
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Федеральное агентство по образованию
ГОУ ВПО «Уральский Государственный Технический Университет – УПИ»
Отчет по лабораторной работе
Компрессия данных. Метод Хаффмана.
Студент: ________________
Группа: ________________
Преподаватель:
Екатеринбург 2007
Содержание
Введение
Метод Хаффмана
Описание проделанной работы
Результаты работы программы
Выводы
Введение
В настоящее время существует огромное количество информации, причем со временем оно только растет. В связи с этим возникает проблема его компактного хранения и передачи в уменьшенном виде. Ведь в любом случае носители информации имеют какую-то свою определенную конечную емкость; бывают ситуации, когда этой емкости бывает недостаточно для хранения той или иной информации. Размер информации при ее передаче также так же имеет огромное значение: чем меньше размер – тем меньше времени требуется на передачу, тем меньше загруженность передающих сетей.
Увеличение объема носителей, пропускной способности сетей – всё это не решит проблему, т. к. размеры информации все время увеличиваются. Проблему можно решить, применяя сжатие, или так называемую архивацию информации.
На сегодняшний день существует достаточно много способов архивации данных. Все способы можно разделить на обратимые и необратимые. Под необратимым сжатием, или сжатием с потерями, подразумевают такое преобразование входного потока данных, при котором выходной поток представляет, с некоторой точки зрения, достаточно похожий по внешним характеристикам на входной поток объект, однако отличается от него объемом. Примером необратимого сжатия является кодирование музыки в формате mp3 (MPEG Layer 3). Сжатие этим форматом идет по нескольким направлениям. Во-первых, человеческое ухо устроено так, что оно не воспринимает звуковые сигналы, которые длятся менее 5 мс. Во-вторых, после громкого низкого звука тихие высокие также не воспринимаются некоторое время. Программа-кодировщик (обычно Lame Encoder) вычисляет места, не воспринимаемые человеком, и просто-напросто пропускает их. Такое «вырезание» неслышимых участков определяется битрейтом. Чем он меньше, тем больше идет обрезка. Также каждому звуку существует его аналог в виде последовательности битов. Можно существенно уменьшить размер, занимаемый звуковым файлом, если уменьшить размер образца. Стандартным является 16 бит в сэмпле. Также допускается 8 бит. Но в данном случае идет потеря качества, т. к. большая часть звуков заменяется их приближенными аналогами из звукового образца. Еще один способ уменьшить размер, занимаемый звуковым файлом – уменьшение частоты дискретизации. Обычному звуку качества компакт-диска соответствует частота 44100 Гц. То есть 44100 звуков в секунду. Естественно, можно уменьшить это число, но в этом случае также будет потеря качества.
Пример: Размер звукового файла без потерь (.wav) продолжительностью 1 минута будет занимать: 44100 сэмпл/с * 16 бит/сэмпл * 2 канала * 60с = бит = 10,09 МБ
Размер этого же файла со сжатием mp3 и битрейтом 128 кбит/с будет занимать место: 128000 бит/с * 60 с = 7680000 бит = 0,92 МБ.
Итак, при незначительной потере качества сжатый аудио файл будет занимать место в 11 раз меньше, чем оригинал без потери качества.
Обратимым называется сжатие, которое приводит к снижению объема выходного потока информации без изменения его информативности, т. е. без потери информационной структуры. Из выходного потока, полученного после выполнения алгоритма обратимого сжатия, при помощи восстанавливающего или декомпрессирующего алгоритма, получается поток, в точности совпадающий с исходным. Для обратимого сжатия характерно наличие в архиве информации для восстановления. Это может быть дерево архивации, может быть и словарь, всё зависит от метода и способа архивации. Примером обратимого сжатия является сжатие архиваторами (форматы .rar. zip. cab и многие другие).
В своей лабораторной работе я постарался сам написать программу для архивации данных при помощи метода Хаффмана.
Метод Хаффмана
Метод Хаффмана широко используется при сжатии информации. В типичной ситуации выигрыш может составить от 20% до 90% в зависимости от типа файла. Алгоритм Хаффмана находит оптимальные коды символов, исходя из частоты встречаемости этих символов в сжимаемом файле.
Пусть в файле длины 100000 известны частоты символов. Нужно построить двоичный код, в котором каждый символ представляется в виде конечной последовательности битов, называемой кодовым словом. При использовании равномерного кода, в котором все кодовые слова имеют одинаковую длину, на каждый символ (из шести имеющихся) надо потратить как минимум три бита, например, a = 000, b = 001, …, f = 101. На весь файл уйдет 300000 битов. Нельзя ли уменьшить это число?
Неравномерный код будет экономнее, если часто встречающиеся символы закодировать короткими последовательностями битов, а редко встречающиеся – длинными. Например, буква a изображается однобитовой последовательностью 0, а буква f – четырехбитовой последовательностью 1100. При такой кодировке на весь файл уйдет (45*1 + 13*3 + 12*3 + 16*3 + 9*4 + 5*4)*1000 = 224000 битов, что дает около 25% экономии.
a | b | c | d | e | f | |
Количество в тысячах | 45 | 13 | 12 | 16 | 9 | 5 |
Равномерный код | 000 | 001 | 010 | 011 | 100 | 101 |
Неравномерный код | 0 | 101 | 100 | 111 | 1101 | 1100 |
При кодировании каждый символ заменяется на свой код. Например, для неравномерного кода строка abc запишется как 0101100. Для такого кода декодирование будет однозначным и выполняется слева направо. Первый символ текста определяется однозначно, т. к. кодирующая его последовательность не может быть началом кода какого-то иного символа. Найдя этот первый символ и отбросив кодировавшую его последовательность битов, мы повторяем процесс для оставшихся битов, и так далее. Например, строка при использовании неравномерного кода разбивается на части 0.0.101.1101 и декодируется как aabe.
Для эффективной реализации декодирования надо хранить информацию о коде в удобной форме. Одна из возможностей – представить код в виде двоичного дерева, листья которого соответствуют кодируемым символам. При этом путь от вершины дерева до кодируемого символа определяет кодирующую последовательность битов: поворот налево дает 0, а поворотнаправо 1.
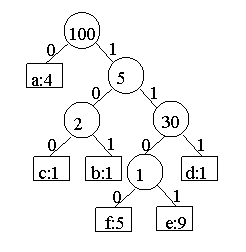

Итак, основной задачей при построении алгоритма Хаффмана является создание двоичного дерева, в котором всякая вершина, не являющаяся листом, имеет двоих детей. Зная дерево, легко найти количество символов, необходимых для кодирования файла.
Описание проделанной работы
Мною была поставлена задача: написать программу для сжатия файлов методом Хаффмана. Для ее выполнения я выбрал язык C++, среду разработки Borland C++ Builder 6.0.
Принцип работы программы.
Основой программы является класс архивации class Tree.
class Tree
{
private:
struct HeapElement
{
int priority;
int index;
HeapElement(int _priority, int _index) : priority(_priority), index(_index){};
};
friend bool operator<(const Tree::HeapElement h1, const Tree::HeapElement h2);
struct TreeElement
{
int left;
int right;
int c;
TreeElement(){c = -1;}
TreeElement(int _c) : c(_c){}
};
static const int MAXLEN = 1000;
std::vector<TreeElement> tr;
std::vector<bool> code[MAX];
int lenght;
void dfs(int x, bool *c = new bool[MAXLEN], int len = 0);
void setbit(unsigned char &byte, unsigned int n);
bool getbit(char byte, int n);
public:
Tree(int);
int encode(unsigned char *buffer, int buffsize, unsigned char *out);
int decode(char *buffer, int buffsize, char *out);
}
Он имеет приватные записи:
struct HeapElement – структура, содержащая сведения о частоте встречаемости символа. По сути является листом дерева.
struct TreeElement – структура, являющаяся узлом дерева. Содержит сыски на своих детей. Необходима для построения дерева архивации.
Далее будет указано, что эти структуры связаны. Структура TreeElement содержит ссылки на HeapElement (записи left и right).
Для экономии места в памяти, а также для удобства работы использованы динамические массивы:
std::vector<TreeElement> tr – массив из узлов. Заранее мы не можем определить, сколько будет узлов в дереве.
std::vector<bool> code[MAX] – массив типа bool*. То есть каждому элементу этого массива соответствует своя последовательность переменных типа bool. Этот массив нужен для хранения двоичного кода того или иного символа.
Работа с динамическими массивами удобна тем, что их легко переинициализировать, т. е. можно не меняя содержимого поменять их размер. Это удобно, т. к. пустые ячейки не будут «болтаться» в памяти.
void dfs – функция прохода по дереву и присвоения тому или иному символу его двоичного кода.
void setbit, bool getbit – функции для работы с битами. Побитовая запись/чтение идет в цикле по 8 операций за цикл. За цикл обрабатывается один байт. Если в коде символа встречается true, то при помощи логического или меняется значение бита на 1, если false, то бит просто пропускается. Когда пройдены все 8 бит, обрабатывается следующий байт.
Основными методами класса являются конструктор, работа которого будет описана ниже, также функции кодирования и декодирования.
Запуск программы можно произвести двумя способами.
Из командной строки huffman. exe file1 file2 param
Где file1 – исходный файл, file2 – конечный файл, param – необходимый параметр, может принимать два значения 1 – для сжатия, 2 – для восстановления.
При помощи пакетного файла MS DOS (.bat файл)
Синтаксис аналогичный
Пример:
Создаем текстовый документ в той же папке, где находится программа, пишем в нем
huffman. exe input. txt output. txt 1
Сохраняем текстовый документ с именем a. bat и запускаем. Программа сожмет файл input. txt в файл output. txt.
При запуске программы с параметром 1 запускается метод code().
При этом инициализируются два потока: поток бинарного считывания из файла, связанный с файлом file1 и переменной stdin, поток бинарной записи в файл, связанный с файлом file2 и переменной stdout.
Имена файлов file1 и file2 берутся командной строки как аргументы 1 и 2 соответственно.
Далее инициализируется массив int w[MAX] – в нем будет храниться информация о частоте встречаемости того или иного символа, также создается счетчик количества различных символов входного файла int t.
После этого весь файл считывается побуферно в массив unsigned char *tmp и считается размер файла. Далее массив пробегается, считается количество входов того или иного символа, это количество заносится в w[MAX]. Причем количество различных символов равно количеству непустых w[cc].
Затем запускается конструктор класса Tree tr(w). По сути, экземпляр класса Tree tr и является двоичным деревом, необходимым для архивации.
Конструктор класса имеет вид:
Tree::Tree(int w[MAX])
{
tr. resize(1000);
unsigned int trn = 0;
lenght = 0;
std::priority_queue<HeapElement> heap;
for(int i = 0; i < 1000; ++i)
tr[i].c = -1;
for(int i = 0; i < MAX; ++i)
if(w[i] != 0)
{
lenght += w[i];
heap. push(HeapElement(w[i], trn));
tr[trn++] = TreeElement((int)i);
}
while(heap. size() != 1)
{
HeapElement h1 = heap. top();
heap. pop();
HeapElement h2 = heap. top();
heap. pop();
HeapElement h(h1.priority + h2.priority, trn);
tr[trn].left = h1.index;
tr[trn++].right = h2.index;
if(trn == tr. size())
tr. resize(trn*2);
heap. push(h);
}
tr. resize(trn);
dfs(tr. size()-1);
}
При запуске конструктора инициализируется размер динамического массива tr. Его размер устанавливается равным 1000. Это число на самом деле завышено. В конечном итоге все равно размер массива будет максимально равен 255. Но это не суть важно, т. к. массив динамический, то мы в любое время можем отбросить нулевые элементы.
Далее создается сортированная очередь heap из структур HeapElement, т. е. очередь, элементы которой сортированы по определенному признаку. В нашем случае очередь сортирована по записям priority каждой структуры в очереди. Затем пробегается все возможные значения (int)char, которые могут присутствовать в файле, для каждого из присутствующих значений создается своя структура и ставится в очередь. Как уже было сказано, очередь сортирована по возрастанию, и элементы расположены по частоте встречаемости того или иного символа.
В цикле пока количество элементов в очереди не останется равным 1 (root = 100%) берутся 2 первых элемента из очереди с наименьшим числом вхождений. Они образуют узел. Узел со своим порядковым номером и числом вхождений, равным сумме вхождений его детей добавляется в очередь. Зная, где находится узел, можно всегда определить его детей. Дети узла создаются как структуры со своим символом и ссылкой на узел. После добавления узла в очередь, она сортируется и процесс «древообразования» продолжается.
После того, как дерево сформировано, созданы узлы, ветви и листья, выполняется функция dfs, которая выполняет проход по дереву, и кодирует каждый символ своей определенной последовательностью бит (здесь использована последовательность переменных типа bool). Но нужно учесть, что эта последовательность является массивом типа bool*, ее еще нужно перевести в последовательность битов. В итоге создается динамический массив типа bool* (либо проще, двумерный массив типа bool).
Далее, когда основная часть – создание дерева выполнена, запускается свойство класса Tree encode. Массив unsigned char* (по сути являющийся буфером) пробегается, при этом подсчитывается количество бит, которое будет в архивированном файле, каждый символ заменяется на свой двоичный код. Процесс замены описан выше в описании методов класса Tree.
После этой операции в выходной файл записывается информация для восстановления в виде <количество различных символов/n> <символ> <пробел> <число входов/n>. Этого достаточно для восстановления информации целиком, т. к. по сути, для создания дерева только это и требуется. При декодировании во входном файле сперва ищется количество различных символов. Это всегда число, стоящее в первой строке входного файла. После этого ищется комбинация <символ> <число> при помощи функции scanf("%c %d", &c, &k). Создается массив int w[int] такой же, как и при кодировании, в данном случае порядковым номером будет (int)char символа, значением – количество его входов. Далее запускается конструктор класса, который точно так же, как и при кодировании создает бинарное дерево, присваивает каждому символу определенную комбинацию бит. Далее идет проход по буферу, при помощи метода decode. В буфере ищется последовательность битов и заменяется на соответствующий ей символ. Массив с восстановленными символами выводится в файл. В конце все потоки закрываются.
Результаты работы программы
Программа была испытана на следующих типах файлов: .txt, .dat. doc, .exe, .cab, .bmp
Как это и следовало ожидать, программа показала свою работоспособность на текстовых документах, и также на изображениях типа. bmp, которые, по сути, также являются текстом. Сжатие архивов и большей части приложений .exe результата не принесло, часто архив был больше оригинала. Но это нормально, т. к. в этих файлах уже применено сжатие, т. е. это файлы с минимальной энтропией. Т. е. большая часть символов в них встречается равное число раз. По определению метод Хаффмана применить к таким файлам невозможно.
Примеры
Из папки %systemroot%\system32\ было взято приложение dxdiag. exe версии 5.3.2600.2180
Его размер составляет 1 298 432 байт, или примерно 1,23 МБ. После сжатия размер составил 1 070 982 байт, или примерно 1,02 МБ. Итого сжатие для данного приложения 82%, выигрыш при сжатии 18%.
Далее из этой же папки (для наглядности) был взят файл ieapfltr. dat версии 7.0.6004.3 размером 2 451 824 байт, или примерно 2,33 МБ. Этот файл является текстом в формате Unicode (UTF-8). После сжатия его размер стал 1 488 683 байт или примерно 1,41 МБ. Итого сжатие составило 61%. Выигрыш 39%.
Из этой же папки взят файл setup. bmp размером 240 120 байт. После сжатия размер архива стал 63 289 байт. Итого сжатие 26%, при этом выигрыш 74%.
Далее с установочного диска Windows XP Service Pack 2 из папки I386 был взят файл IIS6.CAB размером 2,76 МБ. После «сжатия» размер архива стал 3,69 МБ.
Выводы
Минусом в программе является ее быстродействие. Тесты показали, что время архивации зависит прямо пропорционально от размера архивируемого файла. Однако разархивирование происходит практически моментально. Это связано с тем, что при архивации во входном файле необходимо подсчитать частоту того или иного символа. По сути, этот пробег по файлу и занимает больше всего времени. При обратном процессе программа получает во входных данных эту информацию. Ей остается только восстановить дерево и заменить символы.
Также минусом является то, что не все файлы, взятые для эксперимента, уменьшили свой размер. Но это уже минус не программы, а самого метода. Метод Хаффмана не предполагает сжатие файлов, содержащих одинаковое количество вхождений для всех символов. Во многих файлах, зачастую текстовых, встречаются символы, частота которых равна 1 (это, конечно, необязательно). Такие файлы сжать труднее, чем файлы с различным количеством символов.
Еще один минус – невысокая степень сжатия. Но она напрямую зависит от количества различных символов в файле и от их частоты.
Огромный плюс – программа действительно работает и способна сжимать файлы (хотя и не все).
