
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Имитационная модель компьютерного анализа фактов
, , -Теко», Москва
В современном Интернете, включая электронные СМИ, социальные сети, коммерческие и частные сайты, ежедневно публикуются сообщения, содержащие сотни тысяч фактов самой разной значимости: от глобального (Катастрофа в Японии...), государственного (Президент России высказал...) и регионального (Сегодня в Москве...) до корпоративного (Фирма Х объявила о...), клубного («Вышел новый альбом ... ») и личного («Я провел день... »). При этом даже невооруженным глазом заметна высокая комплиментарность этого массива данных, когда представленные факты синергетически подтверждают, дополняют и развивают друг друга, что, в принципе, могло бы существенно повышать их совокупную информационную ценность. К сожалению, естественно-языковая природа публикаций и, главным образом, отсутствие единой интерпретационной модели всерьез затрудняют консолидацию отдельных фактов и их дальнейшую интеграцию в структуры знаний более высокого порядка.
С другой стороны, нельзя не отметить пристальный интерес влиятельных государственных и коммерческих институтов к средствам автоматического извлечения сведений из открытых источников, в первую очередь, из Интернета, с их последующим обобщением для пользователя. Это обусловило появление новой отрасли информатики - компьютерной фактологии (Facts Extraction), задачей которой является анализ связей между сущностями в предложении. Активную работу в этом направлении ведут корпорации Google, Microsoft, SAS и другие; в русскоязычном же секторе Интернета одну из лидирующих позиций занимает компания «Ай-Теко» («Система управления фактографической информацией ”X-Files”»).
В настоящей работе рассмотрен один из способов формализации процесса компьютерного анализа фактов. Предлагаемая формальная модель планируется к использованию в качестве математического обеспечения будущих версий системы ”X-Files” и других перспективных фактоаналитических программных систем (ФПС) компании «Ай-Теко».
А. Вводные замечания
Подавляющее большинство современных работ в области компьютерной обработки фактов ([1], [2] и другие) посвящены вопросам эффективного поиска, фильтрации, верификации и организации фактов, а также методам извлечения релевантной информации из текстовой или иной формы их представления. Однако, скурпулезный сбор фактических данных является лишь предварительным этапом решения гораздо более общей задачи анализа фактов.
В самом деле, посмотрим на новостные заголовки: «Мэрия Самары разместила заказ в форме запроса котировок для заключения контракта на оказание услуг по мониторингу блогосферы...», «Президент Медведев выступил...» - это факты. Полноценный анализ фактов подразумевает их лингвистическую, статистическую и онтологическую обработку, сопоставление друг с другом и с внешними источниками знаний, выявление связей и зависимостей между ними, многоуровневую редукцию и т. д. Результатом этой сложной работы становятся обобщающие утверждения (или действия), имеющие прямую практическую ценность для пользователя. Достоверность и полнота таких утверждений является критерием качества аналитического механизма.
Следует отметить, что многие затронутые выше понятия («факты», «зависимости», «связи») очень плотно входят в ежедневный обиход, а значит весьма субъектизированы и многозначны. Чтобы обеспечить однозначную трактовку этих понятий и привести их к виду, реализуемому алгоритмическими средствами, нам необходим полномасштабный формалистический аппарат, способный дать надежную концептуальную, идеологическую и терминологическую платформу для создания и развития ФПС. С учетом технических условий и опыта эксплуатации ранних версий ФПС «X-Files», нам представляется целесообразным использовать имитационный подход [3] с применением методов ориентированной лингвистики и теории распознавания образов.
Для удобства внутренних ссылок данный материал разбит на алфавитно обозначенные главы с вложенной нумерацией разделов. В главе Б мы начнем с формального определения понятия «факт», аналитических операций над фактами и еще целого ряда формализмов, необходимых для построения функционально полной модели системы анализа фактов. Далее (глава В) будут рассмотрены свойства особых пространств и преобразований, составляющих фундамент этой модели. Действуя в рамках уже упомянутого имитационного подхода, в главе Г мы дадим теоретическое обоснование возможности построения ФПС, по эффективности не уступающей профессиональному Эксперту-аналитику, а в главе Д наметим пути практической реализации такой системы. Наконец (глава Е), мы проиллюстрируем наши построения на примере анализа временных регулярностей групп фактов.
Б. Фактографические принципы
Б1. Вне зависимости от значения слова «факт» в философии или в бытовом обиходе, в нашей системе факт, по существу, - центральный информационный объект с идентификатором и набором системных дескрипторов, как технологических (например, «время регистрации факта в системе»), так и смысловых («субъект», «объект», «атрибут» и т. п.). Примечание. Понятие «Атрибут» или «Атрибут досье» - классификационная характеристика факта, например, принадлежность факта тематической группе «Отзывы о товаре Х» (см. документацию на систему “X-Files”). Значения смысловых дескрипторов (характеристик) извлекаются из исходного информационного материала (текста, записей БД и пр.), а их совокупность уникально определяет факт в пространстве характеристик.
Б2. Характеристика представляет собой ограниченную дискретную величину F, принимающую значения из перечислимого и, в общем случае, неупорядоченного множества {F} = {f1, …, fNF}. Отметим, что характеристика может принимать и кóмплексные значения – например, в случае характеристики «объект» для факта с множественными объектами. Можно определить характеристику как вектор, однако для наглядности удобнее считать все характеристики скалярными, представляя комбинацию объектов факта битовой комбинацией или другой подобной формой.
Б3. Характеристики факта, извлекаемые из источника этого факта и сохраняемые системой в качестве смысловых дескрипторов, будем называть базовыми (или фактографическими) в противоположность производным характеристикам, которые будут определены ниже (см. раздел В1). Множество всех базовых характеристик {Φ}={F1, …, FMΦ} образует фактографическое пространство Φ, которое является ограниченным в силу ограниченности областей значений составляющих его характеристик и, в общем случае, неполным по причине их возможной взаимозависимости. Например, определенные атрибуты факта могут ограничивать набор допустимых субъектов только юридическими или, наоборот, только физическими лицами. Следовательно, некоторые комбинации значений характеристик являются недопустимыми, а соответствующие точки полного фактографического пространства – недоступными.
Б4. Факт, таким образом, определяется как точка в фактографическом пространстве:
φÎΦ: φ = (f1, ..., fM), где fiÎ{Fi}, 1£i£MΦ.
А все факты системы образуют множество {φ}, которое мы будем называть коллекцией фактов.
Естественно было бы определить в пространстве Φ отношение тождественности
φ1 º φ2: f1i= f2i, 1£i£MΦ,
т. е. равенство значений всех характеристик фактов определяет идентичность этих фактов.
Здесь речь идет о смысловом тождестве или, иными словами, об идентичности аналитической значимости фактов, поскольку наше фактографическое пространство Φ выстроено на базисе характеристик, которые по определению (см. Б1) являются смысловыми дескрипторами. При этом тождественные факты могут отличаться значениями своих технических дескрипторов, таких как «системный идентификатор» или «источник факта», однако это различие полностью игнорируется на этапе анализа.
Б5. Интуитивно ясно, что фактографические пространства разных ФПС (или разных версий одной ФПС) отличаются своей описательной силой, т. е. степенью детализации представления факта[1]. В дальнейших построениях мы будем полагать, что фактографическое пространство Φ нашей системы имеет адекватную описательную силу, т. е. равнозначные исходные описания отображаются в одну точку пространства Φ, в то время как разнозначные исходные описания отображаются в разные точки этого пространства.
Возьмем два исходных материала (скажем, текстовые фрагменты газетных новостей), из которых система извлекла два факта, и предъявим эти материалы Эксперту-аналитику. Если Эксперт признает, что эти материалы говорят об одном и том же (например, отчеты об одном событии из разных газет), то они аналитически равнозначны, хотя могут отличаться лексически, стилистически и даже языком текста. Если же Эксперт утверждает, что информационные материалы отражают разные события, то они аналитически разнозначны, хотя могут отличаться всего одной запятой («казнить нельзя ...») или даже быть абсолютно одинаковыми, но происходить из разных источников (серьезное издание или «желтая пресса»).
Недостаточно подробная фактография будет приводить к «слиянию» разных фактов в один - например, в пространстве с недельной точностью характеристики времени выступления одного деятеля в одном месте в разные дни недели неизбежно отразятся единственным фактом. С другой стороны, чрезмерно подробная фактография будет создавать информационный шум из-за трансляции множественных отчетов об одном событии в разные факты - скажем, тонкая шкала характеристики «цвет» даст два разных факта по источникам «Вася купил алую розу» и «Вася купил красную розу».
Построение априорно адекватного фактографического пространства является нетривиальной задачей, если вообще разрешимой – в практическом плане приходится полагаться на здравый смысл, сходимость итеративного процесса совершенствования системы и стационарность сред, производящих исходные информационные материалы.
Б6. Отметим, что фактографическое пространство само по себе не дает нам формализма для аргументированного аналитического обобщения фактов, поэтому в следующей главе мы рассмотрим способы преобразования фактографического пространства в более удобную для анализа форму.
В. Фактологические принципы
В1. Возьмем произвольную функцию H, определенную на фактографическом пространстве: h=H(φ), φÎΦ. Эта функциязадает дискретную ограниченную величину H со множеством значений {H}={h1, …,hNH}, причем NH не превышает мощности множества допустимых значений пространства Φ. Такую величину H мы будем называть производной (или фактологической) характеристикой[2].
Функция H может опираться в своем устройстве на универсальные и/или узкоспециальные онтотологические данные, внешние по отношению к фактографической модели: исторические, политические, географические, инженерные и т. п. Несколько простых примеров:
а) {H} состоит из названий месяцев и H(φ) отображает факт φ в название месяца даты этого факта.
б) {H} состоит из названий стран и H(φ) отображает факт φ в название страны, содержащей место этого факта.
в) {H} состоит из названий политических партий и H(φ) отображает факт φ в название политической партии, к которой принадлежит субъект факта. Если такой партии нет, то в {Y} имеется специальное значение y0: «неопределено».
г) {H} состоит из названий важных событий и H(φ) отображает факт φ в событие, соответствующее дате и месту факта. Если такого события нет, то в {H} имеется специальное значение h0: «неопределено».
Важно, что функция H(φ) по определению транслирует вектор φ в скаляр h. Из нескольких таких скаляров будет впоследствии составлен другой, производный вектор (см. следующий раздел). Эта двуступенчатая схема может показаться странной, но она делает рассуждения существенно более прозрачными и оказывается удобной в практическом, инженерном плане.
В2. Произвольная совокупность фактологических характеристик {Ψ}={H1, …, HMΨ} образует фактологическое пространство Ψ, которое является ограниченным и, в общем случае, неполным по причинам, указанным в разделе Б3. Отношение тождественности точек ψ1 и ψ2 в пространстве Ψ определяется также, как в разделе Б4, т. е ψ1º ψ2: h1i= h2i, 1£i£MΨ.
При этом соответствующая совокупности {Ψ} комбинация фактологических функций вида H(φ) определяет, очевидно, однозначное фактологическое преобразование пространств Ψ:Φ→Ψ, т. е. любому базовому факту φÎΦ соответствует ровно один производный факт ψ=Ψ(φ), ψÎΨ. Обратное не всегда верно: два нетождественных факта φ1≠ φ2 могут отображаться в один производный факт Ψ(φ1)=Ψ(φ2).
Так, если пространство Ψ состоит из примеров а и б к предыдущему разделу, то в одну точку «апрель-Россия» попадет много базовых фактов, отражающих события в России в августе, причем эти факты будут неразличимы средствами пространства Ψ, т. е. тождествены.
В3. Базовые факты φ1 и φ2 такие, что Ψ(φ1)=Ψ(φ2) будем далее называть подобными по фактологическому преобразованию Ψ, обозначая это отношение φ1~Ψφ2. С учетом однозначности отображения Ψ(φ), коллекция фактов {φ} разбивается на классы подобия Ω1, ..., ΩKΨ, так что UΩi={φ}, 1£i£KΨ и Ωi∩Ωj= Ø, "1£i, j£KΨ, то есть любой базовый факт φÎΦ принадлежит ровно к одному классу Ωi.
Множество всех классов подобия {Ω}Ψ = {Ω1, ..., ΩKΨ} назовем классификацией коллекции фактов {φ} по преобразованию Ψ. Для удобства обозначений введем классифицирующий оператор Ω(Ψ,{φ}): {φ}→{Ω}Ψ. Две классификации Ω(Ψ1,{φ}) и Ω(Ψ2,{φ}), образованные преобразованиями Ψ1(φ) и Ψ2(φ) соответственно, будем полагать тождественными при условии равенства {Ω}Ψ1={Ω}Ψ2 в обычном теоретико-множественном смысле. Понятно, что Ω(Ψ1,{φ}1)=Ω(Ψ2,{φ}2) возможно только при {φ}1={φ}2 и, кроме того, Ω(Ψ,{φ}1)=Ω(Ψ,{φ}2) Û {φ}1={φ}2. Учитывая, что любое преобразование Ψ(φ) задает единственную классификацию на заданной коллекции фактов, условие, Ω(Ψ1,{φ})=Ω(Ψ2,{φ}),"{φ} определяет тождественность преобразований Ψ1(φ) и Ψ2(φ).
Заметим, что в практических (т. е. аналитически-осмысленных) классификациях часто будет возникать специальный класс, покрывающий факты, не входящие в аналитически-значимые классы – его можно называть «не определено или «нуль-класс». Во-первых, даже изощренные лингвистические механизмы могут дать сбой при извлечении характеристик факта из ЕЯ-источника и тогда в графе «время факта» появится дефолтный NULL, который обычно (хоть и не всегда) не имеет аналитического смысла. Безусловно, с этим можно бороться логическими и статистическими методами, но совсем исключить подобные ситуации не получится.
Во-вторых, «нуль-класс» может возникать по самому определению фактологической классификации. Для иллюстрации возьмем пример г) к разделу В1. Пусть множество базовых фактов включает в себя «Путин выступил в Пензе 2 сентября», «Медведев прибыл в Пензу 1 февраля», «Чубайс заявил 1 февраля в Пензе» и «Путин посетил завод в Ростове 4 февраля». Сопоставляя комбинацию характеристик «дата факта» и «место факта» с внешним списком важных событий в России в указанный период времени, мы занесем три первых факта в класс «события на выездном совещании в Пензе 1-2 февраля», который даст основания сделать аналитический вывод, скажем, о повышенном внимании руководства РФ к проблемам Пензенской области. Однако последний факт выпадет из этой классификации в «нуль-класс», как не представляющий интереса с точки зрения упомянутого аналитического вывода.
В4. Дополним понятие фактологической функции так, чтобы областью ее определения могло быть не только базовое фактографическое пространство Φ, но и любое фактологическое пространство Ψ, образованное другими фактологическими функциями. Таким образом, функция g=G(ψ), ψÎΨ, определенная на фактологическом пространстве Ψ:Φ→Ψ задает дискретную величину G={g1, …,gNG}, которую уместно называть производной характеристикой второго порядка. Соответственно определяются фактологическое пространство Γ и фактологическое преобразование Γ: Ψ→Γ второго порядка, и далее более высоких порядков.
Приведем простой одномерный пример. Пусть фактографическое (базовое) пространство Φ содержит характеристику «населенный пункт места действия факта». Первая производная фактологическая характеристика может содержать названия регионов, вторая - названия стран и т. д. Для полноты картины следует отметить, что базовое фактографическое пространство Φ естественным образом выступает в роли фактологического пространства нулевого порядка, которое образовано лингвистическими, форматными и т. п. функциями трансляции исходных фактосодержащих материалов в базовые характеристики.
В5. Сформулируем одно важное свойство фактологических классификаций, которое потребуется нам в дальнейших рассуждениях.
Пусть на фактографическом пространстве Φ определены несколько (пусть P) произвольных фактологических преобразований Ψ1, ...., ΨP, образующих P фактологических пространств Ψ1:Φ→Ψ1, ..., ΨP:Φ→ΨP, которые в свою очередь задают P классификаций заданной коллекции фактов: Ω(Ψ1,{φ}),…,Ω(ΨP,{φ}). Нетрудно доказать, что пространство Ψ=Ψ1U...UΨP, получаемое объединением этих пространств, определяет классификацию Ω(Ψ,{φ})=Ω(Ψ1,{φ})´…´Ω(ΨP,{φ}), которая является комбинаторной композицией[3] их классификаций. По существу это означает, что редукция классов в фактологических классификациях имеет последовательно-итеративный характер – методический и практический смысл этого свойства мы рассмотрим в разделе Д5.

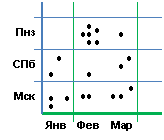 Мы проиллюстрируем это утверждение наглядным графическим примером. Представим себе координатную плоскость, где по одной оси отложено «время факта» (с точностью до дня), а по другой оси – «место факта» (с точностью до населенного пункта). Коллекция фактов отобразится точками на этой плоскости. Пусть первое из двух фактологических преобразований ведет классификацию по времени, определяя каждый класс как месяц (т. е. «события января», «события февраля», и т. д.), что дает вертикальные сектора на плоскости. Второе преобразование, допустим, ведет классификацию по географическим регионам – это дает горизонтальные сектора. В результате композиции этих преобразований плоскость оказывается разбитой на квадратные области, отражающие комбинаторную классификацию «место-время». Интуиция подсказывает, что плотно заполненные области будут соответстветствовать каким-то серьезным событиям (ср. «Пенза-февраль» из раздела В3). В следующей главе мы покажем, что такое предположение имеет вполне рациональные основания.
Мы проиллюстрируем это утверждение наглядным графическим примером. Представим себе координатную плоскость, где по одной оси отложено «время факта» (с точностью до дня), а по другой оси – «место факта» (с точностью до населенного пункта). Коллекция фактов отобразится точками на этой плоскости. Пусть первое из двух фактологических преобразований ведет классификацию по времени, определяя каждый класс как месяц (т. е. «события января», «события февраля», и т. д.), что дает вертикальные сектора на плоскости. Второе преобразование, допустим, ведет классификацию по географическим регионам – это дает горизонтальные сектора. В результате композиции этих преобразований плоскость оказывается разбитой на квадратные области, отражающие комбинаторную классификацию «место-время». Интуиция подсказывает, что плотно заполненные области будут соответстветствовать каким-то серьезным событиям (ср. «Пенза-февраль» из раздела В3). В следующей главе мы покажем, что такое предположение имеет вполне рациональные основания.
Г. Аналитические тезисы и алгоритмы
Г1. Проведем мысленный эксперимент. Допустим, в нашем распоряжении имеется коллекция фактов {φ} и мы передаем ее для анализа авторитетному Эксперту-аналитику (или целому агенству). Результатом работы Эксперта станут аргументированные умозаключения о тенденциях, отношениях и явлениях, которые не обозначены в фактах эксплицитно, но четко проявляются при их группировании и сопоставлении определенным образом, например (в зависимости от темы нашей коллекции): «Руководство РФ проявляет повышенный интерес к...», «Банк Х скоро усилит свои позиции в...» или даже «Этот новый пылесос удобен, но не долговечен» - при том, что с точки зрения непрофессионала в исходных фактах не было даже намека на подобные утверждения! Вместе с тем, высокий профессиональный уровень Эксперта, т. е. сложнейший конгломерат его опыта, образования, эрудиции и даже таланта вкупе с глубоким знанием текущих реалий заданной предметной области, заставляет нас относиться к этим умозаключениям с должным пиитетом и руководствоваться ими в принятии решений. В соответствии с логикой имитационного подхода, целью и главным критерием успеха разработки ФПС является способность системы делать подобные выводы автоматически, без участия Эксперта.
Разберемся, что представляют из себя умозаключения Эксперта, которые мы в дальнейшем будем называть тезисами. Для иллюстрации наших рассуждений возьмем общепонятный пример: пусть это будет система сбора и анализа фактов в предметной области бытовой техники, где роль источников фактической информации играют описания товаров, данные продаж, отзывы покупателей, журнальные обзоры и т. п.
Во-первых, можно считать, что тезис носит характер онтологического предиката, т. е. является логическим утверждением о наличии качественных[4] свойств объектов предметной области и отношений между ними. Так, в системе анализа бытовой техники непременно существует тезис о долговечности товара. Заявление Эксперта «По имеющимся данным пылесос Х долговечен» реализует этот тезис как истинный по отношению к пылесосу Х, а «Отзывы указывают на недолговечность пылесоса Х» - как ложный.
Во-вторых, умозаключения Эксперта врядли будут безаппеляционными – оценка степени надежности анализа является важной частью аналитической работы и имеет существенное значение для заказчика. Именно этим объясняется вероятностная модальность реальных аналитических выводов: «Факты отчетливо указывают на...», «Факты дают некоторые основания думать, что....» и т. д. Таким образом, правильнее говорить о тезисе, как об утверждении нечеткой логики [4], где в роли показателя истинности выступает та самая оценка достоверности, измеряемая обычно в диапазоне [0,1].
На данном этапе мы можем ограничиться троичной логикой: да – нет – неопределено. В нашем примере с тезисом о долговечности пылесоса заявление Эксперта «Имеющиеся данные отчетливо указывают, что пылесос Х долговечен» реализует этот тезис как сильно истинный (пусть 0.95) по отношению к пылесосу Х, а «нет оснований считать пылесос Х надежным» - как неопределенный, потому что указаний на ненадежность здесь тоже нет.
В-третьих, грамотный Эксперт не позволит себе делать «голословные» утверждения, а всегда подкрепляет их подборкой подтверждающих и/или опровергающих фактов: «Факты №№... дают основания полагать, что...» и тому подобное. В нашей модели такая подборка будет ничем иным как классификацией фактов (см. раздел В3).
В самом простом случае речь идет о классах «за», «против» и «не имеет отношения», но следует допускать и много более сложные классификации, например, «очень сильно за», «так себе за» и т. п. В нашем «пылесосном» примере можно было бы представить себе классы покупательских отзывов «все плохо», «в целом хорошо, но есть мелкие недочеты» и т. д.
В-четвертых, естественно предположить, что профессиональный Эксперт сначала производит классификацию фактов по критериям тезиса (гипотезы), а затем использует ее для расчета истиности этого тезиса, но не наоборот – сначала высказывается об истиности или ложности тезиса, а потом подгоняет факты под этот вывод[5]. Это означает, что показатель истиности тезиса на заданной коллекции фактов следует считать функцией классификации фактов для данного тезиса.
В самом деле, если предложить Эксперту уже готовую классификацию фактов, он сможет сделать по ней свое заключение так же, как если бы он группировал факты самостоятельно. Представим, что в примере с бытовой техникой мы не допускаем Эксперта к «голым» фактам, а только сообщаем ему, что имеются 100 хороших отзывов, 50 почти хороших и 300 совсем плохих. Наверняка он сделает свой тезисный вывод на этом материале. Другой вопрос, что допусти мы его к фактам, его собственная классификация отзывов на хорошие, плохие и т. д. могла бы быть бы совсем иной[6].
Итак, в рамках настоящего исследования постановим, что любой тезис T({φ}), высказываемый Экспертом на коллекции фактов {φ}, представляет собой комбинацию трех элементов:
1) онтологического предиката τ;
2) аргументирующей классификации фактов {Ω}τ({φ});
3) показателя истинности Dτ({Ω}),
что можно суммарно записать в следующем виде: T({φ}): [τ,{Ωτ}({φ}},Dτ({Ω})].
На практике онтологические предикаты τ часто бывают параметризованы – например, τ(x) или τ(x, y) – для случаев вида “Товар х долговечен» или “Товар х хорошо продается в y». Здесь это не имеет принципиального значения, мы всегда можем рассматривать параметрическией предикаты как совокупность простых предикатов на полном множестве значений параметров: «Товар X1 долговечен», «Товар X2 долговечен» и т. д.
Г2. Аналитический тезис по определению происходит от Эксперта-человека, а следовательно, является неформализуемым концептом. По этой причине важные для нас свойства тезисов придется представить в виде постулатов.
1) Множество тезисных предикатов {τ} конечно и не зависит от конкретной коллекции фактов:
" {φ}*É{φ}: {τ}*={τ}.
Действительно, любое умозаключение τ, высказанное на коллекции фактов {φ}, может быть высказано и для более широкой коллекции {φ}*É{φ}, хотя, возможно, и с другим значением истинности. Иными словами, каждый вновь прибывающий факт может влиять на меру истинности тезисного предиката τ, но не делает его бессмысленным. Это означает, что тезисы являются принадлежностью фактографического пространства Φ, а не существующей в нем коллекции фактов {φ}[7].
В нашем примере, предикат долговечности пылесоса Х имеет смысл (т. е. исчислим) даже если в системе нет пока ни одного отзыва об этом пылесосе. В этом случае наш Эксперт делает вывод, что долговечность имеет значение «неопределено». Другое дело, что в реальном аналитическом отчете такие заявления опускаются для экономии места, но Эксперт должен быть готов к вопросу клиента «Что вы думаете насчет долговечности пылесоса Х?».
2) Для каждого тезисного предиката τ существует фактологическое преобразование Ψτ(φ), задающее классификацию произвольной коллекции фактов {φ} тождественную тезису T({φ}):
[τ,{Ωτ}({φ}},Dτ({Ω})] : "τ $ Ψτ(φ) : Ω(Ψτ,{φ}}={Ωτ}({φ}), "{φ},
а также, по крайней мере, одна оценочная функция Δτ({Ω}), тождественная показателю истинности Dτ({Ω}):
"τ $ Δτ({Ω}) : Δτ({Ω})=Dτ({Ω}), "{Ω}.
Этим постулатом заявляется вполне очевидная алгоритмическая представимость тезиса, т. е. существование алгоритма, тождественного тезису T({φ}) в смысле соответствия «данные-результат». Иначе пришлось бы признать, что Эксперт не копит личный опыт и строит способы классификации и/или оценки истиности тезиса ad hoc для каждой коллекции фактов {φ}.
Действительно, процесс исчисления Экспертом-человеком отнологического предиката в тезис T({φ}) хоть и не может быть эксплицирован в общем случае, но полностью удовлетворяет всем основным критериям алгоритмичности:
1) Детерминированность - одинаковые коллекции фактов Эксперт прокомментирует одинаково: {φ}*={φ} Þ T({φ})=T({φ}*).
2) Результативность – тезис всегда имеет результатное значение, пусть даже «неопределено».
3) Универсальность – тезис исчислим на любой коллекции фактов, включая пустую коллекцию.
Итак, для любого тезиса T({φ}): [τ,{Ωτ}({φ}},Dτ({Ω})] существует алгоритм Θ({φ}): [τ,Ψτ(φ),Δτ({Ω})], который на произвольной коллекции фактов {φ} вычисляет классификацию фактов и показатель истинности предиката τ, идентичные данному тезису T({φ})=Θ({φ}):
"{φ} : Ω(Ψτ,{φ}} = Ωτ({φ}} Ù Δτ(Ω(Ψτ,{φ})) = Dτ(Ωτ({φ})).
Вообще говоря, таких алгоритмов может быть несколько, но, по всей вероятности, только один будет соответствовать «человеческой» процедуре. При этом совсем необязательно, что именно он будет самым оптимальным для практической реализации.
Г3. Постулаты предыдущего раздела позволяют заявить, что для произвольного заданного фактографического пространства Φ можно построить конечное множество алгоритмов {Θ)Φ такое, что совокупный результат вычисления этих алгоритмов {Θ}Φ({φ}) на любой заданной коллекции фактов {φ}ÎΦ будет неотличим от полного множества тезисов {T}Φ({φ}), представленных Экспертом на той же коллекции фактов.
Здесь самое время переосмыслить вводный манифест этой работы (глава А). Там, напомним, говорилось, что задача анализа фактов состоит в построении информативных обобщений имеющихся фактов, т. е. тезисов в нашей терминологии. Эксперт справляется с этой задачей наилучшим образом по определению[8], а значит важнейшим показателем эффективности ФПС становится совпадение результатов ее работы с результатами Эксперта. В итоге, разработка системы сводится к построению множества алгоритмов {Θ}, оптимального в смысле интегрального критерия вида Q({Θ}) = ò{φ} Σ{τ} Wτ(Δτ({φ}) - Dτ({φ})), где Wτ(x) - функция стоимости ошибки вычисления тезиса τ.
Поясним вышесказанное. Дело в том, что клиенту-заказчику по большому счету все равно, кто делает анализ фактов и формулирует тезисы: человек-аналитик, автомат или их комбинация – его живо интересует только соотношение «скорость-цена-качество». На сегодняшний день, мы полагаем, ответственную факто-аналитическую работу на заказ выполняют все-таки люди: специалисты-аналитики, частные детективы и иногда даже секретари – все зависит от запросов и кошелька клиента. Получается либо «хорошо, но долго и дорого», либо «дешево и быстро, но плохо» и т. п. Наша цель заключается в создании компьютерных средств, способных взять на себя если не всю, то хотя бы часть работы и тем самым улучшить упомянутое соотношение «скорость-цена-качество». Материал разделов Г1-Г3 позволяет думать, что эта цель теоретически достижима.
Г4. Тут неизбежно возникает вопрос: раз для оценки качества тезисов системы на каждой коллекции фактов все равно не обойтись без присутствия Эксперта (причем, самого лучшего), не проще ли сразу поручить эту работу ему? Однако, постулат 1 (раздел Г2) дает основания считать, что множество исчислимых тезисов {τ} универсально в рамках предметной области. Следовательно, мы можем ожидать, что система алгоритмов {Θ}, построенная и отлаженная при участии Эксперта (в ТРО - «обученная») для одного заказчика, окажется работоспособной (с минимальной доводкой) в среде другого заказчика, оперирующего в той же предметной области[9]. Более того, перенос системы в технически отличную, но родственную предметную область окажется не столь болезненным, как ее построение с нуля. Таким образом, один раз подготовленная система оправдает расходы на привлечение Эксперта многократной установкой в разных средах.
Например, нам удалось построить эффективную систему мониторинга дебиторов для банка А с фактографическими характеристиками вроде «декларируемый доход», «сумма выплат», «места отдыха», «марка автомобиля», а также тезисами типа «дебитор скрывает доходы» и «дебитор приближается к границе риска невыплаты». Очевидно, что такая система сможет работать и в другом банке Б, причем перенастройка системы сведется, по большому счету, к замене множества значений характеристик «имя» и т. п. Причина такой универсальности в том, что операционные и административные схемы современных организаций не создаются ad hoc, а наоборот, сильно стандартизированы и отображаются друг на друга с точностью до названий департаментов, стоимости услуг и фамилий руководства.
Итак, все сказанное в разделах Г1-Г4 утверждает теоретическую возможность построения эффективной ФПС, но не предлагает конструктивных путей решения этой задачи. Этму вопросу посвящена следующая глава нашей работы.
Д. Практическая задача
Д1. Признаем, что выдвинутая в разделе Г3 заявка на создание автоматической ФПС, полностью заменяющей Эксперта-аналитика, кажется на данном этапе преждевременной. Эту общую задачу мы обозначим как стратегическую, но пока неосуществимую, и переведем рассмотрение в более практическую плоскость. Как обсуждалось ранее, аналитическая работа с фактами имеет целью построение полезных для клиента умозаключений-тезисов, для каждого из которых требуется выполнить два основных действия:
1) выделить релевантные тезису классы фактов,
2) интерпретировать эту классификацию в аналитическую гипотезу.
Мы предлагаем на текущем этапе сосредоточиться на компьютеризации первого из этих действий, поскольку именно подбор, сопоставление и сортировка фактов в больших массивах содержат много утомительной рутины, которую было бы правильно переложить на компьютер. Таким образом, назначение разрабатываемой нами программной системы формулируется как инструмент построения фактологических классификаций, то есть не автономный анализатор, а техническое средство, которое снимает с оператора-аналитика «грязную работу» и позволяет ему сфокусироваться на творческой деятельности.
Надо заметить, что такое «сужение» целей совсем не означает, что мы отказываемся от более амбициозной задачи построения полностью автоматического анализатора фактов, как обсуждалось в разделе Г3. Наоборот, как мы увидим ниже (см. шаг №6 в схеме следующего раздела), этот подход позволяет набрать опыт и подготовиться к полной автоматизации.
Д2. Итак, в свете новой формулировки задачи рабочий цикл нашей аналитической системы выглядит так.
1. Система получает документы или другие источники фактов, выделяет в них индивидуальные факты и вычисляет их базовые характеристики {Φ}={F1, …, FMΦ}. Тем самым, каждый исходный факт транслируется в точку φ фактографического пространства Φ, а все они образуют коллекцию фактов {φ}.
2. Система оборудована набором заранее подготовленных аналитических алгоритмов {Θ}[10]. Каждый такой алгоритм ΘÎ{Θ} состоит из классификатора фактов ΨΘ({φ}) и критериальной функции ΔΘ({Ω }).
3. Система поочередно запускает алгоритмы из множества {Θ} и для каждого Θ:
3.1. Классификатор ΨΘ вычисляет одну или более функций вида H(φ) – фактологических характеристик - и, следовательно, реализует некое фактологическое преобразование ΨΘ: Φ→ΨΘ. Результатом его работы становится некая классификация фактов Ω(ΨΘ,{φ}).
3.2. Критерий ΔΘ обрабатывает полученное множество классов {Ω}=Ω(ΨΘ,{φ}) и выносит свое решение об информативности этой классификации.
3.3. В случае положительного решения ΔΘ(Ω(ΨΘ,{φ})) данная классификация {Ω} предъявляется Эксперту-оператору в удобной форме, графической или табличной.
3.4. Эксперт-оператор оценивает предъявленную классификацию и либо
3.4.1. Признает ее информативной и использует для построения аналитического тезиса [τ,{Ω},D]. Алгоритм Θ в этом случае помечается как качественный на коллекции фактов {φ}, Q(Θ,{φ})=1, а тезис регистрируется системой. Либо
3.4.2. Признает ее нерелевантной или ошибочной и отбрасывает. Тогда алгоритм Θ помечается как некачественный для коллекции {φ}, Q(Θ,{φ})=0, а разработчик получает сигнал об этом.
4. Эксперт-оператор использует презентационные средства системы (диаграммы, таблицы, графы и пр.) для классификации и анализа фактов в ручном режиме. При этом, возможно, он выстроит хотя бы одну новую классификацию фактов {Ω}, упущенную системой на шаге №3 и аргументирующую некий тезис [τ,{Ω},D]. В этом случае разработчик получает соответствующий сигнал с полной информацией о новом тезисе.
5. Эксперт-оператор переносит все тезисы {Т}, выстроенные на данной коллекции фактов, в окончательный аналитический отчет для клиента.
6. Разработчик совершенствует набор алгоритмов {Θ} с учетом сигналов, полученных от системы на шагах №3.4.2 и №4. Кроме того, по информации с шагов №3.4.1 и №4 разработчик устанавливает соответствия между множеством алгоритмов {Θ} и множеством тезисов {Т} – эти данные будут потом использованы для автоматизации построения тезисов.
7. Цикл повторяется либо
7.1. с шага №1 на другой коллекции фактов {φ}*, расширенной {φ}Ì{φ}* или новой {φ}Ë {φ}*, либо
7.2. с шага №2 с обновленным на шаге №6 набором алгоритмов {Θ}*.
Теоретические принципы, изложенные в разделах Г1-Г3, позволяют нам надеяться, что итеративный процесс совершенствования системы будет сходящимся, так что со временем шаг №6 станет лишним и система будет готова к автономной эксплуатации.
Безусловно, приведенная схема работы системы намеренно огрублена, чтобы не перегружать изложение, но два момента все-таки требуют специального внимания. Во-первых, на шаге №3 должно быть предусмотрено взаимодействие системы с оператором, в частности, настройка параметров аналитических алгоритмов, участие оператора в решении об отсечении неперспективных ветвей анализа и т. п. Во-вторых, данная схема сфокусирована на операциях аналитического ядра, но успех системы как инструмента во многом зависит от эффективности средств обработки и презентации результатов. Например, существующие в текущей версии ФПС «X-Files» графы и таблицы были бы гораздо более информативны при внедрении предикатных тезисов и логики второго порядка над ними.
Д3. Вернемся к схеме предыдущего раздела в момент, когда множество аналитических алгоритмов {Θ} еще пусто. Здесь особое значение приобретает шаг №4, где мы должны предоставить Эксперту-оператору удобные и эффективные средства для построения классификации фактов. Если пока оставить в стороне технические и пользовательские аспекты «удобства» и «эффективности», то речь идет о предъявлении оператору одной или нескольких классификаций-кандидатов, из которых он выберет действительно значащие.
Собственно, отношение числа кандидатов, отобранных экпертом для тезисов, к числу отброшенных кандидатов и будет показателем «эффективности» этого средства, а значит, методы построения классификаций-кандидатов должны быть максимально конструктивны, чтобы не упустить нужного и избежать «ложных тревог».
Абсолютно конструктивных методов поиска эффективных классификаций-кандидатов не существует[11] и их поиск сводится к перебору всех допустимых фактологических преобразований Ψ:Φ→Ψ над фактографическим пространством Φ. Понятно, что предъявление Эксперту-оператору всех результатов такого перебора было бы безумием, поэтому первым шагом на пути к «эффективности» предлагаемого инструмента должно стать создание разумного критерия автоматического отсева неперспективных классификаций
Д4. Возьмем фактологическое преобразование Ψ:Φ→Ψ, задающее на коллекции фактов {φ} классификацию Ω(Ψ,{φ})={Ω1, ..., ΩN}. Допустим, известны априорные вероятности Pi=P(φÎΩi), 1£i£N того, что произвольный факт φ попадает в класс Ωi. С другой стороны, на достаточной большой конкретной коллекции {φ} вычислимы апостериорные вероятности Pi*=P(φÎΩi /{φ}) того же события. Как правило, значимое отклонение Pi* от Pi является индикатором информативной классификации, что формально выражается интегральным критерием такого, например, вида: Σi [(Pi*- Pi) / Pi(1 - Pi)]2 / N ≥ ε, 1£i£N.
Это является прямой формулировкой общего принципа кластеризации, хотя и вырожденного в силу упоминавшейся ранее качественности характеристик нашего фактографического пространства Ф. Предложенный критерий основан на формуле Муавра-Лапласа в предположении о стохастической незавимости и биноминальном распределении значений фактографических функций H(φ), составляющих базис преобразования Ψ. Более тонкая оценка значимости отклонения апостериорных вероятностей от априорных осуществима методами проверки статистических гипотез.
Д5. Предложенный выше способ оценки информативности классификации Ω(Ψ,{φ}), а значит и задающего ее фактологического преобразования Ψ:Φ→Ψ, требует информации об априорных вероятностях Pi=P(φÎΩi), что далеко не всегда возможно на практике для преобразований высших порядков (раздел В4). Однако, это требование выглядит вполне реалистичным для фактологических преобразований первого порядка.
Рассмотрим некоторую фактологическую функцию H(φ), φÎΦ со множеством значений {H}={h1, …,hN}. Часто (хотя не всегда), существует возможность оценить априорные вероятности P(hi), 1£i£N того, что функция H(φ) принимает значение hi на произвольном факте φ. Утверждение, сделанное в разделе В5[12], дает основания полагать, что отклонение апостериорных вероятностей P(hi/{φ}) на конкретной коллекции {φ} от априорных P(hi) является индикатором информативной классификации вокруг соответвующих значений hi.
Для примера, пусть функция H(φ) отображает факты выступлений руководства РФ на ось времени с точностью до дня, игнорируя все факты, не имеющие отношения к таким выступлениям. Естественно, что распределение вероятностей на оси времени (значениях H) будет равномерным по будним дням. Если при этом обнаружится несоразмерное количество фактов, отображаемых в «10 октября», то можно смело заявить – что-то случилось.
Возьмем более сложный, двухмерный случай. Пусть функция H1(φ) остается из предыдущего примера, а H2(φ) отображает место выступления в соответствующий регион РФ. Априорно большинство таких выступлений делается в Москве, а по остальным регионам в зависимости от степени удаленности. Если выясняется, что много фактов попадает в «10 октября» и в «Пенза» - это может означать, что 10 октября в Пензе имело место какое-то выездное событие.
Таким образом, если обнаружена «информативность» функции H1(φ), то перебор в поиске функции H2(φ) для построения качественной классификации-кандидата может быть сокращен до значащих (ненулевых) классов, образованных функцией H1(φ). Например, пусть анализ множества фактов {φ} указывает на абнормальную концентрацию по времени в районе «10 октября». Ограничим дальнейший анализ до подмножества фактов {φ}*, случившихся именно в этот момент. Очевидно, что поиск общности этих фактов по географической, политической или другой характеристике значительно упрощается за счет ограниченности подмножества {φ}* по сравнению с общим {φ}.
Д6. Итак, можно предложить следующую процедуру выдвижения классификаций-кандидатов на шаге №4 схемы раздела Д2. Пусть заранее определено множество «базовых» фактологических функций Â таких, что для любой такой функции H(φ)ÎÂ известны априорные вероятности P(H(φ)=hi) получения значения hi из полного множества значений {H}={h1, …,hNH} на произвольном факте φ. Для простоты ограничимся только функциями с булевым множеством значений {H}={1,0}, где ситуация H(φ)=1 имеет смысл истинности некого онтологического условия, приписанного данной функции.
Простейший пример: H(φ)=1 тогда и только тогда, если факт произошел 10 октября. Понятно, на практике такая функция будет параметризована агрументом применяемой даты H(d,φ), но в рамках теоретического исследования проще считать, что множество Â включает в себя H(d,φ) со всеми возможными значениями d, как отдельные функции.
4.1. Система производит перебор функций H(φ)ÎÂ на данной коллекции фактов {φ} объемом M({φ}). Для каждой такой функции:
4.1.1. Вычисляются значения H(φ) для всех фактов φÎ{φ}. Строится множество фактов {ψ}Ì{φ}, получивших значение 1: H(ψ)=1, "ψÎ{ψ}.
4.1.2. Вычисляется критерий Σ(H,{φ}) = [(PH*- PH) / PH(1 – PH)]2, PH - априорная вероятность P(H(φ)=1), PH*- отношение M({ψ})/M({φ}).
4.1.3. Полученное значение Σ(H,{φ}) сравнивается с некоторым эмпирическим порогом δH.
4.1.4. В случае Σ(H,{φ}) <δH система переходит к шагу 4.1.1 со следующей H(φ).
4.1.5. В случае Σ(H,{φ}) ≥δH система переходит на следующий уровень рекурсии, а именно выполняет шаги 4.1.1–4.1.5 с перебором других функций из Â на выделенном подмножестве фактов {ψ}.
Конкретно, система начинает перебор функций J(φ)ÎÂ, J(φ)¹H(φ). Для каждой такой функции:
4.1.5.1. Вычисляются значения J(ψ) для всех фактов ψÎ{ψ}. Строится множество фактов {χ}Ì{ψ}, получивших значение 1: H(χ)=1, "χÎ{χ}.
4.1.5.2. Вычисляется критерий Σ(J,{ψ}) = [(PJ*- PJ) / PJ(1 – PJ)]2, PJ - априорная вероятность P(J(ψ)=1), PJ*- отношение M({χ})/M({ψ}).
4.1.5.3. Полученное значение Σ(J,{ψ}) сравнивается с некоторым эмпирическим порогом δJ.
4.1.5.4. В случае Σ(J,{ψ}) <δJ система переходит к шагу 4.1.5.1 со следующей J(φ).
4.1.5.5. В случае Σ(J,{ψ}) ≥δJ система переходит на следующий уровень рекурсии.
............................................................................................
4.1.5.6. Cистема переходит к шагу 4.5.1 со следующей функцией J(φ).
4.1.6. Cистема переходит к шагу 4.1.1 со следующей функцией H(φ).
4.2. Все обнаруженные системой «статистически значимые» комбинации базовых фактологических функций из множества  вида H´J´... вместе с соответствующими классами фактов вида {φ}*Ì{φ}, H(φ)=1ÙJ(φ)=1Ù..., "φÎ{φ}* предъявляются Эксперту-оператору через наглядные презентационные средства: диаграммы, графики, таблицы и пр. Далее, для каждой такой комбинации:
4.2.1. Если Эксперт не признает данную классификацию Ω={φ}* информативной, она отбрасывается.
4.2.2. Если Эксперт использует данную классификацию Ω={φ}* для построения некоторого аналитического тезиса [τ,{Ω},D] – либо напрямую, либо в качестве «базы» для более тонкого анализа – информация об этом тезисе передается разработчику для дальнейшего усовершенствования системы.
Применим данную схему к двухмерному примеру из раздела Д5. Пусть на шаге 4.1.1 взята функция H(φ) такая, что H(φ)=1 только если факт φ имеет датой «10 октября». При соблюдении условий примера, вычисления на шаге 4.1.3 дает достаточно большое значение, чтобы перейти к шагу 4.1.5. Пусть на на шаге 4.1.5.1 взята функиця J(φ) такая, что J(φ)=1 только если факт φ имеет местом действия «Пенза». Тогда на шаге 4.1.5.3 будет получено высокое значение, и комбинация H´J будет считаться статистически значимой. Нашему Эксперту будет предъявлено множество всех фактов, произошедших в Пензе 10 октября вместе с объяснениями причин (например, в виде графиков распределения вероятностей, на которых будет отчетливо виден «кластер» вокруг указанных значений). Рассматривая предъявленное множество фактов, Эксперт может сделать какие-то важные выводы.
Д7. В предыдущем разделе предполагалось существование множества Â базовых фактологических функций с известным распределением априорных вероятностей. Мы полагаем, что универсального рецепта построения таких функций не существует, но интуитивно ясно, что в качестве строительного материала для них логично использовать онтологические данные предметной области, которые дают обоснованное обобщение значений характеристик пространства Φ. Сюда относятся географические, социологические, исторические, административные, политические, инженерные и подобные иерархии, а также особые области пространства Φ, имеющие самостоятельное онтологическое значение[13]. Вот несколько очевидных примеров:
- Города → регионы → страны (география) имена → место рождения / место прежней службы / состав семьи (социология), время действия → довоенный / послевоенный (история) имена → должности (администрация) имена → партии (политика), технические объекты → отрасль промышленности (инженерия)
Имеет смысл обратить особое внимание на характеристику «время факта». В силу своей количественной природы, эта характеристика может служить хорошей стартовой точкой для поиска информативных композитных фактологических преобразований (см. пример в разделе Д6). В следующей главе мы рассмотрим эту характеристику более подробно, используя ее как иллюстрацию нашей формальной модели анализа фактов.
Е. Хронологическая регулярность фактов
Поиск хронологических регулярностей в массивах фактов занимают особое место в контексте общей задачи анализа фактов как в силу своей прямой прагматической ценности, так и в качестве отправной точки композитного анализа (см. раздел Д7).
Е1. Пусть в нашем фактографическом пространстве Φ определена базовая характеристика t «время действия факта», tÎ{Φ}. Помимо дискретности и ограниченности, множество значений этой характеристики T={t1, …,tNt} естественно обладает свойством упорядоченности tn£ tn+1. На характеристике t определим хронологическую функцию c=C(t), tÎT, с возможными значениями {C}={c0,...,cNC}. Очевидно, что хронологическая функция C(t) может быть однозначно доопределена до фактологической функции C(φ), φÎΦ, а значит, она сама по себе выражает преобразование ΨC: Φ→ΨC, задающее на коллекции фактов {φ} классификацию Ω(ΨC,{φ}). Иными словами, функция C(φ) опирается только на ось времени и игнорирует все остальные базовые характеристики: например, {C} состоит из названий месяцев и C (φ) отображает факт φ в название месяца даты этого факта.
Рассмотрим произвольную фактологическую функцию h=H(φ), φÎΦ, и соответствующее ей фактологическое преобразование ΨH: Φ→ΨH. Объединение функций H(φ) и C(φ) образует новое пространство ΨH´C: Φ→ΨH´C, задающее на коллекции фактов {φ} комбинаторную классификацию Ω(ΨH´C,{φ}) – см. раздел В5. При этом точное совпадение этой классификации Ω(ΨH´C,{φ}) с исходной хронологической классификацией Ω(ΨC,{φ}) имеет важный смысл:
Фактологическое преобразование ΨH назовем регулярным по отношению к хронологической функции C(φ) на коллекции фактов {φ}, если Ω(ΨC,{φ})=Ω(ΨH´C,{φ}). Соответственно, хронофункция C(φ) будет в этом случае называться регуляризующей преобразование ΨH на коллекции фактов {φ}.
Поясним данное определение на примере. Пусть хронологическая функция C(φ) выделяет только 1-е и 15-е числа, и тем самым определяет множество фактов {φ} в три класса: «факты по 1-м числам», «факты по 15-м числам» и все остальное («нуль-класс»). Пусть теперь фактографическая функция H(φ) выделяет факты в три класса по признаку «зарплата», «аванс» и «прочее». Совпадение классификаций будет означать, что зарплата выдается по 1-м числам, а аванс - по 15-м.
Е2. Общее определение хронологической регулярности может быть наглядно конкретизировано для случая фактологических преобразований булевого типа, задающих только два класса – «значащий» и «нулевой» (см. раздел В3). Положим, что фактологическая функция H(φ) выражает какое-либо онтологическое условие, т. е. H(φ)=1 если факт φ удовлетворяет условию, и H(φ)=0 в противном случае. «Значащий» класс ΩH1={φ}HÌ{φ} представляет собой подмножество всех фактов, удовлетворяющих заданному условию: H(φ)=1,"φÎ{φ}H Ù H(φ)=0,"φÏ{φ}H. Например, функция H(φ) может выражать условие «факт φ сообщает о выступлении Президента», тогда H(φ)=1 для всех фактов, представляющих выступления Президента, и H(φ)=0 для всех прочих фактов. Такая функция H(φ) – точнее ее фактологическое преобразование ΨH – разбивает полную коллекцию фактов {φ} на два класса ΩH1 и ΩH0. Подмножество {φ}H включает в себя все факты о выступлениях Президента, вне зависимости от темы, даты и времени.
Пусть хронофункция C(φ) также имеет булевый результат, т. е. C(φ)=1, если факт φ удовлетворяет какому-то закону на оси времени, и C(φ)=0 в противном случае. Вычисление функции C(φ) – точнее, ее Ф-дополнения C(φ) - на всех фактах множества {φ}H, очевидно, разбивает класс ΩH1 на два подкласса ΩH1´Χ1 и ΩH1´Χ0. Например, C(φ)=1 для событий по понедельникам и C(φ)=0 для прочих дней недели. После применения этой функции к подмножеству {φ}H у нас получатся классы «выступления Президента по понедельникам» и «выступления Президента по другим дням недели».
Если при этом выяснится, что ΩH1´Χ1= ΩH1 и ΩH1´Χ0=Æ, то условие регулярности (раздел Е1) выполнено. Если, например, все факты из класса «выступления Президента».попали в класс «выступления Президента по понедельникам», а класс «выступления Президента по другим дням недели» остался пустым, то из этого можно сделать серьезные выводы о графике работы Президента и, с известной долей достоверности, о его здоровье.
Е3. Для целей практической реализации условие хронологической регулярности фактов можно сформулировать следующим образом:
Подмножество фактов {ψ}Ì{φ} и, соответственно, определяющее его фактологическое преобразование Ψ, является регулярным относительно хронофункции C(φ)={0,1}, если значения C(φ) на подмножестве {ψ} образуют дельта-распределение: P (C(φ)=0 / φÎ{ψ}) < σ, где σ –допустимое статистическое отлонение.
Иными словами, четкая «дельта» гистограммы C(φ) на подмножестве {φ} является очевидным индикатором хронологической регулярности.
Е4. Рассмотрим несколько практически значимых видов хронологической регулярности, но для удобства изложения сделаем сначала несколько предварительных замечаний
Введем в наше рассмотрение функцию T(φ), φÎΦ, отображающую факт φ в значение характеристики «время действия факта» tÎ{Φ}. По предположению раздела Е1 эта функция определена для всех возможных фактов φ в фактографическом пространстве Φ, а множество ее значений зависит от выбранной единицы измерения времени. Граничные значения T(φ) обозначим Tmin и Tmax: Tmin ≤ T(φ) ≤ Tmax.
Учтем, что выбор единицы измерения может сделать функцию Т(φ) вырождающей по отношению к базовой характеристике t. В самом деле, в системном репозитории ФПС время действия факта хранится в виде системной даты с точностью до дня – хотя источник не факта не всегда допускает такую точность («... выступил в августе прошлого года... »). Однако, в практическом анализе даты часто огрубляют до недель, декад, месяцев, лет и даже веков («События второй половины 17 века доказывают, что...»), а также их частей («в конце июля»). В этом случае разные исходные даты будут отображаться в одну аналитическую дату по Т(φ).
В силу упорядоченности значений характеристики t, функция T(φ) задает отношение порядка на произвольной коллекции фактов {φ}={φ1, φ2,...., φN} так, что T(φn) ≤ T(φn+1), 1 ≤ n ≤ N-1. При этом будем считать, что в случае T(φn)=T(φn+1) порядок следования фактов задается любым удобным детерминированным способом.
Очевидно, что «огрубление масштаба» функцией Т(φ) не должно сказываться на порядке фактов, поэтому самым первым способом разрешения проблемы порядка в случае T(φn)=T(φn+1) должна быть техническая дата действия факта. Если даже технические даты фактов φn и φn+1 совпадают, то можно использовать регистрационный факт в системе.
Вычисление хронологической регулярности во всех нижеперечисленных случаях производится согласно схеме раздела Е2 и по определению раздела Е3. Именно, для всех фактов коллекции {φ}={φ1, φ2,...., φN} вычисляется булевое условие C(φ)={0,1}, 1≤n≤N и определяется количество фактов NC=1, для которых данное условие C(φ) оказалось истинным. Далее, мы рассчитываем статистический показатель ложности P(C(φ)=0) условия C(φ) и сравниваем его с допустимым отклонением: 1 - NC=1/N = P(C(φ)=0) < σ.
 а. Ситуационная регулярность обобщает все факты коллекции {φ}, имевшие место на некотором временнóм отрезке, границы которого обусловлены некоторой опорной ситуацией. Например, «до войны» - «во время войны» - «после войны», или «после покупки компании», или «до смены руководства».
а. Ситуационная регулярность обобщает все факты коллекции {φ}, имевшие место на некотором временнóм отрезке, границы которого обусловлены некоторой опорной ситуацией. Например, «до войны» - «во время войны» - «после войны», или «после покупки компании», или «до смены руководства».
Хронофункция: C(φn) = [ Ts ≤ T(φn) ≤ Te ].
Здесь Ts ≥ Tmin и Te ≤ Tmax - время начала и окончания «опорной ситуации» соответственно. При этом случай Ts = Tmin определяет вариант «до ситуации», а Te = Tmax - «после ситуации».
Следует особо отметить, что этот самый простой вид хронологической регулярности имеет двойное применение. С одной стороны, если задавать функции C(φn) даты известных ситуаций, то можно обнаружить связянные с ними аналитически-значимые явления, иначе неочевидные. Например, при Ts=08/08/2008 и Te=15/08/2008 мы можем обратить внимание на повышенную активность некого банка в период российско-грузинского конфликта и сделать важные выводы. С другой стороны, осмысленным перебором значений Ts и Te в функции C(φn) мы можем вычислять сами ситуации, как примере с заседанием в Пензе (см. раздел Д5).
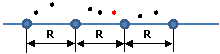
б. Интервальная регулярность формализует обобщение последовательности фактов, следующих друг за другом через определенный промежуток времени.
Хронофункция: C(φn) = [ Rmin ≤ T(φn) – T(φn-1) ≤ Rmax ].
Значения Rmin и Rmax задают минимальный и максимальный допустимый интервал следования фактов.
Соответствующее хронологическое преобразование представляется сверткой оси времени по точкам времени действия анализируемых фактов:[14]


Этот вид хронологической регулярности весьма эффективно описывает ситуации, связанные с потреблением и восполнением каких-то ресурсов. Так, выявление интервальной регулярности в последовательности фактов о поставках материалов на некий военный объект позволяет выстроить аналитический тезис о назначении этого объекта. Или, устойчивый интервал в последовательности фактов о запуске спутников обнаруживает секретный орбитальный проект. Важным свойством интервальной регулярности является статистическая устойчивость к случайным «сбоям»: прохождение внепланового эшелона на военный объект из примера выше не повлияет на общую аналитическую картину.
в. Периодическая регулярность выявляет общность последовательности фактов, привязанных к некоторым периодическим отметкам на оси времени.
Хронофункция: C(φn) = [ (T(φn) – T0) % R ≤ S ] Ù [ (T(φn) – T0) / R ≥ (T(φn-1) – T0) / R ].
Здесь символ «/» означает целочисленное деление, а символ «%» - остаток от такого деления. Значение T0 задает момент начала наблюдаемой последовательности, величина R определяет период регулярности, а S выражает максимально допустимое отклонение от регулярности.
Первая часть хронофункции C(φn) требует попадания факта φn в заданную зону допуска, в то время как вторая ее часть исключает из «значимого» класса (при C(φn)=1) факты, попадающие в «занятый» период.
Хронологическое преобразование, определяемое функцией C(φn), можно представить сверткой оси времени от момента T0-S с периодом R[15] и установкой зоны условия C(φn)=1 шириной 2S:


Периодическая регулярность, по-видимому, наиболее свойствена хронологическим тенденциям организационного и социального характера, вот несколько примеров:
1) T0 = 0, R = «10 дней», S = «2 дня» означает «ежемесячно по 10-м числам плюс-минус 2 дня»
2) T0 = «10 дней», R = «1 месяц», S = «2 дня» означает «ежемесячно по 10-м числам плюс-минус 2 дня»
3) T0 = «вторник», R = «7 дней», S = 0 означает «еженедельно строго по вторникам»
4) T0 = «360 дней», R = «1 год», S = «5 дней» означает «последняя декада года»
г. Корреляционная регулярность обнаруживает аналитически-значимую зависимость одной группы фактов {φ} от другой группы фактов {ψ}, причем {ψ}∩{φ}=Æ.
Хронофункция: C(φn) = [ Rmin ≤ T(φn) – T(ψm) ≤ Rmax ].
Значения Rmin и Rmax задают, соответственно, минимальный и максимальный допустимый интервал отстояния фактов группы {φ} от фактов группы {ψ}.
Хронологическое преобразование хронофункции C(φn) представляется сверткой оси времени по точкам времени действия фактов группы {ψ}:


В своей более строгой форме, корреляционная регулярность выражается составной хронофункцией:
C(φn) = [ Rmin ≤ T(φn) – T(ψm) ≤ Rmax ] Ù [ T(φn) – T(ψm) ≤ T(φn) – T(φn-1) ],
где вторая часть требует однозначного соответствия фактов группы {φ} фактам группы {ψ} без дублирования.
Во многих случаях корреляционная регулярность служит индикатором причинно-следственной связи между явлением, представленным группой фактов {ψ} (причина) и явлением, представляемым группой фактов {φ} (следствие). Например, многолетняя биржевая статистика показывает, что за сообщением о поглощении компании А компанией Б практически неизбежно следует сообщение о падении курса акций Б и эта связь имеет экономические основания. В других случаях, наличие корреляционной регулярности между группами фактов {ψ} и {φ} позволяет построить добротный аналитический тезис о предикторских свойствах фактов вида {ψ} в отношении фактов вида {φ}. Тут невольно вспоминается известная народная мудрость, что заявление правительства о, скажем, гарантиях стабильности курса рубля дает повод ждать его обвала в ближайшее время.
д. Групповая регулярность указывает на то, что явление, представляемое фактами коллекции {φ}, имеет свойство проявляться определенное количество раз K в заданный периодический отрезок времени R:
 C(φn) = ÚK-S≤M≤K+S { Ú1≤i≤M { [ T(φn-i)/R ¹ T(φn+1-i)/R ] Ù [ T(φn+1-i)/R = T(φn+M-i)/R ] Ù [ T(φn+M-i)/R ¹ T(φn+M+1-i)/R ] } }
C(φn) = ÚK-S≤M≤K+S { Ú1≤i≤M { [ T(φn-i)/R ¹ T(φn+1-i)/R ] Ù [ T(φn+1-i)/R = T(φn+M-i)/R ] Ù [ T(φn+M-i)/R ¹ T(φn+M+1-i)/R ] } }
Сложный вид хронофункции C(φn) обусловлен тем, что она допускает возможность случайного отклонения количества повторений K на S раз в каждую сторону (S<K). Символ «/» в формуле обозначает, как и ранее, целочисленное деление.
Легко видеть, что C(φn)=1 только для фактов, образуюших в течении периода R группы размером K±S
Групповая регулярность соответствует фразам типа «ровно три раза в год» (R=«1 год», K=3, S=0), «пару раз в неделю» (R=«7 дней», K=2, S=1) или «обычно четыре раза в месяц, но иногда получается только два» (R=«1 месяц», K=4, S=2).
Ж. Заключение
Представленная имитационная формальная модель алгоритмического анализа фактов далека от завершения – как и все прочее в пока еще не сформировавшейся окончательно отрасли компьютерной фактологии. Мы продолжаем развивать вышеописанные схемы и формализмы, охватывая новые предметные области, типы фактов и аналитических связей между ними. Кроме того, в настоящее время исследовательская группа компании «Ай-Теко» реализует масштабную экспериментальную программу верификации основных положений данной модели на обширном фактическом материале ФПС «X-Files». Мы планируем сообщать о результатах этих экспериментов в наших дальнейших публикациях.
Литература
[1] M. Banko et al. Open Information Extraction From The Web. University of Washington, DCSE, IJCAI, 2007
[2] Andrew Carlson et al. Active Learning for Information Extraction via Bootstrapping, Carnegie Mellon University, 2010
[3] V. S.Fain, L. *****banov. Activity And Understanding: Structure Of Action And Orientated Linguistics. World Scientific, 1998
[4] L. A.Zadeh. Fuzzy Logic And Approximate Reasoning. Synthese, 1975
[1] Количественной мерой описательной силы фактографического пространства может выступать энтропия потока фактов, опреляемая как H(Ψ) = - ∑pi * log pi, 1£i£N(Ψ), где N(Ψ) - мощность множества точек пространства Ψ, а pi – вероятность попадания случайного факта в i-тую точку пространства Ψ.
[2] Фактология (аналитическая дисциплина) противопоставлена фактографии (описательной дисциплине).
[3] Для A={{a}1,…,{a}N} и B={{b}1,…,{b}M}: A´B={{ai}∩{bj}}, 1£i£N, 1£j£M.
[4] Тем самым мы выводим из рассмотрения чисто количественные оценки вроде «Доход банка Х составит 100 миллионов рублей», но это не кажется очень большим упущением. Во-первых, для количественного анализа такого рода уже существуют успешно работающие компьютерные системы. Во-вторых, мы не исключаем качественные оценки количественных величин вида «превысит показатель прошлого года» или «станет самым высоким по стране»..
[5] Впрочем, на практике имеет место комбинация этих двух подходов. При анализе большой коллекции фактов сначала выделяют те факты, которые «бросаются в глаза» и на их основе выдвигают гипотезу, задающую предварительные классы. Затем анализируют всю коллекцию, наполняя эти классы до полного подтверждения или опровержения начальной гипотезы с учетом заданной допустимой стоимости ошибок обоих родов, доверительного интервала и пр.
[6] Тут отметим, что характер вычислений «показателя истинности» может быть либо сравнительным либо абсолютным. К первому типу относятся рассуждения, подобные вышеприведенному примеру, когда Зксперт оценивает сравнительную мощность полученных классов. Другой (абсолютный) тип охватывает ситуации, когда критерий истинности обусловлен просто наличием некоторого минимального количества фактов в значащих (ненулевых) классах. Так, для утверждения об истинности тезиса «Фирма заменила пылесос модели Х моделью Y» достаточно даже одного факта, происходящего от производителя.
[7] Собственно, фактографическое пространство Φ является формальным образом того, что в лингвистике и Искусственном Интеллекте называют предметной областью. В этом свете утверждение приобретает более привычное звучание: информативно-релевантные онтологические предикаты выдвигаются предметной областью, а не данными о ней.
[8] «Эксперт» в контекте данной работы и имитационного подхода вообще является репрезентативной (от фр. идеализацией, т. е. олицетворением профессионального сообщества аналитиков в заданной предметной области. Он образован, грамотен, опытен, но при этом не демонстрирует т. н. «шестое чувство» и прочие иррациональные таланты.
[9] В качестве гипотезы выскажем следующее, пока не доказанное утверждение: Пусть в операционной среде Λ определено фактографическое пространство Φ с описательной силой ÁΛ(Φ), на котором построена система аналитических алгоритмов {Θ), дающая в среде Λ качество QΛ({Θ)). Если в другой операционной среде Λ* пространство Φ обладает описательной силой ÁΛ*(Φ)≥ÁΛ(Φ), то качество этой системы алгоритмов в новой среде QΛ*({Θ)) ≥ QΛ({Θ)). Понятие описательной силы применительно к фактографическим пространствам обсуждалось в разделе Б5, но вопрос о ее количественной мере был отложен. Термин «оперативная среда» заимствован из ориентированной лингвистики, здесь его можно понимать как «множество всех возможных фактов с приписанным к нему Экспертом».
[10] Происхождение этих алгоритмов будет обсуждаться в следующем разделе.
[11] Надо, впрочем, отметить метод получения алгоритмов путем прямой имитации действий Эксперта, то есть прямо через реализацию его указаний вида «Я смотрю новости за неделю и если хотя бы три арабских лидера заявили о сохранении цен на нефть, я делаю прогноз о ее повышении».
[12] В данном контексте это утверждение означает, что объединение независимых «информативных» фактологических функций H1(φ) и функций H2(φ) образует не менее информативную классификацию, чем эти функции по отдельности.
[13] Особые онтологические области фактографического пространства представляют собой пересечение выделенных интервалов характеристик fΦ, соответствующее каким-то эктрасистемным условиям. Например, пересечение отрезка времени и географического региона может выделять область определеного события: см. также пример г) из раздела В1.
[14] Или, что то же самое, переходом к фазовой форме представления времени с адаптивной фазой.
[15] Оно же переход к фазовой форме представления времени с постоянной фазой.
