технологии Java.
Одной из основных идей. NET является совместимость различных служб, написанных на разных языках. Например, служба, написанная на C++ для. NET, может обратиться к методу класса из библиотеки, написанной на Delphi; на C# можно написать класс, наследующий от класса, написанного на Visual , а исключение, выброшенное методом, написанным на C#, может быть поймано и обработано в Delphi. Каждая библиотека (сборка) в. NET имеет сведения о своей версии, что позволяет устранить возможные конфликты между разными версиями сборок.
.NET — кроссплатформенная технология, однако в настоящее время существует реализация для платформы Microsoft Windows, FreeBSD (от Microsoft) и ограниченный вариант технологии для ОС Linux в рамках свободных проектов Mono, DotGNU.[2]
4.3. MySQL
MySQL – это система управления базами данных, разрабатываемая и сопровождаемая компанией MySQL AB. Первоначально сервер MySQL разрабатывался для управления большими базами данных с целью обеспечить более высокую скорость работы по сравнению с существующими на тот момент аналогами. Благодаря своей доступности, скорости и безопасности MySQL очень хорошо подходит для доступа к базам данных по Internet. Сервер MySQL управляет доступом данных, позволяя работать с ними одновременно нескольким пользователям, обеспечивает быстрый доступ к данным и гарантирует предоставление доступа только пользователям, имеющим на это право. То есть MySQL является многопользовательским многопоточным сервером. Главным преимуществом данной СУБД является высокая производительность. Кроме того, пакет MySQL распространяется бесплатно и прост в использовании.
Плюсы MySQL:
· Он протестирован на множестве различных компиляторов и платформ (Unix, Linux, *BSD, Windows и др.);
· Имеет API для различных языков программирования (например, C, C++, Eiffel, Java, Perl, PHP, Python, Ruby и Tcl);
· Удовлетворяет стандарту SQL92.
5. РЕАЛИЗАЦИЯ
5.1. ОСОБЕННОСТИ РЕАЛИЗАЦИИ
Важным условием при реализации разработанных алгоритмов было условие – независимости.
Алгоритмы поиска должны быть абстрагированы от конкретной БД, то есть методы поиска должны работать для любой базы данных. Для обеспечения выполнения данного условия, автором были разработаны функции-конверторы.
Общий объект – это объект, который представляет собой список атрибутов данного объекта (название, значение), имя класса, дескриптор класса, в котором описаны ключевые атрибуты. Общие объекты бывают двух типов: объект, отношение.
Общий объект-отношение – это объект, который представляет собой список атрибутов данного отношения (название, значение), ссылку на связанные общие объекты данным объектом-отношением.
Функция-конвертор – это метод конвертирования объекта из БД в общий объект или в общий объект-отношение, с которым работают алгоритмы, то есть для использования разработанных алгоритмов, на любой другой базе данных, достаточно изменить (переписать) функции работы с объектами БД, такие как функции-конверторы, вставка объекта, удаление объекта, обновление объекта. При этом алгоритмы поиска не требуют корректировок.
5.2. ОПИСАНИЕ МОДУЛЕЙ
Программа состоит из двух основных модулей. Оба выполнены в виде динамически подключаемых библиотек (DLL – файлов).
Интерфе́йс программи́рования приложе́ний (Application Programming Interface, API) — набор методов (функций), который программист может использовать для доступа к функциональности программной компоненты (программы, модуля, библиотеки)[2].
Для работы с MySql сервером использовалась динамическая библиотека MySQL. dll, которая представляет собой набор средств для работы с СУБД MySql.
Модуль Referent. Data. dll – это вспомогательное API средство для работы с базой данных MySQL.
Referent. Data. dll содержит основной класс для работы с базой данных, DataManager, который осуществляет доступ к БД, выполнение текстовых запросов к БД, выполнение хранимых процедур.
Referent. Class. dll – это модуль работы с данными, который включает основные алгоритмы, реализацию разработанных алгоритмов: алгоритма иерархического поиска и алгоритма поиска фокусными множествами.
Основные функции:
UpdateDataObj – функция, которая обновляет информацию об объекте в БД.
InsertDataObj - функция, которая вставляет данные объекта в базу.
MergerObject – функция, объединяющая два объекта.
ConvertFromData_objectsToDataobj – функция - конвертер, которая создает из объекта базы данных общий объект, с которым работают функции поиска.
ConvertFromData_relationToDataRelaction – функция - конвертер, которая создает из объекта-отношение базы данных общий объект-отношение, с которым работают функции поиска.
FokusSetSearch – функция поиска фокусными множествами.
HierarchicalSearchChild – функция иерархического поиска, которая рассматривает объекты класс-наследников.
HierarchicalSearchParent – функция иерархического поиска, которая рассматривает объекты класс-родителей.
Настроечный файл settings. csv – содержащий в себе основные настройки модулей.
Настройки:
Datasource – сервер, где находится БД.
Username – логин.
Password – пароль.
Database – имя БД.
ReplaceOlddata – заменять ли старые данные на новые.
SaveAllData – сохранять все значения.
Тестирование разработанных алгоритмов было проведено на базе данных археологического портала, структура данной базы данных представлена в ПРИЛОЖЕНИИ 1.
ЗАКЛЮЧЕНИЕ
При выполнении дипломной работы были проделаны следующие виды работ:
· изучена предметная область;
· рассмотрена и изучена структура БД археологического портала;
· разработаны и реализованы алгоритмы поиска и идентификации объектов;
· спроектировано и создано АПИ для работы с БД;
· проведено тестирование алгоритмов на различных входных данных.
Общим результатом проекта является создание модуля для автоматической обработки информационных объектов. Основным достоинством данного модуля можно считать автоматическое слежение за корректностью данных, легкость в использовании, а так же уникальность используемых алгоритмов.
ЛИТЕРАТУРА
1. Сидорова : Методы программные средства для анализа документов на основе модели предметной области // Российский НИИ искусственного интеллекта, Институт системам информатики СО РАН 2006г
125ст.
2. Википедия (http://ru. wikipedia. org и http://en. wikipedia. org)
3. , А, Кононенко ://Семантический подход к анализу документов на основе
онтологии предметной области // Российский НИИ Искусственного Интеллекта, ИСИ СО РАН им. , Новосибирск.
4. Сайт компании RCO (http://www. *****/)
5. , , Статья: Система INDOC: интеллектуальная обработка, распределение и поиск документов в электронном архиве // Российский НИИ искусственного интеллекта, Институт системам информатики СО РАН
ПРИЛОЖЕНИЯ
ПРИЛОЖЕНИЕ 1
Структура используемой базы данных археологического портала:
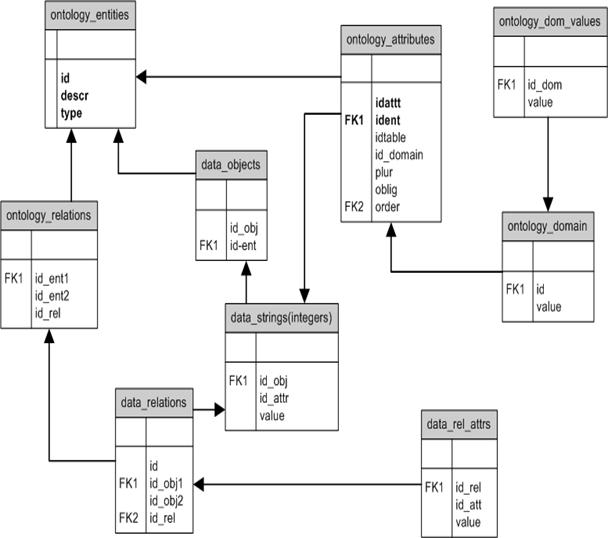
Рис.2. Упрощенная структура базы данных (без учета структурной классификации).
База данных содержит изменяемую часть онтологии. Системная классификация состоит из 2-х частей: таблиц, хранящих данные, и таблиц, отвечающих за отображение.
Онтология хранится с помощью следующих таблиц:
· ontology_entities – таблица онтологических сущностей. Каждая сущность имеет название (descr) и тип (type). Количество типов зафиксировано, каждый тип определяет, что за сущность описывается: понятие, структура, ассоциативное отношение, отношение часть-целое, отношение наследования. Набор типов не может быть изменен;
· ontology_relations – таблица отношений, служит для описания аргументов отношений (при этом само отношение задается в таблице ontology_entities и может иметь дополнительные атрибуты);
· ontology_attributes – таблица атрибутов. Тип атрибута задается указанием таблицы, в которой хранятся данные или значения атрибута (на упрощенной схеме отображена только одна такая таблица data_strings, хранящая строковые значения атрибутов), а также ссылкой на домен, если это требуется. Свойства атрибута: множественность (plur), обязательность (oblig), порядок визуализации (order);
· ontology_domain – таблица доменов, value – строковое название домена;
· ontology_dom_values – таблица значений доменов, связывает строковые значения с доменом, к которому они относятся.
Данные хранятся в таблицах:
· data_objects – таблица объектов; связывает объект с его классом;
· data_relations – таблица связей между объектами, соответствующих некоторому отношению онтологии;
· data_strings – таблица значений атрибутов объектов;
· data_rel_attrs – таблица значений атрибутов связей.
ПРИЛОЖЕНИЕ 2
Реализация основного алгоритма «поиск фокусными множествами»:
public static List<int> FocusSetSearch(List<DataObject> list_DataObject, List<DataRelation> list_DataRelation)
{
List<DataObject> list_DataObject_ = new List<DataObject>(list_DataObject);
FocusSet _FocusSet = new FocusSet();
_FocusSet. IdentficObject = new List<int>();
_FocusSet. NotIdentFicObject = new List<int>();
int countObj = 0;
do
{
_FocusSet. IdentficObject. AddRange(StraightSearch(list_DataObject_, ref _FocusSet. NotIdentFicObject));
list_DataObject_.RemoveAll(new Predicate<DataObject>(delegate(DataObject _DataObject)
{
return _FocusSet. IdentficObject. Contains(_DataObject. LocalID);
}));
countObj = list_DataObject_.Count;
Dictionary<int, List<int>> Focusset = new Dictionary<int, List<int>>();
foreach (DataObject _DataObject in list_DataObject_)
{
List<int> temp = new List<int>();
foreach (DataRelation _DataRelaction in list_DataRelation)
{
if((_DataObject. LocalID==_DataRelaction. oneDataObj. LocalID) && (!temp. Contains(_DataRelaction. twoDataObj. LocalID)))
temp. Add(_DataRelaction. twoDataObj. LocalID);
if((_DataObject. LocalID==_DataRelaction. twoDataObj. LocalID) && (!temp. Contains(_DataRelaction. oneDataObj. LocalID)))
temp. Add(_DataRelaction. twoDataObj. LocalID);
}
Log. WriteMessageIntoLogFile("create focus set");
Focusset. Add(_DataObject. LocalID, temp);
}
Dictionary<int, List<int>> AlikeSetObj = AlikeObject(list_DataObject_);
Log. WriteMessageIntoLogFile("create AlikeSetObj");
Dictionary<int, List<int>> OLDAlikeSetObj = AlikeSetObj;
foreach (KeyValuePair<int, List<int>> temp in AlikeSetObj)
{
Dictionary<int, int> bound = new Dictionary<int, int>();
int MAX = 0;
foreach (int element in temp. Value)
{
int count = 0;
if (element!= 0)
{
foreach (int it in Focusset[element])
{
if (_FocusSet. IdentficObject. Contains(it))
{
count = count + 1;
}
}
if (MAX < count) MAX = count;
bound. Add(element, count);
}
}
foreach (KeyValuePair<int, int> _bound in bound)
{
if (MAX < _bound. Value)
{
OLDAlikeSetObj[temp. Key].Remove(_bound. Key);
Log. WriteMessageIntoLogFile("remove from alike id=" + _bound. Key);
}
}
}
DataObject foundOneDataObject = list_DataObject_.Find(new Predicate<DataObject>(delegate(DataObject dObject)
{
return OLDAlikeSetObj. ContainsKey(dObject. LocalID) && OLDAlikeSetObj[dObject. LocalID].Count == 1;
}));
if (foundOneDataObject!= null)
{
DataObject foundTwoDataObject = list_DataObject_.Find(new Predicate<DataObject>(delegate(DataObject dObject)
{
return dObject. LocalID == OLDAlikeSetObj[foundOneDataObject. LocalID][0];
}));
if (foundTwoDataObject!= null)
{
list_DataObject_.Remove(foundOneDataObject);
list_DataObject_.Remove(foundTwoDataObject);
list_DataObject_.Add(MergerObject(foundOneDataObject, foundTwoDataObject));
Log. WriteObjectIntoBaseFile(foundOneDataObject);
Log. WriteObjectIntoBaseFile(foundTwoDataObject);
if(foundOneDataObject. LocalID >= foundTwoDataObject. LocalID)
{
_FocusSet. NotIdentFicObject. Remove(foundOneDataObject. LocalID);
list_DataRelation. ForEach(new Action<DataRelation>(delegate(DataRelation _DataRelation)
{
if (_DataRelation. LocalID == foundOneDataObject. LocalID) _DataRelation. LocalID = foundTwoDataObject. LocalID;
}));
//_FocusSet. IdentficObject. Add(foundOneDataObject. LocalID);
}
else
{
_FocusSet. NotIdentFicObject. Remove(foundTwoDataObject. LocalID);
list_DataRelation. ForEach(new Action<DataRelation>(delegate(DataRelation _DataRelation)
{
if (_DataRelation. LocalID == foundTwoDataObject. LocalID) _DataRelation. LocalID = foundOneDataObject. LocalID;
}));
//_FocusSet. IdentficObject. Add(foundTwoDataObject. LocalID);
}
}
}
}
while (countObj!= list_DataObject_.Count);
return new List<int>(_FocusSet. IdentficObject);
}
