

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Теория информации и кодирования
Помехоустойчивые коды (корректирующие, избыточные).
Передача информации.
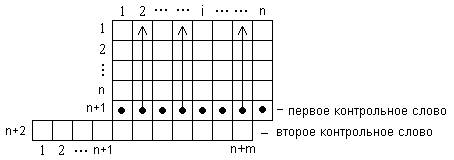
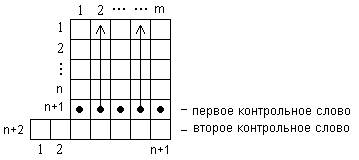
Структурная схема передачи информации от источника к приемнику через канал связи :

Информация передается в виде сообщения от источника к приемнику через канал связи. Каналы связи могут быть телефонные, радио и др. При прохождении информации через канал в нем возникают помехи, в следствие чего приемник может получить неверную информацию. Для устранения этого недостатка используются корректирующие (помехоустойчивые, избыточные) коды, которые с высокой вероятностью гарантируют получение с приемника достоверной информации.
Рассмотрим схему передачи информации справедливую для любых каналов связи. Передаваемая от источника информация может быть избыточна. Чтобы устранить этот недостаток и увеличить скорость передачи данных, используют кодирующее устройство, которое сжимает информацию с помощью оптимальных кодов. Для обнаружения или устранения ошибок, возникающих при передаче, в общей схеме находится кодер и декодер канала. Коррекция ошибок осуществляется кодером канала за счет введения избыточности, в которую кодер записывает специальные данные, позволяющие декодирующему устройству выполнить коррекцию помех. Далее декодирующее устройство при необходимости восстанавливает исходную информацию.
Теория помехоустойчивости кодирования базируется на основной теореме Шеннона.
Выводы из теоремы Шеннона:
1) При любой скорости передачи двоичных символов меньшей, чем пропускная способность
канала, существует такой код, при котором вероятность ошибочного декодирования бесконечна
мала.
2) Вероятность ошибки не может быть сколь угодно малой, если скорость передачи информации
больше пропускной способности канала.
Если через канал связи без помех передается последовательность дискретных сообщений длительностью T , то скорость передачи информации по каналу связи
(бит / сек) = lim ( I / T )
T → ∞
Скорость передачи информации в общем случае зависит от статических свойств сообщений и параметров канала связи.
Пропускная способность – максимальное количество данных, которое можно передать по каналу связи за 1 секунду.
Для достижения наибольшего эффекта, необходимо, чтобы скорость передачи информации была как можно ближе к пропускной способности канала, т. е. источник должен быть согласован с каналом. Согласование осуществляется кодированием.
Основные понятия и определения.
Код – совокупность комбинаций из определенного количества символов для представления информации. Каждая комбинация – кодовая комбинация.
Общее количество кодовых комбинаций в коде обычно меньше, чем количество всех возможных
комбинаций из данного набора символов.
![]() равномерные
равномерные
![]() Коды
Коды
неравномерные
В равномерных кодах все комбинации содержат одинаковое количество символов (разрядов).
В неравномерных кодах каждая комбинация содержит различное количество разрядов (например,
код Морзе).
В вычислительной технике применяют в основном равномерные коды.
Если в качестве кода записать последовательно двоичные числа, то такой код называется простым. Этот код не может обнаружить ни одной ошибки может, т. к. искажение любых разрядов приведет к комбинации, которая содержится в данном коде.
В вычислительной технике используют избыточные коды, т. е. в самом коде присутствует только часть комбинации из всех возможных. Эти комбинации – разрешенные, остальные – запрещенные. Если при передаче информации кодовое слово попало в запрещенную область, то фиксируется факт наличия ошибки. Очевидно, что разрешенные комбинации должны отличаться между собой не менее, чем 2-мя разрядам.
Пример : Пусть передаются числа от 0 до 7. Закодируем их следующим образом :
Десятичное число | Двоичное число |
0 1 2 3 4 5 6 7 | 0000 0011 0101 0110 1001 1010 1100 1111 |
Как видно из таблицы, искажение хотя бы одного разряда при передаче информации переводит число в область запрещенных комбинаций. Таким образом, одиночная ошибка может быть обнаружена данным кодом. Это стало возможным из-за введения 1 дополнительного, избыточного разряда при кодировании чисел. В связи с этим, можно сказать, что из n-разрядной кодовой комбинации, только m разрядов являются информационными, а остальные k = n - m - избыточными (контрольными). Поэтому из 2 n всех возможных комбинаций допустимы только 2 m, а остальные ( 2 n - 2 m ) - запрещенные.

Если кодовые разрешенные комбинации отличаются друг от друга более, чем двумя разрядами, то в этом случае имеется возможность корректировать ошибки большей кратности.
1101 позволяет обнаруживать одиночные, двоичные и троичные ошибки
0010
Обнаруживающие и корректирующие способности кода
Будем считать, что любая передаваемая кодовая комбинация Bi, i = 1,2,…,N вследствие действия помех может перейти в другую кодовую комбинацию Bj, j = 1,2,…,N0
![]()
![]() B1 B1
B1 B1
B2 B2
. .
![]() . .
. .
![]()
![]() . .
. .
BN BN0
Общее количество переходов из разрешенной области (от источника) к приемнику Q = N * N. Среди этих переходов можно выделить 3 варианта перехода :
Без искажений (количество таких переходов N = 2 m) Каждая разрешенная комбинация может перейти в другие разрешенные N*(N-1) = 2 m (2 m -1).Эти ошибки не могут быть обнаружены.
Разрешенные комбинации переходят в запрещенные и могут быть обнаружены. N*(N0 - N)Следовательно, обнаруживающая способность может быть определена как доля :
N*(N0 - N) / N*N0 = 1 – N/ N0 = 1 – 2 m / 2 n = 1 – 1 / 2 K
Для коррекции ошибок необходимо множество всех запрещенных комбинаций разбить на М взаимно непересекающихся подмножеств и каждому такому подмножеству поставить в однозначное соответствие 1 разрешенную комбинацию Bi. Если при передаче информации искаженное слово попало в подмножество Ni, то будет считаться, что правильное слово Bi.
Корректирующая способность равна отношению всех комбинаций, которые могут быть скорректированы ко всем, которые могут быть обнаружены :
(N0 - N) / N*(N0 - N) = 1 / N = 1 / 2 m
Рассмотрим следующий пример, который покажет каким образом можно скорректировать одиночную ошибку при передаче информационной части числа состоящего из одного разряда.
m = a1 = { 0,1 }. Введем дополнительные разряды а2 и а3
a1 | a2 | a3 | |
1 | 1 | 0 | рареш. |
0 1 1 | 1 0 1 | 0 0 1 | запрещ. |
0 | 0 | 1 | разреш. |
1 0 0 | 0 1 0 | 1 1 0 | запрещ. |
Как видно искажение одного разряда приводит к попаданию искаженного слова в запрещенную область, соответствующую данному разрешенному числу, при этом будет восстановлена своя разрешенная комбинация.
Построение кодов с учетом статистики помех
Введем понятие вектора (последовательности) ошибок.
1011010 - искаженное слово

![]() 1001110 - неискаженное слово
1001110 - неискаженное слово
0010100 - последовательность ошибок
Любое искаженное слово чисто теоретически можно представить в виде суммы по модулю 2 двух последовательностей данных - неискаженного слова и последовательности ошибок. В последовательности ошибок стоят все нули, кроме разрядов, в которых ошибка, причем неважно какая это ошибка ( с 1 на 0 или с 0 на 1 ).
Пример : Пусть код состоит из разрешенных комбинаций В1 = 001, В2 = 011, В3 = 110.
Вектор ошибок | Кодовая комбинация | Кратность ошибок Q | ||
В1 = 001 | В2 = 011 | В3 = 110 | ||
000 | 001 | 011 | 110 | 0 |
001 010 100 | 001 ( 011 ) 101 | 010 ( 001 ) 111 | 111 100 010 | 1 |
011 101 110 | 010 100 111 | 000 ( 110 ) 101 | 101 ( 011 ) 000 | 2 |
111 | ( 110 ) | 100 | ( 001 ) | 3 |
Как видно из таблицы из 21 возможной ошибки 6 не могут быть обнаружены ( они указаны в скобках ).
Если передача сообщений равновероятна, а возникающие ошибки являются независимыми, то вероятность возникновения одиночных ошибок намного выше, чем ошибок другой кратности. Эта зависимость обычно носит экспоненциальный характер. Если нет специальных указаний при построении кода, то в первую очередь код строят для обнаружения и коррекции одиночных ошибок.
Рассмотрим варианты построения подмножеств для коррекции одиночной ошибки :
1) М1 = { 000, 101 } 2) М1 = { 000, 101 } 3) М1 = { 000, 101 }
M2 = { 010, 111 } M2 = { 010} M2 = { 111 }
M3 = { 100 } M3 = { 100, 111 } M3 = { 100, 010 }
Классификация корректирующих кодов
Корректирующие коды можно разделить на 2 класса :
Блочные (блоковые) НепрерывныеПри блочном кодировании последовательность элементарных сообщений источника разбивается на отрезки и каждому отрезку ставится в соответствие определенная последовательность (блок) кодовых символов, которая называется обычно кодовой комбинацией. Множество всех кодовых комбинаций и есть блочный код. Кодирование или декодирование производится над каждой кодовой комбинацией в отдельности. Длина блока может быть постоянной или переменной, поэтому соответственно различают :
· равномерные коды
· неравномерные коды
Блочные коды бывают:
- систематические (разделимые) несистематические (неразделимые)
Систематические коды – коды, в которых разряды могут быть разделены на информационные и контрольные, причем контрольные разряды занимают одни и те же позиции в кодовых комбинациях.
Они обозначаются (n, m) , n – длина кодовой комбинации, m – информационная часть.
К несистематическим относят коды, разряды которых нельзя разделить на информационные и контрольные.
Систематические коды разделяют на :
· линейные
· нелинейные
К линейным относят такие коды, поразрядная сумма по модулю 2 (в общем случае по модулю q ) любых двух кодовых слов также является кодовым словом (разрешенным). Линейные блоковые коды часто называют групповыми. Примером нелинейного кода является код Бергера, у которого контрольные разряды представляют двоичную запись числа единиц в последовательности информационных разрядов.
Непрерывные коды характеризуются тем, что операция кодирования / декодирования производится над непрерывной информационной последовательностью без разбиения её на блоки.
Корректирующие коды можно классифицировать по характеру ошибок, на исправление которых они ориентированы. Различные коды - различные ошибки или пачки ошибок. Все рассмотренные выше коды предназначены для исправления ошибок и передачи информации. Существуют другие арифметические коды, предназначенные для контроля арифметических операций.
Основные характеристики и свойства кодов
Корректирующая способность - способность кода обнаруживать и исправлять ошибки.
К основным характеристикам относится :
1) n – длина кода
2) m – информационная часть числа
3) k – контрольные разряды
4) М – основание кода ( для двоичных : 2 )
5) N = 2 m – мощность кода ( количество разрешенных комбинаций)
6) N0 - общее количество всех комбинаций
7) Избыточность кода
8) W – вес кодовой комбинации
9) d min – минимальное кодовое расстояние
![]()
λ = k / n – избыточность
Корректирующая способность кода зависит от избыточности и от того, где стоят контрольные разряды.
Под кодовым расстоянием d между двумя комбинациями понимается количество разрядов, которыми эти две комбинации отличаются друг от друга..
n
d ( Bi , Bj ) = ∑ ( bi, k ![]() bj, k )
bj, k )
k=1
Под минимальным кодовым расстоянием d min понимается наименьшее кодовое расстояние рассматриваемое между всеми возможными парами в коде.
1) d min >= t + 1 - для обнаружения t ошибок
2) d min >= 2t + 1 - для коррекции t ошибок
3) d min >= t + s + 1 , s < t - для обнаружения t ошибок и коррекции s ошибок
Как видно корректирующая способность непосредственно связана с d min. Она обеспечивается введением избыточных контрольных разрядов, при этом очевидно, что их количество нужно выбирать минимальным. Код имеющий минимальное количество контрольных разрядов называется оптимальным.
В общем случае задача получения оптимального кода в теории кодирования не решена, существуют только оценочные выражения, по которым можно судить на сколько данный код близок к оптимальному. Эти выражения разработаны для заданных m и n и называются границами.
граница Хэмминга(d min -1 )/ 2
k >= log 2 ( 1 + ∑ c in ) , c mn = n! / m! ( n – m! )
i=1
граница Плоткинаk >= 2 ( d min -1 ) – log 2 d min
граница Вартамова-Гильберта(d min -1 )/ 2
k >= log ∑ c in )
i=1
Граница Хэмминга близка к оптимальной границе для кодов с большим m / n ( m / n >= 1 / 2 ) , т. е. для высокоскоростных кодов, а граница Плоткина для низкоскоростных ( m / n <= 1 / 3)
Граница Вартамова-Гильберта указывает на существование линейного облачного кода с кодовым расстоянием не менее d min и с числом контрольных разрядов не превышающим n – m.
Таким образом, границы 1 и 2 являются необходимым условием существования кода, а 3 – достаточным. Равенство в выражении 3 справедливо для совершенных кодов. Эти коды исправляют все ошибки кратности <= ( d min - 1) / 2 и не исправляют ни одной ошибки большей кратности.
Код Хэмминга – совершенный код.
Блочные линейные коды
Самым простейшим кодом является код с простым повторением. В этом случае кодовая комбинация повторяется n раз и правильность разряда определяется методом голосования. Такой код имеет большую избыточность.
Следующим кодом, относящимся к простейшим, является код с проверкой на четность (нечетность). В этом случае к информационному слову добавляется 1 контрольный разряд, куда дописывается дополнение до четности. При декодировании проверяется четность принятого слова. Данный код имеет низкую корректирующую способность и может только обнаруживать ошибки нечетной кратности.
Код Хэмминга наиболее эффективен для коррекции одиночной (d min = 3) ошибки и коррекции одиночной и обнаружения двоичной ( d min = 4 ) При кодировании информации часть числа разбивается на подмножества и в соответствии !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
При декодировании производится аналогичная проверка четности по подмножествам, а также проверяется четность всего слова в целом.
Циклические коды
Циклические коды широко используются устройствах вычислительной техники и особенно при передаче цифро - аналоговой информации. В этом случае информация часто передается в последовательном коде.
Основное свойство циклических кодов заключается в том, что любое n – разрядное кодовое слово ( разрешенное ) A = a n -1 a n -2 ……. a 1 a 0 будучи циклически сдвинутым на один разряд влево
B = a n -2 ……. a 1 a 0 a n -1 будет принадлежать тому же самому коду.
Для удобства описания свойств циклических кодов принято представлять n – разрядные двоичные числа в полиномов n – 1 степени по переменной x.
Пример :
A = B = 1101111 - впереди идущие нули не пишутся
P ( A ) = x7 + x5 + x 4+ x2 + x + 1
P ( A ) = 1* x7 +0* x6 +1* x 5+ 1* x 4+ 0* x3 +1*x2 +1* x + 1 , x0 = 1
P ( B ) = = x6 + x5 + x 3+ x2 + x + 1
Действия над полиномами производятся по законам обычной алгебры, но операция сложения производится по модулю 2.
Суть контроля циклическими кодами заключается в том, что в качестве разрешенных (кодовых) комбинаций выбираются те, полиномы которых F(x) делятся без остатка на порождающий полином
P ( x ) . Полином F*(x) , содержащий ошибку, не разделится
F(x) = G(x) x k ![]() R(x) , k – наивысшая степень порождающего полинома
R(x) , k – наивысшая степень порождающего полинома
G(x) – информационная часть
R(x) – остаток от деления
Q(x) * P(x) + R(x) = G(x) * x k
Q(x) * P(x) = G(x) * x k + R(x)
G(x) * x k + R(x) = F(x)
Пример : Закодируем A = 1010010 , выберем полином P(x) = x3 + x +1
F(x) = G(x) * x k + R(x)
G(x) = x6 + x4 + x
G(x) * x k = x9 + x7 + x4
 |
 x9 + x7 + x4 x3 + x +1
x9 + x7 + x4 x3 + x +1
x9 + x7 + x6 x6 + x3 +1

x6 + x4
x6 + x4 + x3
 F(x) = x9 + x7 + x4 + x + 1
F(x) = x9 + x7 + x4 + x + 1
x3
F(x) | информ. | контр. |
1010010 | 011 |
x3 + x +1
x + 1
Покажем операцию деления и нахождения остатка R (x) в двоичном виде. При делении последовательно к старшим разрядам информационной части добавляется число, соответствующее порождающему полиному
Информационная часть | Контрольная часть |
_ 1010010 1011 __ _ 1010 1011 _ 1 1 0 | 000 000 011 011 ß x + 1 |
f (x) = x3 + x + 1
![]()
![]() P2 K узел анализа
P2 K узел анализа
![]()
![]()
![]()
![]()
![]() переключатеь 1
переключатеь 1

![]()
P2 И переключатеь 2 ![]()
![]()
![]()
![]()
ТИ
P2 И - регистр информации
P2 K - регистр контроля (делительное устройство для нахождения остатка)
ТИ - тактовые импульсы
Кодирование : Информационная часть числа по тактовым импульсам поступает на P2 И и сразу через переключатель 2 на выход. Одновременно информационная часть поступает на P2K, где выполняется деление на порождающий полином, далее этот остаток через переключатель 2 подается на выход.
Декодирование : Переданное число через переключатель 1 поступает одновременно на P2И и P2K. В P2И фиксируется только информационная часть, в P2K производится деление всего числа на порождающий полином P(x). Если в результате деления получается 0, то ошибок нет. В противном случае узел анализа определяет ошибку, возникшую при передаче,
и, если код обладает корректирующими свойствами, определяет номер ошибочного разряда.
Выбор порождающего полинома:
Вид выбранного порождающего полинома полностью определяет свойства циклических кодов. Выбор P(x) - сложная задача, т. к. именно от него зависит количество контрольных разрядов и корректирующая способность. Рассмотрим выбор P(x) на примере самой простой задачи.
Пример : Выбрать порождающий полином P(x) для кода, который должен обнаруживать одиночную ошибку в любом разряде передаваемого числа.
![]() - исходное F*(x)
- исходное F*(x)
- без ошибок F(x)
- последовательность ошибок E0(x)
F*(x) = F(x) + E0(x)
К любому числу переданному с ошибкой соответствует искаженный полином F*(x), который всегда теоретически можно представить в виде суммы по модулю 2 безошибочного полинома F(x) и полинома ошибок E0(x). Для обнаружения ошибок F*(x) всегда должен делиться с остатком на P(x), F(x) всегда делиться на P(x) вез остатка, поэтому для выполнения этого условия E0(x) всегда должен делиться на P(x) с остатком. Стремятся P(x) выбрать наименьшей степени.
E(x) = xi , i = 1,2,3 …
P(x) = x+1
Представление линейных кодов в матричном виде
Как правило, систематические линейные коды – групповые, т. к. они образуют группу, состоящую из кодовых комбинаций. Одним свойств таких кодов является то, что разрешенная комбинация может быть получена поразрядным сложением по модулю 2 двух разрешенных комбинаций. Это дает возможность представлять код в матричном виде.
Любой двоичный ( n, m ) код можно представить в виде матрицы, состоящей из n столбцов и 2m - 1 строк ( -1 , т. к. нулевую комбинацию писать не принято ). Очевидно, что такая матрица для
m = 15 будет достаточно громоздкой.
Оказывается, что среди всех комбинаций избыточных кодов часть является линейно независимыми. Линейно независимые комбинации называются базовыми ( базисными ). Именно они записываются в матрицу, а остальные получаются из них путем различных линейных операций.
Пусть разрешенная кодовая комбинация а1 а2 а3 ..… аm e1 e 2 e 3 ….. e k
![]()
![]()
информационная контрольная
ei = α i 1 α 1 + α i 2 α 2 + …. + α i m α m, где α i 1 , α i 2 , …… , α i m или 0 или 1
Базовые комбинации линейного кода удовлетворяют следующим свойствам :
1 ) Они должны быть различны и не включать нулевую комбинацию
2 ) Они должны быть линейно независимыми
3 ) Количество единиц в каждой из них должно быть не менее d min
4 ) Минимальное кодовое расстояние должно соответствовать заданному
Построенная из базовых комбинаций матрица называется порождающей ( образующей ). Она состоит из n столбцов и m строк, записывается M n x m. Порождающая матрица выглядит следующим образом :
![]()
![]() а11 а12 ..… аm e11 e12 ….. e k
а11 а12 ..… аm e11 e12 ….. e k
M n x m = а21 а22 ..… аm e21 e22 ….. e k
………………………………..
am1 аm2 ..… аm em1 em2 ….. e mk
информационная проверочная С k x m
Для информационной части матрицы базовые комбинации удобно представлять в виде единичной матрицы Em n x m
10 … 0
M n x m = 01 … 0
………
00 … 1
Если в качестве информационной части выбрана единичная матрица, то очевидно проверочная матрица С k x m должна быть построена исходя из следующих условий :
1 ) Количество единиц в матрице С k x m должно быть не меньше d min – 1
2 ) Минимальное кодовое расстояние в С k x m должно быть не менее d min – 2
Таким образом порождающая матрица имеет вид
![]()
![]() 1000 ..… 0 e11 e12 ….. e k
1000 ..… 0 e11 e12 ….. e k
M n x m = 0100 ..… 0 e21 e22 ….. e k
………………………………
0000 ..… 1 em1 em2 ….. e mk
Пример : Используя для расчета k границу Хэмминга построить порождающую матрицу для кода способного исправлять одиночную ошибку ( t = 1 ) при передаче N =16 сообщений
для N=16 m = 4 N = 2m (d min -1 )/ 2
граница Хэмминга k >= log 2 ( 1 + ∑ c in )
i=1
для обнаружения t ошибок d min >= t + 1
для исправления t ошибок d min >= 2 t + 1
У нас d min >= 2*1 +1 = 3
1
k >= log 2 ( 1 + ∑ c 1n ) , k >= log 2 ( 1 + n ) , k = 3
1
1
M 7,4 = 0или 0или и т. д.
0
0
Алгоритм образования значений контрольных разрядов кодовой комбинации по информационной части с помощью матрицы M n x m выглядит так :
e1 = e11 а1 + e21 а2 + …..+ e m1 аm
e2 = e12 а1 + e22 а2 + …..+ e m2 аm
………………………………………
ek = e1k а1 + e2k а2 + …..+ e mk аm
Гораздо удобнее проверочные уравнения выполнить с помощью матрицы, состоящей из k строк и m столбцов. Получим ее : сначала строится единичная матрица Е k, k. К ней приписывается D m, k, содержащая m столбцов и k строк, причем каждая ее строка соответствует столбцу контрольных разрядов подматрицы С k, m, порождающей матрицы, другими словами D k, m является транспонированной по отношению к С k, m.
e11 e21 ….. em1 100 ……0
H n x k = [D m, k ; Ek ] e12 e22 ….. em2 010 …….0
………………………………
e1k e2k ….. emk 000 ..… 1
С помощью этой матрицы операция кодирования осуществляется очень просто : позиции занимаемые единицами в i – ой строке подматрицы D m, k определяют те информационные разряды, которые должны участвовать в формировании контрольного разряда
Пример : Построить проверочную матрицу H кода 7,4 , порождающая матрица которого имеет вид :
![]()
![]()
![]()
![]()
![]()
![]() 10100
10100
M 7,4 = 0D 4,3 = 1101 H 7,3 = 1101010
01001
0
Для расчета контрольных разрядов при кодировании по этой матрице получают следующие контрольные соотношения
e1 = a1 + a2 + a3
e2 = a1 + a2 + a4
e3 = a1 + a3 + a4
Закодируем
a1 a2 a3 a4 e1 e2 e3
На основании матричного представления кодов можно сделать следующие выводы :
1) С помощью порождающей матрицы M m x n можно представить весь набор кодовых комбинаций в удобной и компактной форме и довольно просто провести операцию кодирования.
2) Проверочную матрицу H m x k обычно используют при построении кодирующих и декодирующих устройств, т. к. она определяет алгоритм нахождения проверочных разрядов по информационным значениям. Кроме того данная очень удобна для указания места отсечки в кодовой комбинации
Метод исправления ошибок в линейных кодах. Понятие синдрома.
Обычно при декодировании информации используются проверочные соотношения полученные по проверочной матрице H m x k. При этом вычисляется синдром (контрольное число). Синдром рассчитывается как сумма по модулю 2 принятых контрольных разрядов и контрольных разрядов, вычисленных по принятым информационным. Характерной особенностью синдрома является то, что он независим от передаваемой кодовой комбинации, а зависит только от характера ошибок.
Пример : Задана проверочная матрица H 7 x 3
S1 = e1 + e1 /
H 7,3 = S2 = e2 + e2 /
S2 = e3 + e3 /
a1 a2 a3 a4 e1 e2 e3
e1 / - контрольный разряд, вычисленный по принятым информационным
e1 / = a2 + a3 + a4
e2 / = a1 + a3 + a4
e3 / = a1 + a2 + a4
Возьмем А =
a1 a2 a3 a4 e1 e2 e3
Пришедшее число
a1 a2 a3 a4 e1 e2 e3
S1 = 1+0 = 1 0111 100
S2 = 1+1 = 0 1011 010
S3 = 0+0 = 0 S = 001
(в этом разряде ошибка)
Покажем, что синдром не зависит от вида передаваемой информации, а зависит только от возникающих ошибок. Предположим произошла ошибка в информационном разряде a1.
Составим последовательность ошибок 1
S1 = 0+0 = 0
S2 = 0+1 = 1
S3 = 0+1 = 1
Количество разрядов синдрома для обнаружения одиночной ошибки определяется следующим выражением :
2k >= n-1
2k+1 >= n
k >= Cn1
Для исправления одиночных и двоичных ошибок 2k + 1>= Cn1 + Cn2
Для всех разрядов 2k + 1>= Cn1 + Cn2 + …. + Cne
Код с простым повторением
В этом коде передаваемая информация повторяется дважды. При декодировании производится поразрядное сравнение и если получено отличие в разрядах, то фиксируется наличие ошибки.
Данный код обнаруживает все ошибки за исключением искажения в обоих одинаковых разрядах в первой и второй переданной комбинациях.
Инверсный код
Одной из разновидностей кода с простым повторением является инверсный код. В этом коде,
если передаваемая информационная часть содержит четное число единиц, то вторая комбинация передается без изменения. Если число единиц нечетное, то вторая комбинация передается с инвертированием
10
11
При декодировании считается количество единиц в первой принятой комбинации и если оно четное, то вторую комбинацию принимают без изменений, а если нет, то инвертируют. Далее как и в коде с простым повторением попарно сравнивают разряды первой и второй принятой комбинации.
В этом коде не обнаруживаются попарные ошибки 2, 4 , 6 .... кратности
Представление кода Хэмминга в матричном виде
Характерной особенностью кода Хэмминга с d min >= 3 является то, что в его проверочной матрице используются все комбинации, кроме нулевой
![]()
![]()
H 7,3 =
![]()
H 15,4 =
12 1
e1 = a15 + a14 + a12 + a11 + a9 + a7 + a5
e2 = a15 + a13 + a12 + a10 + a9 + a6 + a5
e3 = a14 + a13 + a12 + a8 + a7 + a6 + a5 a6 a5 - ошибка
e4 = a11 + a10 + a9 + a8 + a7 + a6 + a5 S = 0111 S = 1111
В данном коде Хэмминга вычисленный синдром не указывает точно номер искаженного разряда, как это было ранее. Для определения искаженного разряда необходимо как для других кодов сопоставлять значение синдрома со столбцом проверочной матрицы. Хэмминг предложил в проверочной матрице номера контрольных разрядов поставить между информационными. В этом случае полученный синдром точно укажет номер разряда.
H 15,4 =
a4 a3 a2 e3 a1 e2 e1
И кроме того, номера разрядов должны совпадать в двоичном виде с соответствующими столбцами матрицы.
A = 1101
e1 = a4 + a3 + a2
e2 = a4 + a3 + a1
e3 = a4 + a2 + a1
Закодированное число : 1100110
Ошибка в разряде a2
a4 a3 a2 e3 a1 e2 e1
S1 = 0+1 = 1
S2 = 1+1 = 0
S3 = 0+1 = 1 S = 101
Матричная запись циклических кодов
Циклический код обычно бывает представлен порождающей матрицей, состоящей из 2-х подматриц. В качестве единичной матрицы принято (хотя не обязательно) принимать транспонируемую матрицу (единицы расположены по побочной диагонали).
Проверочная матрица С k, m строится наиболее удобно следующими двумя способами :
1) Каждая строка матрицы EmТ, предварительно умноженная на xk, делится на порождающий полином P(x) и полученный остаток R(x) является строкой матрицы С k, m. Деление производится по формуле :
G (x) * xk
 → R(x)
→ R(x)
P(x)
Пример : Построить порождающую матрицу M(7,4) , P(x) = х3 + х +1
0
E 4Т = 0010 С 3,4 = 110
0
1
G (x) * xk 1* х3
1. = = х +1 → 011
P(x) х3 + х +1
G (x) * xk х * х3
2. = = х2 +х → 110
P(x) х3 + х +1
G (x) * xk х2 * х3
3. = = х3 + х +1 → 111
P(x) х3 + х +1
G (x) * xk х3 * х3
4. = = х2 +1 → 101
P(x) х3 + х +1
Проверочную матрицу С k, m можно построить по другому. Для этого!!!!!!!!!!!!!!!!
при этом получающиеся !!!!!!!!!!!!!!!! ,то последующая строка матрицы С k, m получается путем циклического сдвига влево на 1 разряд предыдущей строки. Этот сдвиг продолжается до тех пор пока степень остатка не станет равной n-m-1
1
![]()
![]() 1011
1011
![]() 011
011
1100 С k, m = 110
1
![]() 1
1
 1011
1011
101
Итеративные коды
В самых простейших кодах проверки на четность!!!!!!!. Эти коды в основном применяются для обнаружения и коррекции пачек (пакетов) ошибок, возникающих при передаче информации на жестких и гибких магнитных дисках и магнитных лентах.
Коды, контрольные разряды которых вычислены по информационным, расположенным по разным координатам, называются итеративными. По каждой координате производится проверка с помощью какой-либо линейной операции. Наиболее часто это проверка на четность. Итеративные коды могут быть блочными, либо непрерывными.
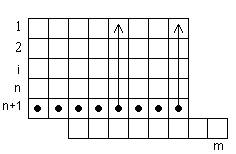
1) Блочный итеративный код с проверкой на четность строк и столбцов.
В этом коде контрольные разряды, как правило, располагаются в крайнем правом или левом столбцах, нижней строке.
 а11 а12 …… а1i …….a1n-1 a1n
а11 а12 …… а1i …….a1n-1 a1n
а21 а22 …… а2i ….. ..a2n-1 a2n
………..………………………..
аj1 аj2 …… .. аji ……..ajn-1 ajn
………..………………………..
аl-1,1 аl-1,2 …..аl-1,i ….al-1,1n-1 al-1,n
 аl,1 аl,2 …….аl, i ……….al, n-1 al, n
аl,1 аl,2 …….аl, i ……….al, n-1 al, n
n-1
ajn = ∑ аji mod 2
i=1
l-1
аl, i = ∑ аji mod 2
i=1
l-1
al, n = ∑ ajn mod 2
j=1
Данный код может обнаруживать и корректировать одиночные ошибки, обнаруживать двоичные ошибки, обнаруживать и корректировать ошибки нечетной кратности, расположенные вдоль одной строки или столбца. При анализе ошибок очевидно также, что данный код не может обнаружить ошибки четной кратности, расположенные вдоль строки или столбца. Неоднозначно могут локализоваться в коде разряды попавшие на одну диагональ. Это может привести к размножению ошибок.
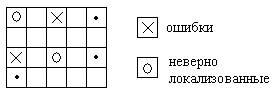
Таким образом, данный код гарантированно корректирует одиночные ошибки и обнаруживает двоичные.
2)Итеративный код с проверкой на четность слов и диагоналей.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
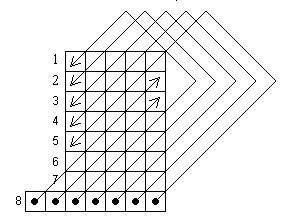
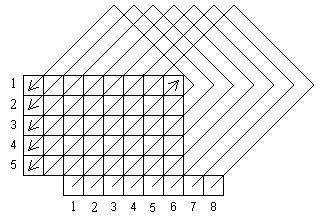
3) Непрерывный двумерный код.
.
Этот код был специально разработан для коррекции групповых ошибок, возникающих при передаче информации на магнитных лентах вдоль одной дорожки. В этом коде к m основных дорожек добавляются 2 контрольные m + 1 и m + 2 , т. е. другими словами на каждое слово.

m
am+1,k+j = ∑ аi, k+j ( mod 2 )
i=1
m+2
am+2,k+m+2 = ∑ аi, k+i ( mod 2 ) , где аi, ki - информационные разряды
i=1
Как видно из рисунка все групповые ошибки, находящиеся вдоль одной дорожки могут быть скорректированы, т. к. каждому групповому искажению будет присуще своё индивидуальное нарушение четности в m + 1 и m + 2 дорожке. В m + 1 контрольную дорожку добавляется дополнение до четности вдоль столбца, а в m + 2 разряд дополнение до четности по диагонали. Лишь часть искаженных информационных разрядов попавших внутрь треугольника, образованного первым столбцом с искаженными разрядами, диагональю, проходящей через первый контрольный разряд и контрольной дорожкой
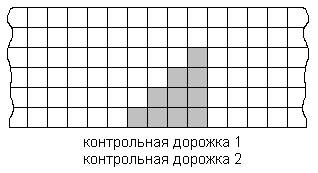
Для реализации данного способа кодирования нужна несложная аппаратура с буферной памятью.
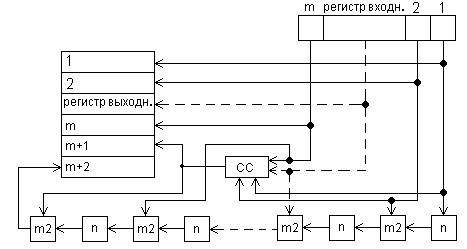
Кодирующее устройство состоит из входного регистра, схемы свертки по модулю 2 для формирования контрольных значений по столбцу ( блок СС ), схем формирования контрольных разрядов по диагонали, включающих n сумматоров по модулю 2 ( блоки m2 ), m ячеек памяти ( П ) и выходного регистра.
Подлежащая кодированию информация поступает с входного регистра на выходной, схема свертки CC формирует дополнение до четности m-разрядного слова по столбцу и результат записывает в m + 1 разряд выходного регистра. Нижняя часть схемы формирует дополнение до четности по диагонали, на первый вход сумматора m2 подается текущий разряд, например, второй, а на второй вход m2 подается разряд предыдущей строки сдвинутой на 1 разряд. Результат записывается в m + 2 выходного регистра.
4) Блочный двумерный код.
Рассмотренный выше код может применяться и для коррекции групповых ошибок в блоках слов или малых массивах. Рассмотрим схему формирования!!!!!!
Как и в предыдущем случае в первый контрольный разряд n + 1 записывается дополнение до четности по столбцу, а в n + 2 записывается дополнение до четности по диагонали.
Избыточность данного кода составляет m + m + n = 2m + n.
Этот код корректирует все групповые ошибки в слове. Но существуют комбинации ошибок, возникающие в разных словах, которые не могут корректироваться, поэтому данный код предназначен для коррекции групповых ошибок только вдоль одного слова.
Для уменьшения избыточности данного кода, при этом сохраняя корректирующую способность, возможно удлинение диагонали. Рассмотрим схемы модернизированного кода.
n > m -2
 избыточность m + n + 1 уменьшилась на
избыточность m + n + 1 уменьшилась на
2m + n – m – n – 1 = m – 1
n ≤ m -2
избыточность 2m
На последнем примере поясним правила построения диагоналей в модернизированном итеративном коде. Каждая диагональ строится таким образом, чтобы сумма числа рядов, через которые она проходит, составляла n + 2 , причем обе части диагонали должны быть параллельны друг другу и другим диагоналям и через каждое слово проходит 1 раз диагональ, которая может состоять из 2-х частей. Все диагонали в массиве строятся так, чтобы каждый разряд массива попадал на диагональ, причем на одну.
Модернизированный код позволяет увеличить скорость передачи данных.
Векторные коды
Векторные коды являются развитием кодов с контролем на четность и непрерывного двумерного кода с проверкой на четность слов и диагоналей. Эти коды имеют минимальную избыточность ( 1 разряд на слово), поэтому именно они нашли широкое применение.
1) Двухвекторный код.
Этот код простейший среди векторных кодов. В контрольный разряд кода записывается дополнение до четности по столбцу и диагонали одновременно.
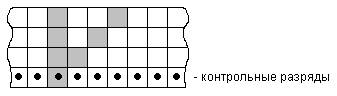
При декодировании в этом коде проверяется выполнение четности контрольных разрядов. При искажении 2-х контрольных разрядов легко локализуется одиночная ошибка. При искажении контрольного разряда нечетность будет наблюдаться в 1 разряде.
Данный код может корректировать все одиночные ошибки. Возникновение некоторых двоичных ошибок может привести к ложному исправлению верного разряда и, как следствие, к размножению ошибок. Подобные двоичные ошибки бывают расположены на одной схеме кодирования одного разряда.
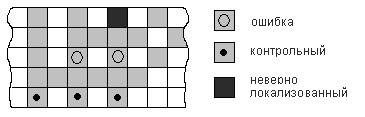
Из-за неверной локализации данные коды не имеют рапротранения на практике.
3) Основной трехвекторный код.
Данный код свободен от указанных недостатков и позволяет корректировать все одиночные и групповые ошибки и обнаруживать двоичные ошибки без их размножения.
Схема кодирования трех векторных кодов
Контрольный разряд рассчитывается как дополнение до четности столбца и двух диагоналей.
Данный код может корректировать все одиночные ошибки. Наличие одиночной ошибки предет к возникновению нечетности в 3-х контрольных разрядах.

Данный код гарантированно обнаруживает все двоичные ошибки и не приводит к размножению ошибок. Однако существует некоторая комбинация двоичных ошибок, искаженные контрольные разряды которых совпадают с искажением от одиночной ошибки. Поэтому данный код гарантированно не корректирует двоичные ошибки.
В соответствии с нумерацией на предпоследнем рисунке, значение каждого контрольного разряда определяется из следующего выражения :
m
![]()
![]() q1i = ∑ ( qki qki, i-k+1 qki, i+-k-1 )
q1i = ∑ ( qki qki, i-k+1 qki, i+-k-1 )
k=2
При декодировании проверяется выполнение четности по столбцу и двум диагоналям
4) Модифицированный трехвекторный код сдополнительной коррекцией разрядов.
Иногда при передаче массива, закодированного основным трехвекторным кодом, возникает троичная ошибка определенного вида, которая может привести к неправильному декодированию и размножению ошибок. Но подобная ситуация встречается редко.
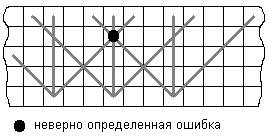
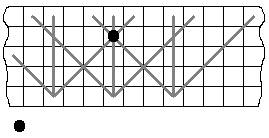
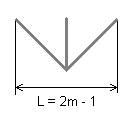
Одним из основных недостатков рассмотренных выше трехвекторных кодов является то, что при кодировании и декодированиипо столбцу и двум диагоналям необходимо иметь большой массив информации. Для кодирования 1 разряда его длина L = 2m-1. При достаточно больших m в кодирующем и декодирующем устройстве необходимо иметь регистровую матрицу достаточно большой длины. Для уменьшения избыточности аппаратурной реализации разработаны специальные коды, которые получаются путем сжатия основного трехвекторного кода.
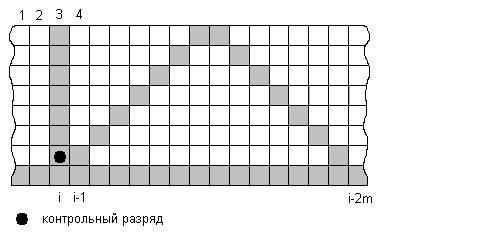
5) Трехминимальный векторный код
При рассмотрении основного трехвекторного кода становится очевидно, что локализация ошибки каждого разряда массива выполняется пересечением трех векторов, причем каждый разряд локализуется пересечением только своих векторов. Анализ трехвекторных кодов исправляющих одиночные и обнаруживающих кратные ошибки показывает, что это возможно, если конфигурация векторного кода удовлетворяет следующим условиям :
1) Сочетания разрядов, используемых для вычисления контрольного разряда каждой k-ой строки схемы конфигурации векторного кода, должны отличатся от других строк хотя бы одним разрядом, причем для строк k = 2,3 … m, количество этих разрядов должно равняться числу векторов в схеме, а при k=1 число их равно 1.
2) Никакая строка векторного кода не может быть получена путем сдвига вправо или влево любой другой строки.
Одним из способов построения кода, удовлетворяющего вышеперечисленным условиям, является следующий способ :
Необходимо записать последовательность двоичного числа в столбец по порядку начиная с единицы. Далее из этих чисел следует выбирать такие комбинации, которые содержат 3 единицы, причем одна из единиц должна находится в крайнем правом или крайнем левом разрядах. Последняя комбинация содержит только одну единицу в крайнем левом или крайнем правом разряде.
Пример : Построить трехминимальный векторный код для m=8
![]()
![]() 10 0
10 0
101
трехминимальный = 101100 ………
векторный код 110
110010 ………
110100
111000
100000
Отсюда следует следующая схема кодирования контрольного разряда :
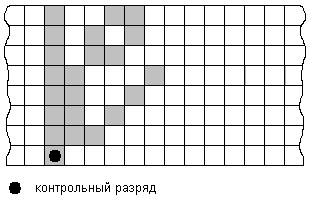
Контрольный разряд рассчитывается как дополнение до четности левого закрашенного столбца и отдельных закрашенных разрядов.
З. Ы. !! – отсутствует кусок текста
 |
Редактор Mishgan
Рукописный вариант лекций предоставил MrBurns
2004 г.
