


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рисунок 7. Экспоненциальный тренд
Экспоненциальный тренд описывает процессы, развивающиеся в условиях отсутствия значимых ограничений изменения уровня. Уровни тренда представляют собой геометрическую прогрессию. Очевидно, что обычно он имеет место на ограниченных отрезках времени.
Основное выражение гиперболического тренда
 .
.
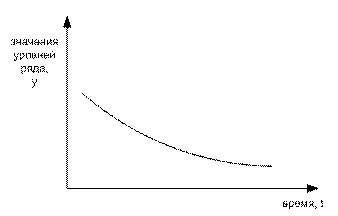
Рисунок 8. Гиперболический тренд
Свободный член уравнения, таким образом – это предел, к которому стремятся уровни ряда. Такая тенденция характерна для процессов демонстрирующих тенденцию к замедляющемуся снижению значений показателя, которые, однако, не могут уменьшиться более некоторого нижнего значения. Например, такими свойствами могут обладать тенденции снижения затрат на производство. В случае b < 0 с течением времени уровни тренда, наоборот, возрастают, стремясь к а.
Если изучаемый и прогнозируемый процесс приводит к замедлению роста показателя, но не вызывает прекращения роста, то вполне адекватным отображением тенденции может стать уравнение логарифмического тренда:
![]() .
.

Рисунок 9. Логарифмический тренд
Подбирая начало отсчета периодов, можно найти такую скорость изменений, которая наиболее точно отвечает фактическому временному ряду.
Логистическая форма уравнения тренда подходит для описания процесса, когда изучаемый показатель проходит полный цикл развития, начиная от нижнего (как правило, нулевого) уровня, сначала медленно с ускорением возрастая, после чего тенденция становится приблизительно прямолинейной. В завершающей части цикла рост замедляется по гиперболе по мере приближения к пределу. В некоторых зарубежных прикладных пакетах статистического анализа логистическая кривая называется S-образной кривой.
Можно считать логисту объединением сразу трех видов тенденций: парабола – прямая – гипербола. Но есть и доводы за рассмотрение логистического тренда как самостоятельного. Его выделение позволяет уже на первом этапе определить всю траекторию развития явления, выяснить сроки перехода от ускоренного роста к замедленному, что может оказаться весьма важно для прогноза.
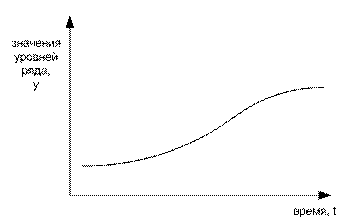
Рисунок 10. Логистический тренд
При изменении уровней от нулевого уравнение тренда по логисте имеет вид
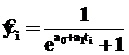 .
.
При а0 > 0 и а1 < 0 с ростом номера периодов времени будет иметь место тенденция роста уровней. Если нужно начать рост почти с нуля, то должно быть а0 ≈ 10. Чем больше будет модуль а1, тем быстрее будут возрастать уровни. При а1 < 0 и а2 > 0 имеет место тренд снижения уровней ряда, если нужно начать снижение почти от 1, то должно быть а0 ≈ –10. Чем больше будет а1, тем быстрее будут снижаться уровни.
Если диапазон изменения уровней ограничен не нулем и единицей, а обозначенными исходя из условий ymax и ymin , то формула логистического тренда примет вид
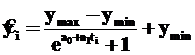
Графическое отображение во многих случаях позволяет приближенно выявить вид тип уравнения, наиболее адекватный тенденции временного ряда. Но при этом следует соблюдать некоторые правила построения графика. Требуется точное соблюдение масштаба как по величине уровней ряда, так и по шкале времени. Время откладывается обычно по оси абсцисс, величины уровней – по оси ординат. По каждой оси следует установить такой масштаб, чтобы ширина графика была примерно в 1,5 раза больше его высоты. Если уровни ряда различаются в десятки, сотни, тысячи раз, ось ординат имеет смысл разместить в логарифмическом представлении, равные отрезки будут означать различие уровней в одинаковое число раз. Тогда изменится и интерпретация графика: при линейном масштабе прямая будет означать прямолинейную тенденцию, при логарифмическом – экспоненту. Нужно соблюдать равенство величин, отображающих время на горизонтальной оси, тут логарифмическая шкала не рекомендуется, это значительно осложнит прочтение графика.
Но графический метод не всегда дает хороший результат. Например, таким путем трудно бывает отличить параболу от экспоненты, логарифмическую кривую от гиперболы и т. д. Хотя специализированные прикладные программные пакеты значительно облегчают анализ, в них нередко встроены средства быстрого расчета и нанесения на график линии тренда в соответствии с различными предположениями о его характере (например, нанесение линии тренда на диаграммы в MS Excel). Кроме того, не всегда вариант уравнения тренда, «лучший» внешне, является лучшим с аналитической и статистической точек зрения. Поэтому имеет смысл использовать и иные методы определения типа уравнения тренда: метод последовательных разностей, МНК (выбор уравнения тенденции, дающего наименьшую сумму квадратов отклонений)…
3.1.3. Особенности прогнозирования на основе трендовых моделей
Трендовое прогнозирование обладает свойств:
- для крупных сложных объектов и систем, обладающих большой инерционностью развития, прогноз по тренду, выявленному на базе изучения предыдущего развития, как правило, вполне реален и надежен;
- выясненные параметры тренда (то есть константы аппроксимирующих тренд выражений) должны быть статистически надежны, что достаточно легко проверить. Если они не надежны, то ненадежен и прогноз;
- срок упреждения прогноза должен быть не более половины периода основания прогноза (лучше – не более трети). То есть, если период основания прогноза, в рамках которого изучалась тенденция явления, составляет, скажем, 30 лет, то возможных период упреждения – 10 – 15 лет максимум.
У прогнозирования на базе временных рядов с помощью выясненной тенденции развития есть некоторые преимущества перед другими методами прогнозирования, есть и недостатки.
Уравнение тренда имеет преимущества перед «обычной» статистической регрессией по потенциальной ширине охвата факторов, влияющих на динамику изучаемого явления. Коэффициент при номере периода в уравнении тренда – это комплексный коэффициент регрессии при всех реальных факторах, влияющих на уровень изменяющегося показателя, которые сами изменяются во времени. «Обычная» регрессия (которая, кстати, составляет основу эконометрических моделей) позволяет учесть только часть факторов, влияние остальных «списывается» на ошибку регрессии.
Второе преимущество состоит в том, что уравнение тренда есть модель динамики процесса, и на ее основании мы прогнозируем динамику, т. е. логическая основа тренда соответствует задаче. Напротив, уравнение многофакторной регрессии – это модель вариации уровня показателя в статической совокупности. Логическая база прогноза по многофакторной регрессии в статике не совсем адекватна задаче прогнозирования.
Последнее, хотя и не очень существенное преимущество прогноза по тренду заключается в том, что для него не требуется большого объема исходной информации о факторах, как для множественной регрессии. Достаточно однородного по характеру тенденции периода, допустим, за 20 – 25 лет.
Но прогноз на основе временного тренда может не давать корректных результатов в случае высокой нестабильности объекта предсказания. Нет возможности проигрывать разные варианты прогноза при разных сочетаниях значений факторов, что обычно делается при прогнозе по регрессионной модели с управляемыми факторами (то есть сделать прогноз действительно вариативным). Кроме того, наилучшие результаты трендовое прогнозирование дает на относительно коротких периодах упреждения (краткосрочный, если по годам – среднесрочный прогноз).
Прогноз производится по такому общему алгоритму:
1. упорядочение прошлых данных;
2. сглаживание временного ряда;
3. выделение тренда;
4. определение уравнения тренда;
5. расчет прогнозного значения;
6. оценка доверительного интервала с заданной вероятностью.
В процессе выяснения тренда показателя может потребоваться учет повторяющихся колебаний в рамках самой основной тенденции, своего рода тренда внутри тренда. В данном случае речь идет о периодической колеблемости неслучайного характера, например, о сезонности. В этом случае трендовую модель имеет смысл дополнить до модели тренда и сезонности.
Такую коррекцию можно провести с помощью индексов сезонности. Сезонность – явление, имеющее обычно ежегодную повторяемость. Для ее определения желательно проанализировать данные по 7-ми – 10-ти периодам, в которых имеет она место. Можно обойтись и меньшим числом периодов (например, лет), но тогда достоверность наличия выявленной закономерности снижается.
Можно рассчитывать индексы сезонности как собой частное от деления отдельных уровней ряда на средний по всему ряду, для которого определяется сезонность, уровень. Например, сезонность в рамках года определима индексами, получаемыми в результате деления месячных уровней на среднемесячное значение уровня ряда за весь год. Умножение на 100 даст величину индекса в процентах.
Возможен и расчет сезонных индексов с использованием весов. Тогда используется несколько иной алгоритм расчетов. Обратимся к примеру расчета квартальной сезонности в течение года на основе помесячных данных за несколько лет:
1. определяются индексы сезонности путем соотнесения эмпирических данных (yi) с рассчитанными по уравнению тренда (![]() ) для сезона (месяц):
) для сезона (месяц):
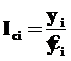 ;
;
2. рассчитываются средние значения уровня ряда ![]() за периоды, для которых предполагается тенденция сезонности (в данном примере – по годам), достаточно средней арифметической простой;
за периоды, для которых предполагается тенденция сезонности (в данном примере – по годам), достаточно средней арифметической простой;
3. определяется средневзвешенное значение индекса сезонности (![]() ) для каждого уже укрупненного периода времени – собственно сезона (квартал). Роль весов играют средние значения уровней ряда для годов, рассчитанные ранее, где
) для каждого уже укрупненного периода времени – собственно сезона (квартал). Роль весов играют средние значения уровней ряда для годов, рассчитанные ранее, где ![]() – индексы сезонности по месяцам:
– индексы сезонности по месяцам:
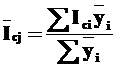 .
.
Далее модель тренда преобразуется в мультипликативную модель трена и сезонности: значения ряда, рассчитанные по тренду, домножаются на соответствующий сезону индекс сезонности.
Учет периодической колеблемости может осуществляться и иными способами (например, на основе рядов Фурье).
3.2. Эконометрическое моделирование
3.2.1. Общее понятие эконометрических моделей
Эконометрические модели (в основе которых лежат методы статистики, точнее – регрессионного анализа) из всех формализованных методов прогнозирования используются, возможно, наиболее часто (по крайней мере, за рубежом).
В качестве самостоятельной отрасли знания эконометрика оформилась в начале 30-х годов XX века. Термины «эконометрика» и «эконометрия» стали общеупотребительными благодаря норвежскому экономисту Р. Фришу. Фришу, эконометрика объединяет «как чистую экономическую теорию, так и статистическую проверку законов чистой экономической теории». Более конкретно: «сущность эконометрики заключается во взаимном переплетении количественной экономической теории и статистических оценок».[27] Отсюда следует, что к числу эконометрических относятся отнюдь не все модели, а лишь такие, которые позволяют проводить статистические операции. Существует не мало моделей и развернутых на их основе «количественных теорий», являющихся экономико-математическими, но вовсе не эконометрическими. Поскольку за каждой переменной эконометрической модели стоит определенный статистический индикатор, с той или иной точностью измеряющий какую-то сторону хозяйственного механизма, расчеты на базе этой модели, как правило, имеют достаточно высокую практическую ценность. Они могут быть использованы при выработке экономической политики государства, рыночной стратегии фирмы и решении других конкретных задач.
Методологическая особенность эконометрики заключается в применении общих гипотез о статистических свойствах экономических параметров и ошибок при их измерении. Полученные при этом результаты могут оказаться нетождественными тому содержанию, которое вкладывается в реальный объект. Поэтому важная задача эконометрики – создание как более универсальных, так и специальных методов для обнаружения наиболее устойчивых характеристик в поведении реальных экономических показателей. Эконометрика разрабатывает методы «подгонки» формальной модели с целью наилучшего имитирования ею поведения моделируемого объекта на основе гипотезы о том, что отклонение модельных параметров от реально наблюдаемых случайны и вероятностные характеристики их известны.
Главным инструментом эконометрики служит эконометрическая модель – модель факторного анализа, параметры которой оцениваются средствами математической статистики. Такая модель выступает в качестве средства анализа и прогнозирования конкретных экономических процессов на основе реальной статистической информации.
Можно выделить два основных класса эконометрических моделей:
1) Регрессионные модели с одним уравнением. В таких моделях зависимая (объясняемая) переменная Y представляется в виде функции ![]() , где x1, …, хn – независимые (объясняющие) переменные, β1, …, βm – параметры. В зависимости от вида функции f(x, β) модели делятся на линейные и нелинейные. Например, можно исследовать среднедушевой уровень потребления населения как функцию от уровня доходов населения и численности населения, или зависимость заработной платы от возраста, пола, уровня образования, стажа работы и т. п. По математической форме они могут быть схожи с моделями временных рядов, в которых в качестве независимой переменной выступает значение момента времени
, где x1, …, хn – независимые (объясняющие) переменные, β1, …, βm – параметры. В зависимости от вида функции f(x, β) модели делятся на линейные и нелинейные. Например, можно исследовать среднедушевой уровень потребления населения как функцию от уровня доходов населения и численности населения, или зависимость заработной платы от возраста, пола, уровня образования, стажа работы и т. п. По математической форме они могут быть схожи с моделями временных рядов, в которых в качестве независимой переменной выступает значение момента времени
Область применения таких моделей, даже линейных, значительно шире, чем моделей временных рядов. Проблемам теории оценивания, верификации (проверки на практике), отбора значимых параметров и другим посвящен огромный объем литературы. Эта тема – стержневая в эконометрике.
2) Системы одновременных уравнений. Эти модели описываются системами уравнений. Системы могут состоять из тождеств и регрессионных уравнений, каждое из которых (кроме независимых переменных) может включать в себя также зависимые переменные из других уравнений системы. В результате имеется набор зависимых переменных, связанных через уравнения системы, решаемые одновременно. Примером может служить модель Уортона, имеющая очень большую размерность (уортоновская квартальная модель американской экономики содержит более 1 тыс. уравнений).
3.2.2. Линейная регрессия. Метод наименьших квадратов (МНК)
С помощью методов регрессионного анализа, основных для эконометрического моделирования, строятся и проверяются модели, характеризующие связь между одной эндогенной (зависимой) переменной и одной или более экзогенными (независимыми) переменными. Независимые переменные называются регрессором.
Направленность связи между переменными определяется путем предварительного обоснования и включается в модель в качестве исходной гипотезы. Задача регрессионного анализа – проверка статистической состоятельности модели, если данная гипотеза верна. Регрессионный анализ не в состоянии «доказать» гипотезу, он может лишь подтвердить ее статистически или отвергнуть.
Рассмотрим методологию построения регрессионных эконометрических моделей на примере моделей из одного уравнения. Модели в виде системы уравнений, обладая своими особенностями (в частности, при определении параметров-коэффициентов модели) также базируются на ней[28].
В общем виде регрессионное уравнение выглядит так:
![]() ,
,
где ![]() – функция, которая описывает детерминированную составляющую модели (само уравнение регрессии), ε представляет собой «случайную» компоненту.
– функция, которая описывает детерминированную составляющую модели (само уравнение регрессии), ε представляет собой «случайную» компоненту.
Обычно наиболее часто для отображения зависимости используются линейные регрессионные уравнения, отображающие зависимость в виде прямой в многомерном пространстве. В случае с парной линейной регрессией это знакомое всем со школы уравнение прямой:
![]() .
.
Здесь α – постоянная составляющая, то есть даже если х = 0, то Y все равно будет иметь какое-либо положительное или отрицательное значение; β обычно называют коэффициентом регрессии, он отражает наклон линии графика, вдоль которой рассеяны значения Y, выявленные в результате наблюдения за поведением Y, а не в результате расчетов в соответствии с моделью; ε – ошибка или значение помехи, также называемая остатком. Существование остатка может объяснимо либо тем, что кроме рассматриваемого фактора х на значение зависимой переменной могут влиять и другие факторы, неучтенные в модели, либо трудностями измерения х. Математическое ожидание (среднее значение) ошибки ε равно нулю.
В качестве факторной переменной может учитываться показатель времени t. Тогда мы имеем дело с уравнением тренда. В случае с линейным трендом значения t = 1, 2, 3 … n.
Метод наименьших квадратов (МНК, англ. Ordinary Least Squares, OLS) является одним из основных методов определения параметров регрессионных уравнений, Он заключается в том, чтобы определить вид кривой, характер которой в наибольшей степени соответствует выраженной эмпирическими данными зависимости. Такая кривая должна обеспечить наименьшее значение суммы квадратов отклонений эмпирических значений величин показателя от значений, вычисленных согласно уравнению этой кривой. Меняя вид теоретических кривых, приближенно отображающих динамику рассматриваемого показателя, пытаются добиться как можно меньшего значения этой разности.
Пусть теоретическая зависимость линейна (парная регрессия, прямая в двухмерном пространстве) и выражена регрессионным уравнением:
![]() .
.
Коэффициент b можно определить по формуле
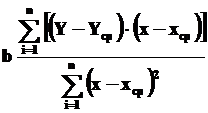
Найдем a, подставив в уравнение прямой, параметры которого находим, значение уже известного параметра b и средние значения xср и Yср:
![]()
Допустим, связь между двумя показателями парной регрессии выражена функцией
![]() ,
,
то есть в виде многочлена степени k.
– матрица коэффициентов системы (2.19). В случае, когда величины хi (то есть, в различных наблюдениях i) различны, столбцы матрицы Х линейно независимы. Тогда вектор-столбец ![]() [29] коэффициентов многочлена Y(х) является единственным решением матричного уравнения:
[29] коэффициентов многочлена Y(х) является единственным решением матричного уравнения:
![]() ,
,
где ![]() – вектор столбец последовательных значений величины Y. Отсюда a (вектор оценок параметров) может быть найден по формуле:
– вектор столбец последовательных значений величины Y. Отсюда a (вектор оценок параметров) может быть найден по формуле:
![]() ,
,
Пусть
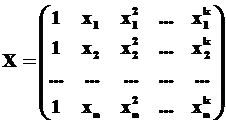
Линейная многомерная регрессионная модель (модель множественной линейной регрессии) является обобщением модели парной линейной регрессии. Она имеет вид:
![]() ,
, ![]()
где Хmt – значение фактора-регрессора Хm в момент наблюдения t, при α0 вектор независимых переменных Х0 = (1, 1, …, 1). В этом случае α0 – так называемый свободный член. Такая модель с учетом допущений, перечисленных выше, называется нормальной линейной регрессионной моделью.
Удобно будет представить формулу (2.23) в матричном виде. Обозначим через Y вектор-столбец значений зависимой переменной (Y1, Y2, …, Yn); α вектор-столбец коэффициентов (α0, α1, α2, …, αm); ε – вектор-столбец стохастических компонент (ошибок) (ε0, ε1, ε2, …, εn); Х – матрица независимых переменных размерности nxm:
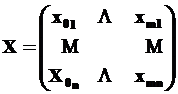
Получим матричную запись системы, состоящей из уравнений вида
![]() .
.
Отсюда, учитывая обратимость матрицы XTX, находим вектор оценок коэффициентов системы, при чем это будет сделано в соответствии с формулой, в точности повторяющей уже знакомую нам формулу:
![]() .
.
Для обоснованного применения метода наименьших квадратов данные должны соответствовать ряду допущений:
1) Математическая форма зависимости эндогенных переменных от экзогенных переменных модели носит линейный характер (другие типы уравнений, отражающих зависимость значения одной переменной от других, должны быть приведены к линейному виду, прежде чем возможно будет использовать метод наименьших квадратов), и независимые переменные модели являются единственными значимыми факторами, определяющими поведение зависимой переменной;
2) Значение ошибки ε нормально распределено со средней, равной 0, и постоянной дисперсией ![]() ,
, ![]() . То есть, хотя значение переменной Y значимо определяется только учтенными в модели факторными признаками, существует также ряд второстепенных факторов, некоторые из которых будут положительно влиять на величину Y, некоторые – отрицательно. В случае множества как положительных, так и отрицательных влияний значение ошибки ε будет нормально распределено. Нормальное распределение полностью определяется двумя параметрами: средней и средним квадратическим отклонением (дисперсией σ2). Чем больше случайных величин действует вместе, тем точнее проявляется закон нормального распределения. Допущение о постоянной дисперсии говорит о постоянности разброса значений ε, вне зависимости от величины значения факторов. Тогда значение ошибки обладает свойством гомоскедастичности. Если разброс значений ошибки ε непостоянен, то имеет место явление гетероскедастичности.
. То есть, хотя значение переменной Y значимо определяется только учтенными в модели факторными признаками, существует также ряд второстепенных факторов, некоторые из которых будут положительно влиять на величину Y, некоторые – отрицательно. В случае множества как положительных, так и отрицательных влияний значение ошибки ε будет нормально распределено. Нормальное распределение полностью определяется двумя параметрами: средней и средним квадратическим отклонением (дисперсией σ2). Чем больше случайных величин действует вместе, тем точнее проявляется закон нормального распределения. Допущение о постоянной дисперсии говорит о постоянности разброса значений ε, вне зависимости от величины значения факторов. Тогда значение ошибки обладает свойством гомоскедастичности. Если разброс значений ошибки ε непостоянен, то имеет место явление гетероскедастичности.
3) Последующие значения ошибок независимы друг от друга, то есть ковариация в парах значений ε равна нулю (covεiεj = 0). Это означает, что второстепенные факторы или факторы-причины ошибки для одной из величин Y, не приводят автоматически к ошибкам для всех наблюдений Y. Когда значения ε независимы, то данные неавтокоррелированы. Если же значения ε не являются независимыми, то данные демонстрируют наличие автокорреляции.
4) Независимые переменные являются нестохастическими, то есть их значения для модели детерминированы, заданы изначально.
Процесс построения и использования эконометрических моделей является достаточно сложным и подразумевает следующее:
1) после определения цели исследования необходимо построить систему показателей и логически рассортировать факторы, в наибольшей степени влияющие на каждый показатель;
2) осуществляется выбор формы связи изучаемых показателей между собой и отобранными факторами, другими словами, выбор типа эконометрической модели (линейная, нелинейная, степенная и т. д.);
3) решается проблемы сбора исходных данных и анализа информации;
4) строится эконометрическая модель, то есть определяются ее параметры;
5) проверяется качество построенной модели, в первую очередь ее адекватность изучаемому явлению, после чего модель может быть использована для экономического анализа и прогнозирования.
3.2.3. Отбор переменных эконометрической модели
Особое внимание следует обратить на построение системы показателей и определение совокупности факторов, влияющих на каждый из показателей. К включаемым в эконометрическую модель факторам предъявляются требования:
· включение каждого фактора в модель следует обосновать теоретически;
· целесообразно учитывать только те факторы, которые оказывают существенное влияние на изучаемые показатели, при этом рекомендуется, чтобы количество включаемых в модель факторов не превышало одной трети от числа наблюдений в выборке (длины временного ряда);[30]
· между факторами не должно существовать линейной зависимости, поскольку ее наличие будет означать, что они характеризуют влияние одной и той же по сути причины на показатель. Например, размер заработной платы работников зависит в том числе и от роста производительности труда и от объема выпускаемой продукции. Однако эти два фактора могут быть тесно взаимосвязаны, коррелированны, следовательно в модель целесообразно включить лишь один из них. Включение в модель линейно зависимых факторов приводит к возникновению мультиколлинеарности, которая отрицательно сказывается на качестве модели;
· в модель рекомендуется включать только те факторы, которые могут быть измерены количественно;
· в одну модель не следует включать какой-либо фактор одновременно с образующими его частными факторами. Это приведет к не соответствующему реальности увеличению их влияния на зависимые переменные модели и, как следствие, к искажению отображения реальной действительности.
При отборе факторов, влияющих на зависимые переменные модели, используются статистические методы отбора. Так, существенного сокращения числа факторов (а значит – сделать модель менее громоздкой) можно достичь с помощью применения пошаговых процедур отбора переменных. Их можно сочетать и с другими подходами к решению проблемы, например, с экспертными методами оценки значимость факторов. Среди пошаговых процедур отбора факторов часто используются процедуры пошагового включения и исключения факторов.
Метод исключения предполагает построение уравнения, включающего некоторую начальную совокупность переменных с последующим последовательным сокращением их числа до тех пор, пока не будет выполнено заданное изначально при составлении уравнения условие. Применение метода включения подразумевает последовательное включение в модель все новых переменных, пока модель не станет соответствовать установленному критерию качества модели. Последовательность включения переменных в модель определяется с помощью частных коэффициентов корреляции: те переменные, для которых значение такого коэффициента, показывающего их связь с исследуемым показателем, больше, чем для прочих, включаются в регрессионное уравнение в первую очередь.
Одним из критериев одновременного включения или невключения нескольких признаков-факторов в модель является их линейная независимость. Если данная предпосылка не выполняется, то возникает явление мультиколлинеарности, то есть наличие сильной корреляции между некоторыми независимыми переменными модели (факторами). В содержательном аспекте мультиколлинеарность приводит к искажению смысла коэффициентов регрессии и затрудненности выявления наиболее влиятельных факторов.
Основные причины мультиколлинеарности: независимые переменные либо характеризуют одно и то же свойство изучаемого явления, либо их влияния являются составными элементами влияния одного и того же признака.
Наиболее распространенным методом выявления мультиколлинеарности является метод корреляции. Устраняют мультиколлинеарность чаще всего исключением одного из таких факторов.
3.2.4. Оценка качества параметров и анализ эконометрической модели
Описывавшиеся выше модели линейной регрессии являются вероятностными, а определяемые на основе метода наименьших квадратов параметры уравнений регрессии – только лишь оценками a и b истинных параметров a и b зависимости эндогенной переменной от некоторых экзогенных. Таким образом, нужно проверить, насколько данные оценки верны относительно истинных коэффициентов. Это осуществляется путем проверки:
статистической значимости коэффициентов регрессии;
близости расположения фактических данных к рассчитанной линии регрессии.
Оценки коэффициентов регрессии так же, как и ошибка (стохастическая компонента уравнения регрессии), предположительно нормально распределены. Статистическая значимость коэффициентов измеряется степенью вариации вокруг оценочного значения. Для измерения величины вариации нормально распределенных ошибок, остатков используется среднее квадратическое отклонение этих остатков – стандартные ошибки коэффициентов. Для определения степени значимости коэффициентов используется t-критерий. Для того чтобы иметь возможность их определить, нужно узнать оценки их дисперсий и, таким образом, средних квадратических отклонений.
После можно проверить гипотезу относительно коэффициентов либо определить для них доверительные интервалы.
Оценки параметров уравнения парной линейной регрессии. Надежность полученных оценок коэффициентов α и β, очевидно, зависит от дисперсии стохастической компоненты уравнения регрессии ε. Однако по данным выборки значений переменных модели дисперсия ε не может быть оценена, то при анализе надежности оценок коэффициентов регрессии используется дисперсия отклонений эмпирических значений переменной Y от рассчитанных на основе полученного уравнения: еi = Yi – a – bxi.
В случае парной линейной регрессии дисперсия b – оценки β равна:
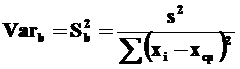
Дисперсия α равна
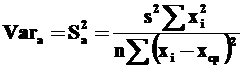
Здесь
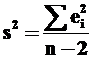
мера разброса значений зависимой переменной вокруг линии регрессии – так называемая «необъясненная дисперсия», «остаточная дисперсия». Sa и Sb – стандартные отклонения случайных величин a и b. Коэффициент b – коэффициент наклона линии регрессии. Чем больше разброс значений зависимой переменной вокруг линии регрессии, тем большей (в среднем) окажется ошибка в определении наклона линии регрессии. Если же все значения Y расположены на линии регрессии (ei = 0, а, значит, σ² = 0), то ошибки в определении значений коэффициентов a и b отсутствуют (отсюда – s2, соответствующее σ², равно нулю).
Формально значимость оцененного коэффициента регрессии b может быть проверена с помощью анализа его отношения к своему стандартному отклонению ![]() . Эта величина в случае соблюдения исходных предпосылок модели характеризуется t-распределением Стьюдента с n–2 степенями свободы, где n – число наблюдений:
. Эта величина в случае соблюдения исходных предпосылок модели характеризуется t-распределением Стьюдента с n–2 степенями свободы, где n – число наблюдений:
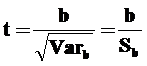
Для t-статистики проверяется гипотеза о равенстве ее нулю. t = 0 будет означать b = 0.
При оценке коэффициента линейной регрессии можно использовать следующее грубое правило. Если стандартная ошибка коэффициента больше его модуля (│t│<1), то он не может быть признан «хорошим», значимым, поскольку доверительная вероятность при двусторонней альтернативной гипотезе составляет менее приблизительно 0,7. Если стандартная ошибка меньше модуля коэффициента, но больше его половины (1<│t│<2), то данная оценка коэффициента может рассматриваться как более или менее значимая (доверительная вероятность от 0,7 до 0,95). Значение t от 2 до 3 свидетельствует о наличии весьма значимой связи (доверительная вероятность от 0,95 до 0,99), │t│>3 означает практически стопроцентное подтверждение ее наличия. Несомненно, в каждом случае определенную роль играет количество наблюдений: чем их больше, тем надежнее при прочих равных условиях выводы о наличии связи и тем меньше граница доверительного интервала для данного числа степеней свободы и уровня значимости. Однако эти различия существенны лишь для малых n, а при n≥10 сформулированные правила приблизительно верны.
Для осуществления проверки значимости оценок коэффициентов регрессии нужно решить, будет ли она односторонней или двусторонней. Выбор определяется теоретическим обоснованием модели связи зависимой и независимой переменных. При этом односторонняя проверка предполагает, что характер связи между X и Y однозначен: либо связь отрицательна, либо положительна, но не то и другое одновременно. При двусторонней проверке исходят из предположения, что связь между X и Y может быть как положительной, так и отрицательной.
С помощью рассчитанных стандартных отклонений и значений t-статистики можно определить доверительный интервал значений α и β с заданной доверительной вероятностью. Предполагаемые значения α и β будут находиться в рамках этого интервала, если же нет, то придется отвергнуть предположение, выдвинутое относительно величины α и β:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
