
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Составитель
УДК 681.3
ББК 32.973.26-018.2.75
РАБОТА С ДИНАМИЧЕСКИМИ ПЕРЕМЕННЫМИ И УКАЗАТЕЛЯМИ В ИНТЕГРИРОВАННОЙ СРЕДЕ ТУРБО ПАСКАЛЬ: Методические указания к лабораторному практикуму по курсу «Информатика и программирование»/ Уфимск. гос. авиац. техн. ун-т; Сост. А. М Сулейманова.– Уфа, 2004.– 45 с.
Содержатся сведения, необходимые для составления алгоритмов и программ, приведены способы реализации программ использующих динамические переменные и указатели. Практическое применение иллюстрируется различными примерами. Обсуждается методика выполнения лабораторной работы. Приведены перечни заданий на выполнение лабораторных работ.
Предназначены для студентов специальности «Прикладная информатика в экономике».
Библиогр.: 3 назв.
Рецензенты: ,
© Уфимский государственный авиационный
технический университет, 2004
СОДЕРЖАНИЕ
1. ЦЕЛЬ РАБОТЫ
2. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
2.1. Типичная проблема4
2.2. Статические и динамические переменные
2.3. Указатели7
2.4. Два вида динамических данных
2.5. Процедуры и функции для работы с динамической
памятью. 20
2.6 Работа с обширным массивом
3. ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ
4. ТРЕБОВАНИЯ К ОТЧЕТУ
5. КОНТРОЛЬНЫЕ ВОПРОСЫ
6. ВАРИАНТЫ ЗАДАНИЙ
СПИСОК ЛИТЕРАТУРЫ . . 45
ЛАБОРАТОРНАЯ РАБОТА
РАБОТА С ДИНАМИЧЕСКИМИ ПЕРЕМЕННЫМИ
И УКАЗАТЕЛЯМИ В ИНТЕГРИРОВАННОЙ СРЕДЕ
ТУРБО ПАСКАЛЬ
1. ЦЕЛЬ РАБОТЫ
Целью настоящей работы является изучение методов программирования алгоритмов с разветвляющейся и циклической структурой.
2. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
Переменные обычно создаются при запуске программы (занимая при этом соответствующий объем памяти) и существуют вплоть до конца работы программы – это так называемые статические переменные. Легко прийти к выводу, что это не самый рациональный способ использования памяти. Познакомимся с возможной альтернативой – динамическими переменными, которые создаются непосредственно перед началом их использования и ликвидируются (освобождая при этом занимаемую память) сразу, как только это использование завершено.
2.1. Типичная проблема
Предположим, нам необходимо создать программу, обрабатывающую массив из 15 тысяч элементов, который содержит целочисленные значения типа LongInt. Как может выглядеть соответствующая программа, демонстрирует пример 1.
Пример 1
Program array1;
Const number=15000;
Type
a=array [0..number] of longint;
var
ch:a;
i:word;
Begin
Writeln;
For i:=1 to 15000 do
If (i mod 1000=0) or (i=number) then
Begin
ch[I]:=I;
Write(I;10, ch[I]:6)
End;
End.
В этой программе объявлен массив, содержащий 15 тысяч значений типа Longint. В теле программы организован цикл (с помощью оператора FOR...TO...DO), в котором каждому элементу массива присваивается значение его индекса. Кроме того, значения элементов массива, а также значения параметра цикла (совпадающие между собой), кратные 1000, выводится на экран для контроля. Для того чтобы сразу же видеть результаты работы программы, в конце имеется оператор ReadLn. Благодаря этому результаты можно наблюдать на экране до тех пор, пока вы не введете что-нибудь и не нажмете клавишу <Enter>.
В принципе, в этой программе нет ничего нового для нас. Однако допустим, что возникла необходимость иметь дело с массивом, содержащим не 15, а 20 тысяч элементов. В представленной выше программе изменим значение константы Number снаи запустим программу на выполнение, чтобы посмотреть, что получится.
При попытке запуска (напомним, что это осуществляется комбинацией клавиш <Ctrl+F9> или выбором пункта Run в одноименном меню) на экране появляется сообщение:
Error 22: Structure too large.
Это значит: "Ошибка 22: Структура чересчур объемиста".
Если теперь в меню Help выбрать пункт Error messages, а затем в появившемся окне дважды щелкнуть на номере этой ошибки (22), появится еще одно окно с соответствующей информацией. Информации в этом окне не так уж и много. Сообщается только, что максимальная размерность для структурированных типов составляетбайт. Что же это значит?
Вспомним, что элементы нашего массива содержат целочисленные значения, принадлежащие типу Longint (один из целочисленных типов), для каждого из которых требуется четыре байта памяти. Кроме того, массив (его первый вариант) включает 15 тысяч элементов, что в целом составляетбайт. Затем мы попытались перейти к массиву сэлементами. Нетрудно вычислить, что для такого массива, каждый элемент которого занимает в памяти четыре байта, в целом потребуется 80 тысяч байт. А теперь вспомним, что информация об ошибке 22 гласит: максимальная размерность для структурированных типов составляетбайт. Это все объясняет. Если в первом случае допустимый предел превзойден не был (60 тысяч – это меньше чем, то второй вариант нашего массива (20 тысяч элементов) оказался недопустимо объемным.
Ну и что же дальше? Что если имеет место настоятельная необходимость работать с большими массивами? Неужели Turbo Pascal для этого не подходит? Оказывается, язык программирования Turbo Pascal позволяет справиться и с этой проблемой. Познакомимся с такими понятиями, принятыми в Turbo Pascal, как динамическая память и указатель.
2.2. Статические и динамические переменные
До сих пор мы имели дело с так называемыми статическими данными и статическими переменными. Такие переменные объявляются в начале программы (в разделе описаний) и существуют до завершения ее работы. Соответственно, память для содержания этих переменных выделяется при запуске программы и остается занятой все время, пока программа работает.
Очевидно, что это не самый рациональный способ использования памяти компьютера. Например, некоторая переменная может использоваться только однажды в единственном операторе обширной программы, однако память, выделенная под эту переменную, остается занята все время, пока работает программа. А нельзя ли сделать так, чтобы память для такой переменной выделялась в момент, когда переменная начинает использоваться, и освобождалась сразу же по завершении ее использования? И чтобы эту память тут же можно было выделить для иных данных? Оказывается, это вполне реально и именно для этой цели в Turbo Pascal введено понятие динамической памяти. Динамическая память, известная также как куча, рассматривается в Turbo Pascal как массив байтов.
Кроме того, динамическая память (или куча), имеющая объем приблизительно байт, позволяет обрабатывать более обширные структуры данных. В предыдущем разделе нам не удалось, используя Обычную (статическую) память, создать массив изэлементов типа LonInt. С помощью динамической памяти можно обработать гораздо больший массив, что мы и докажем в конце данной главы.
Правда, при динамическом размещении к данным не удастся обращаться по именам, как к статическим данным, с которыми мы до сих пор имели дело. Кроме того, количество и тип динамически размещаемых данных заранее неизвестны. Динамическая память выделяется для данных (и освобождается) в ходе работы программы. Для управления динамической памятью Turbo Pascal предоставляет гибкое средство, известное как указатели.
2.3. Указатели
Мы уже знаем, что оперативная память компьютера – это множество ячеек, каждая из которых предназначена для хранения одного байта информации, и каждая имеет собственный адрес, по которому к этой ячейке можно обратиться. Указатель – это переменная, объявленная в разделе описаний программы, значение которой и представляет собой адрес одного байта памяти.
Указатели, используемые в Turbo Pascal, бывают типизированные и нетипизированные. Если нетипизированный указатель – это переменная, содержащая адрес данных произвольного типа, то типизированный указатель содержит адрес данных, тип которых оговаривается при объявлении данного указателя.
Нетипизированные указатели объявляются следующим образом:
var
рр : pointer;
где POINTER – стандартный тип данных;
РР – переменная, содержащая адрес памяти, по которому могут храниться данные произвольного типа.
Что касается типизированных указателей, то их объявления в программах на Turbo Pascal выглядят так:
var
рх : ^char;
ру : ^integer;
В этом примере описаны два типизированных указателя: РХ и PY. Значения этих переменных представляют собой адреса в оперативной памяти, по которым содержатся данные типа Char и Integer соответственно. Нетрудно заметить, что описание типизированного указателя отличается от описания статической переменной того же типа только тем, что в случае указателя перед типом присутствует символ "^".
Подытожим: когда требуется воспользоваться динамической памятью, в разделе описаний объявляется не сама переменная, а указатель (или ссылка) на нее. В этом случае указатель представляет собой обычную переменную, а переменная, на которую он ссылается, – динамическую. При этом если в выражении должен присутствовать указатель, используется идентификатор, объявленный в разделе описаний. Вот так: РХ. Однако, если в выражении должна фигурировать динамическая переменная, на которую ссылается указатель, идентификатор указателя дополняется символом "^". Такое действие называется разыменованием. Например, РХ^.
Еще пример:
type
DatePointer = ^Date;
Date=record
year : 1900..2100;
month : 1..12;
day : 1..31;
next : DatePointer
end;
var
pd : DatePointer;
Здесь объявлен тип DatePointer, представляющий собой указатель на тип Date, который описывает запись. Обратите внимание, что тип DatePointer описан до типа Date, на который он ссылается. В то же время одно из полей записи Date принадлежит типу DatePointer. В целом, в Turbo Pascal не допускается ссылаться на еще не описанные типы, однако в данном случае (достаточно частом, когда приходится иметь дело с указателями) как ни располагай описания, все равно ссылки на еще не описанный тип не избежать. Поэтому единственное исключение сделано для указателей: тип указателя на динамические данные может быть объявлен до описания самих данных.
Необходимо заметить, что применительно к типизированным указателям операция присваивания допустима только для указателей, ссылающихся на данные одного типа. Предположим, в программе объявлены указатели:
var
рх, ру : ^char;
pz : ^integer;
В этом случае операция присваивания допустима для указателей РХ и РY:
px := py
Однако совершенно недопустимыми окажутся операторы:
рх : = pz;
или
pz :=ру;
В то же время нетипизированный указатель может присутствовать в операторе присваивания в паре с любым типизированным указателем. Например, в программе объявлены указатели:
var
рх : ^ char;
py : ^ integer;
pz : pointer;
Для этих переменных допустимы операторы присваивания:
рх : pz; ру : pz;
pz :ру; pz ; рх;
Нетрудно прийти к выводу, что нетипизированные указатели – очень удобное средство преобразования типов данных.
2.3.1. Состояния указателя. Для указателя, после того как он объявлен в разделе описания переменных, возможны три состояния. Указатель может содержать адрес некоторой переменной, "пустой" адрес NIL или иметь неопределенное состояние. Первый случай в объяснениях не нуждается. Во втором случае, когда требуется, чтобы указатель никуда не указывал, ему присваивается специальное значение NIL. Что же касается неопределенного состояния, то оно имеет место сразу после начала работы программы (до того как указателю будет присвоен какой-нибудь адрес в памяти или значение NIL), либо после освобождения памяти, на которую данный указатель ссылается.
Если кого-то смущает "указатель, который никуда не указывает", то это можно представить как ссылку на область памяти, в которой никакая информация никогда не размещается. Значение NIL – это константа, которую можно присвоить любому указателю.
Может возникнуть вопрос, в чем разница между неопределенным состоянием указателя и случаем, когда его значение равно NIL? Поскольку NIL – значение конкретное, хотя и никуда не указывающее, можно сказать, что два указателя, содержащие NIL, имеют равные значения. В то же время значения двух указателей в неопределенном состоянии равными признать нельзя.
2.3.2. Выделение и освобождение динамической памяти. Познакомимся с тем, как выделяется (или резервируется) динамическая память для типизированных и нетипизированных указателей. Кроме того, узнаем как освободить память, которая была выделена ранее.
Для типизированных указателей
Для динамически размещаемых переменных, на которые ссылаются типизированные указатели, память выделяется и освобождается с помощью процедур New и Dispose соответственно. Вот как схематически может выглядеть программа, в которой используются указатели на переменные, размещаемые в динамической памяти:
var
рх, ру : ^char;
pz : ^integer;
begin
new(px);
new(py);
new(pz);
px^ : ='A';
py^ : ='7';
pz^ : =667;
…
dispose(px);
dispose(py);
dispose(pz);
…
end.
В этой программе в разделе описания переменных объявлены три типизированных указателя. Затем в теле программы под динамические переменные, на которые ссылаются эти указатели, с помощью процедуры New выделена динамическая память. После этого динамическим переменным можно присваивать подходящие по типу значения (это есть в теле программы) и использовать их в разного рода выражениях (операторы с этими выражениями в теле программы заменены тремя точками).
Когда надобность в переменных РХ, PY и PZ отпадает, выделенная для них память освобождается с помощью процедуры Dispose. После этого освободившуюся память можно резервировать для других переменных, объявленных в программе и использующихся в оставшихся операторах.
Для нетипизированных указателей
Для динамически размещаемых переменных, на которые ссылаются нетипизированные указатели, память выделяется и освобождается с помощью процедур GetMem и FreeMem соответственно. Вот как схематически может выглядеть программа, в которой используются нетипизированные указатели:
var
px, py : pointer;
begin
GetMem(px, SizeOf(char));
GetMem(py, SizeOf(integer));
px^ : ='A';
py^ : = 7;
…
FreeMem(px, SizeOf(char));
FreeMem(py, SizeOf(integer));
…
end.
В этой программе в разделе описания переменных объявлены два нетипизированных указателя. Затем в теле программы под динамические переменные, на которые ссылаются эти указатели, с помощью процедуры GetMem выделена динамическая память. Эта процедура имеет два параметра, один из которых представляет собой переменную указательного типа, а второй – целочисленное выражение, определяющее объем выделяемой памяти в байтах. Часто для определения второго параметра процедуры GetMem используется функция SizeOf, возвращающая длину в байтах внутреннего представления указанного объекта. В нашем случае функция SizeOf помогает определить, сколько байт памяти потребуется для данных типа Char и Integer..
После выделения памяти динамическим переменным можно присваивать значения подходящего типа (для которых подходит объем зарезервированной памяти – это есть в теле программы) и использовать их в разного рода выражениях (операторы с этими выражениями в теле программы заменены тремя точками).
Когда надобность в переменных РХ и PY отпадает, выделенная для них память освобождается с помощью процедуры FreeMem. Эта процедура имеет те же параметры, что и процедура GetMem. После этого освободившуюся память можно выделять для других переменных, использующихся в оставшихся операторах.
2.3.3. Действия над указателями и динамическими переменными. После того как указатель объявлен (в разделе описаний программы) и под динамическую переменную, на которую он ссылается, выделена память (с помощью процедуры New или GetMem), над указателем и динамической переменной обычно производятся какие-то манипуляции (иначе зачем же их объявлять и выделять память). К динамическим переменным применимы все действия, допустимые для данных этого типа. Иными словами, динамической переменной можно манипулировать так же, как и аналогичной статической переменной. Некоторые из этих действий иллюстрирует рис.1.
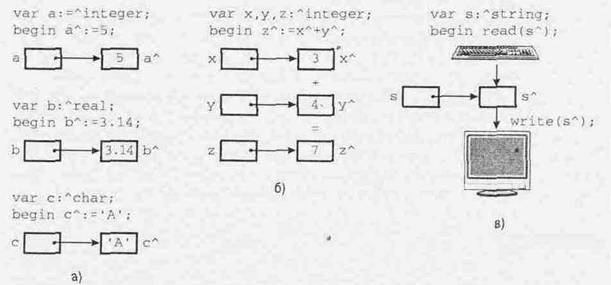
Рис.1. Действия над динамическими переменными
На рис.1(а) представлена операция присваивания. Здесь трем динамическим переменным А, В и С, принадлежащим разным типам, присваиваются некоторые значения.
На рис.1(б) представлена операция сложения. Здесь значения двух динамических переменных Х и Y складываются и присваиваются третьей переменной – Z.
На рис.1(в) представлены операции ввода с клавиатуры и вывода на экран. Здесь значение динамической строковой переменной сначала вводится с клавиатуры, а затем выводится на экран.
Для указателей (а не данных, на которые они указывают) допустимо только следующее:
1. Проверка равенства. Например:
if рх = ру then...
где РХ и PY – указатели. Этот оператор проверяет, ссылаются ли указатели на один и тот же адрес памяти. Однако если бы здесь вместо рх=ру присутствовало рх<ру или рх>ру, то была бы зафиксирована ошибка.
2. Значение одного указателя можно присвоить другому указателю, если оба указателя ссылаются на динамическую переменную одного типа. Например:
рх := ру;
где РХ и PY – указатели.
Это ограничение распространяется только на типизированные указатели. Нетипизированному указателю можно присвоить значение любого указателя. Точно так же любому указателю можно присвоить значение нетипизированного указателя.
3. Значения указателям (представляющие собой адреса памяти) присваиваются процедурой New или GetMem при выделении памяти для динамических переменных. Поэтому присваивать с помощью оператора присваивания указателям какие-либо явно заданные значения нельзя – за исключением NIL. Как мы уже знаем, указатель со значением NIL указывает "в никуда".
После завершения использования в программе динамической переменной не забывайте освободить выделенную для нее память. Для этого предназначены процедуры Dispose и FreeMem.
2.4. Два вида динамических данных
Динамические данные, на которые ссылаются указатели, можно разделить на две категории: данные без внутренних ссылок и данные с внутренними ссылками.
2.4.1. Динамические данные без внутренних ссылок. Эти данные отличаются от статических данных только тем, что в разделе описания переменных объявляются не переменные, а указатели на них. Сами же переменные создаются и ликвидируются в ходе работы программы, когда под них выделяется память (процедурой New или GetMem), или эта память освобождается (процедурой Dispose или FreeMem).
Целесообразно ли использовать такие данные? В чем их преимущества по сравнению с аналогичными статическими данными? Во-первых, как уже отмечалось, для статических данных память выделяется при запуске программы, и эта память остается занята, пока программа не завершит работу. А для динамических данных (с внутренними ссылками и без них) память выделяется в момент начала использования той или иной динамической переменной и освобождается сразу же по завершении ее использования. Иными словами, применяя динамические переменные, можно обойтись меньшим объемом оперативной памяти.
Во-вторых, динамическая память предоставляет возможность работать с данными структурированных типов гораздо большего объема. Помните, массив, содержащийэлементов типа Longint, мы смогли обработать, а– уже нет?
Примеры использования статических и аналогичных динамических (без внутренних ссылок) структур данных можно видеть в табл.1.
В этой таблице можно видеть два фрагмента программ, в одной из которых используются статические переменные (две из них принадлежат типам Boolean, Integer, а третья является массивом), а в другой – аналогичные динамические переменные. Исходные тексты программ расположены таким образом, чтобы подобные операторы в двух программах размещались один против другого (мы знаем, что наличие пустых строк в исходном тексте не влияет на работу программы).
Как указывалось, основная особенность при использовании динамических переменных состоит в необходимости выделять для этих переменных память (в данной случае с помощью процедуры New, поскольку мы имеет дело с типизированными указателями), а затем освобождать выделенную память (процедура Dispose). Это и демонстрируют представленные примеры.
Таблица1
Использование статических и динамических данных
Статические переменные | Динамические переменные |
var a:boolean; b:integer; x:array[1..10] of integer; j:1..10; begin a:=true; b:=44; for j:=1 to 10 do read(x[j]); … end. | type v=array[1..10] of integer; var pa:^boolean; pb: ^integer; px:^v; j:1..10; begin New(pa); New(pb); New(px); pa^:true; pb^:=44; for j:=1 to 10 do read(px^[j]); … Dispose(pa); Dispose(pb); Dispose(px); end. |
И еще нюанс. Обратим внимание, что в первой программе в разделе описания переменных массив объявлен так:
х : аrrау[1..10] of integer;
А во второй программе в разделе описания типов объявлен тип V:
v = array[1..10] of integer;
затем в разделе описания переменных объявлен указатель РХ на данные типа V:
рх : ^v;
А почему бы во второй программе не поступить как в первой, объявить указатель на массив? Вот так:
рх : ^array[1..10] of integer;
К сожалению, если так сделать, а затем запустить программу, появится сообщение об ошибке, гласящее, что в этой точке программы (т. е. после знака ^) ожидается идентификатор. (ARRAY – это, как известно, не идентификатор, а зарезервированное слово). Иными словами, объявить указатель непосредственно на массив нельзя. Чтобы обойти это препятствие, пришлось сначала объявить пользовательский тип V:
v = array[1..10] of integer;
а затем – указатель на данные типа V:
рх : ^v;
То, о чем здесь шла речь применительно к массивам, относится также к записям и множествам, поскольку RECORD и SET – также зарезервированные слова.
2.4.2. Динамические данные с внутренними ссылками. Помимо простых (т. е. без внутренних ссылок) динамических данных возможно существование динамических структур, в которых элементы ссылаются один на другой. Как это реализуется? Очевидно, что элемент подобной структуры должен представлять собой запись не менее чем с двумя полями. Одно поле такой записи предназначено для информации, а второе – для ссылки на следующий элемент этой же структуры. Вот как упомянутая структура может быть объявлена в разделе описания типов:
type
p=^item;
item=record
data:integer;
reference:p
end;
Как эту структуру представить графически, демонстрирует рис.2.

Рис.2. Простейшая структура данных с внутренними ссылками (здесь Item - элемент; Data - данные: Reference - ссылка)
Мы уже знаем, что при описании указателя на запись, одно из полей которого ссылается на этот указатель, первым должно следовать описание указателя (в нашем случае Р). Запись объявленного нами типа Item состоит из полей Data и Reference. Первое поле предназначено для данных, а второе – для указателя, ссылающегося на следующую запись типа Item.
На рис.2 изображена цепочка элементов нашей структуры с внутренними ссылками. Каждый элемент здесь – это запись, принадлежащая типу Item. Кстати, указатель, содержащийся в поле Reference каждого элемента, ссылается не на одно из полей следующего элемента структуры (как это можно понять по изображению), а на элемент (запись) в целом. Структура, о которой идет речь, называется связным списком.
Нетрудно прийти к выводу, что связный список с точки зрения экономии памяти – не самый удачный метод организации данных, поскольку каждый элемент списка, помимо байтов памяти для информации, нуждается в памяти для указателя, ссылающегося на следующий элемент списка. Однако при большем расходе памяти списки обеспечивают и большую гибкость. Действительно, если аналогичные данные организовать в виде массива, для того чтобы включить в структуру новый элемент или исключить один из элементов, потребуется преобразовывать весь массив. В то же время для того чтобы добавить в список новый элемент, достаточно сделать так, чтобы указатель предыдущего элемента ссылался на новый элемент, а указатель нового элемента – на следующий элемент списка. Аналогично, при исключении одного из элементов списка достаточно только изменить значение указателя предыдущего элемента так, чтобы он указывал на элемент, следующий за исключаемым. Как это выглядит на практике, демонстрирует рис.3.
Существует несколько разновидностей связного списка, о котором шла речь выше.
• Кольцевой список. В этом списке указатель последнего элемента ссылается на первый.
• Очередь. Эта разновидность связного списка допускает только добавление нового элемента в конец очереди и исключение элемента в начале очереди.
• Стек. Для этой разновидности связного списка можно только добавлять или исключать элементы с одного его конца.
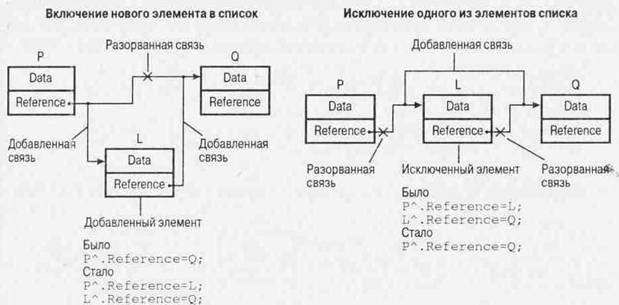
Рис.3. Включение и исключение элемента списка
Помимо линейных связных списков существуют иерархические структуры произвольной конфигурации, известные как деревья. Как может выглядеть такое дерево, позволяет судить рис.4.
Здесь изображено дерево, каждый элемент (или узел) которого содержит два поля-указателя. Поскольку каждый из этих указателей может иметь значение NIL, у каждого из узлов может быть ни одного, один или два последующих узла. При этом число полей-указателей в узле двоичного дерева явно не ограничивается. Чем больше таких полей, тем потенциально "разветвленной" может быть дерево.
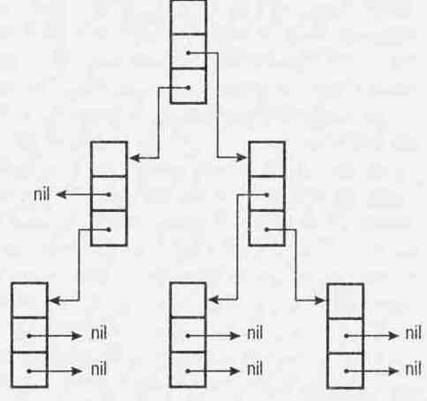
Рис.4. Иерархическое дерево
2.5. Процедуры и функции для работы с динамической
памятью
Приведем краткие сведения о процедурах и функциях. которые могут пригодиться при использовании динамической памяти.
2.5.1. Функция Addr. Возвращает адрес переменной, процедуры или функции, указанной в качестве параметра. Заголовок функции:
Function Addr(x) : Pointer;
Здесь X – идентификатор переменной, процедуры или функции. Функция возвращает нетипизированный указатель, ссылающийся на X. Поскольку он принадлежит типу Pointer, результат, возвращаемый функцией Addr, совместим со всеми типами указателей.
Вот пример программы, в которой используется функция Addr:
program PAddr;
type
b=char;
var
vb:b;
pvb:Pointer;
begin
pvb:=addr(vb);
if pvb=addr(vb) then WriteLn('равно')
else Write ('не равно')
end.
Вместо функции Addr возможно использование оператора @. Так, вместо оператора pvb:=addr(vb) в программе выше можно использовать его эквивалент pvb:=@vb.
2.5.2. Процедура Dispose. Освобождает место, занятое в памяти динамической переменной, на которую ссылается типизированный указатель. Вот как выглядит заголовок этой процедуры:
Procedure Dispose(Var P : Pointer[, Destructor ]);
где P – типизированный указатель.
Возможности процедуры Dispose были расширены, и теперь она может также освобождать память, занятую объектом, если деструктор этого объекта указать в качестве второго параметра процедуры. Например:
Dispose(P, Done);
После обращения к процедуре Dispose, значение указателя Р становится неопределенным. Поэтому повторное обращение к этой процедуре с Р в качестве параметра приведет к ошибке периода исполнения.
2.5.3. Процедура FreeMem. Освобождает память, занятую динамической переменной данного размера, зарезервированную за нетипизированным указателем (с помощью процедуры GetMem). Вот как выглядит заголовок этой процедуры:
Procedure FreeMem(Var p : Pointer; Size : Word);
Здесь Р – нетипизированный указатель, для которого раньше была выделена память (процедурой GetMem);
Size – выражение, определяющее размер освобождаемой динамической переменной в байтах. Это значение должно совпадать с числом байтов, выделенных для этой переменной процедурой GetMem.
Процедура FreeMem ликвидирует переменную, на которую ссылается указатель Р, и освобождает память, занимаемую этой переменной. После обращения к FreeMem значение указателя Р становится неопределенным и при повторном обращении к FreeMem имеет место ошибка времени исполнения. Ошибка также будет иметь место при попытке сослаться на P^.
2.5.4. Процедура GetMem. Создает динамическую переменную определенного размера, на которую ссылается нетипизированный указатель. Вот как выглядит заголовок этой процедуры:
Procedure GetMem (Var Р : Pointer; Size : Word);
Самый большой блок, который может быть зарезервирован за один раз, равенбайт. Если в куче для размещения динамической переменной недостаточно свободного пространства, имеет место ошибка времени исполнения.
Вот пример программы (собственно, это только схема программы), в которой используются процедуры FreeMem и GetMem, а также функция SizeOf:
program GetFreeMem;
type
ar=array[1..10] of integer;
var
P : Pointer;
begin
GetMem(p, SizeOf(ar)); {Выделение памяти}
{...}
{Использование памяти}
{ ...}
FreeMem(P, SizeOf(ar)); {Освобождение памяти}
end.
Использованная здесь функция SizeOf возвращает число байтов, занимаемых объектом, указанным в качестве параметра функции.
2.5.5. Процедура Mark. Присваивает динамической переменной, на которую ссылается указатель-аргумент процедуры, текущий адрес начала свободного участка динамической памяти. Вот как выглядит заголовок этой процедуры:
Procedure Mark(Var p : Pointer);
где Р – нетипизированный указатель.
Процедура Mark часто используется совместно с процедурой Release и не должна использоваться с процедурой FreeMem или Dispose.
2.5.6. Функция MaxAvail. Возвращает размер самого большого непрерывного свободного участка в куче. Возвращаемый функцией результат представляет собой значение, принадлежащее типу LongInt. Заголовок функции:
Function MaxAvail : Longint;
2.5.7. Функция MemAvail. Возвращает количество всей свободной памяти в куче. Свободная память обычно представляет собой не единый блок, а множество разрозненных участков, что объясняется фрагментацией кучи. Возвращаемый функцией результат представляет собой значение типа Longint. Заголовок функции:
Function MemAvail : Longint;
Программа, в которой используются функции MemAvail и MaxAvail, a также функция SizeOf, содержится в примере 2.
Пример 2
program Mem_Max_Avail;
type
ar=array[1..10] of integer;
var
p : Pointer;
begin
writeln('Свободная память= ', memavail,
'; наибольший участок= ', maxavail);
GetMem(p, SizeOf(ar));
writeln('Свободная память= ', memavail,
'; наибольший участок= ', maxavail);
end.
Здесь на экран выводятся сведения об общем объеме свободной динамической памяти и наибольшем свободном участке. Соответствующие значения возвращаются функциями MemAvail и MaxAvail до и после выделения памяти (процедурой GetMem). Можно поэкспериментировать – попробовать изменять количество элементов в массиве AR (ar=array[ ] of integer) или тип элементов (Integer на иной), чтобы выяснить, как это влияет на объем свободной памяти.
Использованная здесь функция SizeOf возвращает число байтов занимаемых, объектом, указанным в качестве параметра функции.
2.5.8. Процедура New. Создает новую динамическую переменную, на которую ссылается типизированный указатель. Вот как выглядит заголовок этой процедуры:
Procedure New(Var P : Pointer [, Init : Constructor ]);
где P – типизированный указатель.
Возможности процедуры New были расширены, и теперь она также может резервировать память для объекта, если конструктор этого объекта указать в качестве второго параметра процедуры. Например:
New(p, Init(420, 252));
где Init(420, 252) – метод-конструктор, задающий для объекта некоторые начальные значения (т. е. выполняющий его инициализацию).
Процедура New может также вызываться как функция, возвращающая значение указателя. При этом параметр функции представляет собой не указатель, а тип указателя на объект. Например:
type
Pchar=^char; {объявление типа указателя}
var
p:PChar; {объявление указателя}
begin
p:=New(PChar);{вызов New как функции}
…
end.
При использовании New в виде функции, как и при традиционном использовании этой процедуры, можно указывать второй параметр, представляющий собой конструктор объектного типа.
Программа, в которой используются процедуры New и Dispose, a также функция MemAvail, содержится в примере 3.
Пример 3
Program New_Disp;
type
ar = array[1..10] of integer;
var
P : ^ar;
begin
writeln;
writeln('Свободно (до выделения памяти) ', memavail,' байт');
New(p);
writeln('Свободно (после выделения памяти) ', memavail,
'байт');
Dispose(p);
writeln('Свободно (после освобождения памяти) ', memavail,
'байт');
end.
Здесь на экран выводятся сведения об общем объеме свободной динамической памяти, возвращаемые функцией MemAvail до и после выделения памяти (процедурой New), а также после освобождения памяти (процедурой Dispose).
2.5.9. Процедура Release. Освобождает часть кучи. Заголовок процедуры:
Procedure Release(Var p : Pointer);
где P – указатель любого типа, ранее определенный процедурой Mark.
При обращении к процедуре Release освобождается часть кучи от адреса, на который указывает Р, до конца кучи.
Программа, в которой используются процедуры Mark, Release, New, a также функция MemAvail, содержится в примере 4.
Пример 4
program MarkRelease;
var
p1, p2 : ^Real;
p3, p4 : ^Integer;
begin
WriteLn;
WriteLn('Свободно (до выделения памяти) ',
MemAvail,' байт');
New(p1); {Выделяем память для р1}
New(p2); {Выделяем память для p2}
Mark(p2);{Сохраняем состояние кучи}
WriteLn('Свободно (после первого выделения памяти)',
MemAvail,' байт');
New(p3); {Выделяем память для р3}
New(p4); {Выделяем память для р4}
WriteLn('Свободно (после второго выделения памяти)',
MemAvail,' байт');
Release(p2);
WriteLn('Свободно (после освобождения памяти) ',
MemAvail,' байт');
End.
В этой программе сначала выделяется память для двух переменных типа Real, затем запоминается текущий адрес начала свободного участка динамической памяти (с помощью процедуры Mark), после этого снова выделяется память – на этот раз для двух переменных типа Integer, наконец память освобождается (с помощью процедуры Release) от адреса, запомненного с помощью процедуры Mark, и до конца кучи. Во всех ключевых точках программы на экран выводится информация о количестве свободной динамической памяти. Программа демонстрирует, что память, занятая переменными Р3 и Р4 при этом освобождается, а переменные Р1 и P2 по-прежнему могут использоваться.
2.5.10. Функция SizeOf. Возвращает число байтов, занимаемых объектом, указанным в качестве параметра функции. Заголовок функции:
Function SizeOf(x) ; Integer;
где Х – идентификатор типа или переменной.
Например, выражение SizeOf (Integer) имеет значение 2. Это же значение имеет выражение SizeOf (х), если Х – переменная (но не выражение) типа Integer.
2.6. Работа с обширным массивом
Сейчас самое подходящее время вернуться к массиву, с которым мы пытались работать в начале. Помните, массив, содержащий 15 тысяч элементов типа Longint, мы смогли обработать, а 20 тысяч – уже нет? Поскольку максимальная размерность для структурированных типов составляет всегобайт, а объем динамической памяти (или кучи) приблизительно байт, почему бы не воспользоваться этой памятью для обработки обширных массивов? Однако и при использовании динамической памяти сохраняется ограничение на максимальную размерность для структурированных типов байт). Поэтому не удастся, выделив предварительно динамическую память (с помощью процедуры NEW), просто объявить наш массив в разделе описания переменных. Однако, для того чтобы преодолеть барьер вбайт, можно создать массив из 9 элементов, представляющих собой нетипизированые указатели на участки в памяти (или на блоки). При этом каждый из таких блоков предназначен для 8 000 элементов типа Longint. (Другими словами, мы попытаемся работать с массивом из 72 тысяч элементов – это приблизительно соответствует возможностям динамической памяти.) Почему для ссылок на участки памяти, в которых будут храниться блоки (по 8 000 элементов) нашего обширного массива, используются именно нетипизированные указатели? Дело в том, что для резервирования памяти под динамическую переменную, на которую ссылается нетипизированный указатель, используется процедура GetMem. А эта процедура, в отличие от процедуры New, используемой для типизированных указателей, имеет параметр, позволяющий указать объем резервируемой памяти. Иными словами, данный прием позволяет определить указатель на первый элемент блока из 8 000 элементов и одновременно зарезервировать память для остальных 7 999 элементов блока.
Как может выглядеть соответствующая программа, демонстрирует пример 5.
Пример 5
program array2;
const number=8000; {число элементов в одном блоке}
type
ab=array[0..0] of longint;
pab=^ab;
var
ch:array[0..8] of pointer;
total, i:longint;
begin
total:=number*9; {число элементов в 9-ти блоках}
writeln('Свободная память=',memavail,
';наибольший участок= ', maxavail);
for i:=0 to 8 do
getmem(ch[i], number*sizeof(longint)); {резервир. памяти}
for i:=0 to total-1 do
pab(ch[i div number])^[i mod number]:=i; {Присвоение
порядкового номера}
for i:=0 to total-1 do
if (i mod 1000=0) or (i=total) then
write(i:10, pab(ch[i div number])^[i mod number]:6);
writeln;
writeln('Свободная память= '.memavail,
'; наибольший участок= ', maxavail);
readln
End.
Здесь константа Number задает количество элементов в блоке. Переменная CH (ch:array[0. .8] of pointer) описывает массив нетипизированных указателей на первые элементы в каждом блоке. Переменная Total содержит общее число элементов во всех блоках (total:=number*9).
До начала выделения динамической памяти и после (в конце программы) на экран выводятся значения общего свободного пространства кучи и ее наибольшего непрерывного свободного участка (функции MemAvail и MaxAvail соответственно). Наконец, для обрабатываемого нами массива выделяется динамическая память:
for i:=0 to 8 do getmem(ch[i], number*sizeof(longint))
Здесь значение переменной I соответствует номеру очередного блока, под который выделяется память. Процедура GetMem (резервирующая за нетипизированным указателем фрагмент динамической памяти) имеет два параметра. Первый из них (ch[i]) – нетипизированный указатель, ссылающийся на область в динамической памяти, предназначенную для первого элемента блока. Второй элемент процедуры (number*SizeOf (longint)) определяет размер динамической переменной в байтах. В нашем случае Number – это число элементов в блокеФункция SizeOf возвращает длину внутреннего представления указанного объекта (для типа Longint – 4 байта). Теперь можно вычислить, сколько всего байт памяти резервируется – 9 блоков умножить на 8 000 элементов в блоке, умножить на 4 байта для каждого элемента – итого 288 тыс. байт. Именно такой должна быть разница между значениями, возвращаемыми функцией MemAvail вначале и в конце программы.
Далее программа заносит некоторые значения (собственно, значение параметра цикла) по адресам памяти, выделенным для каждого из элементов нашего обширного массива:
for i:=0 to total–1 do
pab(ch[i div number ])^[i mod number]:=i
Этот оператор, собственно вторая его половина, требует более пристального внимания. С первой половиной все ясно – оператор цикла с параметром for i:=0 to total–1 do организует обращение к каждому из элементов, содержащихся в девяти блоках, созданных нами в динамической памяти. Но каким образом совершается само обращение? Для того чтобы это понять лучше, взглянем на рис.5.
Очевидно, что в строке программы, представленной на рис.5, выражение i div number определяет номер блока, а выражение i mod number – номер каждого элемента в блоке. (Результат операции деления DIV – целое число без остатка. Результат операции MOD – остаток от деления двух целых чисел.) Вспомним, что СН – это массив из девяти указателей на первые элементы блоков, поэтому выражение ch[i div number] представляет собой обращение к первым элементам девяти блоков.
Но каким образом можно обратиться к каждому элементу в каждом блоке? Для этого массив СН (массив нетипизированных указателей) приводится к типу Pab (pab(ch[i div number]). Мы помним, что Pab – это указатель на массив элементов Longint. Затем этот указатель разыменуется (т. е. преобразуется в обращение к самому массиву) и к выражению, представляющему идентификатор массива (pab(ch[i div number]^), добавляется индекс ([i mod number]). Таким образом, выражение pab(ch[i div number])^[i mod number] обеспечивает обращение к каждому из элементов массива из×9) элементов Longint.
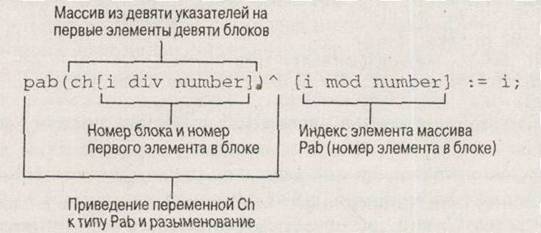
Рис.5. Обращение к каждому из элементов обширного массива
Затем на экран выводятся значения каждого тысячного, а также последнего элементов нашего массива:
for i:=1 to total do
if (i mod 1000=0) or (i=total–1) then
write(i:10, pab(ch[i div number])^[i mod number]:6);
Причем, как и в программе из начала главы, значение каждого элемента выводится (для контроля) в паре со значением параметра цикла I – эти значения должны совпадать.
Наконец, снова на экран выводится информация об общем свободном пространстве кучи и ее наибольшем непрерывном свободном участке (функции MemAvail и MaxAvail соответственно).
Последний оператор программы (функция ReadLn) присутствует здесь для того, чтобы приостановить работу программы и предоставить возможность спокойно рассмотреть экран вывода. Теперь, чтобы завершить программу, достаточно нажать клавишу <Enter>. Используя только статическую память, мы смогли обработать массив всего изэлементов Longint, однако, воспользовавшись динамической памятью, нам удалось справиться с массивом, включающимтаких же элементов.
Обратите внимание, что в программе Аrrау2 динамическая память выделяется (с помощью процедуры GetMem), однако затем не освобождается. Не противоречит ли это тому, о чем шла речь ранее (что зарезервированную ранее динамическую память всегда непременно следует освобождать)?
Дело в том, что освобождение памяти – не самоцель. Память следует освобождать тогда, когда ее затем требуется использовать для других переменных. В нашем случае в момент, когда динамическую память можно было бы освободить, программа уже завершается. Иными словами, бессмысленно освобождать память, которую затем не предполагается использовать. А при повторном запуске программы Аrrау2 экран вывода засвидетельствует, что динамическая память снова имеет исходный объем – байта. Для того чтобы убедиться в этом, достаточно еще раз запустить программу.
3. ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ
Для выполнения работы необходимо:
1. Повторить правила техники безопасности при работе с вычислительной техникой.
2. Изучить раздел "Динамическая память и указатели" лекционного курса, а также теоретическую часть настоящих методических указаний.
3. Получить у преподавателя вариант задания (варианты заданий приведены в разделе 6 настоящих методических указаний).
4. Написать программу на Турбо Паскале (при необходимости используя предварительно разработанный алгоритм).
5. Ввести программу в компьютер, отладить и результаты выполнения показать преподавателю.
6. В соответствии с требованиями, приведенными в разделе 4, оформить отчет по лабораторной работе.
7. Защитить лабораторную работу, продемонстрировав преподавателю:
отчет по лабораторной работе;
умение решать аналогичные задачи;
теоретические знания.
При подготовке к защите для самопроверки рекомендуется ответить на контрольные вопросы, приведенные в разделе 5.
4. ТРЕБОВАНИЯ К ОТЧЕТУ
Отчет по выполненной лабораторной работе должен содержать:
титульный лист;
условие задания;
текст программы на языке Турбо Паскаль.
5. КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Что такое указатели?
2. Каким образом выделяется и освобождается динамическая память?
3. Какие возможны действия над указателями и динамическими переменными?
4. Что такое динамические данные без внутренних ссылок?
5. Что такое динамические данные с внутренними ссылками?
6. Каковы процедуры для работы с динамической памятью?
7. Каковы функции для работы с динамической памятью?
6. ВАРИАНТЫ ЗАДАНИЙ
Вариант 1
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая по списку L строит два новых списка: L1 – из положительных элементов и L2 – из остальных элементов списка L.
2. Используя очередь, за один просмотр файла f и без использования дополнительных файлов, напечатать элементы файла f в следующем порядке: сначала – все числа, меньше a, затем – все числа из отрезка [a,b], и наконец – все остальные числа, сохраняя исходный взаимный порядок в каждой из этих трех групп чисел (a и b – заданные числа, a<b).
3. Используя стек напечатать содержимое текстового файла t, выписывая литеры каждой его строки в обратном порядке.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая присваивает параметру E элемент из самого левого листа непустого дерева T (лист – вершина, из которой не выходит ни одной ветви).
Вариант 2
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу удаления из списка L одного элемента, следующего за элементом E, если такой есть и он отличен от E.
2. Используя очередь, содержимое текстового файла f, разделенное на строки, переписать в текстовый файл g, перенося при этом в конец каждой строки все входящие в нее цифры (с сохранением исходного взаимного порядка как среди цифр, так и среди остальных литер строки).
3. Постфиксной формой записи выражения aΔb называется запись, в которой знак операции размещен за операндами: abΔ. Примеры:
a–b → ab–
a*b+c → ab*c+ (т. е. (ab*)c+)
a*(b+c) → abc+* (т. е. a(bc+)*)
a+b2c2d*e → abc2d2e*+
Написать программу, которая вычисляет как целое число значение выражения (без переменных), записанное в постфиксной форме в текстовом файле postfix.
Использовать следующий алгоритм вычисления. Выражение просматривается слева направо. Если встречается операнд (число), то его значение (как целое) заносится в стек, а если встречается знак операции, то из стека извлекаются два последних элемента (это операнды данной операции), над ними выполняется операция, и ее результат записывается в стек. В конце концов в стеке останется только одно число – значение всего выражения.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая определяет число вхождений элемента E в дерево T.
Вариант 3
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу добавления новых элементов E1 и E2 в список L перед его последним элементом.
2. Используем очередь.
type name=(Anna, …,Zeta);
child=packed array[name, name] of Boolean
next=file of name;
Считая заданными имя N и массив C типа child (C[x,y]=true, если человек по имени y является ребенком человека по имени x), записать в файл NE типа next имена всех потомков человека с именем N в следующем порядке: сначала – имена всех его детей, затем – всех его внуков, затем – всех правнуков и т. д.
3. Постфиксной формой записи выражения aΔb называется запись, в которой знак операции размещен за операндами: abΔ. Примеры:
a–b → ab–
a*b+c → ab*c+ (т. е. (ab*)c+)
a*(b+c) → abc+* (т. е. a(bc+)*)
a+b2c2d*e → abc2d2e*+
Написать программу, которая переводит выражение, записанное в обычной (инфиксной) форме в текстовом файле infix, в постфиксную форму и в таком виде записывает его в текстовый файл postfix.
Использовать следующий алгоритм перевода. В стек записывается открывающая скобка, и выражение просматривается слева направо. Если встречается операнд (число или переменная), то он сразу переносится в файл postfix. Если встречается открывающая скобка, то она заносится в стек, а если встречается закрывающая скобка, то из стека извлекаются находящиеся там знаки операций до ближайшей открывающей скобки, которая также удаляется из стека, и все эти знаки (в порядке их извлечения) записываются в файл postfix. Когда же встречается знак операции, то из конца стека извлекаются (до ближайшей скобки, которая сохраняется в стеке) знаки операций, старшинство которых больше или равно старшинству данной операции, и они записываются в файл postfix, после чего рассматриваемый знак заносится в стек. В заключение выполняются такие же действия, как если бы встретилась закрывающая скобка.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая заменяет в дереве T все отрицательные элементы на их абсолютные величины.
Вариант 4
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая проверяет на равенство списки L1 и L2.
2. Используя очередь, решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется для каждой пары соответствующих открывающей и закрывающей скобок напечатать номера их позиций в тексте, упорядочив пары номеров в порядке возрастания номеров позиций закрывающих скобок. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
8 10; 12 16; 3 17.
3. Постфиксной формой записи выражения aΔb называется запись, в которой знак операции размещен за операндами: abΔ. Примеры:
a–b → ab–
a*b+c → ab*c+ (т. е. (ab*)c+)
a*(b+c) → abc+* (т. е. a(bc+)*)
a+b2c2d*e → abc2d2e*+
Написать программу, которая печатает в обычной (инфиксной) форме выражение, записанное в постфиксной форме в текстовом файле postfix. (Лишние скобки желательно не печатать).
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая вычисляет среднее арифметическое всех элементов непустого дерева T.
Вариант 5
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая переносит в конец непустого списка L его первый элемент.
2. Используя очередь, решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется для каждой пары соответствующих открывающей и закрывающей скобок напечатать номера их позиций в тексте, упорядочив пары номеров в порядке возрастания номеров позиций открывающих скобок. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
3 17; 8 10;
3. Написать программу с использованием указателя на одномерный массив для работы с двумерным массивом. Для этого:
сформировать динамический массив записей из исходных данных, расположенных в текстовом файле;
для формирования использовать процедуру с параметром-переменной типа указателя на массив; функцию, возвращающую указатель на массив;
ввести из файла и вывести исходные данные;
для удаления пробелов в начале и в конце введенной строки использовать функцию с параметром;
обработать данные динамического массива с помощью процедур: с параметром – динамическим массивом – для поиска сведений и о студенте по его фамилии; без параметров – для поиска сведений о студентах по размеру стипендии не менее заданного.
Исходные данные для создания массива записей и поисков вводятся из файлов.
Сведения о студентах содержат: номер зачетной книжки, группу, фамилию и инициалы, размер стипендии.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, меняет местами максимальный и минимальный элементы непустого дерева T, все элементы которого различны.
Вариант 6
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая переворачивает список L, т. е. изменяет ссылки в этом списке так, чтобы его элементы оказались расположенными в обратном порядке.
2. Используя очередь, решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется напечатать в порядке возрастания номера позиций в тексте закрывающих скобок. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
10
3. Написать программу с использованием указателя на одномерный динамический массив для работы с двумерным массивом. Для этого:
сформировать динамический массив арифметических данных из исходных данных, расположенных в текстовом файле;
для формирования использовать процедуру с параметром-переменной типа указателя на массив; функцию, возвращающую указатель на массив;
ввести из файла и вывести исходные данные;
поменять местами максимальный и минимальный элементы массива с помощью процедуры с параметрами.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая печатает элементы всех листьев дерева T.
Вариант 7
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая заменяет в списке L все вхождения элемента E1 на элемент E2.
2. Используя очередь, решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется напечатать в порядке возрастания номеров позиций в тексте открывающих скобок. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
3. Написать программу с использованием указателя на двумерный динамический массив. Для этого:
сформировать динамический массив арифметических данных из исходных данных, расположенных в текстовом файле;
для формирования использовать процедуру с параметром-переменной типа указателя на массив; функцию, возвращающую указатель на массив;
ввести из файла и вывести исходные данные;
найти максимальный и минимальный элементы массива с помощью процедуры с параметрами.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая определяет, есть ли в дереве T хотя бы два одинаковых элемента.
Вариант 8
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая оставляет в списке L только первые вхождения одинаковых элементов.
2. Используя очередь, решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется напечатать в порядке убывания номеров позиций в тексте открывающих скобок. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
12 8 3.
3. Написать программу с использованием указателя на одномерный массив для работы с двумерным массивом. Для этого:
сформировать динамический массив записей из исходных данных, расположенных в текстовом файле;
для формирования использовать процедуру с параметром-переменной типа указателя на массив; функцию, возвращающую указатель на массив;
ввести из файла и вывести исходные данные;
для удаления пробелов в начале и в конце введенной строки использовать функцию с параметром;
обработать данные динамического массива с помощью процедур: с параметром – динамическим массивом – для поиска сведений и о студенте по его фамилии; без параметров – для поиска сведений о студентах по наименованию группы.
Исходные данные для создания массива записей и поисков вводятся из файлов.
Сведения о студентах содержат: номер зачетной книжки, группу, фамилию и инициалы, размер стипендии.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая строит копию дерева T.
Вариант 9
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая определяет, входит ли список L1 в список L2.
2. Используя очередь решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется напечатать в порядке убывания номеров позиций в тексте закрывающих скобок. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
17
3. Разработать программу для формирования и обработки свободного массива записей со сведениями о студентах ряда групп. В качестве исходных данных использовать сведения о студентах из файла исходных данных. В файле размещены сведения о студентах различных групп вперемежку по номерам групп. Номер группы – это 6-й символ в наименовании группы. Надо ввести исходные данные. Создать из них свободный динамический массив. В каждой строке этого двумерного динамического массива разместить сведения о студентах одной из групп.
Для формирования свободного динамического массива записей использовать 2 массива на N элементов:
K – массив на N элементов с количеством студентов в 1÷N группах;
Z – массив из N указателей на массивы записей в 1÷N группах.
Программу выполнить со статическими массивами K и N.
В программе надо:
сформировать динамический массив записей из исходных данных, расположенных в текстовом файле;
ввести из файла и вывести исходные данные;
для удаления пробелов в начале и в конце введенной строки использовать функцию с параметром;
обработать данные динамического массива с помощью процедур без параметров для поиска сведений и о студенте по его фамилии и для поиска сведений о студентах по наименованию группы.
Исходные данные для создания массива записей и поисков вводятся из файлов.
Сведения о студентах содержат: номер зачетной книжки, группу, фамилию и инициалы, размер стипендии.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая находит в непустом дереве T длину (число ветвей) пути от корня до ближайшей вершины с элементом E; если E не входит в T, за ответ принять –1.
Вариант 10
1. Имеются линейные однонаправленные списки:
type
p=^item;
item=record
data:real;
reference:p
end;
Написать программу, которая находит среднее арифметическое всех элементов непустого списка L.
2. Используя очередь, решить следующую задачу. В текстовом файле t записан текст, сбалансированный по круглым скобкам. Требуется напечатать в порядке возрастания номеров позиций в тексте операнды операций вычитания. Например, для текста A+(45–F(X)*(B–C)) надо напечатать:
45 F(X) B C.
3. Разработать программу для формирования и обработки свободного массива записей со сведениями о студентах ряда групп. В качестве исходных данных использовать сведения о студентах из файла исходных данных. В файле размещены сведения о студентах различных групп вперемежку по номерам групп. Номер группы – это 6-й символ в наименовании группы. Надо ввести исходные данные. Создать из них свободный динамический массив. В каждой строке этого двумерного динамического массива разместить сведения о студентах одной из групп.
Для формирования свободного динамического массива записей использовать 2 массива на N элементов:
K – массив на N элементов с количеством студентов в 1÷N группах;
Z – массив из N указателей на массивы записей в 1÷N группах.
Программу выполнить с динамическими массивами K и N.
В программе надо:
сформировать динамический массив записей из исходных данных, расположенных в текстовом файле;
ввести из файла и вывести исходные данные;
для удаления пробелов в начале и в конце введенной строки использовать функцию с параметром;
обработать данные динамического массива с помощью процедур без параметров для поиска сведений и о студенте по его фамилии и для поиска сведений о студентах по размеру стипендии не менее заданного.
Исходные данные для создания массива записей и поисков вводятся из файлов.
Сведения о студентах содержат: номер зачетной книжки, группу, фамилию и инициалы, размер стипендии.
4. Имеются двоичные деревья:
type
tree=^item;
item=record
data:real;
right, left:tree
end;
Написать программу, которая подсчитывает число вершин на n-м уровне непустого дерева T (корень считать вершиной 0-го уровня).
СПИСОК ЛИТЕРАТУРЫ
1. Turbo Pascal: учитесь программировать. – М.: Издательский дом «Вильямс». 2001.– 448 с.
2. Основы программирования в задачах и примерах.– Харьков: Фолио. 2002.– 397 с.
3. Pascal 7.0 практическое программирование. Решение типовых задач.– М.: Кудиц-Образ, 2000.– 425 с.
