

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Способы совместного использования баз данных
Базы данных Microsoft Access могут использоваться одновременно несколькими пользователями в сети. Предоставить общий доступ к базе данных можно несколькими способами:
· поместив базу данных в общую папку в сети на файловый сервер или в общую папку на рабочей станции для обеспечения совместного доступа к базе данных и всем ее объектам: формам, отчетам, запросам, макросам и модулям. Он подходит, если нужно, чтобы все пользователи могли использовать одни и те же объекты базы данных одинаковым способом;
· опубликовав в сети таблицы базы данных Для этого необходимо разделить базу данных на файл объектов данных и файл объектов приложения. После разделения базы данных файл объектов данных помещается на файловый сервер или в общую папку на рабочей станции, чтобы предоставить общий доступ к таблицам, а файл объектов приложений — на компьютер пользователя в виде локальной копии. В этом случае производительность базы данных будет несколько выше, чем при совместном доступе ко всей базе данных, поскольку по сети будут передаваться только данные из таблиц. При этом отдельный пользователь может настроить формы, отчеты и прочие объекты из файла объектов приложения в соответствии со своими индивидуальными потребностями. Эти изменения не отразятся на остальных пользователях, которые используют свои локальные копии файла объектов приложения.
· обеспечив подключение к базе данных через Интернет. Объекты базы данных можно предоставить в совместное использование через Интернет, создав на их основе страницы HTML следующих видов:
* статические страницы HTML
* генерируемые сервером страницы HTML
* страницы доступа к данным
* документы в формате XML
Страницы HTML можно отобразить в программе просмотра Интернета.
· с помощью репликации ;
Портфельная репликация Windows позволяет использовать для работы с файлом (в том числе с базой данных) два компьютера: например, компьютер в офисе и переносной компьютер. Можно создавать реплики (специальные копии) базы данных Access для хранения на разных компьютерах и синхронизировать изменения в них. Аналогично несколько пользователей могут работать со своими копиями — репликами базы данных, которые могут быть синхронизированы по сети, с помощью удаленного доступа к сети или через Интернет.
· с помощью SQL Server. Если в сети организации установлена СУБД SQL Server, ее можно использовать для совместной работы с базой данных Access. Для этого необходимо создать клиент-серверное приложение на основе базы данных Access. В результате станут доступны мощные средства СУБД SQL Server. Можно преобразовать существующую базу данных Access в клиент-серверное приложение с помощью мастера
Основные понятия модели «клиент-сервер»
В основе понятия архитектуры «клиент-сервер» лежит распределенная модель вычислений. В самом общем случае под «клиентом» и «сервером» понимаются два взаимодействующих процесса, из которых один является поставщиком некоторого сервиса для другого.
Сервер — логический процесс, который обеспечивает некоторый сервис по запросу от клиента. Обычно сервер не только выполняет запрос, но и управляет очередностью запросов, буферами обмена, извещает своих клиентов о выполнении запроса и т. д.
Клиент — процесс, который запрашивает обслуживание от сервера. Процесс не является клиентом по каким-то параметрам своей структуры, он является клиентом только по отношению к серверу. При взаимодействии клиента и сервера инициатором диалога с сервером, как правило, является клиент, сервер сам не инициирует совместную работу. Это не исключает, однако, того, что сервер может извещать клиентов о каких-то зарегистрированных им событиях. Инициирование взаимодействия, запрос на обслуживание, восприятие результатов от сервера, обработка ошибок — это обязанности клиента.
Например, сервером может выступать реляционная СУБД Microsoft SQL Server (back-end), а клиентом — приложение, созданное в среде Access 2000, которое использует данные с сервера (front-end).
Отличие архитектуры «клиент-сервер» от архитектуры «файл-сервер»
(для СУБД Access и Microsoft SQL Server)
В архитектуре «файл-сервер» сетевое многопользовательское приложение строится по принципу файл-серверной архитектуры. Данные в виде одного или нескольких файлов размещаются на файловом сервере. Файловый сервер принимает запросы, поступающие по сети от компьютеров-клиентов, и передает им требуемые данные. Однако обработка этих данных выполняется на компьютерах-клиентах. На каждом из компьютеров запускается полная копия процессора обработки данных Jet Engine. Любая копия Jet независимо управляет файлами MDB, содержащими данные. Единственная связь между этими независимыми действиями — файл блокировок (файл, который имеет имя, совпадающее с именем файла приложения, но с расширением Idb), который обязательно создается для каждого файла базы данных с расширением mdb. При этом каждая копия Jet выполняет изменения индексов, работу с системными таблицами и другие функции, входящие в компетенцию СУБД.
В архитектуре «клиент-сервер» сервер базы данных не только обеспечивает доступ к общим данным, но и берет на себя всю обработку этих данных. Клиент посылает на сервер запросы на чтение или изменение данных, которые формулируются на языке SQL. Сервер сам выполняет все необходимые изменения или выборки, контролируя при этом целостность и согласованность данных, и результаты в виде набора записей или кода возврата посылает на компьютер клиента.
Недостатки архитектуры с файловым сервером очевидны и вытекают главным образом из того, что данные хранятся в одном месте, а обрабатываются в другом. Это означает, что их нужно передавать по сети, что приводит к очень высоким нагрузкам на сеть и, вследствие этого, резкому снижению производительности приложения при увеличении числа одновременно работающих клиентов. Вторым важным недостатком такой архитектуры является децентрализованное решение проблем целостности и согласованности данных и одновременного доступа к данным. Такое решение снижает надежность приложения.
Архитектура «клиент-сервер» позволяет устранить все указанные недостатки. Кроме того, она позволяет оптимальным образом распределить вычислительную нагрузку между клиентом и сервером, что также влияет на многие характеристики системы: стоимость, производительность, поддержку.
Виды клиент-серверных архитектур
Процесс разработки клиент –серверных систем достаточно сложен и одной из наиболее важных задач является решение о том, как функциональность приложения должна быть распределена между клиентской и серверной частью. Пытаясь решить эту задачу, разработчики получают двухзвенные, трехзвенные и многозвенные архитектуры. Все зависит от того, сколько промежуточных звеньев включается между клиентом и сервером.
Основная задача, которую решает клиентское приложение, — это обеспечение интерфейса с пользователем, т. е. ввод данных и представление результатов в удобном для пользователя виде, и управление сценариями работы приложения.
Основные функции серверной СУБД — обеспечение надежности, согласованности и защищенности данных, управление запросами клиентов, быстрая обработка SQL-запросов.
Каждое приложение базы данных состоит из трех отдельных компонент:
1.Службы базы данных (database services). Это – конечный сервер базы данных и данные, которые размещены в этой базе данных.
2.Службы приложения (application services). Это – механизмы манипулирования данными, извлекаемыми из базы данных. Логика их работы определяется приложением или потребностями бизнеса.
3.Службы представления (presentation services). Это – пользовательский интерфейс. Службы представления должны быть способными манипулировать данными таким образом, чтобы это было понятно пользователям.
Различие между однозвенной, двухзвенной и трехзвенной архитектурами зависит от того, каким образом разделяются на части эти компоненты. В однозвенной архитектуре они все являются частями одной программы. В двухзвенной архитектуре эти компоненты разделены на две отдельные части. В трехзвенной архитектуре компоненты разделены на три отдельные части.

Рис.1. Различия между однозвенной, двухзвенной и трехзвенной архитектурами
Однозвенная архитектура
Однозвенная (one-tier, single-tier) архитектура – это система, в которой все службы базы данных, приложения и представления (пользовательский интерфейс) размещены на одной системе. Системы такого типа не производят обработку вне тех компьютеров, на которых они исполняются. Примером однозвенной архитектуры может служить база данных Microsoft Аccess с локальными службами представления.
Пример однозвенной архитектуры с SQL Server найти гораздо труднее.
Двухзвенная архитектура
В двухзвенных приложениях службы представления и база данных размещаются на разных системах (компьютерах). Уровень служб представления (пользовательский интерфейс) обычно включает в себя логику работы приложения. Хорошим примером двухуровневого приложения является приложение, использующее SQL Server Enterprise Manager. У таких приложений пользовательский интерфейс и логика работы приложения размещаются в Enterprise Manager, но все данные, необходимые для функционирования приложения, находятся в базе данных SQL Server на другом компьютере.
Двухзвенные приложения встречаются чаще всего. Эти приложения обычно написаны на языках, поддерживающих API (интерфейсы прикладного программирования) для Windows, таких, как Microsoft Visual C++ или Visual Basic. При помощи двухзвенных приложений каждый пользователь может иметь одно или несколько соединений с базой данных SQL Server. Данная архитектура может стать неэффективной из-за того, что большинство этих соединений будут простаивать большую часть времени.
Трехзвенная архитектура
В трехзвенных приложениях уровень базы данных, уровень приложения и уровень служб представления выделены в три разные компоненты. В типичных трехзвенных приложениях используется промежуточный уровень для обслуживания многочисленных соединений от уровня служб представления, благодаря чему уменьшается количество соединений с SQL Server. Кроме того, этот промежуточный уровень может выполнять значительный объем работы, связанной с реализацией специфики целевых задач (логики предметной области), освобождая базу данных для решения тех задач, которые она выполняет лучше всего, – для доставки требуемых данных.
Клиент-серверная система SQL Server
Система SQL Server может быть реализована либо как клиент-серверная система, либо как автономная "настольная" система. Тип проектируемой системы зависит от количества пользователей, которые должны одновременно осуществлять доступ к базе данных, и от характера работ, которые должны выполняться. Клиент-серверная система SQLServer может иметь двухзвенную установку (two-tier setup) либо трехзвенную установку (three-tier setup). Независимо от варианта установки, программное обеспечение и базы данных SQL Server размещаются на сервере базы данных(database server).. Доступ пользователей к серверу базы данных производится при помощи приложений с компьютеров-клиентов (в двухзвенных системах) либо при помощи приложений, выполняющихся на специально предназначенном для этой цели компьютере, который называется сервер приложений(application server)- (в трехзвенных системах).
Вся логика работы приложения — прикладные задачи, бизнес-правила — в двухзвенной архитектуре распределяются разработчиком между двумя процессами: клиентом и сервером
В частности, в двухзвенных системах клиенты исполняли большую часть функций приложения, осуществляющие доступ к серверу базы данных через сеть, сервер занимался только обработкой SQL-запросов. Такие клиенты назывались толстыми (thick client), а архитектура получила название «толстый клиент — тонкий сервер». Двухзвенная установка полезна при относительно небольшом количестве пользователей
Появление возможности создавать на сервере хранимые процедуры, т. е. откомпилированные программы с внутренней логикой работы, привело к тенденции переносить все большую часть функций на сервер. Сервер становился все более "толстым", а клиент — "утоньшался". Такое решение имеет очевидные преимущества, например его легче поддерживать, т. к. все изменения нужно вносить только в одном месте — на сервере. Однако язык, на котором пишутся хранимые процедуры, не является достаточно мощным и гибким, чтобы на нем было удобно реализовывать сложную логику приложения.

Рис. 2. Распределение функций между клиентом и сервером
Тогда возникла тенденция поручить выполнение прикладных задач и бизнес-правил отдельному компоненту приложения (или нескольким компонентам), которые могут работать как на специально выделенном компьютере — сервере приложений, так и на том же компьютере, где работает сервер базы данных. Так возникли трехзвенные и многозвенные архитектуры "клиент-сервер". Появилось специальное программное обеспечение (ПО) промежуточного слоя, которое должно обеспечить совместное функционирование множества компонентов такого многокомпонентного приложения. В системах этого типа в задачи компьютеров-клиентов входит лишь исполнение программного кода по вызову функций с сервера приложений и отображение результатов доступа. Такие клиенты называются тонкими (thin client). Cервер приложений исполняет приложения, которые выполняют задачи, требующиеся для нужд предприятия, эти приложения являются многопотоковыми (multithreaded), благодаря чему с ними могут работать много пользователей одновременно. Cервер приложений соединяется с сервером базы данных, осуществляет доступ к данным и возвращает результаты клиенту.
Достоинством трехзвенной системы является то, что можно позволить серверу приложений организовывать все клиентские соединения с сервером базы данных, вместо того, чтобы разрешить каждому клиенту самостоятельно устанавливать соединения (такая самостоятельность может привести к нерациональному использованию ресурсов сервера базы данных). Этот подход называется организация пула соединений (connection pooling), при этом предполагается, что запросы клиентов помещаются в пул (или, говоря точно, в очередь, queue), в котором они будут дожидаться ближайшего доступного соединения.
Проектирование приложения для SQL Server
Приложение облегчает применение SQL Server, По выполняемым функциям. выделяют: системы оперативной обработки транзакций (OLTP, on-line transaction processing), системы поддержки принятия решений (DSS, decision support system) и системы пакетной обработки данных (batch processing). Эти функции имеют различные требования и могут применять совершенно разные типы приложений.
1. OLTP (системы оперативной обработки транзакций)
Особенностью систем оперативной обработки транзакций (OLTP) является одновременный оперативный доступ многих пользователей к данным. И что более важно, эти пользователи ждут отклика от системы. Системы OLTP могут иметь множество форм, среди которых следующие:
Онлайновые продажи. Этот вид систем OLTP получил широкое распространение из-за быстрого роста Интернет-коммерции. Покупая товары через Интернет, пользователям часто приходится терпеть задержки при передаче, доставке и обработке данных. Минимизируя длительность доступа к базе данных, можно уменьшить общую длительность транзакций.
Продажи в обычных магазинах. Когда кассир в магазине пробивает кредитную карточку, происходит доступ к базе данных. Прежде чем запрос достигнет базы данных, транзакция пройдет через множество компьютеров.
Системы для бизнеса. У каждой фирмы имеется какое-нибудь приложение для доступа к базам данных. Это может быть некая платежная система, система для закупок, база данных кадровой службы, система для учета имущества или еще какая-нибудь другая система. Такие приложения могут быть созданы как приложения для внутренней сети, реализованы на языках программирования вроде C++ или Microsoft Visual Basic, или при помощи инструментального средства – языка четвертого поколения (4GL). В любом случае, в конечном итоге, данные поступают из базы данных.
Все системы OLTP обладают одной общей особенностью – пользователь должен ждать от них ответа. В этом случае задача заключается в спроектировании системы, адекватно обслуживающей запросы пользователей за предусмотренное время ответа.
2. DSS (системы поддержки принятия решений)
Системы поддержки принятия решений (DSS) помогают пользователям принимать важные решения, касающиеся их бизнеса, они выдают специфические результаты, относящиеся к бизнесу. Вот некоторые примеры вопросов про бизнес, на которые могут отвечать системы поддержки принятия решений:
· Кто является основными продавцами в том или ином районе? Какие товары они преимущественно продают?
· В какое время года лучше всего продаются те или иные товары?
· Как влияло понижение цены на продажи того или иного товара?
· Каковы средние размеры комиссионных для продавцов в том или ином районе?
Системы поддержки принятия решений отличаются от систем оперативной обработки транзакций (OLTP) тем, что пользователи систем поддержки принятия решений ожидают ответа на сложные запросы, для которых требуется значительное время ответа. Время ответа на запросы к системам поддержки принятия решений может составить от нескольких секунд до минут и даже часов. Это не значит, что в системах поддержки принятия решений время ответа не играет роли, но здесь можно пойти на компромисс между пропускной способностью (производительностью для всех пользователей) и временем ответа (производительностью для отдельных пользователей).
3. Системы пакетной обработки данных
Системы пакетной обработки данных обрабатывают неоперативные (offline) задания обработки данных, не имеющие никаких компонент для работы с конечными пользователями. Вот типичные примеры таких систем:
· Ежедневное обновление данных. Для некоторых систем поддержки принятия решений требуется еженочная загрузка новых данных, и эта работа часто выполняется автоматически при помощи заданий пакетной обработки данных.
· Преобразование данных. Эта задача похожа на обновление данных, но сопровождается преобразованием данных.
· Очистка данных. При выполнении этой задачи происходит, например, удаление из базы данных дублирующихся записей.
· Автономное выписывание счетов. Эта задача может заключаться в еженощном выписывании счетов потребителям.
Системы для пакетной обработки обычно не имеют пользователей, ожидающих завершения заданий, но, как правило, они ограничены временными рамками, в пределах которых задачи должны быть завершены. Например, ночная загрузка данных не может захватывать время утренних входов в систему.
Основная архитектура приложения может принимать различные формы. Основные различия между архитектурами приложений состоят в количестве систем, участвующих в работе приложения. Эта классификация производится по количеству звеньев (tiers). Реклама многих наиболее популярных приложений основывается на количестве звеньев, которые могут в них содержаться.
Разработка проектов в Access
Проекты Microsoft Access предназначены для создания клиентских приложений, манипулирующих данными и структурой базы данных SQL Server.
Для доступа к серверным базам данных из приложений Access используется один из двух стандартных способов доступа к удаленным данным: ODBC или OLE DB. Достоинством Access как клиента к серверной базе данных является наличие мощных и простых средств для разработки интерфейса — форм, отчетов и страниц Web. Наиболее простым и перспективным способом создания приложений в архитектуре "клиент-сервер" являются проекты Microsoft Access 2002 — файлы с расширением adp. В отличие от файла базы данных Access файл проекта не содержит таблиц с данными. Все таблицы, с которыми работает клиентское приложение, размещаются на сервере базы данных, а файл проекта включает в себя только те объекты, которые создаются на базе этих таблиц: формы, отчеты, страницы, макросы и модули. Однако из проекта Access доступны не только таблицы, но и другие объекты сервера: представления (views), хранимые процедуры (stored procedures), схемы базы данных (database diagrams). Доступ к этим объектам выполняется посредством OLE DB — универсального интерфейса, разработанного фирмой Microsoft для доступа к данным произвольного типа как реляционным, так и нереляционным.
В качестве сервера базы данных в проектах Access 2002 может быть использован либо Microsoft SQL Server версии 6.5 и выше, либо настольная (desktop) версия Microsoft SQL Server 2000.
Замечание
В Access 2002 сохранилась возможность создавать интерфейс к серверным базам данных не только в проектах, но и в базах данных через присоединенные таблицы, используя доступ к серверу с помощью драйверов ODBC
Универсальный доступ к данным через OLE DB
Интерфейс ODBC был первым средством, которое обеспечило универсальный доступ к данным реляционного типа посредством SQL-запросов. Однако реляционные базы данных не единственный формат хранения данных, а современные приложения требуют интеграции информации из разных источников, не только SQL-ориентированных. Отсюда возникает потребность либо перевести все данные в единый формат, т. е. создать универсальную базу данных, что очень дорого и неэффективно, либо обеспечить универсальный доступ к данным разных типов без необходимости их преобразовывать и реплицировать.
OLE DB представляет собой разработанный фирмой Microsoft набор интерфейсов OLE, обеспечивающих унифицированный доступ приложений к данным из разнообразных источников, включая текстовые файлы, файлы электронной почты, электронные таблицы, данные мультимедиа и пр.
Основные отличия OLE DB от ODBC состоят в следующем:
· OLE DB обеспечивает доступ к данным произвольных типов, а не только реляционным;
· OLE DB не является набором функций, а представляет собой набор интерфейсов, построенных в соответствии с компонентной моделью объектов (СОМ).
Общие сведения
Архитектура приложения, использующего интерфейсы OLE DB для доступа к данным, представлена на рис. 3. Эта архитектура является многокомпонентной. Компоненты доступа к данным делятся на три категории: потребители, провайдеры и сервисные компоненты.
Потребители данных (Data Consumer) — это любое приложение или компонент, которые используют интерфейсы OLE DB для доступа к данным.
Провайдеры данных (Data Provider) — это компоненты, которые обеспечивают потребителям доступ к данным через строго специфицированный набор интерфейсов. Они взаимодействуют с данными и представляют их единообразно в табличном виде, используя абстракцию, называемую набор рядов (rowsef).
 |
Рис. 3. Архитектура универсального доступа к данным
Сервисы (Services) — это дополнительные компоненты, которые обеспечивают функции, не реализованные провайдером OLE DB. Они являются как потребителями OLE DB данных, так и провайдерами. Примером сервиса может быть процессор запросов, который может объединять табличную информацию от разных OLE DB провайдеров и обеспечивать доступ к результирующим данным через OLE DB-интерфейс.
Функционирование компонентов может реализовываться как разными процессами, так и на разных компьютерах через сетевые протоколы, такие как DCOM (Distributed Component Object Model — Распределенная компонентная модель объектов) или HTTP. При этом для выполнения распределенных транзакций может использоваться координатор распределенных транзакций, например Microsoft Transaction Server (MTS).
Компоненты OLE DB
В OLE DB определена иерархия компонентов, каждый из которых является СОМ-объектом (рис. 2).
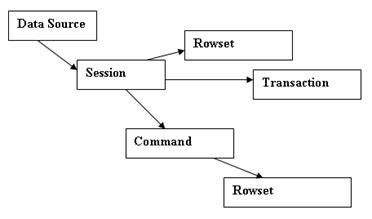
Рис. 2. Объекты — компоненты OLE DB
· Источники данных (Data Source) — объекты, которые реализуют подключение к источнику данных: Они определяют нужный OLE DB-провайдер, проверяют права доступа потребителя данных и инициируют соединение с источником данных.
· Сеансы (Sessions) — объекты, которые реализуют функции поддержки соединения с источником данных. Они предоставляют контекст для выполнения транзакций и команд. Основная цель сеанса — установить рамки транзакции. Один объект — источник данных может поддерживать несколько сеансов, а значит, и несколько транзакций.
· Транзакции (Transactions) — объекты, которые обеспечивают реализацию механизма транзакций. Они предоставляют методы для того, чтобы начать транзакцию для сеанса или новую транзакцию внутри текущей и подтвердить или отменить транзакцию самого нижнего уровня.
· Команды (Commands) — объекты, которые реализуют выполнение действий с данными (например, запросов). Команды порождаются сеансом, и в одном сеансе можно создать несколько команд.
· Наборы рядов (Rowsets) — объекты, которые предоставляют данные в табличной форме. Они порождаются либо сеансом, либо командой в качестве результата ее выполнения. Непосредственно из сессии можно создать набор рядов, содержащий все данные таблицы. Для реализации такого простого запроса не требуется команды. В остальных же случаях для создания набора рядов используются команды.
Microsoft ActiveX Data Objects (ADO)
Хотя OLE DB является очень мощным интерфейсом для работы с данными, этот интерфейс является низкоуровневым. Для удобства работы с OLE DB, так же как и для ODBC, была разработана объектная модель, которую назвали ADO (ActiveX Data Objects). ADO является общей программной моделью для работы с данными различных типов. Она разрабатывалась специально для того, чтобы заменить все другие интерфейсы работы с данными. Модель включила ряд возможностей других известных объектных моделей (DAO и RDO), хотя и не полностью..
· Так как ADO реализована на базе СОМ-объектов, то она может быть использована в любом языке, который может работать с СОМ-объектами, в том числе и в VBA.
· ADO обеспечивает доступ к любому OLE DB источнику данных, для которого имеется OLE DB провайдер, и, более того, она позволяет расширить функциональность провайдера.
· ADO реализована таким образом, чтобы минимизировать сетевой трафик в интернет-приложениях и сократить число промежуточных слоев между фронтальным (клиентским) приложением и источниками данных. Это требуется для того, чтобы сделать интерфейс как можно более легким и высокопроизводительным.
Установка связи с источником данных посредством интерфейса OLE DB
При установке на компьютере Microsoft Office XP или отдельного приложения Access 2002 автоматически устанавливаются следующие провайдеры OLE DB:
· Microsoft Jet 4.0 OLE DB Provider;
· Microsoft OLE DB Provider for SQL Server;
· OLE DB Provider for ODBC Drivers;
· OLE DB Provider for Oracle.
Для того чтобы посмотреть, какие провайдеры OLE DB установлены на вашем компьютере, необходимо открыть диалоговое окно Data Link Properties. Это окно открывается при создании или редактировании специальных файлов — Microsoft Data Link или файлов UDL (universal data link), в которых хранится информация о конкретном источнике данных OLE DB (тип провайдера OLE DB, сервер, на котором размещаются данные, база данных или файл, в котором они хранятся).
Работа с SQL-сервером
Основные объекты структуры базы данных SQL-сервера
Логически данные в SQL Server организованы в виде следующих объектов:
Tables- | таблицы базы данных, в которых хранятся собственно данные |
Views | Просмотры (виртуальные таблицы) для отображения данных из таблиц |
Stored Procedures | Хранимые процедуры |
Triggers | Триггеры – специальные хранимые процедуры, вызываемые при изменении данных в таблице |
User Defined function | Создаваемые пользователем функции |
Indexes | Индексы – дополнительные структуры, призванные повысить производительность работы с данными |
User Defined Data Types | Определяемые пользователем типы данных |
Keys | Ключи – один из видов ограничений целостности данных |
Constraints | Ограничение целостности – объекты для обеспечения логической целостности данных |
Users | Пользователи, обладающие доступом к базе данных |
Roles | Роли, позволяющие объединять пользователей в группы |
Rules | Правила базы данных, позволяющие контролировать логическую целостность данных |
Defaults | Умолчания или стандартные установки базы данных |
Таблицы. Все данные в SQL содержатся в объектах, называемых таблицами. Таблицы представляют собой совокупность каких-либо сведений об объектах, явлениях, процессах реального мира. Никакие другие объекты не хранят данные, но они могут обращаться к данным в таблице. Таблицы в SQL имеют такую же структуру, что и таблицы всех других СУБД и содержат:
• cтроки; каждая строка (или запись) представляет собой совокупность атрибутов (свойств) конкретного экземпляра объекта;
• cтолбцы; каждый столбец (поле) представляет собой атрибут или совокупность атрибутов. Поле строки является минимальным элементом таблицы. Каждый столбец в таблице имеет определенное имя, тип данных и размер.
Представления. Представлениями (просмотрами) называют виртуальные таблицы, содержимое которых определяется запросом. Подобно реальным таблицам, представления содержат именованные столбцы и строки с данными. Для конечных пользователей представление выглядит как таблица, но в действительности оно не содержит данных, а лишь представляет данные, расположенные в одной или нескольких таблицах. Информация, которую видит пользователь через представление, не сохраняется в базе данных как самостоятельный объект.
Хранимые процедуры. Хранимые процедуры представляют собой группу команд SQL, объединенных в один модуль. Такая группа команд компилируется и выполняется как единое целое.
Триггеры. Триггерами называется специальный класс хранимых процедур, автоматически запускаемых при добавлении, изменении или удалении данных из таблицы.
Функции. Функции в языках программирования – это конструкции, содержащие часто исполняемый код. Функция выполняет какие-либо действия над данными и возвращает некоторое значение.
Индексы. Индекс – структура, связанная с таблицей или представлением и предназначенная для ускорения поиска информации в них. Индекс определяется для одного или нескольких столбцов, называемых индексированными столбцами. Он содержит отсортированные значения индексированного столбца или столбцов со ссылками на соответствующую строку исходной таблицы или представления. Повышение производительности достигается за счет сортировки данных. Использование индексов может существенно повысить производительность поиска, однако для хранения индексов необходимо дополнительное пространство в базе данных.
Пользовательские типы данных. Пользовательские типы данных – это типы данных, которые создает пользователь на основе системных типов данных, когда в нескольких таблицах необходимо хранить однотипные значения; причем нужно гарантировать, что столбцы в таблице будут иметь одинаковый размер, тип данных и чувствительность к значениям NULL.
Ограничения целостности. Ограничения целостности – механизм, обеспечивающий автоматический контроль соответствия данных установленным условиям (или ограничениям). Ограничения целостности имеют приоритет над триггерами, правилами и значениями по умолчанию. К ограничениям целостности относятся: ограничение на значение NULL, проверочные ограничения, ограничение уникальности (уникальный ключ), ограничение первичного ключа и ограничение внешнего ключа. Последние три ограничения тесно связаны с понятием ключей.
Правила. Правила используются для ограничения значений, хранимых в столбце таблицы или в пользовательском типе данных. Они существуют как самостоятельные объекты базы данных, которые связываются со столбцами таблиц и пользовательскими типами данных. Контроль значений данных может быть реализован и с помощью ограничений целостности.
Введение в Transact – SQL
Transact-SQL — это язык баз данных, поддерживаемый SQL Server ХХХ. Transact-SQL соответствует стандарту SQL-92 начального уровня, а также поддерживает некоторые функции промежуточного и полного уровней. Transact-SQL также содержит некоторые мощные расширения по сравнению со стандартом SQL-92. Расширения определены в спецификации ODBC и поддерживаются OLE DB.
Transact-SQL — это язык, команды которого позволяют администрировать SQL Server, создавать любые его объекты и управлять ими, а также добавлять, извлекать, модифицировать и удалять данные из таблиц SQL Server. Transact-SQL представляет собой расширение языка, определенного стандартами SQL. Эти стандарты опубликованы организациями ISO (International Organization for Standardization) и ANSI (American National Standards Institute).
Transact – SQL включает следующие средства:
1. данные различного типа баз данных и переменных;
2. константы, стандартные и ограниченные идентификаторы;
3. арифметические и логические выражения, включающие следующие операнды: константы, переменные, имена столбцов таблиц, функции, подзапросы и условные выражения, а также выражения, взятые в круглые скобки;
4. SQL – команды для создания, изменения и удаления баз данных и их объектов, а также для определения запросов на ввод, обработку и извлечение данных;
5. управляющие программные структуры, определяющие условия и порядок выполнения команд в заданной последовательности или пакете команд;
6. встроенные (системные) и определяемые пользователем функции;
7. встроенные (системные) и определяемые пользователем хранимые процедуры.
В системе могут храниться, помимо функций и процедур, последовательности (пакеты) команд, которые называются скриптами. Если скрипт описывает процесс создания базы данных, или каких-либо ее объектов, то такой скрипт называется сценарием. Сценарии позволяют переносить структуру базы данных от одного сервера к другому, а также структуру таблиц и других объектов в различные базы данных. Скрипты хранятся в текстовых файлах. Функции и хранимые процедуры баз данных позволяют уменьшить объем запросов, передаваемых от клиента к серверу, что повышает общую производительность системы. Наличие исходного кода для этих объектов позволяет упростить сопровождение программных комплексов и внесение изменений в них. Обычно все бизнес – правила и алгоритмы обработки данных реализуются на сервере баз данных и доступны конечному пользователю в виде набора функций и хранимых процедур, которые и представляют интерфейс обработки данных. Для обеспечения целостности данных, а также в целях безопасности, приложению обычно не предоставляется прямой доступ к данным. Вся работа ведется с помощью указанного интерфейса.
Подобный подход делает весьма простым изменение алгоритмов обработки данных и обеспечивает возможность расширения системы без внесения изменений в само приложение. Достаточно изменить хранимую процедуру на сервере баз данных, и сделанные изменения тотчас станут доступными всем пользователям сети.
В языке Transact – SQL имеются следующие виды констант:
1. битовые: 0 и 1;
2. логические: FALSE и TRUE;
3. бинарные в шестнадцатеричном представлении: 0*9E70DA;
4. символьные: ‘ABC’; “ABC” (если QUOTED_IDENTIFIER = OFF); N ‘ABC’
(Unicode); N “ABC” (Unicode);
5. целые: 1; 2; 175;
6. с фиксированной точкой: 12.35; - 16.753;
7. с плавающей точкой: 1.75Е5; 3.84Е – 3;
8. для даты: “ April 15.2003”; “4/15/2003”; “”;
9. для времени: 14:30; 14:30:20:999; 4am; 4pm;
10. денежные: $100;?200; 2.15.
Комментарии в языке бывают двух типов: сточные, начинающиеся с двух символов минуса – и блочные, заключаемые символами /* и */.
Все объекты базы данных должны иметь имена, которые используются в командах для ссылки на эти объекты. Любой объект базы данных должен быть уникально идентифицирован.
Помимо программных имен сервер автоматически генерирует внутренние уникальные имена для идентификации объектов баз данных, например, PK_ _Table X_ _ 014543FA.
Программные имена задаются идентификаторами двух типов:
1. стандартными идентификаторами: Table X; Key Col;
2. ограниченными идентификаторами: [My Table]; [Order]; “My Table”; “Order” (если QUOTED_IDENTIFIER = ON).
Длина идентификатора – от 1 до 128 символов. Идентификатором не может быть какое-либо зарезервированное ключевое слово языка.
Стандартный идентификатор в качестве первого символа может иметь любую латинскую или русскую букву, знаки #, ##, @, @@ и знак подчеркивания _. Последующими знаками, помимо указанных, могут быть еще и десятичные цифры.
Ограниченные идентификаторы могут включать и другие символы, в том числе зарезервированные слова. В этом случае они должны заключаться в квадратные скобки или двойные кавычки.
В соответствии с идеологией SQL Server 2000 каждый объект создается определенным пользователем и принадлежит той или иной базе данных. В свою очередь база данных расположена на конкретном сервере. Из имен объекта, пользователя, базы данных и сервера создается полное имя (complete name) или полностью определенное имя (full qualified name), записываемое в следующем виде:
[[[server.].[database].[owner_name].] object_name.
Варианты обращения к объектам базы данных: A. B.C. D; A. B..D; A..C. D; A..D; B. C.D; B..D; C. D; D.
Чтобы сослаться на конкретный столбец таблицы или представления, необходимо в полном имени указать пятый элемент: А. В.С. D.E.
В Transact – SQL существует несколько способов передачи данных между командами. Одним из таких способов является передача данных через локальные переменные, объявляемые следующим образом:
DECLARE {@ имя локальной переменной тип данных}[,…n]
Таким образом, знак @ является признаком имени локальной переменной. Этот же знак используется для определения имен параметров функций и хранимых процедур. Часть синтаксиса [,…n]означает повторение синтаксической конструкции, взятой в фигурные скобки:
DECLARE @Ivar int,
DECLARE @IBit bit
Значения переменным можно присвоить с помощью команд SET и SELECT. Командой SET можно присвоить значение только одной переменной:
SET @Ivar = 5
SET @IBit = 0
Для присваивания значений нескольким переменным, вычисляемых с помощью выражений, следует использовать команду SELECT:
SELECT @Ivar = SUM (price) FROM titles.
Для вывода значений переменных следует использовать команды:
SELECT – для вывода данных в стандартный набор строк;
PRINT – для вывода данных как служебной информации.
Примеры вывода значений переменных:
SELECT @Ivar _ _ в окно Grids утилиты Query Analyzer;
PRINT @IBit _ _ в окно Messages утилиты Query Analyzer.
Константы, переменные и параметры функций и хранимых процедур, вызовы функций, имена столбцов и подзапросы являются операторами арифметических и логических выражений..
Операторами выражения могут быть унарные (+ и - ), бинарные арифметические операторы (+, -, *, % ), оператор присваивания (=), строковая операция конкатенации (+), операторы сравнения (=, >, <, <=, >=, =, != или <>, !<, !>), логические операторы (NOT, AND, OR, ALL, ANY, BETWEEN, EXIST, IN, LIKE, SOME ) и битовые операторы (&, |, ^).
Константы, переменные, операнды и выражения используются при записи команд и программирования функций и хранимых. Команды позволяют создавать, модифицировать и удалять базы данных и их объекты, формировать сложные запросы на ввод, обработку и извлечение данных из баз знаний, выполнять функции администрирования и обслуживания баз данных. Функции и хранимые процедуры реализуют разнообразные алгоритмы обработки данных или выполнение служебных функций сервера.
При формировании запросов очень часто используются специальные логические операторы, синтаксис которых записывают следующим образом:
1. Выражение {= | < > | ! = | > | >= | ! >|, = | !<} ALL подзапрос.
Здесь скалярное выражение вычисляется и сравнивается с каждым значением, возвращаемым подзапросом. Если сравнение дает истину для всех возвращаемых подзапросом значений, то этот оператор возвращает истину.
2. Если вместо ALL записать SOME или ANY, то результатом будет истина, если хотя в одной строке будет выполняться заданное сравнение.
3. Выражение
[NOT] BETWEEN А «Выражение» AND В «Выражение»
возвращает истину, когда значение выражения лежит в диапазоне значений А выражения и В Выражения (или не лежит).
4. Оператор EXISTS (подзапрос) возвращает значение истина, если подзапрос возвращает хотя бы одну строку.
5. Выражение [NOT] IN (подзапрос \ выражение [,…n]) возвращает значение истина, если значение левого выражения совпадает с одним из значений подзапроса или списка значений правых выражений (или не совпадает).
6. Выражение [NOT] LIKE шаблон [ESCAPE знак] дает истину, если значение выражения соответствует или не соответствует шаблону, в котором “%” означает любое количество произвольных символов, “_” – один произвольный символ, “[символы]” – один из указанных в скобках, “[^ символы]” – все символы, кроме указанных. Знак после слова ESCAPE позволяет указать, что следующий за ним знак шаблона не является управляющим знаком шаблона, т. е. знаком “%”, “_” и т. д., а представляет обычный знак строки.
Использование выражения CASE…END – для реализации условного выражения с несколькими альтернативами - CАSE…WHEN…WHEN…ELSE…END.
Оценка списка условий и возвращение одного из нескольких возможных выражений результатов.
Выражение CASE имеет два формата:
1. простое выражение CASE для определения результата, которое сравнивает выражение с набором простых выражений;
Синтаксис:
CASE input_expression
WHEN when_expression THEN result_expression
[ ...n ]
[ELSE else_result_expression
END
2. поисковое выражение CASE для определения результата, которое вычисляет набор логических выражений.
Синтаксис:
CASE
WHEN Boolean_expression THEN result_expression
[ ...n ]
ELSE else_result_expression
END
Оба формата поддерживают дополнительный аргумент ELSE.
Выражение CASE может использоваться в любой инструкции или предложении, которые допускают допустимые выражения. Например, выражение CASE можно использовать в таких инструкциях, как SELECT, UPDATE, DELETE и SET, а также в таких предложениях, как select_list, IN, WHERE, ORDER BY и HAVING.
Например, CASE Город WHEN ‘СПб’ THEN СуммаСтипендии * 2 ELSE СуммаСтипендии / 2 END
Не используется в качестве оператора управления потоком!
Использование операций EXISTS и NOT EXISTS
Ключевые слова EXISTS и NOT EXISTS предназначены для использования только совместно с подзапросами. Результат их обработки представляет собой логическое значение TRUE или FALSE. Для ключевого слова EXISTS результат равен TRUE в том и только в том случае, если в возвращаемой подзапросом результирующей таблице присутствует хотя бы одна строка. Если результирующая таблица подзапроса пуста, результатом обработки операции EXISTS будет значение FALSE. Для ключевого слова NOT EXISTS используются правила обработки, обратные по отношению к ключевому слову EXISTS. Поскольку по ключевым словам EXISTS и NOT EXISTS проверяется лишь наличие строк в результирующей таблице подзапроса, то эта таблица может содержать произвольное количество столбцов.
Пример. Определить список имеющихся на складе товаров
SELECT Название
FROM Товар
WHERE EXISTS (SELECT КодТовара
FROM Склад
WHERE Товар. КодТовара=Склад. КодТовара)
Пример. Определить список отсутствующих на складе товаров
SELECT Название
FROM Товар
WHERE NOT EXISTS (SELECT КодТовара
FROM Склад
WHERE Товар. КодТовара=Склад. КодТовара)
Оператор INSERT (Вставка строк)
Оператор INSERT используется для добавления новой строки или строк в таблицу или представление. Ниже показан основной синтаксис для оператора INSERT:
INSERT [INTO] имя_таблицы [(список_колонок)] VALUES
выражение | производная_таблица
Ключевое слово INTO и параметр список_колонок не являются обязательными. Параметр список_колонок указывает, в какие колонки помещаются данные; эти значения имеют взаимнооднозначное соответствие (по порядку) со значениями, указанными в выражении (которое может быть просто списком значений). Рассмотрим некоторые примеры.
В следующем примере показано, как вставить одну строку данных в таблицу Товары:
INSERT INTO Товары
(КодТовара, Наименование, Цена)
VALUES (333, Компьютерные игры', 200)
Оператор UPDATE (обновить данные в поле)
Оператор UPDATE используется для модифицирования или обновления существующих данных. Ниже показан синтаксис оператора UPDATE:
UPDATE имя_таблицы SET имя_колонки = выражение
[FROM источник_для_таблицы] WHERE условие_поиска
UPDATE Товары SET Цена = Цена * 2
WHERE Товары. Наименование = ‘Компьютерные игры’
Оператор DELETE (удалить данные)
Оператор DELETE используется для удаления строки или строк из таблицы или представления. DELETE не влияет на определение таблицы; он просто удаляет из таблицы строки данных. Ниже показан синтаксис для оператора DELETE:
DELETE [FROM] имя_таблицы | имя_представления
[FROM источники_для_таблицы] WHERE условие_поиска
Первое ключевое слово FROM не является обязательным, как и второе предложение FROM. Строки не удаляются из источников для таблицы во втором предложении FROM; они удаляются только из таблицы или представления, указанного после DELETE.
Удаление отдельных строк
Используя предложение WHERE вместе с DELETE, можно указывать определенные строки для удаления из таблицы. Например,
удалить из таблицы Товары все строки со значением Игрушка в столбце Наименование,:
DELETE FROM Товары
WHERE Товар. Наименование = 'Игрушка'
Операторы управления потоком Transact –SQL
Для написания скриптов и программирования функций и хранимых процедур используются операторы управления потоком Transact –SQL, которые не являются частью языка запросов SQL, а служат для управления выполнением хранимых процедур:
1. BEGIN…END – для создания блока последовательных команд; требуется для операторов типа WHILE.
2. IF…ELSE – для определения условия выбора команды или блока.
3. WHILE …BREAK…CONTINUE – для организации и управления циклически выполняемых команд.
3. Declare – создает локальную переменную;
5. Execute – выполняет хранимую процедуру
6. Goto – безусловный переход к метке;
7. Return – прекращает выполнение процедуры;
8. Break – выход из цикла WHILE.
1. BEGIN…END
Синтаксис:
BEGIN
Блок операторов (один или более операторов (иснтр WHILE укций))
END
Используются как операторные скобки для выделения единого блока операторов, который может использоваться, например, в условном операторе. Последовательность операторов, заключенная в скобки begin и end, называется операторным блоком.
if (select avg(Цена) from Товары) < 1000
begin
update Товары
set Цена = Цена* 2
end
Операторный блок begin…end можно включать внутрь другого операторного блока begin…end.
2. IF…ELSE
Управляющая конструкция IF...ELSE используется для наложения условий, определяющих, какие операторы T-SQL нужно выполнить. Для IF...ELSE используется следующий синтаксис:
IF Булево_выражение
Оператор_T-SQL | блок_операторов
[ELSE[if булевское_выражение] Оператор_T-SQL | блок_операторов]
Булево выражение это выражение, значением которого является истина (TRUE) или ложь (FALSE). Оно может состоять из названий табличных столбцов и констант, соединенных арифметическими или булевскими операциями, или подзапросов, если эти подзапросы возвращают одно (скалярное) значение. Если булевское выражение содержит оператор выбора select, то этот оператор должен быть заключен в скобки и должен возвращать скалярное (невекторное) значение. Ключевое слово if (если), независимо от своего дополнения else (иначе), служит для указания условия, которое определяет нужно ли выполнять следующий оператор. Следующий оператор выполняется, если это условие истинно, т. е. если его значение равно TRUE (истина).
Ключевое слово else служит для указания альтернативного SQL оператора, который выполняется, если условие, указанное в конструкции if оказалось ложным (FALSE).
3. WHILE …BREAK…CONTINUE
Команда while (до тех пор, пока) используется для циклического (повторного) выполнения оператора или блока операторов. Операторы выполнятся до тех пор, пока истинно указанное условие.
Эта команда имеет следующий вид:
while булевское_выражение
оператор
Следующий скрипт объявляет переменную целого типа, задаёт ей значение и выполняет цикл используя её в качестве счётчика.
DECLARE @Counter INT
set @Counter = 10
while @Counter > 0
begin
SET @Counter = @Counter - 1
end
В следующем примере операторы select и update будут выполняться в цикле, пока средняя цена книги будет меньше 300:
while (select avg(Цена) from Книги) < 300
begin
select НомерКниги, Цена
from Книги
where Цена > 150
update Книги
set Цена = Цена* 2
end
Команды break (прервать) и continue (продолжить) управляют последовательностью выполнения операторов внутри цикла while. Команда break прекращает выполнение цикла. После этого управление передается оператору, следующему за ключевым словом end, которое указывает на конец цикла. Команда continue передает управление на начало цикла, поэтому все операторы, расположенные внутри цикла и следующие за этой командой, выполняться не будут. Командам break и continue часто предшествует проверка некоторого условия.
Синтаксис команд break и continue имеет следующий вид:
while булевское_выражение
begin
оператор
….
[оператор]
break
[оператор]
….
continue
….
[оператор]
end
Далее приводится пример использования команд while, break, continue и if, в котором производится действие, обратное инфляционному действию предыдущего примера. До тех пор пока средняя цена книги остается большей 300, все цены уменьшаются наполовину. Затем выбирается максимальная цена. Если она меньше 600, то происходит выход из цикла, в противном случае цикл выполняется снова. Команда continue не допустит выполнение оператора вывода (печати) print, если средняя цена меньше 300. После окончания цикла while в этом примере выводится список книг, чья цена превышает 300 рублей.
while (select avg(Цена) from Книги) > 300
begin
update Книги
set Цена = Цена / 2
if (select max(Цена) from Книги) <600
break
else
if (select avg(Цена) from Книги) >300
continue
print "Средняя цена от 300 до 600 рублей"
end
select КодКниги, Цена from Книги
where Цена > 300
defined Function).
Представления
Представлениями (просмотрами (View)) называют виртуальные таблицы, содержимое которых определяется запросом. Подобно реальным таблицам, представления содержат именованные столбцы и строки с данными, которые они динамически выбирают из таблиц и предлагают эти данные пользователю для просмотра. Для конечных пользователей представление выглядит как таблица, но в действительности оно не содержит данных, а лишь представляет данные, расположенные в одной или нескольких таблицах. Информация, которую видит пользователь через представление, не сохраняется в базе данных как самостоятельный объект.
Таким образом, представления – это виртуальные таблицы, определяемые запросом. К представлению можно применять операции SELECT, INSERT, UPDATE и DELETE. Представления часто применяются для ограничения доступа к конфиденциальным данным в таблицах баз данных. Когда в представление не включается столбец исходной таблицы, то считают, что на таблицу наложен вертикальный фильтр. Если в SQL – запросе установлено одно или несколько условий для выборки строк, то считают, что на таблицу наложен горизонтальный фильтр.
Представление может выбирать данные из других представлений, которые, в свою очередь, могут также основываться на представлениях или таблицах. Вложенность представлений не должна превышать 32. Представления можно создавать, используя базы данных одного сервера (текущего). Максимальное количество столбцов в представлении равно 1024. Представление не может ссылаться на временные таблицы. Кроме того, нельзя создавать временное представление. Для представления нельзя определить ограничения целостности, триггеры, правила, или умолчания, а также создать обычный или полнотекстовый индекс.
Преимущество использования представлений заключается в том, что можно создавать представления с различными атрибутами без необходимости дублирования данных. Представления полезны в целом ряде ситуаций. Одним из преимуществ использования представлений является то, что они всегда содержат самые свежие данные. Оператор SELECT, определяющий представление, выполняется только при доступе к этому представлению, поэтому все изменения, внесенные в базовые таблицы представления, отражаются в этом представлении.
Для представления нельзя определить ограничения целостности, триггеры, правила, или умолчания, а также создать обычный или полнотекстовый индекс.
В основном представления используются для выборки данных. Однако с помощью представлений можно выполнять и изменение данных в таблицах, на основе которых построено представление, при этом требуется соблюдение ряда правил: представление должно содержать, как минимум, одну таблицу в параметре FROM команды SELECT, не разрешается использование функций агрегирования и др.
Как и для таблиц, для представлений можно определить следующие права доступа:
SELECT – просмотр данных;
INSERT – добавление данных через представления;
UPDATE – изменение данных в исходных таблицах;
DELETE –удаление данных в исходных таблицах.
Хранимые процедуры
Хранимая процедура — основное средство программирования серверной логики - это подпрограмма, состоящая из SQL операторов и команд языка управления заданиями. Она представляет собой откомпилированный модуль, написанный на языке Transact-SQL. В коде хранимой процедуры можно использовать не только операции выборки и модификации данных, но и логику ветвления, переменные, вызовы других процедур и некоторые другие средства, характерные для языков программирования высокого уровня.. Хранимая процедура может:
· содержать параметры (аргументы);
· вызывать другие процедуры;
· возвращать свой статус вызывающей процедуре или пакету, указывающий на успешное окончание или ошибку, и в случае ошибки на ее причину;
· возвращать значения параметров вызывающей процедуре или пакету;
· выполняться на удаленном SQL сервере.
Код процедуры синтаксически анализируется при компиляции, а оптимизированный план выполнения создается при первом вызове процедуры. В отличие от запросов, хранимые процедуры имеют возможность возвращать несколько наборов записей, а также значения.
Хранимые процедуры отличаются от обычных SQL операторов и пакетов SQL операторов тем, что они заранее компилируются. Во время первого исполнения процедуры процессор запросов SQL Сервера анализирует процедуру и готовит план выполнения, который хранится в системной таблице. Впоследствии, процедура выполняется в соответствии с сохраненным планом. Поскольку основная часть обработки запросов при этом уже была выполнена, то сохраненные процедуры выполняются почти мгновенно.
Для вызова процедуры клиентская программа или другая процедура должны указать имя выполняемой процедуры и передать ей набор входных параметров.
Имеется три типа хранимых процедур:
- системные хранимые процедуры, расширенные хранимые процедуры и простые определяемые пользователем хранимые процедуры. Системные хранимые процедуры предоставляет SQL Server, и они имеют префикс sp_. Они используются для управления SQL Server и вывода на экран информации о базах данных и пользователях;
- расширенные хранимые процедуры являются динамически подключаемыми библиотеками (DLL), которые может динамически загружать и выполнять SQL Server. Обычно их пишут на C или C++, и они исполняют процедуры, внешние относительно SQL Server. Расширенные хранимые процедуры имеют префикс xp_;
-простые определяемые пользователем хранимые процедуры создаются пользователем и настраиваются для выполнения тех задач, которые требуются данному пользователю.
Хранимые процедуры значительно увеличивают мощность, эффективность и гибкость языка SQL. Скомпилированные процедуры значительно ускоряют выполнение SQL-операторов и пакетов. Кроме того, сохраненные процедуры могут выполняться на другом SQL сервере, если для обоих серверов допускается удаленная регистрация. Пользователь может написать триггер для своего локального SQL сервера, который вызывает процедуры на удаленном сервере, при локальном выполнении таких операторов как удаление, обновление или вставка.
Создание новой и изменение имеющейся хранимой процедуры осуществляется с помощью следующей команды:
<определение_процедуры>::=
{CREATE | ALTER } PROC[EDURE] имя_процедуры
[;номер]
[{@имя_параметра тип_данных } [VARYING ]
[=default][OUTPUT] ][,...n]
[WITH { RECOMPILE | ENCRYPTION | RECOMPILE,
ENCRYPTION }]
[FOR REPLICATION]
AS
sql_оператор [...n]
Номер в имени – это идентификационный номер хранимой процедуры, однозначно определяющий ее в группе процедур. Для удобства управления процедурами логически однотипные хранимые процедуры можно группировать, присваивая им одинаковые имена, но разные идентификационные номера.
Для передачи входных и выходных данных в создаваемой хранимой процедуре могут использоваться параметры, имена которых, как и имена локальных переменных, должны начинаться с символа @. В одной хранимой процедуре можно задать множество параметров, разделенных запятыми.
Наличие ключевого слова OUTPUT означает, что соответствующий параметр предназначен для возвращения данных из хранимой процедуры. Однако это вовсе не означает, что параметр не подходит для передачи значений в хранимую процедуру. Указание ключевого слова OUTPUT предписывает серверу при выходе из хранимой процедуры присвоить текущее значение параметра локальной переменной, которая была указана при вызове процедуры в качестве значения параметра.
Ключевое слово VARYING применяется совместно с параметром OUTPUT, имеющим тип CURSOR. Оно определяет, что выходным параметром будет результирующее множество.
Ключевое слово DEFAULT представляет собой значение, которое будет принимать соответствующий параметр по умолчанию. Таким образом, при вызове процедуры можно не указывать явно значение соответствующего параметра.
Параметр FOR REPLICATION востребован при репликации данных.
Ключевое слово ENCRYPTION предписывает серверу выполнить шифрование кода хранимой процедуры, что может обеспечить защиту от использования авторских алгоритмов, реализующих работу хранимой процедуры.
Ключевое слово AS размещается в начале собственно тела хранимой процедуры, т. е. набора команд SQL, с помощью которых и будет реализовываться то или иное действие. В теле процедуры могут применяться практически все команды SQL, объявляться транзакции, устанавливаться блокировки и вызываться другие хранимые процедуры. Выход из хранимой процедуры можно осуществить посредством команды RETURN
Выполнение хранимой процедуры
Для выполнения хранимой процедуры используется команда:
[[ EXEC [ UTE] имя_процедуры [;номер]
[[@имя_параметра=]{значение | @имя_переменной}
[OUTPUT ]|[DEFAULT ]][,...n]
Если вызов хранимой процедуры не является единственной командой в пакете, то присутствие команды EXECUTE обязательно. Более того, эта команда требуется для вызова процедуры из тела другой процедуры или триггера.
Использование ключевого слова OUTPUT при вызове процедуры разрешается только для параметров, которые были объявлены при создании процедуры с ключевым словом OUTPUT.
Когда же при вызове процедуры для параметра указывается ключевое слово DEFAULT, то будет использовано значение по умолчанию.
Пример 1 Процедура для уменьшения цены товара первого сорта на 10%
CREATE PROC my_proc2
AS
UPDATE Товар SET Цена=Цена*0.9
WHERE Сорт=’первый’
Процедура не возвращает никаких данных.
Использование параметров в хранимых процедурах
Хранимая процедура может использовать входные параметры, чтобы передавать данные в эту процедуру. Чтобы задать входные параметры в хранимой процедуре, необходимо указать список этих параметров с символом @ перед именем каждого параметра через запятую, т. е. @имя_параметра. В хранимой процедуре можно задать до 1024 параметров.
Процедура с входными параметрами
Пример 2.Создать процедуру для уменьшения цены товара заданного типа в соответствии с указанным %.
CREATE PROC my_proc4
@t VARCHAR(20), @p FLOAT
AS
UPDATE Товар SET Цена=Цена*(1-@p)
WHERE Тип=@t
Пример 3. Отобрать всех студентов, получивших пятерку по заданному предмету (предмет задается через параметр)
CREATE PROCEDURE Prosmotr @PredmetName char(50)
AS
SELECT dbo. Студент. фамилия, dbo. Студент. имя, dbo. Студент. отчество, dbo. Предмет. НаименованиеПредмета, dbo. Экзамен. Оценка
FROM dbo. Экзамен INNER JOIN
dbo. Студент ON dbo. Экзамен. КодСтудента = dbo. Студент. КодСтудента INNER JOIN
dbo. Предмет ON dbo. Экзамен. КодПредмета = dbo. Предмет. КодПредмета
WHERE dbo. Экзамен. Оценка = 5) AND (dbo. Предмет. НаименованиеПредмета = @PredmetsName)
Можно задать для параметра значение по умолчанию, которое будет использоваться, когда этот параметр не указан в обращении к процедуре
Триггеры
Триггер - это сохраненная процедура специального вида, которая предназначена для защиты ссылочной (referential) целостности данных, т. е. для отслеживания правил и соотношений, которым должны подчиняться данные из различных таблиц. Триггер активизируется, когда пользователь добавляет или модифицирует (изменяет) данные с помощью операторов insert (вставить), delete (удалить) и update (обновить). Триггера могут вызывать локальные или удаленные сохраняемые процедуры или другие триггера. Глубина вложенности при вызове триггеров может достигать 16 уровней)
Когда пользователь пытается, например, изменить данные в таблице, сервер автоматически запускает триггер и, только если он завершается успешно, разрешается выполнение изменений. Все производимые триггером модификации данных рассматриваются как одна транзакция. В случае обнаружения ошибки или нарушении целостности данных происходит откат этой транзакции. Тем самым внесение изменений будет запрещено. Будут также отменены все изменения, уже сделанные триггером. Триггера особенно полезны в следующих ситуациях:
Триггер может “каскадно” вносить изменения во взаимосвязанные таблицы базы данных. Например, удаляющий триггер, связанный со столбцом №ЗачКнижки таблицы Студент, может также удалить соответствующие строки из таблицы Экзамен, используя значение в столбце №ЗачКнижки как уникальный ключ;
Триггер может запретить или “откатить” изменения данных, вызывающие нарушение ссылочной целостности, путем нейтрализации транзакции, которая вносит эти изменения. Такой триггер может запуститься, если пользователь попытается указать значение внешнего ключа, которое не совпадает с главным ключом. Например, пользователь может создать вставляющий триггер, связанный с таблицей Экзамен и откатывающий любые вставки строк, в которых значение в столбце №ЗачКнижки не совпадает ни с одним из значений в столбце Студент. №ЗачКнижки ;
Триггера могут отслеживать значительно более сложные ограничения по сравнению с правилами. В противоположность правилам, в триггерах можно ссылаться на табличные столбцы и объекты базы данных. Например, триггер может запретить увеличение цены книги, превосходящее один процент от аванса;
Триггера могут выполнять простейший “что, если” анализ. Например, триггер может сравнить состояние таблицы до и после модификации данных и предпринять некоторое действие, основанное на этом сравнении.
Синтаксис триггеров
Триггеры создаются с помощью оператора CREATE TRIGGER
CREATE TRIGGER ИмяТриггера
ON ИмяТаблицы
FOR {INSERT, UPDATE, DELETE}
AS
Операторы SQL
В предложении creat создается триггер и ему присваивается название. Это название должно удовлетворять правилам, установленным для идентификаторов. Имена триггеров должны быть уникальны в пределах базы данных. Каждый триггер может быть связан только с одной таблицей, но для каждой таблицы можно создать любое количество триггеров.
Предложении on указывается название таблицы, которая активизирует этот триггер. Эта таблица иногда называется триггерной таблицей
Предложение FOR определяет, когда вызывается данный триггер. Он может вызываться как для одной так и для нескольких операций. За ключевым словом AS следует тело триггера - операторы SQL, которые определяют триггерные условия или триггерные действия. В триггерных условиях задаются дополнительные критерии, которые определяют, надо ли после выполнения операторов вставки, удаления или обновления вызывать триггер или нет. Если в предложении if надо выполнить несколько операторов, то они должны быть заключены в операторные скобки begin и end.
Таблицы INSERTED и DELETED
Триггеры подобны процедурам обработки события Access BeforeUpdate, потому что вызываются непосредственно перед обновлением данных. Код триггера выполняется перед тем, как данные будут сохранены, но триггер видит таблицу, из которой вызывается в уже измененном состоянии.
SQL server поддерживает две специальные таблицы, с именами INSERTED и DELETED. В них он помещает копии вставляемых, изменяемых или удаляемых строк.
В ходе выполнения команд обновления, удаления или вставки данных SQL server выполняет над таблицами триггера и таблицами INSERTED и DELETED следующие операции:
- Перед вызовом Insert-триггера SQL server добавляет новые строки в таблицу триггера и еще одну их копию в таблицу INSERTED;
Перед вызовом Delete-триггера SQL server удаляет заданные строки из таблицы триггера и копирует их в таблицу Deleted;
Перед вызовом Update-иггера SQL server удаляет старые строки (заменяемые новыми данными) из таблицы триггера и копирует их в таблицу deleted. Тут же SQL server добавляет обновляемые строки в таблицу триггера и еще одну копию в таблицу Inserted.
Примечание. Значения таблиц inserted и deleted доступны только из триггера. После завершения работы триггера эти таблицы больше не доступны
Транзакции и оператор RAISEERROR
Триггер всегда выполняется внутри неявной транзакции. Единственный управляющий оператор транзакции ROLLBACK TRANSACTION
Например,
Create trigger primer
On dbo. tblMenu
For Insert, Update
As
If(select count(*) from inserted where prise<=0) >0
Begin
Raiserror 50001 ‘price must be greater than 0’
Rollback transaction
End
Оператор Raiserror имеет следующий синтаксис
Raiserror кодОшибки СообщениеОбОшибке
Код ошибки должен быть целым числом, а сообщение об ошибке строкой, которую выведет на экран клиент. Чтобы ваши коды не конфликтовали со строенными ошибками SQL server нужно назначать им значения выше 50000.
Обновление столбца
При необходимости выявить, обновлен ли конкретный столбец в ходе операции, для которой вызван триггер, можно воспользоваться специальной формой оператора IF
IF UPDATE (имя столбца) [{and |or } UPDATE (имя столбца) ]
В предложении if update (если обновление) проверяется, надо ли вставлять или обновлять данные в указанном табличном столбце. Условие в предложении if update проверяется на истинность, если название столбца присутствует в предложении set оператора update, даже в том случае, когда обновление не изменяет значение в этом столбце. Предложение if update не используется при удалении данных оператором delete. В этом предложении можно указать несколько столбцов и в одном операторе создания триггера можно поместить несколько предложений if update. Поскольку название таблицы указывается в предложении on, не следует указывать его перед названием столбца в предложении if update.
Например, предыдущий пример можно написать так
Create trigger primer1
On dbo. tblMenu
For Insert, Update
As
If update(Prise)
If(select count(*) from inserted where prise<=0) >0
Begin
Raiserror 50001 ‘price must be greater than 0’
Rollback transaction
End
Оператор If update особенно полезен в тех случаях, когда триггер обновляет данные в других таблицах.
Для получения информации о количестве строк, которое будет изменено при успешном завершении триггера, можно использовать функцию:
@@ROWCOUNT
Возвращает количество строк, которое было изменено последней командой.
В следующем примере триггер delstud предотвращает удаление строки с главным ключом, если значение этого ключа встречается в таблице Экзамен. Таким образом, этот триггер сохраняет возможность последующего выбора строк из таблицы Экзамен.
create trigger delstud
on Студент
for delete
as
if (select count(*)
from deleted, Экзамен
where Экзамен.№ЗачКнижки =
deleted. №ЗачКнижки) > 0
begin
rollback transaction
print "Невозможно удалить студента, в таблице Экзамен есть связанная запись."
end
Этот триггер соединяет удаляемые из таблицы строки Студент строки с таблицей Экзамен. Если произошло хотя бы одно соединение, то транзакция откатывается.
